在互聯網高并發場景中,HTTP 性能表現直接決定系統生死。當每秒請求量突破十萬級甚至百萬級時,哪怕 100 毫秒的延遲都會引發用戶流失、交易失敗等連鎖反應。本文基于五大行業實戰案例,拆解 HTTP 性能瓶頸的底層邏輯,輸出可直接落地的工業級優化方案,幫助技術團隊建立系統化的性能調優思維。
連接復用:減少握手開銷的關鍵
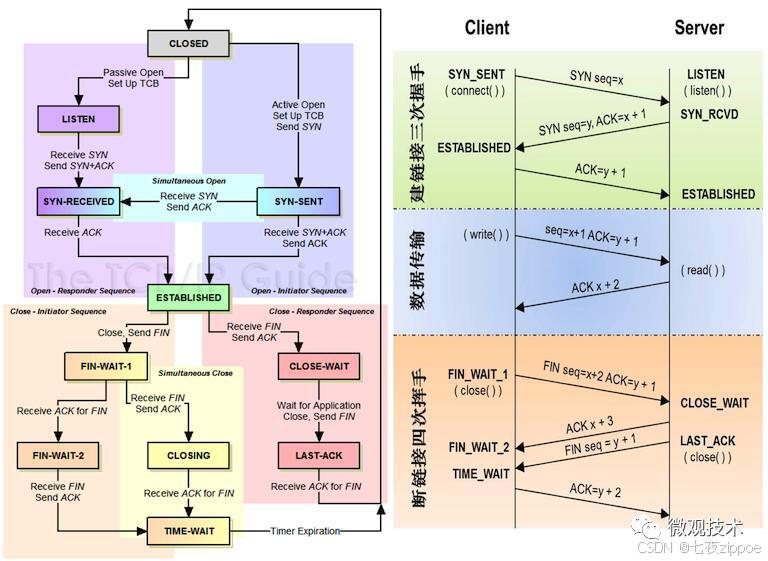
TCP 連接的建立與關閉(三次握手 / 四次揮手)在高并發場景下會產生巨大性能損耗。實驗數據顯示,單次 TCP 握手在跨地域網絡中耗時可達 50-200ms,當 QPS 突破 1 萬時,純握手開銷就會吃掉 30% 以上的服務器資源。
案例:電商平臺的連接復用實踐
某頭部電商平臺在 618 大促期間,遭遇了典型的短連接性能陷阱:
原始架構:采用 HTTP/1.0 短連接模式,每次請求都新建 TCP 連接
性能瓶頸:每秒產生 15 萬次 TCP 握手,服務器 CPU 占用率飆升至 90%,響應超時率達 12%
核心問題:握手耗時占比超過總請求時間的 45%
技術團隊實施的優化方案:
全量啟用HTTP/1.1 持久連接,通過
Connection: keep-alive頭字段將 TCP 連接復用率提升至 85%精細化配置連接參數:
Keep-Alive: timeout=15, max=100(連接保持 15 秒,最多處理 100 個請求)配合 Nginx 的
keepalive_requests與keepalive_timeout參數聯動調優
優化效果呈現:
TCP 握手次數下降 72%,服務器 CPU 占用率降至 55%
平均響應時間從 320ms 壓縮至 48ms
成功支撐每秒 42 萬次的峰值請求,零超時故障
連接復用的進階:連接池技術
在微服務架構中,服務間調用的連接復用需要更主動的管理策略。某支付平臺的實踐數據顯示,未使用連接池時,服務間調用的 90% 響應時間達 350ms,其中 60% 時間消耗在連接建立上。
連接池的核心優化點:
池大小動態調整:基于并發量自動擴縮容,避免連接不足或資源浪費(推薦公式:池大小 = 預估 QPS× 平均響應時間)
空閑連接管理:設置
idleTimeout(如 30 秒)回收閑置連接,同時保留minIdle(如 50)個熱連接失敗重試機制:對無效連接自動檢測并重建,配合熔斷器避免連接風暴
實施成效:
服務間通信延遲降低 40%,90% 響應時間控制在 140ms 內
系統吞吐量提升 50%,支撐每日 2 億筆交易的平穩運行
協議升級:擁抱 HTTP/2 和 HTTP/3
HTTP 協議的演進直接解決了底層傳輸效率問題。對比測試表明,在加載 100 個資源的場景下:
HTTP/1.1 需建立 6-8 個 TCP 連接(受瀏覽器并發限制)
HTTP/2 通過多路復用可減少 80% 的連接數
HTTP/3 在弱網環境下比 HTTP/2 減少 40% 的傳輸失敗率
案例:視頻網站的 HTTP/2 遷移
某長視頻平臺面臨的資源加載困境:
單頁面需加載 30 + 視頻分片、20 + 圖片資源、15+JS/CSS 文件
HTTP/1.1 的隊頭阻塞導致資源加載瀑布流嚴重,首屏渲染耗時 2.8 秒
視頻卡頓率高達 18%,用戶流失率隨加載時間增加呈指數級上升
HTTP/2 的優化實踐:
基于 Nginx 部署 HTTP/2,啟用 ALPN 協議協商自動兼容舊客戶端
利用多路復用特性,將資源加載并行度提升至理論上限
配置服務器推送(Server Push),預推首頁關鍵 CSS 和首幀圖片
遷移后的量化收益:
資源加載并行數從 6 提升至無上限,首屏渲染時間縮短至 1.1 秒
視頻卡頓率降至 7.2%,用戶觀看時長平均增加 12 分鐘
CDN 流量成本下降 18%(減少重復請求)
HTTP/3:告別 TCP 的新選擇
