現在人工智能飛速發展時代,LLM絕對可以算是人工智能領域得一顆明珠,也是現在許多AI項目落地得必不可少得一個模塊,可以說,不管你之前得研究領域是AI得哪個方向,現在都需要會一些LLM基礎,在這個系列,文章會從最基礎的數據處理開始,一步步構建屬于我們自己的GPT2模型,如果之前沒有了解過LLM,強烈推薦Build a Large Language Model (From Scratch)這本書,本文也是對這本書學習總結,代碼圖片都出自隨書教學視頻。
- github地址:https://github.com/rasbt/LLMs-from-scratch
項目概覽
本項目將分為三個核心階段,每個階段都有其獨特的挑戰和技術要點:
🔧 Stage 1: 數據處理與模型架構構建
在這個階段,我們將深入探討:
- 數據預處理與采樣管道:如何高效處理海量文本數據
- 注意力機制的實現:Transformer架構的核心組件
- LLM架構設計:從零搭建完整的語言模型框架
🚀Stage 2: 大模型預訓練
預訓練是整個項目的核心,包含:
- 訓練循環設計:如何穩定訓練大規模模型
- 模型評估策略:設計損失函數,實時監控訓練效果
- 權重管理:預訓練模型的保存與openAI預訓練GPT2權重加載
🎯 Stage 3: 模型微調與應用
最終階段將專注于實際應用:
- 分類任務微調:針對特定任務優化模型性能
- 指令數據集有監督微調(SFT):讓模型更好地理解人類指令
下載文本數據集
以一個簡單的txt文本為例,接下來將進行word embedding,同時之后也會利用這個文本訓練自己的LLM,
import os
import urllib.request
if not os.path.exists("the-verdict.txt"):url = ("https://raw.githubusercontent.com/rasbt/""LLMs-from-scratch/main/ch02/01_main-chapter-code/""the-verdict.txt")file_path = "the-verdict.txt"urllib.request.urlretrieve(url, file_path)
分詞器
拿到一個text文本,先對其進行劃分。這一過程就叫Tokenized,先得到Tokenized text,對劃分的每一個塊(Token),進行數字編碼得到Token IDs,對于Tokenized其實簡單來說就是來做文本劃分,弄清楚這個就可以實現一個最簡單的分詞器
import re
text = "Hello, world. This, is a test."result = re.split(r'(\s)', text)
print(result)
得到結果:[‘Hello,’, ’ ', ‘world.’, ’ ', ‘This,’, ’ ', ‘is’, ’ ', ‘a’, ’ ', ‘test.’]
目前主流LLM的分詞器無非是在這個的基礎上做一些改進優化,比如說增加根據逗號句號等標點符號分詞
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)
結果:[‘Hello’, ‘,’, ‘world’, ‘.’, ‘Is’, ‘this’, ‘–’, ‘a’, ‘test’, ‘?’]
將文本分塊之后就是將由token得到token IDs,把所有token放入集合中,利用集合的唯一性去重,就可以得到每一個不同的token的ids
all_words = sorted(set(preprocessed))
vocab_size = len(all_words)
print(vocab_size)
vocab = {token:integer for integer,token in enumerate(all_words)}
for i, item in enumerate(vocab.items()):print(item)if i >= 50:break
相應的,根據唯一的ids也可以將token ids解碼成對應的token,總之token ids與token是一一對應的關系,由此就可以得到一個最簡單的分詞器SimpleTokenizerV1
class SimpleTokenizerV1:
def __init__(self, vocab):self.str_to_int = vocabself.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)preprocessed = [item.strip() for item in preprocessed if item.strip()]ids = [self.str_to_int[s] for s in preprocessed]return ids
def decode(self, ids):text = " ".join([self.int_to_str[i] for i in ids])# Replace spaces before the specified punctuationstext = re.sub(r'\s+([,.?!"()\'])', r'\1', text)return text
可以使用分詞器將文本編碼(即分詞)為整數ids,這些ids隨后可以被向量嵌入作為大型語言模型(LLM)的輸入
tokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know," Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)
tokenizer.decode(tokenizer.encode(text))
這一個簡便的分詞器有一個最明顯的缺點,LLM在得到輸入時不可能每個token都在訓練集里面出現過,遇到沒有出現在訓練集里的token ids就會報錯
tokenizer = SimpleTokenizerV1(vocab)
text = "Hello, do you like tea. Is this-- a test?"
