25年3月來自香港中文大學的論文“TASTE-Rob: Advancing Video Generation of Task-Oriented Hand-Object Interaction for Generalizable Robotic Manipulation”。
本文也是在解決現有數據集和模型在面向任務的手部-目標交互視頻生成方面的關鍵限制,這是為機器人模仿學習生成視頻演示的關鍵方法。當前的數據集,例如 Ego4D [16],經常受到視角不一致和交互錯位的影響,導致視頻質量下降并限制了它們在精確模仿學習任務中的適用性。為此,推出 TASTE-Rob——一個開創性的大規模數據集,包含 100,856 個以自我為中心的手部-目標交互視頻。每個視頻都與語言指令精心對齊,并從一致的攝像機視角錄制,以確保交互清晰度。通過微調 TASTE-Rob 上的視頻擴散模型 (VDM),實現逼真的目標交互,盡管手部抓握姿勢偶爾存在不一致的情況。為了增強真實感,引入一個三階段姿勢細化流程,可提高生成視頻中手勢的準確性。所挑選的數據集,加上專門的姿勢細化框架,在生成高質量、面向任務的手部物體交互視頻方面提供顯著的性能提升,從而實現卓越的可通用機器人操作。
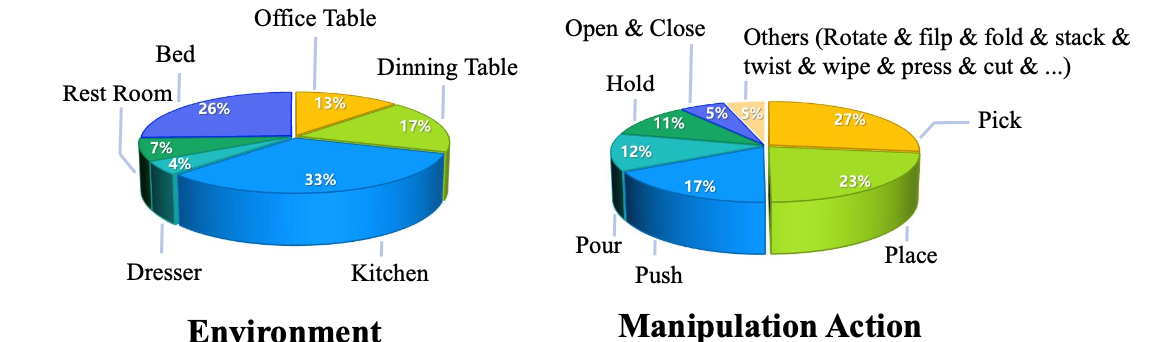
其收集一個海量且多樣化的以自我為中心、面向任務的手-目標交互(HOI)視頻數據集 TASTE-Rob,其中包含 100,856 對視頻及其對應的語言任務指令。為了服務于 HOI 視頻生成,TASTE-Rob 需要實現以下目標:1)每段視頻均采用靜態攝像機視角錄制,并包含與任務指令緊密契合的單一動作。2)涵蓋多樣化的環境和任務。3)展現不同 HOI 場景中的各種手勢。
數據收集策略與攝像機設置
為了實現第一個目標,用多個配備廣角鏡頭的攝像機,能夠拍攝 1080p 的以自我為中心的視頻。在每次錄制過程中,進行以下改進。
