Transformer Feed-Forward Layers Are Key-Value Memories
-
原文摘要
-
研究背景與問題:
- 前饋層占Transformer模型參數總量的2/3,但其功能機制尚未得到充分研究
-
核心發現:提出前饋層實質上是鍵值存儲系統
- 鍵:這里的鍵與訓練數據中出現的特定**文本模式 **相關聯。
- 例如,一個鍵可能被“The capital of France is”這樣的短語激活。
- 值: 與每個鍵對應,這個值的功能是引導模型生成一個關于輸出詞匯的概率分布。
- 繼續上面的例子,與“The capital of France is”這個鍵關聯的值,會生成一個概率分布,其中 “Paris” 這個詞的概率會非常高。
- 鍵:這里的鍵與訓練數據中出現的特定**文本模式 **相關聯。
-
實驗發現:
-
學習到的文本模式具有人類可解釋性
-
層級分化現象:
-
底層網絡捕捉表層模式(如語法結構)
-
高層網絡學習語義模式(深層含義)
-
鍵值協同機制:
-
值分布會集中在可能跟隨鍵模式出現的詞匯上
-
這種特性在高層網絡中尤為顯著
-
-
-
模型工作機制:
-
組合輸出: 單個前饋層的輸出并不是只激活了一個記憶,而是其內部 多個鍵值記憶的組合。
-
逐層精煉: 這個組合后的輸出,會通過殘差連接傳遞到模型的下一層。
- 在后續的網絡層中,這個輸出會被 不斷地修正和精煉。
-
最終結果: 經過所有層的處理和精煉,模型最終生成了用于預測下一個詞的概率分布。
-
-
1. 介紹
-
研究背景:
-
現狀描述:基于Transformer的語言模型(如BERT、GPT)已成為NLP領域的主流架構
-
研究失衡:
- 自注意力機制獲得大量研究關注
- 實際參數分布:自注意力層僅占1/3參數(4d2),前饋層占主要參數(8d2)
-
核心問題:前饋層在Transformer中的具體功能機制是什么?
-
-
理論突破
-
核心觀點:前饋層在功能上模擬了神經記憶
- 結構對應關系:
- 第一參數矩陣 → 記憶鍵(keys)
- 第二參數矩陣 → 記憶值(values)
-
機制:
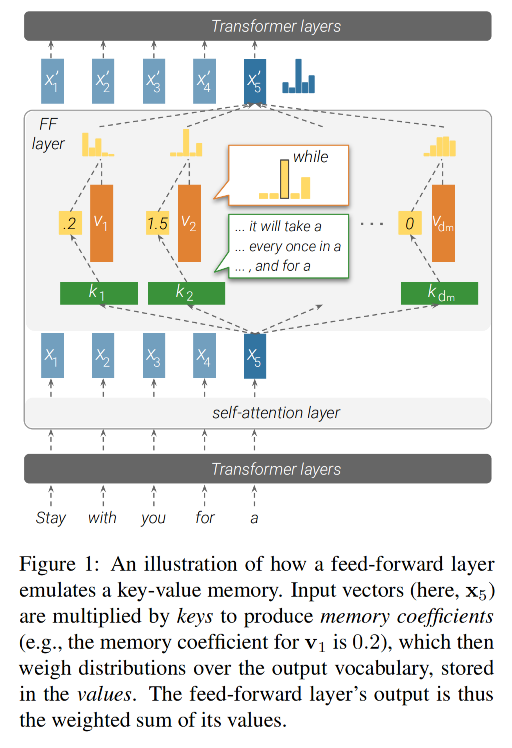
- 鍵與模型的輸入進行交互,生成一組系數。
- 然后,這些系數被用來對值進行加權求和,從而得到該層的輸出。
- 結構對應關系:
- 創新點:首次系統分析前饋層存儲的具體記憶內容
-
-
實證發現
- 鍵特性:
- 每個鍵都與一組特定的、人類可以理解的輸入模式 相關。
- 這些模式可以是 n-gram (如固定詞組),也可以是 語義主題。
- 值特性:
- 每個值都能導出一個關于輸出詞匯的概率分布。
- 這個分布與它對應的鍵后面最可能出現的下一個詞高度相關,這種相關性在模型的高層尤其明顯。
- 鍵特性:
-
系統工作機制:
-
記憶組合機制:
- 每層整合數百個活躍記憶單元
- 產生與單個記憶值性質不同的復合分布
-
殘差連接功能:
- 精煉機制:逐層微調預測分布
- 信息保留:保持底層信息的持續傳遞
-
-
核心結論:
-
前饋層在所有層級中都充當了輸入模式的檢測器。
-
模型的最終輸出分布,是一個通過所有層 自下而上地、逐步構建 起來的結果。
-
2. 前饋層作為未歸一化的鍵值記憶結構
2.1 Feed-forward 層
-
前饋層特性
-
在 Transformer 中,前饋層是逐位置處理的
-
每一個 token 的向量都單獨通過 FFN,不考慮別的位置。
-
輸入向量記為:x∈Rdx \in \mathbb{R}^dx∈Rd(d 是隱藏維度)
-
-
數學表達式
FF(x)=f(x?K?)?VFF(x) = f(x \cdot K^\top) \cdot V FF(x)=f(x?K?)?V-
K∈Rdm×dK \in \mathbb{R}^{d_m \times d}K∈Rdm?×d:key 參數矩陣
-
V∈Rdm×dV \in \mathbb{R}^{d_m \times d}V∈Rdm?×d:value 參數矩陣
-
f(?)f(\cdot)f(?) :非線性函數(如 ReLU)
-
mmm 是隱藏維度數量,表示記憶單元個數