tokenizer.encode(text)
如這個hallo就沒在txt文本中出現過,運行代碼就會報錯,因此需要改進,我們可以增加特殊標記,如“<|unk|>”來表示未知單詞。“<|endoftext|>”表示文本的結束,這對于訓練集包含不同本文txt時這個標記是非常有必要的
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token:integer for integer,token in enumerate(all_tokens)}
len(vocab.items())
for i, item in enumerate(list(vocab.items())[-5:]):print(item)
由此得到改進后的分詞器:
class SimpleTokenizerV2:
def __init__(self, vocab):self.str_to_int = vocabself.int_to_str = { i:s for s,i in vocab.items()}
def encode(self, text):preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)preprocessed = [item.strip() for item in preprocessed if item.strip()]preprocessed = [item if item in self.str_to_int else "<|unk|>" for item in preprocessed]ids = [self.str_to_int[s] for s in preprocessed]return ids
def decode(self, ids):text = " ".join([self.int_to_str[i] for i in ids])# Replace spaces before the specified punctuationstext = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)return text
tokenizer = SimpleTokenizerV2(vocab)
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))print(text)
當然這個版本離實際GPT2使用的分詞器還有些差距,比如說面對未知詞時,并不是直接都將其歸為“<|unk|>,
例如,如果 GPT-2 的詞匯表中沒有“unfamiliarword”這個詞,它可能會將其分詞為 [“unfam”, “iliar”, “word”] 或其他子詞分解,具體取決于其訓練的 BPE 合并規則。這里推薦一個在線網頁可以體驗不同LLM的分詞策略
https://tiktokenizer.vercel.app/?model=Qwen%2FQwen2.5-72B
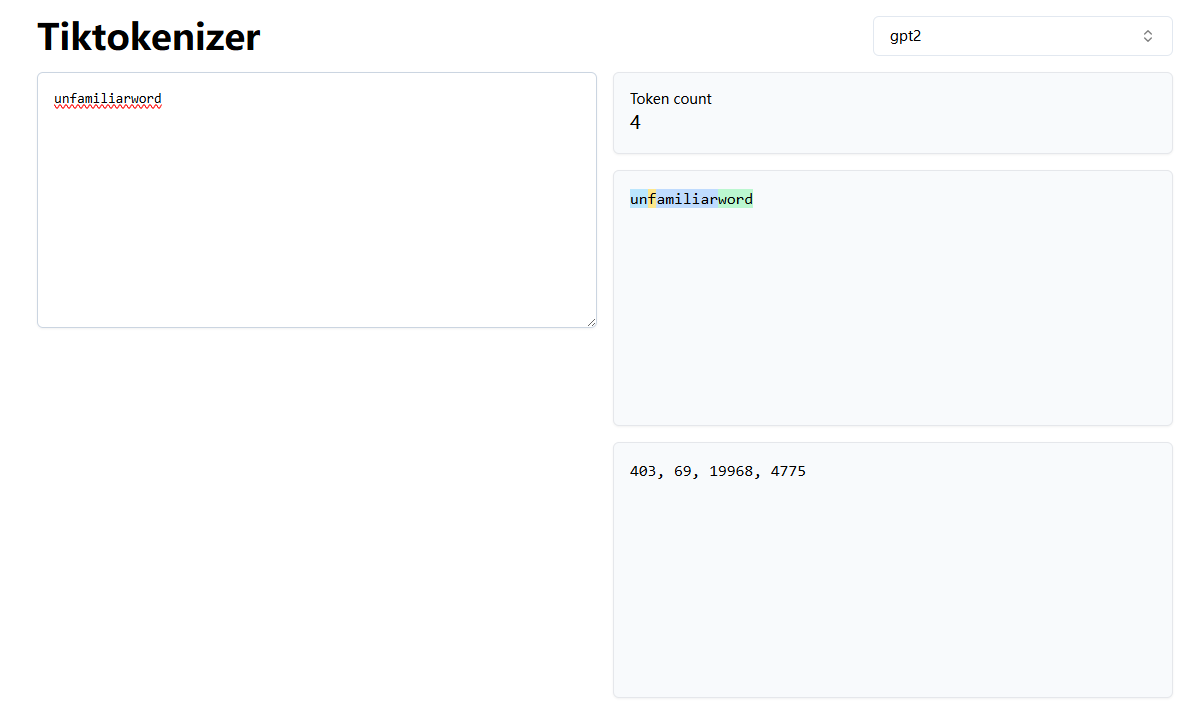
