目錄
一、模型表示
二、代價函數
三、代價函數的直觀理解(1)
四、代價函數的直觀理解(2)
五、梯度下降
六、梯度下降的直觀理解
七、線性回歸的梯度下降
在本篇內容中,我們將介紹第一個機器學習算法——線性回歸算法。更重要的是,我們將借助這個算法,帶你了解一個完整的監督學習流程。
一、模型表示
我們通過一個例子來開始:預測房價。我們擁有一個數據集,記錄了美國俄勒岡州波特蘭市的若干房子面積及其對應的成交價格。橫軸表示房子的面積(平方英尺),縱軸表示房價(千美元)。如果有一套房子面積是 1250 平方英尺,想知道大概能賣多少錢。你可以通過構建一個預測模型來實現,比如你可以用一條直線來擬合數據,從而推斷出:這套房子可能值大約 22 萬美元左右。
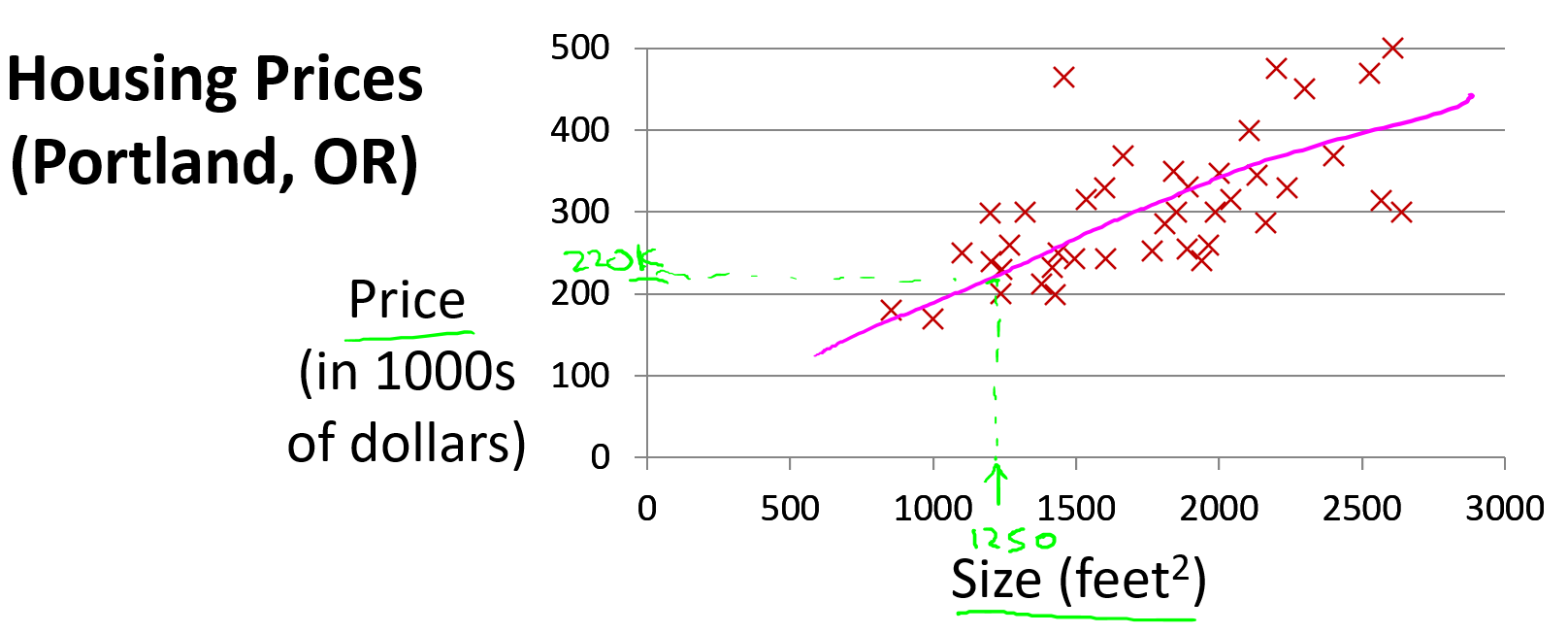
這是監督學習算法的一個例子。?因為在訓練過程中,每個數據樣本都包含一個“正確答案”,也就是我們已經知道的真實輸出(每個房子的實際售價)。而且這還是一個回歸問題的例子,因為預測一個具體的數值輸出(房子的價格)。
在監督學習中我們有一個數據集,這個數據集被稱訓練集,如下圖。
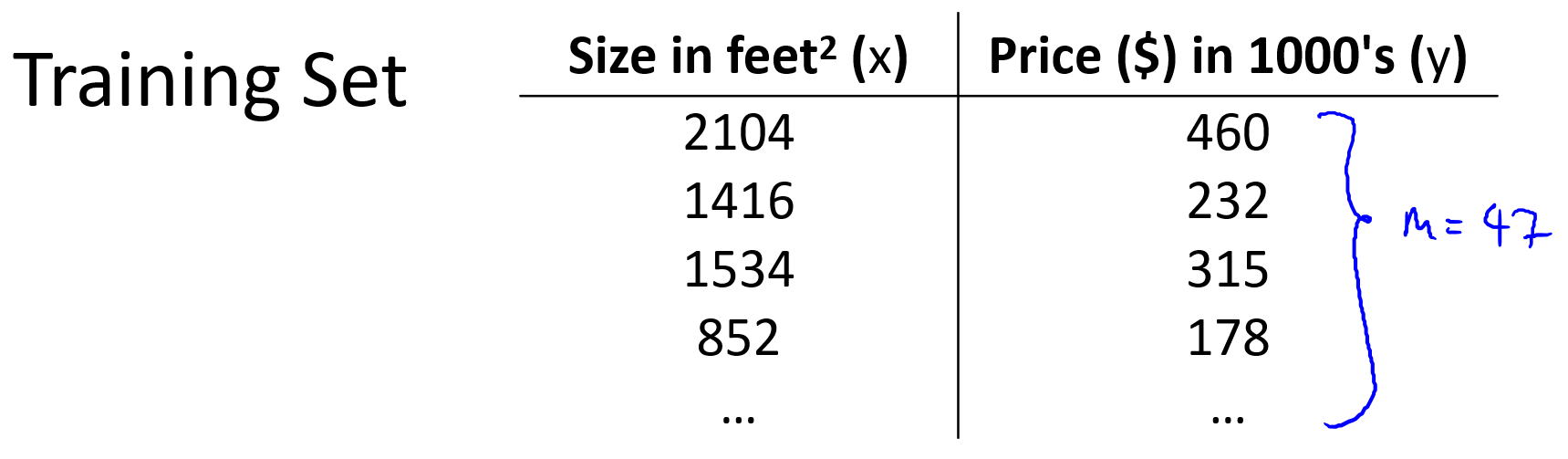
在課程中,使用以下符號來描述訓練集和模型結構:?
