線程池的狀態?
回答:running->shutdown->stop->tidyng->TERMINATED
線程池狀態怎么流轉2.
回答:變成shutdown,執行shutdown()函數變成stop,執行shutdownnow函數
變成tining,所有任務已處理完
變成TERMINATED,線程池調結束
RUNNING | 接收新任務,處理隊列中的任務 |
SHUTDOWN | 不接受新任務,但繼續處理隊列中已有的任務 |
STOP | 不接受新任務,不處理隊列中的任務,中斷正在執行的任務 |
TIDYING | 所有任務都已終止,工作線程數量為0,即將執行?terminated()?鉤子方法 |
TERMINATED |
|
線程狀態的流轉3.
回答:新建狀態(New)線程對象被創建后
阻塞狀態(Blocked):等待監視器鎖。
等待狀態(Waiting)。等待另外一個線程的特定操作
超時等待(timed waiting)。等待特定的時間
運行狀態(Running):線程獲取CPU權限進行執行。需要注意的是,線程只能從就緒狀態進入到運行狀態。
死亡狀態(Dead):線程執行完了或者因異常退出了run()方法,該線程結束生命周期。
NEW:當前 Thread 對象雖然有了,但是內核的線程還沒有(還沒調用 start)
TERMINATED:當前 Thread 對象雖然還在,但是內核的線程已經銷毀了(線程已經結束了)
RUNNABLE:就緒狀態,正在 cpu 上運行 或 隨時可以去 cpu 上運行
BLOCKED:因為 鎖競爭 引起的阻塞
TIMED_WAITNG:有超時時間的等待,比如 sleep 或者 join 帶參數版本
WAITING:沒有超時時間的等待 join /wait
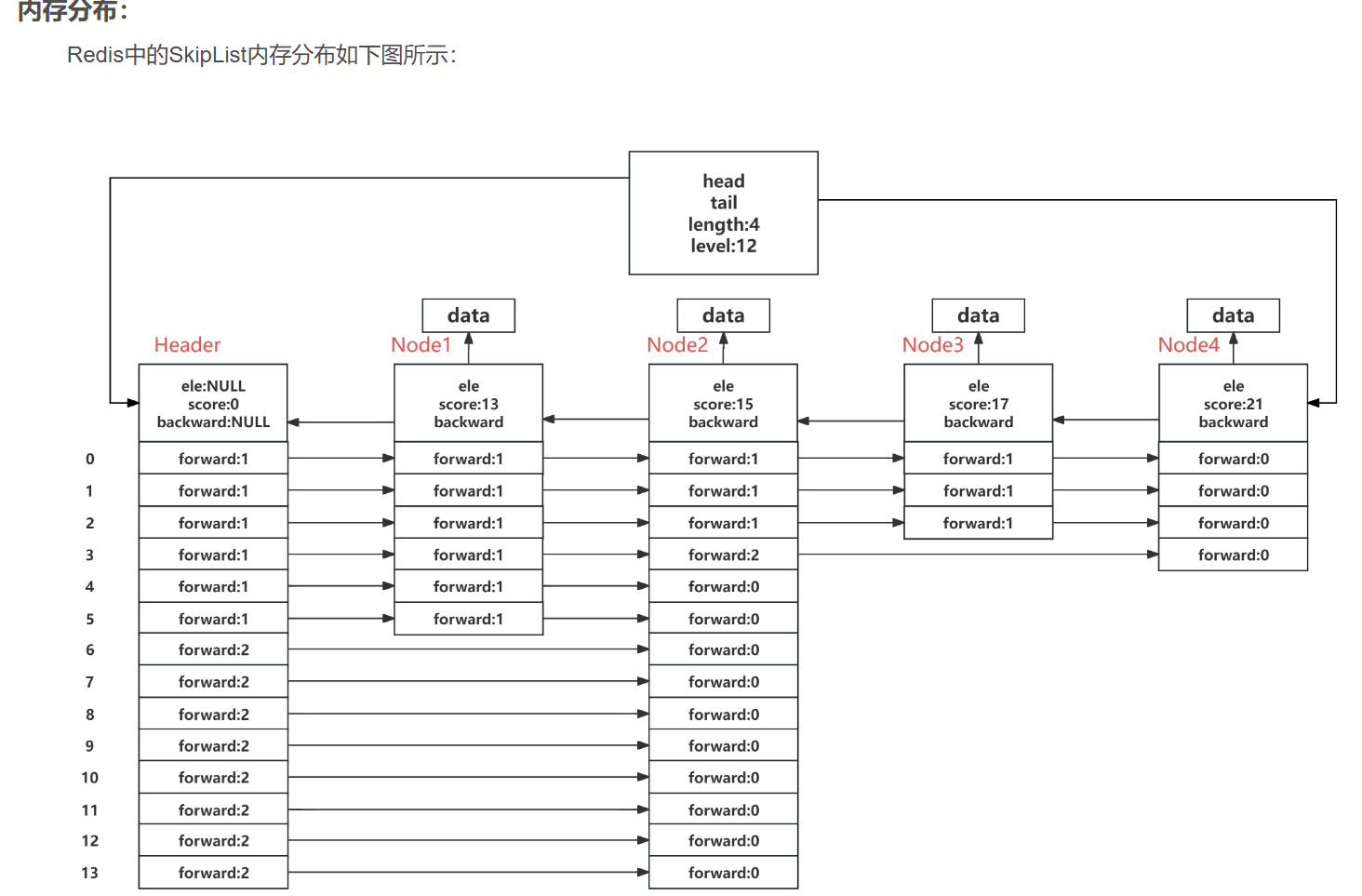
.講-下Redis跳表的數據結構
