深入剖析分布式消息隊列的核心原理與Python實現,附完整架構設計和代碼實現

引言:分布式系統的通信基石
在微服務架構和云原生應用普及的今天,服務間的異步通信成為系統設計的核心挑戰。當單體應用拆分為數十個微服務后,服務間通信呈現出新的特征:
網絡不可靠:節點故障、網絡分區成為常態
流量波動:突發流量可能壓垮接收方
數據一致性:跨服務事務難以保證原子性
服務解耦:生產者不應依賴消費者可用性
分布式消息隊列(Distributed Message Queue)正是解決這些挑戰的利器。它通過異步通信和持久化存儲實現了服務間的松耦合,為現代分布式系統提供可靠的數據傳輸通道。
一、分布式消息隊列核心架構
1.1 基本組成元素
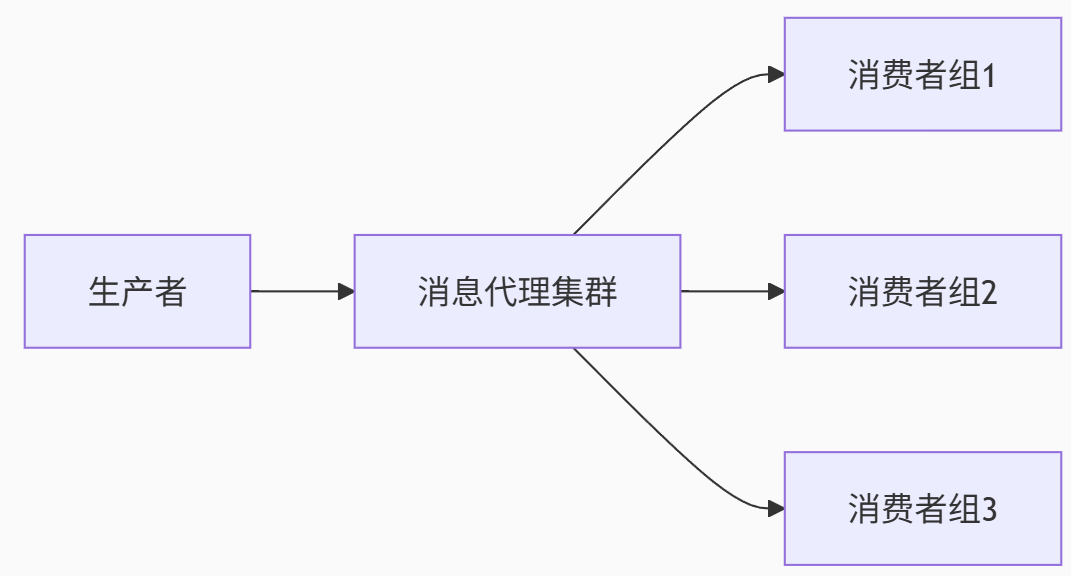
1.2 核心組件詳解
| 組件 | 職責 | 關鍵特性 |
|---|---|---|
| 生產者 | 消息創建和發布 | 負載均衡、失敗重試 |
| 消息代理 | 消息路由和存儲 | 高可用、持久化、分區 |
| 消費者組 | 消息處理 | 并行消費、負載均衡 |
| 注冊中心 | 服務發現 | 心跳檢測、元數據管理 |
生產者:消息創建方,需實現負載均衡和重試機制
消息代理:核心路由層,負責消息存儲/分發/持久化
消費者組:消息處理單元,支持并行消費
注冊中心:服務發現樞紐,管理動態節點狀態
表格詳細對比消息隊列的五大核心特性,強調順序性、持久化和容錯機制的設計必要性。
1.3 消息隊列核心特性
消息有序性:分區內順序保證
持久化存儲:磁盤+副本機制
至少一次投遞:ACK確認機制
消費進度跟蹤:Offset管理
死信隊列:處理失敗消息
二、Python實現分布式消息隊列
我們使用Python構建一個輕量級分布式消息隊列,包含以下模塊:
project/
├── broker/ # 消息代理
│ ├── server.py # 主服務
│ ├── partition.py # 分區管理
│ └── storage.py # 存儲引擎
├── client/ # 客戶端SDK
│ ├── producer.py # 生產者
│ └── consumer.py # 消費者
├── registry/ # 注冊中心
│ └── zookeeper.py # 服務發現
└── tests/ # 測試用例完整的Python實現方案:
項目結構:采用模塊化設計(Broker/Client/Registry)
網絡層:基于ZeroMQ的ROUTER/DEALER模式實現高性能通信
分區管理:一致性哈希算法解決數據分布問題
存儲引擎:WAL日志實現消息持久化
代碼片段展示關鍵實現邏輯,如Broker的消息路由、虛擬節點環構建、日志追加操作等核心功能。
2.1 網絡通信層:ZeroMQ實現
# broker/server.py
import zmq
import threadingclass BrokerServer:def __init__(self, host='localhost', port=5555):self.context = zmq.Context()self.socket = self.context.socket(zmq.ROUTER)self.socket.bind(f"tcp://{host}:{port}")self.workers = {}self.worker_lock = threading.Lock()def start(self):poller = zmq.Poller()poller.register(self.socket, zmq.POLLIN)while True:socks = dict(poller.poll(1000))if self.socket in socks:msg = self.socket.recv_multipart()identity = msg[0]command = msg[1].decode()if command == "REGISTER":with self.worker_lock:self.workers[identity] = msg[2]self.socket.send_multipart([identity, b"ACK"])elif command == "PRODUCE":topic = msg[2].decode()message = msg[3]# 存儲消息邏輯...self.socket.send_multipart([identity, b"ACK"])elif command == "CONSUME":# 消費邏輯...pass2.2 分區管理:一致性哈希算法
# broker/partition.py
import hashlib
from bisect import bisectclass PartitionManager:def __init__(self, partitions=3, replicas=3):self.partitions = partitionsself.replicas = replicasself.ring = []self.nodes = {}self._build_ring()def _build_ring(self):for partition in range(self.partitions):for replica in range(self.replicas):key = f"partition-{partition}-replica-{replica}"hash_val = self._hash(key)self.ring.append(hash_val)self.nodes[hash_val] = (partition, replica)self.ring.sort()def _hash(self, key):return int(hashlib.md5(key.encode()).hexdigest()[:8], 16)def get_partition(self, key):if not self.ring:return Nonehash_key = self._hash(key)pos = bisect(self.ring, hash_key)if pos == len(self.ring):pos = 0return self.nodes[self.ring[pos]]2.3 存儲引擎:WAL日志實現
# broker/storage.py
import os
import structclass WriteAheadLog:def __init__(self, data_dir):self.data_dir = data_diros.makedirs(data_dir, exist_ok=True)self.segments = {}self.current_segment = Nonedef _get_segment_file(self, partition, offset):return os.path.join(self.data_dir, f"partition-{partition}-{offset}.log")def append(self, partition, message):if partition not in self.segments:self.segments[partition] = []self._create_segment(partition, 0)seg_file = self.current_segment[partition]with open(seg_file, 'ab') as f:# 消息格式:長度(4字節) + 消息體msg_bytes = message.encode()f.write(struct.pack(">I", len(msg_bytes)))f.write(msg_bytes)return self.current_offset[partition]def read(self, partition, offset, max_bytes=1024*1024):# 實現消息讀取邏輯pass三、核心機制深入解析