m:訓練樣本數量
x:特征/輸入變量(例如房子面積)
y:目標變量/輸出變量(例如房子價格)
:第 i?個訓練樣本
h:學習算法輸出的假設函數(hypothesis)
一個典型的監督學習過程如下:
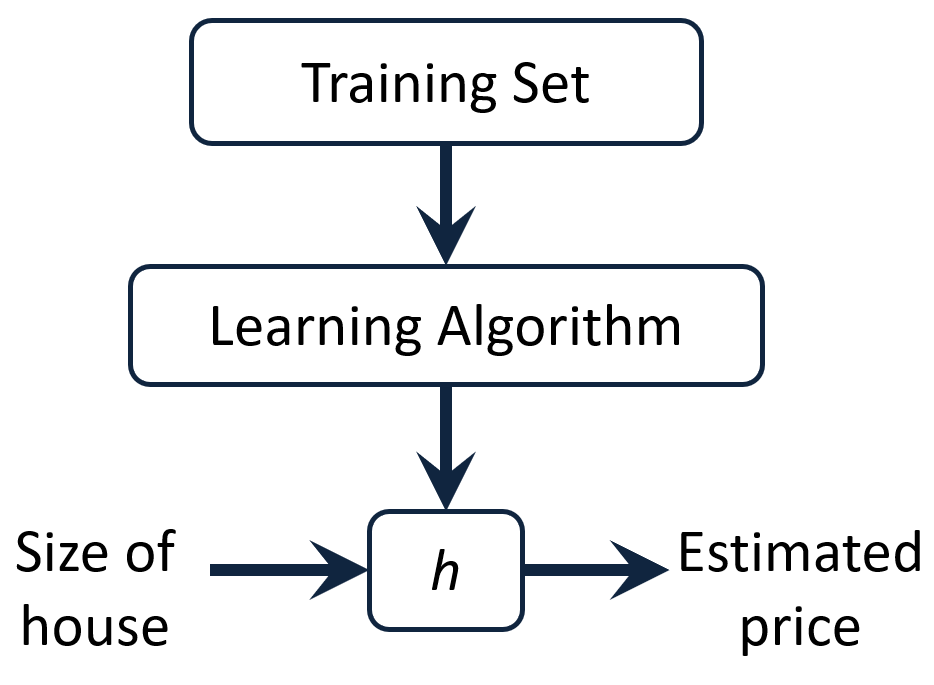
收集訓練數據,比如不同面積的房子及其對應價格。
將這些數據輸入給學習算法。
算法“學習”出一個函數 h,也就是我們的預測模型。
當想預測一套房子的售價時,只需將其面積作為輸入,使用這個函數 h?得到預測價格。
換句話說,我們希望找到一個函數 h,使得它能近似地預測出輸入 x(房屋面積)對應的輸出 y(價格)。這可以用線性函數表示為:
因為這里只有一個特征(房子面積),所以我們稱這種情況為單變量線性回歸。
二、代價函數
在這一節中我們將定義代價函數的概念,這有助于我們弄清楚如何把最有可能的直線與我們的數據相擬合。在上一節中,我們得到的假設函數為一個線性函數形式:
選擇不同的參數??和
?會得到不同的假設函數?
?,如下圖。
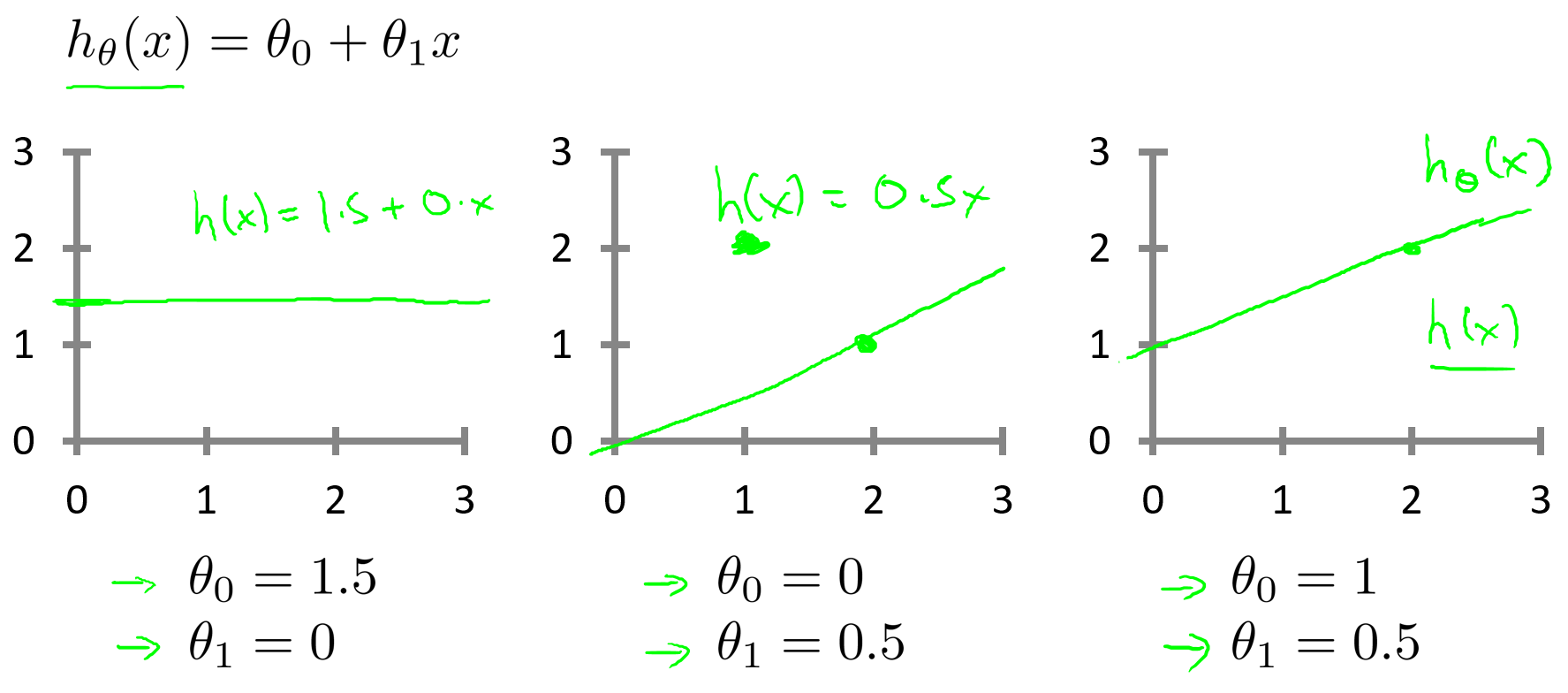
?稱為模型參數,我們要做的是選擇出一組合適的參數
?和
,使得模型預測值
?與實際值 y 的差距最小。這里給出標準定義,在線性回歸中要解決的是最小化問題。
最小化公式,加平方是為了使差距極其小
對所有訓練樣本的差距進行求和,
是為了盡量減少平均誤差
由于假設函數表示為
因此問題變成找到?
