DETR見解
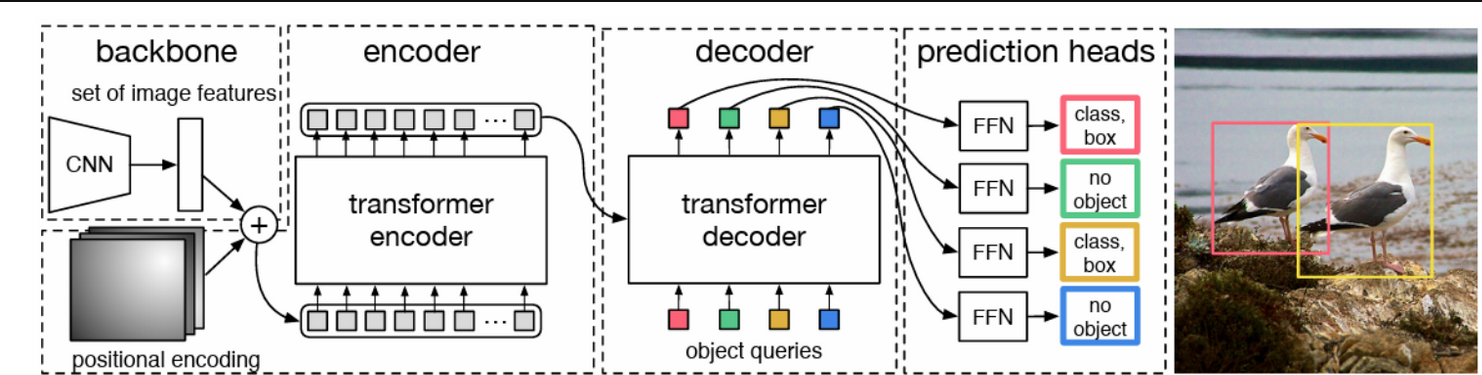
DETR(Detection Transformer)是一種端到端的目標檢測模型,由Facebook AI Research(FAIR)于2020年提出。DETR采用了Transformer架構,與傳統的基于區域的目標檢測方法有所不同,它通過全局上下文來預測圖像中的目標,而無需使用先前的候選框或區域建議網絡。整個DETR可以分為四個部分,分別是:backbone、encoder、decoder以及predictionheads。基本思想是,首先用cnn抽取圖像特征,拿到每一個patch對應的向量,并加上位置編碼。然后用transformer encoder學習全局特征,幫助后面做檢測。接著將encoder的輸出作為tranformer deoder的輸入,同時還輸入了一個對象查詢。對象查詢按我的理解就是,它生成一個查詢分量q和前面encoder傳進來的k和v做一個交互,生成很多預測框。然后把預測框和真實框做匹配,詢問框內是否包含目標,然后在匹配上的這些框里面計算loss,進而向后傳播。接著就是預測頭的建立,最后生成預測結果。所以整個DETR網絡的工作就是:特征提取--特征加強--特征查詢--預測結果
 建議使用云服務器進行操作(如果本機沒有GPU或者顯存資源不充足情況下)
建議使用云服務器進行操作(如果本機沒有GPU或者顯存資源不充足情況下)
一、代碼拉取
官方:GitHub直接搜索即可
改進版:代碼私信發送(資源免費)(主要原因就是資源綁定不成功? :(? 哭泣哭泣 )
論文:文章頂部下載
二、環境準備
解壓代碼,進入主目錄
安裝對應包
pip install -r requirements.txt三、數據集準備
數據集下載
數據集建議準備VOC格式或者是COCO格式。(GitHub上官方使用數據集格式為coco格式)
其實不論是yolo格式或者是VOC格式,他們之間都可以通過代碼去轉換。
建議在訓練前,隨機抽取幾張圖片和標簽,查看標注是否準確無誤。
推薦數據集:CCTSDB_VOC_數據集-飛槳AI Studio星河社區
推薦數據集:水果分類目標檢測VOC數據集_數據集-飛槳AI Studio星河社區
數據集加載
導入數據集之后,查看數據集是否包括:JPG和XML,以及train.txt、val.txt、test.txt
使用運行test.py生成一個存在于主目錄下的train.txt和test.txt。這樣我們就設置完成訓練集和測試集的加載路徑了。
四、模型訓練
參數修改
打開detr.py,和train.py?
里面有相關參數,我們可以進行設置,其中包括凍結訓練層數以及解凍層數,這個是比較重要的。
detr.py參數:?

train.py參數修改
其中預訓練權重文件可以選擇resnet50或者是resnet101,可自行修改
 ?
?

