1.什么是事務
????????事務就是進行多個操作,要么同時執行成功,要么同時執行失敗。
2.事務的特性 - ACID特性
2.1原子性Atomicity
????????原子性(Atomicity):當前事務的操作要么同時成功,要么同時失敗。原子性由undo log日志來實現。
????????在事務中,如果SQL進行了一個減庫存的操作,例如由5扣減為2,在執行這個SQL語句時會使用undo log日志進行記錄一個庫存2到5的日志,如果失敗拋出異常就會執行這條SQL語句。
2.2一致性Aconsistency
????????一致性(Consistency):使用事務的最終目的,由其它3個特性以及業務代碼正確邏輯來實現。
2.3隔離性Isolation
2.3.1什么是隔離性
????????隔離性(Isolation):在事務并發執行時,他們內部的操作不能互相干擾,隔離性由MySQL的各種鎖以及MVCC機制來實現。
????????在InnoDB引擎中,定義了四種隔離級別供我們使用,級別越高事務隔離性越好,但性能就越低,而隔離性是由MySQL的各種鎖以及MVCC機制來實現的。
????????1.read uncommit(讀未提交):臟讀。
????????2.read commit(讀已提交):不可重復讀。
????????3.repeatable read(可重復讀):幻讀。
????????4.serializable(串行):解決上面所有問題,包括臟寫。
????????MySQL的事務隔離性默認使用的是repeatable read(可重復讀)
2.3.2讀未提交
????????在read uncommit(讀未提交)的隔離級別下,會產生臟讀現象。
????????臟讀:事務A讀取到事務B已經修改但是尚未提交的數據。
????????一般不會使用這種隔離級別,這種隔離級別危機太多了。
2.3.3讀已提交
????????在read commit(讀已提交)的隔離級別下,會產生不可重復讀的現象。
????????不可重復讀的意思是,A事務在多次讀取一個數據時,如果B事務在過程中對數據進行修改,并提交,A事務讀到的數據會發生變化。
2.3.4可重復讀
????????在repeatable read(可重復讀)的隔離級別下,會產生幻讀的現象。
????????執行的機制:在事務開啟后,當執行了事務中第一條查詢語句之后,MySQL中所有記錄在事務中都有一條快照了,讀取數據時都是讀取快照中的數據,由此來實現的可重復讀。
????????還需要注意的是,如果在當前事務對數據進行了修改,下次再讀取的時候就會使用修改后的值,其他未修改的數據還是讀取快照中的數據。并且修改的時候,不會用快照的數據,而是真實的數據。
????????由于該機制,A事務在執行完第一天查詢語句后,讀取的數據都是當時快照的數據,無論其他數據如何修改,在事務中讀取的都是快照里的數據。
????????而且還會出現幻讀的現象,幻讀現象就是事務A讀取到了事務B剛新增的數據。
