項目背景
? ? ? ?最近,有時間,想著動手實戰一下,從0到1搭建一個 RAG 系統,也是想通過實戰的方式來更進一步學習 RAG。因此,就定下了以項目實戰為主,書籍為輔的執行方式。(書籍是黃佳老師著的《RAG 實戰課》)
? ? ? ?在我的認知中,技術一直是作為一個工具,它就是為解決問題而生的,而對于企業來說,問題就是企業的業務。本項目選擇的業務領域是金融,為何選擇金融呢?有兩個原因吧。一個是和工作背景有關,以前從事的業務領域一直是和金融相關的;另一個原因是個人興趣,對金融相對感興趣,想借此多了解與學習。
項目目標
- 從0到1做一個 RAG 系統;
- 學習構建 RAG 系統的技術應用;
- 學習評估和優化 RAG 系統。
項目計劃
大的里程碑主要分為兩個:
- 首先是構建一個基于國家金融監督管理總局(National Financial Regulatory Administration,簡稱 NFRA ,后文統一使用它替代)政策法規的智能問答 RAG 系統;
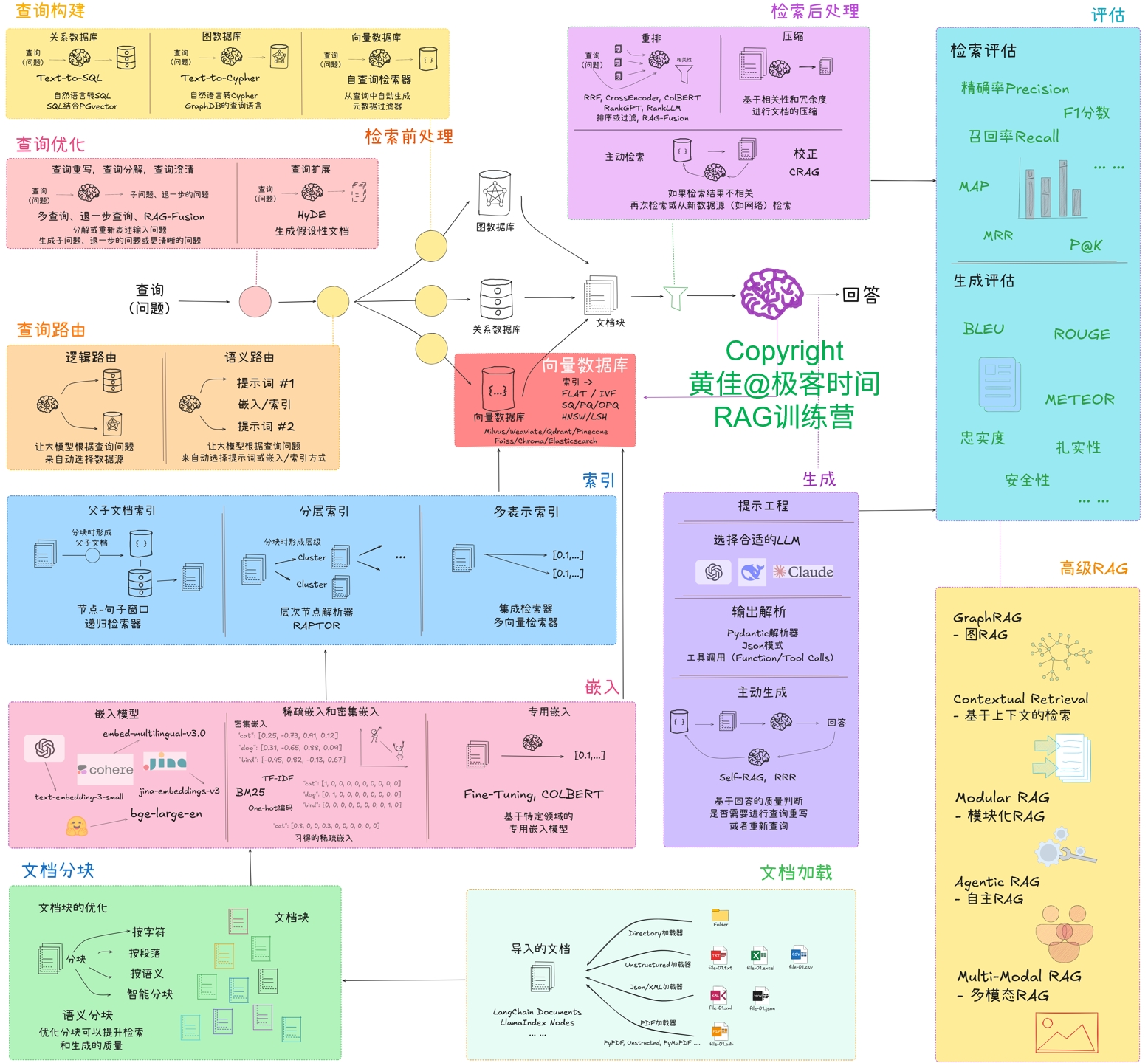
- 其次是基于該智能問答 RAG 系統進行評估與優化。迭代優化整體思路會參考如下圖:
項目簡介
項目名稱
????????NFRA 智能問答系統。
項目代碼
? ? ? ? 項目代碼,已開源發布到 Gitee 平臺。有需要,可點擊
技術棧
? ? ? ? 這里主要介紹項目中使用到的核心技術,LangChain 和 Milvus,以及在項目中應用到的核心技術點。
LangChain
????????LangChain 是一個框架,它使得開發者能夠更加容易地構建基于大型語言模型(LLMs)的應用程序。通過提供一系列工具和組件,LangChain 可以幫助開發者快速搭建如聊天機器人、智能問答系統等應用。
LangChain?需要掌握的關鍵概念:
1. Models (模型)
????????LangChain 支持多種 LLM 接口,包括 OpenAI、Hugging Face 等,提供了標準化接口,允許輕松切換不同模型。
- LLMs:處理純文本輸入并返回純文本輸出的模型。
