摘要
本文深入探討了XXL-Job框架的設計思考,分析了其不使用Lombok的@Data注解的原因,包括明確控制代碼結構、避免依賴侵入、增強可維護性和調試便利性、保持編譯清晰以及遵循項目歷史和團隊編碼規范。文章還詳細介紹了XXL-Job的優化設計,包括數據庫優化、執行優化、服務啟動類以及執行器原理等內容,旨在提升框架的性能、可維護性和兼容性。同時,文章還討論了XXL-Job在真實項目部署中的數據庫部署模式、并發能力以及任務狀態類型等關鍵問題。
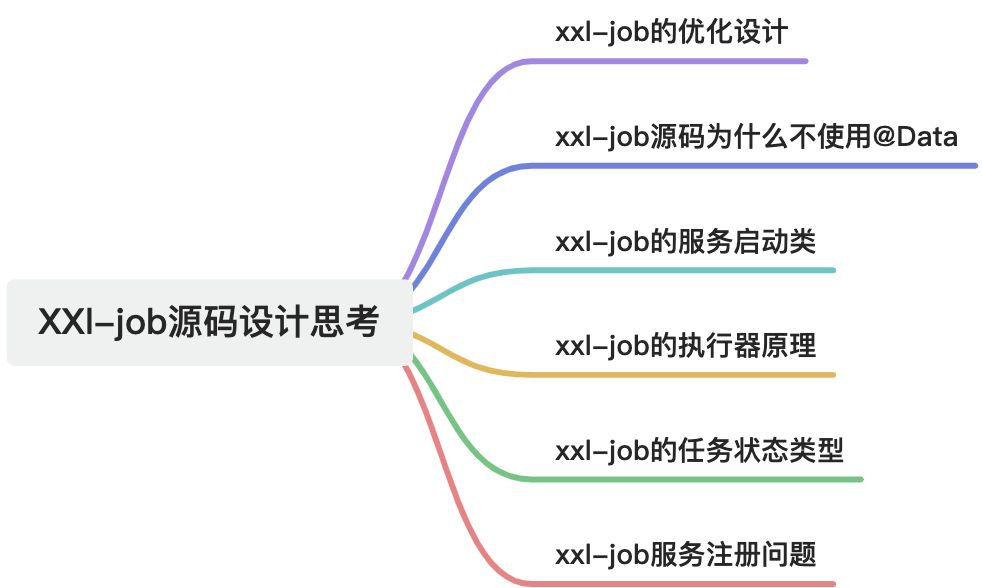
1. XXL-JOB 功能架構設計
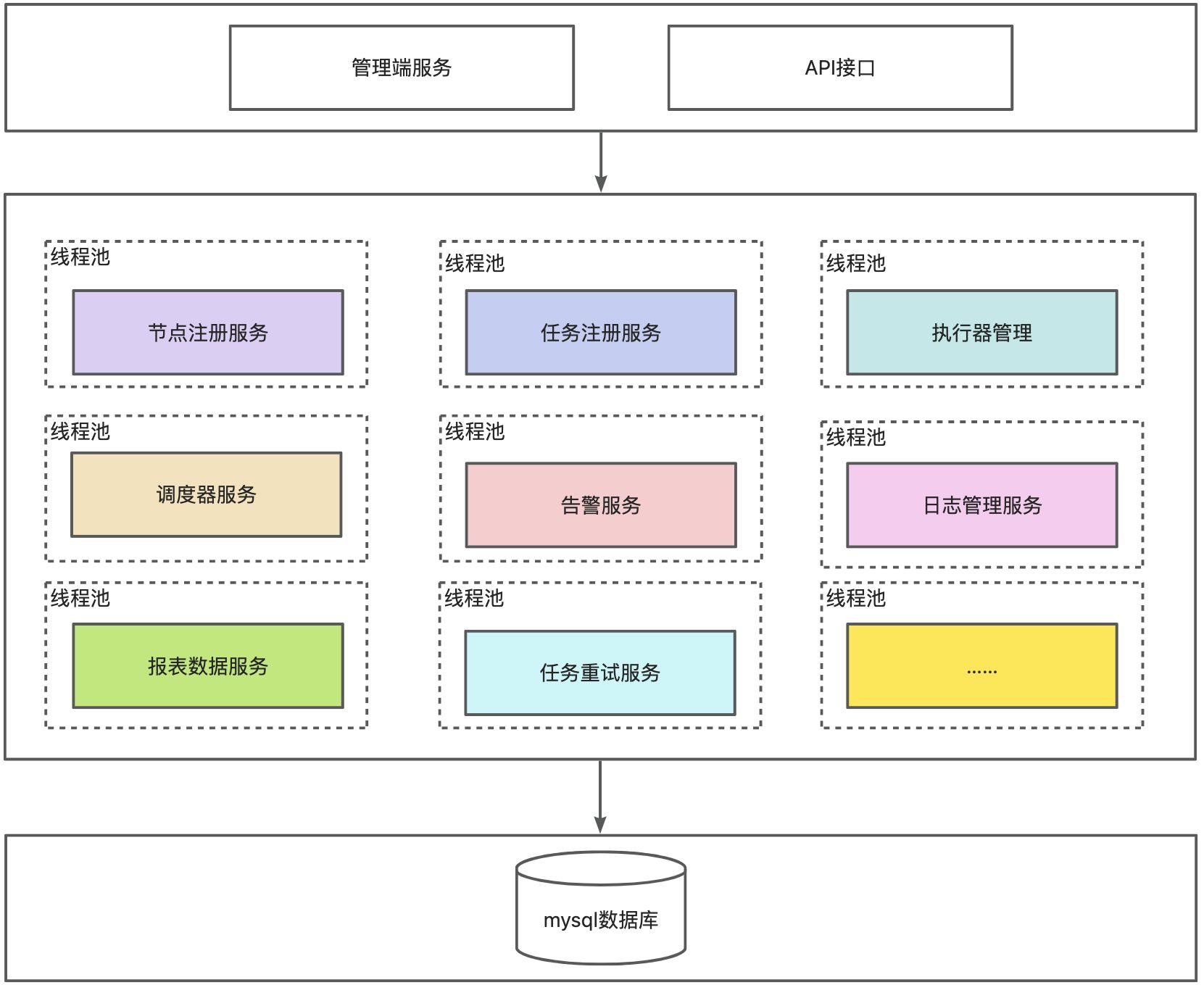
2. xxl-job 真實項部署數據庫是單節點還是的主從模式或者集群模式?
在真實生產環境中,XXL-JOB 調度中心的數據庫部署可以根據業務規模和可靠性需求選擇不同模式,下面是幾種常見部署方式對比和推薦:
2.1. ? 單節點數據庫部署(常見于中小型系統)
特點:
- 使用單個 MySQL 實例(如 RDS、裸機、Docker等)。
- 配合調度中心的分布式部署(多個 admin 節點 + 多個執行器節點),數據庫保持唯一。
優點:架構簡單、部署成本低。
缺點:數據庫單點風險。
👉 這種方式已經能滿足絕大多數中小型企業調度需求。
2.2. ? 主從(讀寫分離)部署
特點:
- 使用 MySQL 主從架構。
- XXL-JOB 調度中心所有寫操作(如任務注冊、日志寫入)走主庫。
- 若自己改造代碼,部分讀操作可以配置讀庫(需自己分庫讀寫)。
優點:減輕主庫壓力、提高查詢性能。
缺點:需要自行維護讀寫分離邏輯(原生 XXL-JOB 不支持自動分庫分表)。
2.3. ? 主主復制 / 高可用集群
特點:
- 通過 MySQL + MGR(Group Replication)、TiDB、PolarDB 等實現強一致 + 高可用。
- 保證數據庫層面的故障自動切換。
優點:強一致、高可用、無主點。
缺點:架構復雜、成本較高。
2.4. ?? 需要注意:
- XXL-JOB 并不支持多數據源或多庫分布式部署,調度中心所有節點必須連接同一個數據庫(IP 一致)。
- 多個 XXL-JOB Admin 實例啟動時,會通過
xxl_job_lock表加行鎖防止重復調度(這依賴數據庫強一致)。
2.5. ? 官方推薦:
一個調度中心 + 一個數據庫 + 多個執行器節點 的部署結構已可滿足大多數需求。數據庫推薦 MySQL 8.x 單實例 或主從讀寫分離。
2.6. ? 補充建議:
如果你希望做到數據庫層的高可用:
- 推薦使用 MySQL 主從 + Keepalived + VIP 實現切換。
- 或者使用 阿里云 PolarDB、騰訊 TDSQL、AWS RDS 多可用區 等。
3. 一個調度中心 + 一個數據庫 + 多個執行器節點并發能力?
XXL-JOB 的任務并發能力,取決于多個因素,下面是詳細分析。
3.1. ? 理論架構下的并發模型
“一個調度中心 + 一個數據庫 + 多個執行器” 是官方推薦的架構,其并發量主要由以下幾個部分決定:
關鍵影響因素:
| 模塊 | 限制說明 |
| 調度中心線程數 | 默認:10(可調,影響觸發并發數) |
| 執行器數 | 每個執行器是一個 Spring Boot 服務,可水平擴展多個實例 |
| 每個 Job 的并發策略 | JobHandler 默認是串行執行(可配置為并行) |
| 數據庫寫入能力 | 任務觸發和日志寫入都依賴數據庫,瓶頸主要在數據庫 QPS |
| 網絡和機器性能 | 網絡延遲 + 機器負載決定實際并發能力 |
3.2. ? 默認配置的并發能力(粗略估算)
| 模塊 | 數量/配置 | 并發能力估計 |
| 調度線程 |
| 每秒可觸發約 100~500 個任務(任務觸發非常輕量) |
| 執行器節點 | 5 個節點(假設) | 每個節點可并發處理 10~100 個任務(視線程池) |
| 數據庫寫入 | MySQL 單實例(較好配置) | 可支持每秒 500~2000 次插入操作(主要是日志寫入) |
? 估算實際可支撐并發量為:1000~5000 個任務/分鐘(輕量級任務)
3.3. ? 如何提升并發能力?
