25年3月來自韓國 POSTECH 的論文 “GraspCorrect: Robotic Grasp Correction via Vision-Language Model-Guided Feedback”。
盡管機器人操作技術取得了顯著進步,但實現一致且穩定的抓取仍然是一項根本挑戰,常常限制復雜任務的成功執行。分析表明,即使是最先進的策略模型也經常表現出不穩定的抓取行為,從而導致失敗案例,并在現實世界的機器人應用中造成瓶頸。為了應對這些挑戰,推出 Grasp-Correct,一個即插即用的模塊,旨在通過視覺-語言模型引導的反饋來提升抓取性能。GraspCorrect 采用一個迭代式視覺問答框架,包含兩個關鍵組件:抓取引導提示(包含特定于任務的約束)和目標-覺察采樣(確保選擇物理上可行的抓取候選)。通過迭代生成中間視覺目標并將其轉化為關節-級動作,GraspCorrect 顯著提高抓握穩定性,并持續提高 RLBench 和 CALVIN 數據集中現有策略模型的任務成功率。
考慮機器人操作學習,其中策略模型從演示軌跡 {(o_1, a_1), (o_2, a_2), …} 和文本任務指令 l 中學習。時間步 t 的每個觀測值 o_t 由 RGB-D 圖像組成,每個動作通過三個分量指定末端執行器的姿態:位置 ap_t、旋轉(四元數)ar_t 和二元夾持器狀態 as_t ∈{0,1}。
該策略模型旨在學習一個映射,該映射可以根據當前觀測值 o 預測適當的動作 a。GraspCorrect 可作為現有策略模型的即插即用模塊,在夾持器接觸 l 中指定目標物體的抓取時刻 t(g) 激活。該模塊利用當前抓取對 (o_t(g), a_t(g)) 和時間窗口 W 內的抓取前觀測值 o_t(g)?W,預測正確的末端執行器抓取姿勢 ao,從而提高執行效率。
