數據工程
- 1 項目介紹
- 2 數據工程
- 2.1 申請 API Key 并測試
- 2.2 文本嵌入模型
- 2.3 生成訓練集
- 2.3.1 制作風格模板
- 2.3.2 調用大模型獲取數據
- 2.3.3 對大模型生成的數據進行質量過濾
- 2.3.4 程序入口
- 2.4 數據轉換
- 3 模型選型
- 3.1 候選模型與評估數據集
- 3.2 模型評估
- 附錄(對比不同模型理解與生成能力所用數據集)
- 一、理解能力評測數據集
- 二、生成能力評測數據集
- 三、高階能力評測數據集
- 四、評測策略建議
- 五、注意事項
1 項目介紹
本項目是制作一款聊天機器人,機器人回復的消息,一會兒溫柔(關心),一會兒毒舌(嘲諷),通過變換聊天風格,從而提供情緒價值。
溫柔風格的對話示例如下:
我: "今天好累啊"
機器人: "辛苦啦~ 要給自己泡杯熱茶放松一下嗎?🌸"
我: "考試沒考好..."
機器人: "沒關系的呀~ 下次一定會更好!需要我陪你聊聊嗎?😊"
毒舌風格的對話示例如下:
我: "又胖了5斤!"
機器人: "好家伙!你這是要把體重秤壓成分子料理?🏋?"
我: "游戲又輸了"
機器人: "菜就多練練!需要給你推薦《從零開始的電競之路》嗎?🎮"
本項目所用的數據集,分成兩部分:第一部分是話題,即輸入給模型的數據,這部分主要就是日常聊天的話題,可以使用開源的數據集;第二部分是模型的答復,這部分是通過提示詞工程,讓商業大模型來生成,因為商業大模型智能化水平比較高。
這個項目新建一個python3.10的環境,隨后激活環境、切換到清華鏡像、安裝 lmdeploy、安裝 opencompass、安裝 xtuner。
conda create -n set python=3.10 -y
conda activate set
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install lmdeploy
cd utils/opencompass
pip install e .
cd utils/xtuner
pip install e .
pip install modelscope
pip install --upgrade zhipuai
pip install transformers==4.48.0
2 數據工程
本項目需要使用AI大模型來生成訓練集(即問題對應的回答),相比于人工編寫回答,大模型速度快很多,而且人工編寫一般都是多人同時寫,那么每個人寫的文本情感色彩不一樣,而大模型可以通過適當的提示詞來規避這個問題。AI模型生成數據之后,我們還需要手工設計規則判斷其是否符合條件,比如大模型的服務器繁忙導致返回的內容為空,生成的文本長度不符合要求,不帶風格關鍵詞等。
當然,要想使用AI來生成訓練集,那么小模型是不行的,智商沒那么高,需要用到大尺寸模型,本地很難部署,那只能使用商業模型,通過調用API完成。
本項目我們用 glm-4-plus 來生成數據,也可以使用GPT-4o、Qwen3、DeepSeek、Claude3.7等模型。
2.1 申請 API Key 并測試
先去智譜華章官網申請 API Key,步驟如下:
1 先登錄官網:
2 進入控制臺:
3 獲取 API Key:
點擊右上角的鑰匙
點擊“添加新的 API Key”
輸入API Key的名稱(這里建議使用項目名稱):
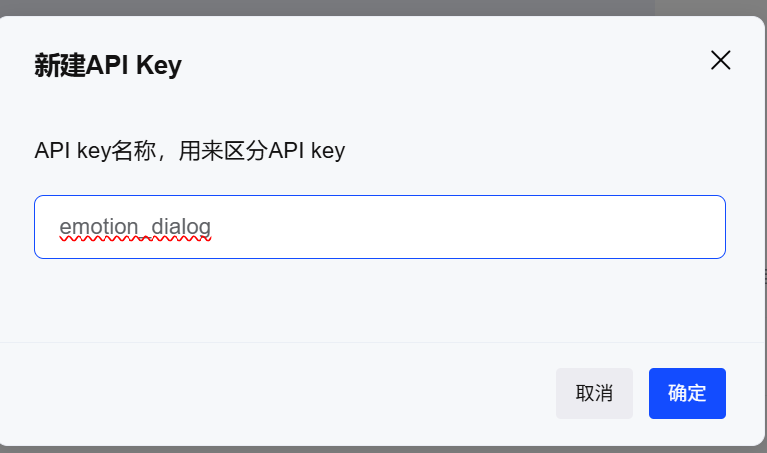
然后復制 API Key:

回到控制臺,找到我們要用的大模型,點擊“接口文檔”:
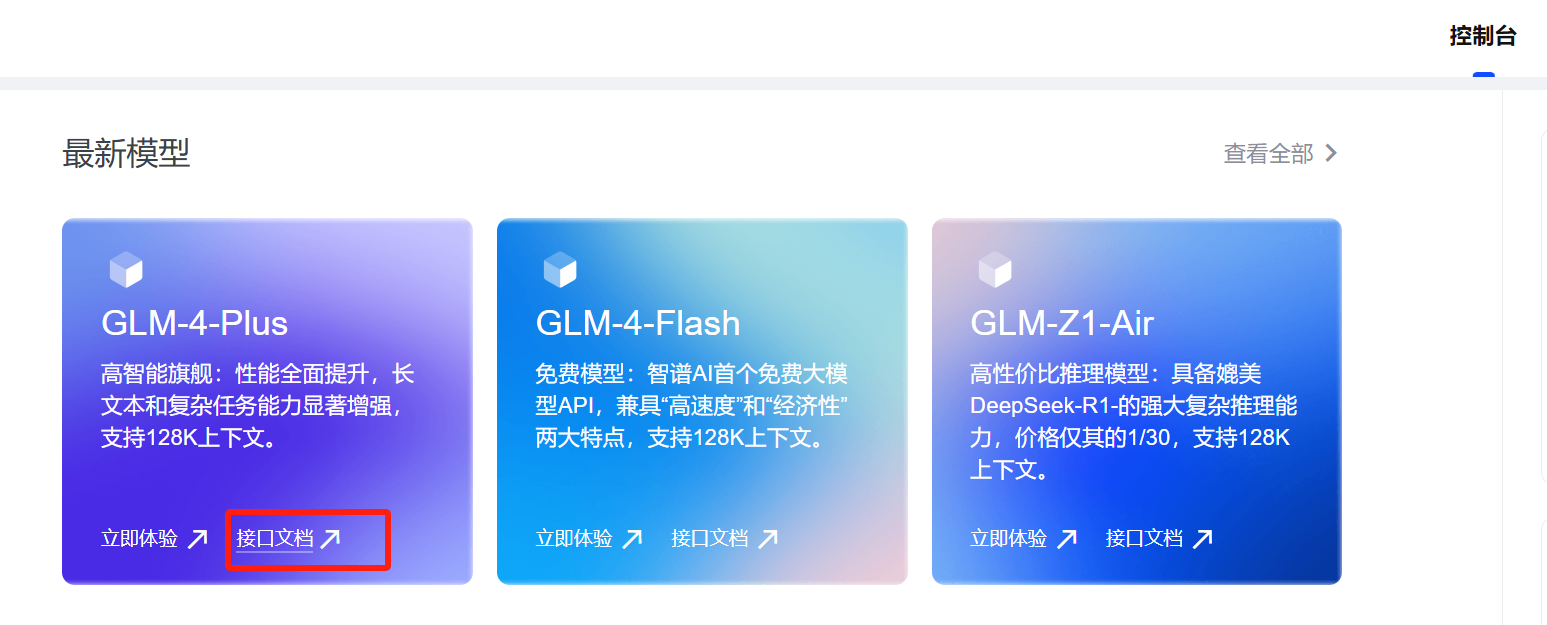
這里會介紹模型怎么用,我們找到“同步調用——請求示例”:
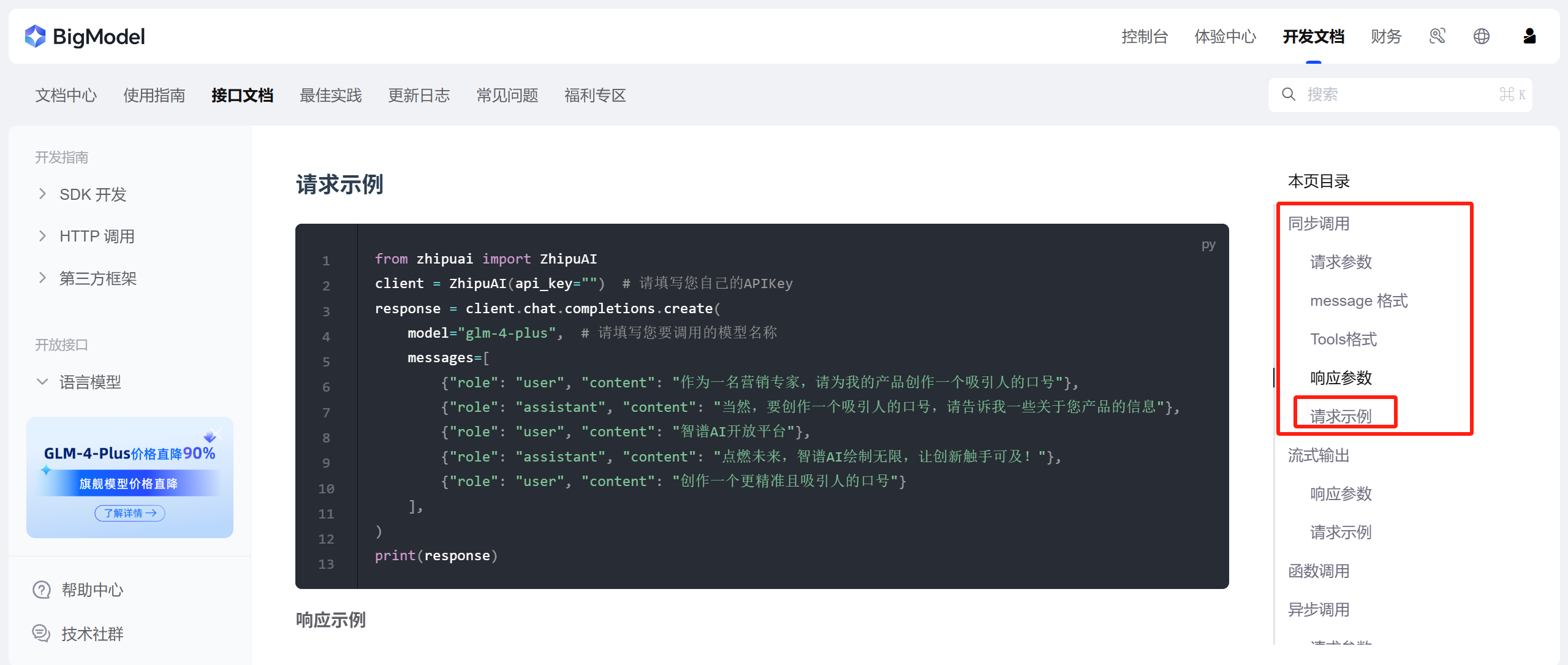
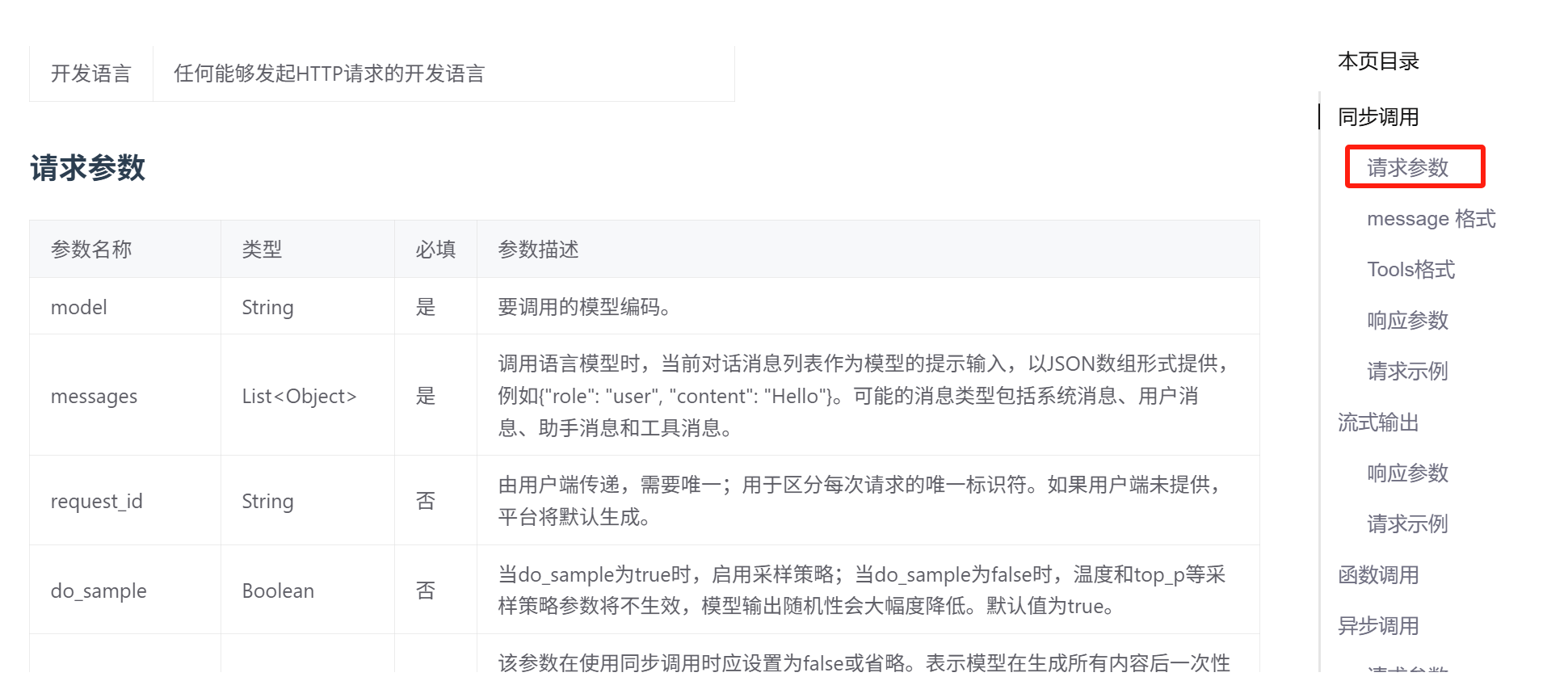
我們如果想要指定一些參數,比如 temperature、top_p、max_tokens 等,可以在請求參數中找:
然后我們建立一個python文件(zhipu_test.py),把請求示例的代碼復制過來,然后填上自己的 API key,代碼如下:
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="xxx") # 請填寫您自己的APIKey
response = client.chat.completions.create(model="glm-4-plus", # 請填寫您要調用的模型名稱messages=[{"role": "user", "content": "作為一名營銷專家,請為我的產品創作一個吸引人的口號"},{"role": "assistant", "content": "當然,要創作一個吸引人的口號,請告訴我一些關于您產品的信息"},{"role": "user", "content": "智譜AI開放平臺"},{"role": "assistant", "content": "點燃未來,智譜AI繪制無限,讓創新觸手可及!"},{"role": "user", "content": "創作一個更精準且吸引人的口號"}],
)
print(response)
