前言
緩存,幾乎是現在互聯網項目中最常見的一種加速工具了。 通過緩存,我們能大幅提升接口響應速度,減少數據庫的訪問壓力,還能支撐各種復雜的業務功能,比如排行榜、風控系統、黑名單校驗等等。
不管你用的是本地緩存,還是像 Redis、Memcached 這樣的分布式緩存,它們和 MySQL 這類數據庫之間,都屬于 “異地、異質存儲” ——也就是說,它們不在一個地方,數據結構和操作方式也不一樣。

這就帶來一個問題:在分布式系統中,我們很難保證數據庫和緩存在更新時 “要么一起成功,要么一起失敗” 。一旦中間出錯,就可能出現數據不一致——數據庫是最新的,但緩存還是舊的;或者緩存更新了,但數據庫失敗了。
為了應對這種情況,業界衍生出了很多種“如何保持緩存和數據庫數據一致性”的解決方案。這些方案在一致性保障、性能開銷等方面各有優缺點。只有我們真正理解了這些方案的原理和適用場景,才能在面對實際復雜業務時,選出最合適的技術路徑。
一、 緩存讀寫策略
在介紹數據庫與緩存一致性方案之前,我們先來看一下經典的三種緩存讀寫策略,這三種策略是出現在計算機系統中的三大基本策略,而數據庫與緩存一致性方案,也是基于這三種策略的思想,進行設計的。
🍎Cache Aside Pattern(旁路緩存模式)
在平時的開發中,我們最常用的一種緩存讀寫策略就是 Cache Aside Pattern(旁路緩存模式)。它特別適合讀多寫少的場景,比如商品詳情頁、用戶資料頁、排行榜等。
這種模式的特點是:緩存不是自動更新的,而是由應用服務自己“旁路”來操作緩存和數據庫。而且,無論緩存和數據庫怎么配合,最終還是以數據庫的數據為準。
📝 寫數據:
- 先更新數據庫:因為數據庫才是最終的數據源,必須先保證它的數據正確。
- 再刪除或更新緩存:確保下一次讀取時不會拿到舊數據。
(有時為了簡單或避免并發問題,寫完數據庫后會選擇“刪緩存”而不是“改緩存”,讓下一次讀請求自動加載最新數據。)
📖 讀數據:
- 先從緩存里查,如果有,就直接返回,速度非常快。
- 如果緩存沒命中(緩存穿透),就去查數據庫;
- 查完數據庫后,再把結果寫入緩存,方便下次讀用。
🍎Read/Write Through Pattern(讀寫穿透)
除了旁路緩存(Cache Aside),還有一種緩存策略叫做 Read/Write Through Pattern,中文通常稱為讀/寫穿透。它的思路是:把緩存當作“主戰場”,應用程序只和緩存打交道,緩存自己負責跟數據庫同步。
也就是說,緩存成了真正的“前線”,數據庫則被藏在了后面,由緩存服務來決定什么時候讀寫數據庫。
這種模式在日常開發中其實不太常見,主要原因是我們常用的 Redis、Memcached 等分布式緩存,本身并不支持自動把數據寫回數據庫。所以這個模式更多出現在一些特定的場景或者緩存服務本身就集成了這種能力的系統中。
📝 寫數據(Write Through):
- 如果緩存中不存在數據,就直接把數據寫入數據庫(有些實現也可能先寫入緩存,然后由緩存去同步數據庫);
- 如果緩存中有數據,就直接更新緩存,由緩存服務自動同步數據到數據庫。
也就是說,寫操作是走緩存 → 緩存再同步到數據庫,這對應用開發者來說是“看不見的”。
📖 讀數據(Read Through):
- 應用先從緩存中讀取數據;
- 如果緩存中沒命中,就自動從數據庫加載,再由緩存服務把數據寫入緩存,最后返回給應用。
在這個模式下,緩存系統不僅是加速器,還是“數據庫代理”,自己負責讀寫落庫邏輯,對調用方來說完全透明。
🔍 和 Cache Aside 有什么區別?