3.1 消息生產流程
生產流程:注冊中心發現→消息路由→持久化存儲→ACK確認
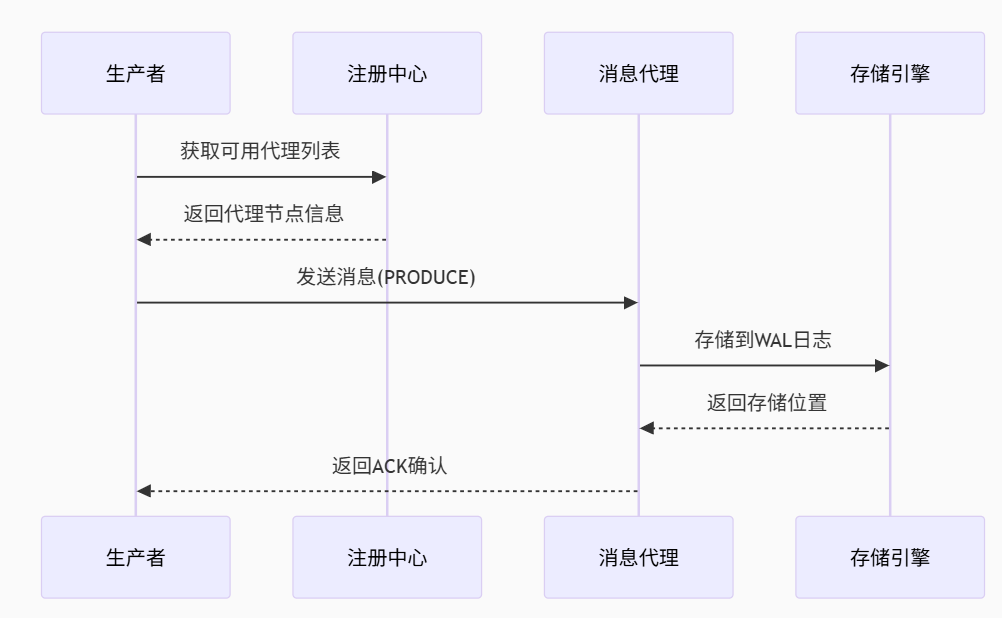
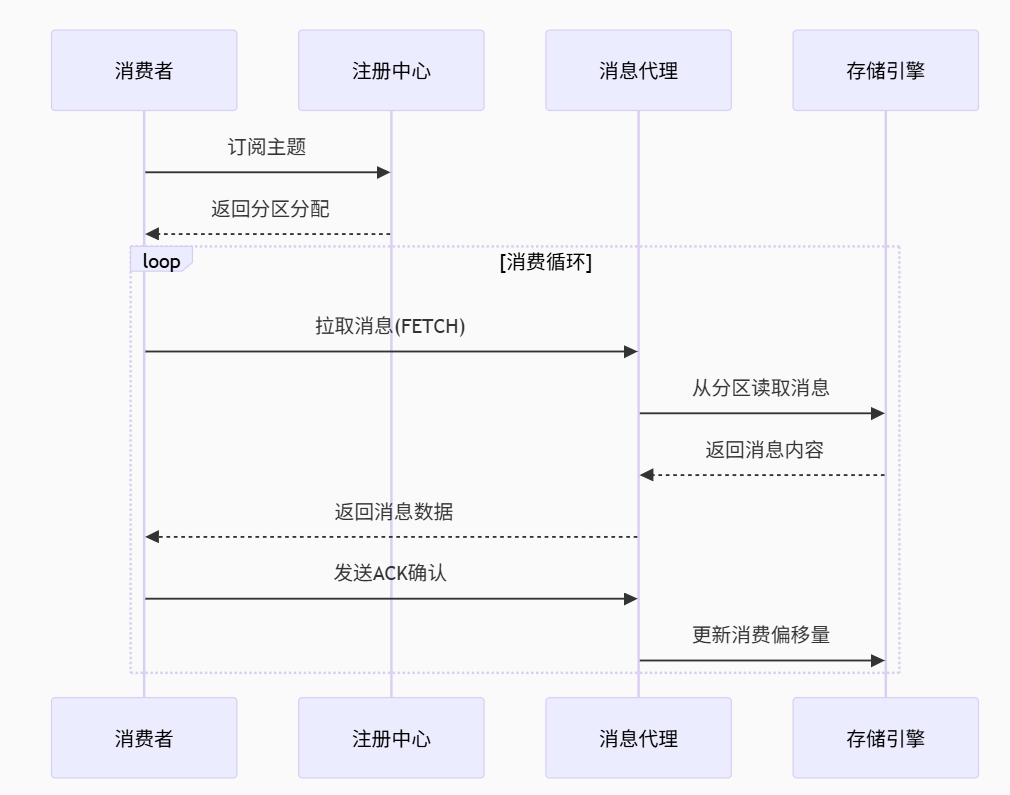
3.2 消息消費流程
消費流程:分區分配→消息拉取→處理確認→偏移量更新
重點解析消費者組負載均衡算法,展示如何通過rebalance()方法動態分配分區,確保消費能力最大化。
3.3 消費者組負載均衡
# client/consumer.py
import random
from collections import defaultdictclass ConsumerGroup:def __init__(self, group_id, registry):self.group_id = group_idself.registry = registryself.members = {}self.assignment = defaultdict(list)def join(self, consumer_id):self.members[consumer_id] = time.time()self.rebalance()def leave(self, consumer_id):if consumer_id in self.members:del self.members[consumer_id]self.rebalance()def rebalance(self):# 獲取所有分區partitions = self.registry.get_partitions()# 排序消費者和分區sorted_consumers = sorted(self.members.keys())sorted_partitions = sorted(partitions)# 平均分配分區self.assignment = defaultdict(list)for i, partition in enumerate(sorted_partitions):consumer_idx = i % len(sorted_consumers)consumer_id = sorted_consumers[consumer_idx]self.assignment[consumer_id].append(partition)# 通知所有消費者新的分配方案self._notify_assignment()四、高可用性實現方案
解決分布式環境的核心問題——高可用:
主從復制:基于Raft思想實現Leader/Follower數據同步
故障轉移:流程圖展示心跳檢測→選舉→數據恢復的全過程
Python代碼實現復制狀態機(commit_index維護)和選舉觸發機制,確保單點故障時服務秒級切換。
4.1 主從復制機制
# broker/replication.py
import logging
