文章目錄
- 前言
- 一、簡介
- struct folio
- 二、page folios的好處
- 2.1 compound page
- 2.2 page cache
- 三、buffer_head、iomap與page folios
- 四、何時分配 Large Folio
- 五、folio結構體演變
- 六、內核主線folio的逐步使用
- 參考資料
前言
Linux 內核的內存管理子系統以“頁”(page)為單位處理內存,這是一個由硬件決定的基本單位(通常為 4KB)。然而,這些“基礎頁”很小,因此內核經常需要以更大的單位處理內存。為此,它將一組物理上連續的頁組合成“復合頁”(compound pages),由一個“頭頁”(head page,即復合頁中的第一個基礎頁)和若干“尾頁”(tail pages)組成。這就導致一個情況:當內核代碼接收到一個 struct page 指針時,通常無法知道它處理的是頭頁還是尾頁,除非顯式檢查。
對于page: 4KB頁的局限性
早期Linux內核在內存以兆字節(MB)計的系統上運行,使用4KB頁是合理的。
如今,系統內存已達數十甚至上百GB,但4KB頁大小基本未變。
后果:
內核需管理的頁面數量劇增。
花費更多內存存儲頁表項(page table entries)。
鏈表更長,掃描開銷更大。
缺頁中斷(page fault)次數顯著增加。
事實證明,這種“確保這是頭頁”的檢查在運行的內核中累積起來會帶來一定的開銷。struct page 的普遍使用也使得內核 API 不夠清晰——很難知道某個給定函數是否能處理尾頁。為了解決這個問題,內核開發人員 提出了“folio”(頁片段)的概念,它類似于 struct page,但已知不是尾頁。通過將內部函數改為使用 page folios。
在 Linux 5.16.0 內核版本發布中,引入了一種新的概念——page folios。page folios與復合頁類似,但具有更清晰、更合理的語義設計。通過在內核的一些核心部分使用頁片段,常見工作負載下的性能得到了提升。
本次發布包含了page folios的核心基礎設施,并已將內核內存管理子系統和頁緩存(page cache)的部分功能遷移到新機制上。未來的內核版本將進一步把一些文件系統改造為支持page folios,并引入支持多頁的page folios功能,從而進一步提升系統性能和可維護性。
folio 是由 struct folio 表示的;它本質上是一個 compound page 的 head page 的別名。
在 Linux 5.16.0 內核版本發布中,當前只有readahead代碼會進行大頁(large folio)的分配,而文件系統的寫路徑仍然以基礎頁(base page)為單位進行。如果要對通過 readahead 得到的 folio 進行寫入,會看到并使用這些 folio。不過,對文件的追加(append)將總是使用 base page。
一、簡介
內存管理通常以“頁”(page)為基本單位進行操作,每頁通常包含 4,096 字節(即 4KB),但也可能更大。然而,內核已經擴展了“頁”的概念,引入了“復合頁”(compound pages),即一組連續的普通頁。這種擴展使得“頁”這一概念的定義變得有些模糊。

為此,Linux內核引入一個名為 page folios的新概念,旨在重新厘清內存管理中的這一混亂局面。
在最底層,頁的概念是由硬件實現的。內存的跟蹤管理——例如判斷某塊內存是否存在于物理內存(RAM)中——都是以頁為粒度進行的。每種 CPU 架構可能支持有限的幾種頁大小,但必須選擇一個“基礎”頁大小,而最普遍的選擇仍是 4,096 字節——這與 30 年前第一個 Linux 內核發布時所采用的大小完全相同。
然而,內核常常需要以更大的內存塊來操作。一個典型的例子是“大頁”(huge pages)的管理,這類功能由硬件直接支持。例如,x86 架構可以支持 2MB 的大頁,在合適場景下使用大頁能帶來顯著的性能優勢。
此外,內核還會在其他情況下分配多個連續的頁,通常用于 DMA 緩沖區或其他需要物理上連續內存的場景。這種將多個頁組合在一起的機制,在內核中被稱為“復合頁”(compound page)。雖然復合頁解決了大塊連續內存的管理問題,但其復雜的實現和模糊的接口也帶來了維護和使用上的困難,這正是“page folios”試圖改進的地方。
在 Linux 內核中,每一個被管理的基礎內存頁(base page)都在系統的內存映射(memory map)中對應一個 struct page 結構。當一組基礎頁被組合成一個“復合頁”(compound page)時,這組頁中的第一個頁(稱為“頭頁”或 head page)的 struct page 會被特別標記,以明確表示它是一個復合頁的起始頁。該頭頁結構中的元數據描述的是整個復合頁的信息。
其余的頁(稱為“尾頁”或 tail pages)也會被標記為尾頁,并且它們的 struct page 結構中包含一個指向對應頭頁結構的指針。多關于復合頁組織方式的細節,可以參考相關技術文章:Linux內存管理之 compound pages
這種機制使得從一個尾頁的結構快速定位到其所屬復合頁的頭頁變得非常容易。內核中的許多接口都利用了這一特性。然而,這也帶來了一個根本性的模糊問題:如果一個函數接收了一個指向尾頁 struct page 的指針,它到底應該對該尾頁本身進行操作,還是應該對整個復合頁進行操作?
