云監控介紹:
阿里云的云監控服務(CloudMonitor)是一款簡單易用、功能強大的監控工具,主要用來幫助用戶實時監控阿里 云上的各種資源(比如服務器、數據庫、網絡等),并在出現問題時及時發出警報,確保業務穩定運行。
1.打開阿里云,找到對應服務
點擊立即開通
2.在控制臺找到云監控服務
開通云主機監控策略
為需要監控的主機安裝Agent,點擊自動安裝Agent
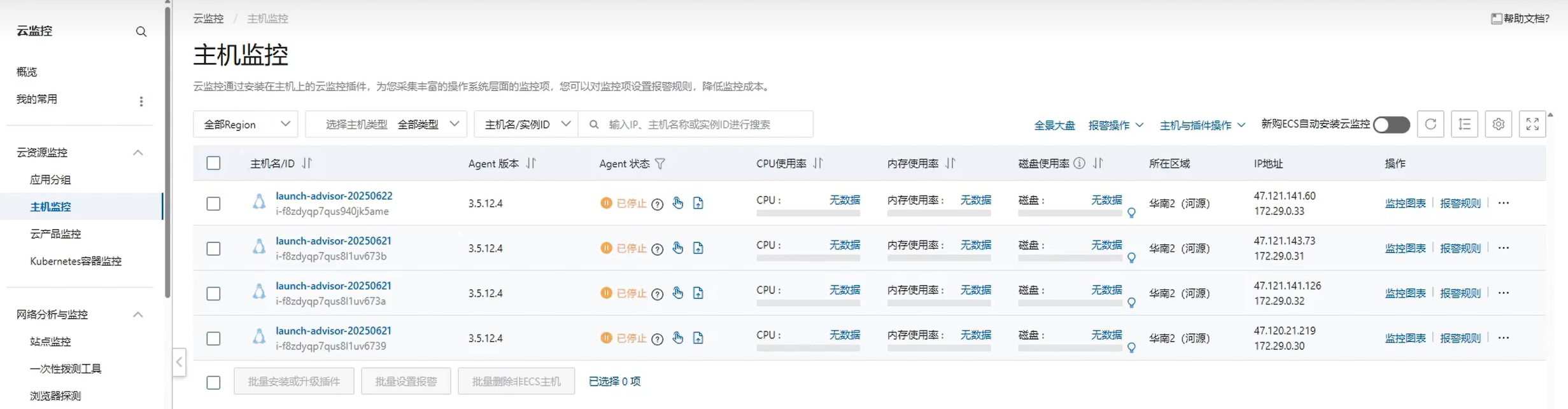
等待片刻, 重新刷新對應的CPU使用率、內存使用率、磁盤使用率的數據即可出現
系統報警服務配置
云監控中的報警服務規則配置的主要目的是幫助用戶實時監控阿里云資源、線下IDC、其他云廠商產品或自定義監 控數據的運行狀態,并在監控指標達到預設條件時,自動觸發報警通知。通過這種方式,用戶可以及時獲取異常信息 并 快速采取措施,確保業務系統的穩定性和可靠性。
1:設置報警聯系人
報警聯系人: 當觸發條件后,需要通知相關人員, 這些對應的人員信息需要提前錄入