// 簡化版 C 結構體(來自 Redis 源碼)
typedef struct zskiplistNode {sds ele; // 學生名字,比如 "xiaohong"double score; // 分數,比如 90.0struct zskiplistNode *backward; // ← 向后指針(用于倒著走)// 多層索引結構(每個節點有自己的層數)struct zskiplistLevel {struct zskiplistNode *forward; // → 向前指針unsigned int span; // 這一跳跨過了幾個節點} level[];
} zskiplistNode;ele | 存儲成員名(Redis 用?sds?是它自己的字符串類型) |
score | 排序依據,按分數從小到大排 |
backward | 指向前一個節點,實現?ZREVRANGE?倒序遍歷 |
level[].forward | 每一層的“快車道”指針 |
level[].span | 記錄這一跳跳過了多少個底層節點(用于算排名) |
typedef struct zskiplist {struct zskiplistNode *header; // 頭節點(不存真實數據)struct zskiplistNode *tail; // 尾節點(最后一個真實節點)unsigned long length; // 當前有多少個真實節點int level; // 所有節點中最高的層數
} zskiplist;📌 想象這是一個“地鐵控制中心”:
header:總站,所有線路從這里出發tail:終點站,方便快速找到最后一個人length:當前排行榜上有多少人level:目前最高有幾條快車道(Level 0 ~ Level N)
IO多路復用
LINUX有哪些IO機制、select poll epoll,底層實現等等
BIO NIO等。