- Chat Models:支持格式化的聊天消息作為輸入和輸出,更適合對話應用。
2. Prompts (提示管理)
Prompts 模塊幫助開發者設計與模型交互的提示詞,并對輸出進行解析。
- PromptTemplate:模板化提示,可以動態插入變量。
- Output Parsers:將模型輸出結構化為易于理解的格式。
3. Chains (任務鏈)
Chains 將多個模型調用或工具調用組合成工作流,實現復雜流程的編排。
- 預定義鏈:如 LLMChain、SequentialChain 等。
- 自定義鏈:可以根據需求創建自己的鏈。
4. Indexes (索引與檢索)
Indexes 模塊集成外部數據源,使得模型能夠訪問這些數據進行增強生成。
- Document Loaders:從各種來源加載文檔,如 PDF、網頁等。
- Text Splitters:處理長文本分塊以便于處理。
- Vector Stores:使用向量數據庫存儲嵌入式表示的數據,便于相似性搜索。
- Retrievers:結合 LLM 實現 RAG(檢索增強生成)。
5. Callbacks (回調)
Callbacks 提供了一種機制來監控模型調用、記錄日志以及實現其他高級功能,比如異步支持。
6. Embeddings
Embeddings 模塊涉及文本向量化表示,這對于基于內容相似性的搜索至關重要。
- Vector Similarity Calculation:計算向量之間的相似度。
- Vector Storage and Retrieval:管理和檢索向量數據。
Milvus
????????Milvus 是一個開源的、高性能的向量數據庫,它支持存儲、索引和查詢大量的向量數據。這些向量通常由機器學習模型生成,用來表示文本、圖像、音頻等復雜的數據類型。通過使用 Milvus,可以快速地找到與給定向量最相似的數據項,這對于構建智能問答系統、推薦系統、搜索引擎等非常有用。
Milvus 需要掌握的關鍵概念:
- Collection(集合):相當于關系型數據庫中的表,包含一組 entity?
- Entity(實體):相當于表中的一行,包含一組 field?