????????有人說可重復讀解決了幻讀現象,也有人說可重復讀沒有解決幻讀現象,這個是需要去分情況討論的。現在同時啟動A和B兩個事務,假設A進行了一次查詢操作,B事務在該表中進行了添加數據操作并提交了事務,這樣A事務再去讀取該表的數據時,由于A事務可重復讀的機制,讀取的數據是快照數據,則不會讀取到B事務添加的數據,就不會產生幻讀現象。但是如果A在開啟事務后,查詢了數據后,B事務去再去添加數據的時候,A事務再次去查詢就會查詢到B事務新增的數據,這樣就會產生幻讀現象。
2.3.5臟寫現象
????????讀未提交、讀已提交、可重復讀都可能會出現臟寫現象。
????????臟寫的意思是,由于隔離級別的問題,讀取的數據是有問題的數據,但是還是在Java中對該數據進行處理后,并寫入到了數據庫中,此時寫入的數據是個錯的數據。
2.3.5.1讀未提交出現臟寫的原因
????????讀未提交會出現臟寫現象是因為,事務A和事務B一起開啟了,事務B進行對數據修改了多次,但是事務B并沒有進行提交,事務A此時讀到了事務B未提交的數據,但是在事務A讀取后,事務B進行了回滾,但是事務A用錯誤的數據,進行了操作,并更新到數據庫,由此就會發生一次臟讀事件。
2.3.5.2讀已提交出現臟寫的原因
????????讀已提交會出現臟寫現象是因為,事務A和事務B一起開啟了,事務B進行對數據修改了多次,但是由于事務B沒有進行提交,事務A讀取到的數據永遠是原始的數據,事務A對數據進行了操作,并提交,事務B此時用事務A未提交之前的數據進行修改,并更新到數據庫,由此會發生一次臟讀事件。
2.3.5.3可重復讀出現臟寫的原因
????????可重復讀會出現臟寫現象是因為,事務A和事務B一起開啟了,事務A查詢了一次數據,事務B對該數據進行了多次修改,并提交,事務A又讀取了一次數據,讀取到的數據是快照數據,并沒有讀取到事務B提交后的數據,并且事務A對該次讀取的數據進行了修改,并提交到數據庫,由此會發生一次臟讀事件。
2.3.5.4解決臟寫的方案:悲觀鎖
????????悲觀鎖解決方案,可以解決讀未提交、讀已提交和可重復讀三種隔離級別的情況。
????????解決臟寫可以采用的方法是采用悲觀鎖,每次更新的時候,使用SQL語句進行更新,而不是使用查詢到的數據,在業務代碼中進行修改后直接更新替換數據。
????????代碼如下:
UPDATE account SET balance = balance + 500 WHERE id = 1;2.3.5.5解決臟寫的方案:樂觀鎖
????????樂觀鎖的解決方案,可以解決讀未提交和讀已提交兩種隔離級別的方案。
????????解決臟寫可以采用的方法是,給表格額外加一個version字段,每次更新的時候,WHERE篩選時加上自己上次查詢出的版本號,如果更新成功就沒事,更新失敗就繼續重新查詢再更新,做一個自旋操作。
????????代碼如下:
UPDATE account SET balance = balance WHERE id = 1 AND version = 1;2.3.6串行化讀取
????????在串行(serializable)情況下,這是最高的隔離級別,解決了以上所有的問題。
????????串行化的機制就是,當A事務開啟后,其隔離級別是serializable時,A事務只要對某個數據表進行了查詢操作,其他任務對該表的增加/更新操作都會被卡住,直到A事務提交/回滾。
????????這種方式解決了臟寫和幻讀的問題了,因為串行化對某個表進行讀取操作后,其他針對該表的新增/刪除/修改操作在串行化事務提交之前都會被阻塞住。