Read/Write Through 和 Cache Aside 看起來很像,但有一個核心差別:
- 在 Cache Aside 模式 中,緩存更新是由客戶端(業務服務)來處理的;
- 而在 Read/Write Through 模式 中,緩存更新是由緩存系統自己處理的,對客戶端是透明的。
可以理解為:Cache Aside 是“你自己去超市買東西”,而 Read/Write Through 是“你告訴助手你要什么,助手幫你搞定所有操作”。
🍎Write Behind Pattern/Write Back(異步緩存寫入/寫回)
除了讀/寫穿透(Read/Write Through),還有一種更激進的緩存寫入策略,叫做 Write Behind Pattern(異步緩存寫入/寫回)。
它和 Read/Write Through 很像,都是由緩存系統來負責數據庫的讀寫工作,但它最大的不同在于寫操作是“先寫緩存,稍后再異步更新數據庫”。
也就是說:應用寫數據時,只寫到緩存里,數據庫并不會立刻更新,而是緩存系統稍后“批量”寫入數據庫。
📝 寫數據(Write Behind):
- 應用將數據寫入緩存;
- 緩存服務暫時保留數據(比如放在內存隊列里);
- 緩存服務在某個時間點,異步地、批量地把數據寫入數據庫。
📖 讀數據:
和其他模式一樣,優先從緩存讀,緩存未命中再從數據庫加載。
?? 優勢與挑戰:
優點:
- 因為數據庫的寫入是延遲+批量的,寫性能非常高;
- 適合高頻更新的場景,比如點贊數、瀏覽量,不需要每次都寫數據庫。
挑戰:
- 數據一致性風險更大:如果還沒來得及寫入數據庫,緩存服務就掛了,那這些數據可能就“丟了”;
- 更復雜的故障恢復和數據容錯機制(比如 WAL、落盤日志、數據回溯等)才能保證安全。
下面針對這三種策略,介紹一些更詳細的方案。
二、緩存一致性方案
CAP
在聊緩存一致性方案之前,我們先來了解一個非常經典的分布式系統理論——CAP 定理,它對我們后續的討論非常關鍵。
CAP 定理,又叫 布魯爾定理(Brewer’s Theorem),是理論計算機科學中關于分布式系統的一個重要結論。它告訴我們:
一個分布式系統,不可能同時滿足以下三件事,只能選其二。
-
一致性(Consistency)
所有節點看到的數據必須是一樣的。你讀到的內容就是最新寫入的結果,哪怕讀的機器不同。 -
可用性(Availability)
每次請求都必須有響應(不能返回超時或錯誤),哪怕返回的不是最新數據。 -
分區容錯性(Partition Tolerance)
系統在網絡分區(比如服務之間通信延遲、網絡中斷)時,仍然能繼續運作。
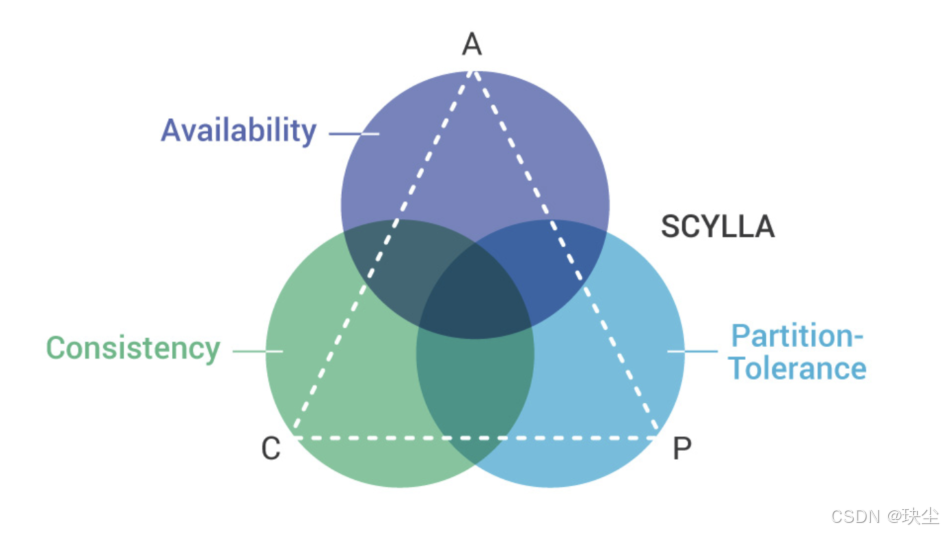
根據定理,分布式系統只能滿足三項中的兩項而不可能滿足全部三項。理解CAP理論的最簡單方式是想象兩個節點分處分區兩側。允許至少一個節點更新狀態會導致數據不一致,即喪失了C性質。如果為了保證數據一致性,將分區一側的節點設置為不可用,那么又喪失了A性質。除非兩個節點可以互相通信,才能既保證C又保證A,這又會導致喪失P性質。
而對于我們的緩存架構來說,分區容錯性是我們必須保證的,那么,這是否代表,一致性和可用性無法同時保證呢?
