第五章:數據模型與架構
歡迎來到第五章!
在前幾章中,我們學習了網頁用戶界面(UI)(控制面板)、應用配置(系統參數設置)、任務編排(視頻生成流程的總調度)和任務狀態管理(進度追蹤機制)。
現在我們將探討支撐這些功能的基礎構件:數據模型與架構。
什么是數據模型與架構?
想象烘焙蛋糕時需要食譜(操作指南)和精確配比的原料(數據)。但如何確定面粉該用什么碗裝?糖的計量方式?這需要原料與工具的結構化組織。
在軟件系統中,數據模型和架構正是為此而生:
- 架構(Schema):類似藍圖模板,定義數據組成要素、類型(文本/數值/布爾值/列表等)及組織方式。例如"用戶"架構可能包含
name(文本)、age(數值)、is_active(布爾值)三個字段。 - 數據模型:基于架構創建的具體實例對象,嚴格遵循藍圖規則。例如用戶模型的實例可能是
{ "name": "Alice", "age": 30, "is_active": true }。
在MoneyPrinterTurbo中,數據模型與架構用于定義:
- 視頻生成請求的結構(用戶在UI中配置的所有參數)
- 視頻素材信息的格式(如URL地址、時長等)
- 系統內部模塊/外部服務間的通信協議
- 第四章所述任務狀態的數據結構
這種結構化設計確保數據組織有序、格式統一,便于各模塊正確處理與流轉。
基于Pydantic的數據模型實現
前文傳送:[Meetily后端框架] AI摘要結構化 | SummaryResponse模型 | Pydantic庫 | vs marshmallow庫
MoneyPrinterTurbo使用Python庫Pydantic構建數據模型:
- Pydantic特性:通過Python類型提示(如
str/int/bool/list)定義數據結構。創建模型對象時自動驗證數據合規性,若類型錯誤(如文本填入數值字段)則拋出異常。 - 選擇Pydantic的原因:
- 定義清晰:代碼中顯式聲明數據結構
- 自動校驗:數據輸入時即時驗證
- 類型轉換:自動將字典等原始數據轉為結構化對象
項目主要數據模型定義于app/models/schema.py,均繼承自Pydantic的BaseModel。
核心模型示例:VideoParams
視頻生成的核心模型是VideoParams,它完整承載用戶在UI中配置的所有參數。以下是app/models/schema.py中的簡化定義:
# 摘自app/models/schema.py的簡化代碼
from typing import Optional, List, Union
from enum import Enum
from pydantic import BaseModel
import pydantic.dataclasses# 視頻比例枚舉定義
class VideoAspect(str, Enum):landscape = "16:9" # 橫屏portrait = "9:16" # 豎屏square = "1:1" # 正方形# 素材信息數據結構
@pydantic.dataclasses.dataclass
class MaterialInfo:provider: str = "pexels" # 素材源url: str = "" # 素材URLduration: int = 0 # 素材時長# 主視頻參數模型
class VideoParams(BaseModel):video_subject: str # 必填:視頻主題(字符串)video_script: str = "" # 可選:劇本文本(默認空字符串)video_terms: Optional[str | list] = None # 可選:關鍵詞(字符串/列表/空值)video_aspect: Optional[VideoAspect] = VideoAspect.portrait.value # 比例(枚舉值)video_clip_duration: Optional[int] = 5 # 素材片段時長(默認5秒)# ... 其他視頻/音頻/字幕參數 ...video_materials: Optional[List[MaterialInfo]] = None # 素材列表(MaterialInfo對象)subtitle_enabled: Optional[bool] = True # 字幕開關(布爾值,默認開啟)font_size: int = 60 # 字體大小(整型,默認60)# ... 更多字幕參數 ...# Pydantic配置(高級設置)class Config:arbitrary_types_allowed = True
關鍵要素解析:
- 繼承結構:
class VideoParams(BaseModel)聲明繼承自Pydantic基類 - 字段類型:
video_subject: str必填字符串字段video_script: str = ""帶默認值的可選字段Optional[...]表示可空字段(如Optional[str]可為字符串或None)Union[bool, str]允許布爾值或字符串(如字幕背景顏色字段)
- 嵌套模型:
List[MaterialInfo]表示該字段為MaterialInfo對象的列表 - 枚舉約束:
VideoAspect枚舉限制比例參數只能取三個預定義值
模型在系統中的應用
數據模型貫穿系統各模塊的交互流程:
1. 網頁UI的數據封裝
用戶在UI表單填寫參數后,數據被封裝為字典并轉換為VideoParams對象:
# 網頁UI(Streamlit)中的概念代碼
from app.models.schema import VideoParams# 收集表單數據
ui_data = {"video_subject": st.session_state["video_subject_input"],"video_aspect": st.session_state["video_aspect_select"],# ... 其他參數 ...
