目錄
一、InfluxDB介紹
1.1 什么是InfluxDB?
1.2 應用場景
1.3 特點
1.4 版本差異
二、數據模型和存儲架構
2.1 相關概念
2.2 存儲架構
三、InfluxDB基礎操作
3.1 數據庫操作
3.2 數據表操作
顯示所有表
新建表
刪除表
3.3 數據保存策略
查看保存策略
創建保存策略
修改保存策略
?刪除保存策略
3.4 數據查詢
查詢全部
條件查詢
or查詢
模糊查詢
排序查詢?
去重
分組
聚合函數
分頁
一、InfluxDB介紹
1.1 什么是InfluxDB?
InfluxDB是一個開源的時間序列數據庫,特別為處理和分析帶有時間戳的數據而設計。
它由InfluxData公司開發,并使用Go語言編寫,目標在提供高性能的數據寫入與查詢能力。
1.2 應用場景
? ???物聯網(IoT):處理來自傳感器的大量實時數據,用于環境監測、智能城市、工業自動化等領域.
? ???系統監控:收集和分析服務器、應用程序的性能指標,如CPU使用率、內存占用、網絡流量.
? ???實時分析:在金融、電商等行業中,用于實時交易分析、市場趨勢預測等.
1.3 特點
? ???高寫入性能
????????專為時序數據的 “寫多讀少” 場景優化,支持每秒數十萬條數據寫入(取決于硬件),寫入時跳過復雜索引和事務檢查,優先保證吞吐量。
? ???時間優化的存儲
????????采用 TSM(Time-Structured Merge Tree)存儲引擎,數據按時間分段存儲,查詢時可快速定位時間范圍,避免全表掃描。