- Field(字段):可以是結構化數據(數字、字符串)或向量?
- Partition(分區):集合的物理分區,用于減少數據讀取范圍?
- 向量索引:提高查詢速度,支持多種索引類型如 IVF_FLAT、IVF_PQ、HNSW 等
RAG 系統評估
? ? ? ? RAG 系統評估的重要性,上文已談及,不再贅述。不同 RAG 系統的評估數據集,格式可能會有所不同,有的時候存在精確的唯一數據來源,而有的時候答案可能來源于多個頁面或者文檔。NFRA 智能問答系統評估,針對的是答案來源單一文檔的。
? ? ? ? 目前,對 RAG 進行整體評估的,有一個叫 TRIAD 框架,它提供了一個無參照的評估體系。這種無參照的評估體系省去了構建評估數據集的麻煩,但同時也意味著評估指標本身具有一定的非確定性。因此,我們在實際項目中,還是要具體問題具體分析的,而且目前也尚未形成一種通用且可行的 RAG 評估標準。
? ? ? ? RAG 系統評估主要分為檢索評估和響應評估。NFRA 智能問答系統評估,重點是放在檢索評估。之所以這樣做,主要是因為在開發驗證過程中,發現了只要能檢索到問題關聯的政策法規條文作為上下文給到 LLM,大語言模型(項目中默認使用的模型是:deepseek-chat)生成的回復效果是相當不錯的,這對于使用基于忠實度(扎實性)指標評估來說,是可以達到良好及以上的。還有,通過調整提示詞,也會得到不一樣的回復風格。(大家可以搭建起項目來嘗試與驗證)
? ? ? ? 檢索評估指標,選擇的是——召回率。召回率衡量系統檢索到的相關文本塊的全面性,即檢索到的相關文本塊數量占數據庫中所有相關文本塊數量的比例。
?評估數據集
? ? ? ? 數據集文件路徑:/evaluation/data
????????一共三個表單,WX(文心),40條問答對; TY(通義),54條問答對; TXYB(騰訊元寶),50條問答對。總共問答對:144條。
RAG 相關處理說明
切分策略:分塊大小: 500; 分塊重疊大小: 100; 使用正則表達式,[r"第\S*條 "]
嵌入模型:模型名稱: BAAI/bge-base-zh-v1.5 (使用歸一化)
向量存儲:向量索引類型:IVF_FLAT (倒排文件索引+精確搜索);向量度量標準類型:IP(內積); 聚類數目: 100; 存儲數據庫: Milvus
向量檢索:查詢時聚類數目: 10; 檢索返回最相似向量數目: 2
檢索評估結果
| 數據表單 | 有效 問題個數 | TOP1 個數 | TOP1 平均相似度 | TOP1 召回率 | TOP2 個數 | TOP1 平均相似度 | TOP2 召回率 | TOP N策略個數 | TOP N策略召回率 |
| 通義 | 29 | 18 | 0.6855 | 62.07% | 5 | 0.6716 | 17.24% | 23 | 79.31% |
| 元寶 | 33 | 17 | 0.6881 | 51.52% | 7 | 0.6953 | 21.21% | 24 | 72.73% |
| 文心 | 21 | 17 | 0.6509 | 80.95% | 2 | 0.6504 | 9.52% | 19 | 90.48% |
| 總計 | 83 | 52 | 0.6748 | 62.65% | 14 | 0.6724 | 16.87% | 66 | 79.52% |
詳細評估數據集檢索處理結果,可見文件:/evaluation/eval_out
表格說明:
- 有效問題個數:是在 LLM 生成的問答對前提下,刪除了無效的問題,比如不在知識庫中的問題,過于開放性的問題等;
- TOP1、TOP2 個數:是指檢索回來的文本塊(被最終用于回復問題的文本塊在檢索返回時相似度的排名)的數量。越是位于 TOP1,說明檢索效率越高;
- TOP N 策略:就是在問題檢索時,需要返回最相似向量個數。(本次評估,N=2)