}try:# 創建結構化對象video_params = VideoParams(**ui_data)print(f"創建視頻參數對象:{video_params.video_subject}")# 傳遞給任務編排器# start_video_task(video_params)
except pydantic.ValidationError as e:st.error(f"參數錯誤:{e}") # 數據校驗失敗時提示
此過程通過Pydantic自動校驗數據合法性,確保傳入編排器的參數結構正確。
2. 任務編排器的參數傳遞
編排器入口函數明確接收VideoParams類型參數:
# 摘自app/services/task.py的簡化代碼
from app.models.schema import VideoParamsdef start(task_id, params: VideoParams):logger.info(f"任務{task_id}啟動,主題:{params.video_subject}")# 直接訪問結構化參數aspect_ratio = params.video_aspectfont_size = params.font_size# ... 調用各服務模塊 ...
通過params.field_name的點語法,編排器可高效獲取各項參數,無需處理原始字典數據。
3. 服務間通信
其他服務模塊也采用模型化交互:
- 素材服務返回
MaterialInfo對象列表 - API接口使用
TaskResponse/VideoScriptResponse等模型定義請求響應格式 - 狀態管理器存儲的任務狀態數據遵循
TaskQueryResponse結構
4. 狀態管理的結構化存儲
第四章所述狀態數據雖然以字典形式存儲,但查詢響應仍通過模型保證結構一致性:
# 狀態查詢響應模型示例
class TaskQueryResponse(BaseModel):task_id: strstate: intprogress: intvideos: Optional[List[str]] = Noneerror: Optional[str] = None
Pydantic的底層運作機制
創建Pydantic模型實例時發生以下過程:
- 數據解析:將原始數據(如UI提交的字典)轉換為字段值
- 類型校驗:驗證各字段類型是否符合定義
- 自動轉換:嘗試類型兼容轉換(如字符串"123"轉為整型123)
- 對象實例化:校驗通過后生成結構化對象
以下序列圖展示模型在系統中的應用流程:
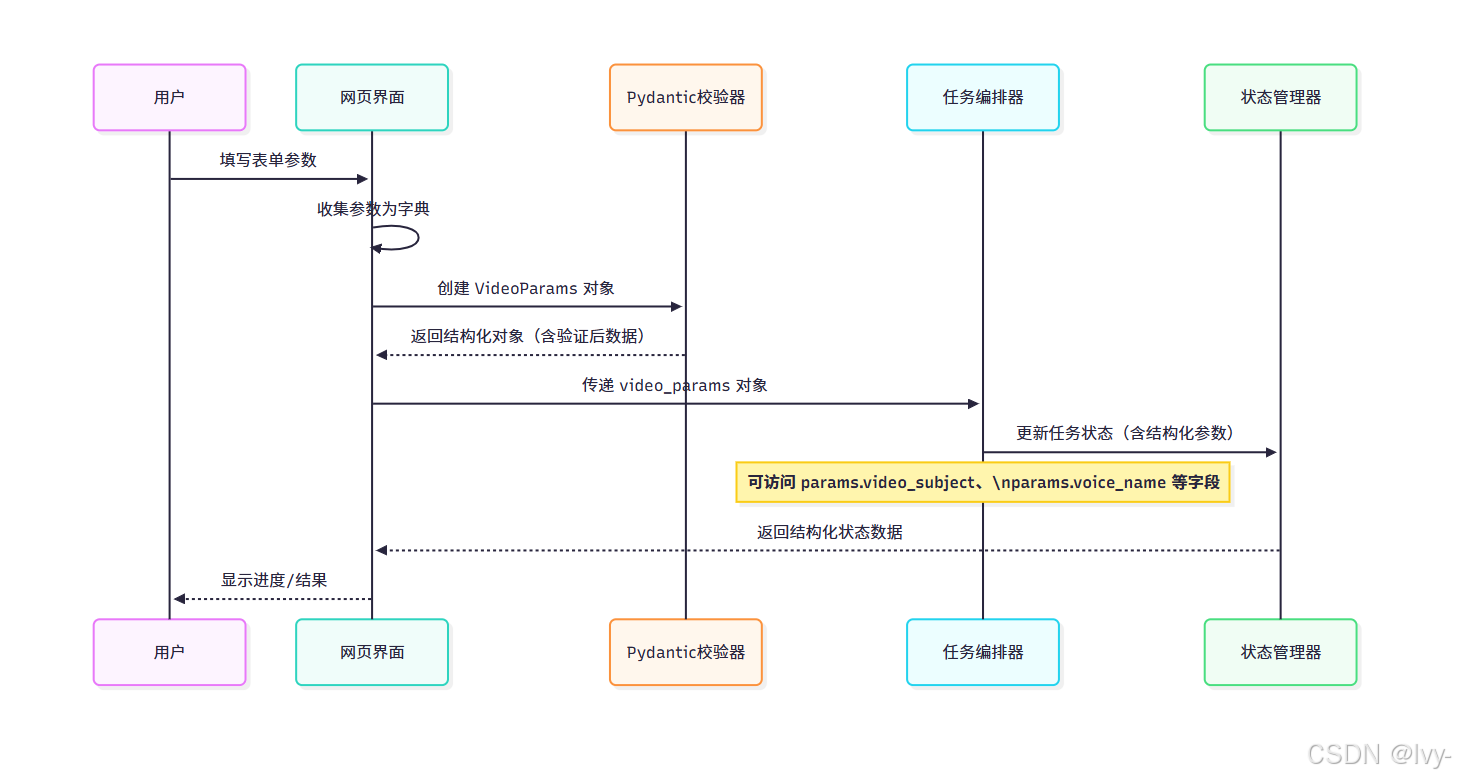
該流程體現了模型如何確保從用戶輸入到狀態存儲的全鏈路數據一致性。
總結
數據模型與架構作為系統基石,通過Pydantic等工具實現結構化數據定義與校驗。VideoParams等模型清晰定義了視頻生成任務的參數結構,貫穿UI、編排器、服務模塊與狀態管理的全流程。這種設計保障了數據流動的可靠性與系統擴展性。
接下來我們將深入探討驅動劇本生成的核心模塊:大語言模型服務,解析AI如何將用戶主題轉化為精彩劇本。
下一章:大語言模型服務
第六章:LLM集成
在前幾章中,我們探討了《第一章:配置》(如何設置系統)、《第二章:任務管理》(任務如何排隊處理)、《第三章:視頻生成任務》(視頻任務的處理步驟)以及《第四章:任務狀態》(如何跟蹤任務進度)。
現在,讓我們看看最激動人心的部分:MoneyPrinterTurbo如何利用人工智能生成視頻創意內容。這正是由LLM集成組件實現的。
為何需要LLM集成?
