目錄
條件構造器
QueryWrapper
UpdateWrapper
LambdaQueryWrapper
自定義SQL
基本用法
多表關聯
Service接口
CRUD
基本用法?
Lambda
批量新增
條件構造器
除了新增以外,修改、刪除、查詢的SQL語句都需要指定where條件。因此BaseMapper中提供的相關方法除了以id作為where條件以外,還支持更加復雜的where條件。
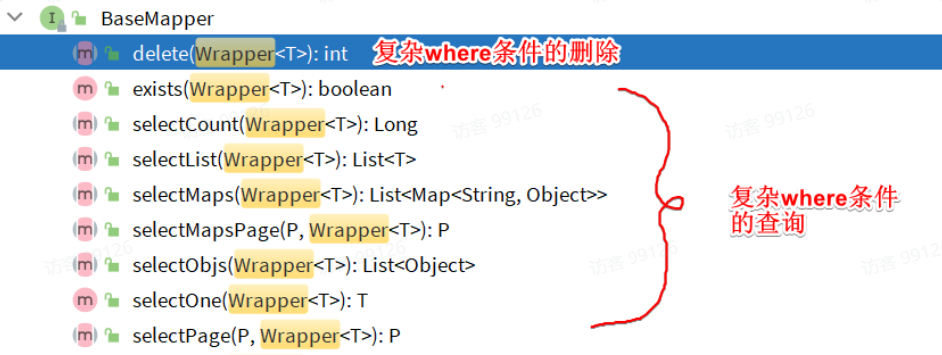
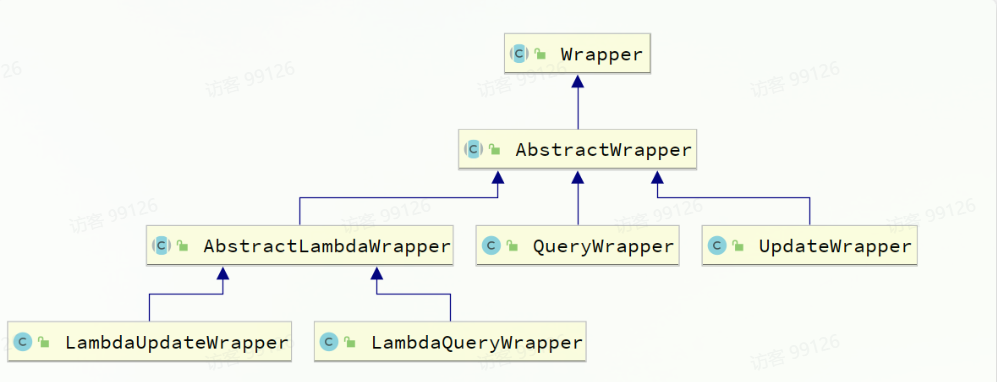
參數中的Wrapper就是條件構造的抽象類,其下有很多默認實現,繼承關系如圖:
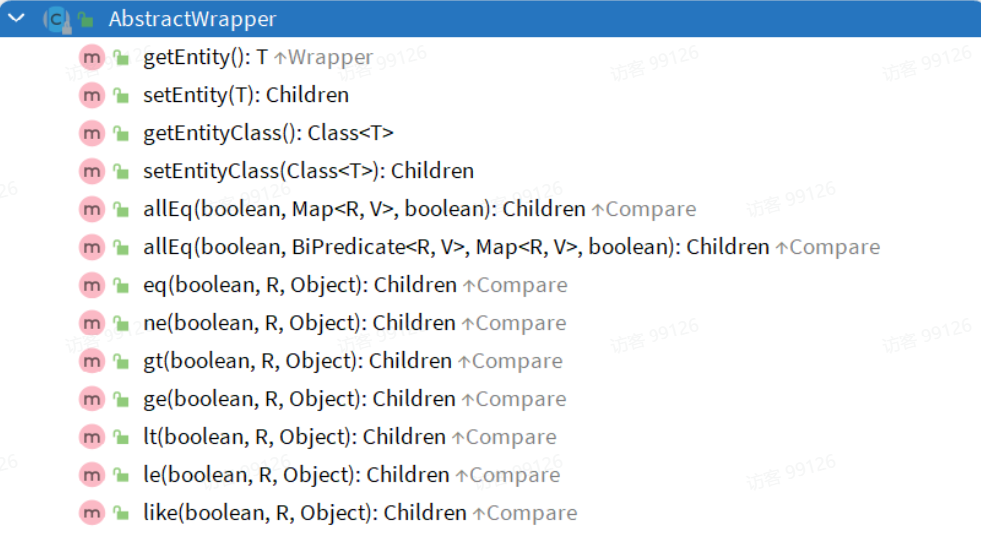
Wrapper的子類AbstractWrapper提供了where中包含的所有條件構造方法:
而QueryWrapper在AbstractWrapper的基礎上拓展了一個select方法,允許指定查詢字段:

而UpdateWrapper在AbstractWrapper的基礎上拓展了一個set方法,允許指定SQL中的SET部分:

接下來就利用Wrapper實現復雜查詢?。
QueryWrapper
無論是修改、刪除、查詢,都可以使用QueryWrapper來構建查詢條件。接下來看一些例子:
查詢:查詢出名字中帶o的,存款大于等于1000元的人。代碼如下:
@Test
void testQueryWrapper() {// 1.構建查詢條件 where name like "%o%" AND balance >= 1000QueryWrapper<User> wrapper = new QueryWrapper<User>().select("id", "username", "info", "balance").like("username", "o").ge("balance", 1000);// 2.查詢數據List<User> users = userMapper.selectList(wrapper);users.forEach(System.out::println);
}更新:更新用戶名為jack的用戶的余額為2000,代碼如下:
@Test
void testUpdateByQueryWrapper() {// 1.構建查詢條件 where name = "Jack"QueryWrapper<User> wrapper = new QueryWrapper<User>().eq("username", "Jack");// 2.更新數據,user中非null字段都會作為set語句User user = new User();user.setBalance(2000);userMapper.update(user, wrapper);
}UpdateWrapper
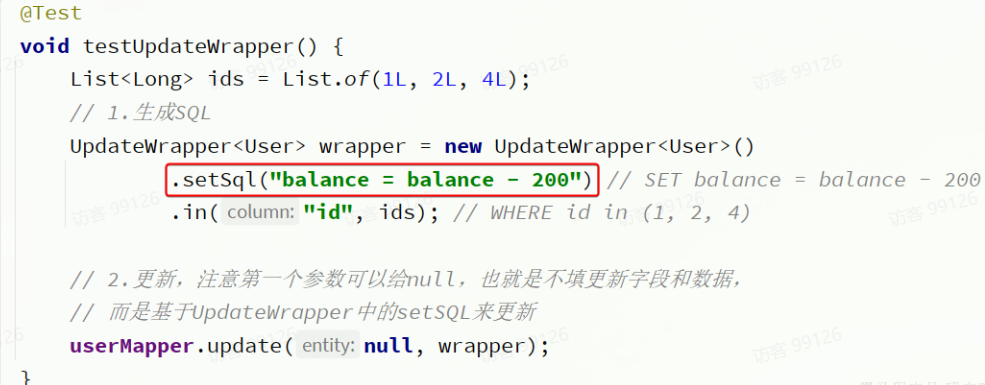
基于BaseMapper中的update方法更新時只能直接賦值,對于一些復雜的需求就難以實現。 例如:更新id為1,2,4的用戶的余額,扣200,對應的SQL應該是:
UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4)SET的賦值結果是基于字段現有值的,這個時候就要利用UpdateWrapper中的setSql功能了:
@Test
void testUpdateWrapper() {List<Long> ids = List.of(1L, 2L, 4L);// 1.生成SQLUpdateWrapper<User> wrapper = new UpdateWrapper<User>().setSql("balance = balance - 200") // SET balance = balance - 200.in("id", ids); // WHERE id in (1, 2, 4)// 2.更新,注意第一個參數可以給null,也就是不填更新字段和數據,// 而是基于UpdateWrapper中的setSQL來更新userMapper.update(null, wrapper);
}LambdaQueryWrapper
無論是QueryWrapper還是UpdateWrapper在構造條件的時候都需要寫死字段名稱,會出現字符串魔法值。這在編程規范中顯然是不推薦的。 那怎么樣才能不寫字段名,又能知道字段名呢?其中一種辦法是基于變量的gettter方法結合反射技術。因此我們只要將條件對應的字段的getter方法傳遞給MybatisPlus,它就能計算出對應的變量名了。而傳遞方法可以使用JDK8中的方法引用和Lambda表達式。 因此MybatisPlus又提供了一套基于Lambda的Wrapper,包含兩個:
-
LambdaQueryWrapper
-
LambdaUpdateWrapper
分別對應QueryWrapper和UpdateWrapper
其使用方式如下:
@Test
void testLambdaQueryWrapper() {// 1.構建條件 WHERE username LIKE "%o%" AND balance >= 1000QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.lambda().select(User::getId, User::getUsername, User::getInfo, User::getBalance).like(User::getUsername, "o").ge(User::getBalance, 1000);// 2.查詢List<User> users = userMapper.selectList(wrapper);users.forEach(System.out::println);
}自定義SQL

在演示UpdateWrapper的案例中,我們在代碼中編寫了更新的SQL語句:
這種寫法在某些企業也是不允許的,因為SQL語句最好都維護在持久層,而不是業務層。就當前案例來說,由于條件是in語句,只能將SQL寫在Mapper.xml文件,利用foreach來生成動態SQL。 這實在是太麻煩了。假如查詢條件更復雜,動態SQL的編寫也會更加復雜。所以,MybatisPlus提供了自定義SQL功能,可以讓我們利用Wrapper生成查詢條件,再結合Mapper.xml編寫SQL