?和
?的值,使以下公式最小
?就是代價函數,這個函數也叫作 平方誤差代價函數,它是回歸問題中最常見也是最合理的選擇之一。
三、代價函數的直觀理解(1)
?在這一節中,為了更好地使代價函數J可視化,我們使用一個簡化的代價函數,可以讓我們更好的理解代價函數的概念。
將假設函數的參數?
那么代價函數就變為
優化目標就是盡量減少?
?的值
實際上,有兩個關鍵函數是我們需要去了解的。一個是假設函數?? ,第二個是代價函數?
?。假設函數h是對于給定的?
?的值,是一個關于 x 的函數。代價函數J是關于參數?
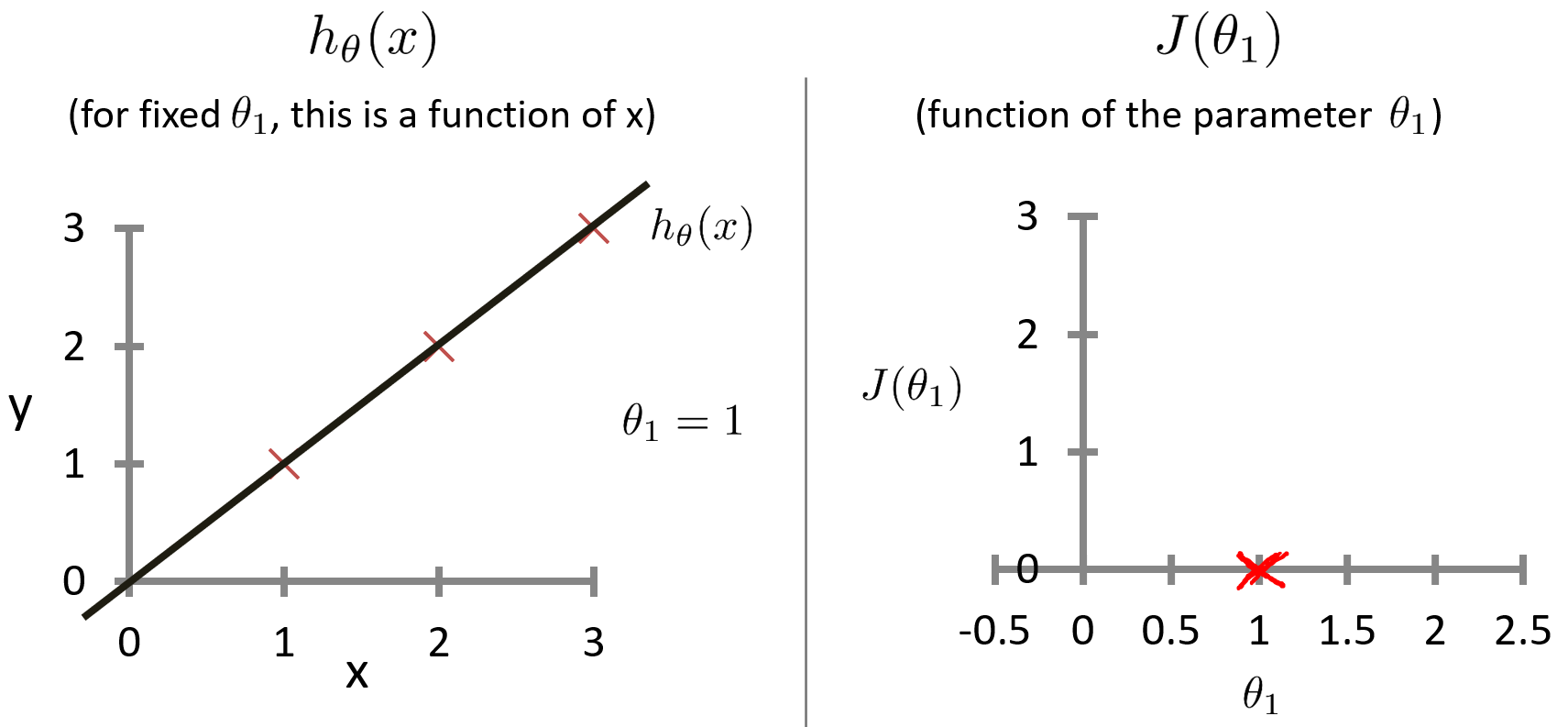
?的函數。假設有三個點的訓練集(1,1) (2,2) (3,3) ,當?
?時,代價函數J的值計算如下。
得出當?
?時,
,因此?