讓我們帶著這個疑惑,來看一下緩存一致性方案。
2.1 Cache Aside Pattern
更新DB,再更新緩存
這種方式雖然保證了數據庫數據的準確性,但也可能引發緩存和數據庫不一致的問題。
舉一個例子來說明:
假設有兩個請求「A」和「B」,幾乎同時對同一條數據進行更新。
- 請求 A 先執行,將數據庫中的數據更新為 1;
- 然而,還沒來得及更新緩存,請求 B 又將數據庫的數據更新為 2,并緊接著更新緩存為 2;
- 此時,A 繼續完成它的流程,把緩存又更新成了 1。
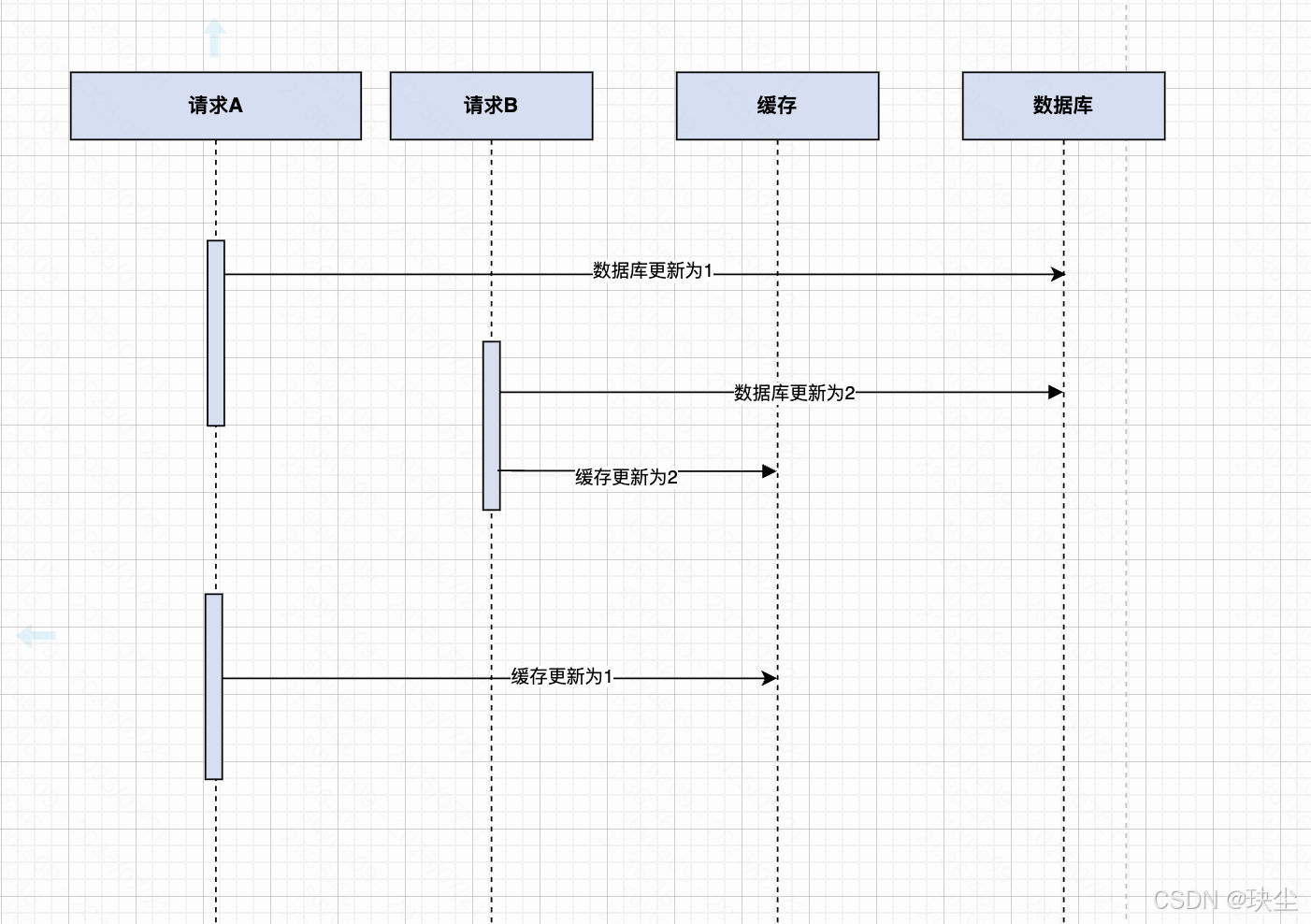
最終,數據庫的值是 2,而緩存中卻是舊值 1 —— 出現了明顯的數據不一致問題。
這種現象,從專業角度來看,就是一種臟寫(Dirty Write):
即后寫入的較新數據被前一個舊寫操作覆蓋,造成數據倒退。
在高并發寫操作的場景下,這種問題極容易發生,嚴重時可能導致業務邏輯混亂,數據紊亂。
更新DB,再刪除緩存
既然更新緩存會導致臟寫問題,那我們是否可以選擇不寫緩存、只刪除緩存,讓讀請求時自動重建緩存,從而避免臟寫?看似可行,但這是否就萬無一失了呢?
