在Python中需要通過正則表達式對字符串進?匹配的時候,可以使??個python自帶的模塊,名字為re。
re模塊的使用:import re
一、匹配函數
1-1、re.match函數:返回匹配對象
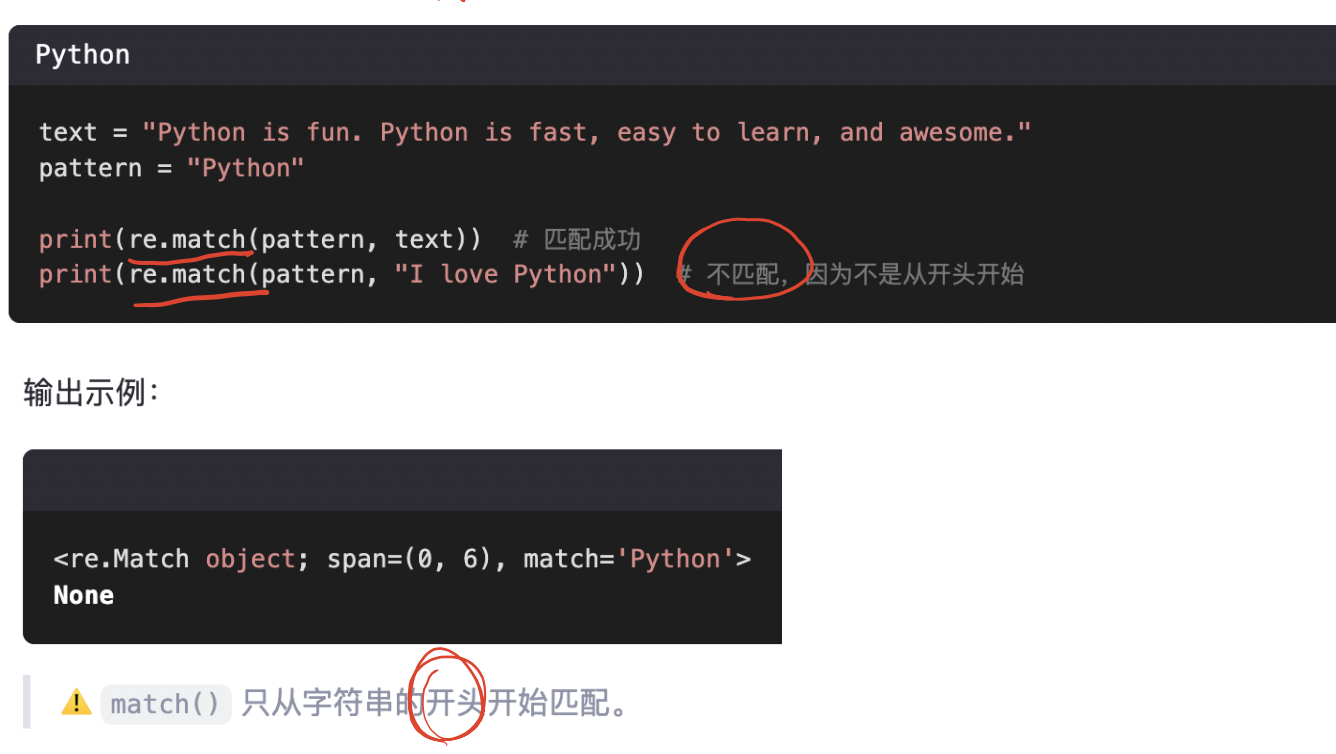
match函數實現的是精準匹配,嘗試從字符串的開頭匹配模式,如果匹配成功,則返回一個匹配對象,否則返回None。
語法:
re.match(pattern, string)-
只在 字符串開頭 嘗試匹配
-
如果開頭不匹配,就直接返回
None
示例:
1-2、re.search函數:返回匹配對象
search()可以在整個字符中查找第一個匹配項,而不僅僅是從開頭!返回第一個匹配到的結果!
語法:
re.search(pattern, string)-
從 整個字符串 中找 第一個匹配
-
找到就返回
Match對象,沒有就None
示例:

【小結】:re.match()函數 VS re.search()函數
re.match()和re.search()都是 只找第一個匹配,一旦找到就停止,不會繼續往下找。如果你想要 所有匹配,就得用
re.findall()(直接得到 list)
re.finditer()(得到迭代器,能看位置等更多信息)
| 方法 | 從哪里開始找 | 找到一個后 | 常見用途 |
|---|---|---|---|
re.match() | 從字符串 開頭 開始匹配 | 停止,不再繼續 | 檢查開頭是否符合格式(如校驗手機號、日期) |
re.search() | 從字符串 任意位置 開始找 | 停止,不再繼續 | 找字符串中 第一次 出現的匹配 |
1-3、re.findall函數:直接返回 列表(list)
語法:
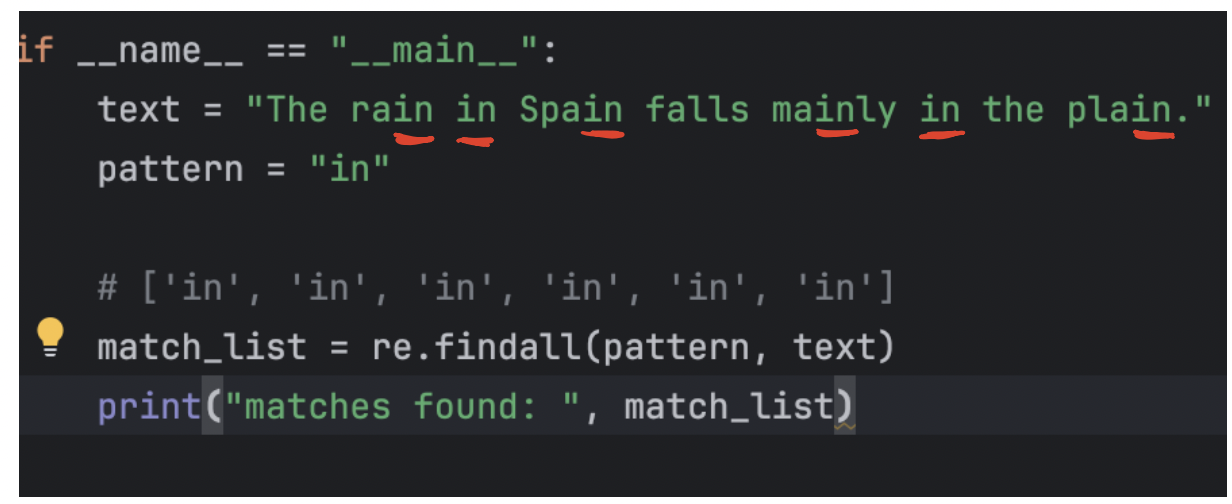
re.findall(pattern, string)-
找到 所有非重疊匹配的列表,直接返回 列表(
list) -
如果 pattern 中有分組,只返回分組匹配的內容
示例:
1-4、re.finditer函數:返回一個 迭代器
語法:
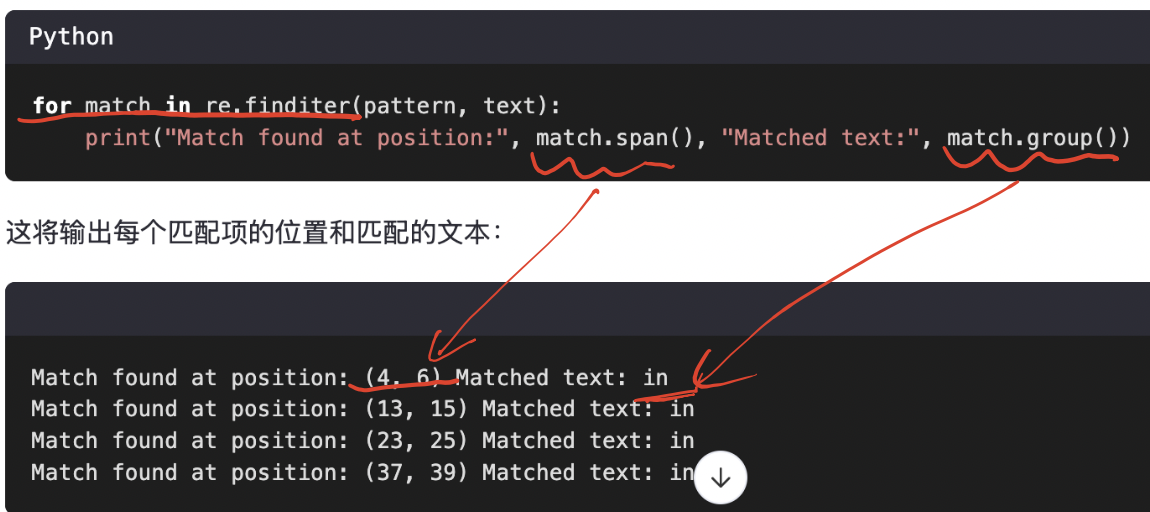