? ???靈活的數據模型
????????不依賴固定表結構,支持動態字段擴展,適合數據格式多變的場景(如不同傳感器的指標差異)。
? ???內置數據生命周期管理
????????通過數據保留策略(Retention Policy, RP)?自動刪除過期數據,減少存儲成本(如只保留最近 30 天的監控數據)。
? ???專用查詢語言
????????支持 InfluxQL(類 SQL,易上手)和 Flux(函數式語言,支持復雜數據處理,如跨時間范圍聚合、數據轉換)。
總的來說;非常適合對實時大量數據進行存儲與計算。
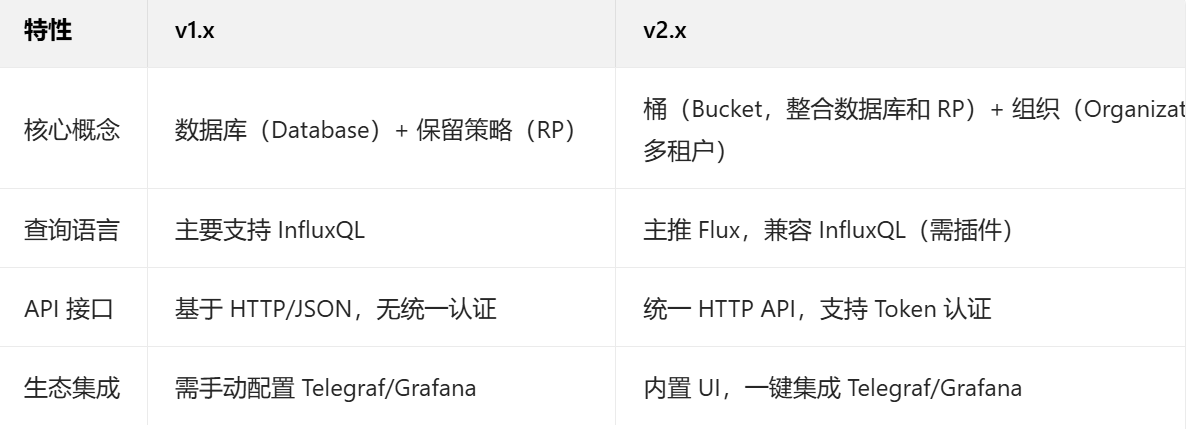
1.4 版本差異
InfluxDB 有兩個主要版本,架構和功能差異較大:
二、數據模型和存儲架構
2.1 相關概念
-
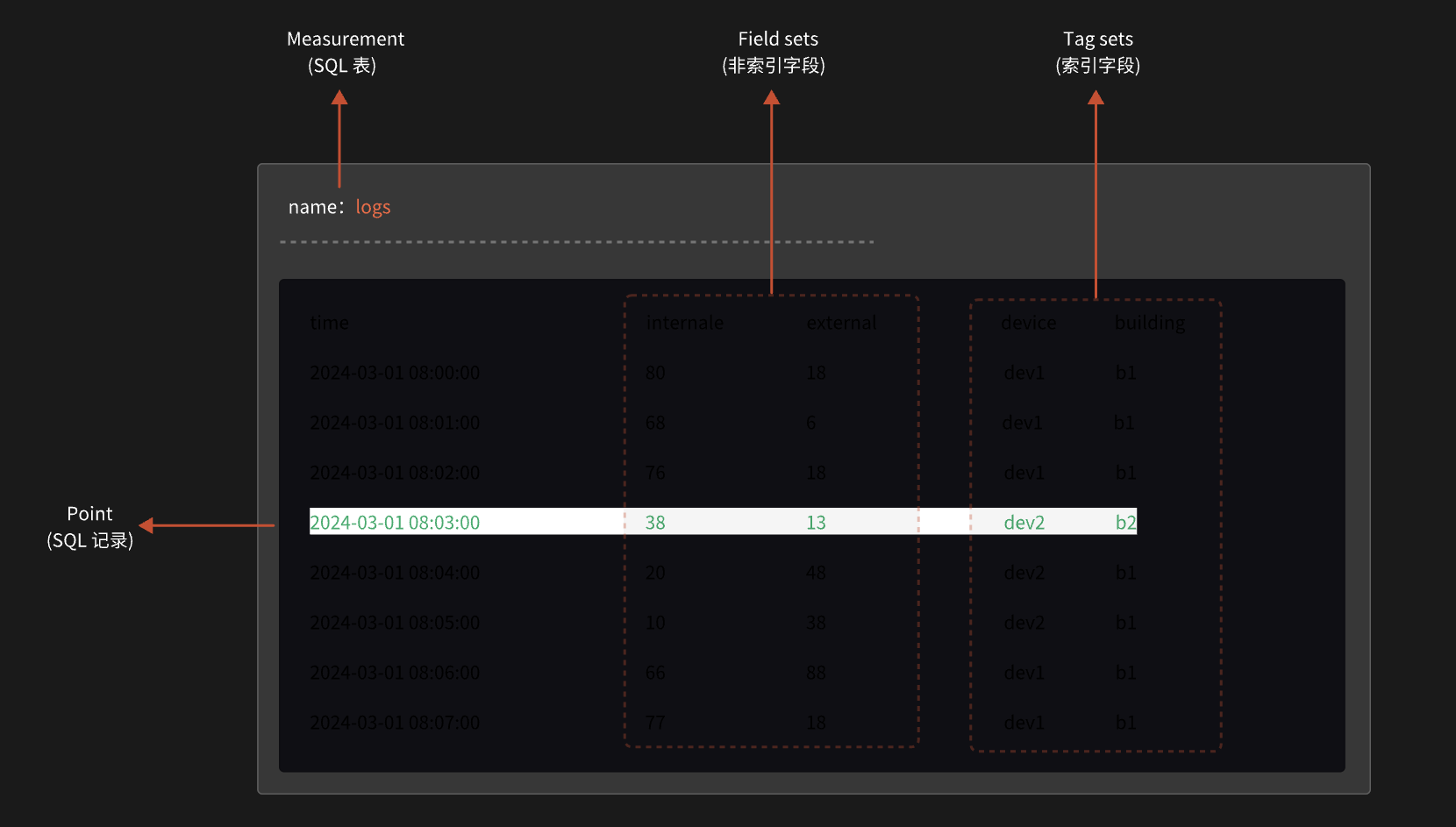
Measurement: 主要用來存儲具有相似特征或屬于同一類別的數據點集合,類似于關系型數據庫中的表(table);包含了列Timestamp時間戳,field字段和tag標簽。
-
Field set: 每組field key和field value的集合,即我們需要的字段,如internale[key] = 76[value], external[key]= 18[value]。不可索引
-