假設我們要制作關于"學習編程的優勢"的視頻,傳統流程需要:
- 編寫說明性腳本
- 構思視覺創意或搜索匹配腳本的視頻素材關鍵詞(如"敲擊筆記本鍵盤"、“團隊協作”、“增長趨勢圖”)
LLM集成組件通過連接大語言模型(如OpenAI的GPT系列、DeepSeek、Moonshot等),實現以下核心功能:
- 根據視頻主題生成完整腳本
- 基于腳本內容提取相關素材搜索關鍵詞
- 構建創意概念與視頻素材間的智能橋梁
前文傳送: [BrowserOS] LLM供應商集成 | 更新系統 | Sparkle框架 | 自動化構建系統 | Generate Ninja
LLM集成工作原理
在視頻生成任務中,LLM集成執行以下流程:
- 接收視頻主題(可選語言和段落數)
- 向配置的LLM服務商發送請求
- 接收LLM生成的視頻腳本
- 再次發送腳本和主題獲取視頻搜索關鍵詞
- 將生成內容傳遞至語音合成和視頻素材處理環節
連接LLM服務商
如第一章:配置所述,通過config.toml文件配置LLM服務商:
# config.toml(簡化LLM配置段)[app]
llm_provider = "OpenAI" # 可選DeepSeek/Moonshot/Ollama等# OpenAI配置
openai_api_key = "您的OpenAI密鑰"
openai_model_name = "gpt-3.5-turbo"# DeepSeek配置
deepseek_api_key = "您的DeepSeek密鑰"
deepseek_base_url = "https://api.deepseek.com"
deepseek_model_name = "deepseek-chat"
API接口視圖
MoneyPrinterTurbo提供獨立API端點供Web UI調用:
1. 生成腳本接口
@router.post("/scripts")
def generate_video_script(body: VideoScriptRequest):video_script = llm.generate_script(video_subject=body.video_subject,language=body.video_language,paragraph_number=body.paragraph_number,)return {"video_script": video_script}
- 輸入:POST請求體含主題、語言、段落數
- 輸出:JSON格式生成腳本
2. 生成關鍵詞接口
@router.post("/terms")
def generate_video_terms(body: VideoTermsRequest):video_terms = llm.generate_terms(video_subject=body.video_subject,video_script=body.video_script,amount=body.amount,)return {"video_terms": video_terms}