????????串行化的實現原理:
????????串行化的實現原理其實十分簡單,在串行化事務中,執行是查詢SQL語句會自動加一個讀鎖,由于讀鎖是共享的,當添加上這個讀鎖之后,對這個表再進行讀取操作時,是沒問題的,但是如果進行增加/修改/刪除操作,就會被卡住,知道讀鎖釋放。
????????查詢的語句:
SELECT * FROM account WHERE id = 1;????????該語句實際執行的時候,執行的SQL語句如下:
SELECT * FROM account WHERE id = 1 lock in share mode;????????一般不會去使用串行化這種方案,因為這個方案的性能太差了,整體并發量低。
2.3.7讀寫鎖
????????剛剛提到串行化隔離級別是使用讀寫鎖實現的,所以現在具體介紹一下讀寫鎖。
????????讀鎖(共享鎖、S鎖):SELECT ... LOCK IN SHARE MODE;
????????讀鎖是共享的,多個事務可以同時讀取同一個資源,但是不允許其它事務修改。
????????寫鎖(排它鎖、X鎖):SELECT ... FOR UPDATE;
????????寫鎖是排他的,會阻塞其他的寫鎖和讀鎖,UPDATE、DELETE、INSERT都會加寫鎖。
2.4持久性Durability
????????一旦提交了事務,它對數據庫的改變就應該是永久性的。持久性由redo log日志來實現。
????????MySQL保證持久性是通過redo log日志機制實現的,先來看MySQL更新一條數據的整體流程:
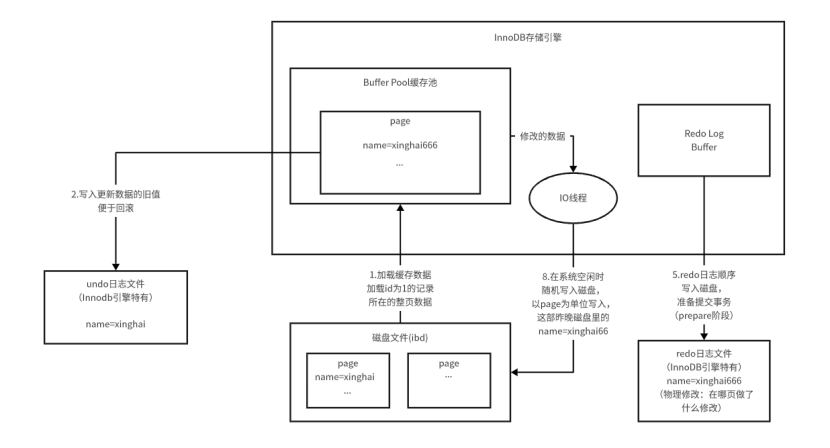
????????InnoDB引擎在執行一條寫數據的操作的時候(假設現在進行的是更新操作),首先會從磁盤中加載需要修改的數據,再將數據寫入到undo日志中(方便進行回滾),下一步并不是直接去修改表中的數據,而是將數據寫入到redo日志中,最后才通過異步IO線程將數據更新到磁盤文件中。
????????之所以MySQL要做這個操作,完全是因為將數據寫入到redo日志中進行的是磁盤順序寫的操作,而寫入到表中的時候,由于多個表分布在多個文件中,無法進行磁盤順序寫,所以MySQL才會先將數據寫入到redo日志中,對于機械硬盤來說,磁盤順序寫的性能提升很高,寫入速度特別快。之所以要利用磁盤順序寫快速寫入數據,是因為MySQL為了保證持久性,由于將數據寫入到磁盤中是一個比較耗時的操作,如果中間出現突發情況,MySQL崩掉了,數據就會丟失,無法保證持久性,但是redo log是磁盤順序寫,性能非常高,所以可以保證持久性。
3.初識MVCC機制
3.1什么是MVVC機制
????????事務分為RNC,RC,RR,Serializable四種,一般來說不會使用Serializable隔離級別,因為該隔離級別雖然安全性很高,但是其性能堪憂,所以一般在真正的項目落地時,都會采用RC和RR這兩種隔離級別,因為這兩種隔離級別可以保障讀寫的并發,所有操作并非都是串行的,可以提高整體的并發量。
????????疑問點:RC和RR事務隔離級別在操作同一條數據的時候,是如何做到讀寫并發的呢?需不需要串行化呢?讀寫操作到底先執行讀呢還是先執行寫呢?
