目錄
一、項目簡介
二、模型訓練+驗證+保存
三、模型測試+保存csv文件
四、單張圖片預測
五、模型評估
六、ONNX導出
七、ONNX推理
八、網絡結構與數據增強可視化
上篇我介紹了具體步驟,今天就以我實際開發的一個具體項目來講:
一、項目簡介
? 苯人的項目是基于CNN實現香蕉成熟度的小顆粒度分類,針對六種不同狀態(新鮮成熟的、新鮮未熟的、成熟的、腐爛的、過于成熟的、生的)進行高精度視覺識別。由于香蕉的成熟度變化主要體現在顏色漸變、斑點分布及表皮紋理等細微差異上,傳統圖像處理方法難以準確區分。因此,本項目通過構建深層CNN模型,利用卷積層的局部特征提取能力捕捉香蕉表皮的細微變化,并結合高階特征融合技術提升分類精度。
數據集長這樣:
苯人是在?https://universe.roboflow.com/ 這個網站上下載的,kaggle我自己覺得不好用(其實是看不來),總之數據集有了,再說一嘴苯人是引用的 ResNet18網絡模型,接下來就開始寫代碼吧:
二、模型訓練+驗證+保存
這里我就不像上篇那樣這么詳細了,主要是看流程:
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision.models import resnet18 #導入網絡結構
from torch import optim# 模型保存
last_model_path = './model/last.pth'
best_model_path = './model/best.pth'#數據預處理
train_transforms = transforms.Compose([transforms.Resize((256, 256)), # 先稍微放大點transforms.RandomCrop(224), # 隨機裁剪出 224x224transforms.RandomHorizontalFlip(p=0.5), # 左右翻轉transforms.RandomRotation(degrees=15), # 隨機旋轉 ±15°transforms.ColorJitter(brightness=0.2, # 明亮度contrast=0.2, # 對比度saturation=0.2, # 飽和度hue=0.1), # 色調transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet均值std=[0.229, 0.224, 0.225]) # ImageNet標準差
])
val_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])#加載數據集
train_dataset = ImageFolder(root='./Bananas/train', transform= train_transforms)
valid_dataset = ImageFolder(root='./Bananas/valid', transform= val_transforms)#數據加載器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=64, shuffle=False)#遷移模型結構
model = resnet18(pretrained = True)
in_features = model.fc.in_features #動態獲得輸入
model.fc = nn.Linear(in_features, 6) #改成6分類
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 優化:解凍最后兩層和fc層(更有學習能力)
for name, param in model.named_parameters():if "layer4" in name or "fc" in name:param.requires_grad = Trueelse:param.requires_grad = False#再用 filter 篩選需要梯度更新的參數
param_grad_true = filter(lambda x:x.requires_grad, model.parameters())#實例化損失函數對象
criterion = nn.CrossEntropyLoss()
#優化器 這里使用AdamW
optimizer = optim.AdamW(param_grad_true, lr=1e-3, weight_decay=0.01)
# 優化:添加學習率調度器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=5, factor=0.5, verbose=True)#開始訓練+每10個輪次驗證一次
def train(model, train_loader, valid_loader, epochs, validate_every=10):import os# 創建模型保存目錄os.makedirs('./model', exist_ok=True)model.train()best_val_acc = 0 #初始化最優準確率# 優化:增加早停機制early_stopping_patience = 10no_improve_epochs = 0for epoch in range(epochs):running_loss = 0 #初始化每輪訓練的損失correct = 0 #初始化正確數與總個數total = 0for images, labels in train_loader:images, labels = images.to(device), labels.to(device)output = model(images) #得到預測值loss = criterion(output, labels) #計算損失optimizer.zero_grad() #梯度清零loss.backward() #反向傳播optimizer.step() #根據梯度更新參數running_loss += loss.item() #當前epoch的總損失pred = torch.argmax(output, dim=1) #拿到當前圖片預測是最大值的索引下標當做類別total += labels.size(0)correct += (pred == labels).sum().item()train_acc = correct/total * 100 #訓練準確率print(f"[Epoch {epoch + 1}/{epochs}] Loss: {running_loss:.4f}, Accuracy: {train_acc:.2f}%")#驗證部分if (epoch + 1) % validate_every == 0: #每10輪驗證一次val_loss = 0val_total = 0val_correct = 0model.eval()with torch.no_grad(): #邏輯與訓練函數差不多for val_images, val_labels in valid_loader:val_images, val_labels = val_images.to(device), val_labels.to(device)val_output = model(val_images)val_loss += (criterion(val_output, val_labels)).item()val_pred = torch.argmax(val_output, dim=1)val_total += val_labels.size(0)val_correct += (val_pred == val_labels).sum().item()val_acc = val_correct/val_total *100 #驗證準確率# 優化:根據驗證準確率調整學習率scheduler.step(val_acc)print(f"[Epoch {epoch + 1}/{epochs}] Loss: {running_loss:.4f}, Accuracy: {train_acc:.2f}%")#保存最優模型參數if val_acc > best_val_acc:best_val_acc = val_acctorch.save(model.state_dict(), best_model_path)print(f"保存了當前最優模型,驗證正確率:{val_acc:.2f}%")# 優化:早停法else:no_improve_epochs += 1if no_improve_epochs >= early_stopping_patience:print(f"驗證準確率連續{early_stopping_patience}輪沒有提升,提前停止訓練")break# 保存最近一次模型參數torch.save(model.state_dict(), last_model_path)model.train()train(model, train_loader, valid_loader, epochs=50) #訓練50次看看
主要邏輯還是像上篇那樣:數據預處理-->加載數據集-->數據加載器-->遷移模型結構-->改變全連接層-->配置訓練細節(損失優化)-->訓練函數-->每10輪訓練后驗證一次-->保存最近一次訓練模型參數以及最優模型參數
改全連接層那里說一下,因為我做的是六分類,原來的模型結構是千分類,所以要把 out_features 改成6,同時凍結其他層只訓練全連接層就好,但是因為第一次訓練的效果不是很好,所以在優化的時候我又解凍了最后兩層,增加了學習能力;另外還有優化就是對學習率,我增加了一個學習率調度器,動態學習率對模型來說效果更好;最后一個優化是增加了早停機制,即在驗證準確率連續多少輪沒有提升時自動停止訓練,這樣大大節省了訓練時間
運行結果我就不貼了因為我搞忘截圖了。。反正最后一輪準確率有98%,模型參數也保存了:
?