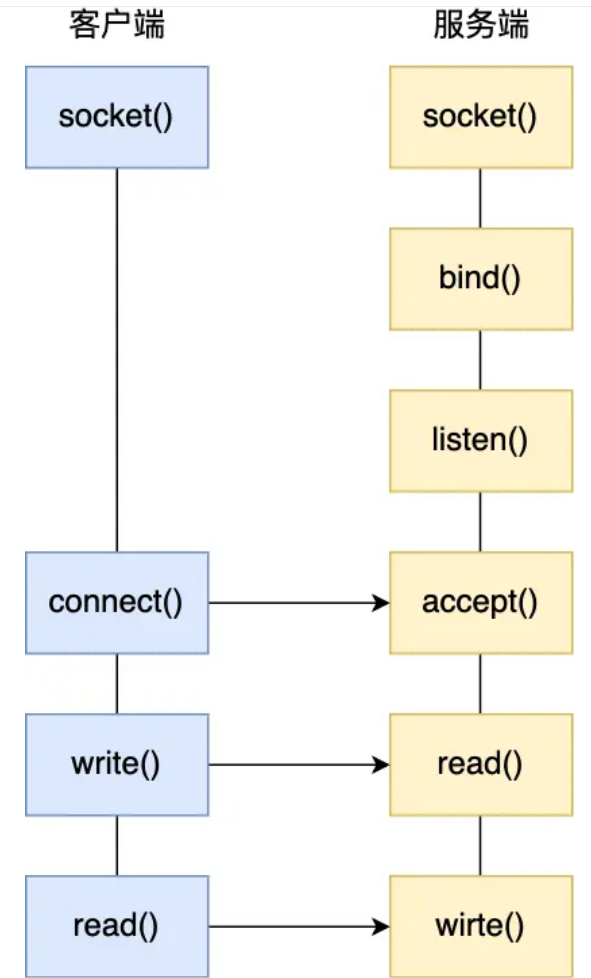
最基礎的 TCP 的 Socket 編程,它是阻塞 1/0 模型,基本上只能一對一通信,那為了服務更多的客戶端,我們需要改進網絡 I/O 模型。
比較傳統的方式是使用多進程/線程模型,每來一個客戶端連接,就分配一個進程/線程,然后后續的讀寫都在對應的進程/線程,這種方式處理 100 個客戶端沒問題,但是當客戶端增大到 10000 個時,10000 個進程/線程的調度、上下文切換以及它們占用的內存,都會成為瓶頸。
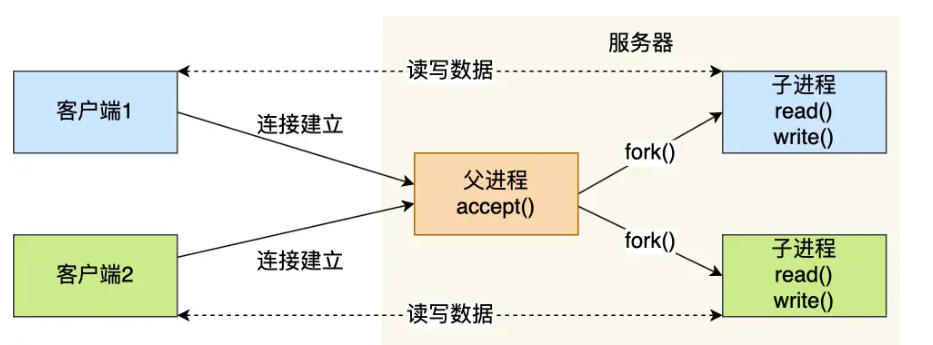
服務器的主進程負責監聽客戶的連接,一旦與客戶端連接完成,accept0 函數就會返回一個「已連接Socket」,這時就通過 fork()函數創建一個子進程,實際上就把父進程所有相關的東西都復制一份,包括文件描述符、內存地址空間、程序計數器、執行的代碼等。
當服務器與客戶端 TCP 完成連接后,通過 pthread_create()函數創建線程,然后將「已連接 Socket」的文件描述符傳遞給線程函數,接著在線程里和客戶端進行通信,從而達到并發處理的目的。我們可以使用線程池的方式來避免線程的頻繁創建和銷毀,所謂的線程池,就是提前創建若干個線程,這樣當由新連接建立時,將這個已連接的 Socket 放入到一個隊列里,然后線程池里的線程負責從隊列中取出「已連接 Socket 」進行處理。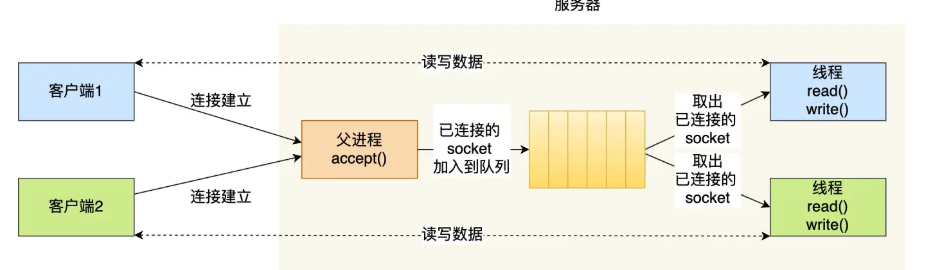
為了解決上面這個問題,就出現了 !/0 的多路復用,可以只在一個進程里處理多個文件的 10,linux 下有三種提供 /O 多路復用的 API,分別是:select、poll、epoll。
select 和 poll 并沒有本質區別,