函數接收 struct page 參數時,無法從類型區分其應操作 單個頁 還是 整個復合頁。*
正如 Matthew Wilcox 在 2020 年 12 月首次提出 page folio 系列補丁時所指出的:
一個接受 struct page 指針作為參數的函數,可能:
只接受頭頁或基礎頁,如果傳入尾頁就會觸發 BUG;
能處理任意類型的頁,但只操作 PAGE_SIZE(4KB)大小的數據;
如果傳入的是頭頁,則操作 page_size()(可能是 2MB 等復合頁大小)字節;但如果傳入的是基礎頁或尾頁,則只操作 PAGE_SIZE 字節;
無論傳入的是頭頁還是尾頁,都操作 page_size() 字節大小的數據。
而現實中,以上所有情況都存在。(其中 PAGE_SIZE 是基礎頁大小,而 page_size(page) 函數返回的是一個頁——可能是復合頁——的實際總大小。)
雖然目前尚未有大量已知的嚴重 bug 直接源于這一模糊的 API,但一個如此不清晰的接口設計,遲早可能導致問題。
為了解決這一混亂局面,Wilcox 提出了 page folio 的概念。所謂 page folio ,本質上就是一個保證不是尾頁的 struct page 結構。任何接受 page folio 作為參數的函數,都可以明確地對整個頁單元(即完整的復合頁或單個頁)進行操作,而不會產生歧義。隨著內核函數逐步遷移到使用 page folio 作為參數,其語義將變得更加清晰:這類函數不應對尾頁進行操作。
在 Wilcox 首次提交該補丁系列時,他還強調了另一個重要優勢:性能和代碼體積的優化。
任何可能接收到尾頁指針、但又需要操作整個復合頁的函數,通常必須先將尾頁指針轉換為頭頁指針,這通常通過調用如下函數實現:
struct page *compound_head(struct page *page);
這個函數本身開銷不大(通常是內聯函數),但在一次頁面操作中可能被頻繁調用多次。這不僅增加了內核代碼體積(因為是內聯展開),也累積了運行時開銷。
而如果函數直接接收的是 page folio,那么它天然知道傳入的不是尾頁,因此完全不需要調用 compound_head()。這直接省去了大量的指針轉換操作,從而節省了執行時間和內存占用。
page folio 的引入,不僅提升了內核內存管理接口的語義清晰度和安全性,還通過消除不必要的頭頁查找調用,帶來了實際的性能和代碼精簡收益,是 Linux 內核內存管理子系統邁向更健壯、高效架構的重要一步。
struct folio
Linux 5.16 內核 page folio 本身被定義為一個簡單的封裝結構,把一些page里面常用字段,提取到了和page同等位置的union里面:
// v5.16/source/include/linux/mm_types.h/*** struct folio - Represents a contiguous set of bytes.* @flags: Identical to the page flags.* @lru: Least Recently Used list; tracks how recently this folio was used.* @mapping: The file this page belongs to, or refers to the anon_vma for* anonymous memory.* @index: Offset within the file, in units of pages. For anonymous memory,* this is the index from the beginning of the mmap.* @private: Filesystem per-folio data (see folio_attach_private()).* Used for swp_entry_t if folio_test_swapcache().* @_mapcount: Do not access this member directly. Use folio_mapcount() to* find out how many times this folio is mapped by userspace.* @_refcount: Do not access this member directly. Use folio_ref_count()* to find how many references there are to this folio.* @memcg_data: Memory Control Group data.