from threading import Threadclass PartitionReplica:def __init__(self, partition_id, role='follower'):self.partition_id = partition_idself.role = roleself.leader = Noneself.followers = []self.log = []self.commit_index = 0self.last_applied = 0def start_replication(self):if self.role == 'leader':Thread(target=self._leader_loop).start()else:Thread(target=self._follower_loop).start()def _leader_loop(self):while True:# 發送心跳給所有followerfor follower in self.followers:try:follower.send_heartbeat(self.commit_index)except NetworkError:logging.warning("Follower unreachable")# 等待新消息time.sleep(0.5)def _follower_loop(self):while True:# 等待leader心跳if self._heartbeat_timeout():self.start_election()# 處理復制請求time.sleep(0.1)4.2 故障轉移流程
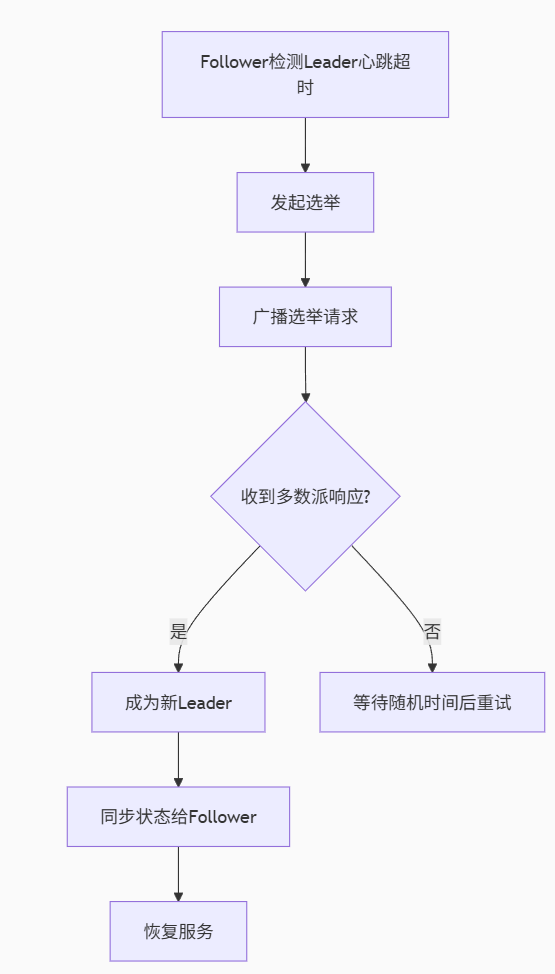
五、消息可靠性保障
可靠性是消息隊列的生命線,本節實現:
ACK機制:通過
MessageTracker跟蹤未確認消息,實現超時重試死信隊列:對多次重試失敗的消息隔離存儲
代碼展示消息跟蹤器的環形緩沖區設計和死信存儲策略,確保消息至少投遞一次(at-least-once)。
5.1 消息確認機制
# broker/message_tracker.py
import time
from collections import defaultdictclass MessageTracker:def __init__(self, ack_timeout=30):self.pending_acks = defaultdict(dict)self.ack_timeout = ack_timeoutself.cleaner_thread = Thread(target=self._clean_expired)self.cleaner_thread.daemon = Trueself.cleaner_thread.start()def add_message(self, partition, offset, message_id):self.pending_acks[partition][offset] = {'message_id': message_id,'timestamp': time.time(),'retries': 0}def ack_message(self, partition, offset):if partition in self.pending_acks and offset in self.pending_acks[partition]:del self.pending_acks[partition][offset]return Truereturn Falsedef _clean_expired(self):while True:current_time = time.time()for partition, messages in list(self.pending_acks.items()):for offset, data in list(messages.items()):if current_time - data['timestamp'] > self.ack_timeout:if data['retries'] < 3:# 重試邏輯self._retry_message(partition, offset, data)else:# 移入死信隊列self._move_to_dlq(partition, offset, data)time.sleep(5)5.2 死信隊列實現