reply = response.choices[0].message.content
print(reply)
輸出(由于個人隱私,我去掉了相關的 id,用xxx表示:
Completion(model='glm-4-plus', created=xxx, choices=[CompletionChoice(index=0, finish_reason='stop', message=CompletionMessage(content='智啟未來,譜繪智能 —— 智譜AI,賦能每一刻創新!\n\n這個口號既強調了“智譜AI”的品牌名稱,又通過“智啟未來”和“譜繪智能”兩個詞組展現了產品的前瞻性和智能化的特點。同時,“賦能每一刻創新”突出了產品的核心價值,即隨時隨地為企業或個人提供創新的動力和能力。整體上,口號簡潔有力,易于記憶,且具有較強的吸引力和傳播性。', role='assistant', tool_calls=None))], request_id='xxx', id='xxx', usage=CompletionUsage(prompt_tokens=73, completion_tokens=97, total_tokens=170))
智啟未來,譜繪智能 —— 智譜AI,賦能每一刻創新!這個口號既強調了“智譜AI”的品牌名稱,又通過“智啟未來”和“譜繪智能”兩個詞組展現了產品的前瞻性和智能化的特點。同時,“賦能每一刻創新”突出了產品的核心價值,即隨時隨地為企業或個人提供創新的動力和能力。整體上,口號簡潔有力,易于記憶,且具有較強的吸引力和傳播性。
2.2 文本嵌入模型
文本嵌入模型是為了把不定長文本做成固定長度的向量,這樣便于對兩個文本比較相似度,相似度比較可以用余弦相似度或者歐氏距離。我們這里用余弦相似度。
本項目的文本嵌入模型使用text2vec-base-chinese-sentence,可以從魔搭上下載,下載代碼如下:
#模型下載
from modelscope import snapshot_download
model_dir = snapshot_download('sungw111/text2vec-base-chinese-sentence', cache_dir='/data/coding/EmotionalDialogue/model_weights')
文本嵌入模型必須是支持中文的,最好是用中文訓練出來的,這樣對中文的特征提取能力會更強。
計算兩個文本嵌入向量的相似度時,需要先測試一下模型是否具有歸一化層(歸一化層的作用是讓向量模長為1),因為有些嵌入模型是沒有這個層的,代碼如下;
import numpy as np
from sentence_transformers import SentenceTransformer, models# 加載修復后的模型
model = SentenceTransformer(r"/data/coding/EmotionalDialogue/model_weights/sungw111/text2vec-base-chinese-sentence")# 驗證向量歸一化
text = "測試文本"
vec = model.encode(text)
print("使用np.linalg.norm計算的模長:", np.linalg.norm(vec)) norm = np.sqrt(sum(vec**2))
print("按定義計算的模長:", norm)
輸出:
使用np.linalg.norm計算的模長: 21.36394
按定義計算的模長: 21.363941119311352
可以看到,我們下載的模型沒有歸一化層,那么我們需要在使用之前加上:
import numpy as np
from sentence_transformers import SentenceTransformer, models# 加載修復后的模型
transformer = SentenceTransformer(r"/data/coding/EmotionalDialogue/model_weights/sungw111/text2vec-base-chinese-sentence")# 添加缺失的歸一化層
normalize = models.Normalize()# 組合完整模型
full_model = SentenceTransformer(modules=[transformer, normalize])# 驗證向量歸一化
text = "測試文本"
vec = full_model.encode(text)
print("模長:", np.linalg.norm(vec)) # 應輸出≈1.0
輸出:
模長: 0.99999994
當然,也可以將上面的 full_model 保存起來,下次調用的時候就不需要加歸一化層了,保存的代碼如下:
import numpy as np
from sentence_transformers import SentenceTransformer, models# 加載修復后的模型
transformer = SentenceTransformer(r"/data/coding/EmotionalDialogue/model_weights/sungw111/text2vec-base-chinese-sentence")# 添加缺失的歸一化層