來看下面這個場景:
- 請求A先去讀緩存,發現緩存未命中,讀取數據庫的值為20
- 與此同時,請求B更新數據庫的值為21
- 請求B繼續刪除緩存
- 請求A回設緩存值為20
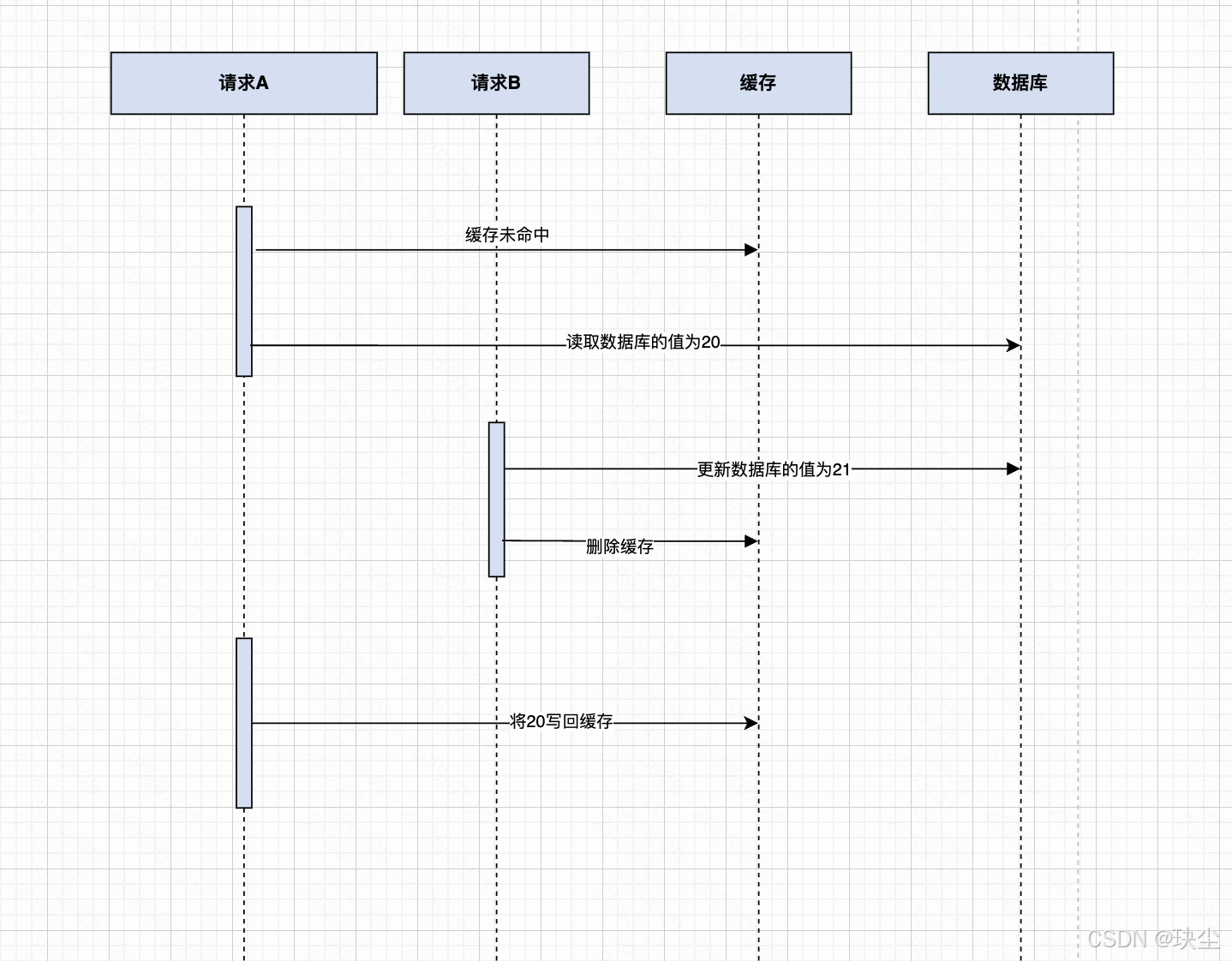
最終結果:
- 數據庫是 21
- 緩存是 20(請求 B 刪除后導致緩存重建為舊值)
這就是典型的臟讀問題:請求順序錯亂導致舊值覆蓋新值。
雖然理論上存在這個問題,但在實際中它的發生概率非常低。因為:
- 數據庫讀操作通常比寫操作快;