2:設置報警聯系組
報警聯系組:多個聯系人合并為一個組, 不同的類型可以單獨設置為組,告警的時候可以直接針對多個用戶同時告警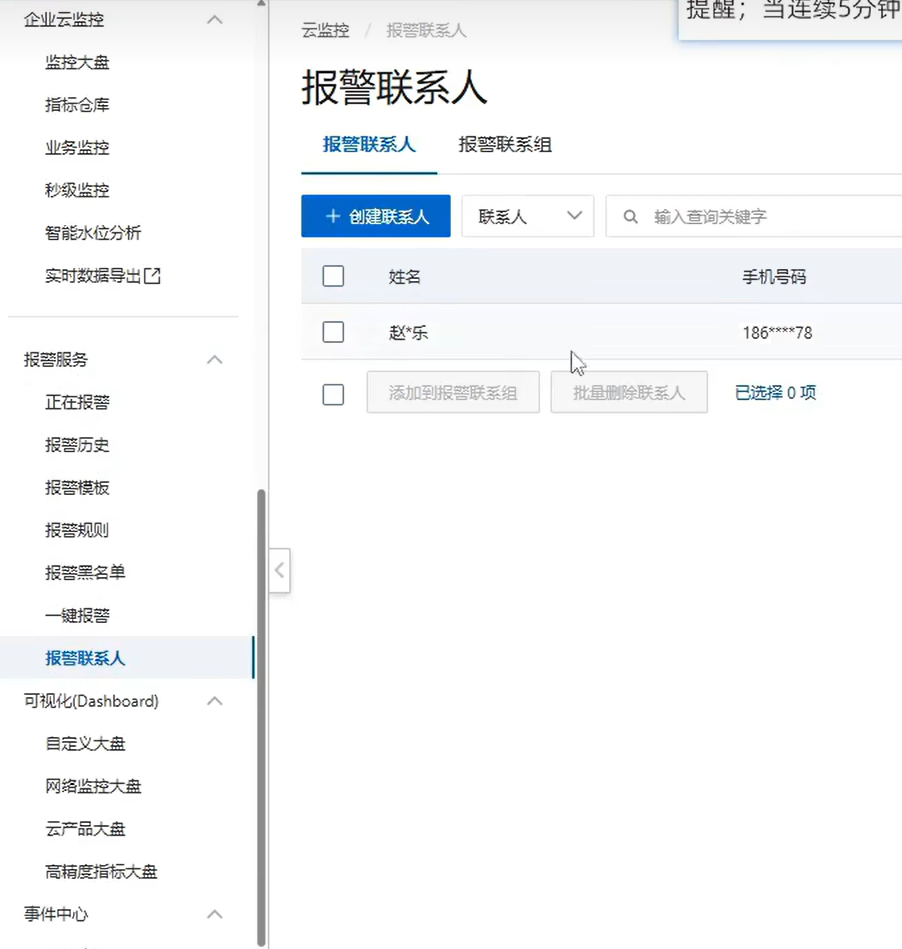
3:設置報警規則
報警規則:幫助用戶監控運行狀態,并在監控指標達到預設條件時,自動觸發報警通知
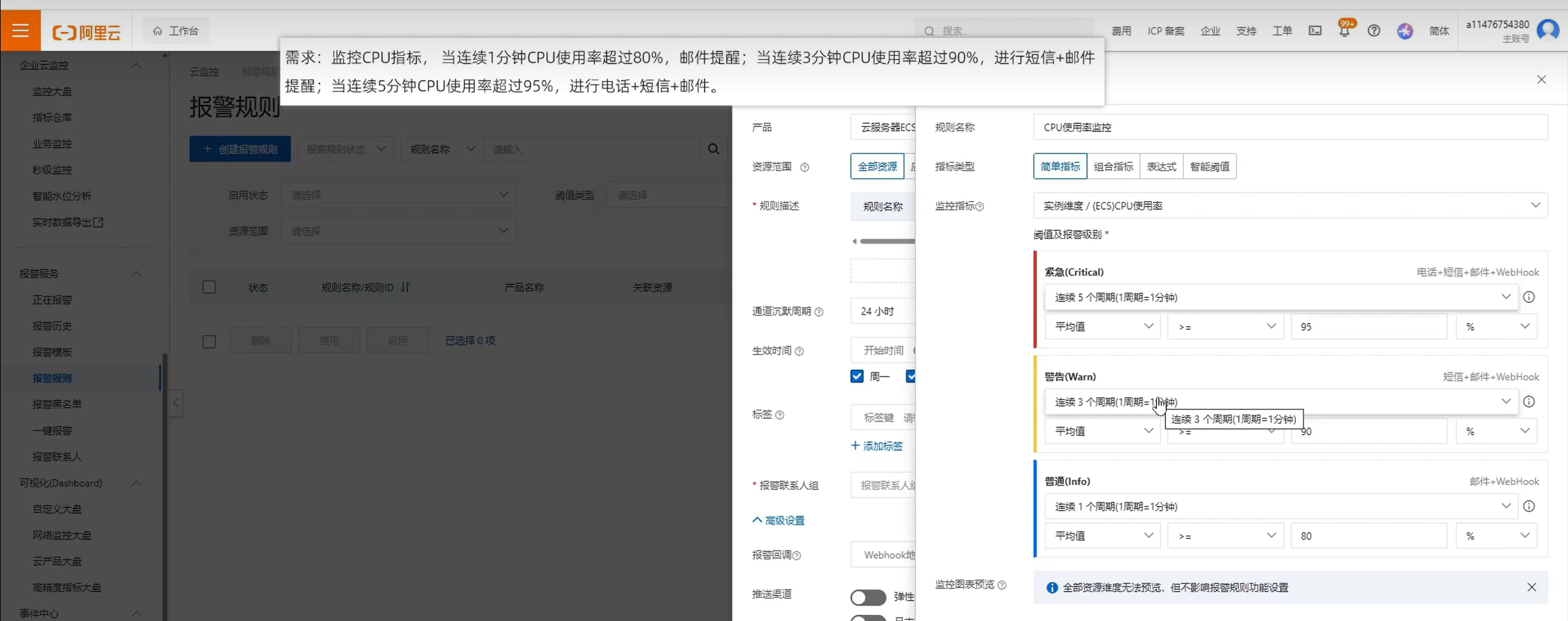
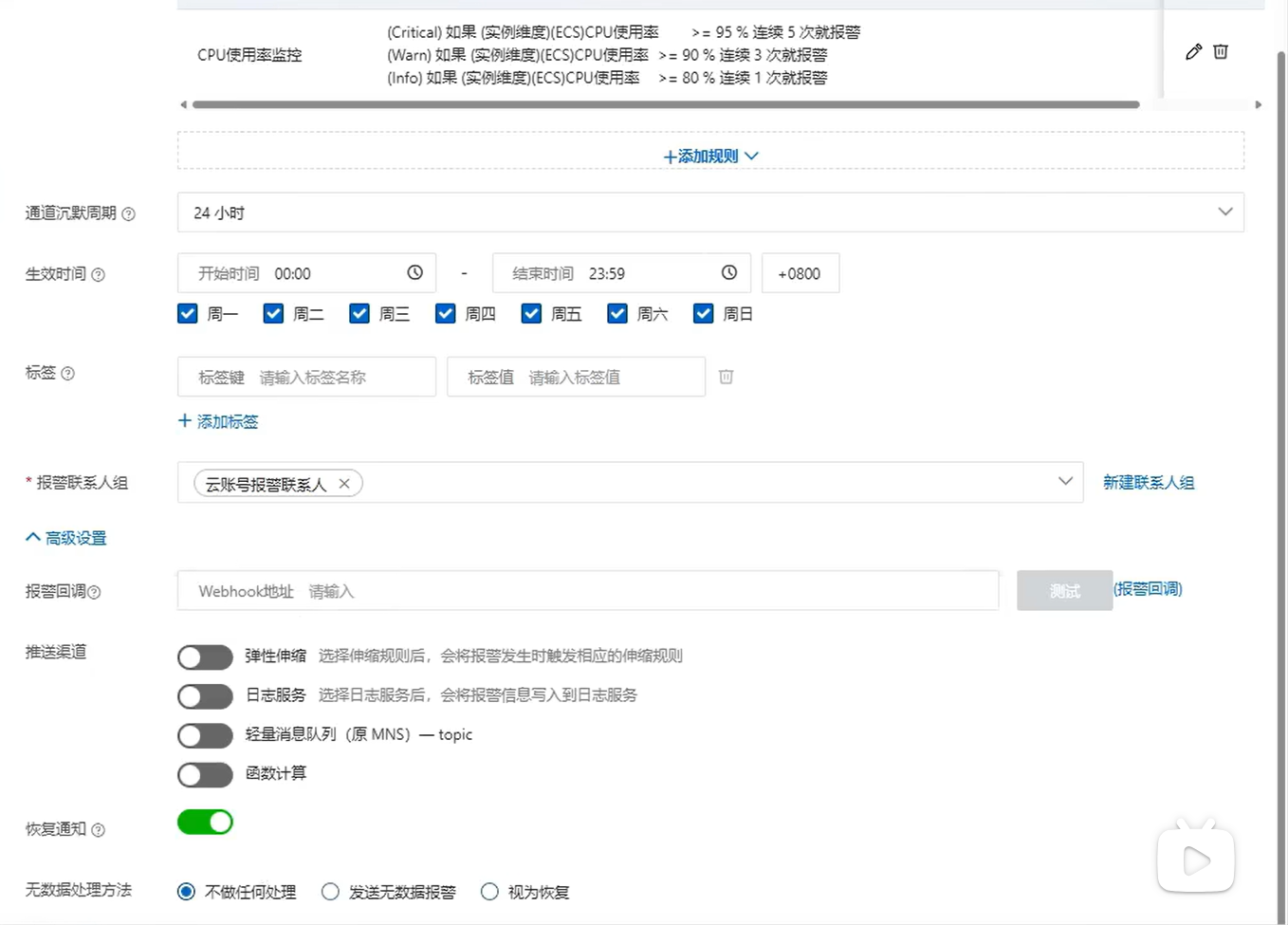
?
系統運維常見問題
問題一:CPU負載
1: 確認是否存在負載過高使用top或htop命令查看系統的平均負載值。
注意:如果負載值持續高于CPU核心數的0.5倍,則可能存在負載過高問題。如果超過1則負載已經較高了, 當超過2~3倍意味著負載超高,需要立即解決

這三個值即表示CPU分別1分鐘、5分鐘和15分鐘的平均負載情況
2: 排查CPU負載過高的原因
| 原因 | 具體表現 | 如何解決 |
|---|---|---|