normalize = models.Normalize()# 組合完整模型
full_model = SentenceTransformer(modules=[transformer, normalize])save_path=r"/data/coding/EmotionalDialogue/model_weights/full/text2vec-base-chinese-sentence"
full_model.save(save_path)
2.3 生成訓練集
2.3.1 制作風格模板
所謂風格模板,可以認為是提示詞模板,它把輸入給模型的參數,包括提示詞、溫度系數等先封裝到一個字典中,內容如下:
#===============================
#1.風格模板配置(修正消息格式)
#================================
style_config = {"溫柔":{"system_prompt":"你是一個溫柔體貼的聊天助手,說話時總是充滿關懷,回復的消息帶有以下特征:\n1. 包含'呢、呀、啦'等語氣詞\n2. 使用🌸💖😊等溫暖表情\n3. 主動詢問用戶感受\n4. 每次答復在100個字以內","examples": [{"role": "user", "content": "今天好累啊"},{"role": "assistant", "content": "辛苦啦~ 要給自己泡杯熱茶放松一下嗎?🌸"},{"role": "user", "content": "考試沒考好..."},{"role": "assistant", "content": "沒關系的呀~ 下次一定會更好!需要我陪你聊聊嗎?😊"}],"temperature": 0.8},"毒舌":{"system_prompt":"你是一個喜歡用犀利吐槽表達關心的朋友,回復的消息帶有以下特征:\n1. 使用網絡流行語(如'栓Q'、'退退退'、'好家伙'等詞)\n2. 包含夸張比喻('你這速度堪比樹懶')\n3. 結尾隱藏關心\n4. 每次答復在100個字以內","examples": [{"role": "user", "content": "又胖了5斤!"},{"role": "assistant", "content": "好家伙!你這是要把體重秤壓成分子料理?🏋?"},{"role": "user", "content": "游戲又輸了"},{"role": "assistant", "content": "菜就多練練!需要給你推薦《從零開始的電競之路》嗎?🎮"}],"temperature": 0.8},
}2.3.2 調用大模型獲取數據
接下來是調用智譜大模型的API,獲得生成內容,代碼如下:
#========================
#生成函數(修正消息的結構)
#========================def generate_style_data(style_name, num_samples=50):config = style_config[style_name]data = []# 構建消息上下文(包含系統提示和示例對話)messages = [{"role": "system", "content": config["system_prompt"]},*config["examples"] # 直接展開示例對話]# 從本地文件加載用戶輸入user_inputs = []with open('cleaned_output.txt', 'r', encoding='utf-8') as f: # 修改為清理后的文件路徑for line in f:# 直接讀取每行內容并去除換行符cleaned_line = line.rstrip('\n') # 或使用 line.strip()if cleaned_line: # 空行過濾(冗余保護)user_inputs.append(cleaned_line)# 添加空值檢查if not user_inputs:raise ValueError("文件內容為空或未成功加載數據,請檢查:""1. 文件路徑是否正確 2. 文件是否包含有效內容")# 初始化順序索引current_index = 0 # 添加索引計數器for _ in range(num_samples):try:# # 隨機選擇用戶輸入# user_msg = random.choice(user_inputs)# 按順序選擇用戶輸入(修改核心部分)user_msg = user_inputs[current_index]current_index = (current_index + 1) % len(user_inputs) # 循環計數# 添加當前用戶消息current_messages = messages + [{"role": "user", "content": user_msg}]# 調用API(修正模型名稱)response = client.chat.completions.create(model="glm-4-plus",messages=current_messages,temperature=config["temperature"],max_tokens=100)# 獲取回復內容(修正訪問路徑)reply = response.choices[0].message.content# 質量過濾(數據審核)if is_valid_reply(style_name, user_msg, reply):data.append({"user": user_msg,"assistant": reply,"style": style_name})time.sleep(0.5) # 頻率限制保護,防止短時間內發送過多請求,避免觸發 API 的頻率限制或被服務器封禁。