基本用法
總結來說思路就是把wrapper傳到自定義的方法中,wrapper中的條件使用特殊占位符標在SQL注解中,并且方法參數要有@Param(“ew”),這里的ew只能叫ew,這是MP官方指定的字符串。
所以,剛剛的案例,即更新id為1,2,4的用戶的余額,進行扣處200元的操作,可以寫成如下:
@Test
void testCustomWrapper() {// 1.準備自定義查詢條件List<Long> ids = List.of(1L, 2L, 4L);QueryWrapper<User> wrapper = new QueryWrapper<User>().in("id", ids);// 2.調用mapper的自定義方法,直接傳遞WrapperuserMapper.deductBalanceByIds(200, wrapper);
}然后在UserMapper中自定義SQL:
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.itheima.mp.domain.po.User;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Update;
import org.apache.ibatis.annotations.Param;public interface UserMapper extends BaseMapper<User> {@Select("UPDATE user SET balance = balance - #{money} ${ew.customSqlSegment}")void deductBalanceByIds(@Param("money") int money, @Param("ew") QueryWrapper<User> wrapper);
}這樣就省去了編寫復雜查詢條件的煩惱了。
總結來說就是,在業務邏輯層中我們封裝好wrapper條件,然后以參數的形式在自定義的方法中傳遞到下游接口訪問層。需要注意的是,接口訪問層的屬性如果是wrapper及其子接口的話,需要用@Param("ew")進行標注,ew是MP官方的寫法,不可以取其他名字,只能是@Param("ew");或者可以將ew寫成MP封裝好的常量類,@Param(Constants.WRAPPER);如果是其他字段的話,直接點明上游傳來的屬性值即可(如上面的int類型的money,直接綁定為上游的money字段)。另外就是,{ew.customSqlSegment} 是一個動態拼接的 SQL 片段,它通常是通過 QueryWrapper 生成的條件語句,例如 WHERE id IN (1, 2, 3)。由于這個片段是一個字符串,且需要直接拼接到 SQL 語句中,因此使用 ${} 是合適的。這種自定義SQL+Wrapper的方式等于把where條件查詢封裝到Wrapper,其余的自己寫,然后在訪問方法的時候進行SQL語句的拼接。
這樣開發就省去了編寫復雜查詢條件的煩惱了。?