GraspCorrect 的運行分為三個階段。首先,在(VLM 引導的)抓取檢測階段,它利用 VLM 的洞察識別穩定的抓取位置。在(視覺)目標生成階段,它以圖像形式生成視覺目標。最后,在動作生成階段,它將視覺目標轉化為精確的關節級動作。如圖展示了整個抓取校正過程。
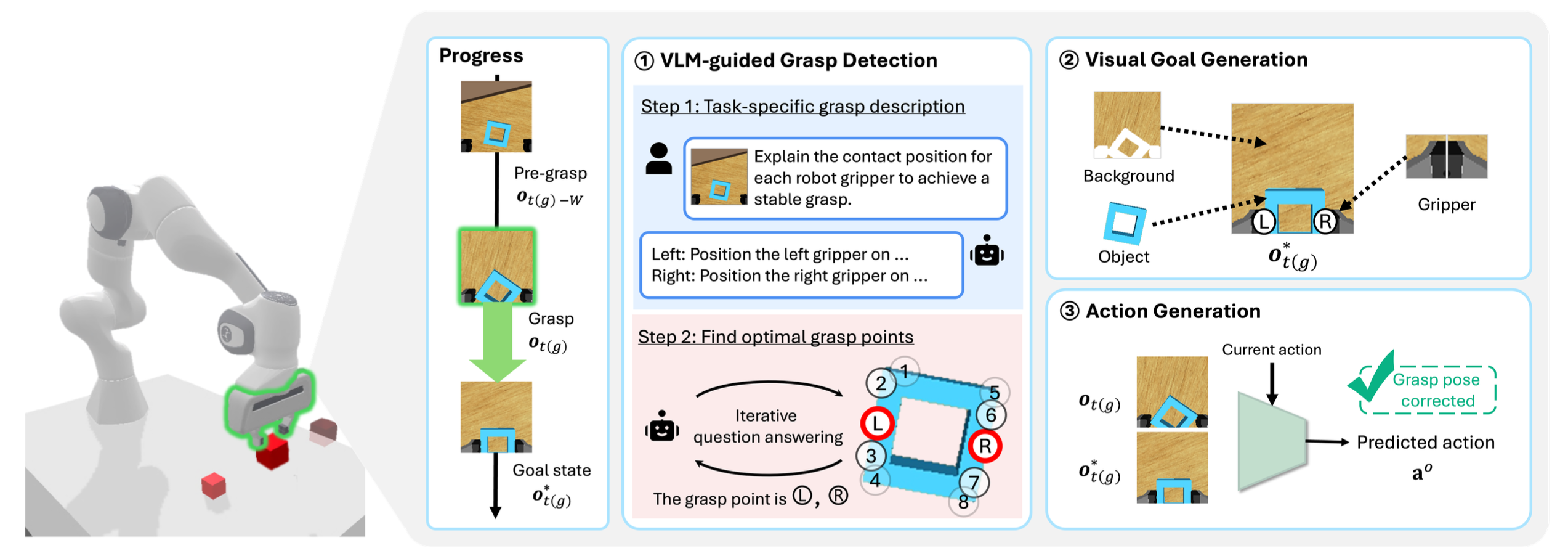
VLM 引導的抓取檢測
此階段將當前觀測值 o_t(g) 和任務描述 l 轉化為面向任務的接觸點 ap_t(g),供機器人夾持器使用,以確保穩定的抓取。利用視覺語言模型 (VLM),這項任務可以定義為空間視覺問答 (VQA),它擴展了傳統的 VQA 任務(例如,識別物體或屬性;“汽車是什么顏色?”),使其包含空間推理,例如確定機器人應該在哪里抓取物體才能穩定地舉起。
預訓練的 VLM 為這項任務提供了豐富的常識性知識庫。然而,將其直接應用于空間推理面臨兩大挑戰。首先,VLM 針對生成文本輸出進行了優化,使其不適合生成坐標或動作等連續值。其次,即使是最先進的 VLM 也難以進行復雜的空間推理(Wang,2024;Chen,2024;Tang,2024b)。
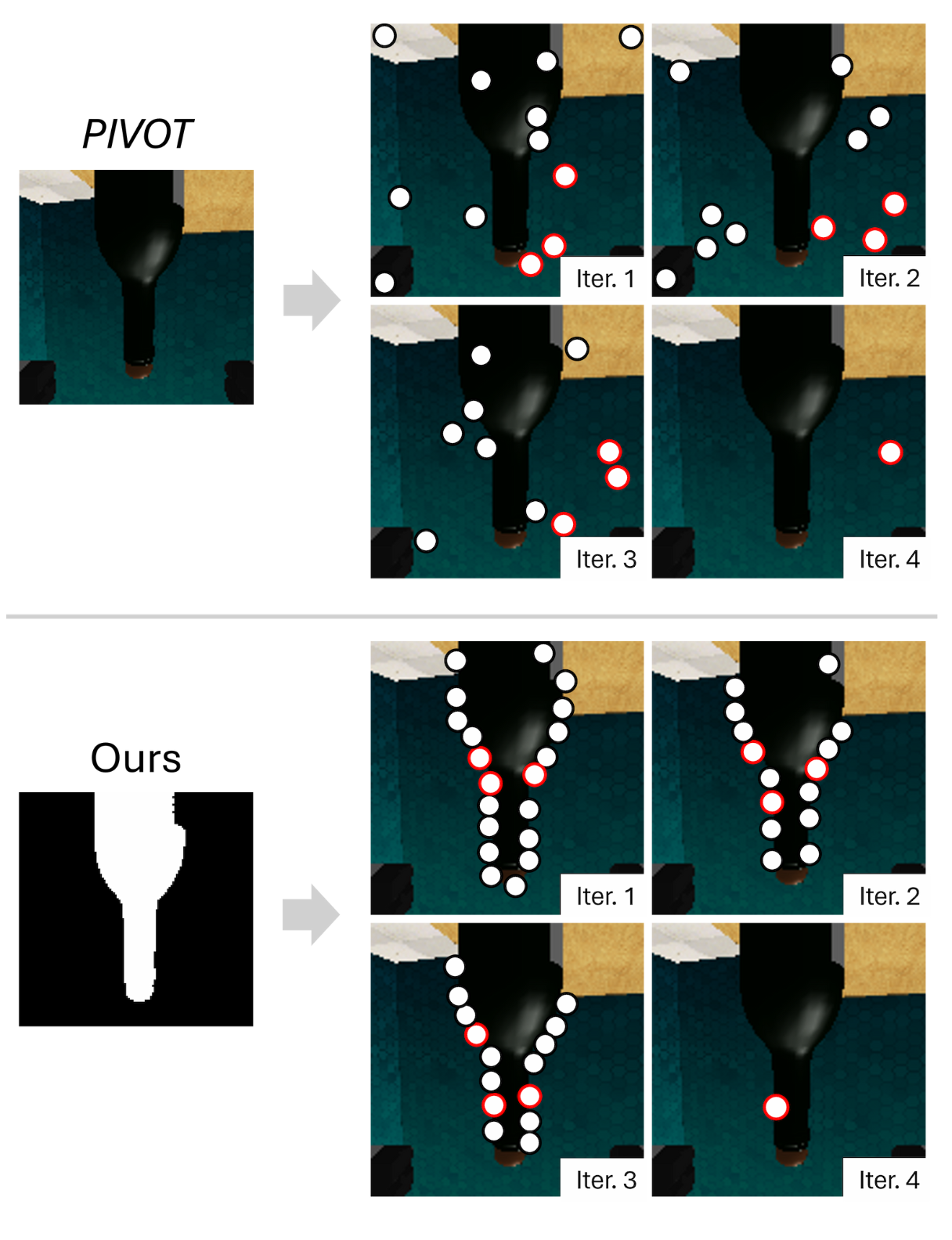
為了克服這些限制,采用一種迭代的 VQA 方法,逐步優化抓取候選點,而不是嘗試直接生成精確的空間坐標。基于 PIVOT (Nasiriany,2024) 的迭代改進策略,引入兩項關鍵改進:(1)抓握引導提示,其中納入特定于任務的約束;(2)目標-覺察采樣,確保生成的抓握候選在物理上是可行的。