繪制的兩個函數的圖形如下。
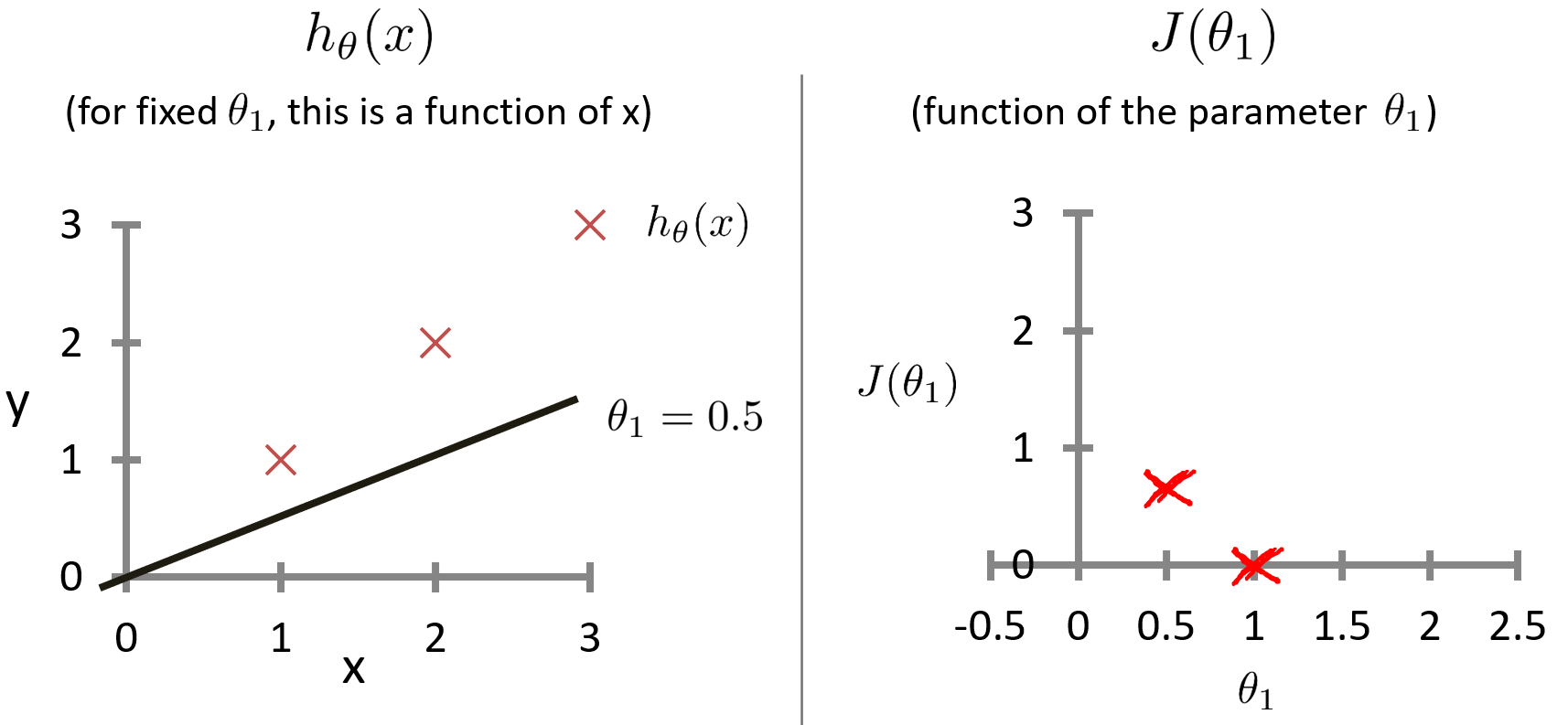
當??時,代價函數J的值計算如下。
得出當?
?時,?
繪制的兩個函數的圖形如下。
同理,計算出其它代價函數J的值,比如:
當?
?時,
當?
?時,
最終,得到的代價函數J的圖形如下。
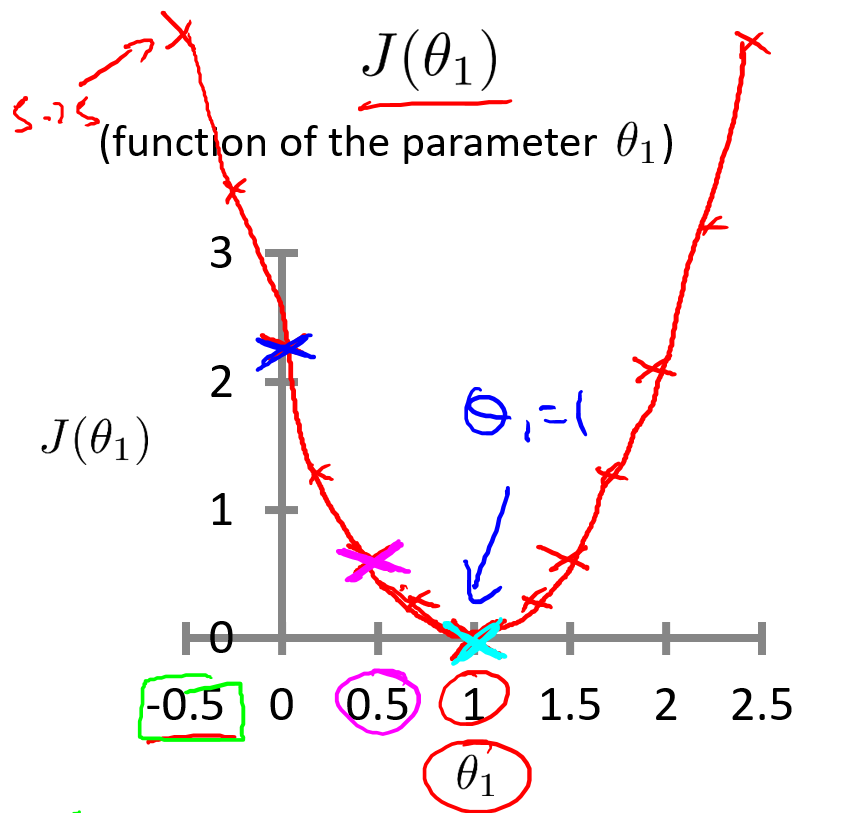
學習算法的優化目標,是通過選擇??的值,獲得最小的?
?。在這條曲線中,當?
?時,
?最小。通過觀察也可以得出,這是條完美擬合訓練集數據的直線。
四、代價函數的直觀理解(2)
在本節課程中,我們將更深入地學習代價函數的作用,并借助圖形化方式(等高線圖)來幫助我們直觀地理解其行為與最小值位置。下面是本節用到的公式,與上節不一樣的是保留參數??和
。
假設函數:? ?
模型參數:? ?
?
代價函數:? ?
優化目標:? ?