re.finditer(pattern, string)-
找到所有匹配,但返回的是一個 迭代器(每個元素是
Match對象) -
更適合需要匹配位置或懶加載的場景
若是你想遍歷所有的匹配項,并且希望得到每個匹配項更多的信息(如:位置),可以使用re.finditer函數。
二、raw-string 格式(原始字符串)
1. 什么是 raw-string
-
Python 普通字符串中,
\是 轉義符-
"\n"代表換行 -
"\t"代表制表符
-
-
在 raw-string(原始字符串)中,
\不會被當作轉義符,而是原樣保留 -
寫法是在字符串前加
r或R:
s1 = "a\nb"
s2 = r"a\nb"print(s1) # a 換行 b
print(s2) # a\nb
2. 為什么正則特別需要 raw-string
正則表達式里 反斜杠 \ 本身就是語法的一部分(比如 \d, \w, \s 等),
如果不用 raw-string,就得寫雙反斜杠來避免 Python 把它當作轉義符。
例子:
import re# 不用 raw-string
pattern1 = "\\d+" # Python 字符串先轉義成 \d
print(re.findall(pattern1, "a123b")) # ['123']# 用 raw-string
pattern2 = r"\d+" # \d 原樣傳給正則引擎
print(re.findall(pattern2, "a123b")) # ['123']
結果是一樣的,但 raw-string 更直觀,省得到處寫 \\。
3. 什么時候不能用 raw-string
-
raw-string 里最后一個字符不能是單個反斜杠:
r"abc\" # ? 會報錯
因為 Python 語法本身需要 \ 轉義引號,raw-string 也要遵守。
4. 總結
| 寫法 | Python 看到的內容 | 適合場景 |
|---|---|---|
"\\d+" | \d+ | 正則,但寫法麻煩 |
r"\d+" | \d+ | 正則推薦寫法 |
建議你記成一句話:“寫正則時,前面加個 r,少寫反斜杠,多活十年。”?
三、常用正則表達式常見的符號
3-1、匹配單個字符