該方法始于自上而下的二維觀測 oTop_t(g)?W,即在抓取時刻之前捕獲的 W 幀圖像。由于 t(g) 時刻的近距離抓取姿勢可能僅部分捕捉到物體,因此較早的幀提供了物體幾何形狀的全面視圖。時間窗口大小 W 固定為 10。使用根據任務需求定制的提示,VLM 生成穩定抓取配置的文本描述,作為迭代優化過程的先驗。
為了確保精準定位,用 LangSAM,這是一個零樣本文本-到-分割掩碼的框架,它結合 GroundingDINO(Liu,2025)和 Segment-Anything(Kirillov,2023)。此分割步驟將抓取建議限制在實際物體上,避免了可能針對背景元素的幻覺。
抓取候選點最初沿物體輪廓進行采樣(如圖所示圓圈)。VLM 評估這些點,以識別可能支持穩定抓取的候選點(紅色圓圈)。然后,通過以這些有希望的點為中心的一維高斯分布沿物體輪廓進行采樣,生成新的候選點。迭代次數 T 固定為 4,在最后一次迭代中,選擇一個候選點。
視覺目標生成
此階段基于輸入觀測值{o_t(g), o_t(g)?W}以及抓取檢測階段識別的抓取點,合成目標抓取姿態圖像o^?_t(g),該圖像描繪了機器人抓取器(左和右)、目標物體及其空間關系。
該過程首先使用 LaMa 修復模型(Suvorov,2022)恢復被遮擋的背景區域,以創建完整的背景圖像。然后,通過融合恢復的背景、抓取器和變換后的前景物體來構建合成圖像。物體與抓取器的對齊是通過在抓取檢測階段的接觸點信息引導下進行常規圖像變換(旋轉和平移)來實現的。生成的目標狀態圖像真實地表示所需的抓取姿態,并為后續的動作生成步驟奠定了基礎。
動作生成
為了實現低級關節驅動,采用目標為條件行為克隆 (GCBC) 框架。作為模仿學習的一種形式,行為克隆通過最小化預測和觀察的專家動作之間差異來訓練智體復制專家演示。遵循 (Walke et al., 2023) 的方法,用去噪擴散概率模型 (DDPM) (Ho et al., 2020) 來實現此目標,該模型迭代地將高斯噪聲分布??細化為數據生成分布。
