大家好,我是愛醬。本篇將會系統地講解隨機森林(Random Forest)的原理、核心思想、數學表達、算法流程、代碼實現與工程應用。內容適合初學者和進階讀者,配合公式和可視化示例。
注:本文章含大量數學算式、詳細例子說明及大量代碼演示,大量干貨,建議先收藏再慢慢觀看理解。新頻道發展不易,你們的每個贊、收藏跟轉發都是我繼續分享的動力!
注:隨機森林(Random Forest)與決策樹(Decision Tree)息息相關,因此不了解決策樹的同學建議先去了解一下,愛醬也有文章深入探討決策樹,這里也給上鏈接。
傳送門:
【AI深究】決策樹(Decision Tree)全網最詳細全流程詳解與案例(附Python代碼演示)|數學原理、案例流程、代碼演示及結果解讀|ID3、C4.5、CART算法|工程啟示、分類、回歸決策樹-CSDN博客
一、隨機森林是什么?
隨機森林是一種集成學習(Ensemble Learning)方法,通過構建大量“去相關”的決策樹,并將它們的預測結果進行集成,提升整體模型的準確率和魯棒性。
-
本質:多個決策樹的集成,每棵樹都是在“有放回抽樣”的數據子集和“隨機特征子集”上訓練得到。
-
任務類型:既可用于分類(Classification),也可用于回歸(Regression)。
-
優點:高準確率、抗過擬合、對異常值和噪聲魯棒、可處理大規模高維數據。
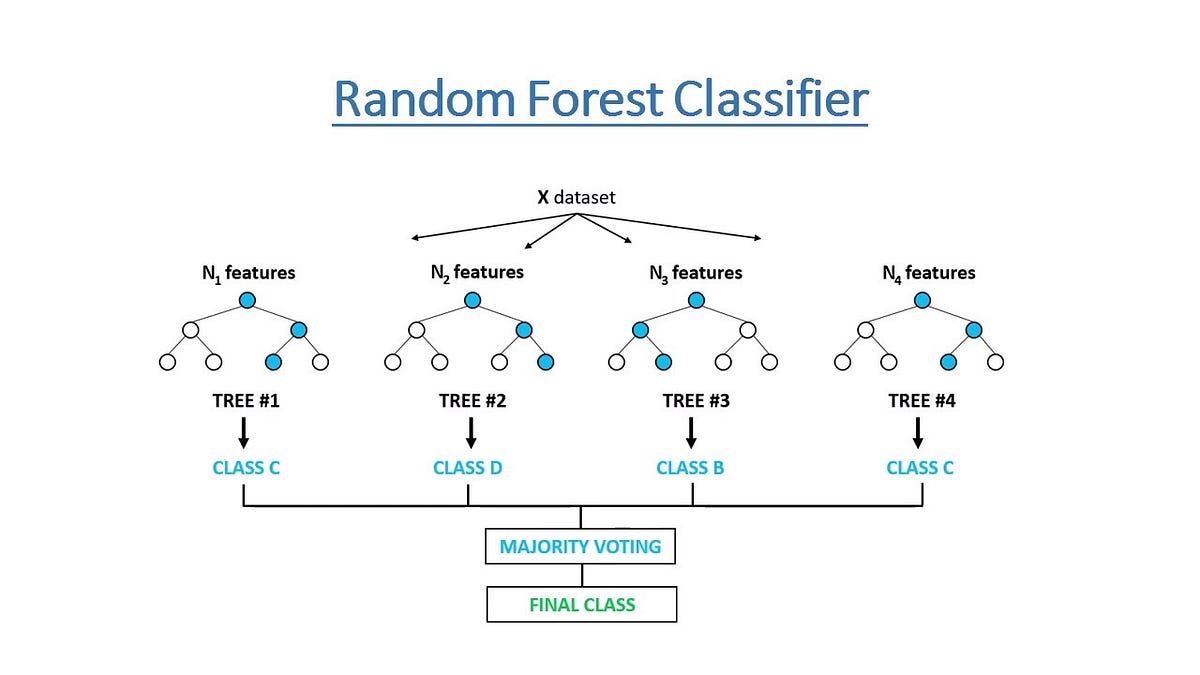
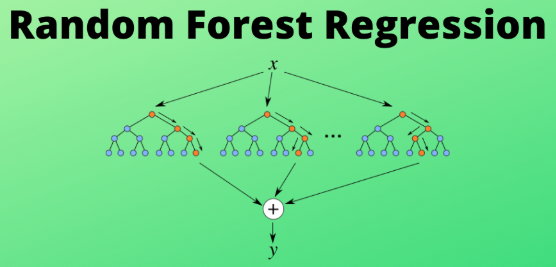
二、隨機森林的核心思想
1. Bagging(Bootstrap Aggregating)
-
有放回抽樣:從原始訓練集隨機采樣
次,得到
個不同的訓練子集(每個子集大小等于原始數據,可重復)。
-
每個子集訓練一棵決策樹,各樹之間相互獨立。
2. 隨機特征選擇(Feature Bagging)
-
每次分裂節點時,不是用全部特征,而是從所有特征中隨機選取
個特征,再從這
-
這樣可進一步增加樹之間的差異性,降低整體模型的方差。
三、隨機森林的數學表達
1. 分類任務
-
隨機森林由
對輸入
做出預測。
-
最終預測為多數投票結果:
2. 回歸任務
-
最終預測為所有樹預測值的平均:
四、隨機森林的算法流程
-
數據采樣:對原始訓練集做
-
訓練樹模型:對每個子集訓練一棵決策樹,每次節點分裂時隨機選擇部分特征。
-
集成預測:
-
分類:所有樹投票,選擇票數最多的類別。
-
回歸:所有樹預測值取平均。
-
-
模型評估:可用OOB(Out-Of-Bag)樣本評估模型性能,無需額外驗證集。
五、隨機森林的主要參數與調優
-
n_estimators:森林中樹的數量,通常越多越好,但計算成本增加。
-
max_features:每次分裂時考慮的最大特征數,分類默認
,回歸默認
。
-
