本文記錄了自己在閱讀《動手學深度學習》時的一些思考,僅用來作為作者本人的學習筆記,不存在商業用途。
語言模型是自然語言處理的關鍵, 而機器翻譯是語言模型最成功的基準測試。 因為機器翻譯正是將輸入序列轉換成輸出序列的 序列轉換模型(sequence transduction)的核心問題。 序列轉換模型在各類現代人工智能應用中發揮著至關重要的作用, 本節將介紹機器翻譯問題及其后文需要使用的數據集。
機器翻譯(machine translation)指的是 將序列從一種語言自動翻譯成另一種語言。 事實上,這個研究領域可以追溯到數字計算機發明后不久的20世紀40年代, 特別是在第二次世界大戰中使用計算機破解語言編碼。 幾十年來,在使用神經網絡進行端到端學習的興起之前, 統計學方法在這一領域一直占據主導地位 (Brown et al., 1990, Brown et al., 1988)。 因為統計機器翻譯(statistical machine translation)涉及了 翻譯模型和語言模型等組成部分的統計分析, 因此基于神經網絡的方法通常被稱為 神經機器翻譯(neural machine translation), 用于將兩種翻譯模型區分開來。
本書的關注點是神經網絡機器翻譯方法,強調的是端到端的學習。 機器翻譯的數據集是由源語言和目標語言的文本序列對組成的。 因此,我們需要一種完全不同的方法來預處理機器翻譯數據集。
import os
import torch
from d2l import torch as d2l
9.5.1 下載和預處理數據集
首先,下載一個由Tatoeba項目的雙語句子對組成的“英-法”數據集,數據集中的每一行都是制表符分隔的文本序列對, 序列對由英文文本序列和翻譯后的法語文本序列組成。 請注意,每個文本序列可以是一個句子, 也可以是包含多個句子的一個段落。 在這個將英語翻譯成法語的機器翻譯問題中, 英語是源語言(source language), 法語是目標語言(target language)。
#@save
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip','94646ad1522d915e7b0f9296181140edcf86a4f5')#@save
def read_data_nmt():"""載入“英語-法語”數據集"""data_dir = d2l.download_extract('fra-eng')with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:return f.read()# 這個數據集返回是字符串, 里面帶有換行符和其他特殊符號
raw_text = read_data_nmt()
# 打印前面75個字符(0到74)
print(raw_text[:75])
🏷運行結果
Go. Va !
Hi. Salut !
Run! Cours?!
Run! Courez?!
Who? Qui ?
Wow! ?a alors?!
下載數據集后,原始文本數據需要經過幾個預處理步驟。 例如,我們用空格代替不間斷空格(non-breaking space), 使用小寫字母替換大寫字母,并在單詞和標點符號之間插入空格。
#@save
def preprocess_nmt(text):"""預處理“英語-法語”數據集"""def no_space(char, prev_char):# 如果當前字符是特殊符號且上一個字符不是空格, 說明當前字符是單詞后面跟著的特殊符號, 則該字符前應該添加空格# 返回布爾變量, 需要添加空格時則返回True, 否則返回Falsereturn char in set(',.!?') and prev_char != ' '# 使用空格替換不間斷空格# text.replace('\u202f', ' ')使用標準空格替換Unicode編碼中的窄空格'\u202f'# text.replace('\xa0', ' ')使用標準空格替換Unicode編碼中的不換行空格'\xa0'# 使用小寫字母替換大寫字母text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()# 在單詞和標點符號之間插入空格# for i, char in enumerate(text)返回字符串text中的每個字符以及其對應的索引# if i > 0 and no_space(char, text[i - 1])如果當前字符不是首字符并且當前字符是特殊字符(,.!?), 則說明當前字符是單詞后面的特殊字符, 在中間插入空格# else如果當前字符是首字符或不滿足上述條件, 則當前字符是單詞內的字符, 直接返回即可out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else charfor i, char in enumerate(text)]# out是數據集raw_text經過字符修正后的結果, 是一個列表, 列表中每個元素是修正后的數據集中的字符# ''.join(out)表示利用列表out中的元素組建字符串, 其中不使用任何額外字符填充# ''.join(["A","B","C"]) "ABC"# ' '.join(["A","B","C"]) "A B C"# '-'.join(["A","B","C"]) "A-B-C"return ''.join(out)# 處理數據集并打印前80個字符
text = preprocess_nmt(raw_text)
print(text[:80])
🏷預處理后的數據集如下
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ?a alors !