????????以上提到的疑問點就是讀寫并發問題,MySQL使用MVVC機制解決了讀寫并發問題。
????????MVVC(Multi-Version Concurrency Control)多版本并發控制,可以做到讀寫不阻塞,且避免了類似臟讀這樣的問題,主要是通過undo日志鏈來實現的。
????????SELECT操作時快照讀(讀取歷史版本)
????????INSERT、UPDATE和DELETE是當前讀(讀取當前版本)
????????Read Commit(讀已提交):語句級快照。
????????Repeatable Read(可重復讀):事務級快照。
3.2MVVC機制的執行流程
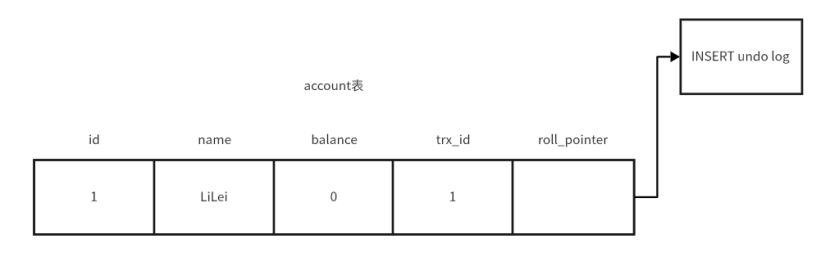
????????MySQL在每張數據表中維護了兩個字段,其中一個字段是trx_id,即最后操作這條數據的事務ID,還有一個字段是roll_pointer,這個字段是回滾指針,該指針指向的是回滾日志,如果事務進行了回滾操作,就會通過數據行中的roll_pointer回滾指針,找到回滾日志,完成回滾操作。
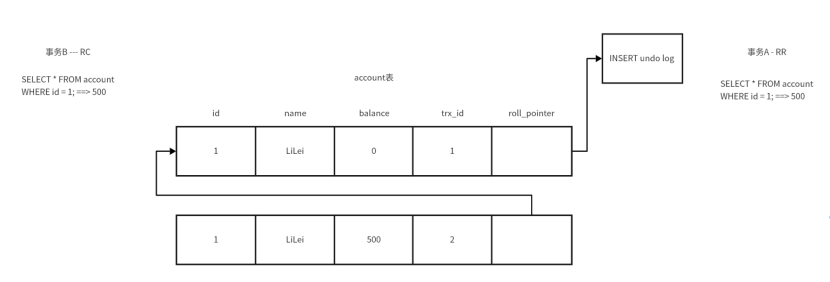
????????假設現在有一個數據表是account表,首先對account表進行一個插入操作,進行了插入操作之后,會講操作account表的事務ID存儲到數據行的trx_id字段中,并且會生成一個undo log日志,roll_pointer會指向該undo log。
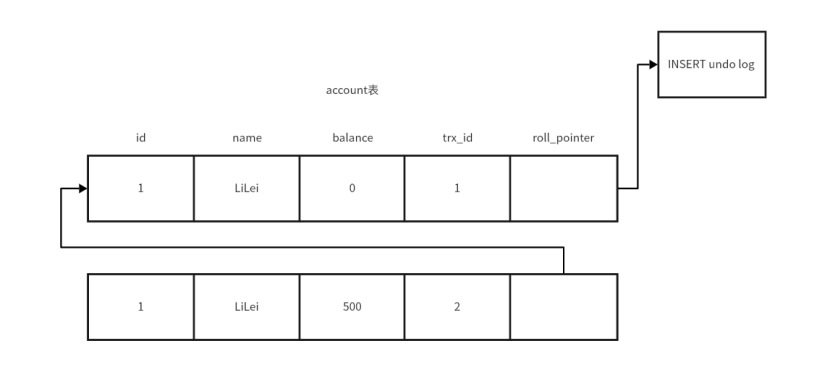
????????又有一個事務對數據行進行了操作,將數據行中的balance進行修改為500,此時會將數據行的trx_id進行替換,并又生成了一個undo log,并將roll_pointer指向該undo log,最后事務完成了提交,完成提交后,會有一個commited標志指向該數據行。
????????假設現在啟動了兩個事務,事務A和事務B,事務A是RR可重復讀隔離級別,事務B是RC讀已提交隔離級別,此時兩個事務同時執行查詢該數據行的操作,最終查詢出的數據均為500。
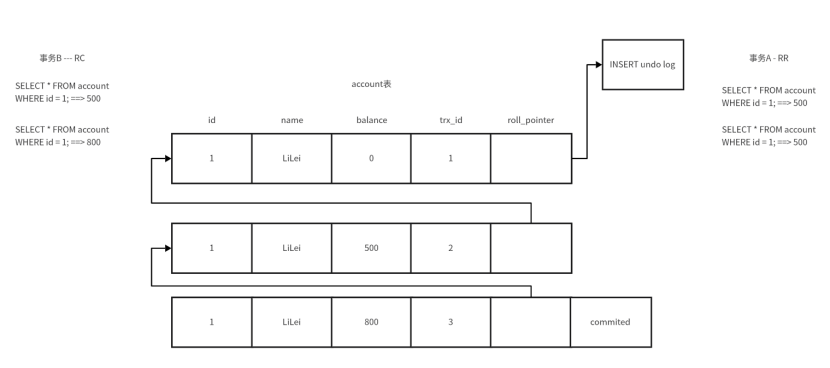
????????此時又有事務對該數據行進行了操作,將balance修改為800,并進行了提交。事務A再進行查詢的時候,由于RR的機制導致器讀取到的數據是500,事務B讀取數據時,由于其永遠讀取的是已提交的數據,所以讀取到的數據是800。