max_depth:樹的最大深度,防止過擬合。
-
min_samples_split / min_samples_leaf:分裂所需的最小樣本數,控制樹的生長。
-
oob_score:是否使用袋外樣本評估模型泛化能力。
六、隨機森林的代碼實現與可視化
1. 分類隨機森林代碼示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score# 加載Iris數據集
iris = load_iris()
X, y = iris.data, iris.target# 訓練隨機森林分類器
rf = RandomForestClassifier(n_estimators=100, max_depth=3, random_state=0, oob_score=True)
rf.fit(X, y)# 預測與評估
y_pred = rf.predict(X)
print("訓練集準確率:", accuracy_score(y, y_pred))
print("OOB分數:", rf.oob_score_)# 可視化特征重要性
plt.bar(range(X.shape[1]), rf.feature_importances_)
plt.xticks(range(X.shape[1]), iris.feature_names, rotation=45)
plt.ylabel('Feature Importance')
plt.title('Random Forest Feature Importance (Iris)')
plt.tight_layout()
plt.show()
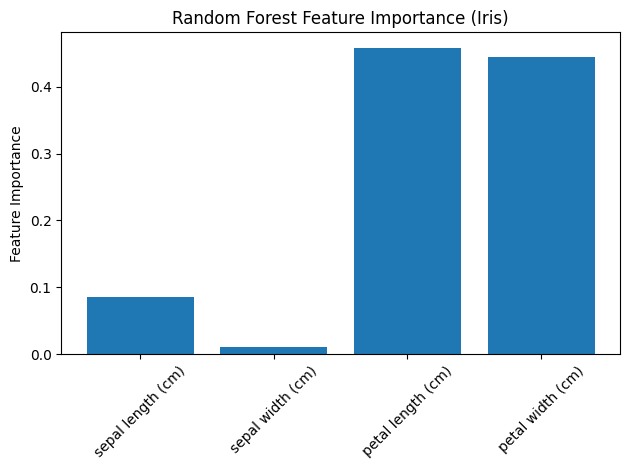
代碼說明:
-
用Iris數據集訓練100棵樹、最大深度為3的隨機森林分類器。
-
輸出訓練集準確率和袋外分數(OOB score)。
-
可視化特征重要性,展示每個特征對模型決策的貢獻。
2. 回歸隨機森林代碼示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor# 生成一維回歸數據
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel() + 0.2 * rng.randn(80)# 訓練隨機森林回歸器
rf_reg = RandomForestRegressor(n_estimators=100, max_depth=3, random_state=0)
rf_reg.fit(X, y)# 預測與可視化
X_test = np.linspace(0, 5, 200)[:, np.newaxis]
y_pred = rf_reg.predict(X_test)plt.figure(figsize=(8, 5))