多表關聯
理論上來講MyBatisPlus是不支持多表查詢的,不過我們可以利用Wrapper中自定義條件結合自定義SQL來實現多表查詢的效果。 例如,我們要查詢出所有收貨地址在北京的并且用戶id在1、2、4之中的用戶 要是自己基于mybatis實現SQL,大概是這樣的:
<select id="queryUserByIdAndAddr" resultType="com.itheima.mp.domain.po.User">SELECT *FROM user uINNER JOIN address a ON u.id = a.user_idWHERE u.id<foreach collection="ids" separator="," item="id" open="IN (" close=")">#{id}</foreach>AND a.city = #{city}</select>可以看出其中最復雜的就是WHERE條件的編寫,如果業務復雜一些,這里的SQL會更變態。但是基于自定義SQL結合Wrapper的玩法,我們就可以利用Wrapper來構建查詢條件,然后手寫SELECT及FROM部分,實現多表查詢。
查詢條件這樣來構建:
@Test
void testCustomJoinWrapper() {// 1.準備自定義查詢條件QueryWrapper<User> wrapper = new QueryWrapper<User>().in("u.id", List.of(1L, 2L, 4L)).eq("a.city", "北京");// 2.調用mapper的自定義方法List<User> users = userMapper.queryUserByWrapper(wrapper);users.forEach(System.out::println);
}然后在UserMapper中自定義方法:
@Select("SELECT u.* FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}")
List<User> queryUserByWrapper(@Param("ew")QueryWrapper<User> wrapper);當然,也可以在UserMapper.xml中寫SQL:
<select id="queryUserByIdAndAddr" resultType="com.itheima.mp.domain.po.User">SELECT * FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}
</select>將上面的思路整理一下:
- 在業務邏輯層中,我們定義一個wrapper 對象,用來存儲我們SQL語句中的where子句里的條件,然后將其以參數的形式在外面自定義的方法中傳遞到我們的接口訪問層中進行處理。在這里,我們的寫法是u.id,a.city,指代用戶的id和地址的城市,這是因為我們在mapper里面定義了別名,"SELECT * FROM user u INNER JOIN address a ON u.id = a.user_id",wrapper是后面手寫sql語句的一部分,自然可以調用sql語句中的user表別名u。
- 在mapper接口訪問層中,對于wrapper的條件構造器對象,我們必須用QueryWrapper<T> wrapper類型的對象對wrapper進行接收,其中T是我們Java中的實體類對象,需要根據業務換成我們要操作的對象;另外,必須加上參數注解,@Param("ew")或者@Param(Constants.WRAPPER),這兩個的注解的作用是一樣的,任選其一即可(ew是MP指定的寫法,不可以換成其他名字,不然MP識別不了)。
- 在mapper的具體代碼上,我們通過${ew.customSqlSegment}")來替換SQL語句中的where子句,因為條件我們已經封裝到了wrapper當中,MP會拼接代碼,我們直接使用即可。
Service接口
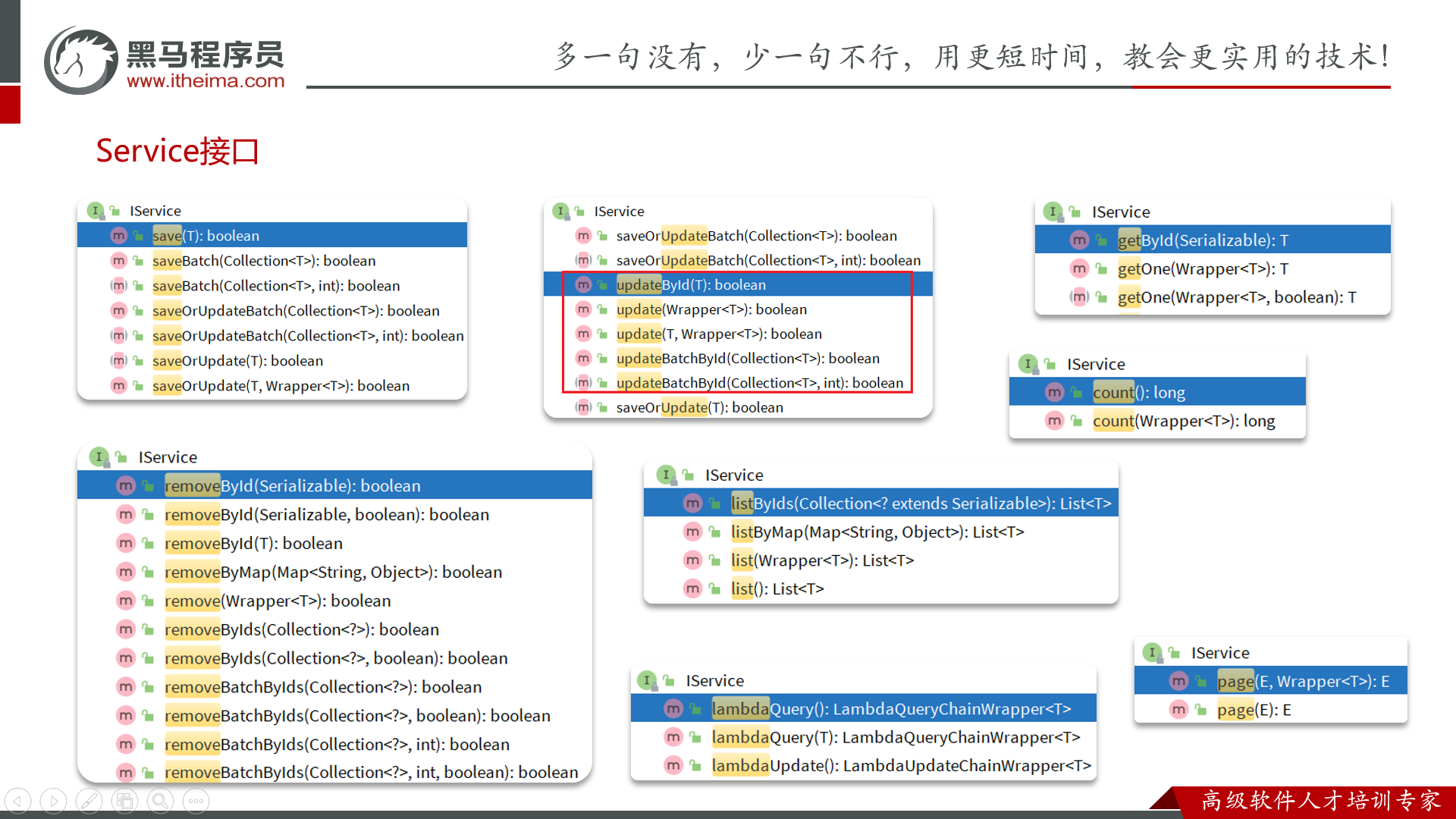
