【Kafka】消息隊列Kafka知識總結
- 【一】消息隊列
- 【1】什么是消息隊列
- 【2】消息隊列有什么用
- (1)異步處理
- (2)削峰/限流
- (3)降低系統耦合性
- (4)實現分布式事務
- (5)順序保證
- (6)延時/定時處理
- (7)即時通訊
- (8)數據流處理
- 【3】使用消息隊列會帶來哪些問題
- 【4】JMS和AMQP
- (1)JMS是什么
- (2)JMS兩種消息模型
- (3)AMQP是什么
- (4)JMS對比AMQP
- (5)總結
- 【5】RPC和消息隊列的區別
- 【6】消息隊列和線程池異步的區別
- 【二】分布式消息隊列選型
- 【三】Kafka基礎
- 【1】Kafka是什么?主要應用場景?
- 【2】優勢
- 【3】核心概念
- 【4】副本機制
- 【5】Zookeeper的作用
- 【四】Kafka問題解決
- 【1】保證消息的消費順序
- 【2】保證消息不丟失
- (1)生產者丟失消息
- (2)消費者丟失消息
- (3)Kafka丟失消息
- 1-設置 acks = all 副本全部收到消息再回調
- 2-設置 replication.factor >= 3 副本數
- 3-設置 min.insync.replicas > 1
- 4-設置 unclean.leader.election.enable = false
- 【3】保證消息不重復消費
- (1)關閉自動提交,開啟手動提交offset
- (2)消費者處理完消息后再手動提交
- (3)添加數據庫唯一約束實現冪等消費
- 【4】Kafka重試機制
- (1)消費失敗會怎么樣?
- (2)默認會重試多少次?
- (3)如何自定義重試次數以及時間間
- (4)如何在重試失敗后進行告警?
- (5)重試失敗后的數據如何再次處理?
- 【五】實現思路案例
- 【1】配置文件
- 【2】Broker 配置(確保消息持久化)
- 【3】生產者服務
- 【4】消費者服務
- 【5】訂單服務(冪等性)
- 【6】消費失敗監控與告警
- 【7】死信隊列服務
【一】消息隊列
【1】什么是消息隊列
我們可以把消息隊列看作是一個存放消息的容器,當我們需要使用消息的時候,直接從容器中取出消息供自己使用即可。由于隊列 Queue 是一種先進先出的數據結構,所以消費消息時也是按照順序來消費的。
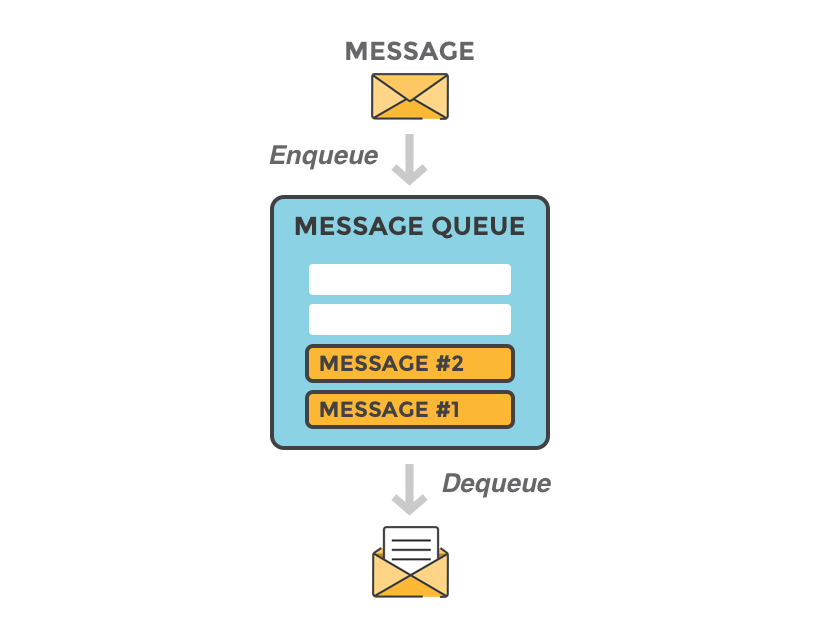
參與消息傳遞的雙方稱為 生產者 和 消費者 ,生產者負責發送消息,消費者負責處理消息。
【2】消息隊列有什么用
通常來說,使用消息隊列主要能為我們的系統帶來下面三點好處:
(1)異步處理
(2)削峰/限流
(3)降低系統耦合性
除了這三點之外,消息隊列還有其他的一些應用場景,例如實現分布式事務、順序保證和數據流處理。
(1)異步處理
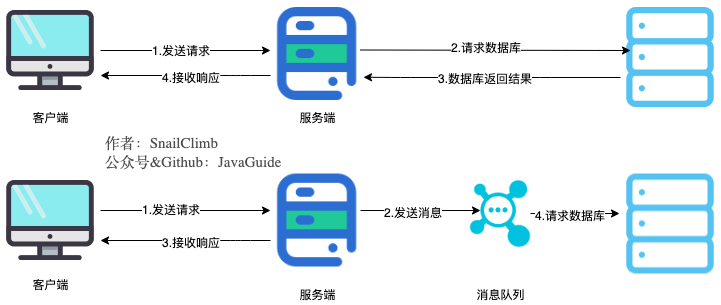
將用戶請求中包含的耗時操作,通過消息隊列實現異步處理,將對應的消息發送到消息隊列之后就立即返回結果,減少響應時間,提高用戶體驗。隨后,系統再對消息進行消費。
因為用戶請求數據寫入消息隊列之后就立即返回給用戶了,但是請求數據在后續的業務校驗、寫數據庫等操作中可能失敗。因此,使用消息隊列進行異步處理之后,需要適當修改業務流程進行配合,比如用戶在提交訂單之后,訂單數據寫入消息隊列,不能立即返回用戶訂單提交成功,需要在消息隊列的訂單消費者進程真正處理完該訂單之后,甚至出庫后,再通過電子郵件或短信通知用戶訂單成功,以免交易糾紛。這就類似我們平時手機訂火車票和電影票。
(2)削峰/限流
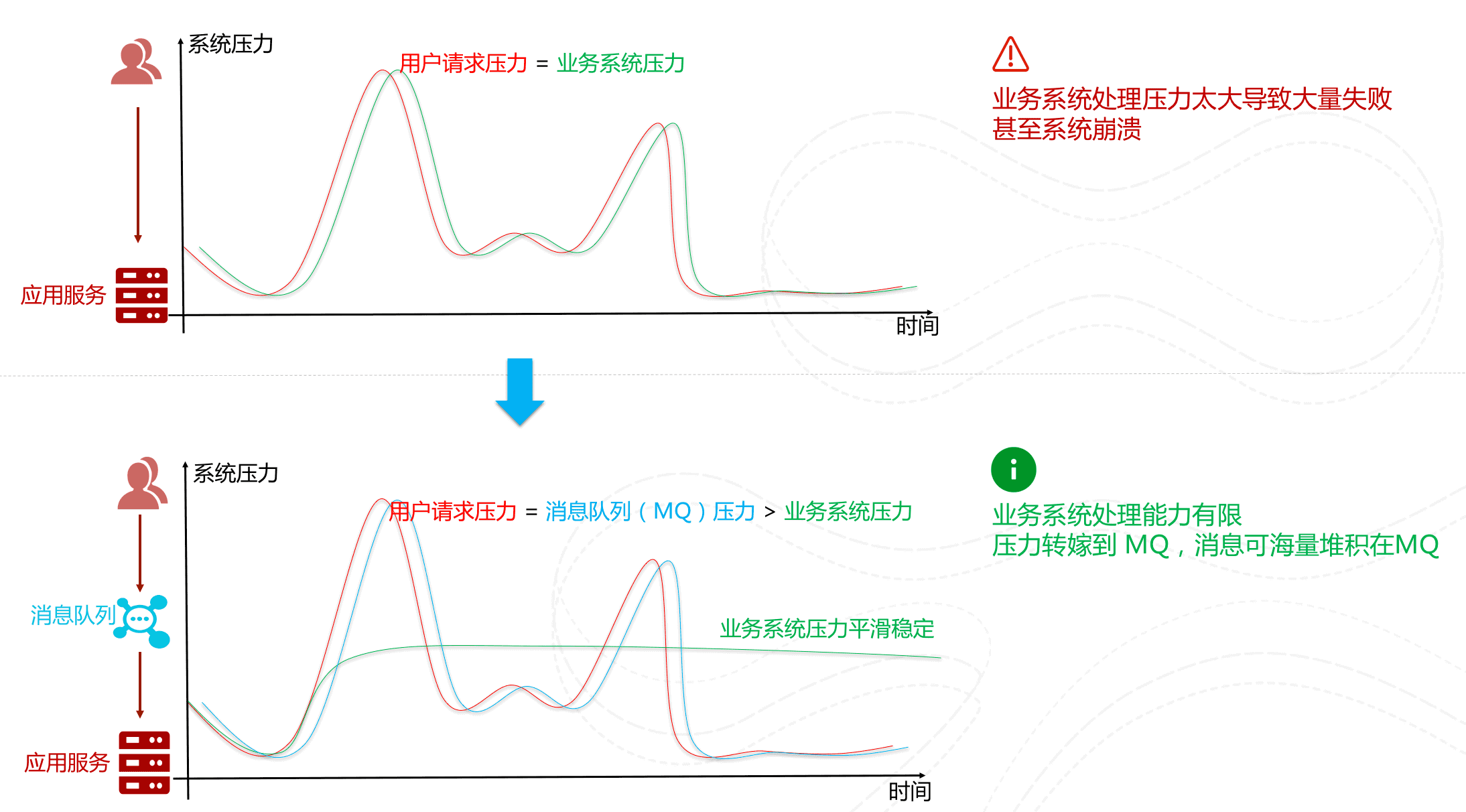
先將短時間高并發產生的事務消息存儲在消息隊列中,然后后端服務再慢慢根據自己的能力去消費這些消息,這樣就避免直接把后端服務打垮掉。