接下來我們使用來自 OpenAI 的開源 tiktoken 庫的 BPE 分詞器,該庫使用 Rust 實現了其核心算法以提高計算性能。
import importlib
import tiktoken
print("tiktoken version:", importlib.metadata.version("tiktoken"))
tokenizer = tiktoken.get_encoding("gpt2")
text = ("Hello, do you like tea? <|endoftext|> In the sunlit terraces""of someunknownPlace.")integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})print(integers)
strings = tokenizer.decode(integers)
print(strings)
數據采樣
有了分詞器我們就可以對txt文本數據進行采樣了
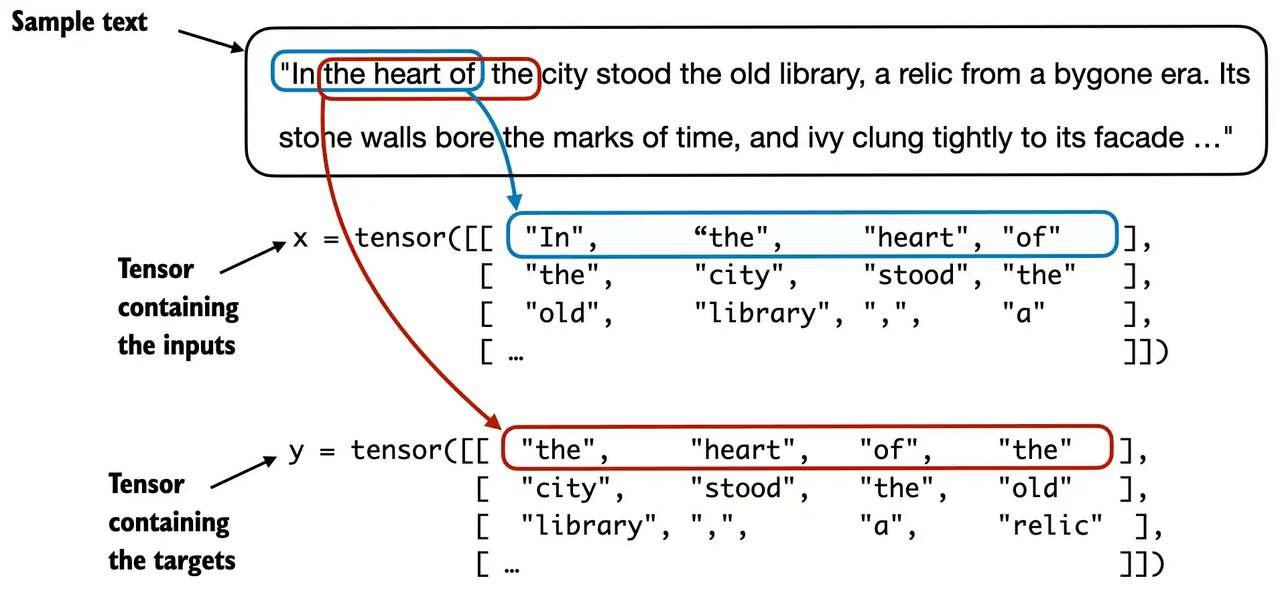
LLM的input和target是什么呢,其實從LLM的工作流程就可以看出一些,LLM都是根據現有文本預測下一個token,

所以LLM是通過滑動窗口對數據進行采樣,一段在訓練文本中連續的token作為輸入,那么他的target就是滑動一定窗口后得到的相同長度的token序列,所以LLM依舊屬于有監督學習的范疇,值得注意的是這里為了便于理解只滑動了一個token,但是實際LLM訓練是有step可以指定的,很少有設為1的,由此就可以實現一個簡單的文本數據加載函數
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):def __init__(self, txt, tokenizer, max_length, stride):self.input_ids = []self.target_ids = []token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})assert len(token_ids) > max_length, "Number of tokenized inputs must at least be equal to max_length+1" for i in range(0, len(token_ids) - max_length, stride):input_chunk = token_ids[i:i + max_length]target_chunk = token_ids[i + 1: i + max_length + 1]self.input_ids.append(torch.tensor(input_chunk))self.target_ids.append(torch.tensor(target_chunk))def __len__(self):return len(self.input_ids)def __getitem__(self, idx):return self.input_ids[idx], self.target_ids[idx]