GCBC 策略模型 π_φ 包含一個 ResNet-34 編碼器,隨后是一個三層多層感知器 (MLP),其參數化為權重 φ。由于觀察圖像是從以自我為中心的自上而下視角捕獲的,將當前動作狀態作為條件變量來增強空間感知。這有助于將生成的輸出動作平滑地集成到正在進行的軌跡中。
訓練數據 D 是在每個基準環境中通過系統地擾亂真實抓握姿勢生成的。
VLM 與行為控制的互補作用:
該方法將用于抓握檢測的 VLM 與用于動作生成的 GCBC 相結合,并認識到 VLM 在直接合成精確抓握動作方面的局限性。雖然 VLM 在場景理解和高級規劃方面表現出色,但它們在具身操作所需的細粒度控制方面卻舉步維艱。
在初步實驗中,直接使用基于當前觀察、動作和任務描述的 VLM 進行動作預測 a 常常會導致不切實際且物理上難以信服的輸出。這驗證了劃分操作流程的決定:使用 VLM 進行感知和規劃,同時依賴專門的 GCBC 模塊進行精確控制。
基于圖像中間表示的優勢:
GraspCorrect 使用圖像作為中間目標表示。這一決定基于幾個關鍵優勢。首先,視覺表示能夠捕捉豐富的空間和上下文信息,而這些信息在基于文本的描述中可能會丟失或模糊。圖像能夠自然地以具體、清晰的方式編碼關鍵的操控相關特征,例如空間關系、物體方向和抓取配置。
其次,VLM 已在大規模視覺數據上進行過廣泛的訓練,使其尤其擅長處理和推理基于圖像的信息。這種協同作用使系統能夠充分利用 VLM 先進的視覺理解和推理能力,同時保持清晰易懂的高級決策界面。
第三,近期使用合成目標圖像進行機器人操控的成功案例,例如 SuSIE(Black,2024)和 GR-MG(Li,2025),進一步證明了該方法的有效性。