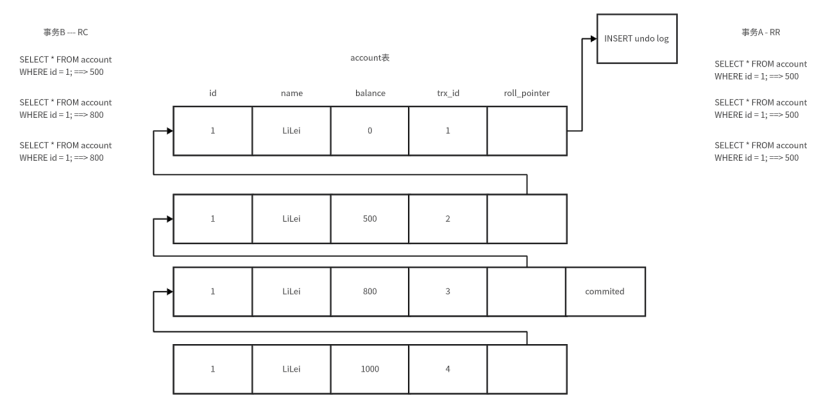
????????事務對該數據行再次進行了操作,將balance更新為1000但是沒有提交,所以事務A和事務事務B再進行查詢時保持原有數據不變。
3.3undo日志鏈
????????從整個MVVC機制的執行流程中可以發現,無論是查詢,回滾,是否提交等操作都是通過該鏈完成的,這樣不僅節省了空間(不是每一個日志都要生成一個undo log),還保證了讀寫的并發性,提高了整體的性能。
4.如何選擇適合隔離級別
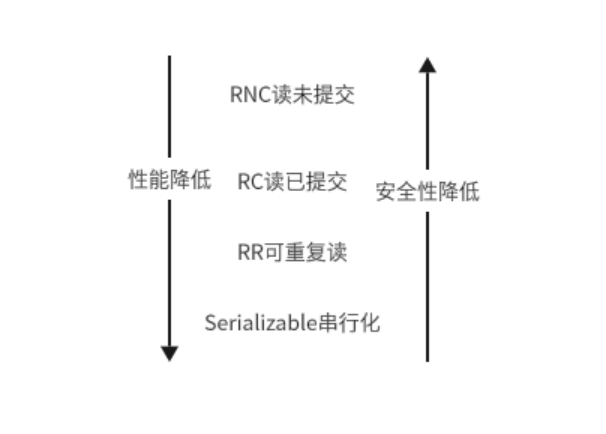
????????對于MySQL中四種隔離界別,RNC讀未提交,RC讀已提交,RR可重復讀,Serilizable串行化,這四種隔離級別,性能從高到低,安全性從低到高,一般在實際生產落地的環境中不會使用到RNC讀未提交,因為這種方式雖然性能很高,但是安全性特別差,會出現臟讀現象,所以一般不會使用這種隔離級別。對于Serializable串行化隔離級別,一般在生產環境中也不會使用這種隔離級別,因為這種隔離級別安全性雖然很高,但是性能實在是太差了。
????????在開發時,一般只會采用RC讀已提交和RR可重復讀這兩種隔離級別。對于一些并發量要求不是巨大的系統,一般都是直接采用MySQL默認的隔離級別RR可重復讀即可,但是對于一些互聯網公司而言,如果需要很高的性能,會考慮采用RC讀已提交這種隔離級別,因為這種隔離級別只會對寫進行加事務,RR這種隔離級別會對讀寫都會加事務,所以相對來說RC的性能會更高一些。
????????在實際事務選型時,需要根據當前業務場景進行分析選型。需要對讀操作加事務的時候,可以采用RR事務隔離級別來保證事務內讀數據時,讀取出的數據在同一時間維度。如果不需要對讀操作進行加事務的操作,可以根據需要考慮使用RC事務級別。
5.大事務的影響及事務優化手段
????????并發情況下,數據庫連接池容易被撐爆。
????????由于事務在使用的時候,會占據著MySQL的一個鏈接,如果此時的并發特別高,且事務都非常大,每個事務需要占據著數據庫連接很長一段時間,那么就會導致數據庫連接池的連接全部被用完,最終數據庫的連接池被撐爆。
????????鎖定太多的數據,造成大量的阻塞和鎖超時。
????????如果事務鎖定了太多的數據,比如事務進行了多次update操作,UPDATE是會加鎖的,加的鎖會阻塞其他的事務對數據進行操作,其他事務會一直等待,但是如果事務特別大,讓其它事務等待的時間過久,最終就會導致大量的阻塞和鎖超時的事件發生。