首先,由于數據收集旨在為 IL 中演示生成面向任務的 HOI 視頻,而為了實現有效的機器人模仿學習,演示通常從固定的攝像機視點錄制,因此確保在錄制過程中不會發生攝像機視角的變化。此外,如圖所示,專門調整攝像機視角以匹配 Ego4D [16] 的頭戴式攝像機設置,確保與自我中心視角保持一致。
第二個目標是確保 TASTE-Rob 中的語言任務指令和視頻動作之間精確對齊,這是保持生成的 HOI 視頻中動作完整性的關鍵方面。與 Ego4D [16] 通過頭戴式攝像機捕獲日常活動的擴展記錄并分割成更短的片段不同,本文采用了更受控制的收集協議:1) 每個視頻的時長嚴格限制在 8 秒以內,并捕獲單個動作。 2)采集器遵循結構化的記錄流程:按下“開始記錄”按鈕,根據提供的指令執行指定的HOI任務,并在任務完成后停止記錄。這種方法確保了操作和任務指令之間的精確對應。
數據多樣性
環境和任務的分布。為了實現廣泛的泛化,TASTE-Rob 中的視頻錄制于不同的環境中,涵蓋廣泛的 HOI 任務。如圖所示,環境包括廚房、臥室、餐桌、辦公桌等地點。收集者需要與各種常用物品進行交互,并執行拾取、放置、推動、傾倒等任務。為了進一步確保任務的多樣性,考慮不同的手部使用模式。具體來說,TASTE-Rob 包含 75,389 個單手任務視頻和 25,467 個雙手任務視頻。
抓握手的分布。為了確保手勢的多樣性,考慮兩個主要因素:不同的手掌方向(整體姿勢)和不同的抓握姿勢(細節姿勢)。為了展示手勢的多樣性,利用 HaMeR [34] 提取手勢參數并分析基于這些參數的分布。
如表所示,分析 TASTE-Rob 中 HOI 交互過程中手掌方向的分布。分析揭示了以下幾點:1)手掌朝下(0° -180°)的手勢最為常見,因為這種方向適合抓握物體。2)手掌朝左(90° -270°)的手勢比朝右的手勢略多,這可能是因為所有收藏家都是右撇子,自然更喜歡用右手來操作物體。

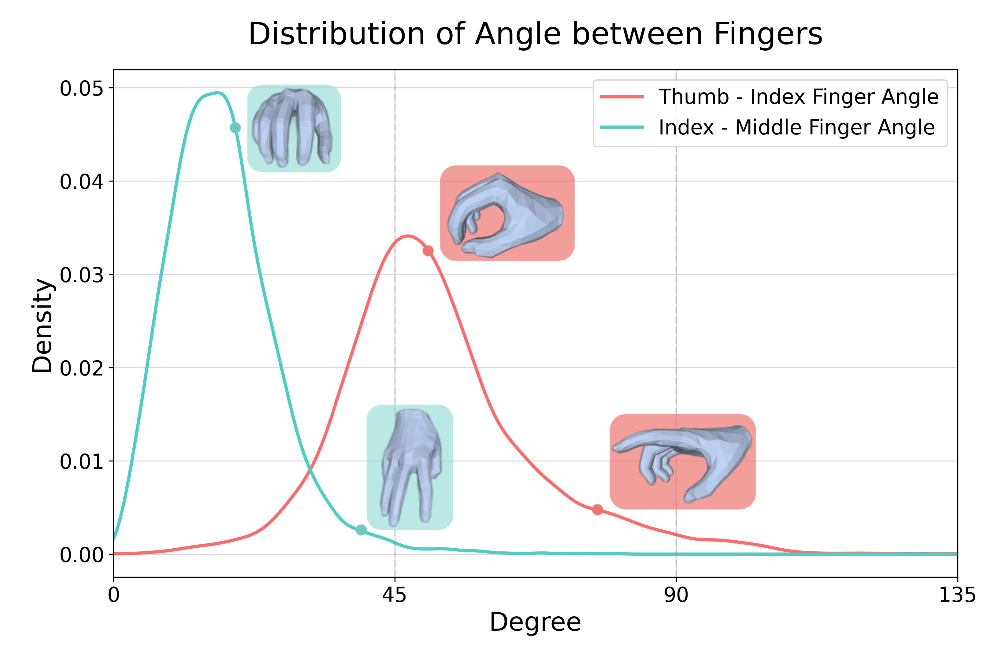