** A folio is a physically, virtually and logically contiguous set* of bytes. It is a power-of-two in size, and it is aligned to that* same power-of-two. It is at least as large as %PAGE_SIZE. If it is* in the page cache, it is at a file offset which is a multiple of that* power-of-two. It may be mapped into userspace at an address which is* at an arbitrary page offset, but its kernel virtual address is aligned* to its size.*/
struct folio {/* private: don't document the anon union */union {struct {/* public: */unsigned long flags;struct list_head lru;struct address_space *mapping;pgoff_t index;void *private;atomic_t _mapcount;atomic_t _refcount;
#ifdef CONFIG_MEMCGunsigned long memcg_data;
#endif/* private: the union with struct page is transitional */};struct page page;};
};
// v5.16/source/include/linux/mm_types.hstruct page {unsigned long flags; /* Atomic flags, some possibly* updated asynchronously *//** Five words (20/40 bytes) are available in this union.* WARNING: bit 0 of the first word is used for PageTail(). That* means the other users of this union MUST NOT use the bit to* avoid collision and false-positive PageTail().*/union {struct { /* Page cache and anonymous pages *//*** @lru: Pageout list, eg. active_list protected by* lruvec->lru_lock. Sometimes used as a generic list* by the page owner.*/struct list_head lru;/* See page-flags.h for PAGE_MAPPING_FLAGS */struct address_space *mapping;pgoff_t index; /* Our offset within mapping. *//*** @private: Mapping-private opaque data.* Usually used for buffer_heads if PagePrivate.* Used for swp_entry_t if PageSwapCache.* Indicates order in the buddy system if PageBuddy.*/unsigned long private;};......
在這個基礎之上,構建了一整套新的基礎設施。例如,get_folio() 和 put_folio() 函數將像 get_page() 和 put_page() 一樣管理對頁片段的引用計數,但無需再調用 compound_head() 來處理尾頁轉換問題。在此基礎上,還衍生出一系列更高層次的操作函數。
page folios帶來的問題:
(1)遷移成本比較大,將內核中各個子系統逐步遷移到這一新類型上,將觸及每一個文件系統,以及大量的設備驅動程序,將是一項巨大的工作。
(2)page 與 folio 類型將長期共存,代碼中到處都是兩者之間相互轉換的代碼。還要持續不斷地添加新的 folio 操作接口,疊加在已有的 page 接口之上等等。
好處:
(1)“這種抽象對文件系統開發者來說是絕對必要的”,特別是當頁緩存未來需要支持多種尺寸的復合頁時。比如:文件系統(如 XFS)需要統一接口處理 多尺寸復合頁。
(2)struct folio 提供更清晰的接口,避免頭頁/尾頁的歧義。引入 struct folio 類型,僅表示 Head Page(或單頁),徹底消除 Tail Page 的歧義。
(3)消除 compound_head() 開銷:傳統復合頁操作需頻繁調用 compound_head() 檢查并轉換 Tail Page,Folio 直接保證無 Tail Page,省去冗余檢查。
在內核里面內核模塊里面,很多內核函數傳遞進來的 page 參數總是需要判斷是 head page 還是 tail page。由于沒有上下文緩存,mm 路徑上可能會存在太多重復的 compound_head 調用。
比如page_mapping:
// v5.15/source/mm/util.cstruct address_space *page_mapping(struct page *page)
{struct address_space *mapping;page = compound_head(page);/* This happens if someone calls flush_dcache_page on slab page */if (unlikely(PageSlab(page)))return NULL;if (unlikely(PageSwapCache(page))) {swp_entry_t entry;entry.val = page_private(page);return swap_address_space(entry);}mapping = page->mapping;if ((unsigned long)mapping & PAGE_MAPPING_ANON)return NULL;return (void *)((unsigned long)mapping & ~PAGE_MAPPING_FLAGS);
}
EXPORT_SYMBOL(page_mapping);
該函數需要先調用 compound_head(page) 判斷是否為 tail page,再獲取 mapping。
當切換到 folio 之后,page_mapping(page) 對應 folio_mapping(folio) ,而 folio 隱含著 folio 本身就是 head page,因此 compound_head(page) 的調用就省略了。
// v5.16/source/mm/util.c/*** folio_mapping - Find the mapping where this folio is stored.* @folio: The folio.** For folios which are in the page cache, return the mapping that this* page belongs to. Folios in the swap cache return the swap mapping* this page is stored in (which is different from the mapping for the* swap file or swap device where the data is stored).** You can call this for folios which aren't in the swap cache or page* cache and it will return NULL.*/
struct address_space *folio_mapping(struct folio *folio)
{struct address_space *mapping;/* This happens if someone calls flush_dcache_page on slab page */if (unlikely(folio_test_slab(folio)))return NULL;if (unlikely(folio_test_swapcache(folio)))return swap_address_space(folio_swap_entry(folio));mapping = folio->mapping;if ((unsigned long)mapping & PAGE_MAPPING_ANON)return NULL;return (void *)((unsigned long)mapping & ~PAGE_MAPPING_FLAGS);
}
EXPORT_SYMBOL(folio_mapping);