舉例:在電子商務一些秒殺、促銷活動中,合理使用消息隊列可以有效抵御促銷活動剛開始大量訂單涌入對系統的沖擊。如下圖所示:
(3)降低系統耦合性
使用消息隊列還可以降低系統耦合性。如果模塊之間不存在直接調用,那么新增模塊或者修改模塊就對其他模塊影響較小,這樣系統的可擴展性無疑更好一些。
生產者(客戶端)發送消息到消息隊列中去,消費者(服務端)處理消息,需要消費的系統直接去消息隊列取消息進行消費即可而不需要和其他系統有耦合,這顯然也提高了系統的擴展性。
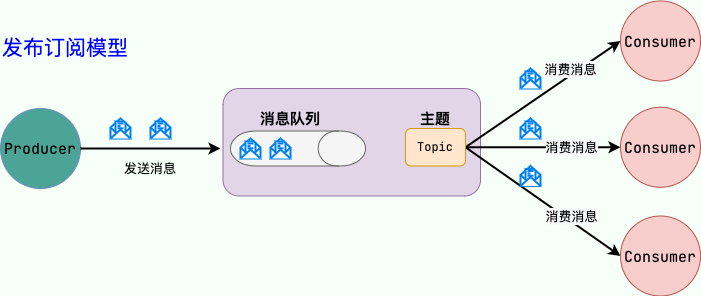
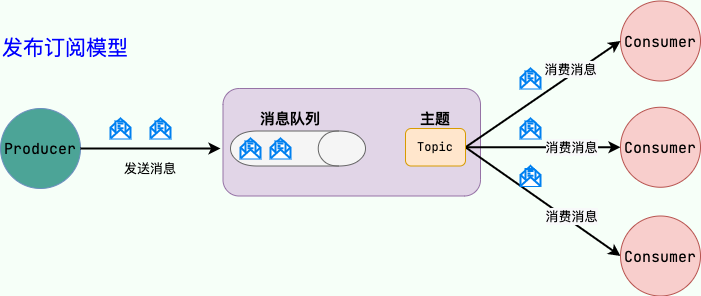
消息隊列使用發布-訂閱模式工作,消息發送者(生產者)發布消息,一個或多個消息接受者(消費者)訂閱消息。 從上圖可以看到消息發送者(生產者)和消息接受者(消費者)之間沒有直接耦合,消息發送者將消息發送至分布式消息隊列即結束對消息的處理,消息接受者從分布式消息隊列獲取該消息后進行后續處理,并不需要知道該消息從何而來。對新增業務,只要對該類消息感興趣,即可訂閱該消息,對原有系統和業務沒有任何影響,從而實現網站業務的可擴展性設計。
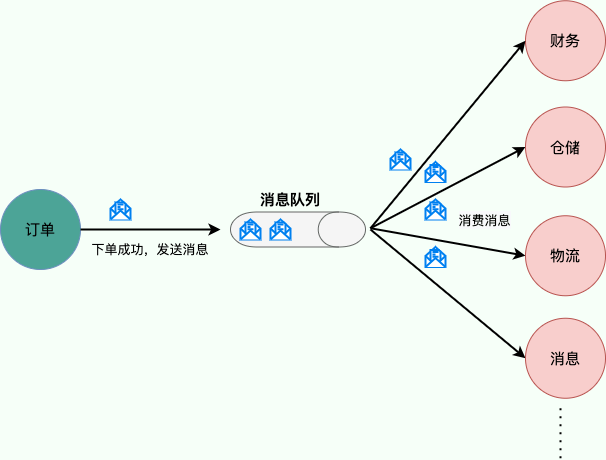
例如,我們商城系統分為用戶、訂單、財務、倉儲、消息通知、物流、風控等多個服務。用戶在完成下單后,需要調用財務(扣款)、倉儲(庫存管理)、物流(發貨)、消息通知(通知用戶發貨)、風控(風險評估)等服務。使用消息隊列后,下單操作和后續的扣款、發貨、通知等操作就解耦了,下單完成發送一個消息到消息隊列,需要用到的地方去訂閱這個消息進行消息即可。
另外,為了避免消息隊列服務器宕機造成消息丟失,會將成功發送到消息隊列的消息存儲在消息生產者服務器上,等消息真正被消費者服務器處理后才刪除消息。在消息隊列服務器宕機后,生產者服務器會選擇分布式消息隊列服務器集群中的其他服務器發布消息。
備注: 不要認為消息隊列只能利用發布-訂閱模式工作,只不過在解耦這個特定業務環境下是使用發布-訂閱模式的。除了發布-訂閱模式,還有點對點訂閱模式(一個消息只有一個消費者),我們比較常用的是發布-訂閱模式。另外,這兩種消息模型是 JMS 提供的,AMQP 協議還提供了另外 5 種消息模型。
(4)實現分布式事務
分布式事務的解決方案之一就是 MQ 事務。
RocketMQ、 Kafka、Pulsar、QMQ 都提供了事務相關的功能。事務允許事件流應用將消費,處理,生產消息整個過程定義為一個原子操作。
(5)順序保證
在很多應用場景中,處理數據的順序至關重要。消息隊列保證數據按照特定的順序被處理,適用于那些對數據順序有嚴格要求的場景。大部分消息隊列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持順序消息。
(6)延時/定時處理
消息發送后不會立即被消費,而是指定一個時間,到時間后再消費。大部分消息隊列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持定時/延時消息。
(7)即時通訊
MQTT(消息隊列遙測傳輸協議)是一種輕量級的通訊協議,采用發布/訂閱模式,非常適合于物聯網(IoT)等需要在低帶寬、高延遲或不可靠網絡環境下工作的應用。它支持即時消息傳遞,即使在網絡條件較差的情況下也能保持通信的穩定性。
RabbitMQ 內置了 MQTT 插件用于實現 MQTT 功能(默認不啟用,需要手動開啟)。
(8)數據流處理
針對分布式系統產生的海量數據流,如業務日志、監控數據、用戶行為等,消息隊列可以實時或批量收集這些數據,并將其導入到大數據處理引擎中,實現高效的數據流管理和處理。
【3】使用消息隊列會帶來哪些問題
(1)系統可用性降低: 系統可用性在某種程度上降低,為什么這樣說呢?在加入 MQ 之前,你不用考慮消息丟失或者說 MQ 掛掉等等的情況,但是,引入 MQ 之后你就需要去考慮了!