如下兩個圖中提供手部抓握姿勢分布的分析。鑒于拇指、食指和中指在 HOI 中起主導作用,重點研究了這些手指之間的夾角及其各自的曲率分布。
如圖中的分析顯示夾角的廣泛分布,表明手部方向各異。
如下圖揭示了兩個關鍵發現:1)食指和中指的曲率分布呈現出相似的模式,反映了它們在 HOI 動作期間的同步彎曲。2)數據集捕捉了各種各樣的抓握姿勢,這些姿勢是由各種被操縱的物體驅動的。

如表所示,對 TASTE-Rob 與現有的以自我為中心的 HOI 視頻數據集進行比較。
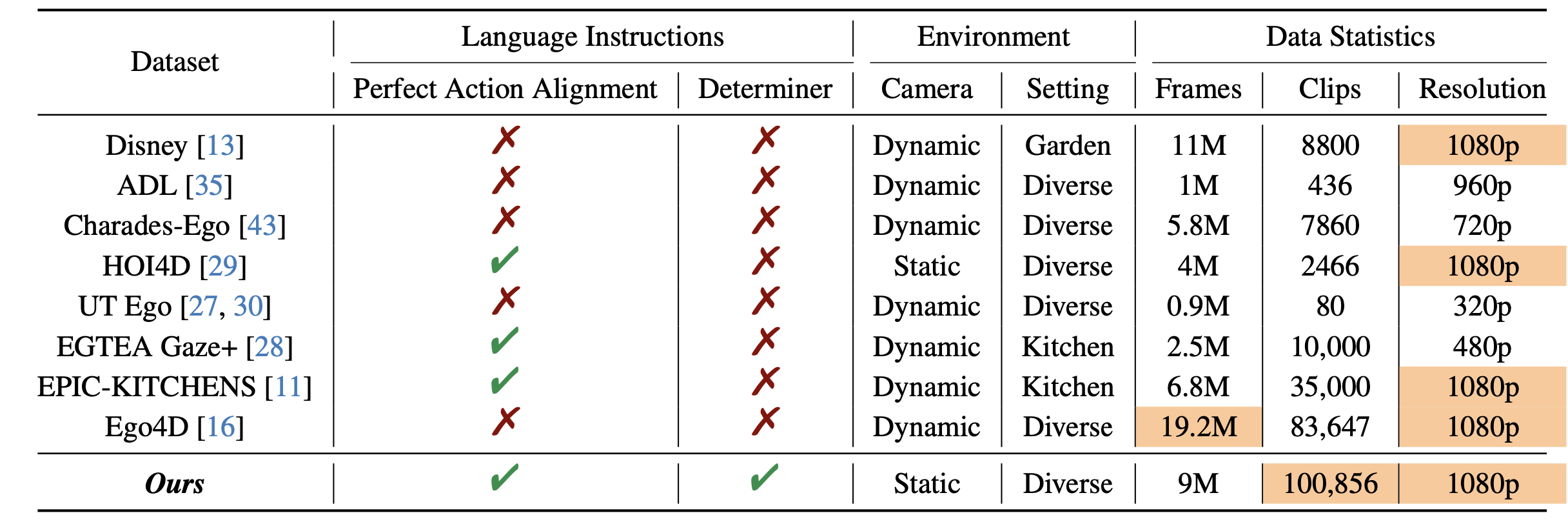
TASTE-Rob 是一個專門為面向任務 HOI 視頻生成設計的視頻數據集,它也可以作為 IL 演示的寶貴資源。鑒于IL視頻演示是從固定攝像機視角錄制的,并且僅包含與任務指令一致的單個動作,在相同設置下收集HOI視頻,這使得TASTE-Rob與其他數據集有所區別。此外,為了提高對目標物體的理解,在語言任務指令中加入多種物體限定詞。借助TASTE-Rob,能夠生成高質量的HOI視頻演示,從而實現IL。
給定一個環境圖像和一段任務描述,生成的面向任務的 HOI 視頻需要滿足:1)準確的任務理解:正確識別要操作的目標以及如何操作它。2)可行的 HOI:在整個操作過程中保持一致的手部抓握姿勢。
如圖中第一階段區域所示,雖然由單個 VDM (v?_c) 生成的視頻展現準確的任務理解,但在保持一致的抓握姿勢方面表現出有限的保真度。為了滿足這兩個要求,提出一個三階段姿勢細化流程,如圖所示:第一階段:采用可學習的圖像-到-視頻 (I2V) 擴散模型生成滿足“準確任務理解”要求的粗略 HOI 視頻。第二階段:從該粗略視頻中提取手勢序列,并使用可學習的運動擴散模型 (MDM) 對其進行細化 [45]。第三階段:使用細化的手勢序列生成滿足兩個要求的高保真 HOI 視頻。
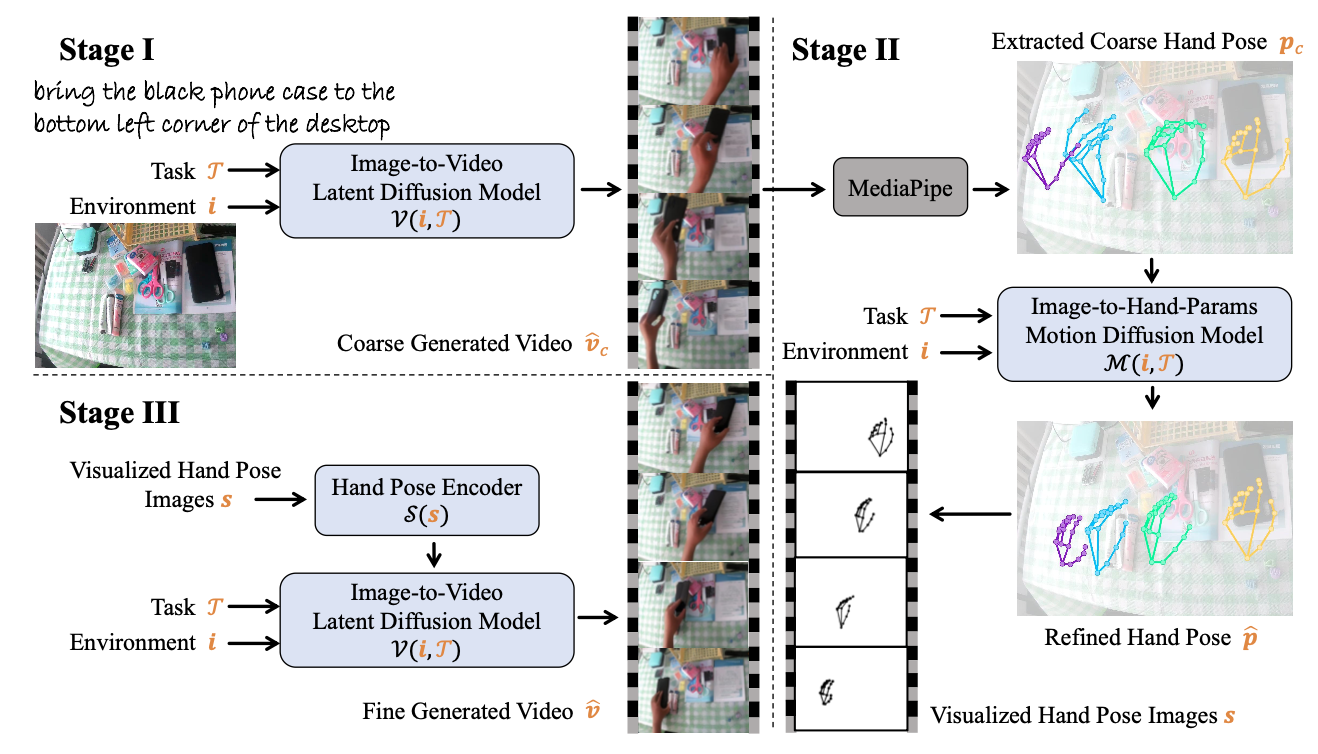