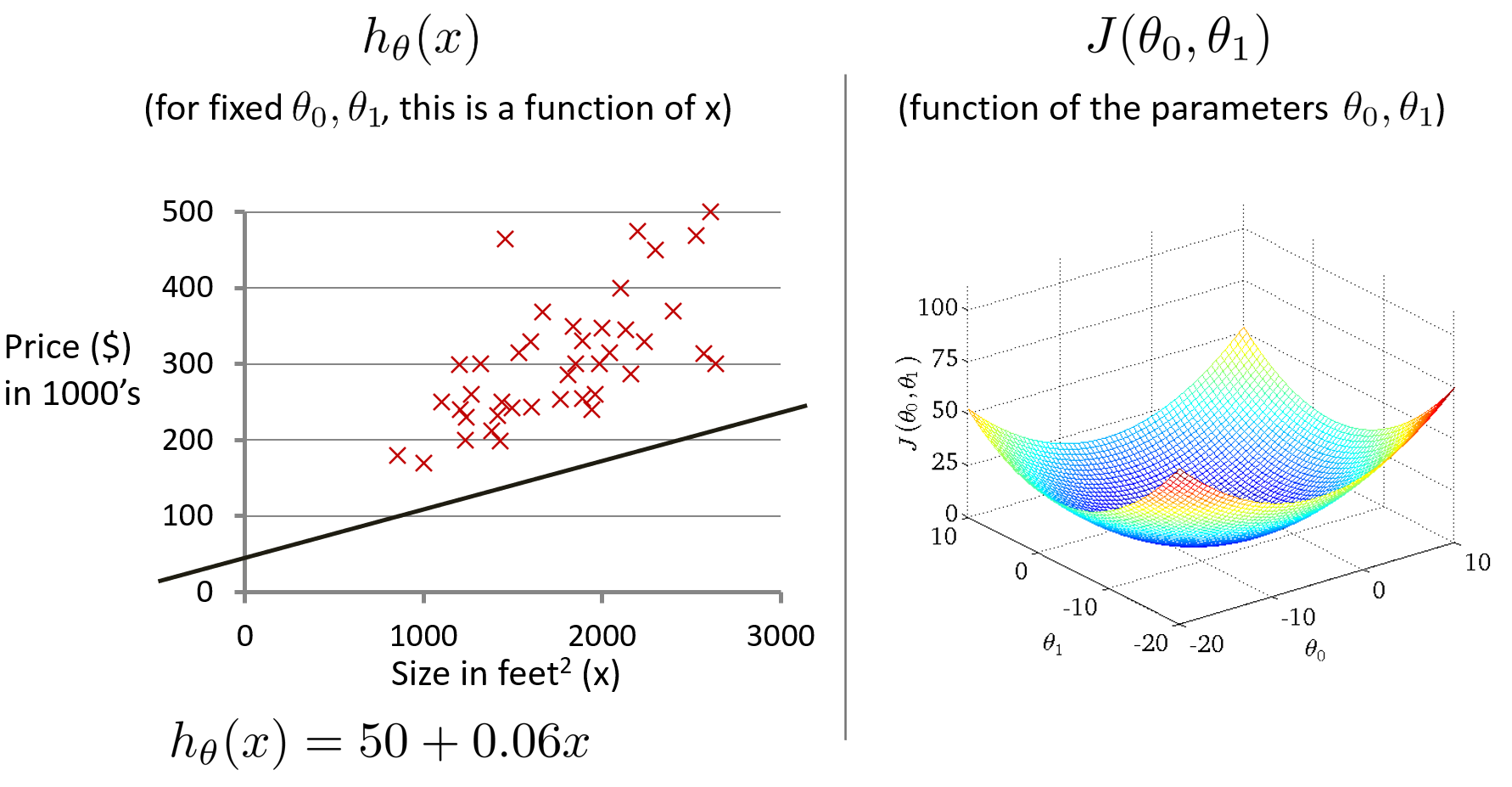
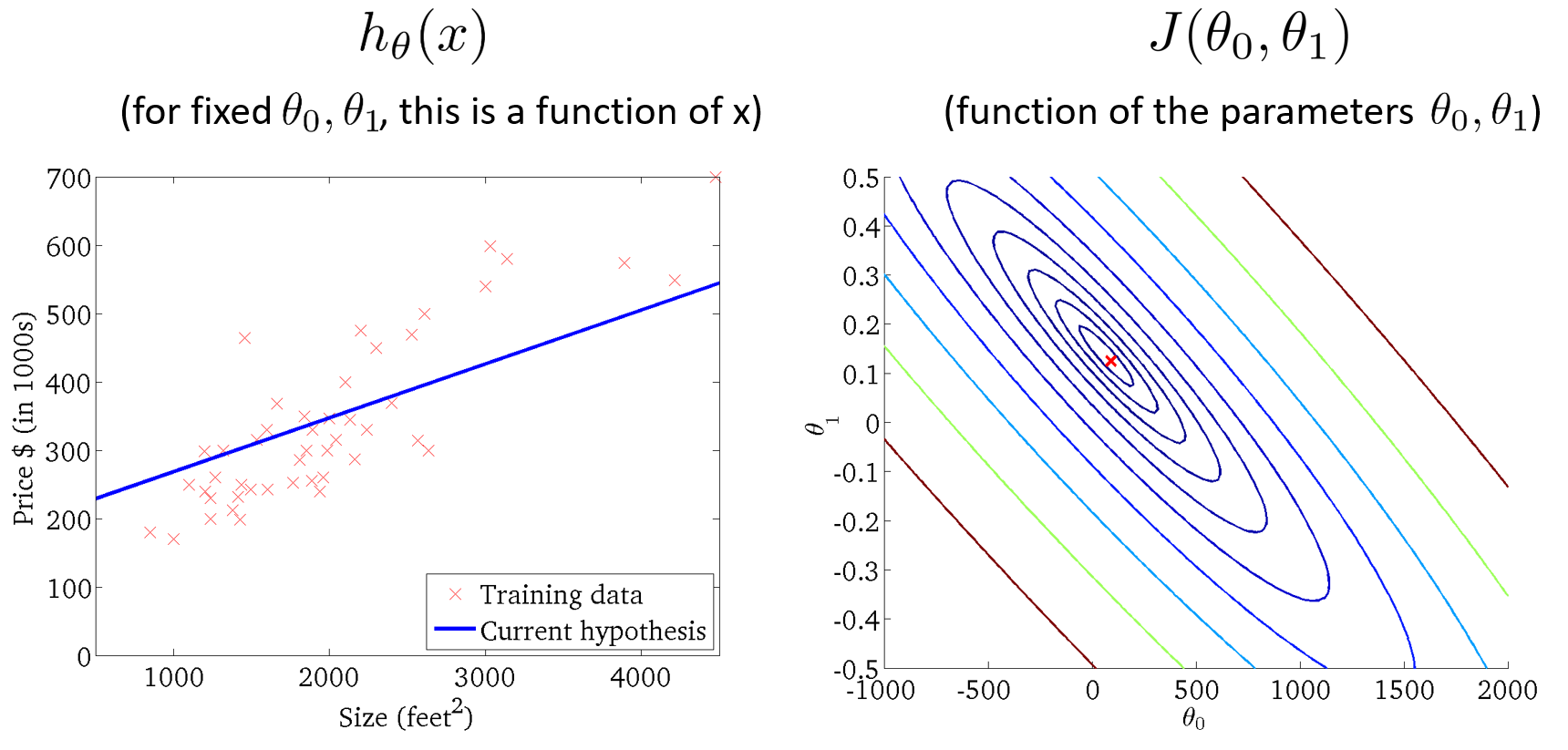
采用關于住房價格的訓練集,假設,繪制假設函數h和代價函數J的圖形。其中,代價函數J是關于?