(2)系統復雜性提高: 加入 MQ 之后,你需要保證消息沒有被重復消費、處理消息丟失的情況、保證消息傳遞的順序性等等問題!
(3)一致性問題: 上面講了消息隊列可以實現異步,消息隊列帶來的異步確實可以提高系統響應速度。但是,萬一消息的真正消費者并沒有正確消費消息怎么辦?這樣就會導致數據不一致的情況了
【4】JMS和AMQP
(1)JMS是什么
JMS(JAVA Message Service,java 消息服務)是 Java 的消息服務,JMS 的客戶端之間可以通過 JMS 服務進行異步的消息傳輸。JMS(JAVA Message Service,Java 消息服務)API 是一個消息服務的標準或者說是規范,允許應用程序組件基于 JavaEE 平臺創建、發送、接收和讀取消息。它使分布式通信耦合度更低,消息服務更加可靠以及異步性。
JMS 定義了五種不同的消息正文格式以及調用的消息類型,允許你發送并接收以一些不同形式的數據:
(1)StreamMessage:Java 原始值的數據流
(2)MapMessage:一套名稱-值對
(3)TextMessage:一個字符串對象
(4)ObjectMessage:一個序列化的 Java 對象
(5)BytesMessage:一個字節的數據流
ActiveMQ(已被淘汰) 就是基于 JMS 規范實現的。
(2)JMS兩種消息模型
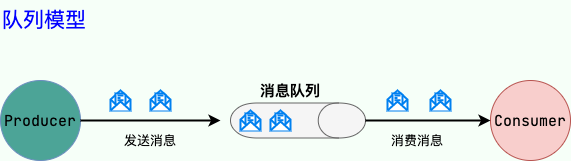
(1)點到點(P2P)模型
使用隊列(Queue)作為消息通信載體;滿足生產者與消費者模式,一條消息只能被一個消費者使用,未被消費的消息在隊列中保留直到被消費或超時。比如:我們生產者發送 100 條消息的話,兩個消費者來消費一般情況下兩個消費者會按照消息發送的順序各自消費一半(也就是你一個我一個的消費。)
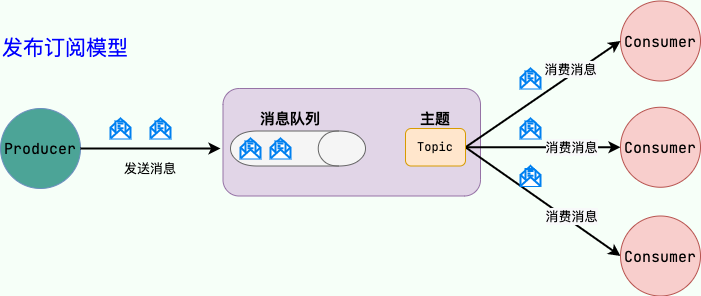
(2)發布/訂閱(Pub/Sub)模型
發布訂閱模型(Pub/Sub) 使用主題(Topic)作為消息通信載體,類似于廣播模式;發布者發布一條消息,該消息通過主題傳遞給所有的訂閱者。
(3)AMQP是什么
AMQP,即 Advanced Message Queuing Protocol,一個提供統一消息服務的應用層標準 高級消息隊列協議(二進制應用層協議),是應用層協議的一個開放標準,為面向消息的中間件設計,兼容 JMS。基于此協議的客戶端與消息中間件可傳遞消息,并不受客戶端/中間件同產品,不同的開發語言等條件的限制。
RabbitMQ 就是基于 AMQP 協議實現的
(4)JMS對比AMQP
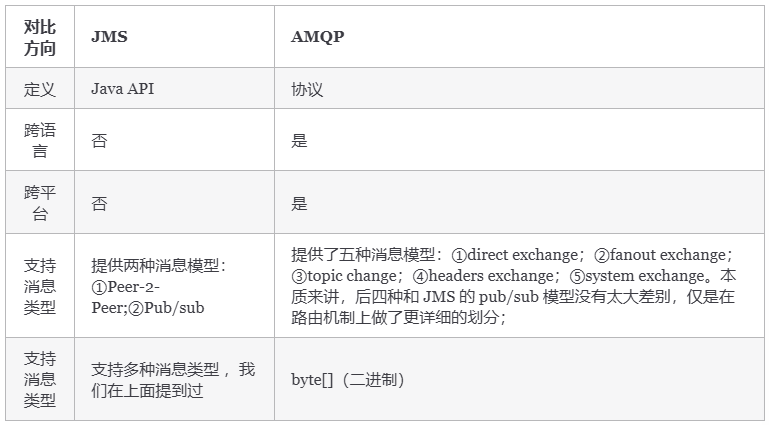
(5)總結
(1)AMQP 為消息定義了線路層(wire-level protocol)的協議,而 JMS 所定義的是 API 規范。在 Java 體系中,多個 client 均可以通過 JMS 進行交互,不需要應用修改代碼,但是其對跨平臺的支持較差。而 AMQP 天然具有跨平臺、跨語言特性。
(2)JMS 支持 TextMessage、MapMessage 等復雜的消息類型;而 AMQP 僅支持 byte[] 消息類型(復雜的類型可序列化后發送)。
(3)由于 Exchange 提供的路由算法,AMQP 可以提供多樣化的路由方式來傳遞消息到消息隊列,而 JMS 僅支持 隊列 和 主題/訂閱 方式兩種。
【5】RPC和消息隊列的區別
RPC 和消息隊列都是分布式微服務系統中重要的組件之一,簡單對比一下兩者:
(1)從用途來看
RPC 主要用來解決兩個服務的遠程通信問題,不需要了解底層網絡的通信機制。通過 RPC 可以幫助我們調用遠程計算機上某個服務的方法,這個過程就像調用本地方法一樣簡單。消息隊列主要用來降低系統耦合性、實現任務異步、有效地進行流量削峰。
(2)從通信方式來看
RPC 是雙向直接網絡通訊,消息隊列是單向引入中間載體的網絡通訊。
(3)從架構上來看
消息隊列需要把消息存儲起來,RPC 則沒有這個要求,因為前面也說了 RPC 是雙向直接網絡通訊。
(4)從請求處理的時效性來看
通過 RPC 發出的調用一般會立即被處理,存放在消息隊列中的消息并不一定會立即被處理。
RPC 和消息隊列本質上是網絡通訊的兩種不同的實現機制,兩者的用途不同
【6】消息隊列和線程池異步的區別
【二】分布式消息隊列選型
【三】Kafka基礎
【1】Kafka是什么?主要應用場景?