在本研究中,探索基于 DynamiCrafter [54](一個強大的 I2V 潛擴散模型)的 HOI 視頻生成。假設 T 和 v 分別表示任務語言描述、環境圖像和真實視頻幀。DynamiCrafter 在緊湊的潛空間中學習去噪過程:v 通過編碼器 E 編碼到緊湊的潛在空間中,得到潛表示 z = E(v),并通過解碼器 D 進行解碼。在這個潛空間中,該模型以 T 和 i 為條件,執行前向擴散和引導去噪過程。
MDM [45] 采用獨特的 Transformer 編碼器架構,在生成人體運動序列方面表現出色。MDM 不是通過預測單步噪聲,而是直接生成干凈的運動序列。設 p 表示運動序列,M 表示 MDM 網絡。其中,p_0 ~ p_data § 和 p_T ~ N (0, I)。訓練結束后,MDM 通過 T 步去噪過程生成最終的干凈運動序列 p?_0。然而,在每一步中,MDM 不是通過單步去噪直接生成 p_t?1,而是首先根據 p_t 預測干凈的運動序列 p?_0,t。然后,重新引入噪聲得到 p_t?1,通過重復此過程 T 次,MDM 生成最終干凈的運動序列p?_0,0,記為p?_0。
第一階段:粗略動作規劃器
可學習的粗略動作規劃器,旨在生成基于任務描述 T 和環境圖像 i 的粗略 HOI 視頻 v?_c。具體來說,在 TASTE-Rob 上對 DynamiCrafter [54] 進行微調,將其用作粗略動作規劃器,記為 V。
訓練。在微調過程中,采用與 DynamiCrafter [54] 類似的訓練策略。為了充分利用 DynamiCrafter 強大的時間處理能力,同時使其適應本文特定的 HOI 視頻生成,僅對其圖像上下文投影器和其去噪 U-Net中的空間層進行微調。訓練目標保持一致,其中可訓練參數 θ_V 表示圖像上下文投影器和空間層的參數。