?和
?的函數,是一個3D曲面圖,橫軸為?
?和
?,豎軸為代價函數J。
為了更好地展現圖形,?我們使用等高線圖來展示代價函數,軸為??和
?,每個橢圓形顯示一系列?
?值相等的點,這些同心橢圓的中心點是代價函數的最小值。右下圖是代價函數的等高線圖,左下圖是代價函數的最小值(橢圓的中心點)對應的假設函數的圖形。
五、梯度下降
在本節課程中,我們將使用梯度下降法替代在上節中的人工方法,來自動尋找代價函數J最小值對應的參數??和
?,也更適合處理在遇到更復雜、更高維度、更多參數的難以可視化的情況。
問題概述:假設有個代價函數?
?,我們需要用一個算法來最小化這個代價函數。
梯度下降法的思路:首先給定?
?和
?的初始值,通常為?
?,然后不停地一點點地改變?
通過圖像可以更直觀地理解梯度下降法是如何最小化代價函數J的。下圖是橫軸為??和
?,豎軸為代價函數J ,并對?
?和
?賦以不同的初始值。
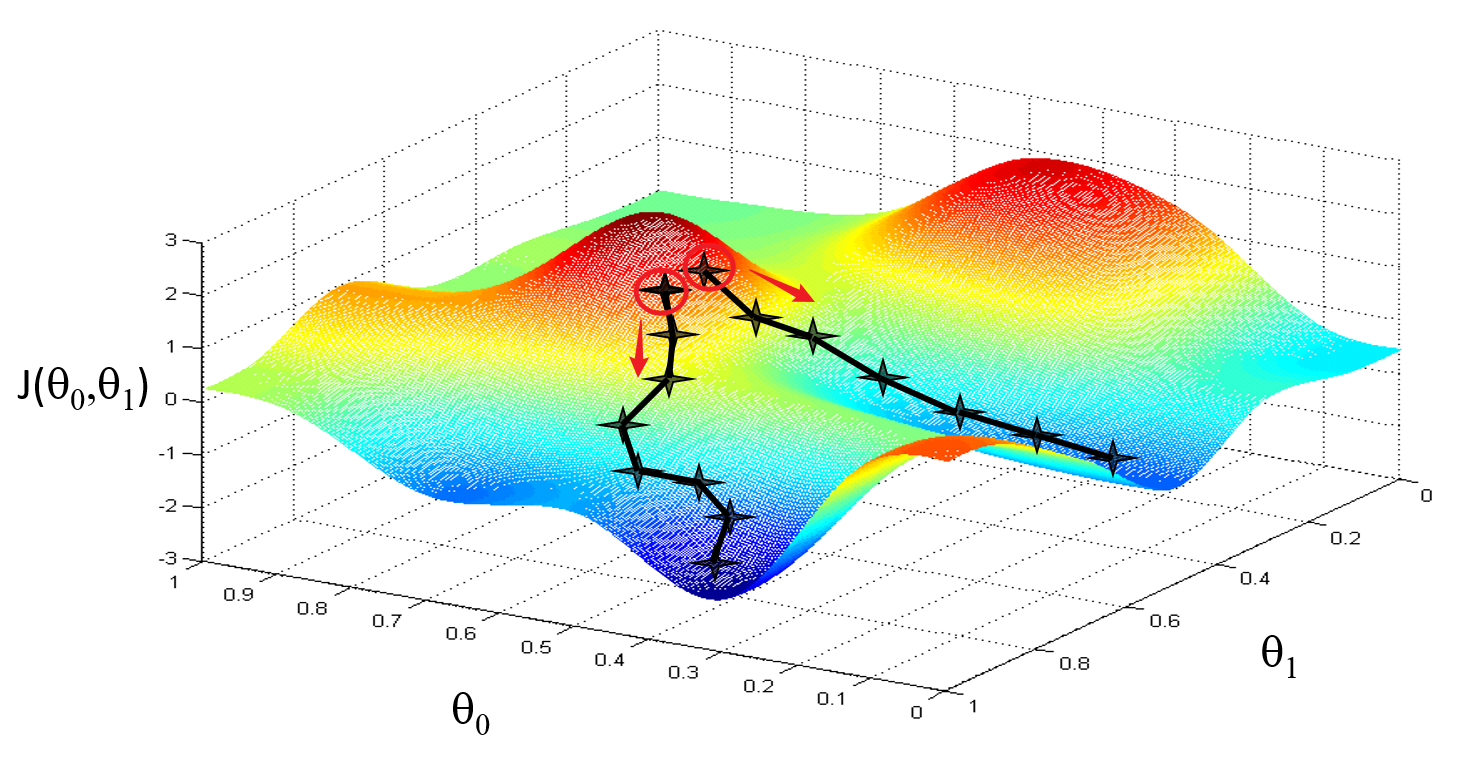
把這個圖像想象為公園中的兩座山,然后你正站在山上的一個點上,在梯度下降算法中,我們要做的就是旋轉360度,看看周圍,并問自己要盡快下山的話,我應該朝什么方向邁步?然后你按照自己的判斷邁出一步,重復上面的步驟,從這個新的點,你環顧四周,并決定從什么方向將會最快下山,然后又邁進了一小步,并依此類推,直到你接近局部最低點的位置。對?
如下圖是梯度下降法的數學定義,將會重復更新??的步驟,直到收斂。

其中是 α 學習率,用來控制梯度下降時邁出的步子有多大。如果 α 值很大,會用大步子下山,梯度下降就很迅速;如果 α 值很小,會邁著小碎步下山,梯度下降就很慢。?是代價函數J的導數,這跟微積分有關系。
要正確實現梯度下降法,還需要同時更新??和
?,左下圖的同時更新是正確的,右下圖沒有同時更新是錯誤的。

六、梯度下降的直觀理解
梯度下降算法的數學定義如下,其中,α 是學習率,?是導數項。本節課程將直觀認識這兩部分的作用,以及更新過程有什么意義。

下面將直觀解釋導數項的意義,如下圖像,是一個只有參數??的簡化的代價函數?