Kafka 是一個分布式流式處理平臺。
流平臺具有三個關鍵功能:
(1)消息隊列:發布和訂閱消息流,這個功能類似于消息隊列,這也是 Kafka 也被歸類為消息隊列的原因。
(2)容錯的持久方式存儲記錄消息流:Kafka 會把消息持久化到磁盤,有效避免了消息丟失的風險。
(3)流式處理平臺: 在消息發布的時候進行處理,Kafka 提供了一個完整的流式處理類庫。
Kafka 主要有兩大應用場景:
(1)消息隊列:建立實時流數據管道,以可靠地在系統或應用程序之間獲取數據。
(2)數據處理: 構建實時的流數據處理程序來轉換或處理數據流。
【2】優勢
(1)極致的性能:基于 Scala 和 Java 語言開發,設計中大量使用了批量處理和異步的思想,最高可以每秒處理千萬級別的消息。
(2)生態系統兼容性無可匹敵:Kafka 與周邊生態系統的兼容性是最好的沒有之一,尤其在大數據和流計算領域。
【3】核心概念
Kafka 將生產者發布的消息發送到 Topic(主題) 中,需要這些消息的消費者可以訂閱這些 Topic(主題),如下圖所示:
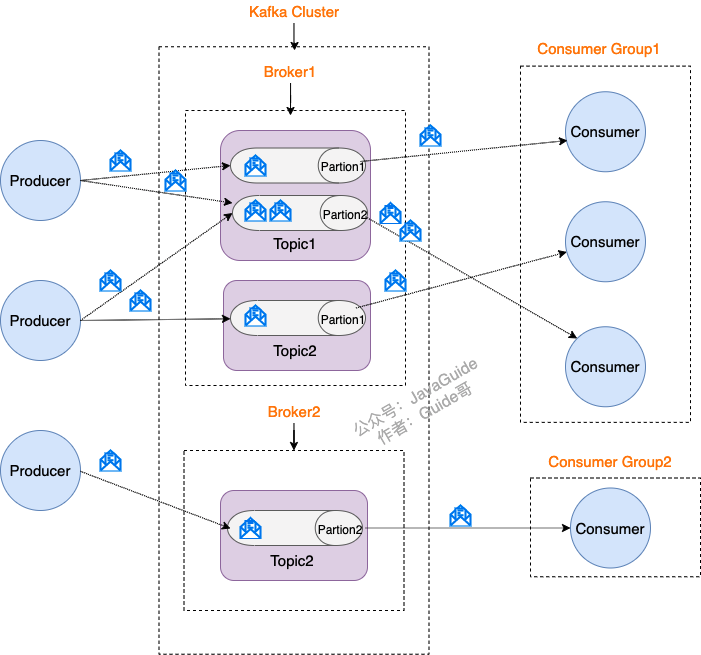
(1)Producer(生產者) : 產生消息的一方。
(2)Consumer(消費者) : 消費消息的一方。
(3)Broker(代理) : 可以看作是一個獨立的 Kafka 實例。多個 Kafka Broker 組成一個 Kafka Cluster。
(4)Topic(主題) : Producer 將消息發送到特定的主題,Consumer 通過訂閱特定的 Topic(主題) 來消費消息。
(5)Partition(分區) : Partition 屬于 Topic 的一部分。一個 Topic 可以有多個 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,這也就表明一個 Topic 可以橫跨多個 Broker 。這正如我上面所畫的圖一樣。Kafka 中的 Partition(分區) 實際上可以對應成為消息隊列中的隊列
【4】副本機制
Kafka 為分區(Partition)引入了多副本(Replica)機制。分區(Partition)中的多個副本之間會有一個叫做 leader 的家伙,其他副本稱為 follower。我們發送的消息會被發送到 leader 副本,然后 follower 副本才能從 leader 副本中拉取消息進行同步。
生產者和消費者只與 leader 副本交互。可以理解為其他副本只是 leader 副本的拷貝,它們的存在只是為了保證消息存儲的安全性。當 leader 副本發生故障時會從 follower 中選舉出一個 leader,但是 follower 中如果有和 leader 同步程度達不到要求的參加不了 leader 的競選。
多副本的好處:
(1)Kafka 通過給特定 Topic 指定多個 Partition, 而各個 Partition 可以分布在不同的 Broker 上, 這樣便能提供比較好的并發能力(負載均衡)。
(2)Partition 可以指定對應的 Replica 數, 這也極大地提高了消息存儲的安全性, 提高了容災能力,不過也相應的增加了所需要的存儲空間。
【5】Zookeeper的作用
下圖是本地 Zookeeper ,和本地的 Kafka 關聯上,ZooKeeper 主要為 Kafka 提供元數據的管理的功能。
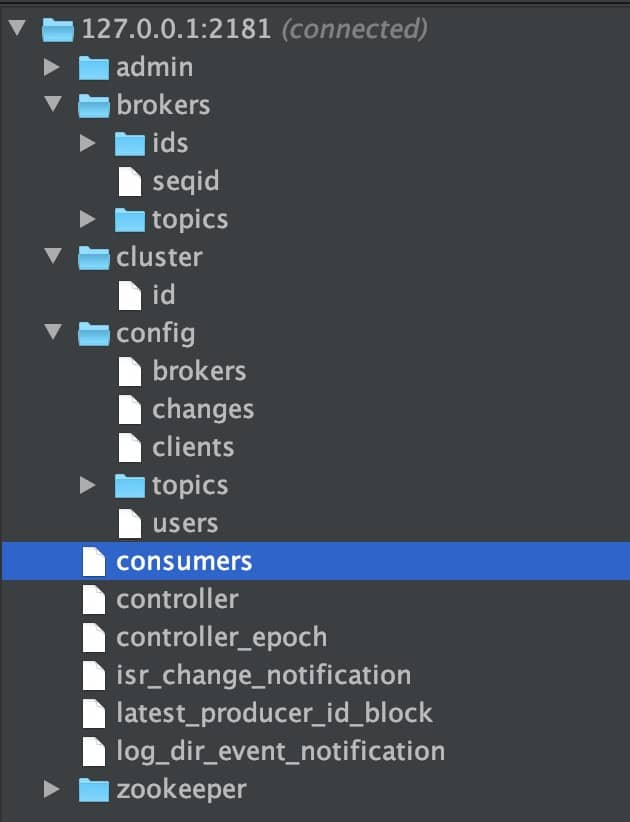
Zookeeper 主要為 Kafka 做了下面這些事情:
(1)Broker 注冊:在 Zookeeper 上會有一個專門用來進行 Broker 服務器列表記錄的節點。每個 Broker 在啟動時,都會到 Zookeeper 上進行注冊,即到 /brokers/ids 下創建屬于自己的節點。每個 Broker 就會將自己的 IP 地址和端口等信息記錄到該節點中去
(2)Topic 注冊:在 Kafka 中,同一個Topic 的消息會被分成多個分區并將其分布在多個 Broker 上,這些分區信息及與 Broker 的對應關系也都是由 Zookeeper 在維護。比如我創建了一個名字為 my-topic 的主題并且它有兩個分區,對應到 zookeeper 中會創建這些文件夾:/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1
(3)負載均衡:上面也說過了 Kafka 通過給特定 Topic 指定多個 Partition, 而各個 Partition 可以分布在不同的 Broker 上, 這樣便能提供比較好的并發能力。 對于同一個 Topic 的不同 Partition,Kafka 會盡力將這些 Partition 分布到不同的 Broker 服務器上。當生產者產生消息后也會盡量投遞到不同 Broker 的 Partition 里面。當 Consumer 消費的時候,Zookeeper 可以根據當前的 Partition 數量以及 Consumer 數量來實現動態負載均衡。
(4)……
在 Kafka 2.8 之前,Kafka 最被大家詬病的就是其重度依賴于 Zookeeper。在 Kafka 2.8 之后,引入了基于 Raft 協議的 KRaft 模式,不再依賴 Zookeeper,大大簡化了 Kafka 的架構,讓你可以以一種輕量級的方式來使用 Kafka。
【四】Kafka問題解決
【1】保證消息的消費順序
在使用消息隊列的過程中經常有業務場景需要嚴格保證消息的消費順序,比如我們同時發了 2 個消息,這 2 個消息對應的操作分別對應的數據庫操作是:
(1)更改用戶會員等級。
(2)根據會員等級計算訂單價格。
假如這兩條消息的消費順序不一樣造成的最終結果就會截然不同。