- 輸入:POST請求體含主題、腳本、關鍵詞數量
- 輸出:JSON格式關鍵詞列表
核心實現(app/services/llm.py)
通信樞紐(_generate_response)
def _generate_response(prompt: str) -> str:llm_provider = config.app.get("llm_provider")# 根據配置初始化不同服務商客戶端if llm_provider == "openai":client = OpenAI(api_key=config.openai_api_key)elif llm_provider == "deepseek":client = OpenAI(api_key=config.deepseek_api_key)# 發送請求并處理響應response = client.chat.completions.create(model=model_name, messages=[{"role": "user", "content": prompt}])return response.choices[0].message.content
腳本生成邏輯
def generate_script(video_subject: str, language: str, paragraph_number: int):prompt = f"""# 角色:視頻腳本生成器## 目標:基于主題生成{paragraph_number}段視頻腳本## 約束:1. 直接輸出原始腳本內容2. 禁用Markdown格式3. 使用與主題相同的語言## 初始化:- 視頻主題:{video_subject}""".strip()return _generate_response(prompt)
關鍵詞生成邏輯
def generate_terms(video_subject: str, video_script: str, amount: int):prompt = f"""# 角色:視頻搜索詞生成器## 目標:生成{amount}個素材搜索詞## 約束:1. 輸出JSON數組格式2. 每個詞1-3個單詞## 上下文:### 視頻主題{video_subject}### 視頻腳本{video_script}""".strip()response = _generate_response(prompt)return json.loads(response)
流程圖解
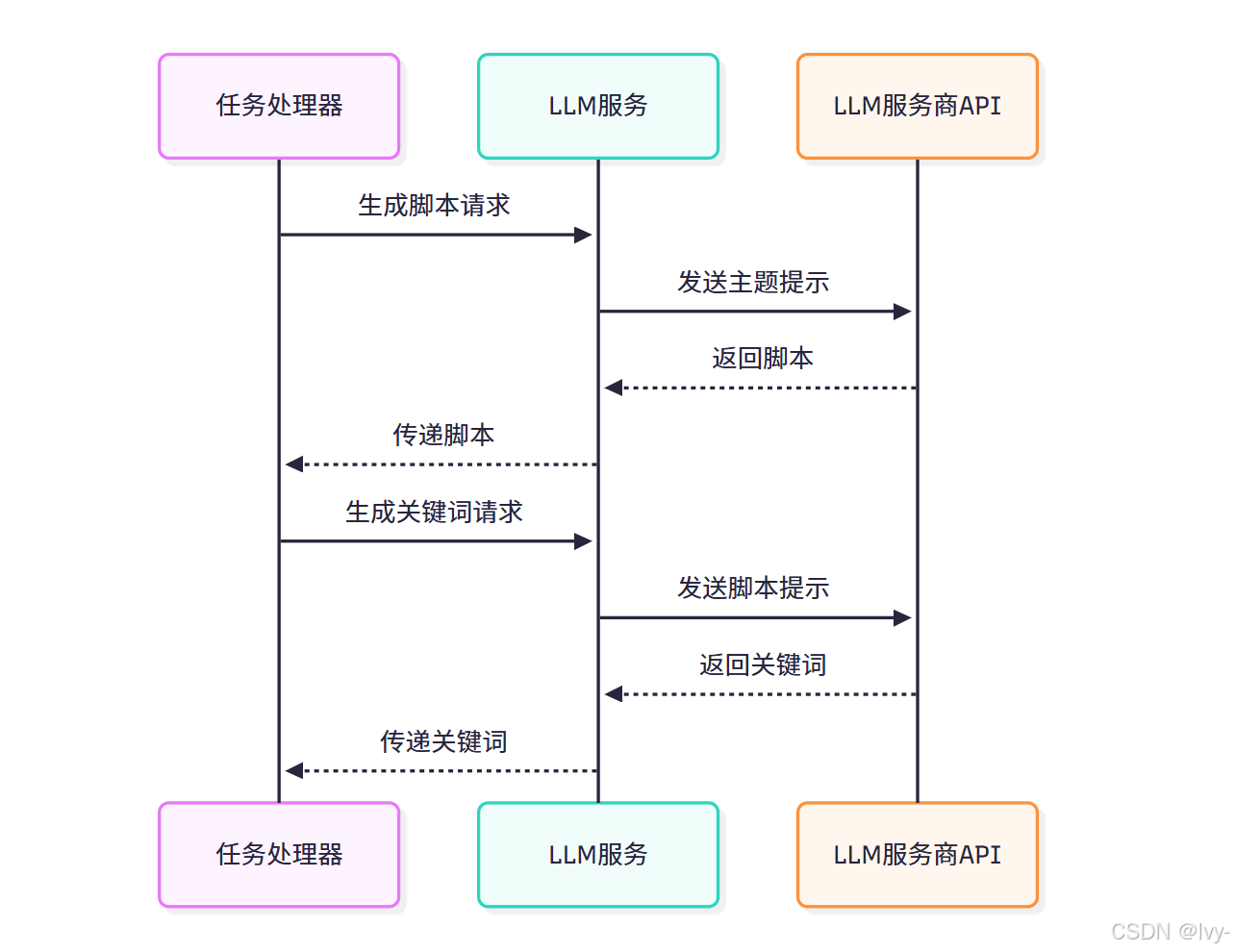
結論
LLM集成組件通過智能生成腳本和素材關鍵詞,成為自動化視頻制作流程的核心。














)