| 優化點 | 建議 |
| 🔧 增加執行器節點數 | 執行器可無限水平擴展,提高處理能力 |
| 🔧 擴大執行器線程池 | 每個執行器默認線程池為 |
| 🔧 JobHandler 設置為并行執行 | BlockStrategy 選擇 |
| 🔧 數據庫優化 | 日志表分表,使用 SSD,開啟 binlog async,避免成為瓶頸 |
| 🔧 批量觸發任務 | 盡量減少調度頻率,比如將多個數據放一個 Job 處理 |
| 🔧 調度中心線程提升 | 增加調度線程數,如 |
3.4. ? 極限高并發案例(社區實際案例)
有用戶反饋(在 XXL-JOB 社區 / GitHub Issues):單調度中心 + 10 個執行器節點,執行 2W+ 個小任務/小時(平均每分鐘 300+ 任務),穩定運行。
但同時也指出:
- 日志表每秒寫入過多會拖慢性能,需要分表;
- 任務執行應盡可能輕量化,避免任務阻塞線程。
3.5. ? xxl-job并發模型總結
| 模塊 | 默認配置并發 | 可擴展性 |
| 調度中心 | 每秒觸發數百任務 | 可調線程數提升能力 |
| 執行器 | 默認串行執行 | 增加線程池 + 節點 |
| 整體瓶頸 | 數據庫(寫日志) | 分表 + 高性能實例解決 |
4. XXL-JOB 的優化設計
如果一個系統中的任務需要不斷掃描數據庫,且隨著時間推移,數據量不斷增大,這種情況可能會導致性能瓶頸。為了應對這種問題。
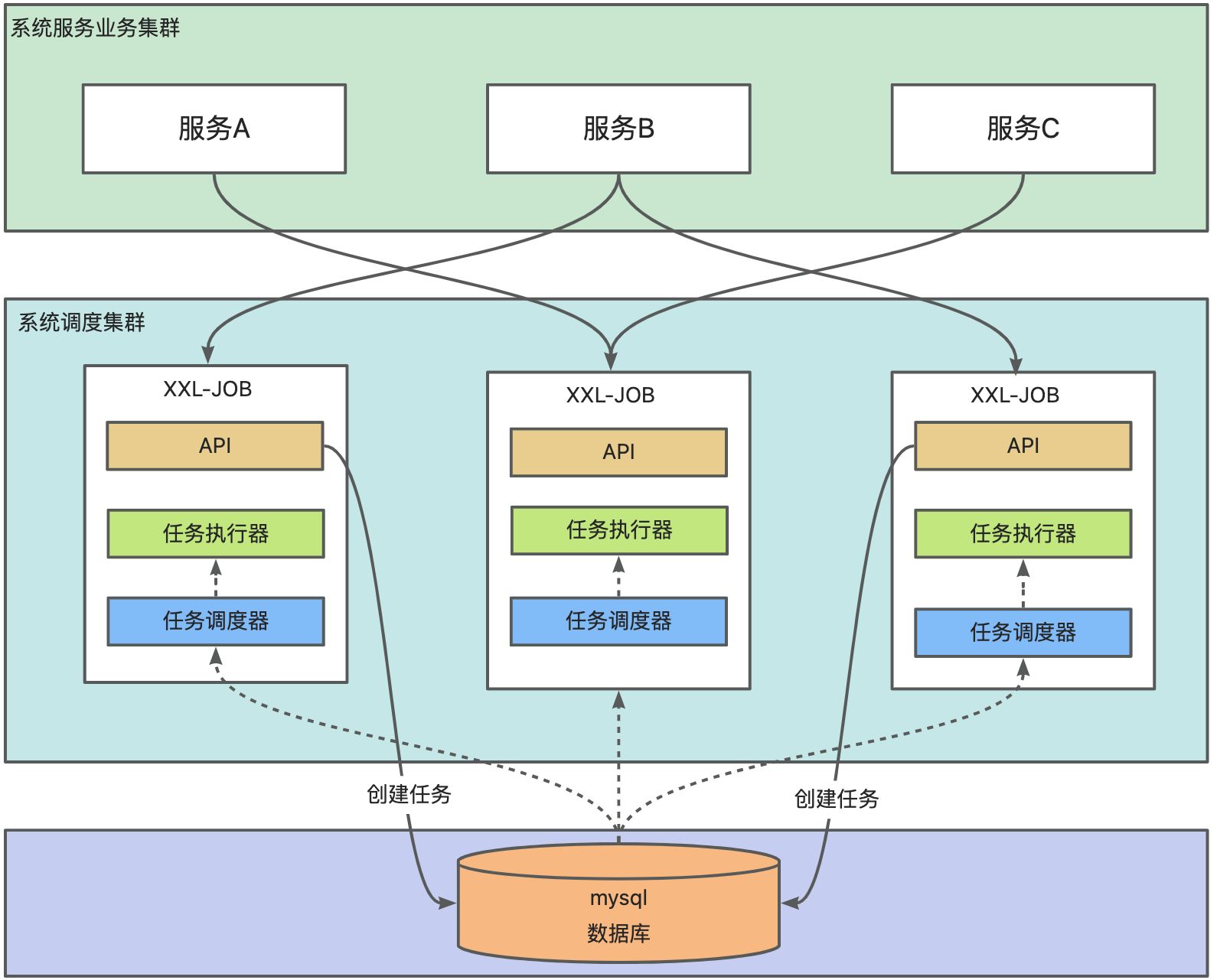
4.1. XXL-JOB數據庫優化
在 XXL-JOB 中,數據庫通常是單點部署的,但也可以通過一些方法實現高可用性,以避免單點故障影響任務調度的穩定性。具體情況如下:
4.1.1. 默認使用單點數據庫
XXL-JOB默認依賴一個單一數據庫實例來存儲任務信息(包括任務配置、執行日志、任務狀態等)。- 在單節點部署中,如果數據庫發生故障,整個調度系統將無法正常工作,任務調度會受到影響。
- 對于小規模應用或任務調度不關鍵的場景,單點數據庫通常是足夠的,部署簡單且易于維護。
4.1.2. 可以使用主從復制或高可用數據庫集群
- 為了保證數據庫的高可用性,
XXL-JOB可以部署在數據庫主從復制或集群環境中,例如使用 MySQL 的主從復制、讀寫分離,或者使用 MySQL Cluster、MySQL Group Replication 等集群方案。 - 這樣可以提高數據庫的容錯能力,在主庫出現問題時,數據庫服務可以自動切換到從庫,從而保證調度系統的連續性。
4.1.3. 高可用方案:使用數據庫中間件或云數據庫
- 一些企業級數據庫中間件(如 MyCAT)可以實現數據庫讀寫分離和故障轉移,可以在
XXL-JOB與數據庫之間增加中間件層,利用中間件的高可用特性實現數據庫的容災。 - 也可以使用云數據庫,如阿里云 RDS、AWS RDS 等,這些服務通常支持自動故障轉移、備份恢復等功能,能夠實現數據庫的高可用,減少單點故障的影響。
4.1.4. 分布式任務調度的高可用性
XXL-JOB本身支持調度中心(Admin)和執行器(Executor)多節點集群部署,以提高調度系統的整體高可用性。- 在高可用的配置下,即使某個執行器節點故障,任務也可以被分配到其他節點執行,從而保證任務的正常運行。數據庫作為任務數據存儲核心,可以使用高可用方案來進一步保障穩定性。
4.1.5. 避免單點的注意事項
- 配置數據庫高可用時,需要確保調度中心(
XXL-JOB Admin)能夠感知數據庫的主從切換,并且在切換過程中不會造成任務數據丟失或任務狀態不一致。 - 使用高可用數據庫時,還需要考慮調度日志、任務配置等數據的同步,確保在數據庫切換時數據的一致性。
XXL-JOB 默認使用單點數據庫,但在生產環境下,可以通過主從復制、高可用數據庫集群或數據庫中間件來提升數據庫的容錯能力,從而實現高可用部署。
4.2. xxl-job的執行優化
可以從以下幾個方面著手優化:
- 減少掃描量(增量掃描、分頁)、
- 提升查詢效率(分區、索引、歸檔)、
- 緩解數據庫壓力(緩存、分片、異步處理)
- 以及適當的數據存儲選擇。
4.2.1. 使用增量掃描
- 問題描述:如果每次都掃描整個數據庫,數據量增大時會導致查詢越來越慢。
- 解決方案:使用增量掃描技術,只處理自上次掃描后新增或修改的數據。可以使用時間戳或遞增的ID字段來標記數據變更。每次掃描時只讀取比上次時間戳或ID更大的記錄,減少查詢量。只查詢沒有被消費任務數據,同時在數據被消費之后會寫數據狀態。
4.2.2. 分頁處理
- 問題描述:一次性加載大量數據到內存中,可能會導致內存溢出或性能下降。
- 解決方案:將數據分批處理,使用分頁技術逐頁讀取數據。例如可以使用SQL的