-
2.2 神經記憶
-
神經記憶組成
- 神經記憶由一組
key-value對組成(也稱 memory cells)-
神經記憶論文中就是用Memory去乘以對應的嵌入矩陣
-
每個 kik_iki? 是一個 d 維向量,構成整個 key 矩陣 K∈Rdm×dK \in \mathbb{R}^{d_m \times d}K∈Rdm?×d
-
每個 viv_ivi? 是一個 d 維向量,構成 value 矩陣 V∈Rdm×dV \in \mathbb{R}^{d_m \times d}V∈Rdm?×d
-
- 神經記憶由一組
-
神經記憶的輸出形式:
p(ki∣x)∝exp(x?ki)→基于點積做?softmax?得到匹配概率MN(x)=∑i=1dmp(ki∣x)?vi→輸出是記憶值的加權平均p(k_i | x) ∝ exp(x · k_i) \rightarrow \text{基于點積做 softmax 得到匹配概率} \\ MN(x) = \sum^{d_m}_{i=1} p(k_i | x) · v_i \rightarrow \text{輸出是記憶值的加權平均} p(ki?∣x)∝exp(x?ki?)→基于點積做?softmax?得到匹配概率MN(x)=i=1∑dm??p(ki?∣x)?vi?→輸出是記憶值的加權平均- 簡化式
MN(x)=softmax(x?K?)?VMN(x) = softmax(x \cdot K^\top) \cdot V MN(x)=softmax(x?K?)?V
- 簡化式
-
神經記憶論文原文
2.3 FFN就是模擬神經記憶
-
兩者的結構幾乎完全一致,區別只在于:
結構 前饋層 FFN 神經記憶 Memory 輸入與 key 的相似度計算 x?K?x \cdot K^\topx?K? x?K?x \cdot K^\topx?K? 激活函數 ReLU(非歸一化)softmax(歸一化)輸出 $ f(x \cdot K^\top) \cdot V$ $ softmax(x \cdot K^\top) \cdot V$ - 區別:FFN 用的是
ReLU,沒有歸一化;神經記憶用的是softmax,輸出是概率分布。
- 區別:FFN 用的是
-
FFN 的隱藏層:記憶系數
m=f(x?K?)m = f(x \cdot K^\top)m=f(x?K?),這個激活向量其實就是每個 memory 的記憶系數
-
m∈Rmm \in \mathbb{R}^mm∈Rm 是 FFN 中間的隱藏表示
-
每個 mim_imi? 就代表第 iii 個記憶單元對當前輸入的響應強度
- 如果輸入 xxx 很符合第 iii 個 key (kik_iki?),那么 mim_imi? 就會很大
-
-
論文觀點:
- 每個 key 向量 kik_iki? 會對輸入序列中的某種模式(n-gram、短語、語義片段)產生響應
- 對應的 value 向量 viv_ivi? 表示該模式之后的可能輸出分布
3. 鍵捕捉輸入模式
- 核心觀點:
- 在Transformer模型的前饋層中,**鍵矩陣 KKK **的作用是檢測輸入序列中的特定模式。
- 具體來說,每個矩陣中的每個向量kik_iki?對應輸入前綴x1,...,xjx_1,...,x_jx1?,...,xj?中的某種特定模式。
3.1 實驗驗證
-
實驗目標:證明這些 Key 確實與某些人類可解釋的輸入模式存在強關聯。
-
實驗設置:
- 模型:Baevski & Auli 的16層Transformer語言模型(基于WikiText-103訓練)。
- 每層前饋層的隱藏維度d=1024,dm=4096,總關鍵向量數量為dm·16=65,536。
- 采樣:從每層隨機抽取10個關鍵向量(共160個)進行分析。
- 數據:使用WikiText-103訓練集的所有句子前綴計算記憶系數。
- 模型:Baevski & Auli 的16層Transformer語言模型(基于WikiText-103訓練)。
-
實驗步驟
-
計算記憶激活值
-
給定某個鍵 kik_iki?,計算其在訓練集(WikiText-103)中所有句子前綴上的記憶激活值:
ReLU(xj??ki?)\text{ReLU}(x_j^\ell \cdot k_i^\ell) ReLU(xj???ki??)- 其中,xj?x_j^\ellxj?? 是前綴 xjx_jxj? 在第 ? 層的表示,ki?k_i^\ellki?? 是第 ?\ell? 層的第 iii 個關鍵向量。
-
對每個句子,計算其所有前綴的記憶激活值。如:
- 輸入句子:
I love dogs - 前綴:
I、I love、I love dogs - 每個前綴都過模型第 ?\ell? 層,得到向量 xj?x_j^\ellxj??,然后與 key ki?k_i^\ellki?? 做內積,ReLU 激活
- 輸入句子:
-
-
選出激活值最大的 top-t 個例子
- 選擇與ki?k_i^\ellki?? 內積后激活值最高的前t個前綴(即觸發示例)。
-
人工分析
-
讓人類專家(NLP研究生)對每個key kik_iki? 的前25個觸發示例進行標注,要求:
- 識別至少出現在3個前綴中的重復模式——降低隨機性
- 例如某個 key 的 25 個高激活句子中有 5 個包含“in the middle of”,那這個短語可能就是該 key 的檢測目標
- 用自然語言描述這些模式;
- 將模式分類為shallow或semantic
- 淺層模式:如 n-gram、詞形搭配
- 語義模式:如主題、句子結構、語義場景
- 識別至少出現在3個前綴中的重復模式——降低隨機性
-
每個前綴可能關聯多個模式。
-
-
-
結果

3.2 結果
3.2.1 每個 memory 都與人類可識別的語言模式相關
- 專家標注結果:
- 對于每一個key,人類專家都能識別出至少1種模式,平均每個關鍵向量關聯3.6種模式。
- 65%-80% 的觸發前綴(top觸發示例)至少包含一種可識別的模式。
- 結論:
- Key確實捕捉到了可解釋的模式,而不僅僅是隨機激活。
- 這些模式在人類看來是明確的,表明前饋層的keys在某種程度上類似于模式探測器。
3.2.2 淺層 key 更偏向于淺層模式
- Transformer 的底層 FFN 層(第1-9層)更擅長捕捉“表層語言結構”
- 而越往上的層,越傾向于捕捉語義一致性:
- 雖然激活的句子在表面形式上不相似,但上下文語義很接近
3.2.3 通過局部修改驗證模式敏感性
-
為了進一步驗證淺層/深層關鍵向量的差異,作者進行了可控擾動實驗:
- 方法:
- 對每個關鍵向量的top-50觸發示例進行三種修改:
- 刪除第一個token(測試開頭的影響);
- 刪除最后一個token(測試結尾的影響);
- 隨機刪除一個token(作為基線)。
- 然后測量這些修改對記憶系數的影響。
- 對每個關鍵向量的top-50觸發示例進行三種修改:
- 方法:
-
結果(圖3):
- 模型更關注句子的尾部(比如,刪除最后一個詞,對激活影響更大)
- 說明模型的 FFN 更敏感于前綴的結尾部分
- 但在深層 FFN 中,刪除最后一個詞影響反而小
- 說明:深層 key 并不依賴于具體詞序,而更多關注語義結構
- 模型更關注句子的尾部(比如,刪除最后一個詞,對激活影響更大)
4. 值表示詞匯分布
- 核心目標:證明每個 FFN 的 value 向量 viv_ivi? 可以近似看作是一個詞匯分布,即預測下一個詞的概率分布。
4.1 方法:把 value 映射到詞匯表上
pi=softmax(vi?E)p_i= softmax(v_i \cdot E) pi?=softmax(vi??E)
-
解釋
- viv_ivi?:某個 FFN 中的 value 向量
- EEE:模型的輸出 embedding 矩陣(每一行表示一個詞的嵌入向量)
- pip_ipi?:是一個概率分布,表示:如果只靠這個viv_ivi?來預測,會最傾向于哪個詞?
-
說明
-
由于實際的模型預測不僅用了viv_ivi?,還用了激活系數,所以這個 pip_ipi? 是一種理想化的預測分布,不能代表真實概率,但可以用來分析。
-
也就是說:我們可以看它最喜歡哪個詞(即 argmax),但不能直接當成語言模型輸出概率。
-
4.2 value 的 top 預測是否匹配 key 激活句子的下一個詞?