三、模型測試+保存csv文件
import torch
import os
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision.models import resnet18
import numpy as np
import pandas as pd#最優模型參數路徑
best_model_path = './model/best.pth'#數據預處理
val_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])#準備測試數據集
test_dataset = ImageFolder(root='./Bananas/test', transform=val_transforms)#數據加載器
test_load = DataLoader(test_dataset, batch_size=64, shuffle=False)#導入模型結構
model = resnet18(pretrained = False) #不用加載自帶的參數
in_features = model.fc.in_features #同樣動態接受輸入特征
model.fc = nn.Linear(in_features, 6) #同樣更改模型結構device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#加載之前保存的最優模型參數
model.load_state_dict(torch.load(best_model_path, map_location = device))
model.to(device)#開始測試
model.eval()
correct = 0
total = 0
with torch.no_grad():for images, labels in test_load:images, labels = images.to(device), labels.to(device)out = model(images) #得到預測值pred = torch.argmax(out, dim=1)correct += (pred == labels).sum().item()total += labels.size(0)
test_acc = correct / total *100
print(f'測試集測試的準確率為:{test_acc:.2f}%')valid_dataset = ImageFolder(root='./Bananas/valid', transform= val_transforms)
valid_loader = DataLoader(valid_dataset, batch_size=64, shuffle=False)
classNames = valid_dataset.classes #拿到類名model.eval()
acc_total = 0
val_dataloader = DataLoader(valid_dataset, batch_size=64, shuffle=False)
total_data = np.empty((0,8))
with torch.no_grad():# 每個批次for x, y in val_dataloader:x = x.to(device)y = y.to(device)out = model(x)# [10,3]pred = torch.detach(out).cpu().numpy()# [10,]p1 = torch.argmax(out, dim=1)# 轉化為numpyp2 = p1.unsqueeze(dim=1).detach().cpu().numpy()label = y.unsqueeze(dim=1).detach().cpu().numpy()batch_data = np.concatenate([pred, p2, label],axis=1)total_data = np.concatenate([total_data, batch_data], axis=0)# 構建csv文件的第一行(列名)
pd_columns = [*classNames, 'pred', 'label']os.makedirs('./results', exist_ok=True)
csv_path = os.path.relpath(os.path.join(os.path.dirname(__file__), 'results', 'number.csv'))pd.DataFrame(total_data, columns=pd_columns).to_csv(csv_path, index=False)
print("成功保存csv文件!")運行結果:
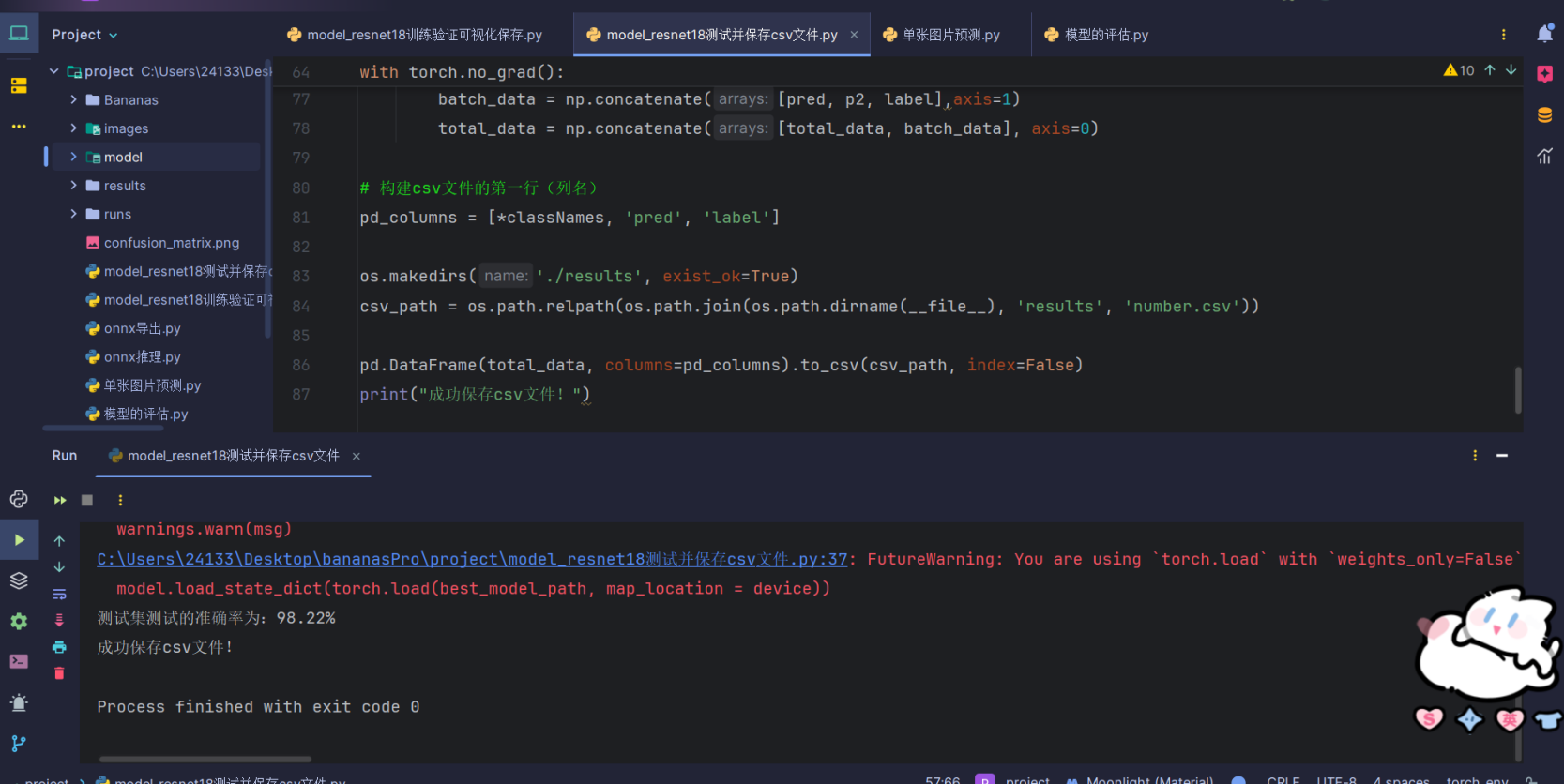
測試集的準確率也有這么高說明沒有過擬合,我們可以打開csv文件看一下:
?