Tag set: 不同的每組tag key和tag value的集合,如device[key]= dev1[value], buiding[key]= b1[value]。可索引
-
Point:表里面的一行數據,由時間戳(timestamp)、標簽(tag)、字段(field)和組成:
-
時間戳time:每條數據記錄的時間,也是數據庫自動生成的主索引,如果時間戳沒有指定。那么InfluxDB就使用當前系統的時間戳(納秒)
-
字段field:字段包含數據的實際值,可以是各種數據類型(整數、浮點數、字符串、布爾值等);與標簽不同,字段在查詢時可以進行數學運算。
-
標簽tag:用于索引和過濾數據;通常是字符串類型。
-
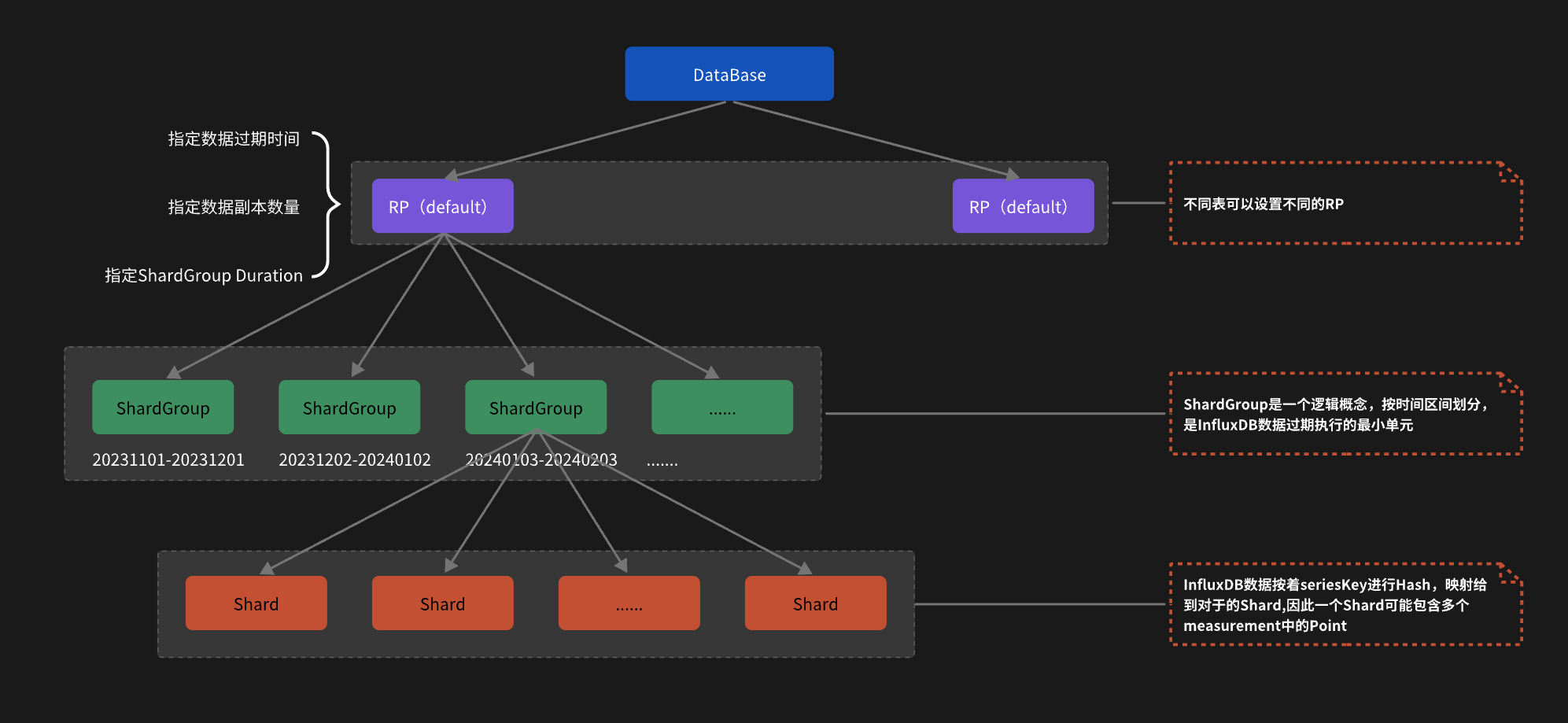
2.2 存儲架構
三、InfluxDB基礎操作
這里我已經進行安裝
# 進入InfluxDB的命令行終端
docker exec -it influxdb /bin/bash# 連接InfluxDB
influx3.1 數據庫操作
連接InfluxDB:
進入InfluxDB的命令行終端,再連接InfluxDB
# 進入InfluxDB的命令行終端
docker exec -it influxdb /bin/bash# 連接InfluxDB
influx
數據庫操作:
# 顯示數據庫
show databases# 創建數據庫
create database itheima# 刪除數據庫
