摘要:基于Yue等學者2019年發表的權威綜述,本文系統總結情感分析的技術框架、實戰資源與前沿方向,附Python代碼示例。
一、情感分析為何重要?
情感分析(Sentiment Analysis)旨在從文本中提取主觀態度,在商業、政治、公共安全領域價值顯著:
-
商業決策:電商評論分析(如“電池續航長但機身太重”)驅動產品優化
-
政治預測:Twitter情緒分析成功預測歐盟選舉傾向(德語區39%積極 vs 5%消極)
-
公共安全:阿拉伯之春期間社交媒體情緒預警社會動蕩
論文案例:2016年澳大利亞聯邦選舉中,對61萬條推文的空間情感分析準確預測聯盟黨領先10%
二、三大技術視角解析
1. 任務導向(Task-Oriented)
| 任務類型 | 典型方法 | 實踐建議 |
|---|---|---|
| 情感極性分類 | SVM/樸素貝葉斯(Pang et al. 2002) | 結合NLTK+VADER庫 |
| 細粒度方面提取 | 雙傳播算法(Qiu et al. 2011) | SpaCy依存解析+規則過濾 |
| 時空情感分析 | STWS地理語言指紋模型 | 需融合GPS與文本特征 |
# 使用VADER進行情感極性分析
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
text = "The picture quality is amazing but battery drains too fast"
print(analyzer.polarity_scores(text)) # 輸出: {'neg': 0.211, 'neu': 0.508, 'pos': 0.281, 'compound': -0.177}2. 粒度導向(Granularity-Oriented)
-
文檔級:適用于整體評價(如亞馬遜產品評論)
-
句子級:處理復雜語義(反諷識別:SASI算法)
-
詞級:依賴情感詞典(SentiWordNet/NTUSD)
實戰陷阱:文檔級分析在跨領域時準確率下降40%(Blitzer et al. 2007),建議采用SFA特征對齊
3. 方法導向(Methodology-Oriented)
| 學習范式 | 代表算法 | 適用場景 |
|---|---|---|
| 監督學習 | CNN-LSTM混合模型(Tang 2015) | 標注數據充足時 |
| 半監督學習 | 協同訓練(Co-Training) | 標注成本高場景 |
| 無監督學習 | 情感詞典+規則推理 | 領域專業知識驅動 |
三、實戰資源清單
1. 核心數據集
| 數據集 | 規模 | 特點 | 獲取方式 |
|---|---|---|---|
| TSentiment15 | 2.28億條推文 | 2015全年跨領域數據 | 學術申請 |
| Amazon Product Reviews | 4領域各2000樣本 | 標注精細含方面標簽 | 公開下載 |
| MPQA | 692文檔 | 標注主觀表達式及情感源 | 官網 |
2. 工具與詞典
-
綜合工具包:
-
LingPipe(支持命名實體與情感聯合抽取)
-
SentiStrength(社交文本強度分析,支持多語言配置)
-
-
領域專用詞典:
-
金融領域:Financial Sentiment Dictionary
-
中文場景:NTUSD(臺大情感詞典,含2812積極詞)
-
四、未來突破方向:多模態情感分析
傳統文本分析的局限性催生多模態融合:
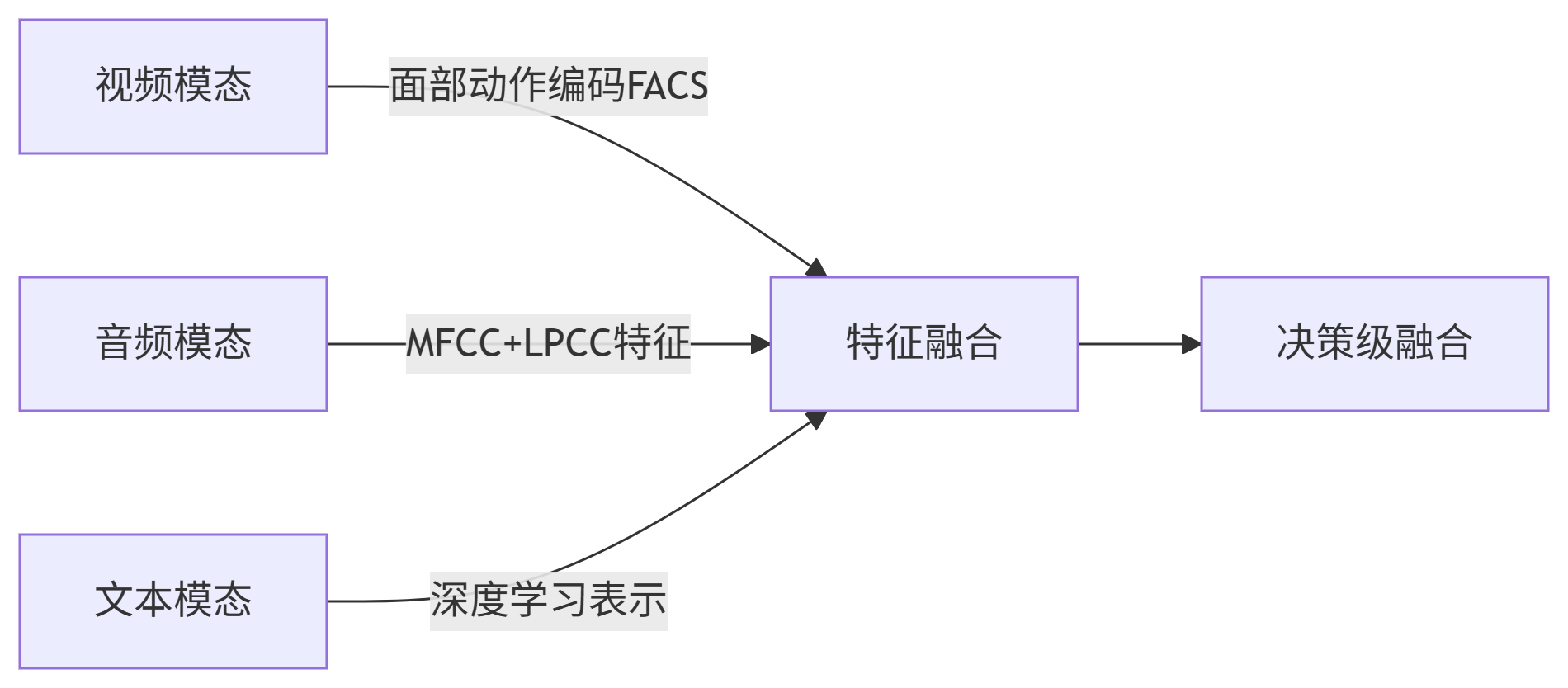
?
-
前沿進展:
-
多模態數據集ICT-MMMO(視頻+音頻+文本)
-
特征融合模型:Convolutional MKL(Poria et al. 2016)
-
-
待解難題:
-
模態缺失場景的魯棒性(如僅視頻無音頻)
-
跨文化情感表達差異
-
五、結語
情感分析正從單一文本走向多模態融合。研究者需關注:
-
領域適應:跨領域情感詞典遷移(如醫療評論分析)
-
細粒度解析:方面級情感聯合抽取
-
實時系統:Twitter/抖音流數據處理
論文啟示:情感分析需結合心理學與社會學(如PAD情緒模型),純工程視角難以突破深層語義瓶頸













)


)
|SVM-拉格朗日函數求解上)