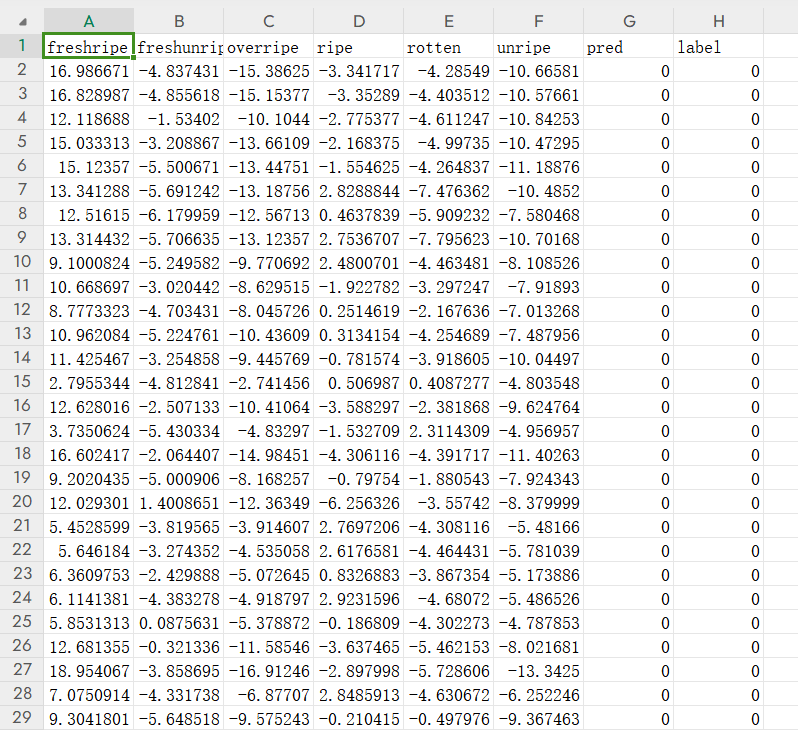
預測的準確率還是挺高的,這里也說明一下測試的時候是加載之前訓練保存的模型參數,所以
model = resnet18(pretrained = False)? 這里的參數填false,然后再加載保存的模型參數:
model.load_state_dict(torch.load(best_model_path, map_location = device)).
四、單張圖片預測
這里我們可以從網上找幾張圖片來預測一下:
import torch
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torchvision.models import resnet18#最優模型參數路徑
best_model_path = './model/best.pth'
10
#數據預處理
val_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])
train_transforms = transforms.Compose([transforms.Resize((256, 256)), # 先稍微放大點transforms.RandomCrop(224), # 隨機裁剪出 224x224transforms.RandomHorizontalFlip(p=0.5), # 左右翻轉transforms.RandomRotation(degrees=15), # 隨機旋轉 ±15°transforms.ColorJitter(brightness=0.2, # 明亮度contrast=0.2, # 對比度saturation=0.2, # 飽和度hue=0.1), # 色調transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet均值std=[0.229, 0.224, 0.225]) # ImageNet標準差
])#加載圖片
img_path = 'images/b8_rotten.jpg'
img = Image.open(img_path).convert('RGB') # 確保是RGB三通道
img = val_transforms(img) # 應用transform
img = img.unsqueeze(0) # 加上 batch 維度#導入模型結構
model = resnet18(pretrained = False) #不用加載自帶的參數
in_features = model.fc.in_features #同樣動態接受輸入特征
model.fc = nn.Linear(in_features, 6) #同樣更改模型結構device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#加載之前保存的最優模型參數