然而,基于圖像的表示也存在一定的局限性,尤其是在處理遮擋和捕捉動態物理特性方面。未來的研究可以探索融入更多模態,例如 3D 點云或力反饋,以提供更豐富、更全面的目標狀態表征。
替代的視覺目標生成策略:
預期的目標狀態抓握姿勢通常需要對預訓練策略模型提供的當前抓握姿勢進行微調。雖然像快速探索隨機樹 (RRT) (Steven, 1998) 這樣的路徑規劃算法看似適用,但它們并不適用于此情境,因為它們需要精確的目標坐標,而由于以自我為中心的機器人攝像頭與機器人坐標系不匹配,獲取這些坐標非常困難。因此,精確定位 VLM 響應所指示的精確坐標變得具有挑戰性。
另一種方法是使用由 VLM 生成的抓握描述所啟發的圖像編輯或圖像生成擴散模型。在 RLBench 中測試四個這樣的模型:DALL-E(圖像生成)(Ramesh,2021)、SuSIE(Black,2024)、DiffEdit(Couairon,2023)和 Imagic(圖像編輯)(Kawar,2023)。遵循 SuSIE 的方法,采用專門針對操作任務調整的 InstructPix2Pix(Brooks,2023)的微調版。
如圖所示,這些模型通常無法生成準確可靠的結果。例如,DALL-E 往往會生成過于復雜的機械手,與實際的機械手設計存在很大偏差。DiffEdit 和 SuSIE 會錯誤地表示正方形的方向,使其無法與預期的抓取姿勢對齊,而 Imagic 則引入了不切實際的人類手指。
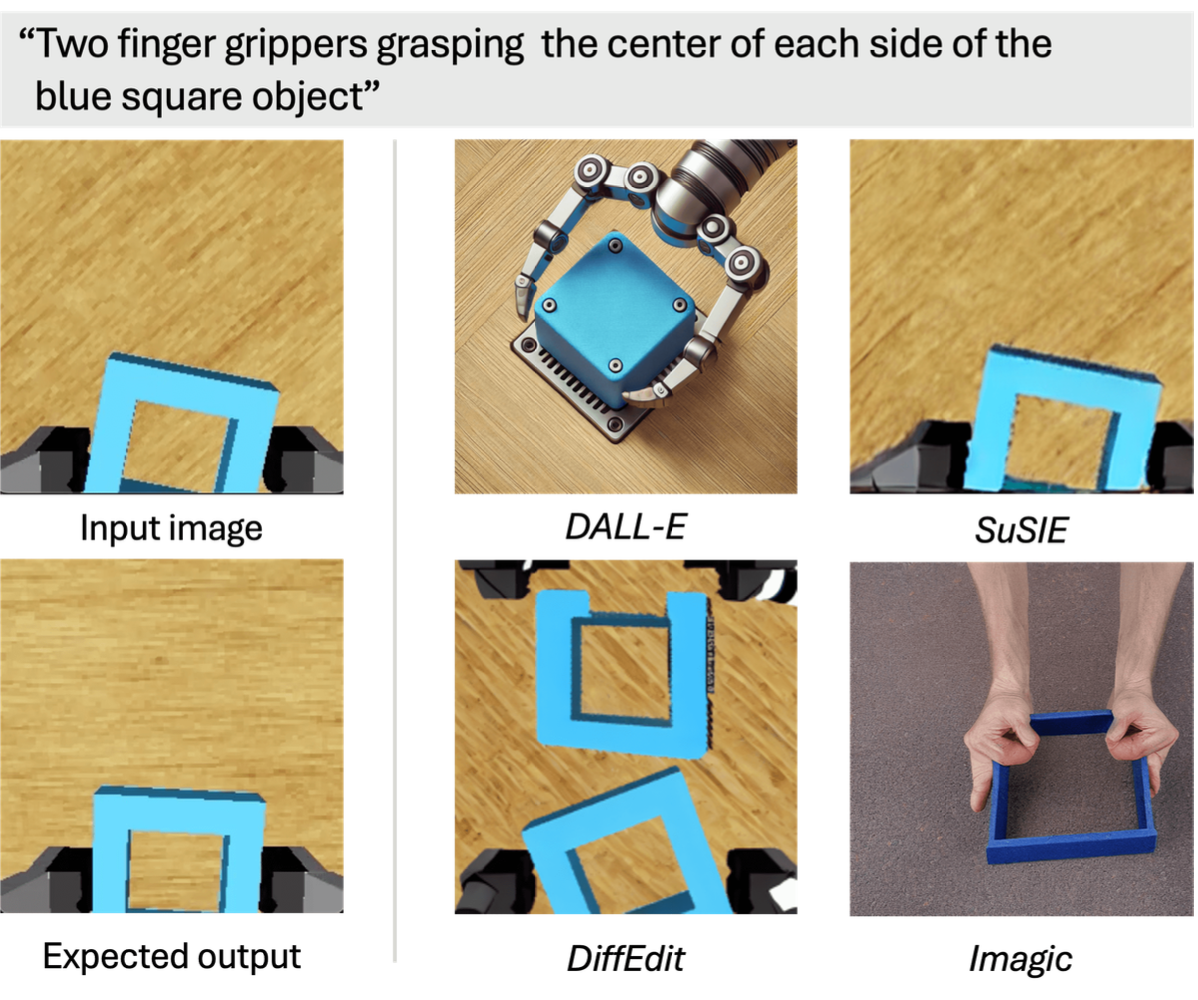
相比之下,簡單的圖像混合技術被證明能夠高效地生成目標狀態的精確逼真的合成圖像。這種方法保留了目標物體的結構完整性,并維持了對成功操作至關重要的空間關系。
動作生成