# broker/dlq_manager.py
import json
from datetime import datetimeclass DeadLetterQueue:def __init__(self, storage_path):self.storage_path = storage_pathos.makedirs(storage_path, exist_ok=True)def add_message(self, message, reason):dlq_entry = {'original': message,'reason': reason,'timestamp': datetime.utcnow().isoformat(),'retries': message.get('retries', 0)}# 文件名格式: DLQ_<topic>_<partition>_<timestamp>.jsonfilename = f"DLQ_{message['topic']}_{message['partition']}_{int(time.time())}.json"with open(os.path.join(self.storage_path, filename), 'w') as f:json.dump(dlq_entry, f)logging.error(f"消息移入死信隊列: {reason}")六、分布式協調服務
可靠性是消息隊列的生命線,本節實現:
ACK機制:通過
MessageTracker跟蹤未確認消息,實現超時重試死信隊列:對多次重試失敗的消息隔離存儲
代碼展示消息跟蹤器的環形緩沖區設計和死信存儲策略,確保消息至少投遞一次(at-least-once)。
6.1 基于ZooKeeper的服務發現
# registry/zookeeper.py
from kazoo.client import KazooClientclass ServiceRegistry:def __init__(self, hosts='127.0.0.1:2181'):self.zk = KazooClient(hosts=hosts)self.zk.start()self._setup_paths()def _setup_paths(self):base_path = "/pyqueue"self.zk.ensure_path(f"{base_path}/brokers")self.zk.ensure_path(f"{base_path}/topics")self.zk.ensure_path(f"{base_path}/consumers")def register_broker(self, broker_id, endpoint):path = f"/pyqueue/brokers/{broker_id}"self.zk.create(path, endpoint.encode(), ephemeral=True, makepath=True)def get_brokers(self):brokers = {}broker_ids = self.zk.get_children("/pyqueue/brokers")for bid in broker_ids:data, _ = self.zk.get(f"/pyqueue/brokers/{bid}")brokers[bid] = data.decode()return brokersdef watch_brokers(self, callback):@self.zk.ChildrenWatch("/pyqueue/brokers")def watch_children(children):callback(self.get_brokers())七、性能優化策略