LIMIT和OFFSET,或游標(cursor)讀取數據。這樣每次只處理一小部分數據,有助于控制內存消耗和處理時間。
4.2.3. 分區表
- 問題描述:單表中的數據量過大,影響查詢效率。
- 解決方案:對數據進行分區,將不同時間段的數據放入不同的分區表。例如按月或按年分區查詢,數據庫會僅掃描相關的分區,減少查詢量。此外,數據庫如MySQL、PostgreSQL、Oracle等都支持表分區。就是講任務已經完成的進行歸檔處理。
4.2.4. 索引優化
- 問題描述:大數據量下全表掃描耗時較長。
- 解決方案:針對查詢條件創建合適的索引,減少掃描行數。特別是增量掃描時,可以在時間戳或ID字段上創建索引,提高查詢效率。但要注意,過多的索引可能影響寫入性能。
4.2.5. 定期歸檔歷史數據
- 問題描述:歷史數據存放在主庫中,但不再被頻繁查詢。
- 解決方案:將舊數據歸檔到冷數據存儲中,比如定期將一年前的數據轉移到備份表或歷史表中,主庫中只保留活躍數據。這種方式也適合使用數據倉庫進行歷史數據分析。
4.2.6. 緩存熱點數據
- 問題描述:同一數據被頻繁掃描,導致數據庫壓力增大。
- 解決方案:對熱點數據使用緩存技術,如Redis、Memcached等,將常用數據放在內存中,減少對數據庫的直接訪問。可以在緩存中設置過期策略,確保數據一致性。
4.2.7. 優化SQL查詢
- 問題描述:查詢效率低,尤其是復雜查詢的性能可能會顯著下降。
- 解決方案:優化SQL查詢語句,簡化復雜的SQL邏輯,避免子查詢、JOIN操作過多。可以通過查詢計劃(如
EXPLAIN命令)查看查詢的執行情況并進一步優化。
4.2.8. 數據庫分片
- 問題描述:單個數據庫存儲和處理能力有限,數據量大時難以應對。
- 解決方案:對數據進行分片,按一定規則(如用戶ID、地理位置等)將數據分散到不同的數據庫中,減小單個數據庫的壓力。可以使用分布式數據庫或中間件來管理分片。
4.2.9. 異步處理和消息隊列
- 問題描述:實時處理所有數據的成本高,并且無法保證處理時延。
- 解決方案:將掃描任務異步化,比如使用消息隊列(如Kafka、RabbitMQ)將需要處理的數據推送給消費者異步處理,這樣可以讓生產者和消費者解耦,避免數據庫壓力過大。
4.2.10. 使用合適的數據存儲
- 問題描述:某些數據增長過快,數據庫難以處理大量寫入。
- 解決方案:根據數據類型和查詢模式,考慮將一部分非關系型數據遷移到適合的數據存儲中,例如大數據集可以使用NoSQL數據庫(如MongoDB、HBase)或分布式文件系統(如HDFS)來存儲和處理。關系型數據庫和非關系型數據庫結合使用,可以提升整體性能。
5. XXL-JOB 中類沒有使用@Data,為什么?
在 XXL-Job 中,確實很多類并沒有使用 Lombok 提供的 @Data 注解,而是手動編寫了 getter、setter、toString 等方法。這種做法其實是有意為之,主要出于以下幾個原因:
5.1. 💡 原因分析:
5.1.1. 明確控制代碼結構,提升可讀性
@Data會自動生成 getter/setter、equals、hashCode、toString 等多個方法。- 在公共組件或框架中,如 XXL-Job,開發者往往希望對生成的每個方法有更明確的控制和可讀性,避免 Lombok 的黑盒行為。
5.1.2. 避免 Lombok 帶來的依賴侵入
- XXL-Job 是一個廣泛使用的調度框架,如果底層使用 Lombok,意味著使用者也必須引入 Lombok 依賴,否則編譯報錯。
- 為了保持框架的“零侵入”性,作者可能選擇避免 Lombok,以提升兼容性與移植性。
5.1.3. 可維護性和調試便利性
- 手寫方法雖然冗長,但在調試和閱讀源碼時更加直觀,便于定位問題。
@Data生成的toString()、equals()、hashCode()方法,有時會導致日志輸出過多或出現性能問題,手寫更安全。
5.1.4. 保持編譯清晰,避免IDE插件依賴
- Lombok 依賴編譯器插件(如 IntelliJ 的 Lombok Plugin)才能正確識別。
- 有些開發者或團隊不希望因為 IDE 配置不同導致無法正常閱讀源碼或編譯錯誤。
5.1.5. 項目歷史或團隊編碼規范
- XXL-Job 是早期開發的項目(最初發布于 2016 年),當時 Lombok 并不如現在流行。
- 很多老項目為了保持一致風格和團隊規范,堅持手寫 getter/setter。
5.2. @Data 注解總結
XXL-Job 中不使用 @Data 是為了代碼清晰、控制力強、避免依賴、增強兼容性和調試友好性,這是一種更適合框架/中間件開發的風格。
6. XXL-JOB 服務啟動類
在 XXL-JOB 的調度中心(xxl-job-admin)中,程序的啟動入口 是標準的 Spring Boot 方式。