drop database itheima# 使用數據庫
use itheima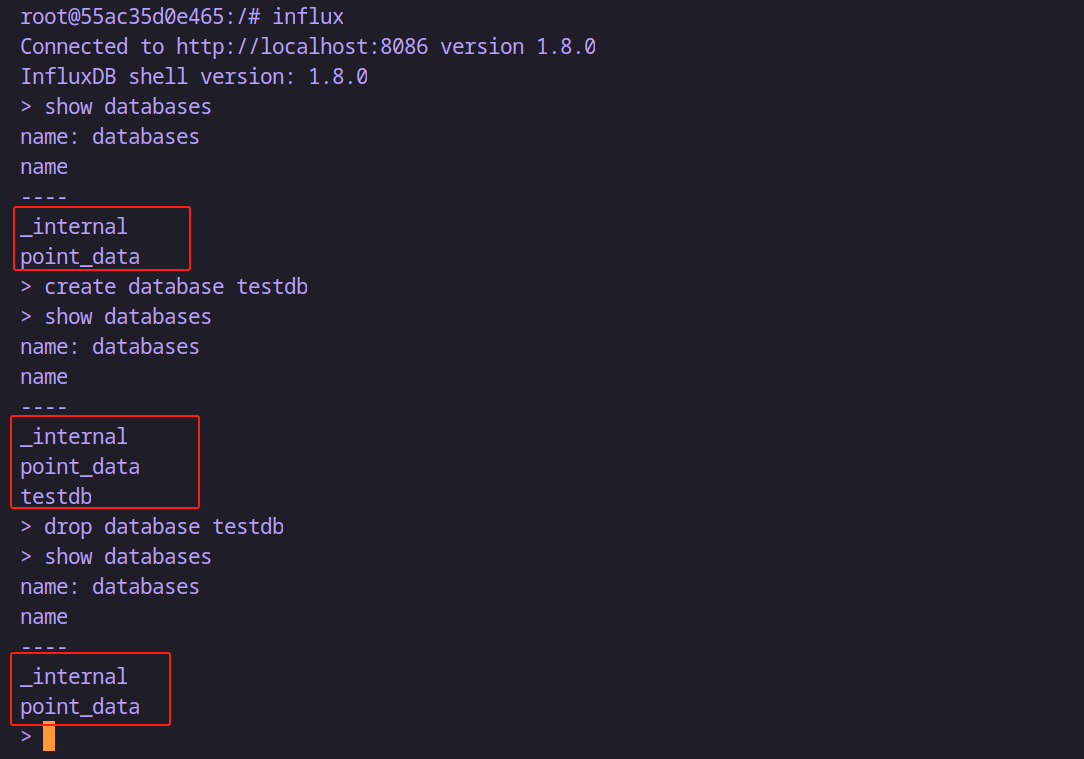
3.2 數據表操作
顯示所有表
# 顯示所有的 measurement
show measurements?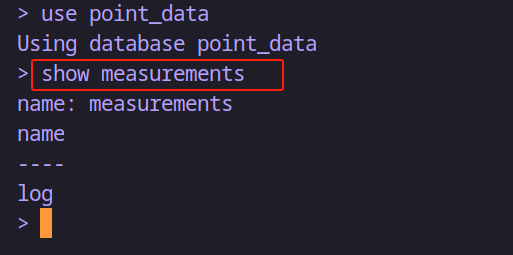
新建表
insert measurement+","+tag1=value1,tag2=value2 + 空格 + field1=value1,field2=values2-- 例如:對measurement為tb_user的插入數據;有一個tag索引名為region,值為廣東;有三個field分別是age,high,weight 對應的值分別為25、175、130
insert tb_user,region=廣東 name="張三",age=25,high=175,weight=130
刪除表
-- 刪除語法
drop measurement 表名-- 例如:刪除名為 tb_user 的measurement
drop measurement tb_user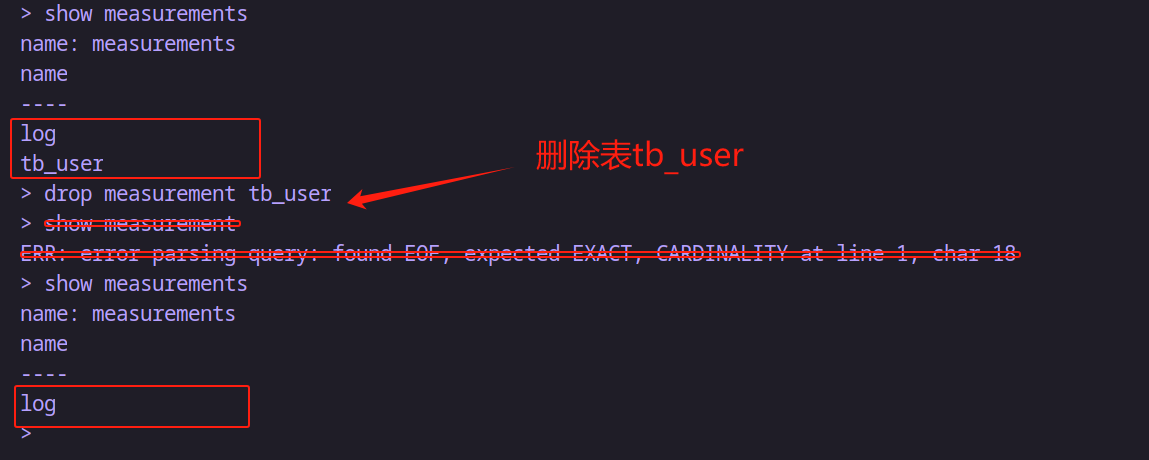
3.3 數據保存策略
查看保存策略
show retention policies on 數據庫名稱-- 例如:查看 point_data 數據庫的保存策略