9.5.2 詞元化
在機器翻譯中,我們更喜歡單詞級詞元化 (最先進的模型可能使用更高級的詞元化技術)。 下面的tokenize_nmt函數對前num_examples個文本序列對進行詞元, 其中每個詞元要么是一個詞,要么是一個標點符號。此函數返回兩個詞元列表:source和target: sourcei是源語言(這里是英語)第iii個文本序列的詞元列表, targeti是目標語言(這里是法語)第iii個文本序列的詞元列表。
#@save
def tokenize_nmt(text, num_examples=None):"""詞元化“英語-法語”數據數據集"""# 創建兩個空列表source和targetsource, target = [], []# text.split('\n')按換行符拆分修正后的數據集text,得到每個英語-法語單詞對(一行是一個)# for i, line in enumerate(text.split('\n'))返回每行line及行索引ifor i, line in enumerate(text.split('\n')):# 如果num_examples存在值(正整數)并且當前處理的行超過了num_examples時則終止(當前處理的是第i個單詞對, 但設置了只處理前面num_examples個單詞對)if num_examples and i > num_examples:break# line.split('\t')按照空格拆分, parts[0]是英語部分, parts[1]是法語部分parts = line.split('\t')# 如果拆分不出來兩個部分, 說明當前行不是英語-法語單詞對if len(parts) == 2:# 按照空格拆分英語部分(單詞直接有空格, 單詞和特殊符號之間有空格)source.append(parts[0].split(' '))# 按照空格拆分法語部分(單詞直接有空格, 單詞和特殊符號之間有空格)target.append(parts[1].split(' '))# 返回英語列表source和法語列表targetreturn source, target# 打印前6個英語單詞和對應的法語單詞
source, target = tokenize_nmt(text)
source[:6], target[:6]
🏷運行結果如下
([['go', '.'],['hi', '.'],['run', '!'],['run', '!'],['who', '?'],['wow', '!']],[['va', '!'],['salut', '!'],['cours', '!'],['courez', '!'],['qui', '?'],['?a', 'alors', '!']])
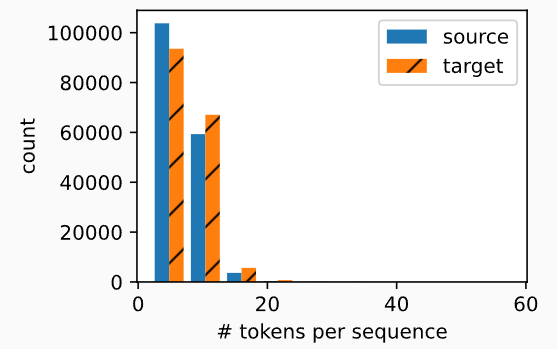
繪制每個文本序列所包含的詞元數量的直方圖。 在這個簡單的“英-法”數據集中,大多數文本序列的詞元數量少于20個。
#@save
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):"""繪制列表長度對的直方圖"""# 設置圖表大小d2l.set_figsize()# for l in xlist, for l in ylist遍歷source和target中的每個元素(就是原始數據text的每一行)# len(l)獲得source和target中包含的詞元數量, 比如英語的['go','.']是兩個詞元, 對應法語的['va','!']也是兩個詞元_, _, patches = d2l.plt.hist([[len(l) for l in xlist], [len(l) for l in ylist]])d2l.plt.xlabel(xlabel)d2l.plt.ylabel(ylabel)# 設置target的直方圖樣式為帶斜線for patch in patches[1].patches:patch.set_hatch('/')d2l.plt.legend(legend)show_list_len_pair_hist(['source', 'target'], '# tokens per sequence','count', source, target);
9.5.3 詞表
由于機器翻譯數據集由語言對組成, 因此我們可以分別為源語言和目標語言構建兩個詞表。 使用單詞級詞元化時,詞表大小將明顯大于使用字符級詞元化時的詞表大小。 為了緩解這一問題,這里我們將出現次數少于2次的低頻率詞元 視為相同的未知(“”)詞元。 除此之外,我們還指定了額外的特定詞元, 例如在小批量時用于將序列填充到相同長度的填充詞元(“”), 以及序列的開始詞元(“”)和結束詞元(“”)。 這些特殊詞元在自然語言處理任務中比較常用。
# 具體可以參考8.2文本預處理中的代碼
# 以['go', '.']為例, 在d2l.Vocab中調用collection.Counter時會分別統計'go'和'.'出現的頻率
src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])
len(src_vocab)
🏷運行結果顯示英語詞表共包含10012個詞元
10012
9.5.4 加載數據集
在機器翻譯中,每個樣本都是由源和目標組成的文本序列對, 其中的每個文本序列可能具有不同的長度。為了提高計算效率,我們仍然可以通過截斷(truncation)和 填充(padding)方式實現一次只處理一個小批量的文本序列。 假設同一個小批量中的每個序列都應該具有相同的長度num_steps, 那么如果文本序列的詞元數目少于num_steps時, 我們將繼續在其末尾添加特定的“”詞元, 直到其長度達到num_steps; 反之,我們將截斷文本序列時,只取其前num_steps 個詞元, 并且丟棄剩余的詞元。這樣,每個文本序列將具有相同的長度, 以便以相同形狀的小批量進行加載。
#@save
def truncate_pad(line, num_steps, padding_token):"""截斷或填充文本序列"""if len(line) > num_steps:return line[:num_steps] # 截斷return line + [padding_token] * (num_steps - len(line)) # 填充# 根據source[0], 即['go', '.'], 去詞表src_vocab中查找對應的詞元索引