| 字符 | 功能 | |
| . | 匹配除換行符\n以外的任意單個字符。 | |
| [ ] | 匹配[ ]中列舉的字符 | [abc]:?匹配 a 或 b 或 c 中的一個字符 |
| [^ ] | 匹配不是[ ]中列舉的字符 | [^abc]:匹配 不是 a/b/c 的一個字符 |
| \d | 匹配數字 | 等價于:[0-9] |
| \D | 匹配非數字 | 等價于:[^0-9] |
| \s | 匹配空白符(空格、制表符\t、換行\n,換頁\f、回車\r 等) | 等價于:[ \t\n\r\f\v] |
| \S | 匹配非空白字符 | [^ \t\n\r\f\v] |
| \w | 匹配單詞字符(字母、數字、下劃線) | [a-zA-Z0-9_] |
| \W | 匹配非單詞字符 | [^a-zA-Z0-9_] |
記憶技巧
d→ digit(數字)
s→ space(空格)
w→ word(單詞字符)大寫版本(
\D \S \W)就是取反
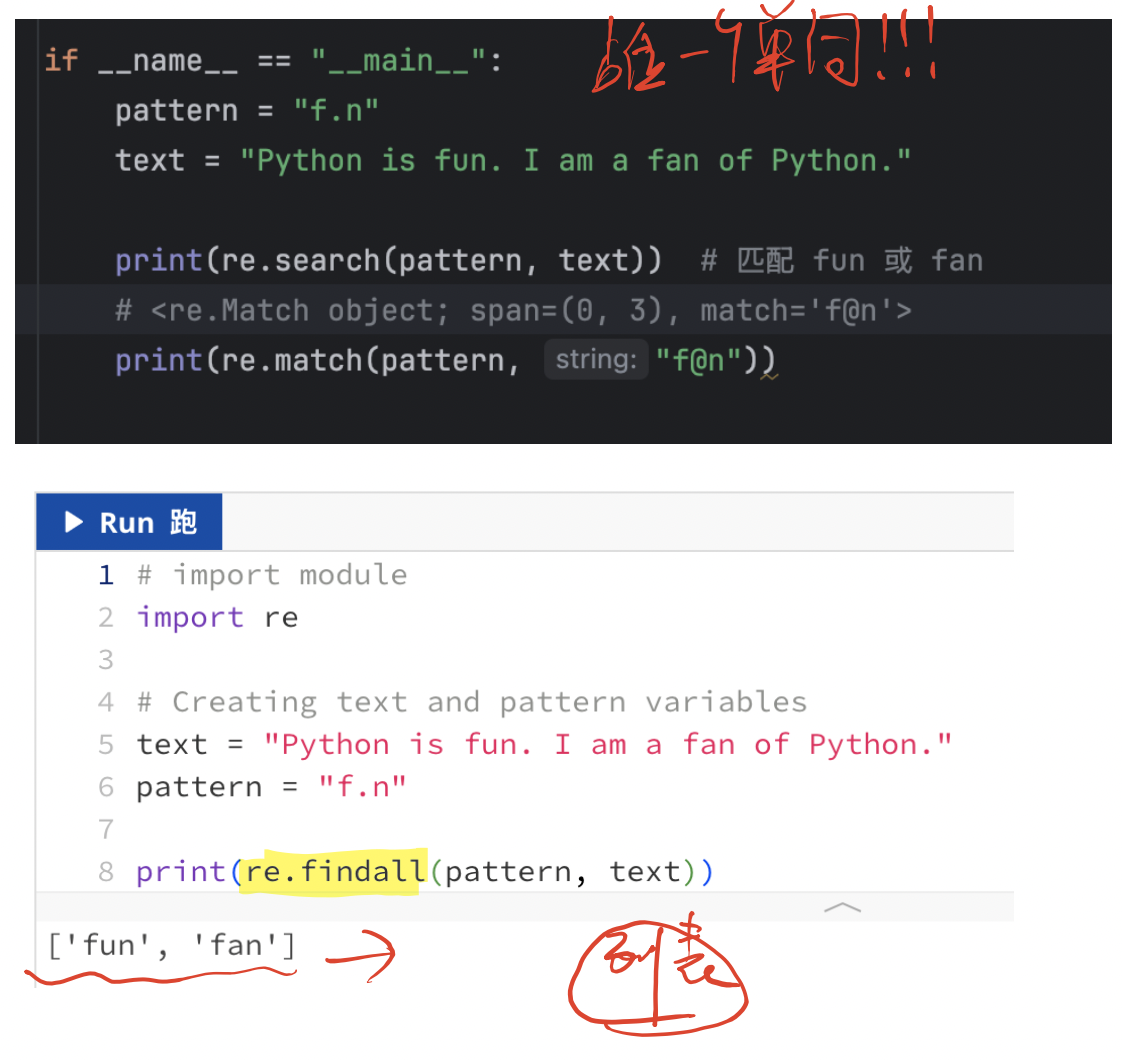
1、.(點號)
匹配除換行符\n以外的任意單個字符。
【注意】:
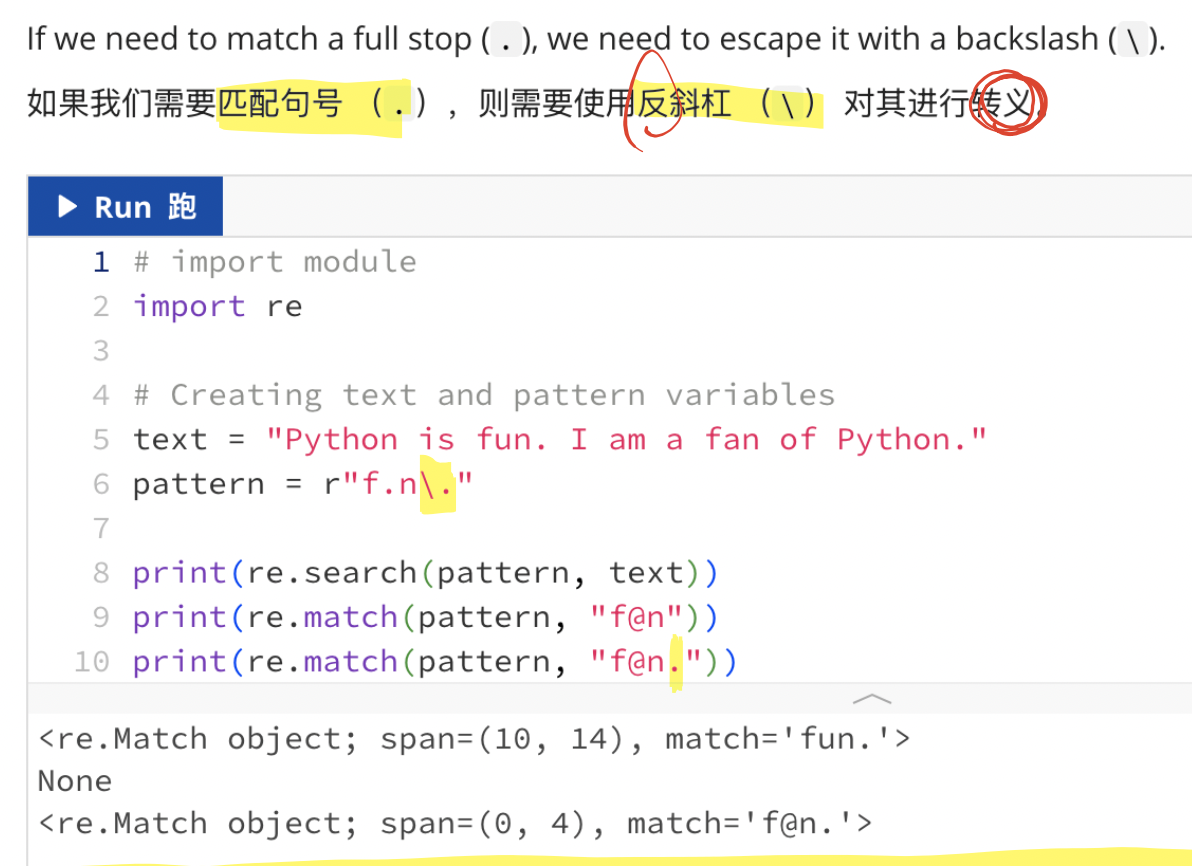
2、匹配一組字符:[ ]
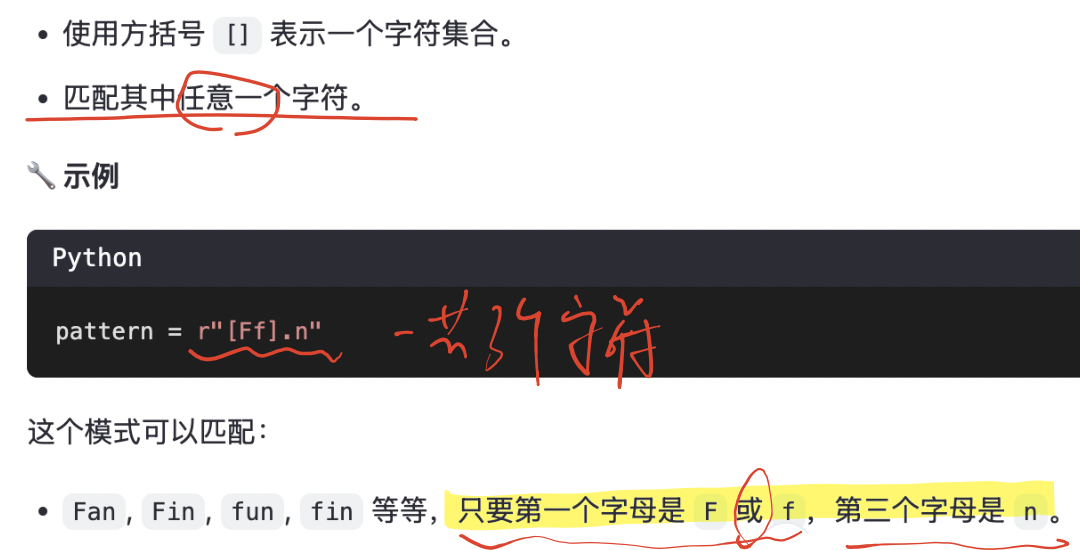
【注意】:

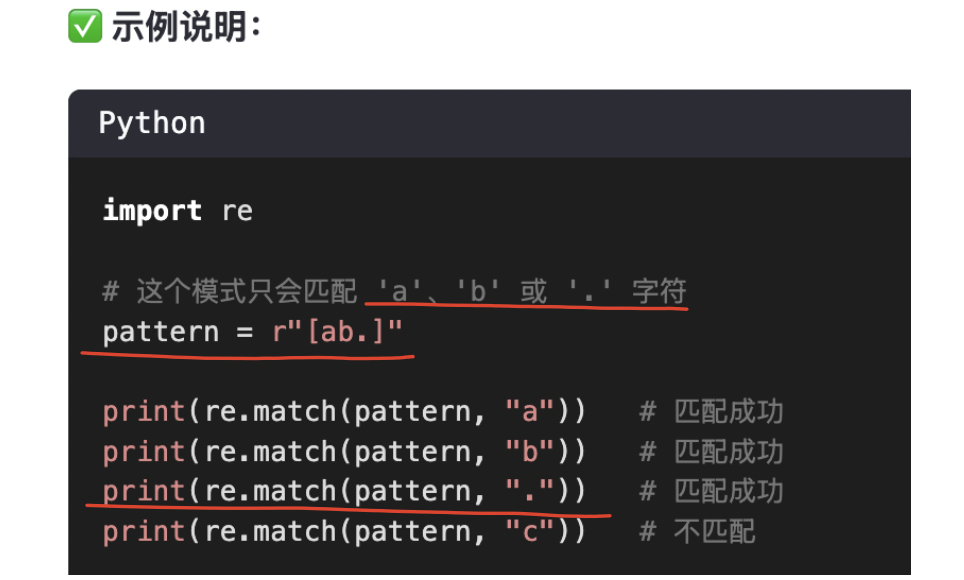
【注意1】:
在 正則表達式 里,方括號 [ ] 不是用來表示數值范圍的,而是用來表示 “字符集合”。
正則里的 [] 永遠是匹配單個字符:
-
[abc]→ 匹配a或b或c中的一個字符 -
[0-9]→ 匹配 0 到 9 中的一個數字字符 -
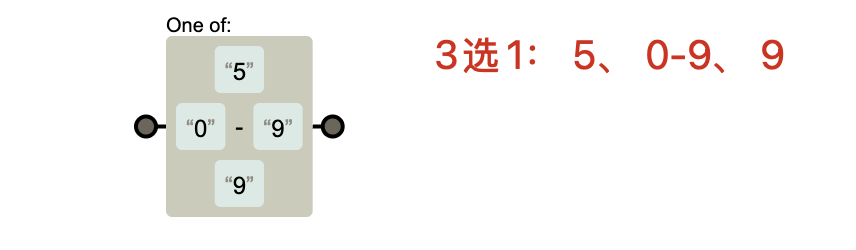
[50-99]→ 不是匹配兩位數,而是:-
匹配
5 -
或匹配 0~9 之間的單個數字字符,實際等價于
[0-9],只是多寫了個5,沒啥區別。
-
如果你要匹配 50 到 99 的數字,不能用 [50-99],而是:
5[0-9]|9[0-9] # 兩位數寫法【記住】:
[ ]→ 字符集合,一次只匹配一個字符!!!!