-
探究:如果一個 key 檢測到了某個輸入模式,那么它對應的 value 是否預測了這句話接下來的下一個詞?
-
驗證方式:
-
對每個 key ki?k_i^\ellki??,找到激活它最強的句子(top-1 trigger example),記作 x1,...,xjx_1, ..., x_jx1?,...,xj?
-
這句話的下一個token記為 wi?w_i^\ellwi??
-
比較這個token是否就是 value 對應分布 pip_ipi? 中得分最高的詞
- 即:argmax(pi)==wi?argmax(p_i) == w_i^\ellargmax(pi?)==wi?? 是否成立
-
-
結果
-
層數從 1 到 10:匹配率接近 0%
-
從第 11 層開始:匹配率迅速上升,到達約 3.5%
-
雖然這個數值不高,但論文指出:
遠高于隨機猜詞的匹配率(0.0004%)
說明這是非隨機的語言現象
-
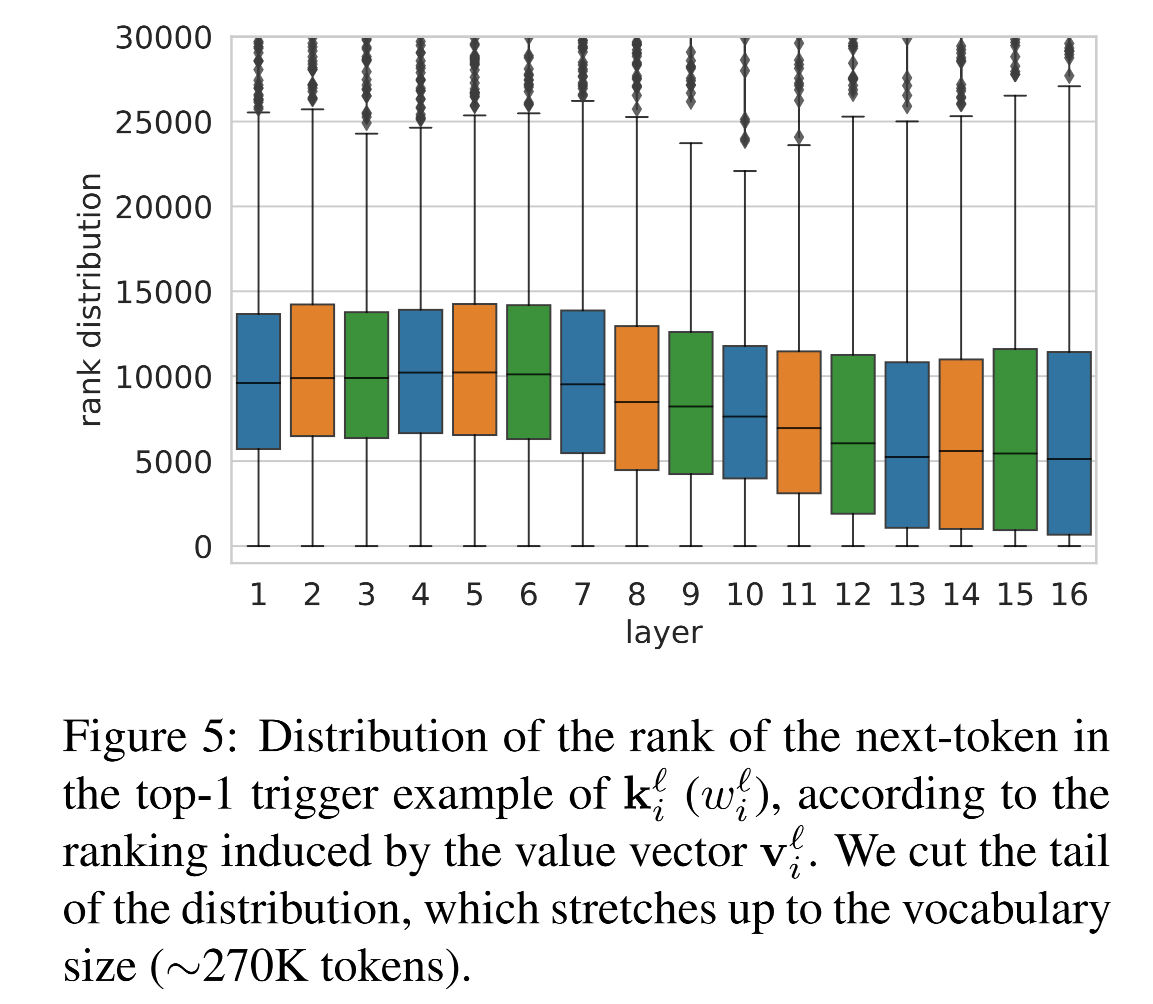
4.3 value 分布中預測詞的排序越來越靠前
-
進一步探究:即使正確token不是top-1,那個正確的token在 value 預測分布中排第幾?