select 使用固定長度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的個數是有限制的,在Linux 系統中,由內核中的 FD SETSIZE 限制, 默認最大值為 1024 ,只能監聽 0~1023 的文件描述符。
poll 不再用 BitsMap 來存儲所關注的文件描述符,取而代之用動態數組,以鏈表形式來組織,突破了select 的文件描述符個數限制,當然還會受到系統文件描述符限制。
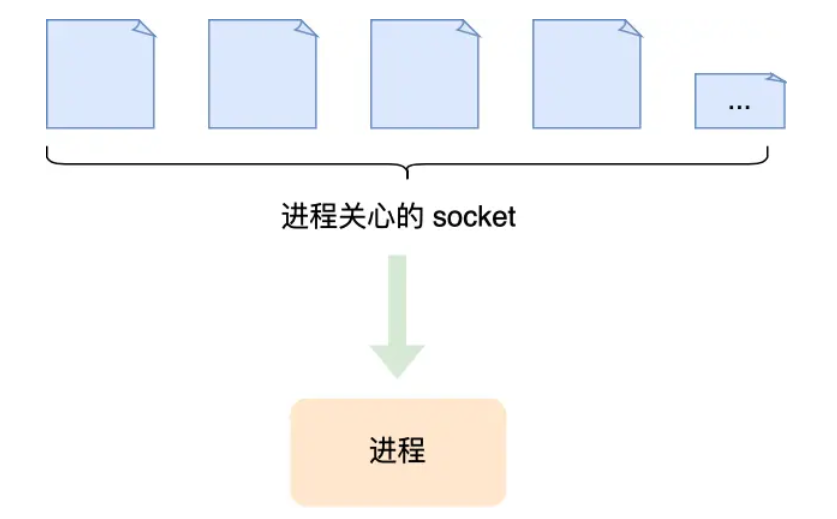
它們內部都是使用「線性結構」來存儲進程關注的 Socket 集合。
在使用的時候,首先需要把關注的 Socket 集合通過 select/poll 系統調用從用戶態拷貝到內核態,然后由內核檢測事件,當有網絡事件產生時,內核需要遍歷進程關注 Socket 集合,找到對應的 Socket,并設置其狀態為可讀/可寫,然后把整個 Socket 集合從內核態拷貝到用戶態,用戶態還要繼續遍歷整個 Socket集合找到可讀/可寫的 Socket,然后對其處理。
很明顯發現,select和 pol 的缺陷在于,當客戶端越多,也就是 Socket 集合越大,Socket 集合的遍歷和拷貝會帶來很大的開銷,因此也很難應對 C10K。
epoll 是解決 C10K 問題的利器,通過兩個方面解決了 select/poll 的問題。
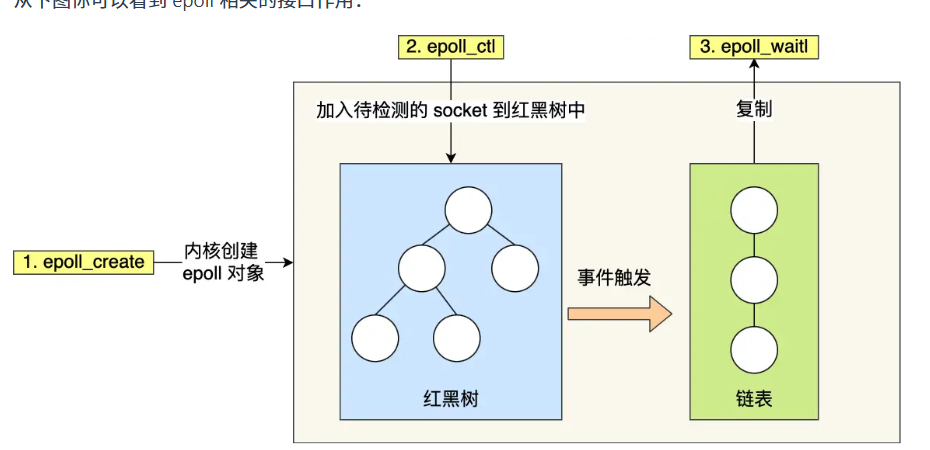
·epoll 在內核里使用「紅黑樹」來關注進程所有待檢測的 Socket,紅黑樹是個高效的數據結構,增刪改-般時間復雜度是 O(logn),通過對這棵黑紅樹的管理,不需要像 select/poll 在每次操作時都傳入整個Socket 集合,減少了內核和用戶空間大量的數據拷貝和內存分配。