MybatisPlus不僅提供了BaseMapper,還提供了通用的Service接口及默認實現,封裝了一些常用的service模板方法。 通用接口為IService,默認實現為ServiceImpl,其中封裝的方法可以分為以下幾類:
-
save:新增 -
remove:刪除 -
update:更新 -
get:查詢單個結果 -
list:查詢集合結果 -
count:計數 -
page:分頁查詢
CRUD
我們先倆看下基本的CRUD接口。
新增:
-
save是新增單個元素 -
saveBatch是批量新增 -
saveOrUpdate是根據id判斷,如果數據存在就更新,不存在則新增 -
saveOrUpdateBatch是批量的新增或修改
刪除:?
-
removeById:根據id刪除 -
removeByIds:根據id批量刪除 -
removeByMap:根據Map中的鍵值對為條件刪除 -
remove(Wrapper<T>):根據Wrapper條件刪除 -
~~removeBatchByIds~~:暫不支持
修改:
-
updateById:根據id修改 -
update(Wrapper<T>):根據UpdateWrapper修改,Wrapper中包含set和where部分 -
update(T,Wrapper<T>):按照T內的數據修改與Wrapper匹配到的數據 -
updateBatchById:根據id批量修改
?Get:
-
getById:根據id查詢1條數據 -
getOne(Wrapper<T>):根據Wrapper查詢1條數據 -
getBaseMapper:獲取Service內的BaseMapper實現,某些時候需要直接調用Mapper內的自定義SQL時可以用這個方法獲取到Mapper
?List:
-
listByIds:根據id批量查詢 -
list(Wrapper<T>):根據Wrapper條件查詢多條數據 -
list():查詢所有
Count:
-
count():統計所有數量 -
count(Wrapper<T>):統計符合Wrapper條件的數據數量
getBaseMapper:
當我們在service中要調用Mapper中自定義SQL時,就必須獲取service對應的Mapper,就可以通過這個方法:

基本用法?
方法總覽(方法基本上見名知意,直接用就行):
由于Service中經常需要定義與業務有關的自定義方法,因此我們不能直接使用IService,而是自定義Service接口,然后繼承IService以拓展方法。同時,讓自定義的Service實現類繼承ServiceImpl,這樣就不用自己實現IService中的接口了。
首先,定義IUserService,繼承IService:
package com.itheima.mp.service;import com.baomidou.mybatisplus.extension.service.IService;
import com.itheima.mp.domain.po.User;public interface IUserService extends IService<User> {// 拓展自定義方法
}然后,編寫UserServiceImpl類,繼承ServiceImpl,實現UserService:
package com.itheima.mp.service.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.itheima.mp.domain.po.User;
import com.itheima.mp.domain.po.service.IUserService;
import com.itheima.mp.mapper.UserMapper;
import org.springframework.stereotype.Service;@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService {
}項目結構如下:
思路如下:

其中的泛型需要指定為自己項目的實體類和mapper接口名。?