# 由于source[0] = ['go','.']共包含兩個詞元, 而num_steps設置了10, 即每行應包括10個詞元,
# 所以需要填充8個'<pad>', 去詞表src_vocab中查找對應的詞元索引后拼接成包含10個詞元索引的向量
truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])
🏷運行結果如下所示
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
現在我們定義一個函數,可以將文本序列轉換成小批量數據集用于訓練。 我們將特定的“”詞元添加到所有序列的末尾, 用于表示序列的結束。 當模型通過一個詞元接一個詞元地生成序列進行預測時, 生成的“”詞元說明完成了序列輸出工作。 此外,我們還記錄了每個文本序列的長度, 統計長度時排除了填充詞元, 在稍后將要介紹的一些模型會需要這個長度信息。
#@save
def build_array_nmt(lines, vocab, num_steps):"""將機器翻譯的文本序列轉換成小批量"""# for l in lines, 從lines中遍歷每行l# vocab[l]獲得該行中的詞元在詞表中的索引# lines是一個列表, 每個元素也是列表, 包含該行中的所有詞元在詞表中索引, 比如[[47, 4], [12, 4]]lines = [vocab[l] for l in lines]# 遍歷lines中的每個元素l, 向里面加入終止符'<eos>'在詞表中對應的索引, 于是lines變成類似[[47, 4, 0], [12, 4, 0]]lines = [l + [vocab['<eos>']] for l in lines]# 遍歷lines中的每個元素, 如果不滿足num_steps則填充'<pad>'在詞表中的索引# 轉成torch.tensor返回# array類似tensor([[ 9, 4, 3, ..., 1, 1, 1],# [113, 4, 3, ..., 1, 1, 1]])array = torch.tensor([truncate_pad(l, num_steps, vocab['<pad>']) for l in lines])# array的每個元素就是一行, array != vocab['<pad>']逐元素比較是否為填充詞元'<pad>'的索引, 獲得布爾值# sum(1)按照列求和, 于是可以得到一行中有多少不是填充詞元'<pad>'的詞元, 即獲得一行的長度valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)# 返回填充后的每行索引以及每行的長度(包含的詞元數)return array, valid_len
9.5.5 訓練模型
定義load_data_nmt函數來返回數據迭代器以及源語言和目標語言的兩種詞表。
#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):"""返回翻譯數據集的迭代器和詞表"""# 預處理"英語-法語"數據集(規范化空格并統一小寫)text = preprocess_nmt(read_data_nmt())# 詞元化source, target = tokenize_nmt(text, num_examples)# 根據英語獲得英語詞表src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])# 根據法語獲得法語詞表tgt_vocab = d2l.Vocab(target, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])# 獲得填充后的英語及每行長度src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)# 獲得填充后的法語及每行長度tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)# 將數據集打包成元組data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)# 返回數據集迭代器, d2l.load_array需要元組型數據和批量大小, 元組型數據格式是(數據特征, 標簽)data_iter = d2l.load_array(data_arrays, batch_size)return data_iter, src_vocab, tgt_vocab
讀取"英語-法語"數據集中的第一個小批量數據
# 批量大小為2, 時間長度為8(每行應該包括8個詞元)
# 返回訓練集迭代器, 英語詞表, 法語詞表
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
# 打印第一個批量的數據
for X, X_valid_len, Y, Y_valid_len in train_iter:print('X:', X.type(torch.int32))print('X的有效長度:', X_valid_len)print('Y:', Y.type(torch.int32))print('Y的有效長度:', Y_valid_len)break
🏷運行結果,注意每個批量使用了兩行(batch_size = 2),每行需要8個詞元(num_step = 8)
X: tensor([[ 7, 43, 4, 3, 1, 1, 1, 1],[44, 23, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
X的有效長度: tensor([4, 4])
Y: tensor([[ 6, 7, 40, 4, 3, 1, 1, 1],[ 0, 5, 3, 1, 1, 1, 1, 1]], dtype=torch.int32)
Y的有效長度: tensor([5, 3])



創建新的slave從機)




)

回文鏈表)





)