plt.scatter(X, y, color='darkorange', label='Training data')
plt.plot(X_test, y_pred, color='navy', label='Random Forest Regression')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Random Forest Regression Example')
plt.legend()
plt.show()
?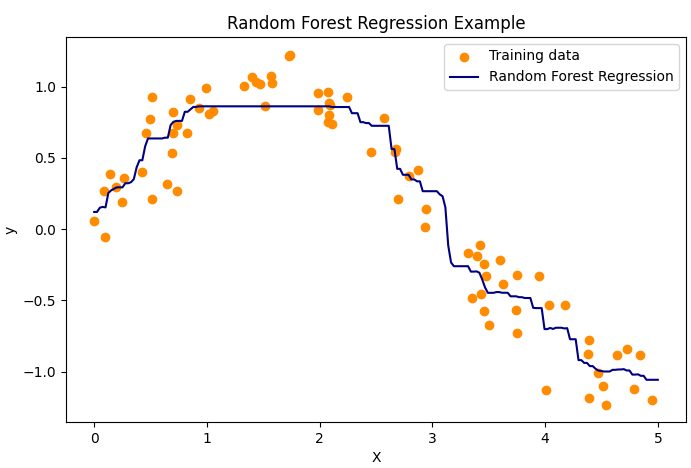
代碼說明:
-
用帶噪聲的正弦數據訓練100棵樹的隨機森林回歸器。
-
可視化回歸曲線,顯示隨機森林對非線性關系的強大擬合能力。
七、隨機森林與單棵決策樹的對比
| 特點 | 單棵決策樹 | 隨機森林 |
|---|---|---|
| 模型結構 | 一棵樹 | 多棵樹集成 |
| 擬合能力 | 易過擬合 | 抗過擬合,泛化能力強 |
| 魯棒性 | 對噪聲敏感 | 對噪聲和異常值魯棒 |
| 可解釋性 | 強,易于可視化 | 較弱,需看特征重要性 |
| 計算成本 | 低 | 高(樹多,需并行/分布式實現) |
| 主要應用 | 基線模型、規則挖掘 | 主流分類/回歸、特征選擇 |
八、隨機森林的優缺點
優點:
-
高準確率,抗過擬合,泛化能力強。
-
對異常值和噪聲數據魯棒。
-
可處理高維數據和大規模數據集。
-
可評估特征重要性,輔助特征選擇。
-
支持并行計算,易于擴展。
缺點:
-
單棵樹可解釋性強,隨機森林整體可解釋性較差。
-
訓練和預測速度較慢,尤其是樹數量多時。
-
對于極度稀疏或高相關特征,提升有限。
九、實際應用與工程建議
-
分類與回歸:適合金融風控、醫學診斷、客戶流失預測、價格預測等多種場景。
-
特征選擇:利用特征重要性排序,篩選關鍵變量。
-
異常檢測:通過樹的投票分布識別異常樣本。
-
集成學習基線:作為強基線模型,常用于Kaggle等數據競賽。
-
工程建議:
-
合理設置樹的數量和深度,防止過擬合和計算資源浪費。
-
使用OOB分數快速評估模型泛化能力。
-
可結合GridSearchCV等工具自動調參。
-
十、結論
隨機森林作為集成學習的代表算法,憑借其高準確率、強魯棒性和廣泛適用性,已成為機器學習和數據科學領域的主流方法。它不僅能有效提升模型性能,還能輔助特征工程和異常檢測。理解隨機森林的原理、調參方法和工程應用,有助于你在實際項目中高效落地和持續優化模型。
如需進一步講解隨機森林與Boosting方法的對比、集成學習原理、或實際案例分析,歡迎繼續提問!
謝謝你看到這里,你們的每個贊、收藏跟轉發都是我繼續分享的動力。
如需進一步案例、代碼實現或與其他聚類算法對比,歡迎留言交流!我是愛醬,我們下次再見,謝謝收看!

)




)