Kafka 中 Partition(分區)是真正保存消息的地方,我們發送的消息都被放在了這里。而我們的 Partition(分區) 又存在于 Topic(主題) 這個概念中,并且我們可以給特定 Topic 指定多個 Partition。
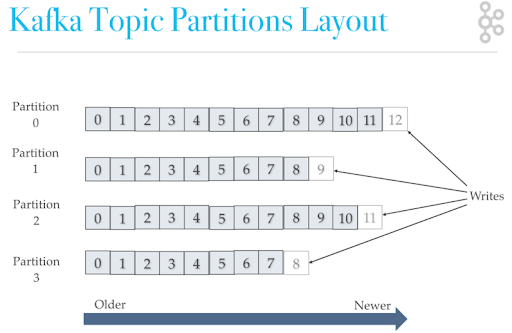
每次添加消息到 Partition(分區) 的時候都會采用尾加法,如上圖所示。 Kafka 只能為我們保證 Partition(分區) 中的消息有序。
消息在被追加到 Partition(分區)的時候都會分配一個特定的偏移量(offset)。Kafka 通過偏移量(offset)來保證消息在分區內的順序性。
所以,我們就有一種很簡單的保證消息消費順序的方法:1 個 Topic 只對應一個 Partition。這樣當然可以解決問題,但是破壞了 Kafka 的設計初衷。
Kafka 中發送 1 條消息的時候,可以指定 topic, partition, key,data(數據) 4 個參數。如果你發送消息的時候指定了 Partition 的話,所有消息都會被發送到指定的 Partition。并且,同一個 key 的消息可以保證只發送到同一個 partition,這個我們可以采用表/對象的 id 來作為 key 。
(1)1 個 Topic 只對應一個 Partition。
(2)(推薦)發送消息的時候指定 key/Partition。
【2】保證消息不丟失
(1)生產者丟失消息
生產者(Producer) 調用send方法發送消息之后,消息可能因為網絡問題并沒有發送過去。
所以,我們不能默認在調用send方法發送消息之后消息發送成功了。為了確定消息是發送成功,我們要判斷消息發送的結果。但是要注意的是 Kafka 生產者(Producer) 使用 send 方法發送消息實際上是異步的操作,我們可以通過 get()方法獲取調用結果,但是這樣也讓它變為了同步操作,示例代碼如下:
SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get();
if (sendResult.getRecordMetadata() != null) {logger.info("生產者成功發送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendResult.getProducerRecord().value().toString());
}
但是一般不推薦這么做!可以采用為其添加回調函數的形式,示例代碼如下:
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);future.addCallback(result -> logger.info("生產者成功發送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),ex -> logger.error("生產者發送消失敗,原因:{}", ex.getMessage()));
如果消息發送失敗的話,我們檢查失敗的原因之后重新發送即可!
另外,這里推薦為 Producer 的retries(重試次數)設置一個比較合理的值,一般是 3 ,但是為了保證消息不丟失的話一般會設置比較大一點。設置完成之后,當出現網絡問題之后能夠自動重試消息發送,避免消息丟失。另外,建議還要設置重試間隔,因為間隔太小的話重試的效果就不明顯了,網絡波動一次你 3 次一下子就重試完了。
(2)消費者丟失消息
消息在被追加到 Partition(分區)的時候都會分配一個特定的偏移量(offset)。偏移量(offset)表示 Consumer 當前消費到的 Partition(分區)的所在的位置。Kafka 通過偏移量(offset)可以保證消息在分區內的順序性。
當消費者拉取到了分區的某個消息之后,消費者會自動提交了 offset。自動提交的話會有一個問題,試想一下,當消費者剛拿到這個消息準備進行真正消費的時候,突然掛掉了,消息實際上并沒有被消費,但是 offset 卻被自動提交了。
解決辦法也比較粗暴,我們手動關閉自動提交 offset,每次在真正消費完消息之后再自己手動提交 offset 。 但是,這樣會帶來消息被重新消費的問題。比如你剛剛消費完消息之后,還沒提交 offset,結果自己掛掉了,那么這個消息理論上就會被消費兩次。
(3)Kafka丟失消息
Kafka 為分區(Partition)引入了多副本(Replica)機制。分區(Partition)中的多個副本之間會有一個叫做 leader 的家伙,其他副本稱為 follower。我們發送的消息會被發送到 leader 副本,然后 follower 副本才能從 leader 副本中拉取消息進行同步。生產者和消費者只與 leader 副本交互。你可以理解為其他副本只是 leader 副本的拷貝,它們的存在只是為了保證消息存儲的安全性。
試想一種情況:假如 leader 副本所在的 broker 突然掛掉,那么就要從 follower 副本重新選出一個 leader ,但是 leader 的數據還有一些沒有被 follower 副本的同步的話,就會造成消息丟失。
1-設置 acks = all 副本全部收到消息再回調
解決辦法就是我們設置 acks = all。acks 是 Kafka 生產者(Producer) 很重要的一個參數。
acks 的默認值即為 1,代表我們的消息被 leader 副本接收之后就算被成功發送。當我們配置 acks = all 表示只有所有 ISR 列表的副本全部收到消息時,生產者才會接收到來自服務器的響應. 這種模式是最高級別的,也是最安全的,可以確保不止一個 Broker 接收到了消息. 該模式的延遲會很高.