-
在上層,key 所對應句子的下一個token,在 value 的預測中,排序越來越靠前
-
說明 value 越來越傾向于預測出 key 對應前綴之后的詞
-
4.4 哪些value具有更強的預測性
-
探究:能否找出那些真正有預測能力的 value ?
-
方法:
-
觀察每個 value 分布中 top-1 的概率值(即 max(pi)max(p_i)max(pi?))
-
如果這個值很大,說明這個 value 特別偏向某一個token
-
檢查這類 value 是否更可能匹配 key 的激活句子?
- 即value預測的結果是否是key觸發示例的下一個token
-
-
結果
- 值向量的最大概率越高,其預測與關鍵向量模式的匹配率也越高。
- 在所有層中,選取Top 100最高概率的值向量,發現:
- 97個來自高層(11-16層),僅3個來自低層。
- 46個值向量(46%) 的Top預測與至少一個關鍵向量觸發示例的下一個token匹配。
4.5 討論
- 高層值向量具有預測能力:
- 高層的值向量vi?v_i^\ellvi??傾向于預測關鍵向量ki?k_i^\ellki??模式的下一個詞token,表明它們存儲了模式→預測的映射關系。
- 例如,如果關鍵向量檢測到模式 “The capital of France is”,則對應值向量可能會高概率預測 “Paris”。
- 低層值向量無顯著預測能力:
- 低層的值向量與關鍵向量模式無關,可能因為:
- 低層的值向量不在輸出詞嵌入空間,導致投影后的分布無意義。
- 低層更關注局部語法,而非語義預測。
- 低層的值向量與關鍵向量模式無關,可能因為:
- 部分中間層可能共享高層空間:
- 某些中間層(如10-11層)的值向量開始表現出預測能力,表明Transformer的表示空間可能逐漸對齊。
5. 累加記憶
-
本節探究的核心問題
-
在一個前饋層內部,多個激活的 memory cell 是如何組合起來輸出一個向量的?
-
多個前饋層之間是如何通過殘差連接將這些組合進一步細化、優化的?
-
5.1 單個前饋層中多個 memory 的組合行為
-
前饋層的輸出:
y?=∑iReLU(x??ki?)?vi?+b?y^\ell = \sum_i \text{ReLU}(x^\ell \cdot k_i^\ell) · v_i^\ell + b^\ell y?=i∑?ReLU(x??ki??)?vi??+b?-
每個 key 向量 ki?k_i^\ellki?? 與輸入 x?x^\ellx? 點積,經過 ReLU 得到激活系數
-
對應的 value vi?v_i^\ellvi?? 被加權求和
-
加上 bias,得到這一層 FFN 的輸出 y?y^\elly?
每一層的輸出是很多子預測的組合結果。
-
-
探究問題
- 這些 value 到底是如何組合成一個輸出的?
- 是某個單獨的 memory 主導?
- 還是多個記憶單元共同決定?
- 這些 value 到底是如何組合成一個輸出的?