def create_dataloader_v1(txt, batch_size=4, max_length=256, stride=128, shuffle=True, drop_last=True, num_workers=0):# Initialize the tokenizertokenizer = tiktoken.get_encoding("gpt2")# Create datasetdataset = GPTDatasetV1(txt, tokenizer, max_length, stride)# Create dataloaderdataloader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers)return dataloader
有了這個dataloader,就可以得到任意batch size的token id序列,
dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4, shuffle=False)data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Inputs:\n", inputs)
print("\nTargets:\n", targets)
向量嵌入
然而,輸入大型語言模型(LLM)的并不是直接的 token IDs,而是需要通過嵌入層(token embeddings,也稱為詞嵌入)將其轉換為連續的向量表示。這些向量作為嵌入層的權重,在模型訓練過程中會通過梯度下降不斷更新,以優化對下一個 token 的預測能力。值得一提的是,雖然每個 token ID 對應的嵌入向量值在訓練中會發生變化,但其在嵌入矩陣中的行索引(即與 token ID 的固定對應關系)始終保持不變。這種穩定的映射關系確保了模型在編碼和解碼過程中的一致性。

嵌入層方法本質上是一種更高效的實現方式,等價于先進行 one-hot 編碼,然后通過全連接層進行矩陣乘法,由于嵌入層只是獨熱編碼加矩陣乘法的一種更高效的實現方式,因此它可以被視為一個神經網絡層,并且可以通過反向傳播進行優化。
input_ids = torch.tensor([2, 3, 5, 1])
vocab_size = 6
output_dim = 3torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
print(embedding_layer.weight)
位置編碼:
只對不同token進行詞嵌入對于LLM來說是不夠的,因為Transformer本身是不具備處理序列順利的能力的,而同一個單詞位于一句話的不同位置是可以表達出不同的意思的。
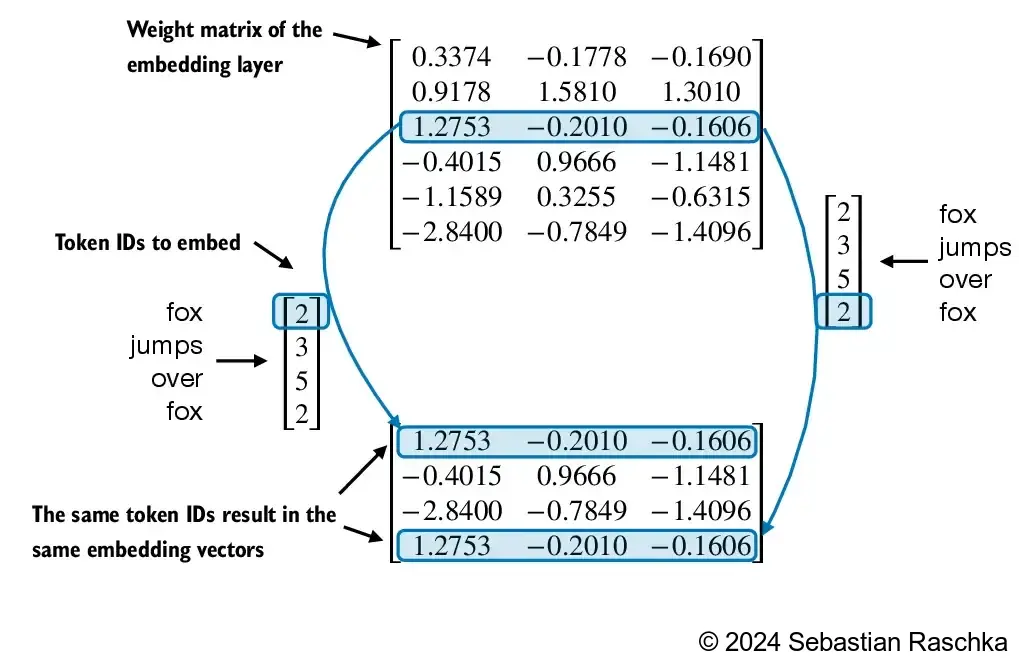