【注意2】:
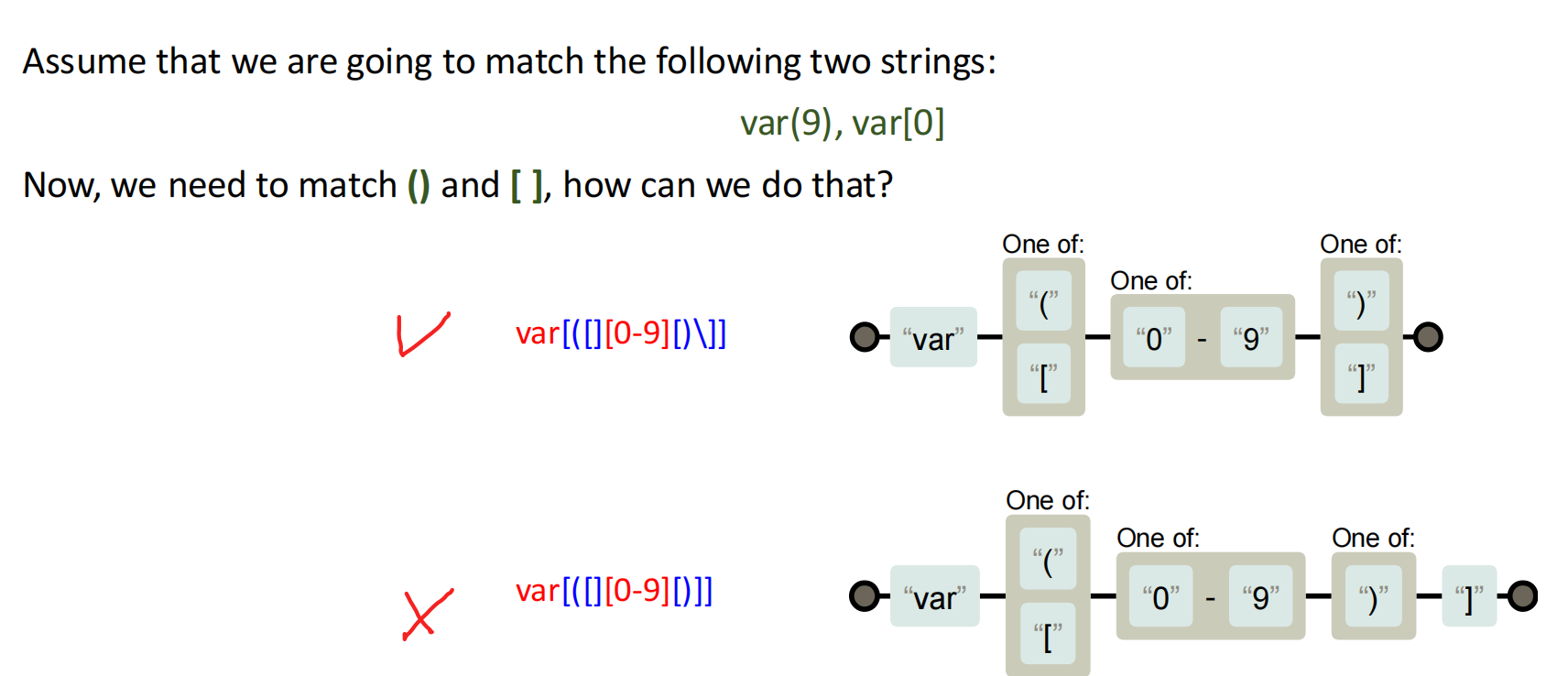
]在集合里如果不是第一個字符,需要用\]轉義,否則會被當作結束方括號。
3、排除一組字符[^...]

4、匹配一組范圍:[x-z]
5、綜合練習

3-2、匹配多個字符
| 數量詞 | 含義 | 示例 | 匹配效果(字符串 "aaab") |
|---|---|---|---|
* | 0 次或多次 | a* | 'aaa' |
+ | 1 次或多次 | a+ | 'aaa' |
? | 0 次或 1 次 | a? | 'a' |
{n} | 恰好 n 次 | a{2} | 'aa' |
{n,} | 至少 n 次 | a{2,} | 'aaa' |
{n,m} | n 到 m 次 | a{1,3} | 'aaa' |
以上這些字符也稱為量詞!
在正則表達式里,數量詞(Quantifier)就是用來描述 某個模式重復出現多少次 的符號。
1、*和+
- *:匹配前?個字符出現 0次或者多次;(>= 0)
- +:匹配前?個字符出現 一次或者多次。(>= 1)
示例:
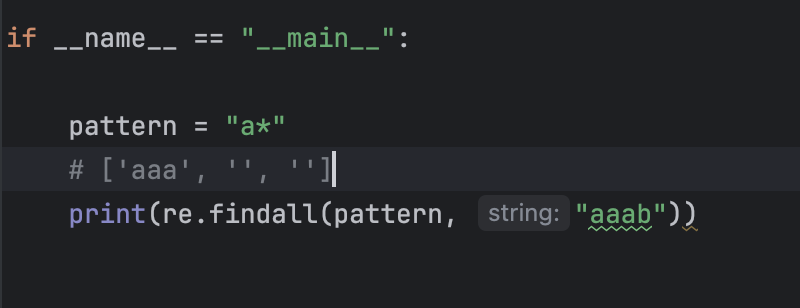
結果分析:
-
a*表示:匹配 零個或多個連續的a -
可以匹配空字符串(零個
a)
| 起始位置(index) | 當前字符 | a* 匹配結果 | 說明 |
|---|---|---|---|
| 0 | 'a' | 'aaa' | 從開頭連續匹配了 3 個 'a',停在 index=3(字符 'b' 之前) |
| 3 | 'b' | '' | 'b' 不是 'a',匹配 0 個 'a'(空字符串) |
| 4 | 結束 | '' | 到了字符串末尾,匹配 0 個 'a'(空字符串) |
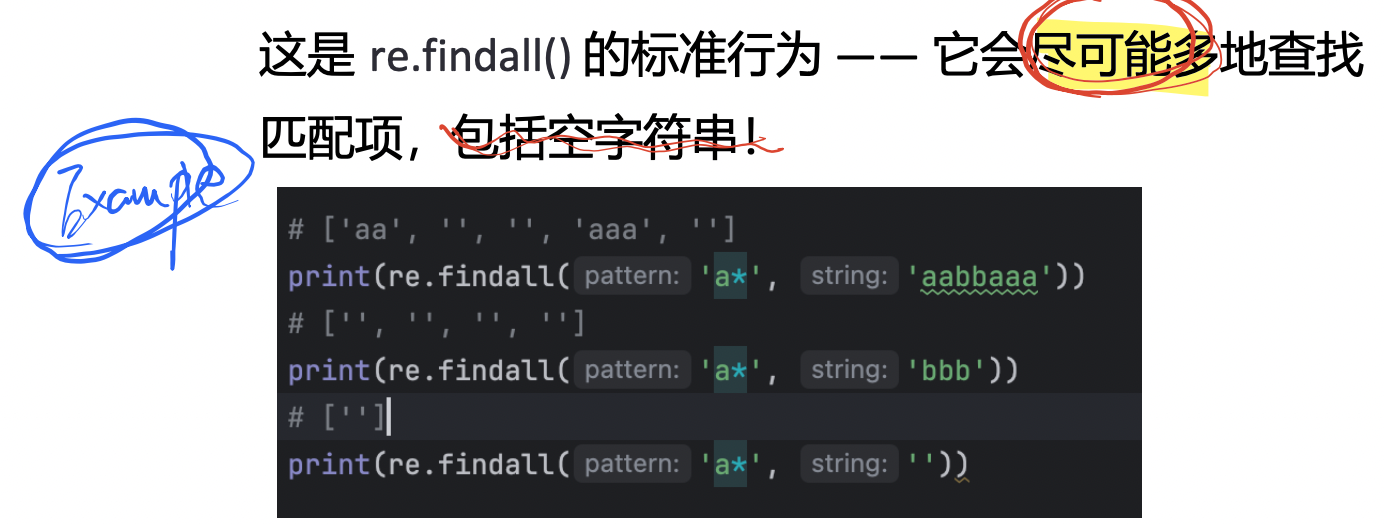
如果不想要空匹配,可以改成 a+(至少一個 a):
import re
pattern = "a+"
print(re.findall(pattern, "aaab")) # ['aaa']【注意】:
.*表示“匹配任意數量的任意字符(除了換行)
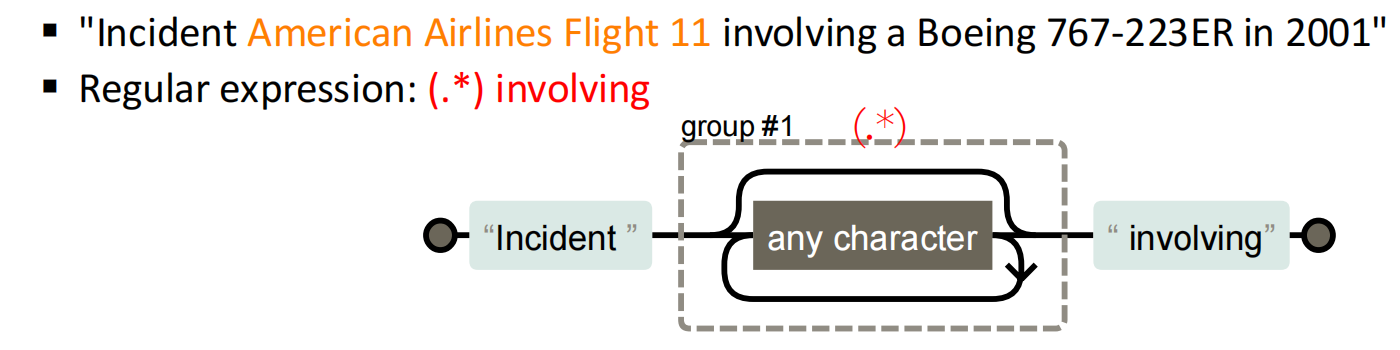
2、?(問號)
匹配前?個字符出現1次或者0次,即要么有1次,要么沒有。
示例:

【小結】:+、*、?