model.load_state_dict(torch.load(best_model_path, map_location = device))
model.to(device)#模型預測
model.eval()
with torch.no_grad():output = model(img)pred_class = torch.argmax(output, dim=1).item()train_dataset = ImageFolder(root='./Bananas/train', transform= train_transforms)
idx_to_class = {v: k for k, v in train_dataset.class_to_idx.items()}
pred_label = idx_to_class[pred_class]
print(f"模型預測這張圖片是:{pred_label}")運行結果:
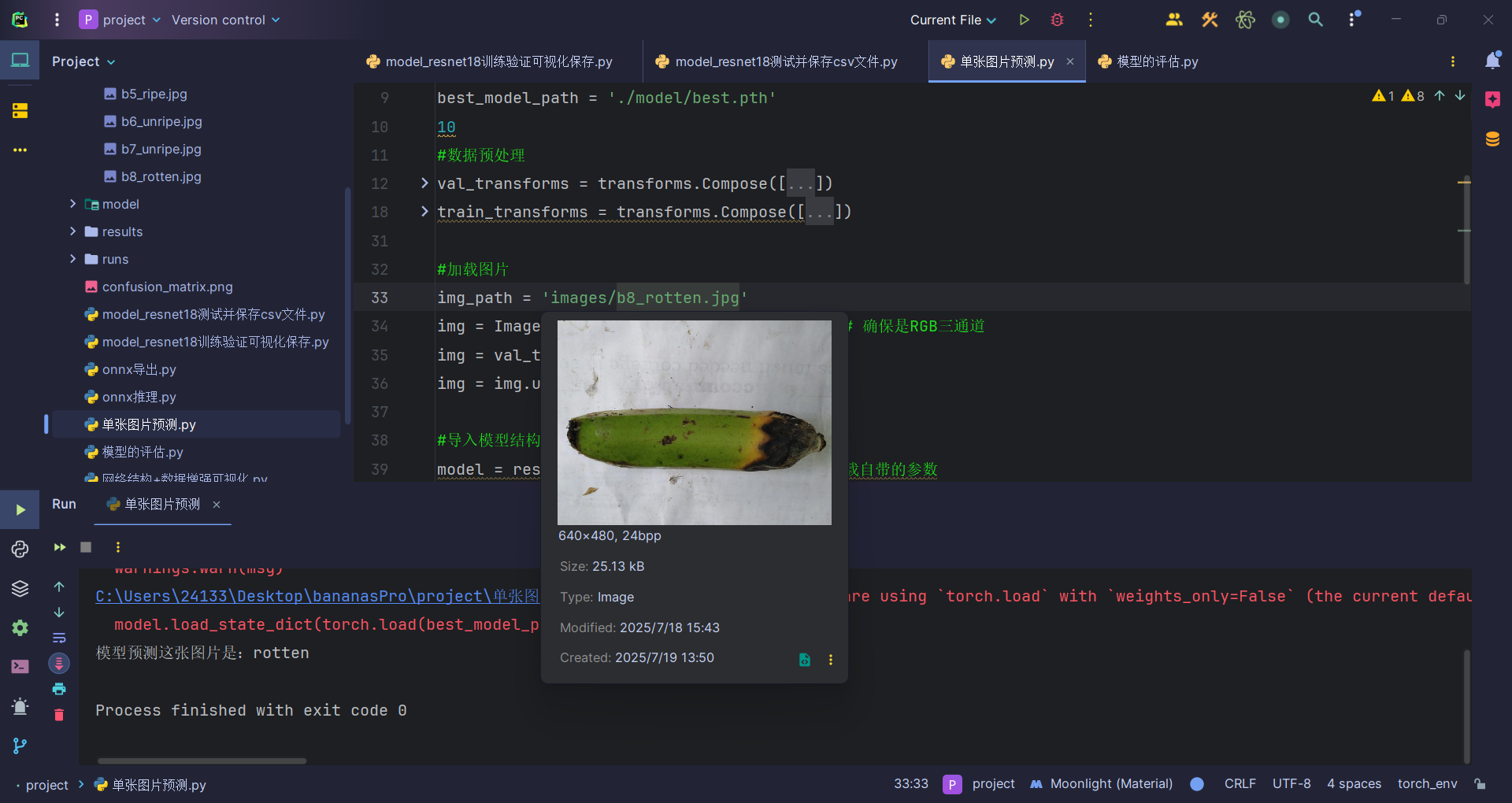
注意要記得給原圖片升維,因為要求傳入的圖片形狀是(N, C, H, W)
五、模型評估
在CNN項目中,對模型評估的指標(準確率、召回率、F1等)應該基于測試集的結果進行最終評估,因為模型在測試集上的表現是最接近于真實情況的:
import pandas as pd
import os
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib
import matplotlib.pyplot as plt#設置中文字體
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = Falsecsv_path = os.path.relpath(os.path.join(os.path.dirname(__file__), 'results', 'number.csv'))
# 讀取CSV數據
csvdata = pd.read_csv(csv_path, index_col=0)
# 拿到真實標簽
true_label = csvdata["label"].values
# 拿到預測標簽
true_pred = csvdata["pred"].values# 根據預測值和真實值生成分類報告
report = classification_report(y_true=true_label, y_pred=true_pred)
print(report)# 混淆矩陣可視化
cm = confusion_matrix(true_label, true_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=[str(i) for i in range(6)])