至此,項目整合Service接口完成了,我們可以直接調用對應的方法來簡化開發。
Lambda
IService中還提供了Lambda功能來簡化我們的復雜查詢及更新功能。
案例一:實現一個根據復雜條件查詢用戶的接口,查詢條件如下:
-
name:用戶名關鍵字,可以為空
-
status:用戶狀態,可以為空
-
minBalance:最小余額,可以為空
-
maxBalance:最大余額,可以為空
可以理解成一個用戶的后臺管理界面,管理員可以自己選擇條件來篩選用戶,因此上述條件不一定存在,需要做判斷。我們首先需要定義一個查詢條件實體,UserQuery實體:
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;@Data
@ApiModel(description = "用戶查詢條件實體")
public class UserQuery {@ApiModelProperty("用戶名關鍵字")private String name;@ApiModelProperty("用戶狀態:1-正常,2-凍結")private Integer status;@ApiModelProperty("余額最小值")private Integer minBalance;@ApiModelProperty("余額最大值")private Integer maxBalance;
}其實這就是個DTO類,咋也不明白為啥不以DTO結尾,傳輸對象
接下來我們在UserController中定義一個controller方法:
@GetMapping("/list")
@ApiOperation("根據id集合查詢用戶")
public List<UserVO> queryUsers(UserQuery query){// 1.組織條件String username = query.getName();Integer status = query.getStatus();Integer minBalance = query.getMinBalance();Integer maxBalance = query.getMaxBalance();LambdaQueryWrapper<User> wrapper = new QueryWrapper<User>().lambda().like(username != null, User::getUsername, username).eq(status != null, User::getStatus, status).ge(minBalance != null, User::getBalance, minBalance).le(maxBalance != null, User::getBalance, maxBalance);// 2.查詢用戶List<User> users = userService.list(wrapper);// 3.處理voreturn BeanUtil.copyToList(users, UserVO.class);
}在這段代碼里,傳輸前面沒有加上@Requestbody注解,這是因為這個方法是get請求,請求參數是json格式的,因此可以不加注解。
在組織查詢條件的時候,我們加入了 username != null 這樣的參數,意思就是當條件成立時才會添加這個查詢條件,類似Mybatis的mapper.xml文件中的<if>標簽。這樣就實現了動態查詢條件效果了。不過,上述條件構建的代碼太麻煩了。 因此Service中對LambdaQueryWrapper和LambdaUpdateWrapper的用法進一步做了簡化。我們無需自己通過new的方式來創建Wrapper,而是直接調用lambdaQuery和lambdaUpdate方法:
基于Lambda查詢:
@GetMapping("/list")
@ApiOperation("根據id集合查詢用戶")
public List<UserVO> queryUsers(UserQuery query){// 1.組織條件String username = query.getName();Integer status = query.getStatus();Integer minBalance = query.getMinBalance();Integer maxBalance = query.getMaxBalance();// 2.查詢用戶List<User> users = userService.lambdaQuery().like(username != null, User::getUsername, username).eq(status != null, User::getStatus, status).ge(minBalance != null, User::getBalance, minBalance).le(maxBalance != null, User::getBalance, maxBalance).list();// 3.處理voreturn BeanUtil.copyToList(users, UserVO.class);
}可以發現lambdaQuery方法中除了可以構建條件,還需要在鏈式編程的最后添加一個list(),這是在告訴MP我們的調用結果需要是一個list集合。這里不僅可以用list(),可選的方法有:
-
.one():最多1個結果 -
.list():返回集合結果 -
.count():返回計數結果
MybatisPlus會根據鏈式編程的最后一個方法來判斷最終的返回結果。
與lambdaQuery方法類似,IService中的lambdaUpdate方法可以非常方便的實現復雜更新業務。
例如下面的需求:
需求:改造根據id修改用戶余額的接口,要求如下
如果扣減后余額為0,則將用戶status修改為凍結狀態(2)
也就是說我們在扣減用戶余額時,需要對用戶剩余余額做出判斷,如果發現剩余余額為0,則應該將status修改為2,這就是說update語句的set部分是動態的。
@Override
@Transactional
public void deductBalance(Long id, Integer money) {// 1.查詢用戶User user = getById(id);// 2.校驗用戶狀態if (user == null || user.getStatus() == 2) {throw new RuntimeException("用戶狀態異常!");}// 3.校驗余額是否充足if (user.getBalance() < money) {throw new RuntimeException("用戶余額不足!");}// 4.扣減余額 update tb_user set balance = balance - ?int remainBalance = user.getBalance() - money;lambdaUpdate().set(User::getBalance, remainBalance) // 更新余額.set(remainBalance == 0, User::getStatus, 2) // 動態判斷,是否更新status.eq(User::getId, id).eq(User::getBalance, user.getBalance()) // 樂觀鎖.update();