?的圖像,梯度下降算法的更新規則:
?
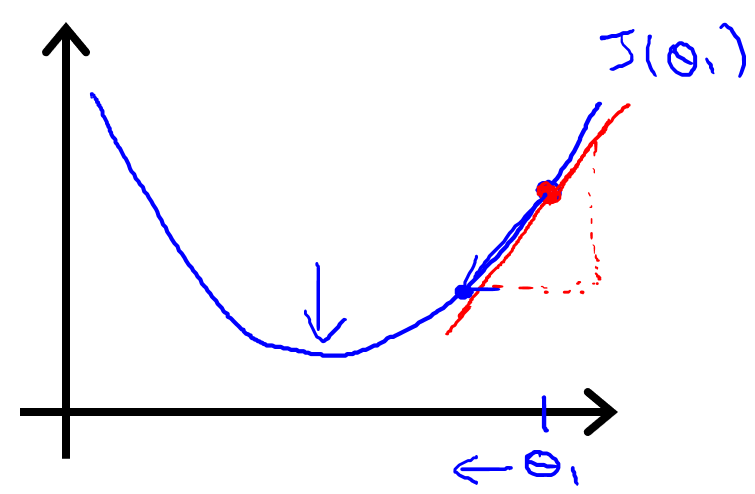
?導數項??可以說是?
?點關于代價函數?
?的切線的斜率,斜率可以表示?
? ?其中,β 是直線與?x?軸正方向的夾角。因此,圖中是個正斜率,也就是正導數,同時學習率 α 永遠是個正數,所以?
?更新后變小了,要往左移,更接近最低點。
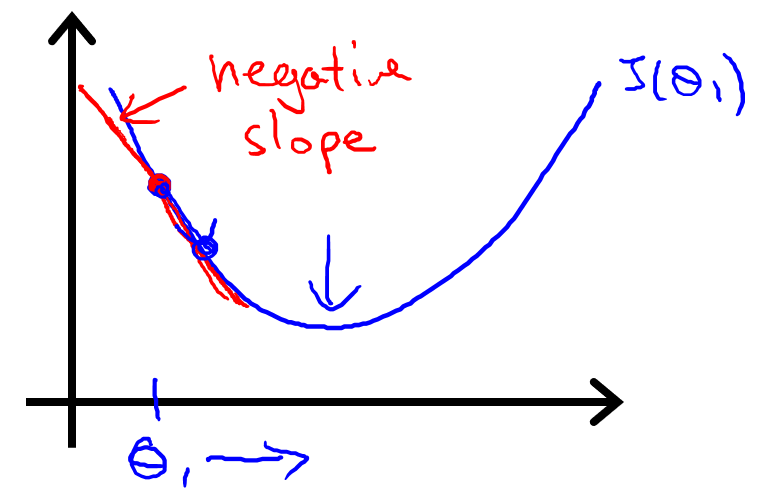
取另一個點??,如上圖,計算得出是負斜率,也就是負導數,所以?
?更新后變大了,要往右移,更接近最低點。
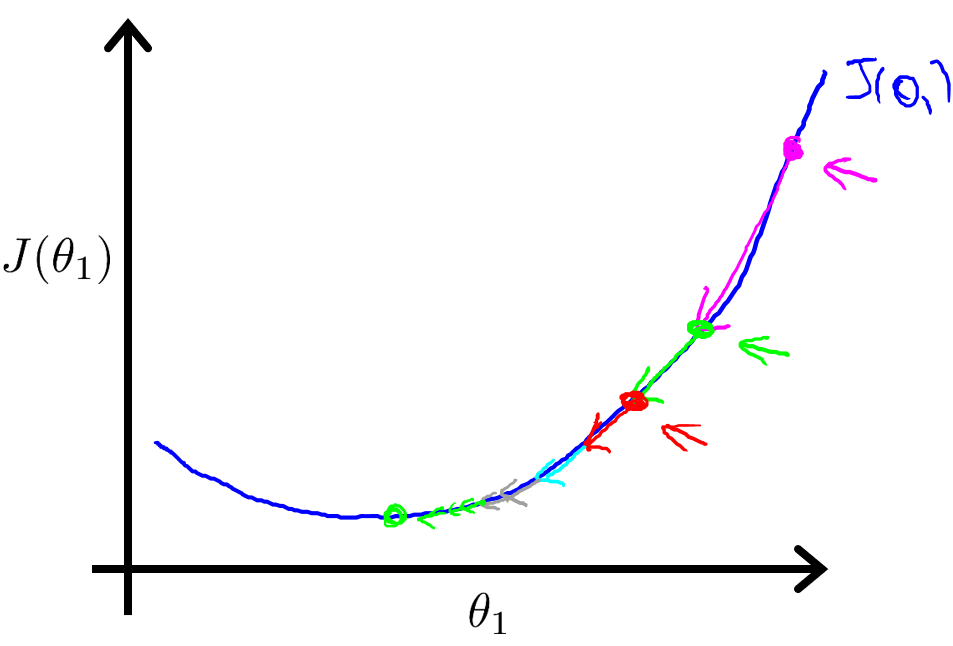
接下來介紹學習率?α 的作用,如果?α 太小,如下圖,結果就是會一點點地挪動,需要很多步才能到達全局最低點。
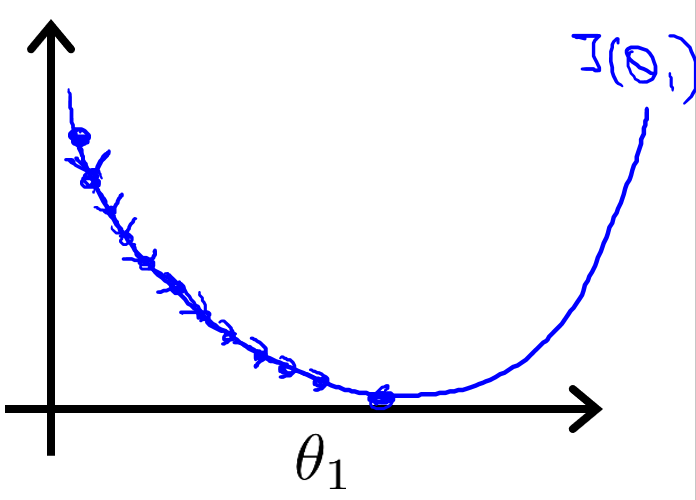
如果?α 太大,如下圖,那么梯度下降法可能會越過最低點,甚至可能無法收斂或者發散。
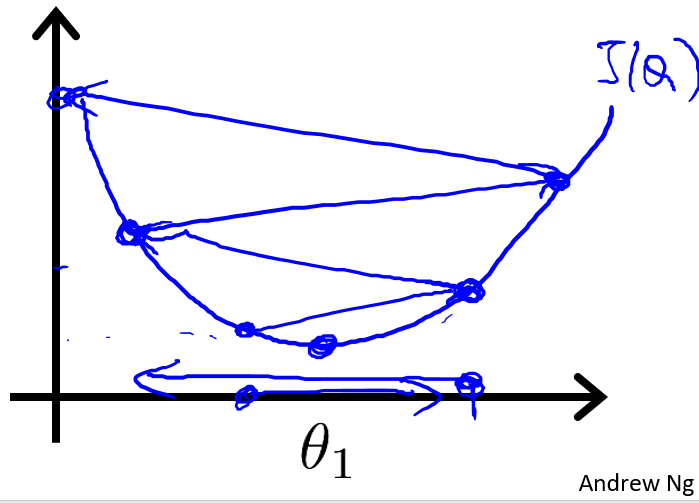
如果??已經處在一個局部的最低點,如下圖,由于最低點的斜率為0,也就是導數等于0,所以?