disp.plot(cmap='Greens', values_format='d')
plt.title("訓練結果混淆矩陣視圖")
plt.tight_layout()
plt.savefig("confusion_matrix.png")
plt.show()
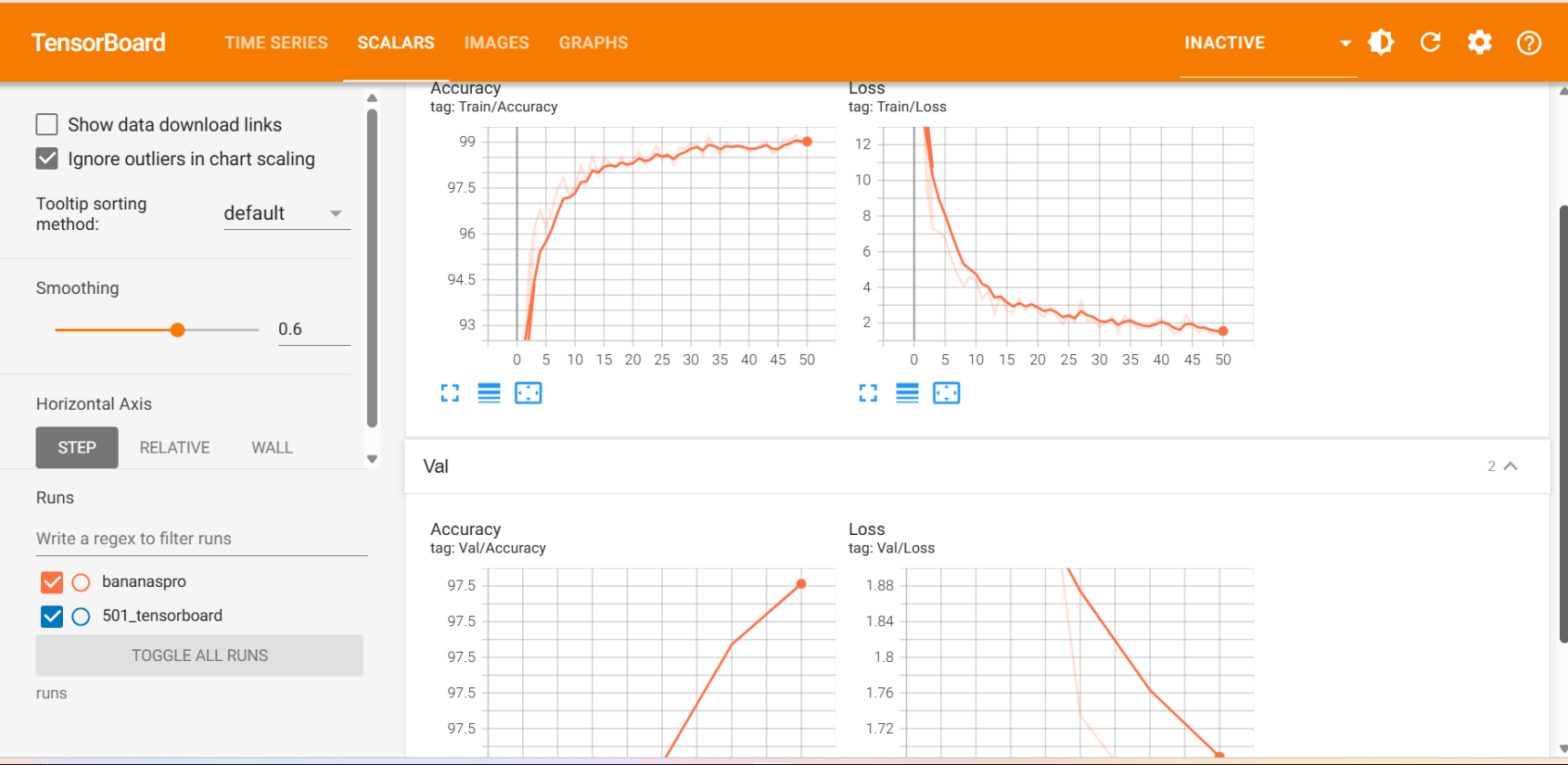
運行結果:
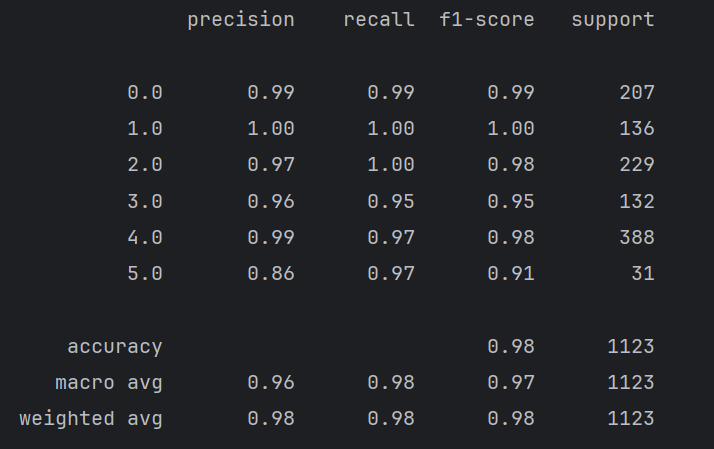
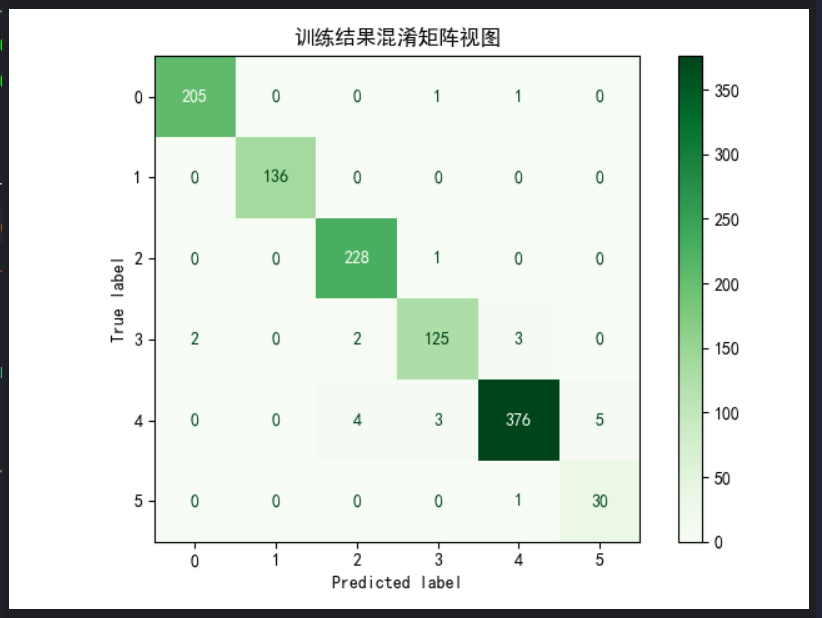
可以看到,f1分數比較高,混淆矩陣的對角線數字也很大,說明模型表現良好。
六、ONNX導出
導出為ONNX格式主要是它兼容性很高,且可以被專用推理引擎優化,減少計算開銷,代碼如下:
import torch
from torchvision.models import resnet18
import torch.nn as nnbest_model_path = './model/best.pth'
onnx_path = './model/best.onnx' #保存路徑#加載模型結構與權重參數
model = resnet18(pretrained = False)
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, 6) #同樣修改全連接層device = torch.device("cuda" if torch.cuda.is_available() else "cpu" )
model.load_state_dict(torch.load(best_model_path, map_location=device))#創建實例輸入
x = torch.randn(1, 3, 224, 224)
out = model(x)
# print(out.shape) #確認輸出不是None torch.Size([1, 6])#導出onnx
model.eval()
torch.onnx.export(model, x, onnx_path, verbose=False, input_names=["input"], output_names=["output"])
print("onnx導出成功!")import onnx
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print("onnx模型檢查通過!")?導出后我們可以通過這個網站來可視化一下:Netron,打開剛剛保存的ONNX文件:
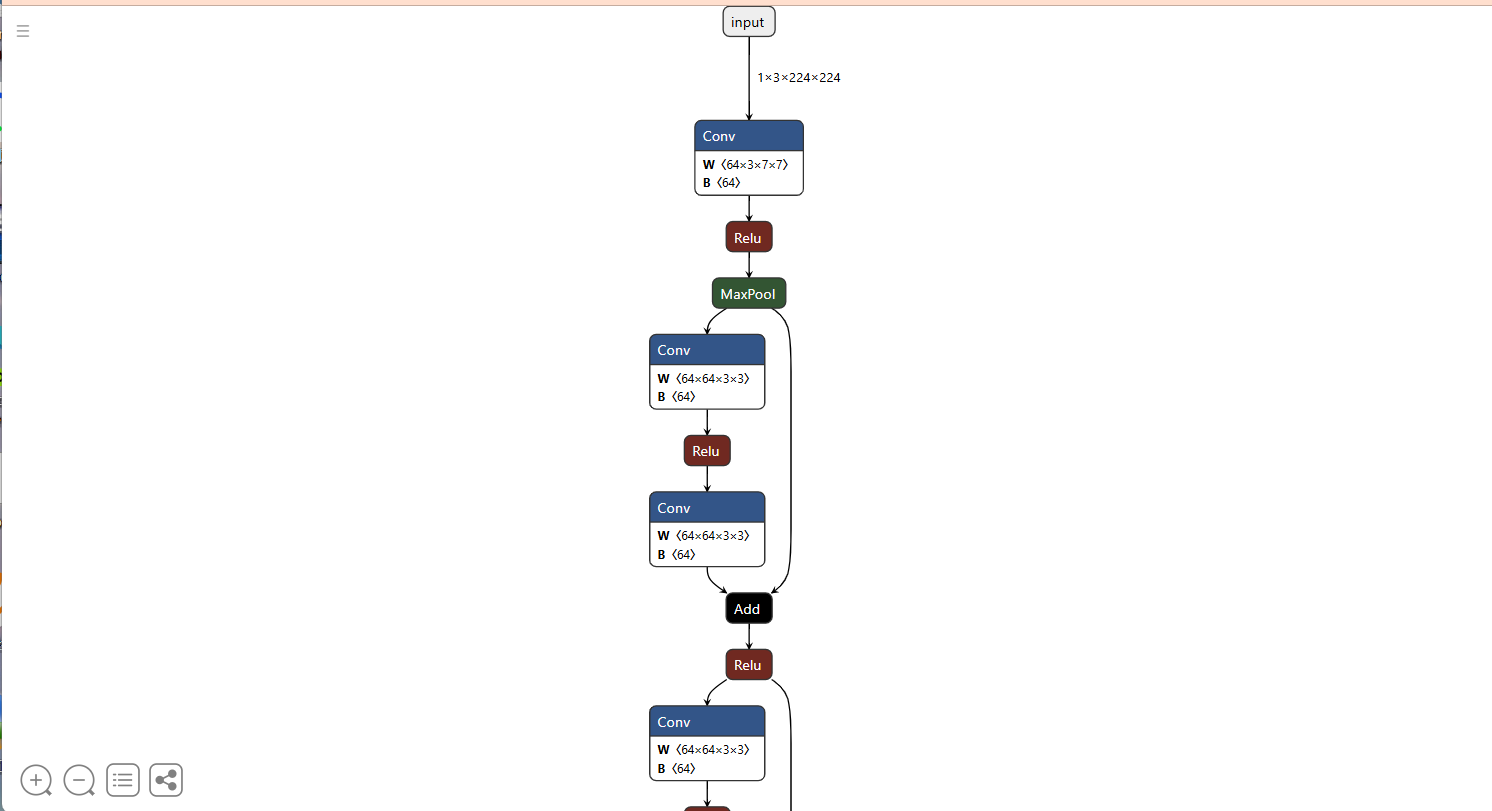
然后就可以看到網絡結構了,這里我只截一部分:
七、ONNX推理
代碼如下:
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import transforms
from PIL import Image
import onnxruntime as ort
import torch#數據預處理
val_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])#加載路徑
img_path = './images/b8_rotten.jpg'
onnx_path = './model/best.onnx'#加載并處理圖片
img = Image.open(img_path).convert("RGB")
img_tensor = val_transforms(img) #經過數據預處理后轉為了tensor
img_np = img_tensor.unsqueeze(0).numpy()
# print(img_tensor.shape) torch.Size([3, 32, 32])#加載onnx模型
sess = ort.InferenceSession(onnx_path)
out = sess.run(None, {"input": img_np})
# print(out)
# [array([[-6.8998175, -8.683616 , -5.1299562, -2.8295422, 8.335733 ,
# -5.098113 ]], dtype=float32)]#后處理
valid_dataset = ImageFolder(root='./Bananas/valid', transform= val_transforms)
valid_loader = DataLoader(valid_dataset, batch_size=64, shuffle=False)
classNames = valid_dataset.classes #拿到類名
# print(classNames)
# ['freshripe', 'freshunripe', 'overripe', 'ripe', 'rotten', 'unripe']logits = out[0]
#用softmax函數將結果轉成0-1之間的概率
probs = torch.nn.functional.softmax(torch.tensor(logits), dim=1)
pred_index = torch.argmax(probs).item()
pred_label = classNames[pred_index]print(f"\n 預測類別為:{pred_label}")
print("各類別概率:")
for i, cls in enumerate(classNames):print(f"{cls}: {probs[0][i]:.2%}")注意傳入ONNX模型的必須是numpy數組。
運行結果:
?