- 如果請求 A 在請求 B 之前完成了緩存寫入,那請求 B 的刪除操作不會影響后續的數據一致性;
- 即使不一致,也只是短暫的,后續請求會從數據庫中重新拉取數據。
總結:
- 這種「先更新數據庫,再刪除緩存」的方式可以大概率保證數據一致性;
- 配合合理的緩存過期時間,可實現最終一致性。
但還沒完,另一個風險點是:刪除緩存失敗。
如果數據庫更新成功,但緩存刪除失敗,舊緩存仍然存在,導致數據不一致。這是分布式系統中典型的部分成功問題。
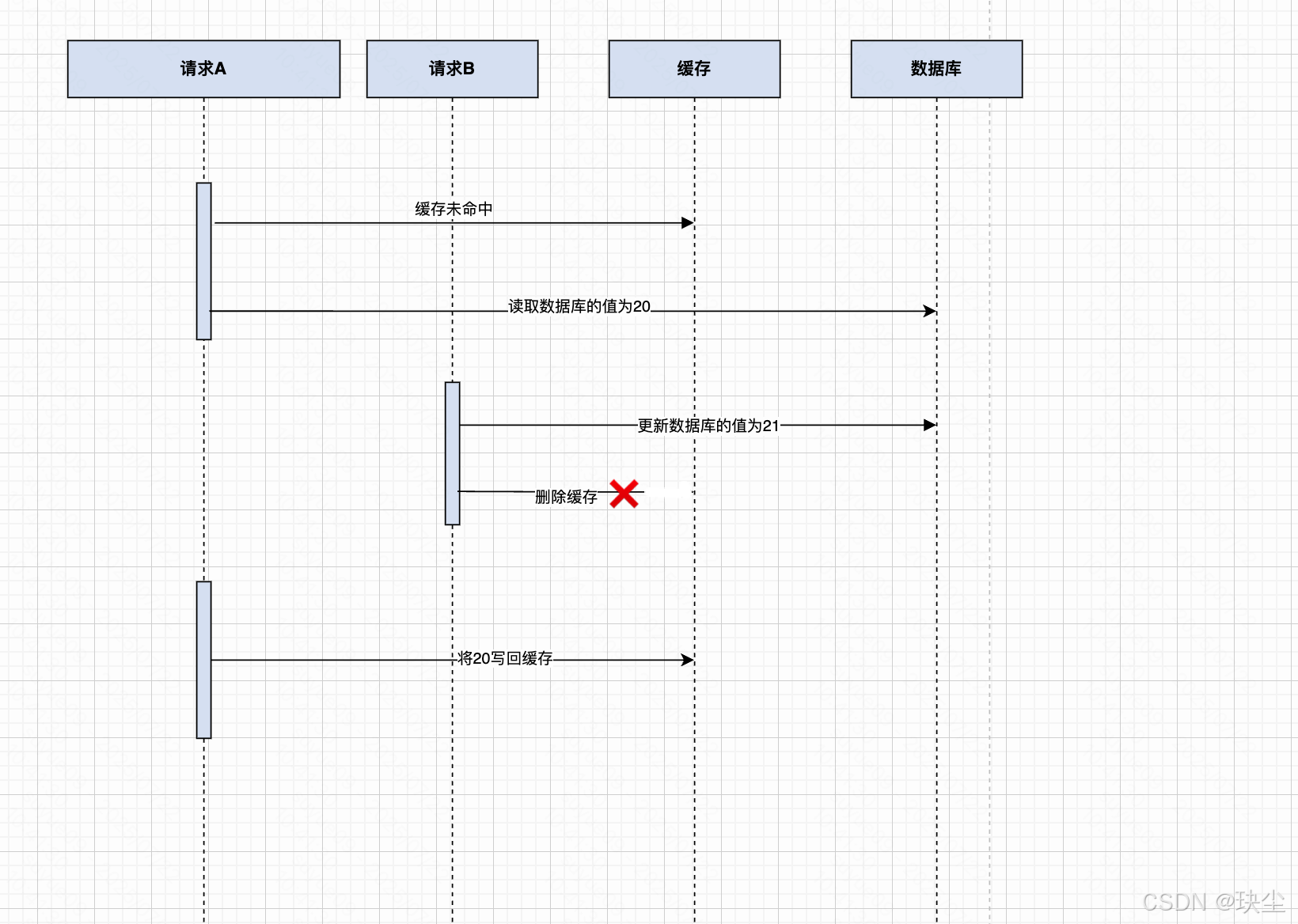
如何解決?