-
實驗設計:
-
從驗證集中的隨機采樣 4,000 個前綴
-
驗證集用于模擬模型在推理時的行為(而不是記憶訓練樣本)
-
-
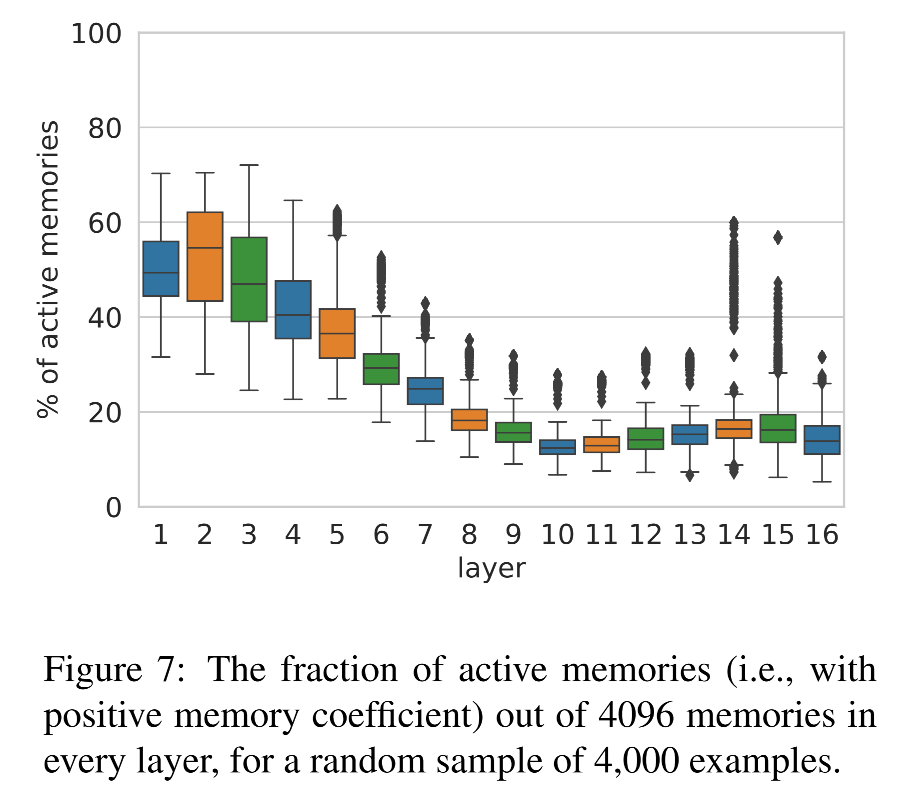
指標1:每層被激活的 memory 數量
-
每一層中,大概有 10%–50%memory cell 被激活(也就是激活值 > 0)
-
到了第 10 層,激活數量下降,正好對應之前在第3節提到從淺層結構過渡到語義層的臨界點
-
-
指標2:輸出是否由單一記憶主導的?
-
定義:top(h)=argmax(h?E)top(h) = argmax(h \cdot E)top(h)=argmax(h?E)
- 即某個向量 h 的預測詞是哪個(映射到詞表)
-
檢驗:當前層的輸出向量 y?y^\elly?,是否等于某一個 value vi?v_i^\ellvi?? 的預測結果?
?i:top(vi?)=top(y?)\exist i:top(v_i^\ell) = top(y^\ell) ?i:top(vi??)=top(y?)- 如果是,那就說明某個 memory 完全主導了預測。
-
實驗結果:在網絡的任意層中,至少 68% 的預測和所有單個 memory 的預測都不一致。即:
-
模型在大多數情況下,不會只依賴某個記憶單元來做預測
-
而是將多個 memory 組合起來,產生了一個新分布
-
這就是組合式預測
-
-
補充分析:如果有單個memory的輸出匹配,是為什么?
-
在少數情況下,某個 memory cell 的預測正好是整層的預測,作者進一步分析這些例子:
-
60% 的預測是停用詞(例如 “the”, “of”)
-
43% 的輸入前綴很短(少于 5 個詞)
-
-
觀點:
-
這些常見模式可能導致模型用某個 memory “緩存”了它們(類似緩存/記憶)
-
因此對這些簡單情況,不需要多個 memory 組合,單個 memory 就能給出準確預測
-
-
-
5.2 跨層預測改善
-
模型的前饋計算路徑和殘差機制
x?=LayerNorm(r?)y?=FF(x?)o?=y?+r?x^\ell = LayerNorm(r^\ell)\\ y^\ell =FF(x^\ell)\\ o^\ell = y^\ell + r^\ell x?=LayerNorm(r?)y?=FF(x?)o?=y?+r?-
r?r^\ellr?:來自前一層的殘差向量
-
這些步驟說明:每一層并不會獨立做決策,而是將上一層的“意見”作為基礎,再進一步調整。
-
-
核心假設
- 模型通過層層殘差連接形成了一種逐層精化預測的機制
- 早期層已經做出了部分決策,后續層只是慢慢地調整這些決策。
5.2.1 哪一層就已經決定了最終輸出?