某社交 APP 的移動端性能優化案例揭示了 TCP 的固有缺陷:在 4G 網絡下,1% 的丟包率會導致 TCP 傳輸效率下降 30%。HTTP/3 基于 QUIC 協議的革新:
無隊頭阻塞:UDP 傳輸 + 幀重傳機制,單個數據包丟失不影響整體
連接遷移:支持網絡切換(WiFi→4G)時保持連接不中斷
0-RTT 握手:首次連接后,后續可實現零往返時間建立連接
實施效果:
弱網環境下請求成功率從 78% 提升至 98%
頁面加載時間縮短 30%,尤其在地鐵、電梯等網絡切換場景表現優異
消息發送成功率提升 22%,用戶活躍度增長 8%
緩存策略:減輕服務器負擔
緩存是性價比最高的性能優化手段。某資訊平臺的測算顯示,每增加 10% 的緩存命中率,可減少 25% 的服務器負載和 30% 的網絡帶寬消耗。
案例:新聞資訊網站的多級緩存架構
面對日均 10 億 PV 的訪問壓力,該平臺構建了 “瀏覽器→CDN→應用→數據庫” 的四級緩存體系:
- 瀏覽器緩存:
靜態資源(圖片 / CSS/JS)設置
Cache-Control: max-age=86400(24 小時)采用指紋命名(如
style.1a2b3c.css)實現緩存精確更新
- CDN 緩存:
熱點新聞頁面設置
Cache-Control: s-maxage=300(5 分鐘)結合
Vary: Accept-Encoding頭處理不同壓縮格式的緩存
- 應用層緩存:
Redis 集群緩存熱門新聞列表(TTL=60 秒)
本地內存緩存不常變化的配置數據(如頻道分類)
- 數據庫緩存:
MySQL 查詢緩存配合 Redis 二級緩存
分庫分表 + 索引優化減少磁盤 IO
優化數據:
源站請求量下降 83%,數據庫負載降低 75%
頁面平均加載時間從 2.1 秒降至 480ms
突發新聞事件時,系統平穩承接 3 倍日常流量
緩存的一致性維護
緩存與數據一致性的平衡是實戰難點。某電商的庫存系統曾因緩存不一致導致超賣事故,后采用混合策略解決:
寫透 + 過期:商品基礎信息采用 “更新數據庫后同步更新緩存 + 24 小時過期”
失效 + 重試:庫存數據采用 “更新數據庫后刪除緩存 + 讀取時重建”
消息隊列異步更新:評論數、點贊數等高頻變動數據通過 Kafka 異步同步
關鍵指標:
緩存一致性達到 99.99%,超賣事故零發生
緩存更新延遲控制在 100ms 內
峰值期緩存命中率穩定在 92% 以上
負載均衡:分散請求壓力
單臺服務器的處理能力存在物理上限(通常 QPS 在 1 萬 - 5 萬之間),負載均衡通過資源池化實現水平擴展。某金融系統的實踐表明,合理的負載均衡架構可使系統可用性從 99.9% 提升至 99.99%。
案例:金融交易系統的負載均衡方案
為支撐每秒 10 萬筆的交易峰值,該系統設計了三層負載架構:
- DNS 負載均衡:
基于地理位置解析至最近接入點(如北方用戶→北京節點)
配合健康檢查自動下線故障節點
- 硬件負載均衡:
采用 F5 BIG-IP 設備處理四層轉發,單機吞吐量達 10Gbps
配置會話保持(Source IP Hash)確保交易連續性
- 應用層負載均衡:
Nginx+Lua 實現基于權重的輪詢算法
結合服務健康度動態調整權重(如 CPU>80% 時降權)
核心收益:
單節點故障對整體性能影響控制在 5% 以內
交易響應時間穩定在 95ms,波動幅度 < 10ms
災備切換時間從 30 分鐘縮短至 15 秒
結語
HTTP 性能優化需要建立 “指標→瓶頸→方案→驗證” 的閉環思維:
先通過 APM 工具(如 SkyWalking)定位具體瓶頸(連接?協議?緩存?)
結合業務場景選擇適配方案(電商重連接復用,視頻重協議升級)
小流量灰度驗證,監控核心指標(響應時間、吞吐量、錯誤率)
建立性能基準線,持續迭代優化
記住:沒有放之四海皆準的最優方案,只有最適合業務場景的平衡策略。在高并發的戰場上,毫秒級的優化積累終將轉化為決定性的競爭優勢。













)





MySQL學習筆記(完):事務和鎖)