- 重試機制雖然可以一定程度緩解,但難以控制重試次數,太少不穩,太多影響接口響應時間;
- 更優方案是:異步可靠刪除緩存。
做法是:
- 將刪除緩存操作寫入消息隊列或任務隊列中,由后臺服務異步拉取并執行;
- 配合失敗重試與日志告警機制,確保緩存刪除最終成功。
這樣既保證了數據一致性,又不會阻塞主業務流程,是更推薦的實踐方式。
更新DB,異步刪除緩存
我們在更新數據庫后刪除緩存時,可以通過異步方式來處理緩存刪除操作。常見的異步實現方式包括以下三種:
- 線程池異步執行刪除任務
- 消息隊列異步投遞刪除請求
- 基于數據庫 Binlog 日志消費(如 Canal)
前兩種方式雖然常用,但它們對業務代碼侵入較大:每當更新數據庫時,開發者都必須顯式編寫刪除緩存的邏輯,容易遺漏、維護成本高。
相比之下,基于 Binlog 的異步刪除方式是當前業界較為推薦的方案。其核心流程如下:
- 數據庫完成寫入
- Canal 監聽 Binlog 日志變化并解析
- 將變化內容發送到消息隊列
- MQ 消費者接收到消息,觸發緩存刪除
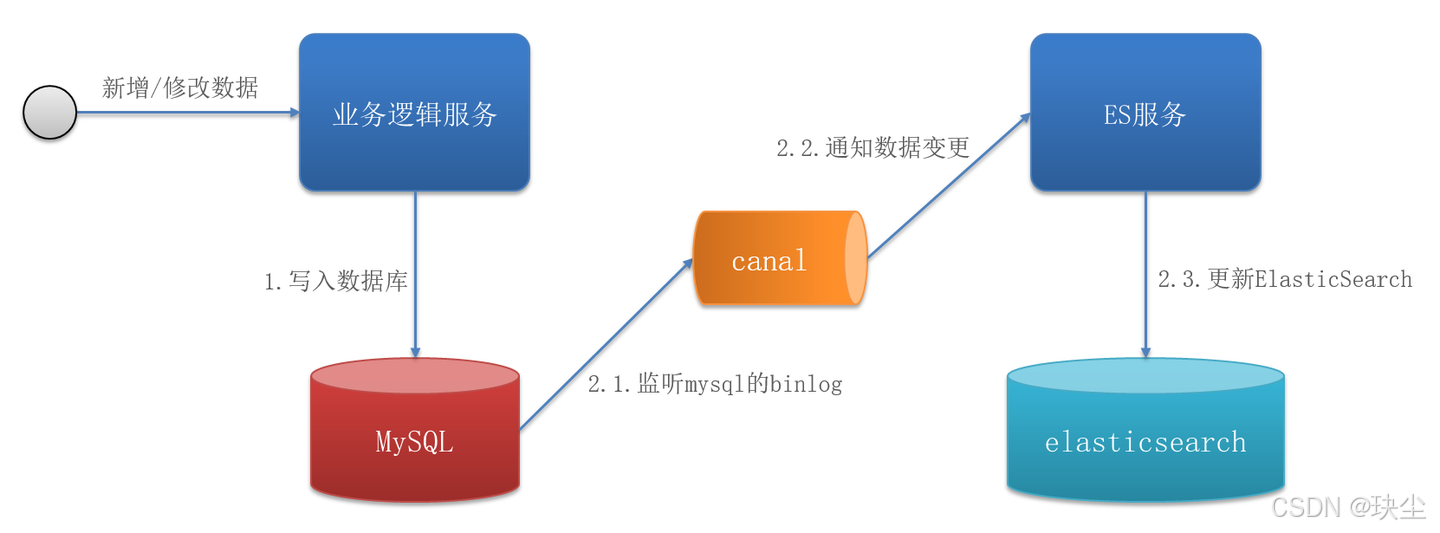
由于 MQ 的可靠投遞機制,能大幅提升緩存刪除的成功率,從而增強緩存與數據庫的一致性。
延伸思考
1. 為什么選擇刪除緩存而不是更新緩存?
因為更新緩存容易產生并發亂序問題。例如:一個舊值覆蓋了新值,造成臟寫,難以控制。而刪除緩存是冪等操作,天然具備更好的一致性保障。
2. 有沒有辦法不刪除緩存也能解決臟寫?
有,比如加分布式鎖,通過串行化更新操作防止亂序。但分布式鎖使用復雜、對性能影響大,一般只在強一致場景中才推薦。
3. 刪除緩存是否也有副作用?
是的,主要有兩點:
- 刪除后首次訪問會觸發緩存重建,若是熱點數據(hotkey),可能造成緩存擊穿。
- 一部分請求會落到數據庫,導致緩存命中率下降,影響性能表現。
4. 異步機制會有什么問題?