6.1. 初始化邏輯入口XxlJobAdminConfig
@Component
public class XxlJobAdminConfig implements InitializingBean, DisposableBean {private static XxlJobAdminConfig adminConfig = null;@Overridepublic void afterPropertiesSet() throws Exception {adminConfig = this;xxlJobScheduler = new XxlJobScheduler();xxlJobScheduler.init(); // 初始化調度器}
}6.2. 核心調度入口:XxlJobScheduler
在 XxlJobAdminConfig 中初始化的 XxlJobScheduler 是 XXL-JOB 的 調度核心組件:
public class XxlJobScheduler {public void init() throws Exception {// 初始化觸發器線程池、注冊服務、日志清理等JobTriggerPoolHelper.toStart();JobRegistryMonitorHelper.getInstance().start();...}
}其中會啟動多個核心線程模塊,如:
JobTriggerPoolHelper(任務觸發線程池)JobRegistryMonitorHelper(注冊節點監控)JobFailMonitorHelper(失敗任務監聽)JobLogReportHelper(日志統計線程)
6.3. XXl-job啟動總結
| 步驟 | 組件 | 說明 |
| ① |
| Spring Boot 啟動入口 |
| ② |
| 加載配置,初始化調度器 |
| ③ |
| 啟動調度線程、任務池、注冊中心等 |
| ④ | 各種 Helper 類 | 真正執行調度、監控、失敗處理、清理日志等任務 |
如果你是在使用 xxl-job-executor 客戶端,則入口會是:Spring Boot 應用啟動后執行 XxlJobSpringExecutor#start() 注冊自己到調度中心。需要我再補充一下 執行器客戶端的入口流程 也可以繼續發問。
7. XXL-JOB 執行器原理概述
XXL-JOB 執行器項目確實是 借助 Spring 啟動機制進行初始化,在初始化階段完成了各種 任務調度相關線程組件的加載與啟動,包括你提到的 JobFailMonitorHelper、JobLogReportHelper、TriggerCallbackThread、ExecutorRegistryThread 等核心線程模塊。
7.1. 🧩 XXL-JOB 執行器原理概述
XXL-JOB 執行器是一個內嵌于 Spring Boot 應用中的組件,啟動時完成:
- 注冊任務處理器(@XxlJob)
- 注冊到調度中心(通過心跳線程)
- 啟動內嵌 HTTP Server 接收調度請求
- 啟動多個線程模塊用于調度、監控、日志回調等
7.2. 🧵 核心線程模塊一覽(執行器中)
| 線程模塊 | 作用 | 實現機制 |
|
| 執行器注冊&清理失效節點 | 心跳檢測 |
|
| 失敗任務監控與重試 | 日志表輪詢 |
|
| 檢測未執行的調度任務 | 時間差+日志判斷 |
|
| 異步觸發任務執行 | Fast/Slow 線程池 |
|
| 日志報表生成 | 每小時統計一次 |
|
| 按 cron 周期調度任務 | 任務輪詢觸發 |
7.3. 🧬 初始化順序原理分析
com.xxl.job.admin.core.conf.XxlJobAdminConfig(spring的對象)
/*** 這個是InitializingBean 實現方式,主要是為了初始化的相關類* @throws Exception*/@Overridepublic void afterPropertiesSet() throws Exception {logger.info(">>>>>>>>>>> xxl-job config init.");adminConfig = this;xxlJobScheduler = new XxlJobScheduler();xxlJobScheduler.init();logger.info(">>>>>>>>>>> xxl-job admin config init end.");}com.xxl.job.admin.core.scheduler.XxlJobScheduler