由于 folio 保證不是 tail page,因此無需 compound_head(),可直接訪問。
mm 路徑上到處是 compound_head 的調用。積少成多,不僅執行開銷減少了,開發者也能得到提示,當前 folio 一定是 head page,減少判斷分支。
二、page folios的好處
2.1 compound page
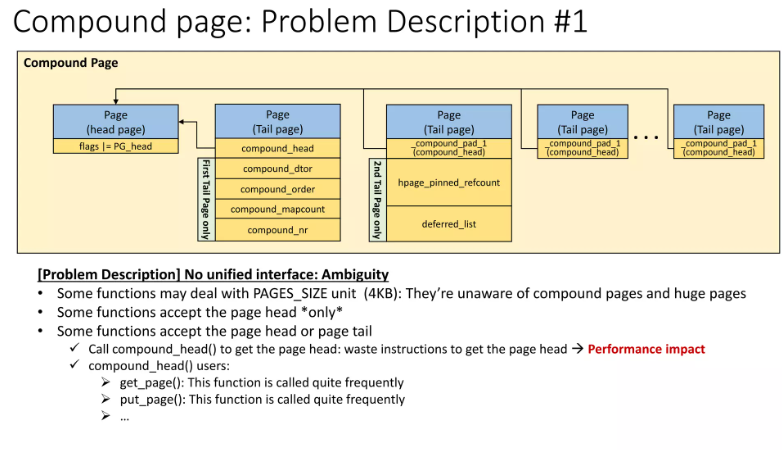
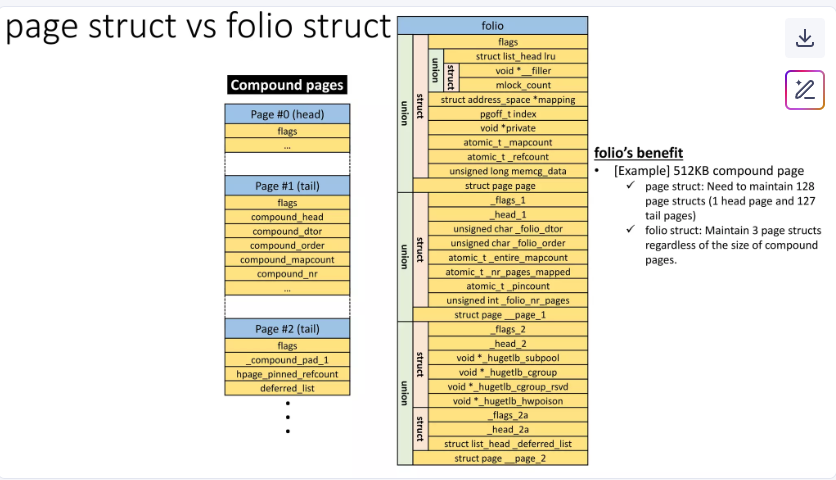
復合頁包含頭頁(Head Page)和尾頁(Tail Pages),尾頁需要額外的 compound_head() 調用以定位頭頁,增加運行時開銷。
任何可能接收到尾頁指針、但又需要操作整個復合頁的函數,通常必須先將尾頁指針轉換為頭頁指針,這通常通過調用如下函數實現:
struct page *compound_head(struct page *page);
這個函數本身開銷不大(通常是內聯函數),但在一次頁面操作中可能被頻繁調用多次。這不僅增加了內核代碼體積(因為是內聯展開),也累積了運行時開銷。
Folio 的改進:
保證不包含尾頁:struct folio 僅代表完整的內存單元(頭頁或單頁),無需處理尾頁的查找。
而如果函數直接接收的是 page folio,那么它天然知道傳入的不是尾頁,因此完全不需要調用 compound_head()。這直接省去了大量的指針轉換操作,從而節省了執行時間和內存占用。
2.2 page cache
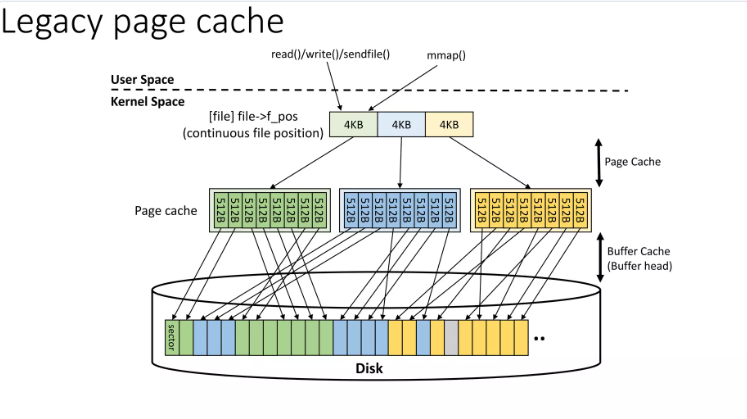
(1) legacy page cache:即 5.16.0以前的管理
$ grep -i active /proc/meminfo
Active: 12773136 kB
Inactive: 17503876 kB
Active(anon): 2128 kB
Inactive(anon): 3775856 kB
Active(file): 12771008 kB
Inactive(file): 13728020 kB
傳統頁緩存(legacy page cache)的問題,特別是在沒有復合頁(compound page)概念的情況下。主要問題包括:
- 頁緩存占據了大部分內存頁。
- 每個頁緩存(作為單個基礎頁)都被添加到活躍/非活躍LRU列表中,導致LRU列表非常長。
- 長LRU列表導致鎖競爭和緩存失效(cache misses)問題。
傳統頁緩存設計的核心問題是 粒度過細。
(2)引入 Page Folios
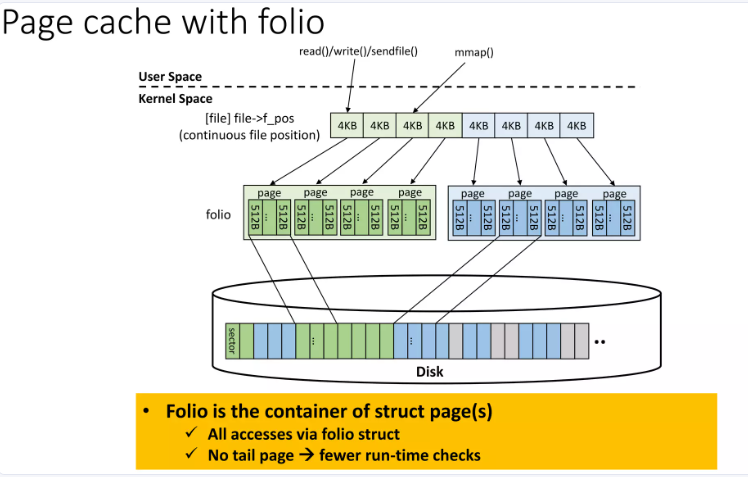
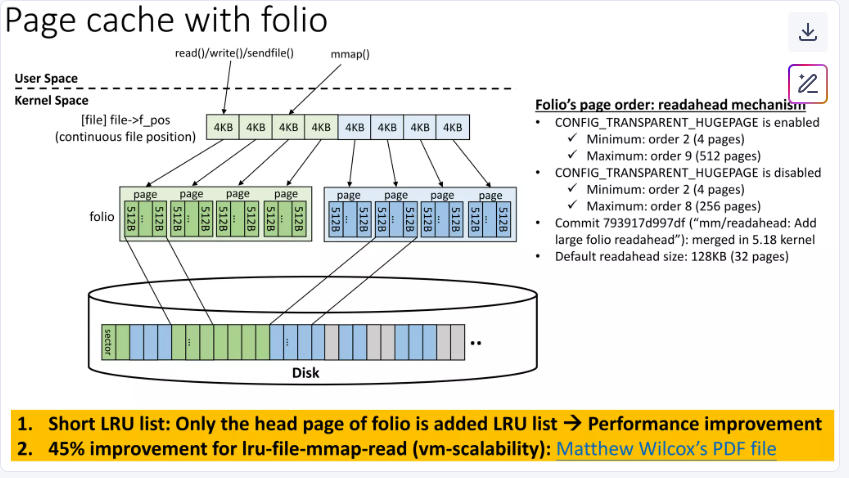
僅頭頁加入 LRU:每個 folio 作為一個完整單元,僅其頭頁(head page)加入 LRU 列表。
在folio模型中,一個folio可以包含多個連續的物理頁(例如一個folio包含多個page)。當將folio添加到LRU鏈表時,整個folio作為一個條目加入- 只有folio的頭頁被加入LRU列表,而不是每個基礎頁單獨加入。這樣,LRU鏈表的長度大大縮短,從而減少了鎖競爭和緩存未命中的問題。
具體來說,在folio實現中:
- 每個folio都有一個LRU鏈表節點(
struct list_head lru)。 - 當需要將folio加入LRU鏈表時(例如在
folio_add_lru()函數中),只有folio的頭頁被加入LRU列表。 - 當進行LRU鏈表掃描(如kswapd)時,每次處理一個folio(可能包含多個頁),效率更高。
只有folio的頭頁被加入LRU列表。傳統情況下,每個page獨立加入LRU列表,導致列表過長,鎖爭用和緩存未命中。而folio將多個頁合并為一個單元,只需添加頭頁到LRU列表,縮短列表長度,減少鎖操作和緩存壓力。
三、buffer_head、iomap與page folios
對于文件系統來說,盡可能不再使用舊的 buffer-head API,盡可能使用相對較新的 iomap 的基礎設施。
(1)buffer_head
buffer_head用于將單個塊映射到頁內,并且是文件系統和塊層I/O的基本單位。每個buffer_head通常對應一個4K的塊,但文件系統可能使用更小的塊大小,如1K或512字節。這種情況下,一個頁(4K)可能包含多個buffer_head結構體,每個描述該頁對應的不同磁盤塊位置。這導致在處理多頁讀寫時,每個頁都需要通過get_block調用來獲取磁盤偏移關系,增加了復雜性和開銷。