2-設置 replication.factor >= 3 副本數
為了保證 leader 副本能有 follower 副本能同步消息,我們一般會為 topic 設置 replication.factor >= 3。這樣就可以保證每個 分區(partition) 至少有 3 個副本。雖然造成了數據冗余,但是帶來了數據的安全性。
3-設置 min.insync.replicas > 1
一般情況下我們還需要設置 min.insync.replicas> 1 ,這樣配置代表消息至少要被寫入到 2 個副本才算是被成功發送。min.insync.replicas 的默認值為 1 ,在實際生產中應盡量避免默認值 1。
但是,為了保證整個 Kafka 服務的高可用性,你需要確保 replication.factor > min.insync.replicas 。為什么呢?設想一下假如兩者相等的話,只要是有一個副本掛掉,整個分區就無法正常工作了。這明顯違反高可用性!一般推薦設置成 replication.factor = min.insync.replicas + 1。
4-設置 unclean.leader.election.enable = false
我們發送的消息會被發送到 leader 副本,然后 follower 副本才能從 leader 副本中拉取消息進行同步。多個 follower 副本之間的消息同步情況不一樣,當我們配置了 unclean.leader.election.enable = false 的話,當 leader 副本發生故障時就不會從 follower 副本中和 leader 同步程度達不到要求的副本中選擇出 leader ,這樣降低了消息丟失的可能性。
【3】保證消息不重復消費
kafka 出現消息重復消費的原因:
(1)服務端側已經消費的數據沒有成功提交 offset(根本原因,消費者沒來得及提交offset就掛了)。
(2)Kafka 側 由于服務端處理業務時間長或者網絡鏈接等等原因讓 Kafka 認為服務假死,觸發了分區 rebalance。
解決方案:
(1)消費消息服務做冪等校驗,比如 Redis 的 set、MySQL 的主鍵等天然的冪等功能。這種方法最有效。
(2)將 enable.auto.commit 參數設置為 false,關閉自動提交,開發者在代碼中手動提交 offset。
那么這里會有個問題:什么時候提交 offset 合適?
1-處理完消息再提交:依舊有消息重復消費的風險,和自動提交一樣
2-拉取到消息即提交:會有消息丟失的風險。允許消息延時的場景,一般會采用這種方式。然后,通過定時任務在業務不繁忙(比如凌晨)的時候做數據兜底。
(1)關閉自動提交,開啟手動提交offset
spring:kafka:bootstrap-servers: localhost:9092consumer:enable-auto-commit: false # 關閉自動提交auto-offset-reset: latest # 可選:設置為latest避免啟動時重復消費max-poll-records: 50 # 每次拉取的最大記錄數max-poll-interval-ms: 300000 # 處理消息的最大間隔key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerlistener:ack-mode: manual # 配置手動提交
(2)消費者處理完消息后再手動提交
@Service
public class OrderConsumerService {@Autowiredprivate OrderService orderService;@KafkaListener(topics = "orders-topic", groupId = "order-consumer-group")public void listen(ConsumerRecord<String, String> record, Acknowledgment ack) {try {String orderJson = record.value();OrderDTO orderDTO = JSON.parseObject(orderJson, OrderDTO.class);// 1. 處理訂單(冪等性)orderService.processOrder(orderDTO);// 2. 手動提交offsetack.acknowledge();} catch (Exception e) {log.error("處理訂單消息失敗: {}", e.getMessage(), e);// 根據異常類型決定是否重試或跳過if (e instanceof RetryableException) {// 重試異常,不提交offsetthrow e;} else {// 非重試異常,記錄日志并提交offsetlog.error("非重試異常,跳過消息: {}", record.value());ack.acknowledge();}}}
}
(3)添加數據庫唯一約束實現冪等消費
消費消息的時候,根據數據庫的唯一鍵判斷消息是否已經消費過了,如果已消費就跳過
@Service
public class OrderService {@Autowiredprivate OrderRepository orderRepository;@Autowiredprivate MessageDeduplicationService deduplicationService;@Transactionalpublic void processOrder(OrderDTO orderDTO) {String messageId = orderDTO.getOrderId();// 1. 檢查消息是否已處理(Redis去重)if (!deduplicationService.isMessageProcessed(messageId)) {log.info("訂單已處理,跳過: {}", messageId);return;}// 2. 再次檢查數據庫中是否存在(雙重檢查)Optional<Order> existingOrder = orderRepository.findByOrderId(messageId);if (existingOrder.isPresent()) {log.info("訂單已存在,跳過: {}", messageId);return;}// 3. 處理新訂單Order order = new Order();order.setOrderId(messageId);order.setAmount(orderDTO.getAmount());order.setStatus("CREATED");// 4. 保存訂單orderRepository.save(order);// 5. 后續業務邏輯...processPayment(order);updateInventory(order);}// 其他方法...
}
使用redis校驗的邏輯
@Service
public class MessageDeduplicationService {@Autowiredprivate RedisTemplate<String, String> redisTemplate;private static final String DEDUPLICATION_KEY = "processed_messages:";private static final long EXPIRE_TIME = 24 * 60 * 60; // 24小時過期/*** 檢查消息是否已處理*/public boolean isMessageProcessed(String messageId) {String key = DEDUPLICATION_KEY + messageId;return Boolean.TRUE.equals(redisTemplate.opsForValue().setIfAbsent(key, "1", EXPIRE_TIME, TimeUnit.SECONDS));}
}
【4】Kafka重試機制
(1)消費失敗會怎么樣?
在消費過程中,當其中一個消息消費異常時,會不會卡住后續隊列消息的消費?這樣業務豈不是卡住了?
生產者代碼:
for (int i = 0; i < 10; i++) {kafkaTemplate.send(KafkaConst.TEST_TOPIC, String.valueOf(i))}
消費者消代碼:
@KafkaListener(topics = {KafkaConst.TEST_TOPIC},groupId = "apple")private void customer(String message) throws InterruptedException {log.info("kafka customer:{}",message);Integer n = Integer.parseInt(message);if (n%5==0){throw new RuntimeException();}}
在默認配置下,當消費異常會進行重試,重試多次后會跳過當前消息,繼續進行后續消息的消費,不會一直卡在當前消息。下面是一段消費的日志,可以看出當 test-0@95 重試多次后會被跳過。
2023-08-10 12:03:32.918 DEBUG 9700 --- [ntainer#0-0-C-1] o.s.kafka.listener.DefaultErrorHandler : Skipping seek of: test-0@95
2023-08-10 12:03:32.918 TRACE 9700 --- [ntainer#0-0-C-1] o.s.kafka.listener.DefaultErrorHandler : Seeking: test-0 to: 96
2023-08-10 12:03:32.918 INFO 9700 --- [ntainer#0-0-C-1] o.a.k.clients.consumer.KafkaConsumer : [Consumer clientId=consumer-apple-1, groupId=apple] Seeking to offset 96 for partition test-0
因此,即使某個消息消費異常,Kafka 消費者仍然能夠繼續消費后續的消息,不會一直卡在當前消息,保證了業務的正常進行。
(2)默認會重試多少次?
默認配置下,消費異常會進行重試,重試次數是多少, 重試是否有時間間隔?