檢索評估結論:
???????從表格中可以看到,在有效的 83個問題評估中,總共有 66個問題相關文本塊被召回,召回率是:79.52%。算是中規中矩吧,后續有待優化,至少得達到 90%以上。
檢索召回率不高分析
? ? ? ? 在核對檢索評估結果數據的過程中,基本上都是未能檢索到相關的條文,因而召回率不夠高。召回率不高可能存在的原因有多方面:
- 有些問題相關的條文內容少,在文本塊中占比就會小,文本塊經過嵌入處理后損失一定的語義性,在檢索時相似度得分就不會高,就很可能無法達到 TOP N 返回;(探究能否把政策法規逐條分塊)
- 條文因分塊大小而剛好被截斷,致使出現類似上述第一點的問題;
- 查詢問題與其他文件的分塊存在更高的相似性,致使實際相關的文本塊未能出現在 TOP N 中;(探究檢索前處理技術——查詢重寫;檢索后處理技術——重排)
- ……
其他
- 項目過程遇到的問題,考慮到文章結構和篇幅問題,會單獨再寫一篇。
總結
從0到1做 RAG系統
從0到1做?NFRA 智能問答 RAG系統的過程,有幾點感受比較深的:
- 首要弄清楚你這個智能問答系統,主要面臨的用戶問題都有什么,要在項目開始前調研清楚。若是在公司里,我們要拉著相關業務部門把這個梳理清楚,整理出問答表。這個表會作為?RAG 系統評估數據集的重要來源。
- 其次,確定?RAG系統的評估指標。在梳理、整理問答對的這個過程中,我們也會得出評估 RAG 系統所要的指標,檢索評估指標是看精確率,還是召回率,亦或者是它們的平衡—— F1 分數等等;響應評估指標,是基于?n-gram 匹配程度,還是基于語義相似性,亦或者是基于忠實度(扎實性)等。
- 接著,是對用于構建知識庫的資料進行處理,主要包括:讀取、獲取、切分。同樣地步驟一進行的梳理、整理問答對過程,會讓我們在處理資料時有一個總體認知,能相對好地處理諸如此類問題——需要在資料中獲取什么樣的知識,是否需要獲取元數據,是否要做元數據的過濾,怎么切分這些知識內容等。這一步,與最終檢索的效果密切相關。
- 緊接著,要考慮選擇什么嵌入模型來進行分塊的嵌入,選擇什么樣的向量數據庫進行嵌入的存儲。這一步,看似是技術為主,但它又與業務息息相關。
- 往下,到了檢索、構建 prompt、生成回復,一般來說,按項目迭代的過程來看,這里面先考慮的是生成模型的選擇。
- 再往后,就是對 RAG 進行評估。具體上述RAG 系統評估章節,已談。
實戰感受
- 通過項目實戰方式來學習技術是一個挺好的方式,不過短期內需要投入的時間會相對多,因為在實戰的過程中,會犯一些看似簡單但又讓你一時難以解決的問題,所以要有一定的耐心。
這里舉一個項目中遇到的問題:在做向量檢索過程中,從 Milvus 向量數據庫中查詢并返回結果,沒有注意到 Collection.search() 和 MilvusClient.search() 的區別,這兩個方法的傳參挺像的,而且方法名又是一樣的,導致在處理查詢結果上一直獲取不到想要的內容。當搞清楚Collection.search() 返回的是 Hits對象的集合,而 MilvusClient.search() 返回的是字典類型的集合,問題自然就解決了。
- 以往做系統,我們主要關注的是準確性,不管是面向關系型還是非關系型數據庫,都是如此;而如今,我們主要關注的是相似性,面向的是向量數據庫。不管如何,都是試圖通過一種技術手段把現實世界進行建模、數據化,根據用戶的輸入,從數據化的“現實世界”中找到滿足用戶的輸出。
項目代碼地址:https://gitee.com/qiuyf180712/rag_nfra








)









![[matlab]matlab上安裝xgboost安裝教程簡單版](http://pic.xiahunao.cn/[matlab]matlab上安裝xgboost安裝教程簡單版)