buffer_head以塊(block)為單位,通常為4KB或更小(如1KB/512B)。一個4KB頁(page)可能包含多個buffer_head(最多8個),導致每個頁的元數據管理復雜。
多頁操作低效:
逐塊操作:在讀寫多頁(multi-page)數據時,需逐個調用get_block獲取每個頁的磁盤偏移,增加了I/O路徑的開銷,每次 I/O 觸發多次 get_block() 翻譯(頁→磁盤塊)。
與THP的沖突
透明大頁(THP):THP將多個4KB頁合并為2MB或1GB的大頁,以減少頁表項和TLB壓力。然而,buffer_head的粒度無法直接適配THP,導致處理大頁時仍需分解為多個小塊操作,效率低下。
(2)iomap
iomap:iomap最初來自XFS,基于extent,天然支持多頁操作。通過iomap,文件系統可以一次性獲取所有頁的磁盤偏移關系,而不需要逐頁處理。這減少了I/O操作的次數和復雜度,提高了效率。此外,iomap使用字節作為單位,與page cache解耦,使得文件系統在處理數據大小時更加靈活,不需要依賴具體的頁數。
元數據操作:iomap目前缺乏對元數據操作的輔助函數。文件系統(如XFS)需自行實現元數據映射,而無法完全依賴iomap。
向后兼容性:部分舊功能(如submit_bh)仍需buffer_head支持,導致iomap無法完全替代。
當前iomap缺乏某些buffer_head的功能,而folio的合并能夠推動iomap的發展,使基于塊的文件系統轉換為使用iomap。
(3)folio
folio旨在簡化內存管理,減少運行時檢查,通過將多個物理頁封裝為一個邏輯單元來提高性能。Folio的引入有助于隔離文件系統與page cache,使得文件系統能夠更高效地處理大頁(如THP),從而提升I/O效率。XFS和AFS等基于iomap的文件系統已經率先采用folio,因為它們天然支持多頁操作,這使得folio的合并對這些文件系統的優化尤為重要。
FS 開發者都希望 folio 被合入,他們可以方便地在 page cache 中使用更大的 page,這個做法可以使文件系統的 I/O 更有效率。
四、何時分配 Large Folio
(1)來自用戶空間的提示(Hints from Userspace)
比如調用 madvise(MADV_HUGEPAGE) 來向內核表明希望使用大頁。
MADV_HUGEPAGE 是當前最有效的用戶空間提示(用于透明大頁 THP),但僅適用于匿名內存(anon pages),不直接用于文件頁緩存(page cache)。
(2)文件系統決策 (Filesystem Hints)
文件系統(如 ext4、XFS)知道文件的布局(如 extent 分配是否連續),但缺乏完整的訪問模式信息。
文件系統可以建議大 folio(例如通過 iomap 接口),但最終決策權在通用頁緩存層。
(3)Readahead 的激進策略 (Page Cache Readahead)
readahead 已成為決定大頁分配的核心:
它根據訪問模式(如順序讀、流式讀)決定預讀多少頁。
同時,它也決定分配多大的folio(4KB基礎頁 or 2MB大頁)。
覆蓋了大部分順序讀場景(如大文件讀取)。
(4)寫入未緩存的文件區域 —— 仍使用基礎頁(Order-0 Pages)
(5)缺頁 + MADV_HUGEPAGE → 分配PMD級大頁(僅限匿名內存)
如果用戶空間設置了 MADV_HUGEPAGE,缺頁異常(page fault)會嘗試分配 PMD-order(如 2MiB)的大 folio。
但僅適用于匿名內存(如 mmap(MAP_ANONYMOUS)),不適用于文件頁緩存。
五、folio結構體演變
到了Linux6.2,struct folio結構體:
/*** struct folio - Represents a contiguous set of bytes.* @flags: Identical to the page flags.* @lru: Least Recently Used list; tracks how recently this folio was used.* @mlock_count: Number of times this folio has been pinned by mlock().* @mapping: The file this page belongs to, or refers to the anon_vma for* anonymous memory.* @index: Offset within the file, in units of pages. For anonymous memory,* this is the index from the beginning of the mmap.