????????執行時間長,容易造成主從延遲。
????????由于大事務的執行時間比較長,如果此時MySQL是主從多節點,就可能會出現主從延遲。
????????回滾所需要的時間比較長。
????????由于大事務中對數據庫的操作比較多,所以一旦其中發生的錯誤,需要回滾的操作也會更多,這就導致了回滾所需要花費的時間比較長。
????????undo log膨脹。
????????大事務中對數據庫的操作比較多,很多操作都會記錄undo log日志,所以整條undo log日志鏈會膨脹,導致占用的空間較大。
????????容易導致死鎖。
????????大事務中對數據庫的操作比較多,很有可能引發死鎖的出現。
5.2事務的優化實踐原則
????????將查詢等數據準備操作放到事務外。
????????如果查詢操作需要使用RR隔離級別保證查詢到的數據在同一時間維度時,是需要將查詢操作放在事務內,但是如果查詢操作不需要保證查詢的數據在同一時間維度,使用RC隔離級別時,是可以將查詢準數據的操作放到事務外的。
????????事務中避免遠程調用,遠程調用要設置超時,防止事務等待時間太久。
????????事務中進行執行業務代碼的時候,是需要避免遠程調用的,因為遠程調用的接口的時間控制是不好控制的,如果等待時間過長,事務會膨脹為大事務,所以不能將遠程調用放置在事務內,或者為遠程調用設定超時時間。
????????事務中避免一次性處理太多數據,可以拆分為多個事務分次處理。
????????事務中如果一次性處理太多數據,事務可能會成為大事務,導致出現各種各樣的問題,所以建議將事務拆分為多個事務分批次處理。
????????更新等涉及加鎖的操作盡可能放在事務靠后的位置。
????????更新加鎖操作是需要放在最后的,并且要放在Insert的后面,雖然Update和Insert兩個操作都會加鎖,但是Update加鎖的時候會導致其他操作改行數據的操作卡住,但是Insert不會,因為沒有插入的數據是不可能被其他事務操作的,自然不會出現卡住的現象
- 能異步處理的盡量異步處理。
- 應用側(業務代碼)保證數據一致性,非事務執行。
????????如果系統對于性能的要求非常高,可以考慮使用try...catch等操作替代事務,使用業務代碼實現事務的回滾功能,這樣會顯著提升性能。









)







 視頻教程 - 用戶注冊實現)

:機器學習圖像特征與描述)