}set方法的第一個參數可以設置,表示只有滿足什么情況才會去執行該語句,如上代碼所示,表示只有當余額等于0的時候,才會將status設置為凍結狀態。需要注意的是,lambdaUpdate()方法只是構建條件,只有在最后加上類似于update()的方法,才會去執行語句。
批量新增
IService中的批量新增功能使用起來非常方便,但有一點注意事項,我們先來測試一下。 首先我們測試逐條插入數據:
@Test
void testSaveOneByOne() {long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {userService.save(buildUser(i));}long e = System.currentTimeMillis();System.out.println("耗時:" + (e - b));
}private User buildUser(int i) {User user = new User();user.setUsername("user_" + i);user.setPassword("123");user.setPhone("" + (18688190000L + i));user.setBalance(2000);user.setInfo("{\"age\": 24, \"intro\": \"英文老師\", \"gender\": \"female\"}");user.setCreateTime(LocalDateTime.now());user.setUpdateTime(user.getCreateTime());return user;
}執行結果如下:

可以看到速度非常慢。
然后再試試MybatisPlus的批處理:
@Test
void testSaveBatch() {// 準備10萬條數據List<User> list = new ArrayList<>(1000);long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {list.add(buildUser(i));// 每1000條批量插入一次if (i % 1000 == 0) {userService.saveBatch(list);list.clear();}}long e = System.currentTimeMillis();System.out.println("耗時:" + (e - b));
}?執行最終耗時如下:

可以看到使用了批處理以后,比逐條新增效率提高了10倍左右,性能還是不錯的。
不過,我們簡單查看一下MybatisPlus源碼:
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveBatch(Collection<T> entityList, int batchSize) {String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE);return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}
// ...SqlHelper
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {Assert.isFalse(batchSize < 1, "batchSize must not be less than one");return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {int size = list.size();int idxLimit = Math.min(batchSize, size);int i = 1;for (E element : list) {consumer.accept(sqlSession, element);if (i == idxLimit) {sqlSession.flushStatements();idxLimit = Math.min(idxLimit + batchSize, size);}i++;}});
}可以發現其實MybatisPlus的批處理是基于PrepareStatement的預編譯模式,然后批量提交,最終在數據庫執行時還是會有多條insert語句,逐條插入數據。SQL類似這樣:
Preparing: INSERT INTO user ( username, password, phone, info, balance, create_time, update_time ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
Parameters: user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01
Parameters: user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01
Parameters: user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01而如果想要得到最佳性能,最好是將多條SQL合并為一條,像這樣:
INSERT INTO user ( username, password, phone, info, balance, create_time, update_time )
VALUES
(user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01),
(user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01),
(user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01),
(user_4, 123, 18688190004, "", 2000, 2023-07-01, 2023-07-01);MySQL的客戶端連接參數中有這樣的一個參數:rewriteBatchedStatements。顧名思義,就是重寫批處理的statement語句。參考文檔:
Docs![]() https://b11et3un53m.feishu.cn/wiki/PsyawI04ei2FQykqfcPcmd7Dnsc#SSsSd1nENoCFcSx6ttGc2ocLnlc
https://b11et3un53m.feishu.cn/wiki/PsyawI04ei2FQykqfcPcmd7Dnsc#SSsSd1nENoCFcSx6ttGc2ocLnlc
這個參數的默認值是false,我們需要修改連接參數,將其配置為true
修改項目中的application.yml文件,在jdbc的url后面添加參數&rewriteBatchedStatements=true:
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=truedriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: MySQL123再次測試插入10萬條數據,可以發現速度有非常明顯的提升:

在ClientPreparedStatement的executeBatchInternal中,有判斷rewriteBatchedStatements值是否為true并重寫SQL的功能.




)

)












)