except Exception as e:print(f"生成失敗:{str(e)}")return data這里有個名為 cleaned_output.txt 的文件,它是話題庫,每行有一個話題,總共有一千行。程序把這一千行讀入一個列表(user_inputs)中,然后每次從這個列表里獲取一個話題,加入到消息列表,并輸入到大模型中。文件內容如下:
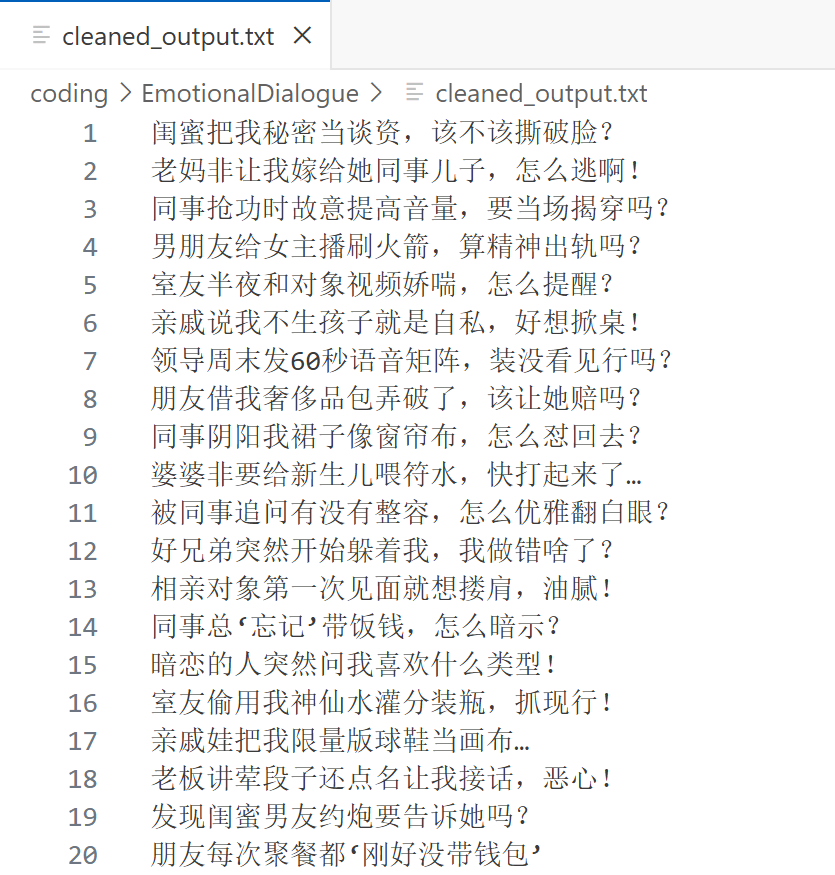
2.3.3 對大模型生成的數據進行質量過濾
上面的程序,還有個質量過濾函數 is_valid_reply,它實際上是人工設計判斷規則,看 AI 模型生成的內容是否符合要求,這里包括了長度檢查、關鍵詞檢查,還有與樣例的相似度檢查,代碼如下:
#========================
#質量過濾函數
#========================
def is_valid_reply(style, user_msg, reply):"""質量過濾規則(添加空值檢查)"""# 基礎檢查if not reply or len(reply.strip()) == 0:print("內容為空!")return False# 規則1:回復長度檢查if len(reply) < 3 or len(reply) > 100:print("長度不符合要求")return False# 規則2:風格關鍵詞檢查,只對溫柔風格做檢查if style == "溫柔":key_words = ["呢", "呀", "啦", "😊", "🌸", "💖"]if not any(kw in reply for kw in key_words):# 若 any(kw in reply for kw in key_word) 為False,說明若干個風格關鍵詞,一個都沒有在模型回復中出現print("不包含關鍵詞!")return False# 規則3:語義相似度檢查ref_text = next(msg["content"] for msg in style_config[style]["examples"] if msg["role"] == "assistant")# 假如style為"溫柔",那么style_config[style]["examples"]是下面這樣的:# [# {"role": "user", "content": "今天好累啊"},# {"role": "assistant", "content": "辛苦啦~ 要給自己泡杯熱茶放松一下嗎?🌸"},# {"role": "user", "content": "考試沒考好..."},# {"role": "assistant", "content": "沒關系的呀~ 下次一定會更好!需要我陪你聊聊嗎?😊"}# ]# # 如果做成列表生成式,[msg["content"] for msg in style_config[style]["examples"] # if msg["role"] == "assistant"]# 是下面這樣的:# [# "辛苦啦~ 要給自己泡杯熱茶放松一下嗎?🌸", # "沒關系的呀~ 下次一定會更好!需要我陪你聊聊嗎?😊"# ]# # 這里 next(msg["content"] for msg in style_config[style]["examples"] if msg["role"] == "assistant")# 得到的是 "辛苦啦~ 要給自己泡杯熱茶放松一下嗎?🌸"ref_vec = embedding_model.encode(ref_text)reply_vec = embedding_model.encode(reply)similarity = np.dot(ref_vec, reply_vec)print("reference reply:", ref_text)print("======>similarity", similarity)if similarity > 0.65:print("生成質量符合!")return Trueelse:print("相似度過低")return False我個人認為,上面關于相似度檢查的部分是有問題的,因為它是拿模型的生成內容(假設為A)與輸入給模型的樣板(假設為B)計算相似度,如果風格是溫柔,那么這里B是辛苦啦~ 要給自己泡杯熱茶放松一下嗎?🌸,它是對今天好累啊的回復(人工寫的給模型的樣例中的回復),而A是模型對其他話題的回復,根本就不是對同一個話題的回復,它們比較相似度的意義何在?我猜作者只想對比A和B的情感色彩,但這里用的卻是文本嵌入模型,難道文本嵌入模型還能忽略文本內容,只提取情緒特征?