show retention policies on point_data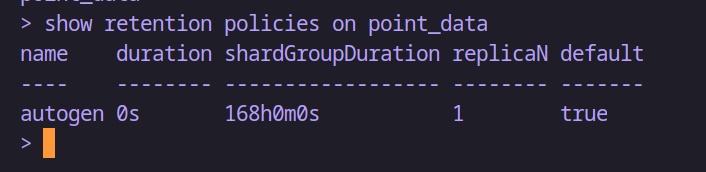
創建保存策略
-- 語法
create retention policy 策略名 on 數據庫名 duration 保留時長 replication 副本個數 [default]-- 示例:創建point_data數據庫的默認保存策略名字為 my_retention ,保留時長為24小時,副本數1個
create retention policy my_retention on point_data duration 24h replication 1 default-- 示例:同樣的,但是保存時長設置為3天,但是不設置為默認的保存策略的話就不加default
create retention policy my_retention2 on point_data duration 3d replication 1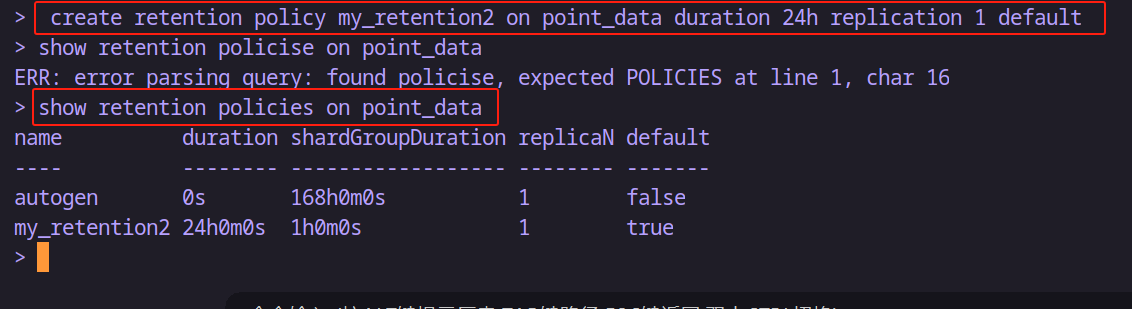
修改保存策略
-- 語法
alter retention policy 策略名 on 數據庫名 duration 時長 default(可選)-- 例如:修改point_data數據庫中的my_retention2策略,保留時長為2天,并設置為默認
alter retention policy my_retention2 on point_data duration 2d default