3、{m, n}
匹配前?個字符出現從m到n次。
m必須要有,但是可以是0;
n是可選的,若省略n,則{m, }匹配m到無限次。
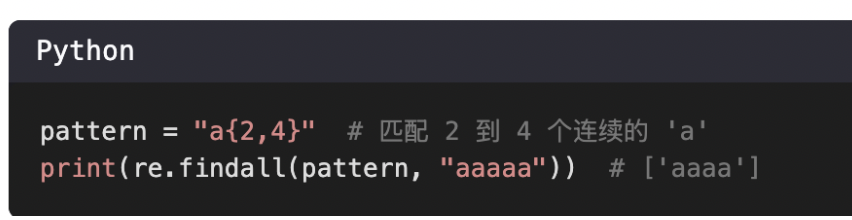
{m, n}是貪婪匹配,盡可能多的匹配。
3-3、貪婪匹配和?貪婪匹配
Python?數量詞默認是貪婪的(在少數語??也可能是默認?貪婪),總是嘗試匹配盡可能多的字符;?貪婪則相反,總是嘗試匹配盡可能少的字符。
| 貪婪量詞 | 非貪婪量詞 | 含義 |
|---|---|---|
* | *? | 0 次或多次 |
+ | +? | 1 次或多次 |
? | ?? | 0 次或 1 次 |
{m,n} | {m,n}? | m 到 n 次 |
記住規律:只要在量詞后面加 ?,就變成非貪婪(懶惰)模式。

示例:

3-4、匹配開頭結尾
| 字符 | 功能 |
| ^ | 匹配字符串開頭 |
| $ | 匹配字符串結尾 |
在 Python 正則里,匹配開頭和結尾主要用兩個錨點(Anchor):
1. ^ —— 匹配開頭
-
匹配字符串的開始位置
-
如果開啟了
re.MULTILINE,還會匹配每一行的開頭
例子:
import res = "hello\nworld"print(re.findall(r"^h", s))
# ['h'] → 只匹配整個字符串的開頭print(re.findall(r"^w", s, re.MULTILINE))
# ['w'] → 匹配第二行的開頭,因為 MULTILINE 模式
【注意】:

2. $ —— 匹配結尾
-
匹配字符串的結束位置
-
如果開啟了
re.MULTILINE,還會匹配每一行的結尾
例子:
print(re.findall(r"d$", s))
# ['d'] → 只匹配整個字符串的結尾print(re.findall(r"o$", s, re.MULTILINE))
# ['o'] → 匹配第一行的結尾
3. 常用組合
| 模式 | 含義 | 示例 |
|---|---|---|
^abc | 以 "abc" 開頭 | "abc123" ?, "1abc" ? |
abc$ | 以 "abc" 結尾 | "123abc" ?, "abc1" ? |
^$ | 匹配空字符串或空行 | 在 MULTILINE 模式下可匹配空行 |
4、綜合應用:使用^...$實現完全匹配

四、替換函數
re.sub()和re.subn(),它們都是 Python 正則模塊re里用來做替換的函數。
4-1、re.sub()函數
語法:
re.sub(pattern, repl, string, count=0, flags=0)
將string中所有匹配pattern的部分用repl替換掉。
-
pattern:正則表達式 -
repl:替換的內容(字符串,或函數) -
string:原文本 -
count:替換次數,默認0表示替換所有 -
flags:正則匹配模式(re.IGNORECASE等)
示例:

4-2、re.subn()函數
語法:
re.subn(pattern, repl, string, count=0, flags=0)和
sub一樣,也是替換,但它多返回一個替換次數。
返回值:一個 元組 (new_string, number_of_subs)
-
new_string:替換后的字符串 -
number_of_subs:實際替換的次數。
五、好用的正則函數可視化的方法
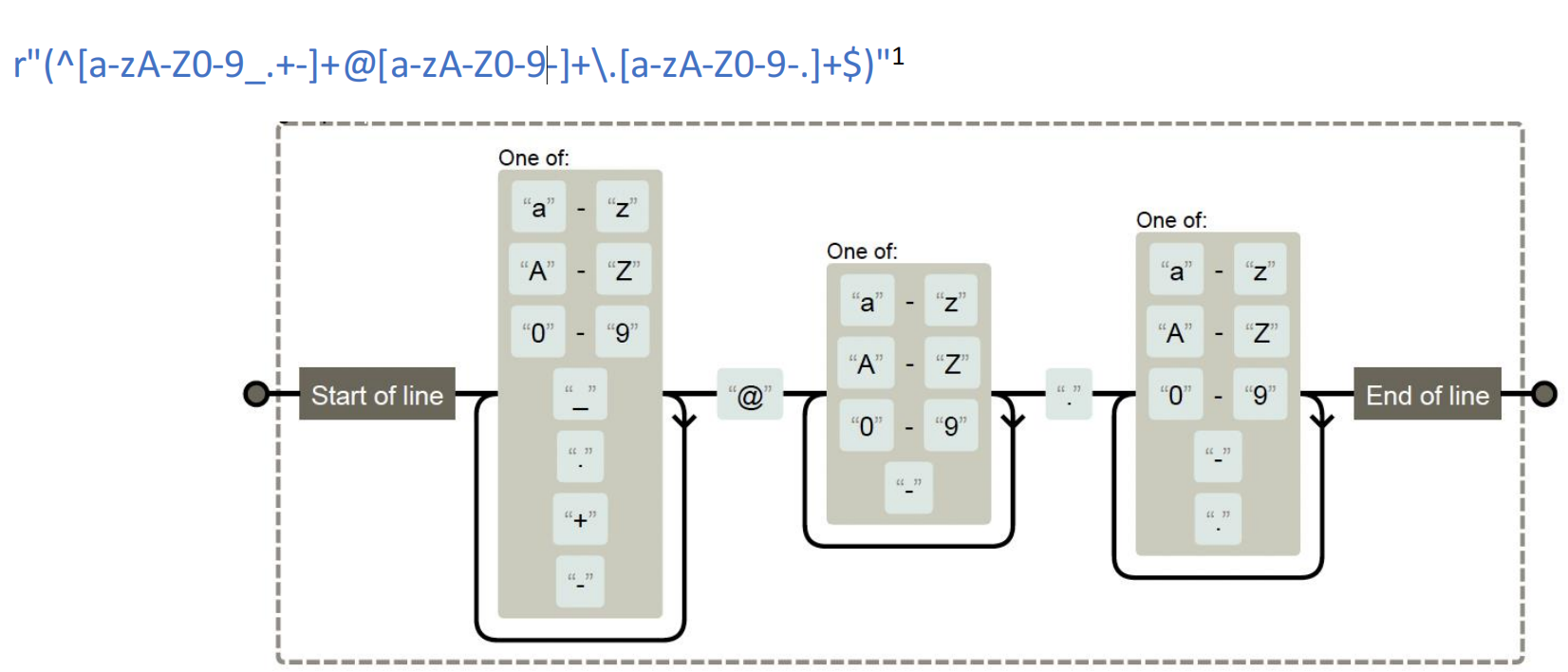
推薦使用檢驗網站:https://regexper.com/
【分析】:
這個正則是一個 郵箱地址的匹配模式:
(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$)
1. 外層括號 ( … )
-
把整個郵箱模式放進一個捕獲分組里(其實這里不分組也可以,只是會讓
group(1)直接得到整個郵箱地址)。
2. ^
-
錨點:匹配字符串的開頭位置。
-
這樣保證郵箱必須從開頭就符合這個模式,而不是出現在中間。
3. [a-zA-Z0-9_.+-]+
-
字符集:匹配郵箱用戶名(@ 前面)的合法字符。
-
a-z→ 小寫字母 -
A-Z→ 大寫字母 -
0-9→ 數字 -
_ . + -→ 下劃線、點、加號、減號
-
-
+→ 匹配 1 次或多次(不能為空)。
4. @
-
字面量
@符號,分隔用戶名和域名。
5. [a-zA-Z0-9-]+
-
匹配域名第一部分(@ 后、
.前)-
允許字母、數字和
- -
+→ 至少一個字符。
-
6. \.