* @private: Filesystem per-folio data (see folio_attach_private()).* Used for swp_entry_t if folio_test_swapcache().* @_mapcount: Do not access this member directly. Use folio_mapcount() to* find out how many times this folio is mapped by userspace.* @_refcount: Do not access this member directly. Use folio_ref_count()* to find how many references there are to this folio.* @memcg_data: Memory Control Group data.* @_flags_1: For large folios, additional page flags.* @_head_1: Points to the folio. Do not use.* @_folio_dtor: Which destructor to use for this folio.* @_folio_order: Do not use directly, call folio_order().* @_compound_mapcount: Do not use directly, call folio_entire_mapcount().* @_subpages_mapcount: Do not use directly, call folio_mapcount().* @_pincount: Do not use directly, call folio_maybe_dma_pinned().* @_folio_nr_pages: Do not use directly, call folio_nr_pages().* @_flags_2: For alignment. Do not use.* @_head_2: Points to the folio. Do not use.* @_hugetlb_subpool: Do not use directly, use accessor in hugetlb.h.* @_hugetlb_cgroup: Do not use directly, use accessor in hugetlb_cgroup.h.* @_hugetlb_cgroup_rsvd: Do not use directly, use accessor in hugetlb_cgroup.h.* @_hugetlb_hwpoison: Do not use directly, call raw_hwp_list_head().** A folio is a physically, virtually and logically contiguous set* of bytes. It is a power-of-two in size, and it is aligned to that* same power-of-two. It is at least as large as %PAGE_SIZE. If it is* in the page cache, it is at a file offset which is a multiple of that* power-of-two. It may be mapped into userspace at an address which is* at an arbitrary page offset, but its kernel virtual address is aligned* to its size.*/
struct folio {/* private: don't document the anon union */union {struct {/* public: */unsigned long flags;union {struct list_head lru;/* private: avoid cluttering the output */struct {void *__filler;/* public: */unsigned int mlock_count;/* private: */};/* public: */};struct address_space *mapping;pgoff_t index;void *private;atomic_t _mapcount;atomic_t _refcount;