?刪除保存策略
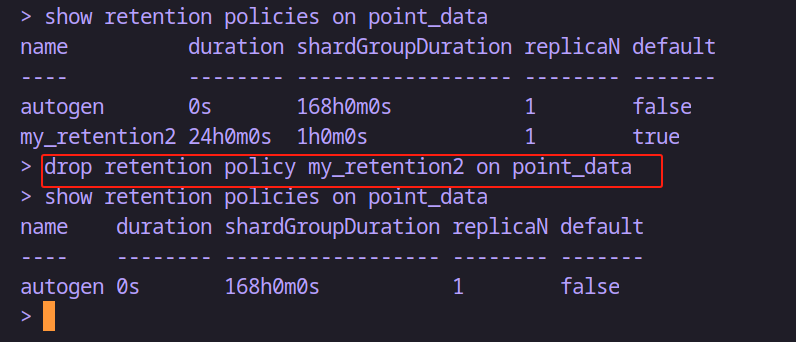
drop retention policy 策略名 on 數據庫名-- 例如:刪除point_data數據庫中策略名為 my_retention2 的策略
drop retention policy my_retention2 on point_data--- 刪除保存策略如果是默認的;則不會自動的指定一個策略為默認;不過可以修改
alter retention policy autogen on point_data default
3.4 數據查詢
查詢全部
-- 插入數據
insert tb_user,region=廣東 name="張三",age=25,high=175,weight=130
insert tb_user,region=湖南 name="李四",age=21,high=177,weight=135
insert tb_user,region=廣東 name="王五",age=28,high=178,weight=138-- 查詢數據
select * from tb_user
條件查詢
-- 查詢名字為 李四,年齡為21 的用戶
select * from tb_user where "name"='李四' and age=21

or查詢
-- 查詢姓名為張三或李四