異步天然存在延遲,在這段時間內,緩存和數據庫可能處于不一致狀態。不過通常這種不一致窗口較小,可通過優化消費速率、重試機制等方式緩解。
2.2 Read/Write Through Pattern
雖然這種策略看起來與旁路緩存(Cache Aside Pattern)類似,但兩者之間還是存在一些區別。最主要的不同點在于:該方案并不是由業務邏輯直接控制緩存的寫入,而是由專門的緩存服務(如 CacheSetter)負責完成緩存回源與更新。
正因為如此,這種策略更多的是一種架構層面的演進,并不是一種新的緩存一致性策略,因此我們在本文中不再對其展開詳細討論。
2.3 Write Behind Pattern
在前文中,我們介紹了多種緩存一致性策略,而這一節要討論的“先更新緩存,異步更新數據庫”的方式,則屬于Write Behind(異步緩存寫入/寫回)模式,它與前述策略的最大區別是:只更新緩存,不立即更新數據庫,而是通過異步手段,延遲、批量地將數據刷新到數據庫中。
寫流程:
- 客戶端寫入請求直接更新緩存;
- 同步或異步地將修改寫入隊列(如消息隊列、內存隊列);
- 后臺線程池 / MQ 消費者 / 定時任務從隊列中批量取出數據寫入數據庫。
讀流程:
- 優先從緩存中讀取數據;
- 若緩存不存在,則從數據庫讀取,并同步回寫緩存。
該方案的優勢在于:
- 寫吞吐能力強:所有寫操作都直接打到緩存,極大減輕數據庫寫壓力;
- 數據即時可讀:用戶寫入后立刻可讀緩存,體驗更好;
- 適合高并發寫入場景:如秒殺庫存、日志上報、計數器類應用等。
??存在的風險與缺陷:
- 數據庫和緩存可能不一致:緩存中的數據是最新的,而數據庫是延遲更新;
- 數據可能丟失:如果緩存宕機、消息隊列丟失消息、服務重啟等,都可能導致更新未寫入數據庫;
- 一致性難以保障:特別在關鍵業務中,數據丟失可能帶來嚴重問題。
方案對比匯總
| 策略 | 存在問題 | 優點 | 適用場景 |
|---|---|---|---|
| 更新數據庫 → 更新緩存 | 并發可能導致臟寫 | 緩存命中率較高 | 對一致性要求不高,注重命中率 |
| 更新數據庫 → 更新緩存(加鎖) | 分布式鎖影響性能 | 保證強一致性 | 寫請求較少,強一致性場景 |
| 更新數據庫 → 刪除緩存 | 命中率略降,少數并發異常可能 | 簡潔,最終一致性好 | 主流方案,適用于大多數業務 |
| 更新數據庫 → 異步刪除緩存 | 有延遲窗口,不是強一致 | 性能優,兼顧一致性和吞吐 | 主流推薦方案,適合大多數系統 |
| 更新緩存 → 異步更新數據庫 | 數據可能丟失,無法保障一致性 | 寫性能極強,延遲低 | 日志、計數器、非關鍵業務 |
三、真實業務中的緩存一致性實踐
某手緩存方案
在某手,目前主流的緩存架構方案是將數據庫中的熱點數據寫入到 Memcached中,以加速讀請求,降低數據庫壓力。為確保緩存與數據庫之間的數據一致性,采用的是 Cache Aside Pattern(旁路緩存模式) 的一種變種策略:
即在數據更新時,先更新數據庫,再通過異步方式消費 binlog 日志,刪除或更新對應緩存。
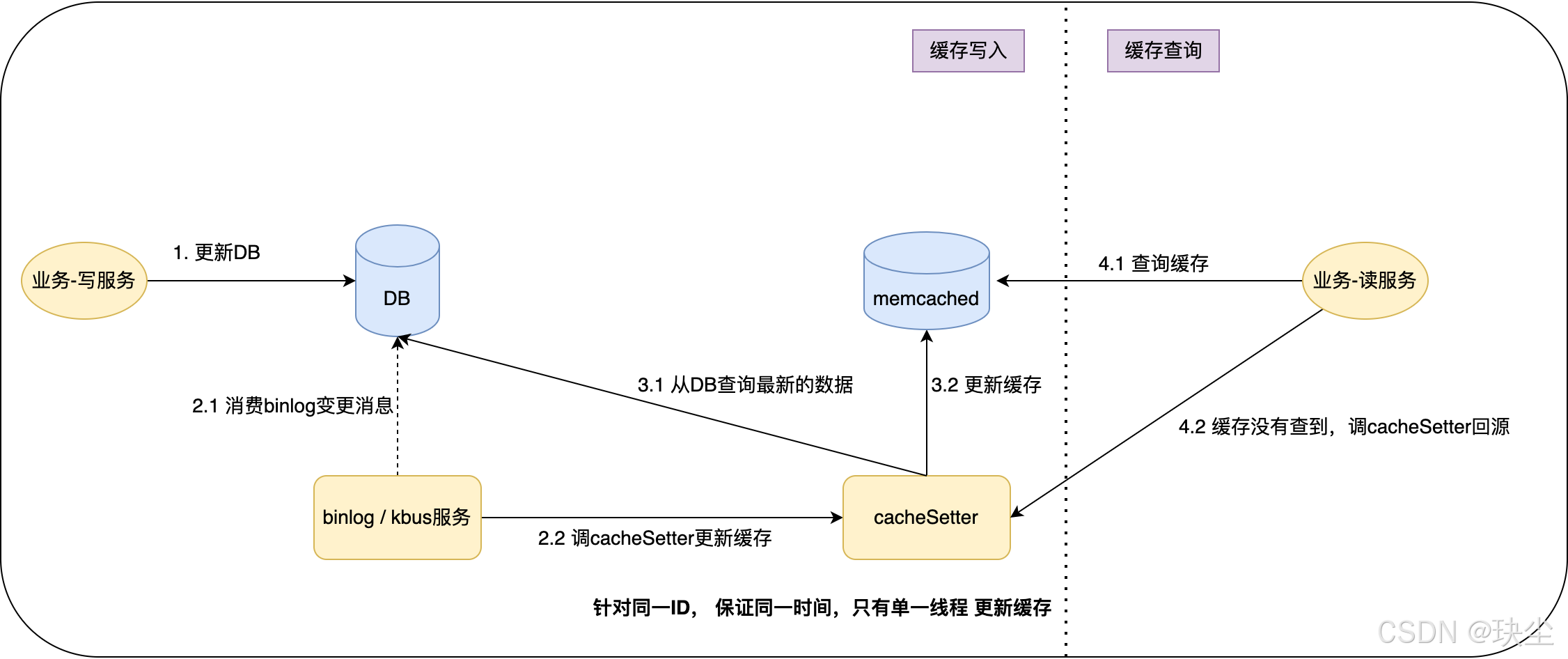
📖 讀流程
- 先查緩存:優先從緩存(Memcached)中查詢目標數據。
- 未命中則回源:如果緩存未命中,則調用
CacheSetter服務進行回源。 - 讀取并更新緩存:CacheSetter 從數據庫中讀取最新數據并更新緩存,再返回結果。
?? 寫流程
- 更新數據庫:應用服務處理用戶寫請求,直接更新數據庫。