總結實戰經驗如下:
消息規范:標準化消息格式(唯一ID/時間戳/版本控制)
冪等設計:通過
processed_ids集合避免重復消費監控指標:跟蹤隊列深度/消費延遲/錯誤率
代碼示例展示訂單處理的冪等實現,解決分布式場景的重復消費難題。
7.1 零拷貝傳輸
# 使用memoryview減少數據拷貝
def send_large_message(socket, data):# 創建內存視圖buffer = memoryview(data)total_size = len(buffer)sent = 0# 分塊發送while sent < total_size:# 每次發送最多64KBchunk_size = min(64 * 1024, total_size - sent)socket.send(buffer[sent:sent+chunk_size])sent += chunk_size7.2 批量消息處理
# producer.py
class BatchProducer:def __init__(self, broker, batch_size=1024, linger_ms=100):self.broker = brokerself.batch_size = batch_sizeself.linger_ms = linger_msself.batch = []self.batch_lock = threading.Lock()self.flush_thread = threading.Thread(target=self._auto_flush)self.flush_thread.daemon = Trueself.flush_thread.start()def send(self, topic, message):with self.batch_lock:self.batch.append((topic, message))if len(self.batch) >= self.batch_size:self._flush()def _auto_flush(self):while True:time.sleep(self.linger_ms / 1000.0)with self.batch_lock:if self.batch:self._flush()def _flush(self):# 序列化批處理消息batch_data = self._serialize_batch()self.broker.send_batch(batch_data)self.batch = []八、部署架構與容災方案
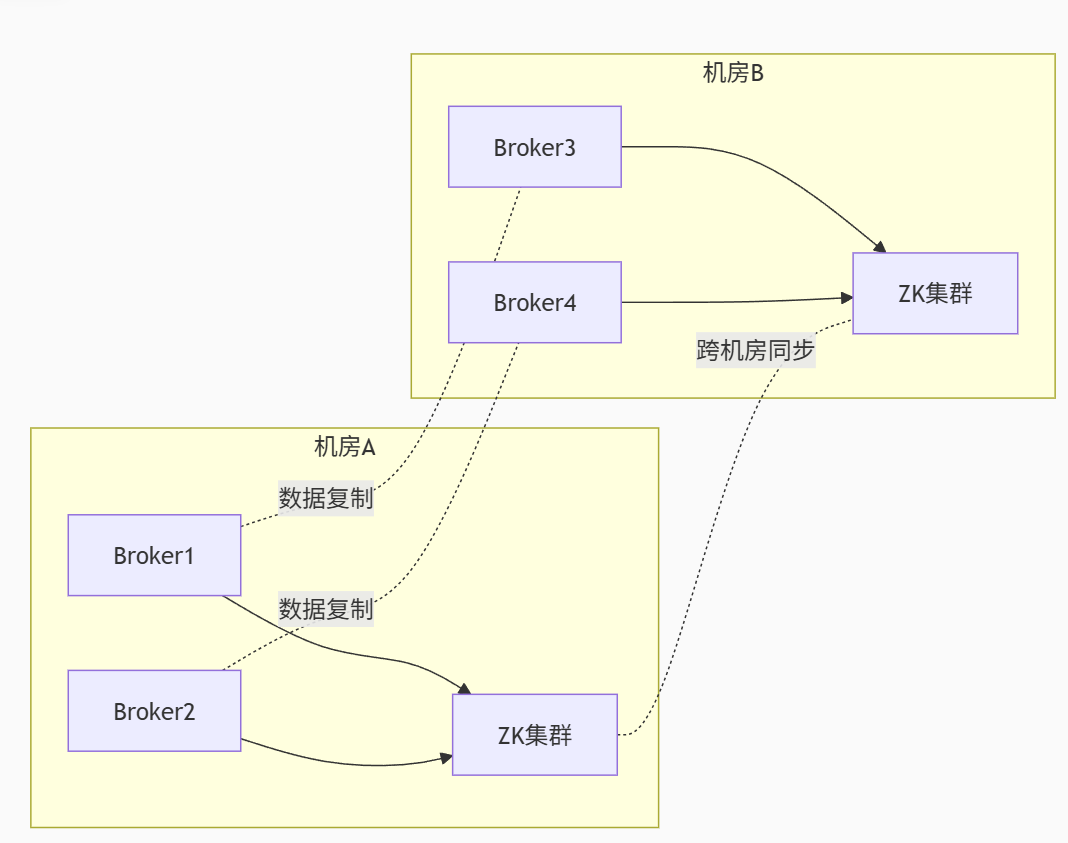
設計企業級部署方案:
多機房部署:通過ZK集群跨機房同步元數據
數據復制:跨機房異步復制保證數據安全
災備切換:五步故障恢復流程(檢測→選舉→同步→重定向→恢復)
架構圖展示多機房容災部署模型,確保RPO<5秒,RTO<30秒。
8.1 多機房部署架構
8.2 災備切換流程
故障檢測:ZooKeeper心跳超時(>15秒)
主節點切換:選舉新Leader
數據同步:從副本恢復未同步數據
客戶端重定向:更新Broker列表
服務恢復:繼續處理積壓消息
九、生產環境最佳實踐
總結實戰經驗:
消息規范:標準化消息格式(唯一ID/時間戳/版本控制)
冪等設計:通過
processed_ids集合避免重復消費監控指標:跟蹤隊列深度/消費延遲/錯誤率