select * from tb_user where "name"='張三' or "name"='李四'
模糊查詢
-- 查詢名字中包含王的
select * from tb_user where "name"=~/王/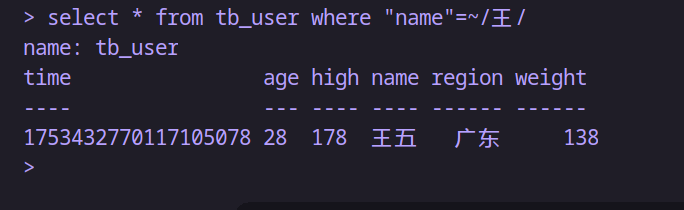
排序查詢?
-- 只能根據時間排序;根據創建時間降序排序
select * from tb_user order by time desc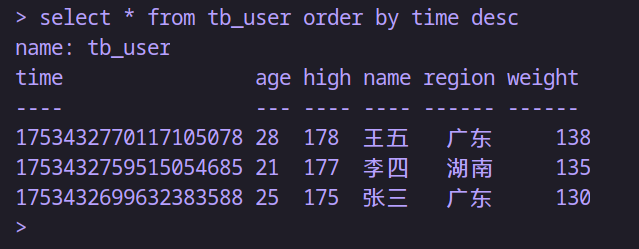
去重
insert tb_user,region=廣西 name="錢六",age=28,high=178,weight=138-- 對age字段去重查詢;注意:只能在distinct 之后接一個字段
select distinct age from tb_user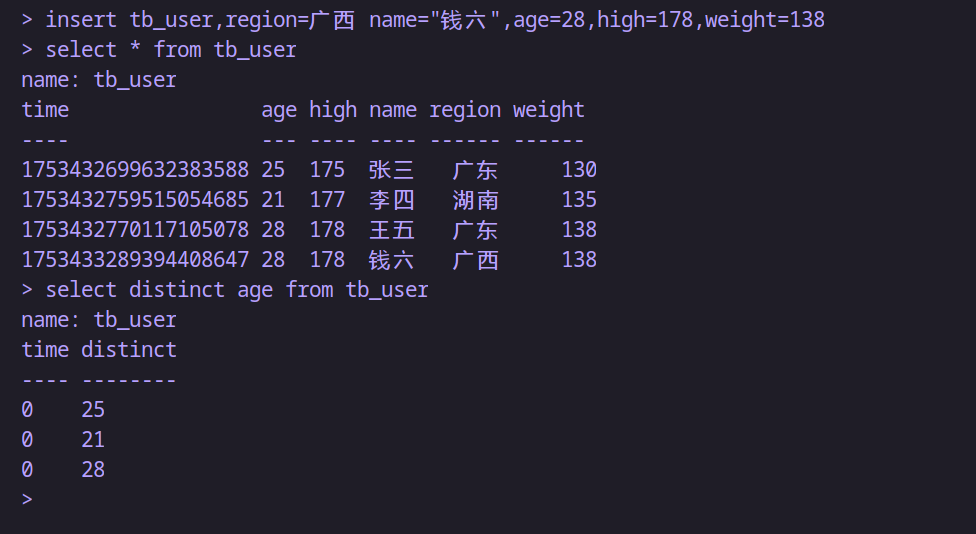
分組
在InfluxDB中,GROUP BY 語句主要用于根據時間序列數據的標簽(tags)進行分組。GROUP BY 僅能用于標簽(tag)字段,而不能直接用于字段(field)進行分組。
-- 根據region進行分組
select * from tb_user group by region-- 統計所有年齡之和
select sum(age) from tb_user聚合函數
-- 統計一條記錄中;每個非空field的總數