其實感覺預測得有點絕對,但是這個模型的準確率這么高我也是沒想到
八、網絡結構與數據增強可視化
如果想要更直觀地看到訓練變化的話可以加這一步:
import torch
from torch.utils.tensorboard import SummaryWriter
from torchvision.utils import make_grid
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torchvision.models import resnet18
import torch.nn as nn# 可視化配置
writer = SummaryWriter("runs/501_tensorboard")# 網絡結構可視化
print("添加網絡結構圖")
model = resnet18()
model.fc = nn.Linear(model.fc.in_features, 6)
input = torch.randn(1, 3, 224, 224) # ResNet18的輸入尺寸
writer.add_graph(model, input)# 數據增強效果可視化
print("添加數據增強圖像")
# 數據增強方式
train_transforms = transforms.Compose([transforms.Resize((256, 256)), # 先稍微放大點transforms.RandomCrop(224), # 隨機裁剪出 224x224transforms.RandomHorizontalFlip(p=0.5), # 左右翻轉transforms.RandomRotation(degrees=15), # 隨機旋轉 ±15°transforms.ColorJitter(brightness=0.2, # 明亮度contrast=0.2, # 對比度saturation=0.2, # 飽和度hue=0.1), # 色調transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet均值std=[0.229, 0.224, 0.225]) # ImageNet標準差
])# 加載訓練數據集
train_dataset = ImageFolder(root='./Bananas/train', transform= train_transforms)# 寫入3輪不同的數據增強圖像
for step in range(3):imgs = torch.stack([train_dataset[i][0] for i in range(64)]) # 取64張圖grid = make_grid(imgs, nrow=8, normalize=True)writer.add_image(f"augmented_mnist_step_{step}", grid, global_step=step)writer.close()
print("所有可視化完成!")
運行代碼后在終端輸入?tensorboard --logdir=runs,回車后可以看到生成了一個網址,用瀏覽器直接訪問即可,如果不行的話就在 runs 后面加當前文件的絕對路徑,苯人的可視化是這樣:
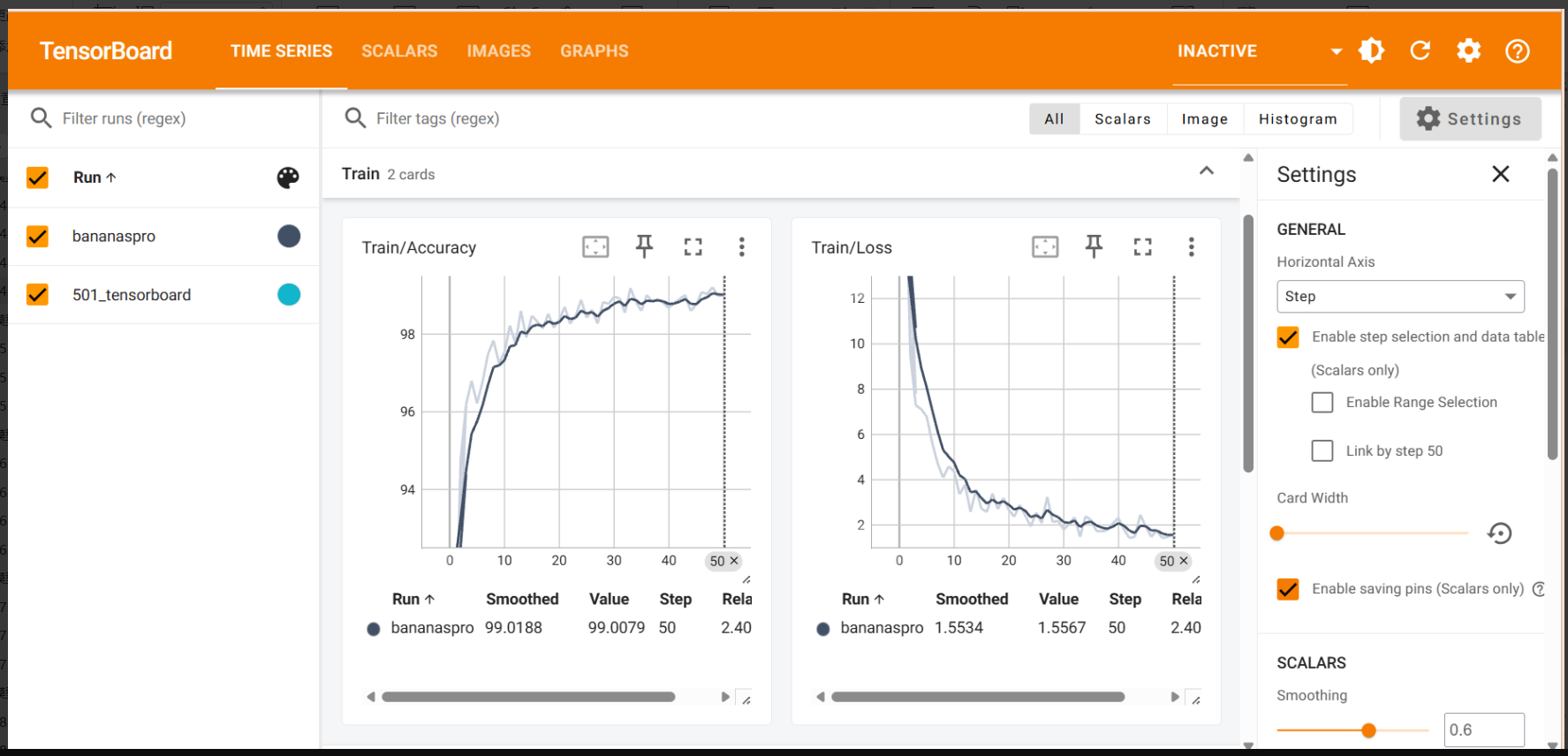
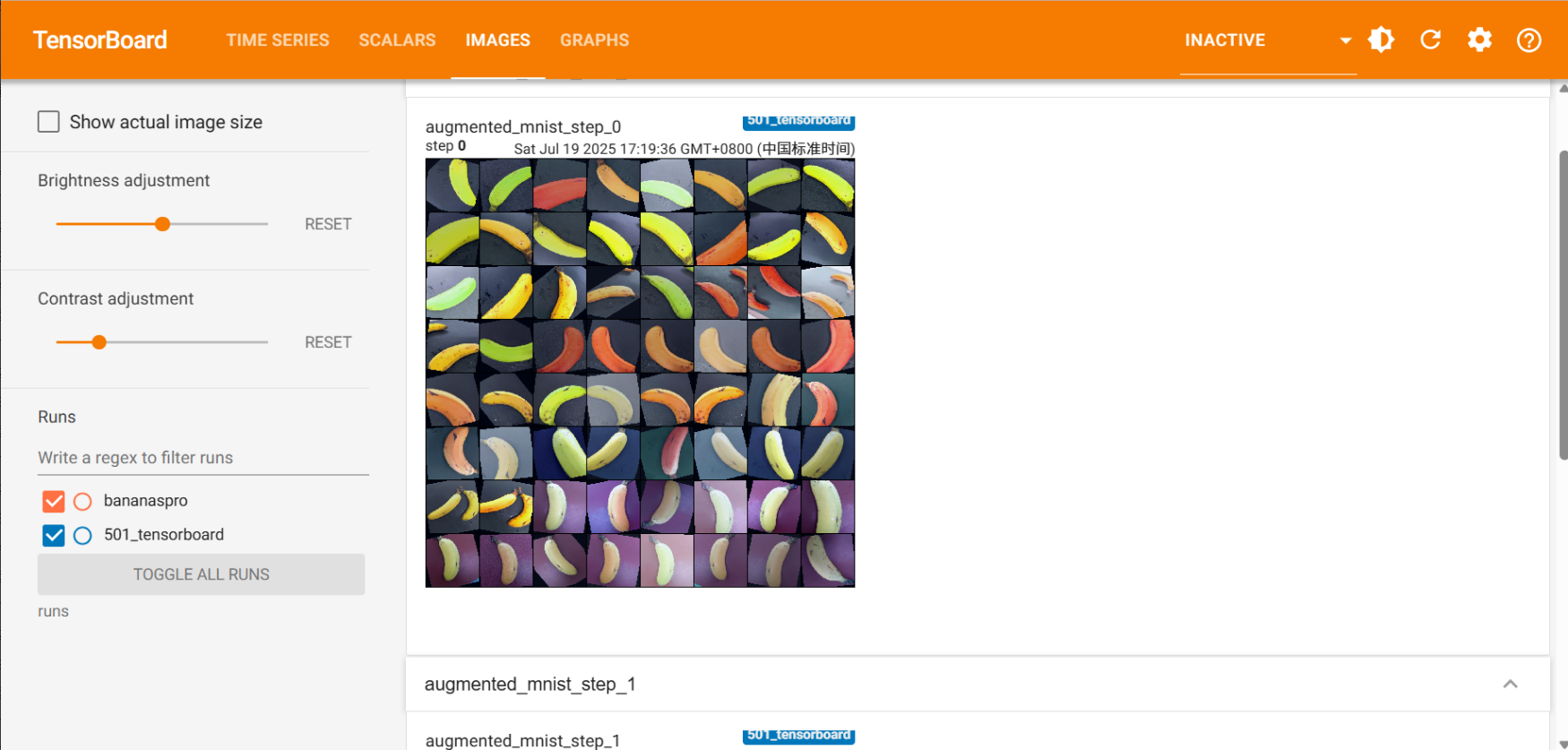
數據增強可視化:?
最后,我整個的項目文件夾長這樣:
對上篇的補充就到此為止,下一篇寫啥也沒想好,前面拖得太多了。。
以上有問題可以指出(??????)??


)







)




![[IMX][UBoot] 16.Linux 內核移植](http://pic.xiahunao.cn/[IMX][UBoot] 16.Linux 內核移植)