-
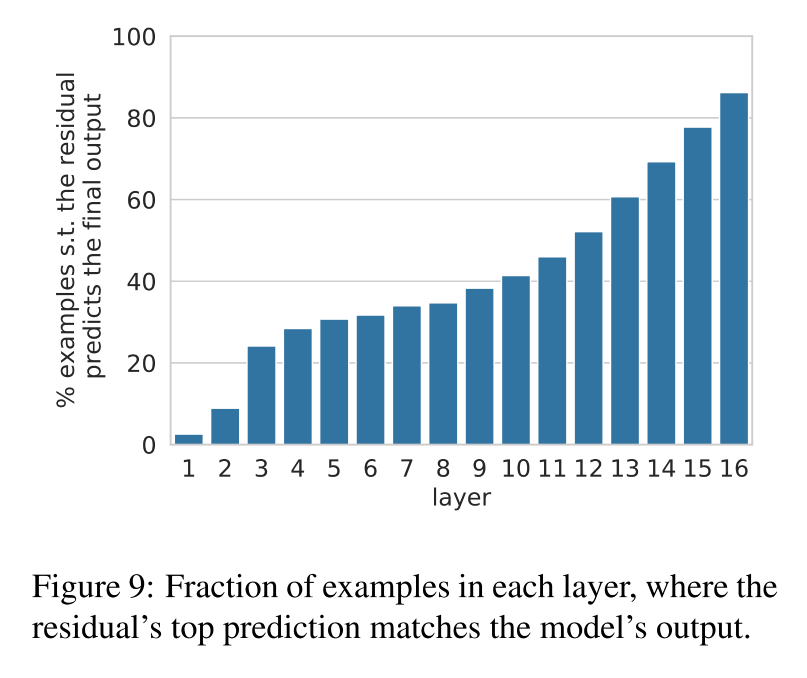
實驗設計:對每一層 r?r^\ellr?,檢查它是否已經能預測出最終模型輸出 oLo^LoL
top(r?)=top(oL)top(r^\ell) = top(o^L) top(r?)=top(oL) -
結果:
-
大約有三分之一的預測,早在底層(尤其是第10層之前)就已經確定了
-
從第10層開始,這個比例迅速上升
-
-
說明:
-
許多明確的預測在中層甚至底層就已經形成了
-
上層更多在進行微調,而非決定性預測
-
5.2.2 每一層對最終預測的置信度是怎么變化的?
-
實驗設計
-
拿當前層的殘差 r?r^\ellr?
-
對它做 softmax,得到詞表分布 ppp
-
查看它對最終預測詞 w=top(oL)w = top(o^L)w=top(oL) 的概率是多少
p=softmax(r??E)pw=p[w]p = softmax(r^\ell · E) \\ p_w = p[w] p=softmax(r??E)pw?=p[w]
-
-
結果:殘差對最終預測的信心是逐層增強的
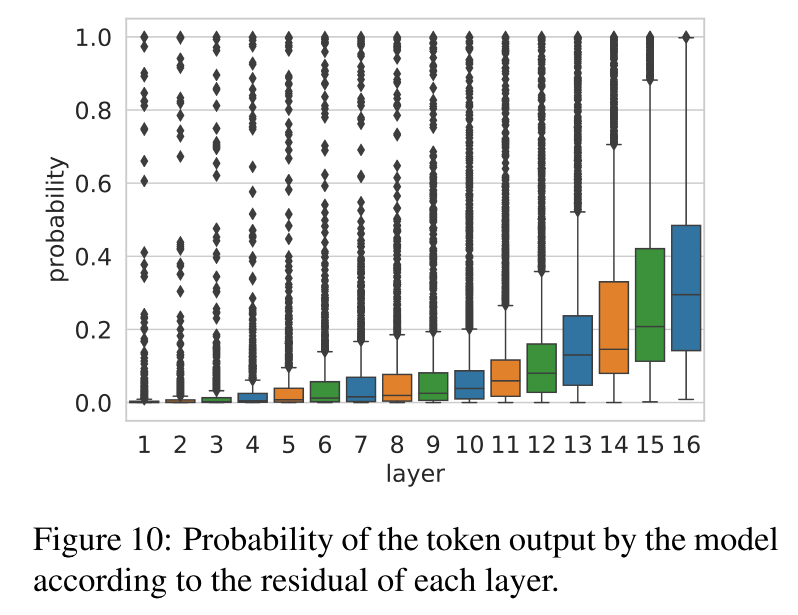
- 模型逐層在收斂意見,越來越肯定這個預測是對的。
5.2.3 前饋層到底對殘差做了什么事?