看源碼 FailedRecordTracker 類有個 recovered 函數,返回 Boolean 值判斷是否要進行重試,下面是這個函數中判斷是否重試的邏輯:
@Overridepublic boolean recovered(ConsumerRecord << ? , ? > record, Exception exception,@Nullable MessageListenerContainer container,@Nullable Consumer << ? , ? > consumer) throws InterruptedException {if (this.noRetries) {// 不支持重試attemptRecovery(record, exception, null, consumer);return true;}// 取已經失敗的消費記錄集合Map < TopicPartition, FailedRecord > map = this.failures.get();if (map == null) {this.failures.set(new HashMap < > ());map = this.failures.get();}// 獲取消費記錄所在的Topic和PartitionTopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());FailedRecord failedRecord = getFailedRecordInstance(record, exception, map, topicPartition);// 通知注冊的重試監聽器,消息投遞失敗this.retryListeners.forEach(rl - >rl.failedDelivery(record, exception, failedRecord.getDeliveryAttempts().get()));// 獲取下一次重試的時間間隔long nextBackOff = failedRecord.getBackOffExecution().nextBackOff();if (nextBackOff != BackOffExecution.STOP) {this.backOffHandler.onNextBackOff(container, exception, nextBackOff);return false;} else {attemptRecovery(record, exception, topicPartition, consumer);map.remove(topicPartition);if (map.isEmpty()) {this.failures.remove();}return true;}}
其中, BackOffExecution.STOP 的值為 -1。
@FunctionalInterface
public interface BackOffExecution {long STOP = -1;long nextBackOff();}
nextBackOff 的值調用 BackOff 類的 nextBackOff() 函數。如果當前執行次數大于最大執行次數則返回 STOP,既超過這個最大執行次數后才會停止重試。
public long nextBackOff() {this.currentAttempts++;if (this.currentAttempts <= getMaxAttempts()) {return getInterval();}else {return STOP;}
}
那么這個 getMaxAttempts 的值又是多少呢?回到最開始,當執行出錯會進入 DefaultErrorHandler 。DefaultErrorHandler 默認的構造函數是:
public DefaultErrorHandler() {this(null, SeekUtils.DEFAULT_BACK_OFF);
}
SeekUtils.DEFAULT_BACK_OFF 定義的是:
public static final int DEFAULT_MAX_FAILURES = 10;public static final FixedBackOff DEFAULT_BACK_OFF = new FixedBackOff(0, DEFAULT_MAX_FAILURES - 1);
DEFAULT_MAX_FAILURES 的值是 10,currentAttempts 從 0 到 9,所以總共會執行 10 次,每次重試的時間間隔為 0。
最后,簡單總結一下:Kafka 消費者在默認配置下會進行最多 10 次 的重試,每次重試的時間間隔為 0,即立即進行重試。如果在 10 次重試后仍然無法成功消費消息,則不再進行重試,消息將被視為消費失敗。
(3)如何自定義重試次數以及時間間
從上面的代碼可以知道,默認錯誤處理器的重試次數以及時間間隔是由 FixedBackOff 控制的,FixedBackOff 是 DefaultErrorHandler 初始化時默認的。所以自定義重試次數以及時間間隔,只需要在 DefaultErrorHandler 初始化的時候傳入自定義的 FixedBackOff 即可。重新實現一個 KafkaListenerContainerFactory ,調用 setCommonErrorHandler 設置新的自定義的錯誤處理器就可以實現。
@Bean
public KafkaListenerContainerFactory kafkaListenerContainerFactory(ConsumerFactory<String, String> consumerFactory) {ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();// 自定義重試時間間隔以及次數FixedBackOff fixedBackOff = new FixedBackOff(1000, 5);factory.setCommonErrorHandler(new DefaultErrorHandler(fixedBackOff));factory.setConsumerFactory(consumerFactory);return factory;
}
(4)如何在重試失敗后進行告警?
自定義重試失敗后邏輯,需要手動實現,以下是一個簡單的例子,重寫 DefaultErrorHandler 的 handleRemaining 函數,加上自定義的告警等操作。
@Slf4j
public class DelErrorHandler extends DefaultErrorHandler {public DelErrorHandler(FixedBackOff backOff) {super(null,backOff);}@Overridepublic void handleRemaining(Exception thrownException, List<ConsumerRecord<?, ?>> records, Consumer<?, ?> consumer, MessageListenerContainer container) {super.handleRemaining(thrownException, records, consumer, container);log.info("重試多次失敗");// 自定義操作}
}
DefaultErrorHandler 只是默認的一個錯誤處理器,Spring Kafka 還提供了 CommonErrorHandler 接口。手動實現 CommonErrorHandler 就可以實現更多的自定義操作,有很高的靈活性。例如根據不同的錯誤類型,實現不同的重試邏輯以及業務邏輯等
(5)重試失敗后的數據如何再次處理?
當達到最大重試次數后,數據會直接被跳過,繼續向后進行。當代碼修復后,如何重新消費這些重試失敗的數據呢?
死信隊列(Dead Letter Queue,簡稱 DLQ) 是消息中間件中的一種特殊隊列。它主要用于處理無法被消費者正確處理的消息,通常是因為消息格式錯誤、處理失敗、消費超時等情況導致的消息被"丟棄"或"死亡"的情況。當消息進入隊列后,消費者會嘗試處理它。如果處理失敗,或者超過一定的重試次數仍無法被成功處理,消息可以發送到死信隊列中,而不是被永久性地丟棄。在死信隊列中,可以進一步分析、處理這些無法正常消費的消息,以便定位問題、修復錯誤,并采取適當的措施。
@RetryableTopic 是 Spring Kafka 中的一個注解,它用于配置某個 Topic 支持消息重試,更推薦使用這個注解來完成重試。
// 重試 5 次,重試間隔 100 毫秒,最大間隔 1 秒
@RetryableTopic(attempts = "5",backoff = @Backoff(delay = 100, maxDelay = 1000)
)
@KafkaListener(topics = {KafkaConst.TEST_TOPIC}, groupId = "apple")
private void customer(String message) {log.info("kafka customer:{}", message);Integer n = Integer.parseInt(message);if (n % 5 == 0) {throw new RuntimeException();}System.out.println(n);
}
當達到最大重試次數后,如果仍然無法成功處理消息,消息會被發送到對應的死信隊列中。對于死信隊列的處理,既可以用 @DltHandler 處理,也可以使用 @KafkaListener 重新消費。
【五】實現思路案例
【1】配置文件
spring:kafka:bootstrap-servers: localhost:9092# 生產者配置producer:acks: all # 所有副本都確認才返回成功retries: 3 # 重試次數retry-backoff-ms: 100 # 重試間隔buffer-memory: 33554432 # 緩沖區大小max-in-flight-requests-per-connection: 1 # 限制每個連接的未確認請求數enable-idempotence: true # 啟用冪等性key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer# 消費者配置consumer:group-id: order-consumer-groupenable-auto-commit: false # 關閉自動提交auto-offset-reset: earliest # 從最早的消息開始消費max-poll-records: 50 # 每次拉取的最大記錄數max-poll-interval-ms: 300000 # 處理消息的最大間隔key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerproperties:spring.kafka.listener.error-handler: customErrorHandler # 配置死信隊列處理器# 監聽器配置listener:ack-mode: manualconcurrency: 3missing-topics-fatal: false
【2】Broker 配置(確保消息持久化)
# server.properties
min.insync.replicas=2 # 至少2個副本同步
default.replication.factor=3 # 默認3個副本
unclean.leader.election.enable=false # 禁止非ISR節點成為leader
log.flush.interval.messages=1 # 每寫入一條消息就刷新到磁盤
【3】生產者服務
@Service
public class KafkaProducerService {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendOrder(OrderDTO orderDTO) {String topic = "orders-topic";String key = orderDTO.getOrderId();String value = JSON.toJSONString(orderDTO);// 發送消息并添加回調ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, key, value);future.addCallback(result -> log.info("訂單消息發送成功: orderId={}, partition={}, offset={}",orderDTO.getOrderId(), result.getRecordMetadata().partition(),result.getRecordMetadata().offset()),ex -> log.error("訂單消息發送失敗: orderId={}", orderDTO.getOrderId(), ex));}
}
【4】消費者服務
@Service