public void init() throws Exception {logger.info(">>>>>>>>> init xxl-job admin start.");// init i18ninitI18n();// admin registry monitor runJobRegistryMonitorHelper.getInstance().start();// admin fail-monitor runJobFailMonitorHelper.getInstance().start();// admin lose-monitor runJobLosedMonitorHelper.getInstance().start();// admin trigger pool startJobTriggerPoolHelper.toStart();// admin log report startJobLogReportHelper.getInstance().start();// start-scheduleJobScheduleHelper.getInstance().start();logger.info(">>>>>>>>> init xxl-job admin success.");}com.xxl.job.admin.core.scheduler.XxlJobScheduler
public void init() throws Exception {logger.info(">>>>>>>>> init xxl-job admin start.");// init i18ninitI18n();// 執行器注冊監控JobRegistryMonitorHelper.getInstance().start();// 任務失敗重試監控。JobFailMonitorHelper.getInstance().start();// 任務丟失檢測。JobLosedMonitorHelper.getInstance().start();// 初始化任務觸發線程池。JobTriggerPoolHelper.toStart();// 日志統計報表線程。JobLogReportHelper.getInstance().start();// 定時任務調度線程。JobScheduleHelper.getInstance().start();logger.info(">>>>>>>>> init xxl-job admin success.");}7.4. ? JobRegistryMonitorHelper
com.xxl.job.admin.core.thread.JobRegistryMonitorHelper
作用:監控執行器的注冊情況(執行器注冊、心跳維持、自動清理失效節點)
實現原理:
- 后臺線程每 30 秒掃描注冊表(
xxl_job_registry) - 清理超過心跳間隔(
DEAD_TIMEOUT)的死節點 - 類似心跳檢測機制
核心方法:
registryMonitorThread = new Thread(() -> {while (!toStop) {// 查找超時的執行器注冊記錄并刪除}
});7.5. ? JobFailMonitorHelper
- 作用:監控失敗任務,處理失敗重試邏輯
- 實現原理:
-
- 掃描日志表(
xxl_job_log)中失敗但尚未處理的任務 - 根據任務配置是否允許失敗重試
- 重新觸發任務執行
- 掃描日志表(
- 核心邏輯:
while (!toStop) {List<XxlJobLog> failLogList = xxlJobLogDao.findFailJobLog(1000);for (...) {// 調用 JobTrigger.trigger() 重新調度任務}
}7.6. ?JobLosedMonitorHelper
作用:監控被調度中心“調度成功”但未在執行器端實際執行的“丟失任務”
實現原理:
- 根據時間窗口判斷是否有任務在應執行時間后一直未開始執行
- 多用于處理網絡延遲、執行器崩潰等特殊場景
核心邏輯:
while (!toStop) {List<XxlJobInfo> list = jobInfoDao.findLosedJobList(...);// 調用 trigger 補償執行
}7.7. 🚀 JobTriggerPoolHelper
作用:任務調度線程池,處理 JobTrigger 調用產生的異步任務觸發請求
實現原理:
- 包含 fast/slow 兩種線程池
-
- fast:用于頻繁/輕量級觸發
- slow:用于耗時較長或批量觸發
- 使用
ThreadPoolExecutor管理觸發請求
核心代碼:
static ThreadPoolExecutor fastTriggerPool = new ThreadPoolExecutor(...);
