文章目錄
- ==有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主==
- 項目背景
- 數據來源與采集方式
- 數據預處理與清洗流程
- 探索性數據分析(EDA)
- 模型構建與預測方法
- 項目意義與應用前景
- 相關可視化展示
- 總結
- 每文一語
有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主
項目背景
隨著我國房地產市場逐步邁入存量房時代,二手房市場的活躍度不斷上升,房源數量持續增加,供需格局發生深刻變化。在當前行業震蕩調整的背景下,二手房價格的波動和影響因素成為社會廣泛關注和學術界深入研究的重要議題。針對這一背景,準確識別影響房價的關鍵因素并構建科學合理的預測模型,對于購房者、政策制定者及房產中介機構均具有重要意義。
數據來源與采集方式
本項目依托鏈家網作為數據來源,針對成都市各大區域的二手房源信息進行了大規模自動化數據采集。為突破網站的反爬蟲機制,采用多種策略提升爬蟲的魯棒性和穩定性,包括:偽裝瀏覽器請求頭、配置Cookies、設置智能延時訪問策略,并結合異常頁面識別機制與郵件提示功能進行動態監控與反饋。同時,系統還具備字段提取自動化檢測功能,保障數據采集的完整性與準確性。
最終共收集到31834條有效房源記錄,涵蓋20多個房源特征字段,為后續建模分析奠定了堅實的數據基礎。
數據預處理與清洗流程
為保證分析與建模質量,本項目對原始數據進行了系統的預處理工作。主要流程包括:
- 缺失值處理:針對少量缺失數據,選擇整行刪除策略以確保樣本質量;
- 重復值剔除:移除數據中出現的重復記錄,避免影響統計結論;
- 異常值檢測與范圍約束:通過箱型圖等可視化手段對數值字段進行分布分析,識別極端值并設定合理取值范圍;
- 特征衍生與歸一化:對文本類字段進行關鍵信息提取與格式標準化,同時對部分字段進行合并與降維;
- 字段擴展:處理后字段總計達到24個維度,為建模提供了全面的特征輸入。
探索性數據分析(EDA)
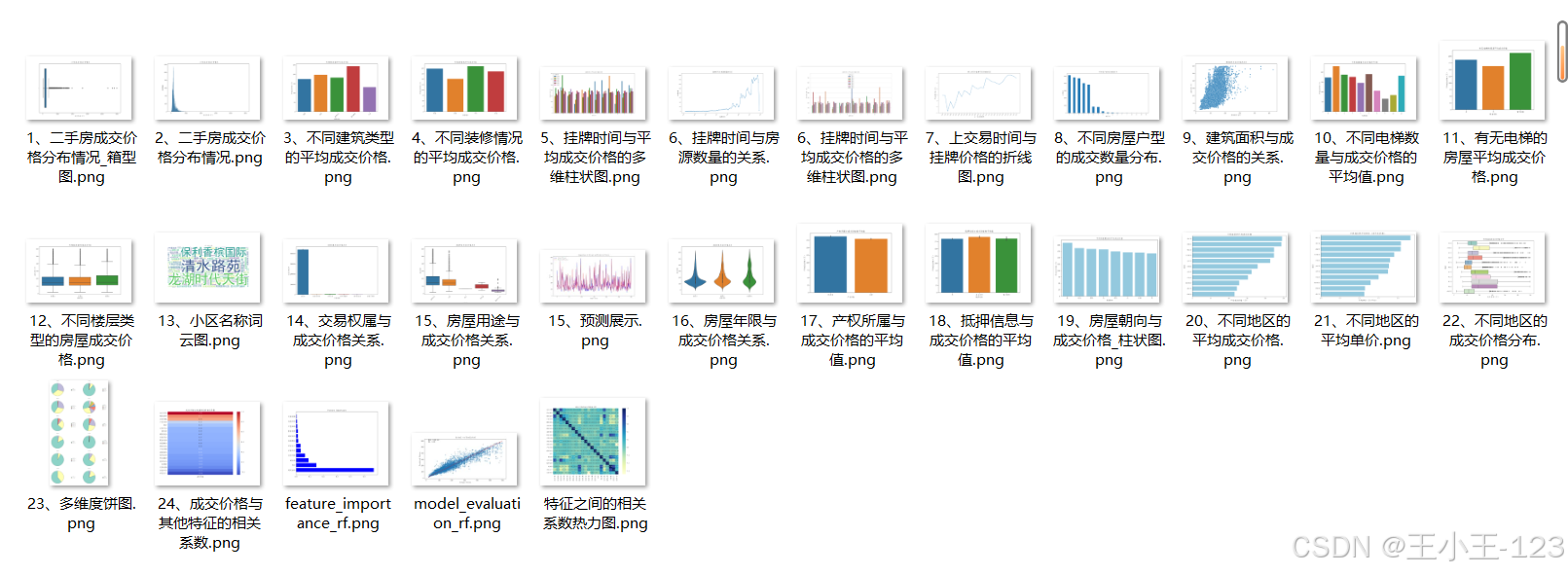
為深入挖掘成都市二手房市場的內在結構和價格影響機制,本項目從多個維度展開探索性數據分析,具體包括:
- 地理維度:分析各區/板塊房價差異及熱度分布;
- 房屋基本屬性:如面積、戶型、樓層、裝修狀態對價格的影響;
- 價格分布特征:整體價格區間、均值、中位數與極值情況;
- 業主與掛牌信息:包含掛牌時間、房源關注度等對房價的潛在影響;
- 時間趨勢:分析不同時間段內價格波動情況;
- 小區熱度與房源集中度分析。
在可視化手段方面,綜合采用柱狀圖、折線圖、餅圖、詞云、箱型圖和熱力圖等多種形式,全面揭示數據規律和變量間的關聯特征。
模型構建與預測方法
針對二手房價格預測這一非線性回歸問題,傳統線性回歸方法在高維、復雜數據下表現有限。因此,本項目引入多種主流的機器學習樹模型進行建模與對比實驗:
- 模型選型:采用隨機森林(Random Forest)、極端梯度提升(XGBoost)以及輕量化梯度提升(LightGBM)三種模型;
- 特征選擇:利用遞歸特征消除結合交叉驗證(RFECV)方法,自動篩選最具解釋力的特征,規避人為偏差;
- 超參數優化:通過貝葉斯優化框架 Optuna 對各模型進行參數自動調優,相較傳統網格搜索顯著提升效率;
- 模型評估指標:以R2擬合優度、均方誤差(MSE)等指標評估模型性能。
最終實驗結果顯示,隨機森林模型在擬合能力與預測準確性方面表現最優,R2達到0.88,具備較強的實用價值和推廣潛力。
項目意義與應用前景
本研究不僅系統地分析了成都市二手房市場的多維度影響因素,還通過先進的機器學習方法構建了精度較高的房價預測模型。其成果可為:
- 購房者提供科學的購房決策支持;
- 政府制定更為精準的房地產調控政策;
- 房產平臺與中介公司優化房源推薦機制。
未來,本項目可進一步擴展至更多城市和多源異構數據融合分析,實現更廣泛的應用落地。