select count(*) from tb_user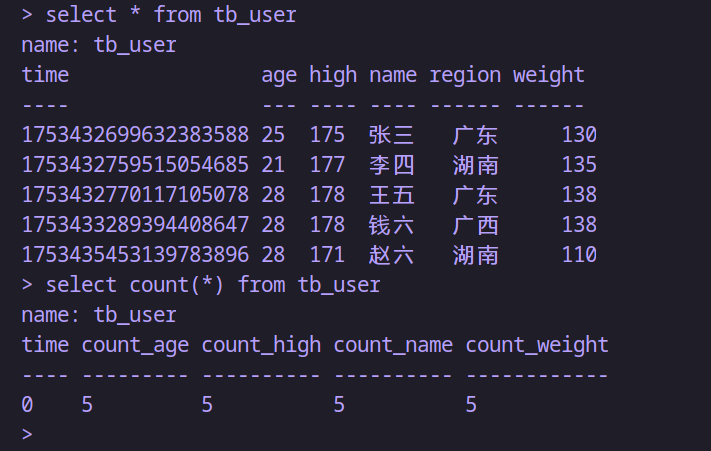
-- 求用戶表的廣東地區的用戶平均年齡
select mean(age) from tb_user where region='廣東'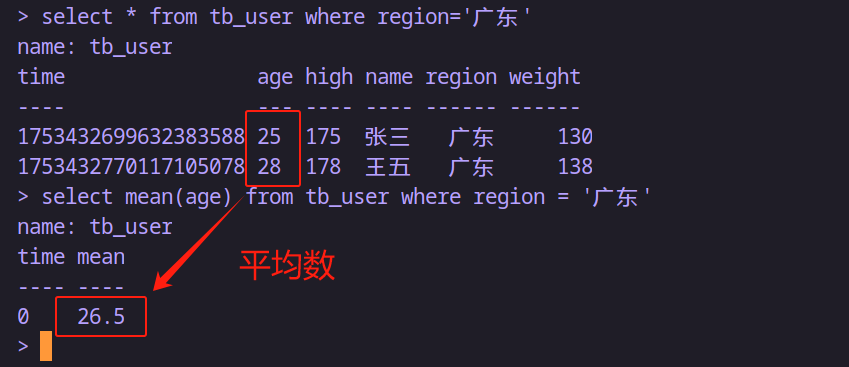
-- 查詢身高中間值
select median(high) from tb_user-- 插入數據后再查看
insert tb_user,region=湖南 name="趙六",age=28,high=171,weight=110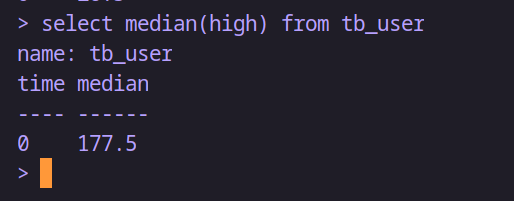
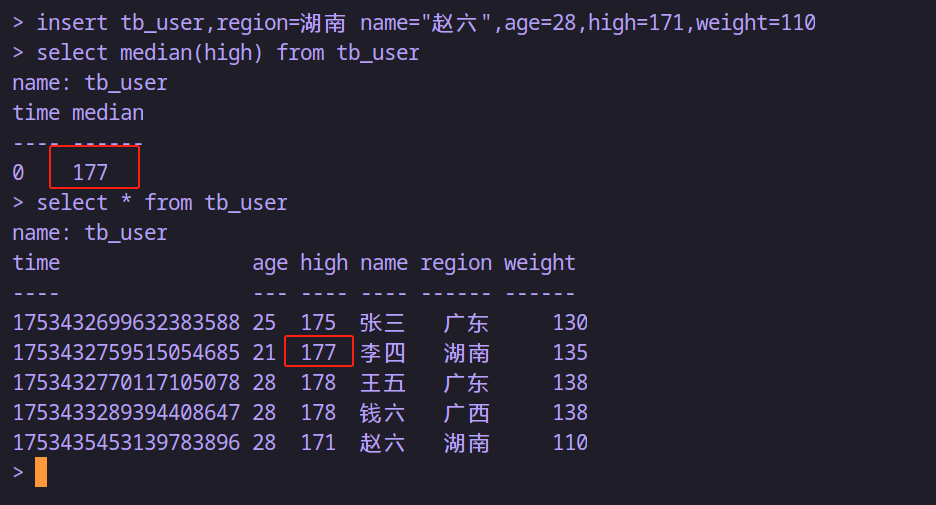
-- 返回最大與最小年齡之間的差值
select spread(age) from tb_user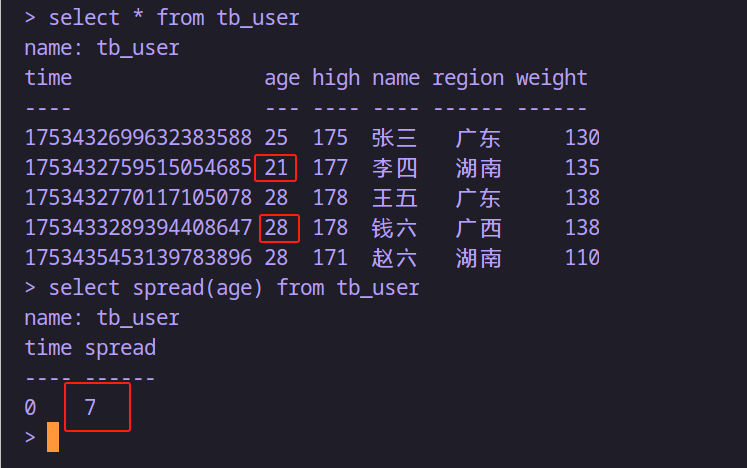
分頁
-- 查詢第1頁,每頁3條數據
select * from tb_user limit 3 offset 0-- 查詢第2頁,每頁3條數據
select * from tb_user limit 3 offset 3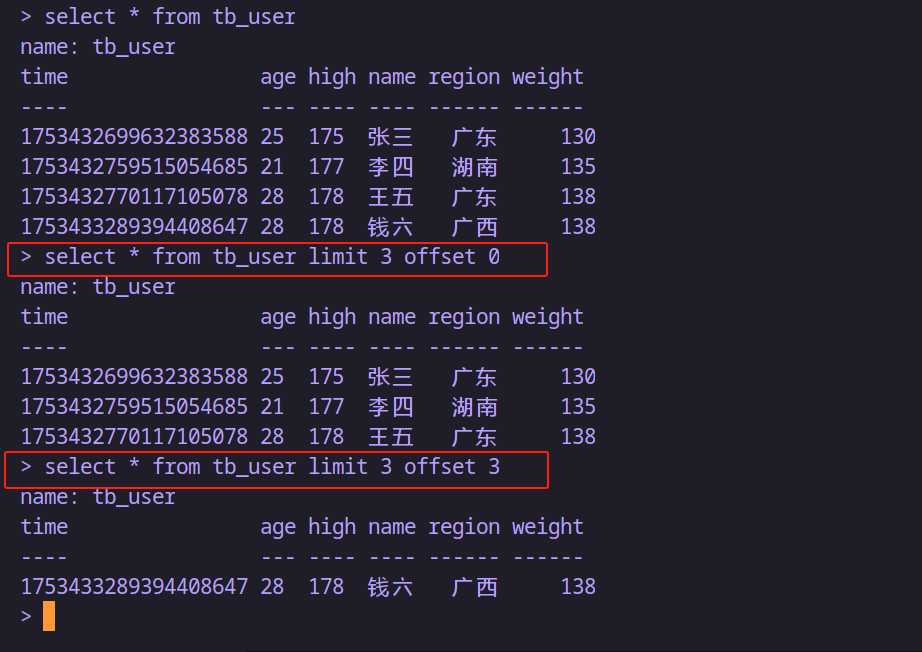










)








)