-
\.匹配一個 字面量點.(因為普通的.在正則里是“任意字符”,要用反斜杠轉義才能表示“點”)。
7. [a-zA-Z0-9-.]+
-
匹配域名后綴部分,比如:
-
com -
co.uk -
xn--fiqs8s(國際化域名 punycode)
-
-
包含:
-
字母
a-zA-Z -
數字
0-9 -
點
. -
減號
-
-
-
+→ 至少一個字符。
8. $
-
錨點:匹配字符串的結尾位置。
-
確保整個字符串正好是郵箱,而不是包含郵箱的長文本。
9. 總結匹配規則
這個正則匹配的郵箱格式類似:
用戶名@域名.后綴
示例匹配成功:
test.email+alex@leetcode.com
user_name@my-domain.co.uk
示例匹配失敗:
test@.com # 域名第一部分為空
test@domain # 缺少點和后綴
六、分組(...)
1. 分組是什么
( ... ) 就像數學里的括號,把里面的正則看作一個整體。
-
它不會像字符集
[ ... ]那樣只是“列出單個可選字符”,而是把一個完整的子模式包起來。 -
這樣你可以:
-
整體重復(數量詞作用在整個括號上)
-
整體作為一個單位處理
-
捕獲里面的內容(匹配結果可以取出來)
-
2. 整體重復的例子
假設你想匹配:
ab abab ababab
不能直接用 ab+,因為 + 只會讓 b 重復,而不是 ab 整體重復。
你需要:
(ab)+
解釋:
-
(ab)→ 把a和b作為一個整體 -
+→ 重復這個整體一次或多次
匹配效果:
(ab)+ → "ab", "abab", "ababab"
3. 捕獲分組
分組會把匹配到的內容存起來,方便后續使用。
例子:
import re
m = re.match(r"(ab)+(\d+)", "abab123")
print(m.group(1)) # ab
print(m.group(2)) # 123
說明:
-
第一個
(ab)+里的ab是捕獲組 1 -
第二個
(\d+)是捕獲組 2 -
你可以用
.group(n)取出對應的匹配內容
4. 不能放進字符集 [ ... ]
方括號 [ ... ] 是“字符集合”,它只能寫單個字符或字符范圍,不能在里面放一個完整的分組:
[ (ab) ] ? 會被當作匹配字符 '('、'a'、'b'、')'
(ab) ? 這是分組,能當一個整體用
5. 小總結
| 功能 | 舉例 | 說明 |
|---|---|---|
| 作為整體 | (ab)+ | + 作用在整個 ab 上 |
| 捕獲內容 | (ab)(\d+) | 可以用 .group(1)、.group(2) 取出 |
| 提高可讀性 | `(?:abc | def)` |
| 不能在字符集里 | [()] | 只能匹配 ( 或 ) 這樣的單個字符 |
七、Alternation(交替匹配)|
1. 基本概念
-
|在正則中是**“或”**運算符(OR)。 -
A|B會匹配 A 或 B 任意一個能匹配成功的模式。
例子:
apple|orange
匹配 "apple" 或 "orange"。
2. 匹配順序(優先級)
-
從左到右匹配,第一個能匹配的就用它,不會去嘗試右邊的。
-
這叫左側優先(leftmost precedence)。
例子:
cat|cater
匹配 "cat" 時就會停,不會去匹配 "cater",因為 "cat" 在左邊先匹配成功了。
3. 多個模式可連續連接
-
你可以把很多模式用
|串起來,比如:
dog|cat|bird
匹配 "dog"、"cat" 或 "bird"。
4. 用括號分組以避免歧義
-
如果直接寫:
apple|orange juice
它匹配的是 "apple" 或 "orange juice",并不會匹配 "apple juice"。

-
如果你想讓
"juice"在兩種水果后面都適用,需要用分組:
(apple|orange) juice
匹配 "apple juice" 和 "orange juice"。
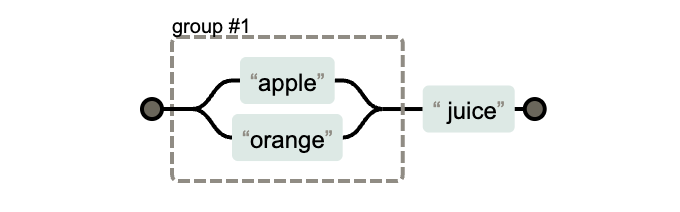
【注意】:
|左右是整個模式,所以哪怕有空格,它也會把空格算進匹配里。
5. 例子解析
-
apple|orange→"apple"或"orange" -
(apple|orange) juice→"apple juice"或"orange juice" -
w(ei|ie)rd→"weird"或"wierd"(括號內是兩個可選的字母組合)
要點總結
| 寫法 | 含義 | 注意事項 |
|---|---|---|
A|B | 邏輯 OR(交替),findall 不會單獨返回捕獲值 | 左側優先 |
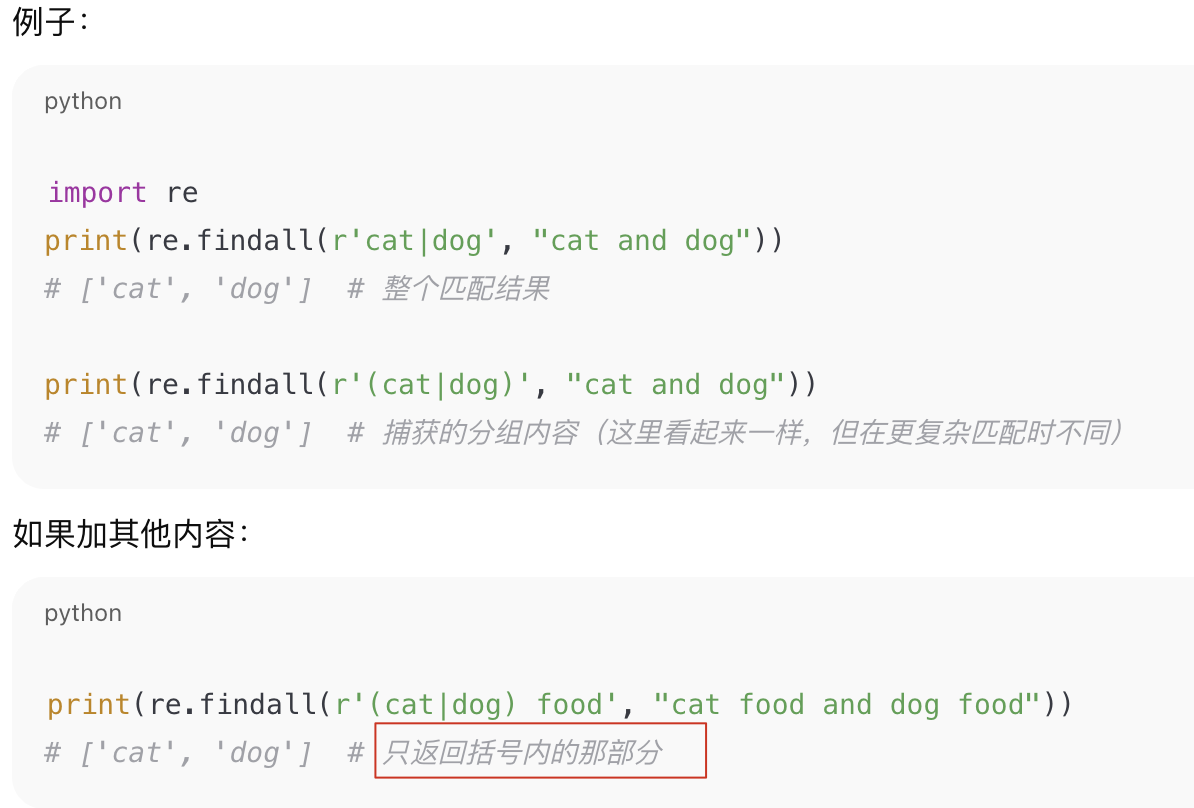