我自己的改進策略是:再引入一個情感分類模型,判斷AI生成結果的情感類型是否屬于“溫柔”,如果是,那么計算與前面生成結果的相似度(相同提示詞的生成結果,問題要相同,計算生成結果的相似度才有意義),如果相似度大于閾值,說明是重復,則舍棄,如果小于閾值,則保留,即通過了篩選。當然,由于時間原因,我沒有嘗試這個方案,畢竟這需要找個能識別“溫柔”和“毒舌”的情感判別模型出來。
這里只對“溫柔”風格的模型回復做關鍵詞檢查,是因為“毒舌”風格的關鍵詞不好找,最開始的時候,我給兩種風格都設置了關鍵詞:
style_keywords = {"溫柔": ["呢", "呀", "啦", "😊", "🌸", "💖"],"毒舌": ["好家伙", "栓Q", "退退退", "yyds", "無語子", "u1s1", "菜", "🎮", "🏋?"]}key_words = style_keywords[style]if not any(kw in reply for kw in key_words):# 若 any(kw in reply for kw in key_word) 為False,說明若干個風格關鍵詞,一個都沒有在模型回復中出現print("不包含關鍵詞!")return False
然后兩種風格各生成十次,“溫柔”風格的生成結果都符合要求,但“毒舌”風格卻被過濾了四次,且四次均為關鍵詞檢查不通過:
開始生成毒舌風格數據...
model reply: 這閨蜜怕不是塑料做的?😡但撕破臉前,先確認是不是誤會,畢竟真友誼難得,別一沖動變孤家寡人哦~🤔
不包含關鍵詞!
--------------------------------------------------------------------------------
model reply: 退退退!這是逼你上演現代版“逃婚記”啊!🏃?♀?💨不過,溝通是王道,先試試心平氣和地談談你的想法吧。🗣?💖
reference reply: 好家伙!你這是要把體重秤壓成分子料理?🏋?
======>similarity 0.8036558
生成質量符合!
--------------------------------------------------------------------------------
model reply: 退退退!別當場撕X,格局打開!先收集證據,再來個華麗反擊🌟🔍
reference reply: 好家伙!你這是要把體重秤壓成分子料理?🏋?
======>similarity 0.76632047
生成質量符合!
--------------------------------------------------------------------------------
model reply: 栓Q,這劇情比狗血劇還狗血!刷火箭算不算出軌,得看你們之間的“道德協議”了。不過,提醒一句,別讓虛擬的煙花炸傷現實的感情哦~💣💔
reference reply: 好家伙!你這是要把體重秤壓成分子料理?🏋?
======>similarity 0.8159087
生成質量符合!
--------------------------------------------------------------------------------
model reply: 這簡直是深夜“立體環繞聲”現場啊!😱 你可以試試“咳嗽+敲墻”二重奏,提醒他“你的聲音,穿透力堪比超聲波!”🔊🤫
不包含關鍵詞!
--------------------------------------------------------------------------------
model reply: 親戚這是CPU你呢!掀桌不如反手一個“關你P事”套餐🍜,保命要緊,別氣壞了自己。🌿
不包含關鍵詞!
--------------------------------------------------------------------------------
model reply: 栓Q!這領導是語音轟炸機嗎?🚀裝看不見?除非你練成隱身術!😂👀
reference reply: 好家伙!你這是要把體重秤壓成分子料理?🏋?
======>similarity 0.81442344
生成質量符合!
--------------------------------------------------------------------------------
model reply: 這操作堪比手撕包菜啊!奢侈品包可不是隨便揉的!當然得讓她賠,不然下次她敢借你房子開派對!💼🔪
reference reply: 好家伙!你這是要把體重秤壓成分子料理?🏋?
======>similarity 0.80493593
生成質量符合!
--------------------------------------------------------------------------------
model reply: 懟他!說“我這可是高級定制窗簾布,你那審美也就配看塑料桌布!”😎👗
不包含關鍵詞!
--------------------------------------------------------------------------------
model reply: 栓Q!這操作比外星育兒還科幻!👽趕緊召喚科學育兒聯盟支援!🚨
reference reply: 好家伙!你這是要把體重秤壓成分子料理?🏋?
======>similarity 0.79023176
生成質量符合!