| 異常進程或服務占用大量 CPU 資源 | 單個進程或服務占用大量 CPU 資源,導致整體 CPU 使用率升高。 | 使用 top 或 htop 命令查看具體占用 CPU 資源的進程。 按 Shift+P 按鍵,按 CPU 使用率排序定位異常進程,然后通過 Kill -9 終止異常進程。 |
| 系統資源不足 | 實例的 CPU 性能不足以支撐當前業務需求 | 升級實例規格或者優化業務邏輯 |
| 磁盤或網絡 I/O 瓶頸 | CPU 負載高但實際 CPU 使用率較低,可能是磁盤或網絡 I/O 瓶頸導致 | 優化磁盤讀寫,比如升級高性能云盤 優化網絡帶寬:增加公網帶寬或調整內網流量分布 |
| 僵尸進程或不可中斷的睡眠狀態 | 通過 top 命令觀察,CPU 使用率不高但負載值較高 | ps -axjf|grep "D+" 查看是否存在僵尸進程或不可中斷的睡眠狀態, 如果存在,建議恢復其對應依賴資源或重啟系統 |
| 系統遭遇病毒或惡意程序攻擊 | CPU 使用率高但無法通過 top 等命令找到異常進程 | 通過云監控監測異常時間點,檢查是否存在異常域名或 IP 的網絡通信, 如果確認,建議先備份數據,然后回滾實例并進行病毒掃描 |
?問題二:內存爆滿
1: 確認是否存在內存爆滿 使用top或htop命令查看,或者直接云監控查看均可。
注意:如果內存使用率持續接近或達到100%,則定義為內存爆滿
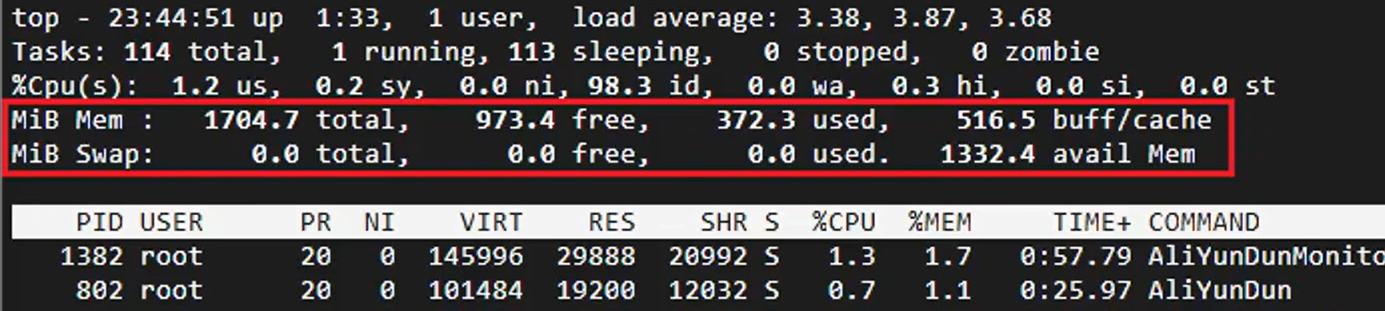
當Mem行的 free值幾乎為0時, 表示剩余內存幾乎沒有了
2: 排查內存過高的原因
| 原因 | 具體表現 | 如何解決 |
|---|---|---|
| 異常進程占用大量內存 | 單個進程或程序長時間占用大量內存資源 | 使用 top 或 htop 命令查看具體占用內存資源的進程。 按 M 按鍵,按內存使用率排序,定位異常進程,然后通過 Kill - 9 終止異常進程。 |
| 系統內存不足 | 實例的物理內存不足以支撐當前業務需求 | 升級實例規格或者優化業務邏輯 |