- 寫請求結束:數據庫更新成功后,用戶請求結束。
- 異步同步緩存:
- kbus 服務監聽數據庫 binlog 變更;
- 收到變更后,異步調用
CacheSetter; CacheSetter再從數據庫中讀取最新值,更新緩存。
? CacheSetter 如何保證緩存一致性?
由于異步更新存在并發修改緩存的可能,CacheSetter 被設計為一個特殊的 RPC 服務,核心職責是 在高并發場景下,避免緩存更新過程中的“臟寫”問題,確保最終一致性。
CacheSetter 保證針對同一id,同一時間,只有單一線程,在更新緩存,因此可以 避免并發問題 ,可以保證了緩存的 最終一致性 。
具體機制包括:
- 同 ID 路由固定:客戶端請求使用一致性Hash算法,確保相同 ID 的請求路由到固定的
CacheSetter實例,避免多實例并發更新同一份緩存。 - 并發訪問收斂:
CacheSetter內部通過CountDownLatch等并發控制手段,確保同一時刻對于同一 ID 的并發 load 請求,只會命中一次DB,其他線程等待結果復用即可。
當一臺實例上一個key已經在進行load的操作的時候,如果這時候又有這個key的請求要load cache,此時這次請求的這個key將不會在進行load操作。CacheSetter會為某個key分配一個 CountDownLatch ,當某個key請求CacheSetter時,會先檢查下當前是否為這個key分配了CountDownLatch,如果已經分配了,說明這個key已經在loading了,就不再執行load操作了,只會通過CountDownLatch.await,在這個key load完成之后再返回;如果沒有分配,就創建一個新的CountDownLatch,并將id和該CountDownLatch保存到map,等到load操作執行完,會執行CountDownLatch.countDown操作,并從map中移除該key和對應的CountDownLatch。
當然,這種方案依賴于異步 binlog 消費流程,所以不能保證實時一致性,但在大多數讀多寫少的場景下效果良好。
四、總結:緩存與數據庫一致性策略的本質與抉擇
在每種方案中,我們結合其在一致性與性能方面的權衡,明確了各自適用的業務場景。通過對比可以看出,緩存與數據庫一致性問題的根本原因主要有兩個:
- 指令亂序問題:即多個請求之間操作缺乏原子性保障;
- 分布式系統中的不確定性:包括網絡失敗、節點宕機等,導致單個請求的多個操作無法組成原子事務。
所有的一致性方案,實質上就是圍繞著如何緩解這兩大問題,進行策略設計與技術落地。
回到最初的問題:CAP 中的 C 和 A 是否能兼得?
經過前文的分析可以發現,在實際場景中:
- 當追求強一致性(Consistency)時,往往需要加鎖、順序執行或等待異步流程完成,帶來的副作用就是性能下降,可用性降低;
- 而當強調可用性(Availability)與高性能時,則必然在一致性上做出一定讓步,常見的表現如最終一致性或順序一致性等。
寫在最后
緩存與數據庫一致性問題沒有“銀彈”式的完美解決方案。所有架構設計都是權衡的藝術。技術選型和策略制定,應該回歸到業務的實際需求、系統的承載能力、以及對一致性與性能的優先級判斷上。
愿本文內容,能為你在系統設計與架構演進過程中提供一些參考與思考。
五、參考文獻:
CAP-Wiki百科
三種常用的緩存讀寫策略詳解
數據庫和緩存如何保證一致性
緩存和數據一致性問題,看這篇就夠了













)

)

)
)