static ThreadPoolExecutor slowTriggerPool = new ThreadPoolExecutor(...);7.7.1. 📊 JobLogReportHelper
- 作用:定時統計任務執行日志(成功/失敗數等),用于報表展示
- 實現原理:
-
- 每小時統計一次執行情況,寫入報表表(
xxl_job_log_report)
- 每小時統計一次執行情況,寫入報表表(
- 核心方法:
for (int i = 0; i < 24; i++) {Date from = ..., to = ...;int runningCount = ..., successCount = ...;logReportDao.save(...);
}7.7.2. 6. ? JobScheduleHelper
- 作用:核心調度線程,按照 cron 表達式周期性觸發任務
- 實現原理:
-
- 輪詢所有的調度任務,根據 cron 時間判斷是否應觸發
- 精度通常為秒
- 是調度中心的“大腦”
- 核心邏輯:
while (!scheduleThreadToStop) {List<XxlJobInfo> jobInfoList = jobInfoDao.scheduleJobQuery(...);for (...) {// 計算 cron,觸發執行器JobTrigger.trigger(...);}
}8. XXL-JOB 任務狀態類型
在 XXL-JOB 中,任務的狀態并不是簡單的“完成”和“結束”兩種狀態碼,而是通過日志表(xxl_job_log)中的幾個字段來間接描述任務狀態的。嚴格來說沒有統一的任務“狀態枚舉”,而是通過執行日志狀態組合判斷任務狀態。
8.1. ? 實際的任務狀態判斷依賴字段
表:xxl_job_log主要字段如下:
| 字段名 | 類型 | 含義 |
|
| int | 調度是否成功(200 表示成功) |
|
| int | 執行器執行是否成功(200 表示成功) |
|
| string | 調度日志 |
|
| string | 執行器處理日志 |
8.2. 🔍 狀態碼定義(ReturnT)
8.2.1. trigger_code
- 定義在調度中心,表示調度請求是否成功(如調度器能否找到執行器并發出任務)
- 狀態碼說明:
-
200:調度成功- 其他:調度失敗(如路由失敗、注冊失敗)
8.2.2. handle_code
- 由執行器返回,表示任務實際運行的結果
- 狀態碼說明:
-
200:執行成功- 其他:執行失敗
-
-
- 如代碼異常、邏輯失敗等
-
這些狀態碼是通過 ReturnT 類統一表示的:
public class ReturnT<T> {public static final int SUCCESS_CODE = 200;public static final int FAIL_CODE = 500;private int code;private String msg;private T content;
}8.3. 💡 狀態組合的實際含義示例
| trigger_code | handle_code | 狀態解釋 |
| 200 | null | 調度成功,但執行器還未返回(執行中) |
| 200 | 200 | 執行成功 ? |
| 200 | 500 | 調度成功,執行失敗 ? |
| 500 | null | 調度失敗(如路由不到執行器) ? |
| null | null | 尚未調度(如未來定時執行) ? |
8.4. ?中間狀態有嗎?
雖然 XXL-JOB 沒有像“運行中”、“等待中”這樣的狀態字段,但你可以通過以下方式判斷中間態:
8.4.1. ? 判斷是否運行中
SELECT * FROM xxl_job_log
WHERE trigger_code = 200 AND handle_code IS NULL;說明:任務已調度,執行器未返回結果 → 正在運行中。
8.4.2. ? 判斷失敗但可重試
SELECT * FROM xxl_job_log
WHERE handle_code != 200 AND retry_count < retry_limit;說明:可以進入 JobFailMonitorHelper 的重試邏輯。
8.5. 🧠 XXL-JOB 任務狀態總結
- XXL-JOB 沒有統一的“任務狀態枚舉類”,而是依賴
trigger_code和handle_code的組合判斷狀態 - 中間態是隱含存在的,例如執行中狀態是
handle_code = null。 - 所有狀態信息都在
xxl_job_log表中。 - 如果你需要更精確的任務狀態跟蹤,可以自行擴展日志表或構建任務狀態視圖。
9. 守護線程(Daemon Thread)是什么?