相關可視化展示











總結
本研究通過對成都二手房市場的多維度分析,探討了影響房價的關鍵因素,并對三種常用回歸模型(隨機森林、XGBoost和LightGBM)進行了比較評估。研究的主要結論如下:
首先,分析結果表明,房價受多種因素的影響,其中建筑面積、總房間數和戶型結構等因素對房價具有顯著的正向影響。此外,地區、交易年份等變量也對房價有一定程度的影響。基于這些發現,可以為政策制定者和房地產開發商提供重要的市場洞察,幫助他們更好地預測房價波動和優化產品布局。
其次,模型評估表明,隨機森林在房價預測中表現最為優秀,其在均方誤差(MSE)、均方根誤差(RMSE)和平均絕對誤差(MAE)等指標上均優于XGBoost和LightGBM,且R2值也較高。這表明隨機森林在處理數據的多樣性和復雜性方面具有較強的擬合能力。相對而言,XGBoost和LightGBM雖然在計算效率上更為優越,但在預測精度上略遜色,尤其是LightGBM在大規模數據集上的優勢尤為明顯。
綜合來看,本研究不僅為成都二手房市場的分析提供了有價值的參考,也展示了不同機器學習模型在實際應用中的優劣。未來的研究可以進一步探索更多模型的應用,尤其是在處理更大規模、更多特征的數據時,可以考慮對模型進行調優和集成,以提高預測精度。同時,結合市場動態和政策變化,進一步優化預測模型,將為房地產市場的決策提供更加準確的數據支持。
每文一語
不斷學習














)



應用開發平臺Dify)
里的文檔管理)