?將保持不變,那么梯度下降法更新其實什么都沒做,它不會改變參數的值。
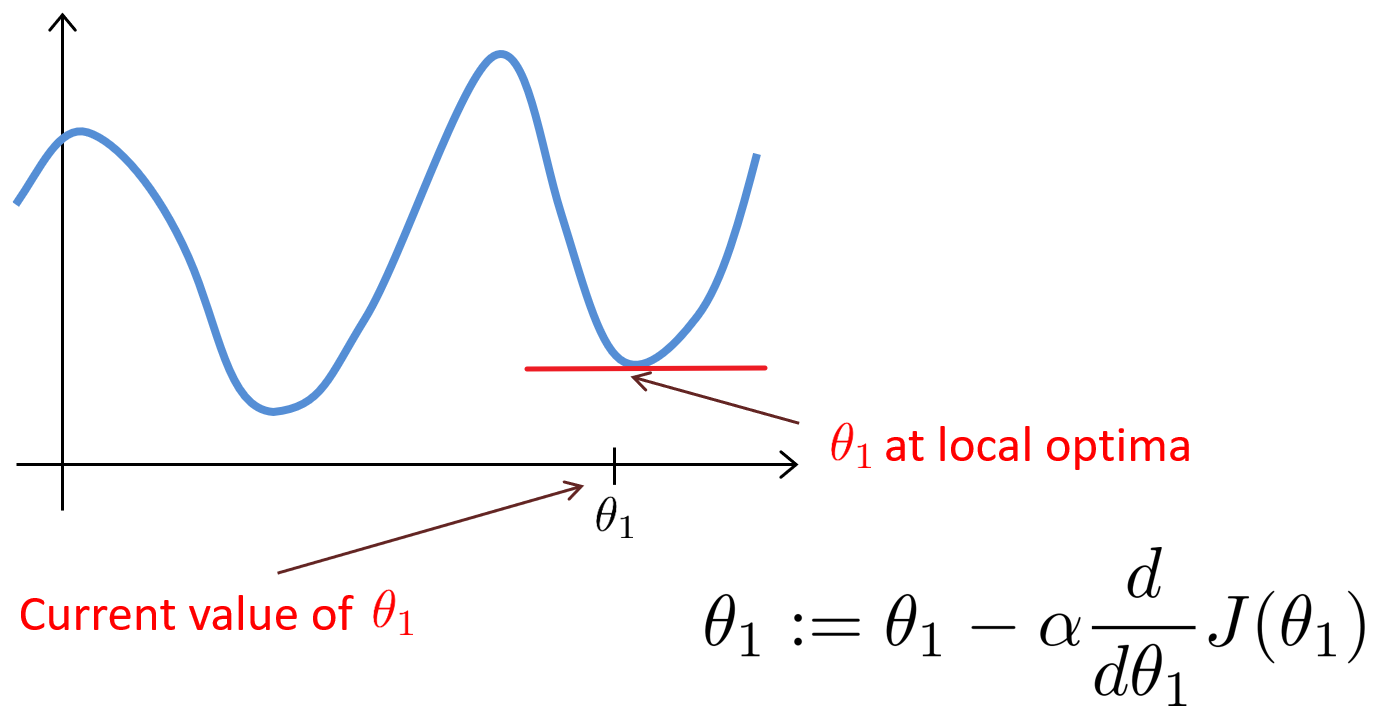
接下來解釋即使學習速率?α 保持不變時,梯度下降也可以收斂到局部最低點。如下圖,在梯度下降法的更新過程中,隨著越接近最低點,導數(斜率)越來越小,梯度下降將自動采取較小的幅度,??更新的幅度就會越小,直到收斂到局部極小值,這就是梯度下降的做法。所以實際上沒有必要再另外減小?α 。
七、線性回歸的梯度下降
在本節課程,我們要將梯度下降法和代價函數結合,得到線性回歸的算法,它可以用直線模型來擬合數據。如下圖,是梯度下降算法和線性回歸模型,線性回歸模型包含了假設函數和平方差代價函數。

將梯度下降法和代價函數結合,即最小化平方差代價函數,關鍵在于求出代價函數的導數
根據微積分公式,在 j 等于0和1時,推導出的偏導數公式如下
?根據公式計算出偏導數項的值,就可以代入到梯度下降法中,不斷地對參數進行同步更新,直到收斂,得到線性回歸的全局最優解。

在上面的算法中,有時也稱為”批量梯度下降”,指的是在梯度下降的每一步中,我們都用到了所有的訓練樣本。在梯度下降中,在計算微分求導項時,我們需要進行求和運算,需要對所有 m 個訓練樣本求和。而事實上,有時也有其他類型的梯度下降法,不是這種"批量"型的,不考慮整個的訓練集,而是每次只關注訓練集中的一些小的子集。
如果之前有學過高等線性代數,應該知道有一種計算代價函數 J 最小值的解法,而不需要使用梯度下降這種迭代算法。這是另一種稱為正規方程(normal equations)的方法。實際上在數據量較大的情況下,梯度下降法比正規方程要更適用一些。
)
--批退率通過率等數據分析)
)
