手-物體交互不一致問題。生成的粗略 HOI 視頻展現準確的任務理解能力,例如識別要操作的物體并確定其目標位置。然而,如上圖 p_c 所示,抓取姿勢在操作過程中表現出時間上的不一致性,表明缺乏運動連貫性。具體而言,這些不一致性指的是抓取姿勢隨時間發生的不良變化,表現為手勢的不自然變化,而理想情況下,手與被抓物體之間的相對位置應該保持穩定。如圖的 p_c 所示,綠色手勢展示一種捏的手勢,這與黃色手勢的抓取姿勢不一致,并且不適合被操作的目標物體。
第二階段:修改手勢序列
為了解決 HOI 不一致問題,訓練一個圖像-到-手勢參數的 MDM 模型 M。該模型用于細化從粗略視頻 v?_c 中提取的手勢序列 p_c。具體來說,將 p_c 定義為手勢關鍵點序列的歸一化坐標,其中 L_p 表示序列長度,N_h 表示手勢關鍵點的數量。
訓練:可學習模型 M 旨在以任務描述 T 和環境圖像 i 作為輸入,預測精細的人體手勢序列。為此,擴展原始的 MDM [45] 框架,通過一個附加的圖像分支引入環境信息。如圖所示,與 [45] 中的文本條件分支類似,新增的圖像分支集成環境圖像 i 的 CLIP [37] 類特征。
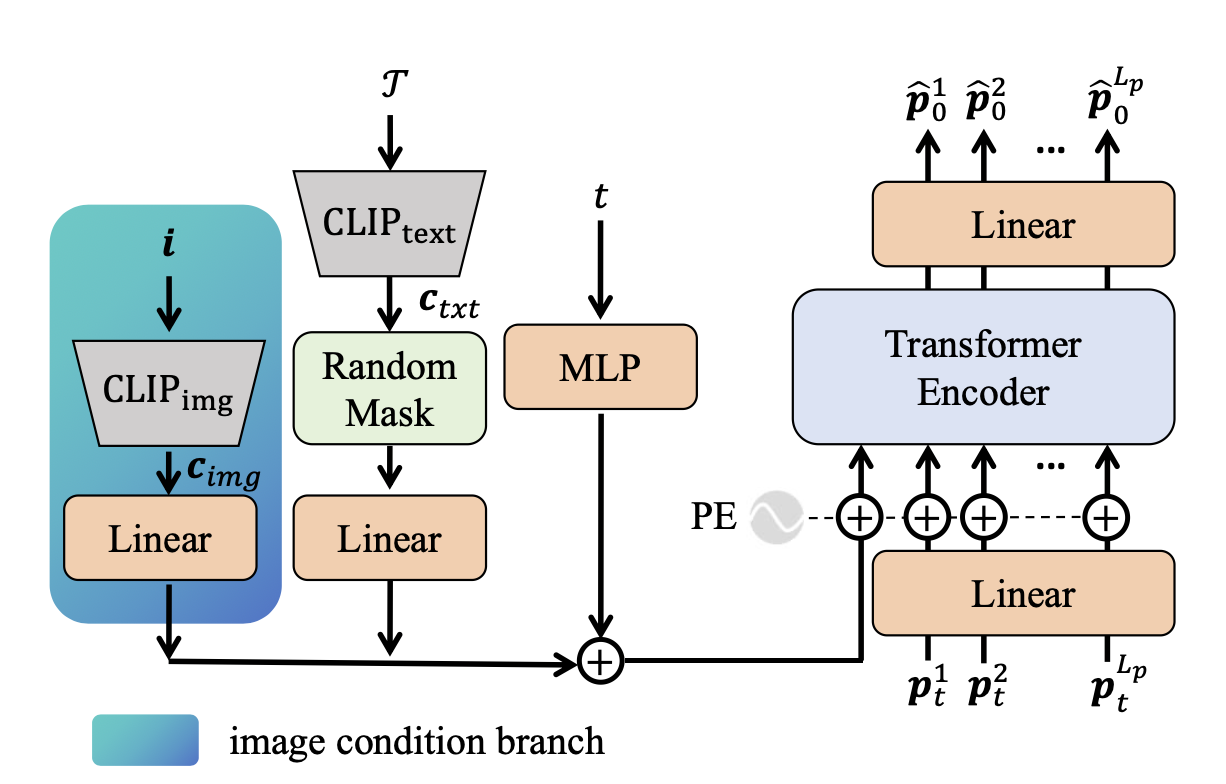
當通過 T 步去噪過程直接生成最終的干凈姿勢序列 p? 時,p? 實現物理上合理的手部運動,但表現出有限的空間意識。相反,p_c 表現出顯著的空間意識。為了解決這個限制,用 M 來優化 p_c,而不是從高斯噪聲生成。具體來說,用 p_0,N_rv 初始化 M 的去噪過程,將 p_c 設置為 p_0,N_rv。通過 N_rv 步去噪,優化 p_c 以獲得最終的干凈手部姿勢序列 p?,該序列同時滿足空間精度和運動可行性。
第三階段:基于精細姿態的再生
利用精細化的??手勢序列,生成附加姿態條件 p? 的細粒度 HOI 視頻。受 ToonCrafter [55] 的啟發,訓練一個與幀無關的姿態編碼器 S 來控制生成視頻中的手勢。將 S 設計為一個逐幀適配器,它以 p? 為條件,獨立地調整每幀的中間特征:F^i = S(s^i_inject, z^i, t),其中 s^i 是 p? 的可視化圖像序列,F^i_inject 的處理方法類似于 ControlNet [62]。