模型架構:策略網絡架構由一個 ResNet-34(He,2016)和組歸一化(Wu & He,2018)組成,用于處理沿通道維度堆疊的當前和目標觀察圖像。編碼器的輸出隨后通過一個三層多層感知器 (MLP),該感知器包含 256 個隱藏單元,每層都使用 Swish 激活函數(Hendrycks & Gimpel,2016)。該 MLP 輸出高斯動作分布的平均值和標準差。
訓練使用 Adam 優化器(Kingma & Ba,2014)進行,學習率為 5e-4,線性預熱調度超過 2,000 步,批處理大小為 256。在連接之前,當前圖像和目標圖像均經過標準圖像增強處理,包括隨機裁剪以及亮度、對比度、飽和度和色相調整。
數據生成協議:動作生成策略需要由觀察-動作三元組 (o_t(g), a_t(g), o?_t(g), a?_t(g)) 組成的成對數據,其中需要抓取校正的狀態與其對應的穩定抓取配置配對。在 RLBench 環境中實施一個兩階段數據收集協議來生成這些訓練對。
為了收集需要校正的狀態 (o_t(g), a_t(g)),首先初始化一個模擬環境,該環境包含桌面工作空間、目標物體和 Franka Panda 機器人。運動路徑由航點定義,這些航點作為 RLBench 路徑規劃算法的參考點,如圖所示。通過對這些航點的位置和方向引入受控隨機化,生成抓取嘗試的真實變化。在抓取的瞬間,記錄觀察值和執行的動作向量。為了獲得穩定的參考狀態 (o?_t(g), a?_t(g)),在相同條件下重復抓取序列,但不進行航點隨機化。通過這個系統化的過程,為每個操作任務生成 200 個配對示例,為策略學習提供平衡的數據集。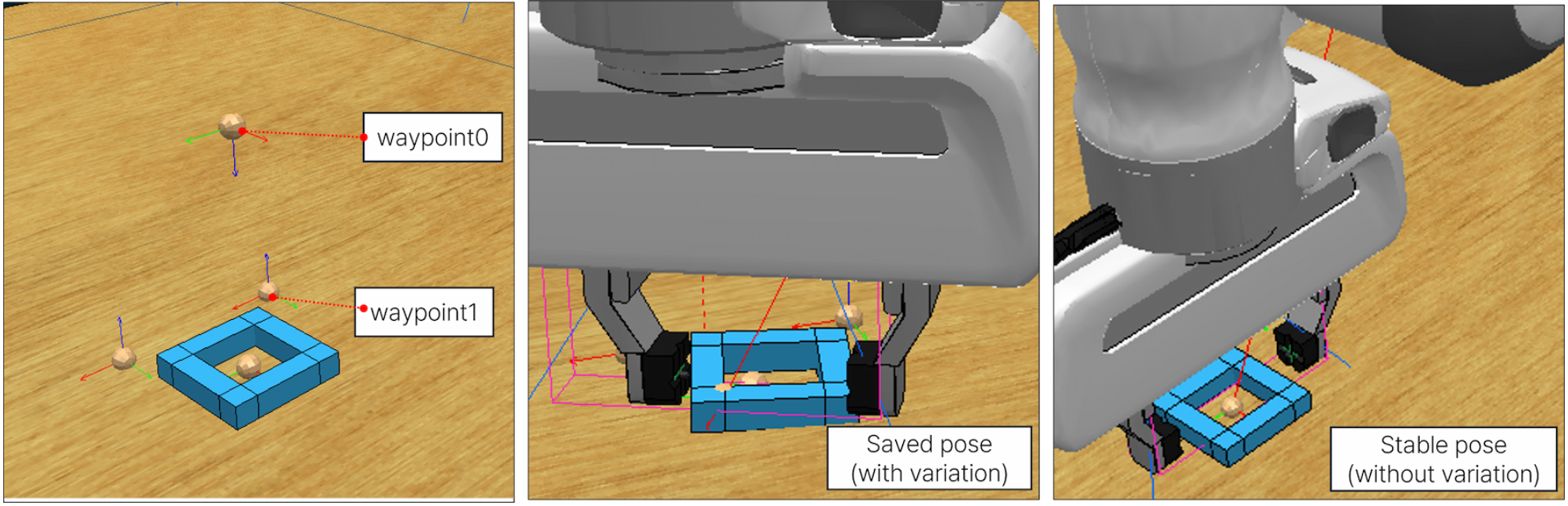


-Hive數據分析3)
)