所以要引入token的位置編碼,為txt文本的每一個token引入一個位置編碼,這里我們用的是絕對位置編碼,也是個gpt2所使用的,絕對位置嵌入是指為輸入序列中每個位置分配一個固定編號(0, 1, 2, …),并為每個編號對應地創建一個向量。這些向量表示每個 token 在序列中的具體位置,與 token 本身無關。所以位置編碼的行數就是整個文本的長度
vocab_size = 50257
output_dim = 256 token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
max_length = 4
dataloader = create_dataloader_v1( raw_text, batch_size=8, max_length=max_length, stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Token IDs:\n", inputs)
print("\nInputs shape:\n", inputs.shape)
token_embeddings = token_embedding_layer(inputs)
print(token_embeddings.shape)
context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
pos_embeddings = pos_embedding_layer(torch.arange(max_length))
print(pos_embeddings.shape)
為了創建在大語言模型(LLM)中使用的輸入嵌入,我們只需將詞元嵌入和位置嵌入相加。
input_embeddings = token_embeddings + pos_embeddings
print(input_embeddings.shape)

總結
上圖總結了一個完整的文本數據的處理過程:
文本經過分詞器劃分為token,得到token id后經行向量嵌入,這一步可以模型得以進行loss的反向傳播,每一個詞向量還需要加上與之對應的位置編碼,這是為了提升LLM的順序序列處理能力,得到的input embedings就可以輸入
LLM進行訓練了,關于位置編碼,目前的改進很多,絕對位置編碼的應用少了很多,比如千文3使用的RoPE(Rotary Position Embedding),也是目前大語言模型中常用的一種位置編碼方式
和相對位置編碼相比,RoPE 具有更好的外推性,目前是大模型相對位置編碼中應用最廣的方式之一:
其原理用直觀的話來說就是將位置編碼看作一個二維旋轉角度,讓QK的點乘運算本身隱含順序差異
因為旋轉可以表示相對位置,所以天然支持相對位置感知
備注:什么是大模型外推性?
外推性是指大模型在訓練時和預測時的輸入長度不一致,導致模型的泛化能力下降的問題。例如,如果一個模型在訓練時一個batch只使用了512個 token
的文本,那么在預測時如果輸入超過512個 token,模型可能無法正確處理。這就限制了大模型在處理長文本或多輪對話等任務時的效果。
詳細可以參考博客:https://www.zhihu.com/tardis/bd/art/647109286





)

題解)



)

)