(A|B) | 分組交替,捕獲分組,findall 會返回匹配的那一部分 | 括號能避免歧義 |
A|B|C | 多個交替 | 可以無限串聯 |
八、re.compile 函數
在 Python 的?re?模塊中,re.compile()?函數用于將正則表達式模式編譯為一個正則表達式對象(RegexObject),以便后續重復使用。
這種編譯操作可以提高正則表達式的匹配效率,尤其適合需要多次使用同一模式的場景。
1、基本語法
re.compile(pattern, flags=0)
pattern:必填,字符串類型的正則表達式模式。flags:可選,用于修改正則表達式行為的標志(如忽略大小寫、多行模式等)。
主要作用
-
提高效率:
當同一個個正則表達式需要被多次使用時(例如在循環中匹配),提前用?re.compile()?編譯可以避免重復解析模式,從而提升性能。 -
復用正則對象:
編譯后返回的正則對象可以直接調用?match()、search()、findall()?等方法,語法更簡潔。
2、使用示例
示例 1:基礎用法
import re# 編譯正則表達式(匹配郵箱格式)
pattern = re.compile(r'\w+@\w+\.\w+')# 使用編譯后的對象進行匹配
text1 = "我的郵箱是test@example.com"
text2 = "聯系我:abc123@gmail.com"# 查找匹配項
print(pattern.findall(text1)) # 輸出:['test@example.com']
print(pattern.findall(text2)) # 輸出:['abc123@gmail.com']
示例 2:使用標志(flags)
常用標志包括:
re.IGNORECASE(re.I):忽略大小寫匹配。re.MULTILINE(re.M):多行模式,使?^?和?$?匹配每行的開頭和結尾。
import re# 忽略大小寫匹配 "hello"
pattern = re.compile(r'hello', re.IGNORECASE)print(pattern.findall("Hello World")) # 輸出:['Hello']
print(pattern.findall("HELLO Python")) # 輸出:['HELLO']
與直接使用函數的區別
不編譯模式時,也可以直接使用?re.findall(pattern, text)?等函數,但本質上這些函數內部會隱式編譯模式。因此:
- 單次使用:兩種方式效率差異不大。
- 多次使用:
re.compile()?編譯后復用的方式更高效。
總結
????re.compile()?是優化正則表達式性能的重要工具,尤其適合在循環或批量處理中重復使用同一模式的場景。編譯后的正則對象提供了與?re?模塊函數對應的方法(如?match()、search()),使用起來更加靈活。
好的,我們來翻譯并講解這一段 “The Backslash Plague” 的意思。
九、反斜杠災難(The Backslash Plague)
-
反斜杠
\用來表示特殊形式(special forms),或者讓特殊字符失去它原本的特殊含義(轉義)。 -
因此,如果要在正則表達式中匹配一個真正的反斜杠,你必須寫成
'\\\\'作為正則表達式字符串。 -
那么,我們能不能簡化這種寫法呢?
這個“災難”是因為反斜杠在 Python 字符串 和 正則表達式 里都被當作轉義符號:
-
Python 字符串解析階段
-
在普通字符串
"\\n"中,\\會被 Python 解析成一個反斜杠字符\,而\n則會被解析成換行符。 -
所以如果你想在字符串里寫一個“正則表達式里的反斜杠”,就得先把它在 Python 里轉義成
\\。
-
-
正則表達式解析階段
-
在正則里,反斜杠本身也有特殊含義,比如
\d是數字、\w是單詞字符。 -
如果你想匹配反斜杠本身,還得在正則層面再轉義一次,所以是
\\(正則層面)。
-
-
疊加效果
-
在 Python 普通字符串里寫正則匹配反斜杠,要寫成:
"\\\\"-
前兩層
\\→ Python 轉義成\ -
后兩層
\\→ 正則轉義成 “匹配一個反斜杠”
-
-
9-1、如何簡化?
用 原始字符串
r"..."
pattern = r"\\"
這樣:
-
Python 不會解析
\,直接把\\交給正則引擎 -
只需要一層
\\表示“匹配一個反斜杠”
對比表
| 想匹配內容 | 普通字符串寫法 | 原始字符串寫法 |
|---|---|---|
一個反斜杠 \ | "\\\\" | r"\\" |
數字字符 \d | "\\d" | r"\d" |
點號 . | "\\." | r"\." |
十、捕獲組(...)