epoll 使用事件驅動的機制,內核里維護了一個「鏈表」來記錄就緒事件,只將有事件發生的 Socket 集合傳遞給應用程序,不需要像 select/poll 那樣輪詢掃描整個集合(包含有和無事件的 Socket),大大提高了檢測的效率。
而且,epo 支持邊緣觸發和水平觸發的方式,而 select/poll 只支持水平觸發,一般而言,邊緣觸發的方式會比水平觸發的效率高
這兩個術語還挺抽象的,其實它們的區別還是很好理解的。
使用邊緣觸發模式時,當被監控的 Socket 描述符上有可讀事件發生時,服務器端只會從 epoll wait 中蘇醒一次,即使進程沒有調用 read 函數從內核讀取數據,也依然只蘇醒一次,因此我們程序要保證-次性將內核緩沖區的數據讀取完;
使用水平觸發模式時,當被監控的 Socket 上有可讀事件發生時,服務器端不斷地從 epoll wait 中蘇醒,直到內核緩沖區數據被 read 函數讀完才結束,目的是告訴我們有數據需要讀取;
索引失效的場景有哪些,你知道什么改進方法嗎
我們查詢語句對索引字段進行左模糊匹配、表達式計算、函數、隱式類型轉換操作,或者聯合索引沒有遵循最左匹配原則,這時候查詢語句就無法走索引了
java版本改動問題 1.7 1.8有哪些主要區別
Java 7新特性:鉆石操作符,try-with-resource 語句、支持動態類型語言、Fork/Join 框架等。
Java8新特性:Lambda 表達式、Stream API、新的Date/Time API、 NashornJavaScript 引|擎等。如何找到需要回收的垃圾、引用等等
- Java 8: 提供了Optional類來避免空指針異常,它是一個容器類,代表一個值存在或不存在的情況。
- Java 7: 需要手動檢查對象是否為null,并進行相應的處理。
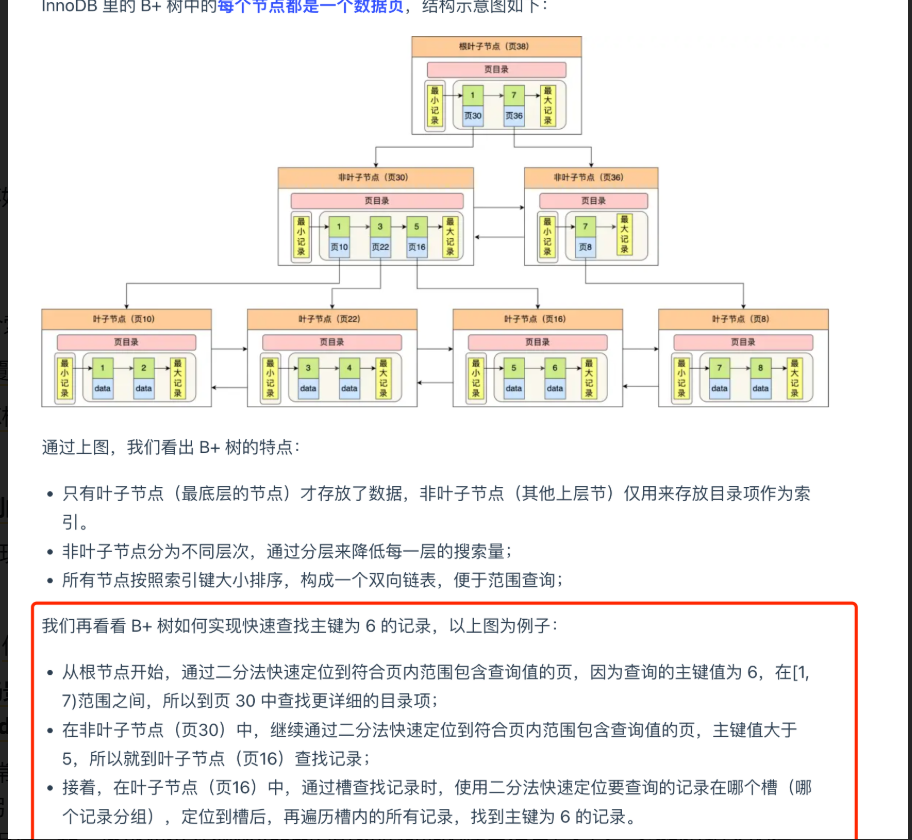
整個索引查詢的過程是怎樣的、













)