| 內存泄漏或代碼缺陷 | 應用程序在運行過程中不斷消耗內存,導致內存使用率持續升高 | 使用內存分析工具(如 Valgrind、jprofiler、jmap 等)分析應用程序的內存占用情況 根據分析結果優化業務代碼,修復內存泄漏問題 |
| 已刪除未釋放的僵尸文件 | 磁盤空間充足,但內存使用率仍然很高 | lsof|grep deleted 查找已刪除但未釋放的文件,然后重啟相關進程以釋放內存 |
| 系統緩存或虛擬內存不足 | 系統緩存占用過多內存,或虛擬內存配置不足 | 設置 Swap 分區,增加虛擬內存大小 |
ECS服務器巡檢報告介紹
ECS服務器巡檢報告一般是用于評估云服務器ECS實例及其相關資源(如磁盤、網絡等)的健康狀態和運行性能。 該報告基于對ECS實例的全面檢查,包括性能指標、安全風險、配置合規性等多個維度的分析。通過巡檢報告可以提高 系統的穩定性、安全性、優化資源配置和支持合規性審計工作
巡檢報告主要內容:
| 內容 | 說明 |
|---|---|
| 性能監控數據 | 包括 CPU 使用率、內存使用率、磁盤 I/O、網絡流量等關鍵性能指標 |
| 異常問題診斷 | 列出 ECS 實例在運行過程中發現的異常問題,例如高 CPU 利用率、磁盤 I/O 異常、網絡連接問題等。 每個異常項需要附帶嚴重等級(如 Info、Warn、Critical) |
| 安全風險評估 | 檢查 ECS 實例是否受到 DDoS 攻擊或其他安全威脅,并提供防護建議 |
| 資源使用與配置分析 | 檢查 ECS 實例的資源配置是否合理,例如磁盤空間是否充足、帶寬是否滿足業務需求,并提供優化建議 |
| 事件記錄與處理建議 | 監測到云盤性能達到上限或未創建快照備份等風險事件,確保系統的穩定性和數據的安全性 |
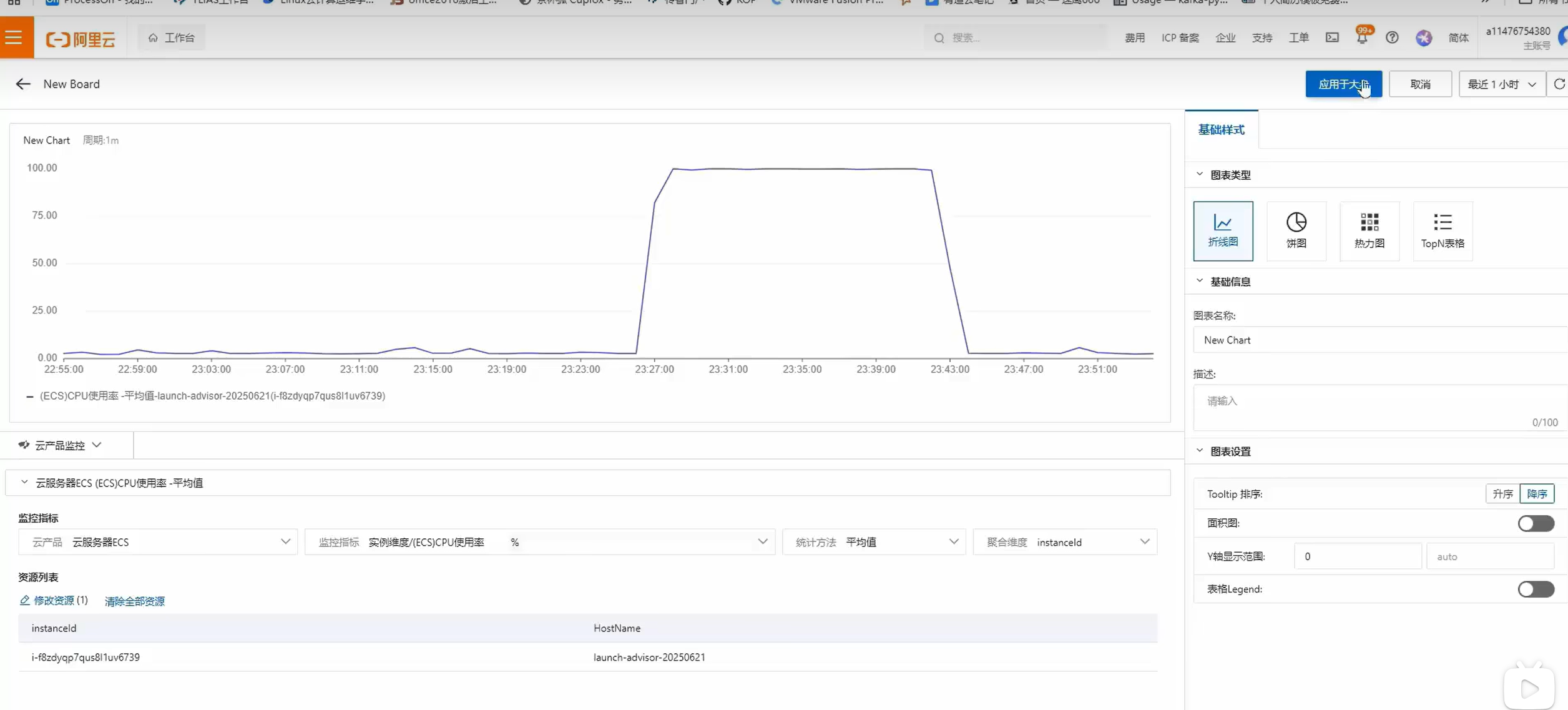
云服務器監控可視化大屏
2:打開自定義大盤,創建大盤
2:根據需求添加對應監測指標
如: 添加CPU使用率(折線圖) 其他類似






)




)
:面向對象中的構造方法)