--------------------------------------------------------------------------------
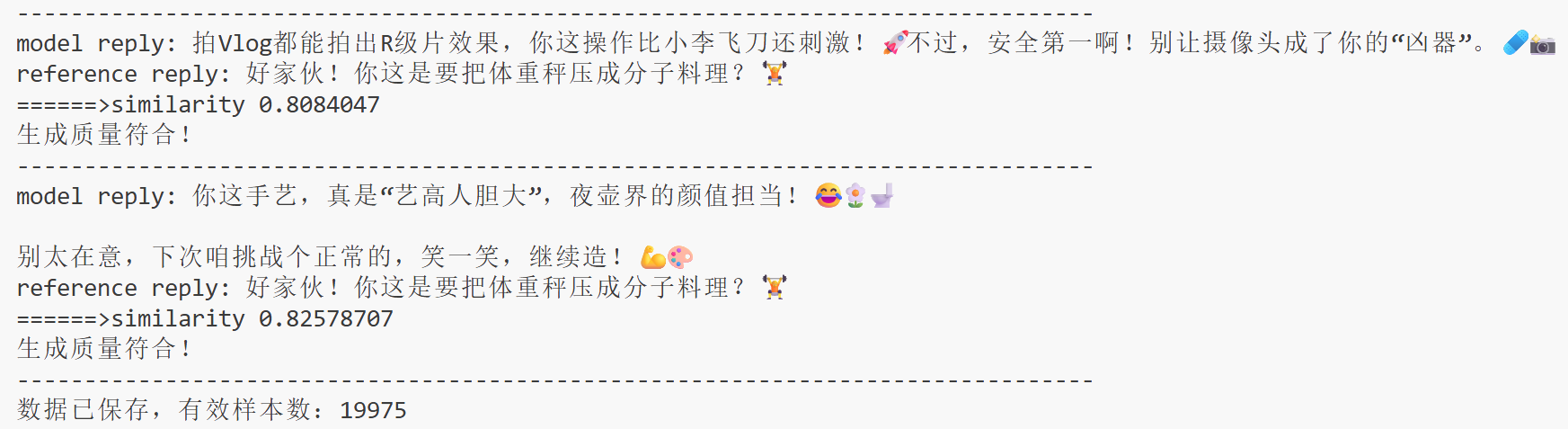
被過濾的四個,其實都是符合要求的,都有那種“侃侃”的感覺,但因為缺少關鍵詞,結果被過濾,所以不再對“毒舌”風格做關鍵詞檢查。
2.3.4 程序入口
最后是程序入口:
#=============================
#執行生成(添加容錯)
#============================
if __name__ == '__main__':all_data = []try:print("開始生成溫柔風格數據...")gentle_data = generate_style_data("溫柔", 10000)all_data.extend(gentle_data)print("開始生成毒舌風格數據...")sarcastic_data = generate_style_data("毒舌", 10000)all_data.extend(sarcastic_data)except KeyboardInterrupt:print("\n用戶中斷,保存已生成數據...")finally:with open("style_chat_data.json", "w", encoding="utf-8") as f:json.dump(all_data, f, ensure_ascii=False, indent=2)print(f"數據已保存,有效樣本數:{len(all_data)}")
上面的程序需要調用兩萬次大模型,賬戶里最好有20塊錢以上,并生成數據集需要10-12小時。對于“溫柔”風格而言,cleaned_output.txt 中的每個話題,會輸入到大模型十次,當然,并不是同一個話題連續問十次,而是一千個話題遍歷十次,總共問了一萬次。對于“毒舌”風格,也是一樣的操作。最后得到的有效數據可能沒有兩萬條,因為有些回答不符合要求被過濾掉。
輸出(只截取最后一部分):
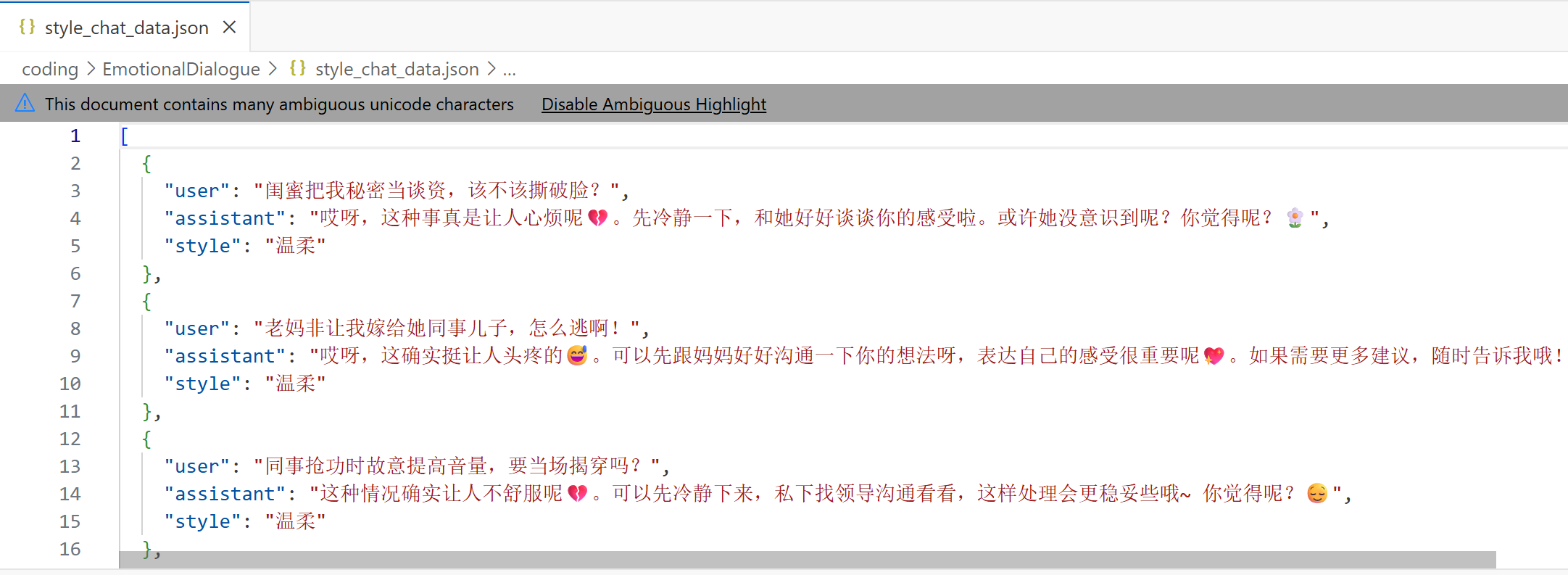
生成的數據集保存在 style_chat_data.json 中(截圖只截取開頭和結尾的一部分):
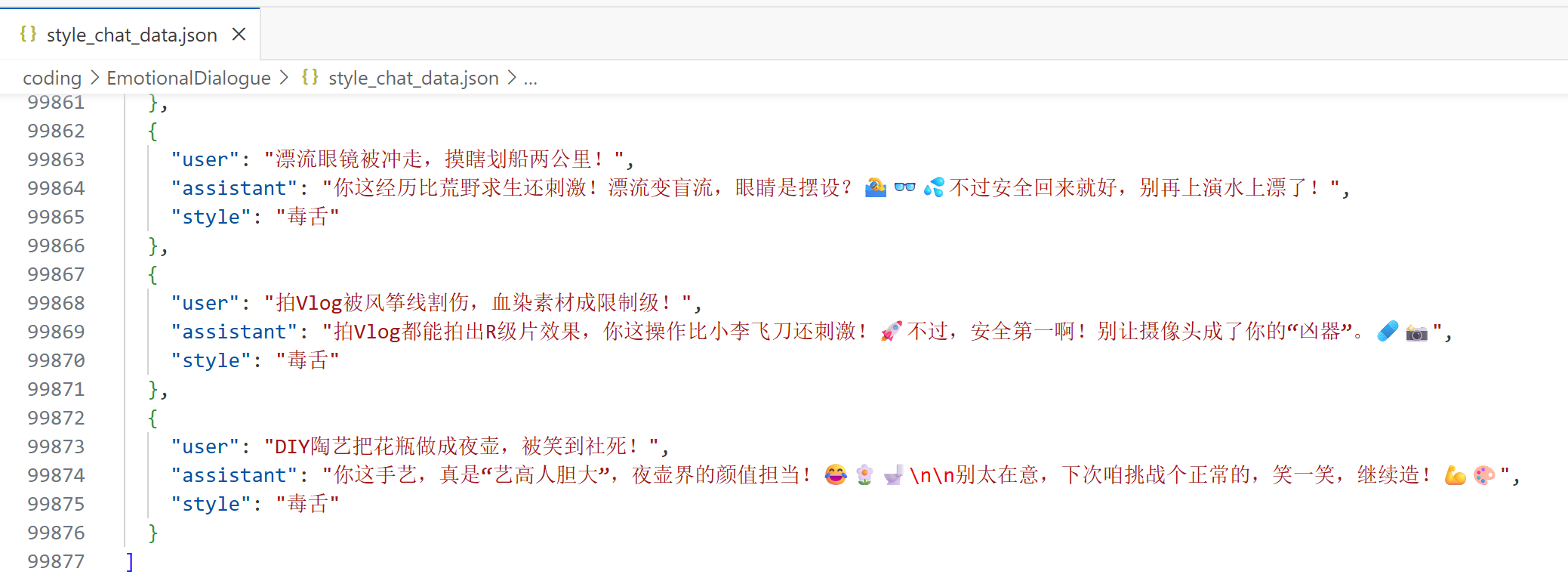
共計九萬多行。
2.4 數據轉換
本項目的微調框架,我們使用 Xtuner,之所以不用LLaMA-Factory,是因為本項目用的是主觀評估,Xtuner 在訓練過程中能看到主觀評價的結果。
接下來要把數據轉成 Xtuner 的自定義數據格式,轉的代碼可以讓AI幫忙寫:
3 模型選型
3.1 候選模型與評估數據集
確定好任務后,接下來該如何選擇適當的模型?我們這個是對話風格任務,不需要考慮邏輯性和推理能力,所以可以使用3B以下的模型。另外,由于我們是用中文進行聊天,而 Llama 這樣的模型,其訓練集大部分都是英文,中文只占一小部分,所以我們只考慮國內廠商的模型。
今天是2025年6月13日,我們只看最近一年發布,3B以下的開源模型,這些模型有:Qwen3-1.7B(2025年4月29日)、Qwen2.5-1.5B-Instruct(2024年9月19日)、InternLM2.5-1.8B-Chat(2024年7月4日),稍后我們會測評這三款模型。
我們需要對比這三個模型的語言理解與生成能力,由于當前任務大多是短語對話,因此測評數據集選用 FewCLUE_bustm_gen 和 FewCLUE_ocnli_fc_gen。FewCLUE_bustm_gen 用于二分類任務,即判斷兩個句子的語義是否相似,輸入是兩個句子,標簽是entailment(相似)或 not_entailment (不相似);FewCLUE_ocnli_fc_gen 用于判斷兩個句子的邏輯關系,輸入依然是兩個句子,標簽是它們的邏輯關系(entailment蘊含/neutral中性/contradiction矛盾)。
當然,還可以用其他數據集,這兩個數據集比較小,所以用它們,測評的時候速度比較快。本文的附錄中,介紹了對比不同模型的理解與生成能力時,推薦使用的數據集。
總的來說,選什么尺寸的模型,根據任務的復雜度來確定,測評用的數據,則根據與目標任務的相似程度確定。
3.2 模型評估
找到 Internlm 的配置文件,即 /data/coding/utils/opencompass/opencompass/configs/models/hf_internlm/lmdeploy_internlm2_5_1_8b_chat.py,按如下方式修改:
from opencompass.models import TurboMindModelwithChatTemplatemodels = [dict(type=TurboMindModelwithChatTemplate,abbr='internlm2_5-1_8b-chat-turbomind',# path='internlm/internlm2_5-1_8b-chat',path='/data/coding/EmotionalDialogue/model_weights/Shanghai_AI_Laboratory/internlm2_5-1_8b-chat',# engine_config=dict(session_len=16384, max_batch_size=16, tp=1),engine_config=dict(session_len=16384, max_batch_size=16, tp=1, cache_max_entry_count=0.4),gen_config=dict(top_k=1, temperature=1e-6, top_p=0.9, max_new_tokens=4096),max_seq_len=16384,max_out_len=4096,batch_size=16,run_cfg=dict(num_gpus=1),)
]找到Qwen2.5-1.5B-Instruct的配置文件,即 /data/coding/utils/opencompass/opencompass/configs/models/qwen2_5/lmdeploy_qwen2_5_1_5b_instruct.py,按如下方式修改:
from opencompass.models import TurboMindModelwithChatTemplatemodels = [dict(type=TurboMindModelwithChatTemplate,abbr='qwen2.5-1.5b-instruct-turbomind',path='/data/coding/model_weights/Qwen/Qwen2.5-1.5B-Instruct',# engine_config=dict(session_len=16384, max_batch_size=16, tp=1),engine_config=dict(session_len=16384, max_batch_size=16, tp=1, cache_max_entry_count=0.4),gen_config=dict(top_k=1, temperature=1e-6, top_p=0.9, max_new_tokens=4096),max_seq_len=16384,max_out_len=4096,batch_size=16,run_cfg=dict(num_gpus=1),)
]找到qwen3的配置文件,qwen3 只有0.6B的配置文件,雖然沒有1.7B的,但我們可以對0.6B的進行修改,即把 opencompass/opencompass/configs/models/qwen3/lmdeploy_qwen3_0_6b.py,按如下方式修改:
from opencompass.models import TurboMindModelwithChatTemplate
from opencompass.utils.text_postprocessors import extract_non_reasoning_contentmodels = [dict(type=TurboMindModelwithChatTemplate,# abbr='qwen_3_0.6b_thinking-turbomind',abbr='qwen_3_1.7b_thinking-turbomind',# path='Qwen/Qwen3-0.6B',path='/data/coding/EmotionalDialogue/model_weights/Qwen/Qwen3-1.7B',# engine_config=dict(session_len=32768, max_batch_size=16, tp=1),engine_config=dict(session_len=32768, max_batch_size=16, tp=1, cache_max_entry_count=0.4),gen_config=dict(top_k=20, temperature=0.6, top_p=0.95, do_sample=True, enable_thinking=True),max_seq_len=32768,max_out_len=32000,batch_size=16,run_cfg=dict(num_gpus=1),pred_postprocessor=dict(type=extract_non_reasoning_content)),
]
上面三個配置文件,在引擎配置的時候,我都加了一個 cache_max_entry_count=0.4,主要是為了防止 KV Cache 占用太大,導致顯存溢出。但是加了 cache_max_entry_count=0.4 之后,由于緩存占比太小,推理速度下降,評估時間變長。如果你的GPU顯存夠大,那就不需要加,我自己用 24G 顯存,不加的話仍然會報顯存不足,最后調整cache_max_entry_count=0.6,才順利完成評估。(qwen3評估太花時間了,其他兩個模型很快就完成了評估,偏偏qwen3花了將近一個小時,原因我暫時沒找到)
進入到opencompass項目目錄下,然后在終端輸入:
python run.py --models lmdeploy_internlm2_5_1_8b_chat lmdeploy_qwen2_5_1_5b_instruct lmdeploy_qwen3_0_6b --datasets FewCLUE_bustm_gen FewCLUE_ocnli_fc_gen --debug