#ifdef CONFIG_MEMCGunsigned long memcg_data;
#endif/* private: the union with struct page is transitional */};struct page page;};union {struct {unsigned long _flags_1;unsigned long _head_1;unsigned char _folio_dtor;unsigned char _folio_order;atomic_t _compound_mapcount;atomic_t _subpages_mapcount;atomic_t _pincount;
#ifdef CONFIG_64BITunsigned int _folio_nr_pages;
#endif};struct page __page_1;};union {struct {unsigned long _flags_2;unsigned long _head_2;void *_hugetlb_subpool;void *_hugetlb_cgroup;void *_hugetlb_cgroup_rsvd;void *_hugetlb_hwpoison;};struct page __page_2;};
};
如下圖所示:
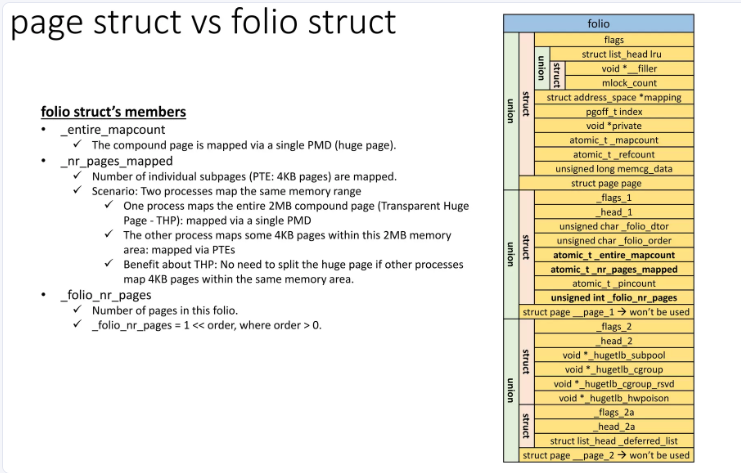
字段說明:



與compound pages的比較:

六、內核主線folio的逐步使用
Linux 5.16.0:引入page folios。
Linux 5.18.0:
(1)Memory management folio patches (get_user_pages, vmscan, start on the page cache, make readahead use large folios)
(2)Filesystem conversions to folio structures
Linux 5.19.0:
(1)conversion from alloc_pages_vma() to vma_alloc_folio(), finish converting shrink_page_list() to folios, start converting shmem from pages to folios
(2)Convert aops->read_page to aops->read_folio
Linux 6.0.0:
(1)Finish the conversion from alloc_pages_vma() to vma_alloc_folio(), finish converting shrink_page_list() to folio, start converting shmem from pages to folios
(2)Convert the swap code to be more folio-based
Linux 6.1.0:
Folio changes: this round has focused on shmem
Linux 6.2.0:
(1)Convert migrate_pages()/unmap_and_move() to use folios
(2)Begin converting hugetlb code to folios
(3)Convert core hugetlb functions to folios
…
參考資料
https://lwn.net/Articles/849538/
https://www.infoq.cn/article/kCRXZhKLOZ9lYJzaasZ0
https://zhuanlan.zhihu.com/p/1902473318315058208
https://www.infradead.org/~willy/linux/2022-06_LCNA_Folios.pdf
https://www.slideshare.net/slideshow/memory-management-with-page-folios/258148418
](http://pic.xiahunao.cn/[優選算法專題一雙指針——兩數之和](雙指針和哈希表))

是如何影響系統性能的?)


)



免安裝中文版)


:無界面 TCP 通信服最小實現)
實戰應用:從微調到部署全流程??)

 --運算符重載)