-
實驗設計:檢查三種情況,是哪個導致了輸出的變化
-
top(r?)top(r^\ell)top(r?):殘差原本的預測
-
top(y?)top(y^\ell)top(y?):前饋網絡本層的預測
-
top(o?)top(o^\ell)top(o?):這兩者相加之后的最終輸出
-
-
三種交互類型:
類型 條件 意義 residual + agreement top(o?)=top(r?)top(o^\ell) = top(r^\ell)top(o?)=top(r?) 前饋網絡只是支持了殘差的判斷,沒有改變它 ffn override KaTeX parse error: Undefined control sequence: \and at position 27: … = top(y^\ell) \?a?n?d? ?top(o^\ell) \ne… 前饋層強勢改變了殘差的預測 composition top(o?)≠top(y?)≠top(r?)top(o^\ell) \neq top(y^\ell) \neq top(r^\ell)top(o?)=top(y?)=top(r?) 輸出是殘差和前饋的折中 -
結果:
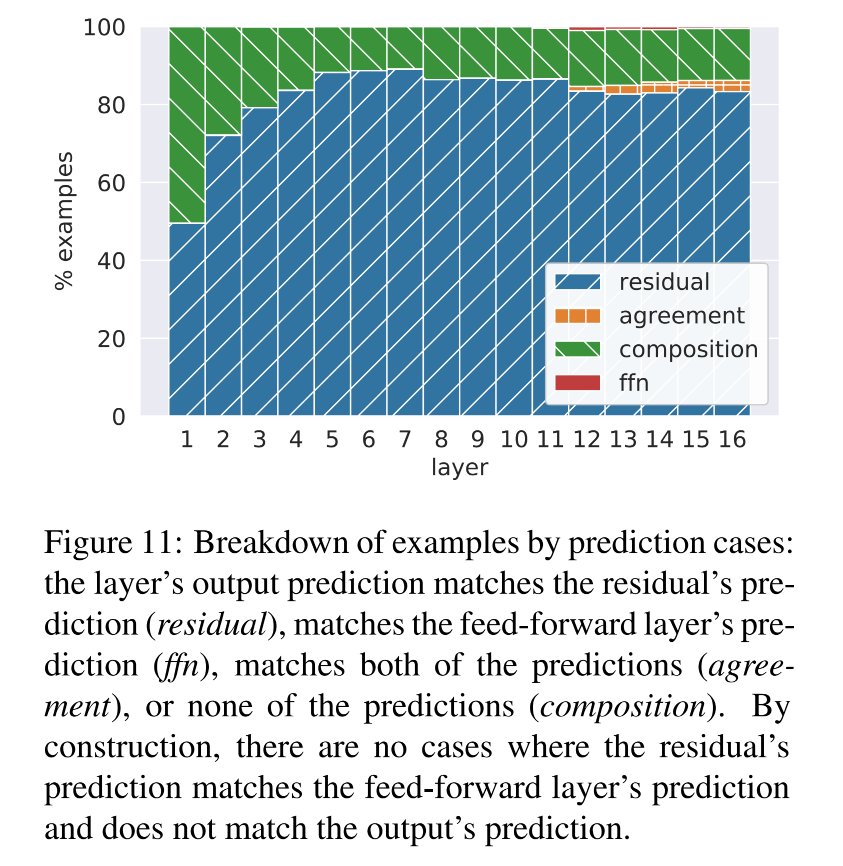
-
絕大多數時候,最終輸出等于殘差預測(residual+agreement)
-
只有極少數情況下是前饋預測主導(ffn override)
-
有一定比例是二者的組合(composition)
-
-
結論:FFN 并不是直接替代殘差預測,而是作為一種權重再分布機制,對殘差輸出進行修正或微調。
- 現象:當前層的最終預測往往既不是殘差向量的預測結果,也不是前饋層的預測結果,而是介于兩者之間的折中預測
- 猜測:前饋層有時會對 residual 中 top1 的token投否決票,從而把注意力引向其他候選詞。
- 現象:當前層的最終預測往往既不是殘差向量的預測結果,也不是前饋層的預測結果,而是介于兩者之間的折中預測
5.2.4 最后一層的改動是否有意義的?
-
人工看了 100 個最后一層中 FFN 改變殘差預測的例子,發現:
-
66 個案例是語義上較遠的跳變:
- 例如:“people” → “same”
-
34 個案例是語義相近的微調:
- 例如:“later” → “earlier”、“gastric” → “stomach”
-
-
即使在最后一層,前饋層仍然可以細調預測,表現出對語義的精細掌控能力。
6. 相關工作
-
神經元功能分析
-
研究者通過分析單個神經元或神經元群體的激活情況,理解它們捕捉了哪些語言現象
-
這些工作與模型架構無關,關注的是“神經元是否編碼了語法、語義、世界知識等”。
-
-
卷積模型中的模式提取
-
Jacovi 分析了 CNN 在文本分類任務中,發現其能自動提取關鍵的 n-gram 模式。
-
與本論文類似,也是尋找網絡中自動學習到的可解釋模式。
-
-
Transformer 中的自注意力研究
-
大量研究聚焦在 Transformer 的 self-attention 層的功能和可解釋性
-
也有一些研究探索 不同層級之間的功能差異
-
-
前饋層的研究仍然稀缺
- 有少量論文提到 FFN可能具有獨立重要性:
- 但 它們都沒有系統性地刻畫 FFN 的機制,因此本論文填補了這一空白。



)

回文鏈表)





)