public class OrderConsumerService {@Autowiredprivate OrderService orderService;@Autowiredprivate MessageDeduplicationService deduplicationService;@KafkaListener(topics = "orders-topic", groupId = "order-consumer-group",containerFactory = "kafkaListenerContainerFactory")public void listen(ConsumerRecord<String, String> record, Acknowledgment ack) {try {String orderJson = record.value();OrderDTO orderDTO = JSON.parseObject(orderJson, OrderDTO.class);// 檢查消息是否已處理if (!deduplicationService.isMessageProcessed(orderDTO.getOrderId())) {log.info("訂單已處理,跳過: {}", orderDTO.getOrderId());ack.acknowledge();return;}// 處理訂單orderService.processOrder(orderDTO);// 手動提交offsetack.acknowledge();} catch (Exception e) {log.error("處理訂單消息失敗: {}", e.getMessage(), e);// 根據異常類型決定是否重試或跳過if (e instanceof RetryableException) {// 重試異常,不提交offsetthrow e;} else {// 非重試異常,記錄日志并提交offsetlog.error("非重試異常,跳過消息: {}", record.value());ack.acknowledge();}}}
}
【5】訂單服務(冪等性)
雙重校驗,首先redis去重,然后mysql查詢校驗
@Service
public class MessageDeduplicationService {@Autowiredprivate RedisTemplate<String, String> redisTemplate;private static final String DEDUPLICATION_KEY = "processed_messages:";private static final long EXPIRE_TIME = 24 * 60 * 60; // 24小時過期/*** 檢查消息是否已處理*/public boolean isMessageProcessed(String messageId) {String key = DEDUPLICATION_KEY + messageId;return Boolean.TRUE.equals(redisTemplate.opsForValue().setIfAbsent(key, "1", EXPIRE_TIME, TimeUnit.SECONDS));}
}
@Service
public class OrderService {@Autowiredprivate OrderRepository orderRepository;@Transactionalpublic void processOrder(OrderDTO orderDTO) {// 檢查訂單是否已存在Optional<Order> existingOrder = orderRepository.findByOrderId(orderDTO.getOrderId());if (existingOrder.isPresent()) {log.info("訂單已處理,跳過: {}", orderDTO.getOrderId());return;}// 處理新訂單Order order = new Order();order.setOrderId(orderDTO.getOrderId());order.setAmount(orderDTO.getAmount());order.setStatus("CREATED");order.setCreateTime(new Date());// 保存訂單orderRepository.save(order);// 后續業務邏輯...processPayment(order);updateInventory(order);}private void processPayment(Order order) {// 支付處理邏輯log.info("處理訂單支付: {}", order.getOrderId());}private void updateInventory(Order order) {// 更新庫存邏輯log.info("更新庫存: {}", order.getOrderId());}
}
【6】消費失敗監控與告警
全局異常處理器
@Configuration
public class KafkaErrorHandlerConfig {@Beanpublic KafkaListenerErrorHandler errorHandler() {return new SeekToCurrentErrorHandler(new FixedBackOff(1000, 3) // 重試3次,間隔1秒);}@Beanpublic ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory(ConsumerFactory<String, String> consumerFactory,KafkaListenerErrorHandler errorHandler) {ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(consumerFactory);// 配置錯誤處理器factory.setErrorHandler(errorHandler);return factory;}
}
自定義錯誤處理器
@Component
public class CustomErrorHandler implements ConsumerAwareListenerErrorHandler {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@Autowiredprivate DeadLetterQueueService deadLetterQueueService;@Overridepublic Object handleError(Message<?> message, ListenerExecutionFailedException exception, Consumer<?, ?> consumer) {log.error("消費消息失敗: {}", message.getPayload(), exception);// 獲取原始消息ConsumerRecord<?, ?> record = (ConsumerRecord<?, ?>) message.getHeaders().get(KafkaHeaders.RECEIVED_RECORD);// 記錄失敗消息到數據庫saveFailedMessage(record, exception);// 發送告警sendAlert(record, exception);// 發送到死信隊列deadLetterQueueService.sendToDlq(record, exception);// 返回null表示處理完成,不需要重試return null;}private void saveFailedMessage(ConsumerRecord<?, ?> record, Exception exception) {FailedMessage failedMessage = new FailedMessage();failedMessage.setTopic(record.topic());failedMessage.setPartition(record.partition());failedMessage.setOffset(record.offset());failedMessage.setKey(record.key() != null ? record.key().toString() : null);failedMessage.setValue(record.value().toString());failedMessage.setException(exception.getMessage());failedMessage.setStackTrace(ExceptionUtils.getStackTrace(exception));failedMessage.setFailedTime(new Date());// 保存到數據庫// failedMessageRepository.save(failedMessage);}private void sendAlert(ConsumerRecord<?, ?> record, Exception exception) {String alertMessage = "Kafka消費失敗: " +"Topic=" + record.topic() +", Partition=" + record.partition() +", Offset=" + record.offset() +", Exception=" + exception.getMessage();// 發送告警(郵件、短信、釘釘等)log.error(alertMessage);}
}
【7】死信隊列服務
@Service
public class DeadLetterQueueService {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@Autowiredprivate FailedMessageRepository failedMessageRepository;/*** 發送消息到死信隊列*/public void sendToDlq(ConsumerRecord<?, ?> record, Exception exception) {String dlqTopic = record.topic() + ".DLQ";// 創建死信消息Map<String, Object> headers = new HashMap<>();headers.put("original_topic", record.topic());headers.put("original_partition", record.partition());headers.put("original_offset", record.offset());headers.put("exception_message", exception.getMessage());headers.put("exception_stacktrace", ExceptionUtils.getStackTrace(exception));// 構建消息Message<String> message = MessageBuilder.withPayload(record.value().toString()).setHeaders(new MessageHeaders(headers)).build();// 發送到死信隊列kafkaTemplate.send(dlqTopic, record.key().toString(), record.value().toString());// 記錄到數據庫saveFailedMessage(record, exception);}/*** 從死信隊列重試消費*/@KafkaListener(topics = "orders.DLQ", groupId = "dlq-retry-group")public void retryFromDlq(ConsumerRecord<String, String> record) {try {// 解析消息OrderDTO orderDTO = JSON.parseObject(record.value(), OrderDTO.class);// 嘗試重新處理orderService.processOrder(orderDTO);// 處理成功,記錄日志log.info("從死信隊列重試成功: {}", orderDTO.getOrderId());// 更新數據庫狀態updateRetryStatus(record, true);} catch (Exception e) {log.error("從死信隊列重試失敗: {}", record.value(), e);// 更新數據庫狀態updateRetryStatus(record, false);// 可以考慮發送到重試隊列或歸檔隊列sendToRetryQueue(record, e);}}// 其他方法...
}





)

)










)