五、訓練結果可視化
運行get_map.py生成loss、Map、recall等(如果不懂可以具體了解一下模型評估的幾個參數)
5.1模型評估參數介紹
- 1. 精確率(Precision)?
- 定義:在所有被模型預測為正類(即存在目標)的樣本中,實際為正類的比例。
- 公式?:
- Precision=(True Positives (TP)+False Positives (FP)) / True Positives (TP)
- 解釋:
- TP(True Positive)?:模型正確預測了目標的邊界框和類別。
- FP(False Positive)?:模型錯誤地預測了目標的邊界框或類別(例如,將背景誤判為目標)。
- 意義:高精確率意味著模型在預測目標時較少出現誤報。
- 2. 召回率(Recall)?
- 定義:在所有實際為正類的樣本中,被模型正確預測為正類的比例。
- 公式?:
- Recall=True Positives (TP) / (True Positives (TP)+False Negatives (FN))
- 解釋?:
- FN(False Negative)?:模型未能檢測到實際存在的目標。
- 意義?:高召回率意味著模型能夠檢測到更多的真實目標,減少漏檢。
- 3. 平均精度(Average Precision, AP)?
- 定義:在不同置信度閾值下,精確率和召回率的綜合表現,通常以AP@[IoU閾值]表示,如AP@0.5。
- 計算方法?:
- 對每個類別,根據預測的置信度從高到低排序。
- 計算不同置信度閾值下的精確率和召回率。
- 繪制精確率-召回率曲線(Precision-Recall Curve)。
- 計算曲線下的面積(Area Under Curve, AUC),即AP。
- 意義?:AP綜合考量了模型在不同置信度下的精確率和召回率,是評估目標檢測模型性能的重要指標。
- 4. 平均精度均值(Mean Average Precision, mAP)?
- 定義:在多個類別上計算的平均AP值。
- 公式?:
- mAP=N1∑i=1NAPi
- 其中,N 是類別的總數,APi 是第 i 個類別的AP值。
- 常見變體?:
- mAP@[IoU閾值]?:如mAP@0.5表示IoU閾值為0.5時的平均精度均值。
- mAP@[0.5:0.95]?:在IoU閾值從0.5到0.95(步長為0.05)范圍內計算的平均mAP,更全面地評估模型性能。
- 意義?:mAP綜合考慮了所有類別的性能,是目標檢測任務中最常用的綜合評估指標。
- 5. 交并比(Intersection over Union, IoU)?
- 定義:預測邊界框與真實邊界框之間的重疊程度。
- 公式?:
- IoU=Area of UnionArea of Overlap
- 解釋?:
- IoU值范圍在0到1之間,值越大表示預測框與真實框的重疊程度越高。
- 常用IoU閾值(如0.5、0.75)來判斷預測框是否正確。
- 意義?:IoU用于評估單個預測框的準確性,是計算TP、FP和FN的基礎。
- 6. 其他相關指標?
- F1分數(F1-Score):精確率和召回率的調和平均數,用于平衡兩者。
- F1=2×Precision+RecallPrecision×Recall
- 每秒幀數(Frames Per Second, FPS)?:模型推理速度,適用于實時檢測任務。
- GFLOPs(Giga Floating Point Operations)?:模型的計算復雜度,影響推理速度和硬件需求。
- Instances 的含義
- 定義:
- Instances 指的是當前批次(Batch)中所有圖像中真實存在的目標對象數量的總和?。

六、模型調優
yolo相關參數介紹鏈接:(https://docs.ultralytics.com/zh/modes/train/#train-settings)?
可以參考里面的參數介紹,來進行調優





數據庫恢復技術)







)


和歐姆龍NJ PLC的高效數據交換)