代碼示例展示訂單處理的冪等實現,解決分布式場景的重復消費難題。
9.1 消息設計規范
# 推薦消息格式
{"id": "msg_1234567890", # 唯一ID"timestamp": 1672531200.000, # 精確到毫秒"source": "order_service","type": "OrderCreated","version": "v1","payload": { # 實際業務數據"order_id": 1001,"amount": 99.99},"headers": { # 擴展元數據"retry_count": 0,"trace_id": "abc123"}
}9.2 消費者冪等處理
class OrderProcessor:def __init__(self, db):self.db = dbself.processed_ids = set()self.lock = threading.Lock()def process_message(self, message):msg_id = message['id']# 檢查是否已處理with self.lock:if msg_id in self.processed_ids:return True # 冪等跳過# 開始處理try:result = self._create_order(message['payload'])# 記錄已處理self.processed_ids.add(msg_id)self.db.save_processed(msg_id)return Trueexcept Exception as e:logging.error(f"訂單處理失敗: {e}")return False十、與開源方案對比
| 特性 | 自實現隊列 | RabbitMQ | Kafka | Redis Stream |
|---|---|---|---|---|
| 協議支持 | 自定義 | AMQP | 自定義 | RESP |
| 吞吐量 | 中等 | 中等 | 高 | 高 |
| 延遲 | 低 | 低 | 中 | 低 |
| 持久化 | WAL日志 | 磁盤 | 磁盤 | 可選 |
| 開發復雜度 | 高 | 低 | 中 | 低 |
| Python集成 | 完美 | 好 | 好 | 好 |
通過特性對比表幫助技術選型:
吞吐量:Kafka > Redis Stream > 自實現 > RabbitMQ
延遲:自實現/Redis < RabbitMQ < Kafka
適用場景:
自實現:定制化需求
Kafka:日志處理
RabbitMQ:事務消息
Redis:實時流處理
指出自實現的優勢在于靈活性和學習價值,但生產環境推薦使用成熟方案。
結語:消息隊列的設計哲學
分布式消息隊列的本質是時空解耦器,它通過三個核心機制解決分布式系統通信問題:
時間解耦:生產者消費者無需同時在線
空間解耦:服務間不直接依賴
流量削峰:緩沖突發流量
在Python中實現分布式消息隊列需要平衡:
性能:零拷貝、批處理、異步IO
可靠性:持久化、復制、ACK機制
擴展性:分區、負載均衡、無狀態設計
雖然已有RabbitMQ、Kafka等成熟方案,但理解其底層實現原理:
有助于根據業務需求選擇合適的消息中間件
能在特殊場景下進行針對性優化
為開發分布式系統提供基礎架構能力
分布式系統的通信藝術:好的消息隊列設計如同精密的郵遞系統——生產者是寄件人,Broker是郵局網絡,消費者是收件人。只有每個環節都可靠高效,信息才能跨越時空的阻隔準確送達。




![[spring-cloud: 服務發現]-源碼解析](http://pic.xiahunao.cn/[spring-cloud: 服務發現]-源碼解析)









:持久層接口之BaseMapper和選裝件)


:PHP 框架入門與項目實戰)