在訓練過程中,采用與 ToonCrafter [55] 類似的策略,其中 V 的所有參數都被凍結,并且只訓練 S 的參數(表示為 η)。
最后,將生成的優質 HOI 視頻 v? 作為 IL 的視頻演示,并使用 Im2Flow2Act 策略模型實現機器人操作 [58]。如圖所示,以生成的 HOI 視頻作為演示,展示模仿學習的結果,也證實其在實現機器人操作方面的有效性。
實施
訓練過程中,在 TASTE-Rob 數據集的訓練集上訓練模型。第一階段:基于 DynamiCrafter 對粗略動作規劃器進行微調,步長為 30K,批次大小為 16,學習率為 5 × 10?5。第二階段:訓練 MDM,步長為 100K,批次大小為 64,學習率為 1 × 10?4。第三階段:基于 SD 對姿態編碼器進行微調,步長為 30K,批次大小為 32,學習率為 5 × 10?5。在推理過程中,用 50 步去噪過程生成視頻,并使用 Nrv 為 10 來優化姿態序列。
基線與比較
選擇了四種現有的強大的 I2V 擴散模型——DynamiCrafter [54]、consistI2V [38]、Open-Sora Plan [26] 和 CogVideoX [60]——作為基線,并對這些基線與本文方法進行了比較實驗。圖中給出 TASTE-Rob-Test 和真實環境下視頻生成性能的定性比較。

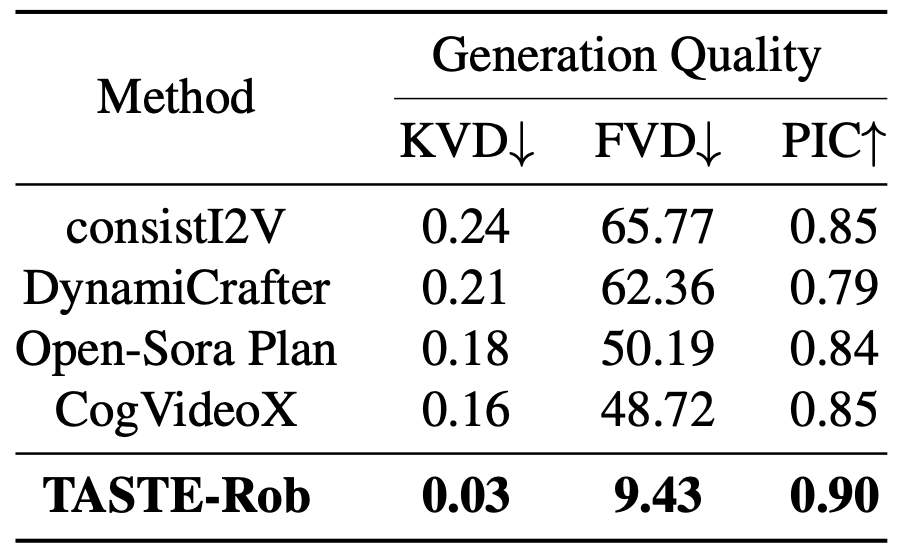
下表中給出 TASTE-Rob-Test 上的定量比較,結果證明本文方法卓越的視頻質量和更好的泛化能力。根據以上實驗,所有現有的強大的通用 VDM 都無法很好地完成操作任務,因此不適合生成 HOI 視頻演示。鑒于其他兩個評估方面側重于衡量生成視頻的細粒度細節,在此省略與這些基線方法的進一步比較。




-Hive數據分析3)
)