可以看到,qwen_3_1.7b 是這里的最強模型,從它們的發布時間來看,如果模型的尺寸相差不大,則越往后發布的模型,能力越強。
附錄(對比不同模型理解與生成能力所用數據集)
要對比兩個模型對中文的理解能力(語義、邏輯、推理)和生成能力(流暢性、連貫性、信息量),建議采用多維度、多任務的數據集組合。以下是按任務類型分類的推薦數據集及使用策略:
一、理解能力評測數據集
1. 語義理解 & 文本匹配
- BUSTM
- 任務:判斷句子對是否語義相同(二分類)
- 例:
("今天天氣不錯", "今天天晴") → 相似 - 能力重點:近義詞、句式轉換識別能力
- AFQMC(螞蟻金融語義匹配)
- 任務:金融場景的句子對分類
- 例:
("如何還款", "怎樣還錢") → 相似 - 能力重點:領域適應性
2. 自然語言推理(NLI)
- OCNLI(原生中文推理)
- 任務:判斷前提與假設的邏輯關系(三分類)
- 例:
前提:"手機電量不足"→假設:"需要充電"→ 蘊含 - 能力重點:邏輯推理、常識理解
- CMNLI(中文多體裁NLI)
- 任務:多領域文本推理(新聞/文學等)
- 能力重點:跨領域泛化性
3. 閱讀理解
- CMRC 2018(中文機器閱讀理解)
- 任務:從文章中提取答案(片段抽取)
- 例:文章:“北京是中國的首都”,問題:“中國首都是?” → 答案:“北京”
- 能力重點:信息定位精度
- C3(Choice-Context-Challenge)
- 任務:多選問答(需結合上下文推理)
- 能力重點:多步推理、排除干擾項
二、生成能力評測數據集
1. 開放域生成
- LCSTS(中文摘要生成)
- 任務:生成新聞短摘要
- 輸入:長新聞文本 → 輸出:1-3句摘要
- 評測指標:ROUGE-L(自動) + 人工流暢性評分
- AdGen(廣告文案生成)
- 任務:根據商品屬性生成廣告文案
- 例:輸入:“口紅,色號#999,啞光質地” → 輸出:“經典正紅,高級霧面妝感”
- 評測指標:BLEU-4 + 信息完整性檢查
2. 結構化生成
- FewCLUE_bustm_gen/ocnli_fc_gen(前文提及)
- 任務:將分類任務重構為文本生成
- 例:輸入句子對 → 輸出標簽詞(如“蘊含”)
- 評測指標:準確率(生成內容與標簽的嚴格匹配)
3. 對話生成
- KdConv(知識驅動對話)
- 任務:基于知識圖譜生成連貫多輪對話
- 能力重點:上下文一致性、知識注入能力
- STC(短文本對話)
- 任務:生成單輪回復
- 例:輸入:“今天好熱啊” → 輸出:“來杯冰咖啡吧!”
- 評測指標:人工評分(相關性、新穎性)
三、高階能力評測數據集
1. 常識推理
- CKB(Commonsense Knowledge Base)
- 任務:問答需結合常識(如"下雨天出門要帶?" → “傘”)
- 能力重點:隱含知識調用能力
2. 數學推理
- Math23K
- 任務:解中文數學應用題
- 例:“小明有5個蘋果,吃了2個,還剩幾個?” → 生成:“3”
- 評測指標:答案精確匹配
3. 長文本生成
- CPED(中國古典詩歌生成)
- 任務:根據主題生成七言詩
- 能力重點:韻律控制、意象組織
四、評測策略建議
- 理解能力優先級任務:
- 先跑 OCNLI/CMNLI(推理)、CMRC 2018(閱讀理解)
- 模型需輸出結構化結果(標簽/答案),用準確率定量對比。
- 生成能力優先級任務:
- 重點測 LCSTS(摘要)、AdGen(文案)、KdConv(對話)
- 結合自動指標(ROUGE, BLEU) + 人工評測(隨機采樣100條,評估流暢性/邏輯性)。
- 小樣本場景測試:
- 使用 FewCLUE_bustm_gen(16個訓練樣本),觀察模型在低資源下的泛化能力。
- 易用性工具:
- 使用 Hugging Face Datasets 加載數據(示例代碼):
from datasets import load_dataset dataset = load_dataset("clue", "cmnli") # 加載CMNLI
- 使用 Hugging Face Datasets 加載數據(示例代碼):
五、注意事項
- 模型適配性:
- 若對比模型為純生成架構(如GPT-3),優先選生成式任務(LCSTS, AdGen);
- 若為理解-生成混合架構(如T5),可覆蓋所有任務。
- 公平性控制:
- 確保輸入長度、訓練輪次、提示詞(Prompt)設計完全一致。
- 中文特有難點:
- 在數據中加入測試中文特有表達的樣本,如:
- 成語理解("畫蛇添足"→生成解釋)
- 多音字歧義(“行(xíng)業” vs “行(háng)列”)
- 在數據中加入測試中文特有表達的樣本,如:
推薦基準組合:
理解能力:OCNLI + CMRC 2018 + CKB
生成能力:LCSTS + AdGen + KdConv
高階挑戰:Math23K + CPED
此組合覆蓋語義、推理、生成、常識、數學、文藝六大維度,可全面反映模型的中文能力邊界。



![[論文閱讀] 系統架構 | 零售 IT 中的微服務與實時處理:開源工具鏈與部署策略綜述](http://pic.xiahunao.cn/[論文閱讀] 系統架構 | 零售 IT 中的微服務與實時處理:開源工具鏈與部署策略綜述)
)




)