用(...)括起來,希望匹配結果中提取出特定的部分。
10-1、不捕獲組 VS 分組
所有的捕獲組都是分組,但并不是所有的分組都是捕獲組。
1. 分組(Grouping)
括號 () 在正則里的第一個作用就是把多個模式當作一個整體,方便:
-
改變運算優先級
-
給整個模式應用數量詞(
*,+,{m,n}等)
例子:
import re
print(re.findall(r'(ab)+', "abababx")) # ['ab']
這里 (ab)+ 表示“ab 這個整體重復一次或多次”。
2. 捕獲組(Capturing Group)
括號的第二個作用是捕獲匹配到的內容,以便之后使用:
-
通過
re.findall()返回分組內容 -
在
re.search()里用.group(n)獲取 -
在
re.sub()中通過\1,\2引用
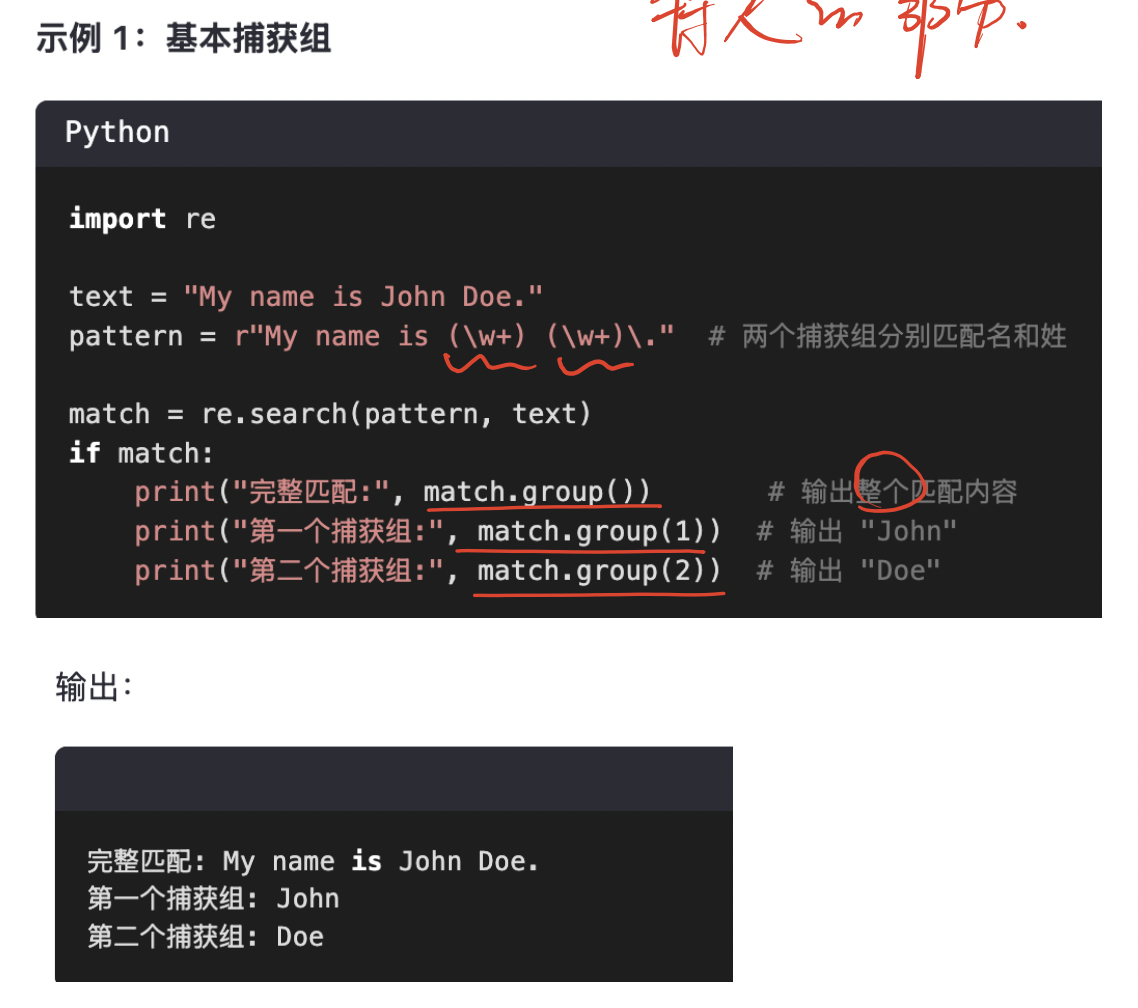
例子:
示例字符串
text = "John Smith, Alice Brown"
目標:匹配 "名字 姓氏" 的模式,并把名字和姓氏分別作為分組。
1?? 通過 re.findall() 返回分組內容
findall() 如果正則里有捕獲組,會只返回組的內容(如果有多個組,就返回元組)。
import repattern = r"(\w+)\s+(\w+)" # 第1組=名字, 第2組=姓氏
matches = re.findall(pattern, text)
print(matches)
輸出:
[('John', 'Smith'), ('Alice', 'Brown')]
每個元組
(group1, group2)對應一次匹配的兩個分組內容。
2?? 在 re.search() 里用 .group(n) 獲取
search() 只找第一個匹配,.group(0) 是整個匹配,.group(1) 是第1組,依此類推。
m = re.search(pattern, text)
print(m.group(0)) # 整個匹配:John Smith
print(m.group(1)) # 第1組:John
print(m.group(2)) # 第2組:Smith
輸出:
John Smith
John
Smith
3?? 在 re.sub() 中通過 \1, \2 引用
sub() 的替換字符串里,可以用 \1, \2 引用捕獲組的內容。
result = re.sub(pattern, r"\2, \1", text)
print(result)
輸出:
Smith, John, Brown, Alice
這里
\2是姓氏,\1是名字,所以替換成了 “姓, 名” 的形式。
總結表格
| 用法 | 獲取方式 | 返回值特點 |
|---|---|---|
findall() | 返回列表 | 有分組時返回元組列表 |
search().group(n) | 數字 n | 只獲取第一個匹配,0 是全部 |
sub() 替換字符串 \n | 反斜杠加組號 | 在替換時插入對應組內容 |
10-2. 非捕獲組(Non-Capturing Group)
如果只想分組但不想捕獲,可以用 (?:...)。這樣括號只負責邏輯分組,不會把內容保存到組里:
import re
print(re.findall(r"(?:ab)+", "abababx")) # ['ababab']
不會產生 .group(1) 等捕獲內容。
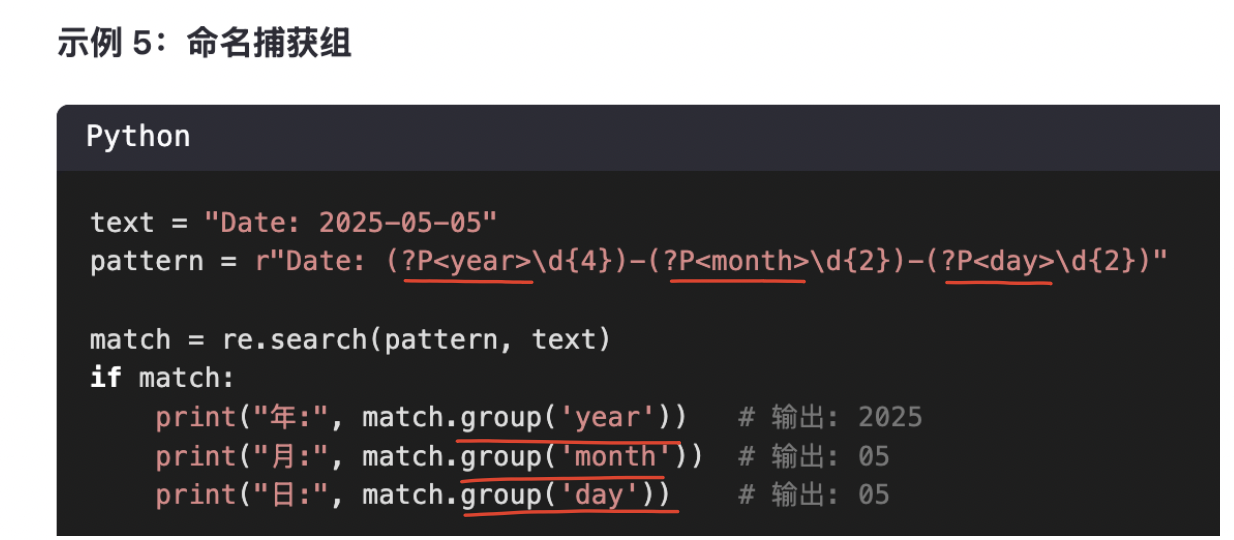
10-3、命名捕獲組(?P<name>)
使用(?P<name>)給捕獲組命名,然后在re.search()中,通過.group('name')引用
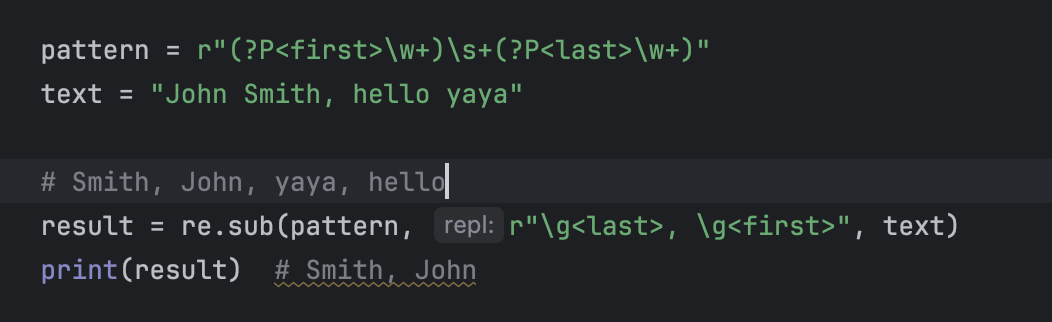
在re.sub()替換字符串里,可以用 \g<name> 來引用命名組(比數字引用更直觀)。
總結
| 寫法 | 是否分組 | 是否捕獲 | 常用用途 |
|---|---|---|---|
( ... ) | ? | ? | 捕獲內容、數量詞作用范圍 |
(?: ... ) | ? | ? | 僅用于邏輯分組 |
(?P<name>...) | ? | ?(命名) | 捕獲并用名字引用 |





部署)













跳過登錄微軟賬戶,創建本地賬戶)