9.1. 在 Java 中,線程有兩種類型:
| 類型 | 描述 |
| 用戶線程(User Thread) | 主線程、業務線程等,一般用于完成程序的主要邏輯 |
| 守護線程(Daemon Thread) | 輔助線程,用于服務用戶線程,例如垃圾回收線程、日志線程、調度線程 |
9.2. 🔍 守護線程 vs 用戶線程
- 當所有“用戶線程”都執行完畢時,JVM 會退出運行,不管是否還有守護線程在運行。
- 守護線程是“輔助線程”,JVM 不會等待守護線程執行完畢。
| 對比點 | 用戶線程(User Thread) | 守護線程(Daemon Thread) |
| 是否阻止 JVM 退出 | ? 是(有用戶線程則 JVM 不退出) | ? 否(只剩守護線程時,JVM 退出) |
| 是否獨立運行 | ? 是 | ? 也是(從執行邏輯看是獨立的) |
| 生命周期關系 | JVM 直到所有用戶線程結束才退出 | 所有用戶線程結束后即強制結束守護線程 |
| 典型用途 | 業務邏輯線程,如 HTTP 請求處理 | 輔助性線程,如日志寫入、GC、調度等線程 |
9.3. ? 應用在 XXL-JOB 中的意義:
scheduleThread.setDaemon(true); 說明調度線程是 守護線程,表示:
- 不阻止 JVM 正常退出(避免主線程結束后還因調度線程掛起)
- JVM 在關閉時不會等待調度線程清理或執行完畢。
9.4. ? 在 XXL-JOB 中的作用
XXL-JOB 中的很多后臺線程(如:調度線程、失敗重試線程、日志清理線程等)都被設置為 Daemon,意味著:
- 這些線程是“后臺服務線程”
- 當調度中心關閉(比如 Spring 容器關閉),不會阻止 JVM 退出
如果你希望線程 不被 JVM 自動中止(如需要優雅關閉),可以不設置為守護線程,并在 Spring @PreDestroy 或 DisposableBean.destroy() 中做回收邏輯。
10. 多個XXl-job 服務,任務注冊到了服務A 但是調度到服務B,顯示沒有的對應JobHandler 處理器?
10.1. ? 問題本質
XXL-JOB 默認調度邏輯是:在“執行器組”中的所有機器中隨機選擇一個機器調度執行。所以如果服務 A 注冊了 JobHandler,但服務 B 沒有注冊相應的 JobHandler,而調度卻派發到服務 B —— 任務就會失敗,提示:
com.xxl.job.core.exception.XxlJobException: JobHandler not found10.2. 🔥 場景復現流程
假設:
- 服務 A:注冊了 JobHandler
testJob - 服務 B:沒有
testJob,但同屬于執行器組default - 管理后臺的任務綁定了執行器組
default,沒有綁定指定執行器地址 - 調度系統從
default組中隨機挑選執行器地址時選中了 B
💥 于是任務派發到 B,找不到 testJob,就報錯了!
10.2.1. ? 方式一:為每個 JobHandler 精準綁定執行器地址(推薦)
在 XXL-JOB 管理后臺:
- 進入任務編輯頁
- 找到“執行器地址類型”,選擇:手動輸入地址
- 指定部署了該
JobHandler的服務實例地址,例如:
http://10.0.0.101:9999- 保存
這樣調度器就不會再隨機分配,而是只發給這個地址。
10.2.2. ? 方式二:按業務拆分執行器組
舉例:
- 服務 A 的執行器注冊為組
group-a - 服務 B 的執行器注冊為組
group-b
然后:
testJob任務配置為綁定group-a執行器組testJob2綁定group-b
?? 注冊執行器時需配置 appname,例如:
xxl:job:executor:appname: group-a # 服務 A10.2.3. ? 方式三:所有服務都部署同樣的 JobHandler
將所有任務的 @XxlJob 方法統一打包到一個公共模塊中,每個服務都引入它 —— 保證每個服務都有相同 JobHandler。?? 不推薦。雖然能解決問題,但會導致服務臃腫、維護成本高,且不符合職責分離原則。
10.3. 🚫 常見錯誤用法
- ? 僅配置執行器組,不綁定具體地址
- ? 不同服務部署不同 JobHandler,卻共用一個執行器組
- ? 開啟自動注冊,但未合理管理服務。
11. XXL-job 注冊 IP 獲取與任務調度目標 IP 的綁定控制
在 XXL-JOB 中,任務注冊默認不會返回注冊的 IP 地址,但你可以通過以下幾種方式實現注冊 IP 獲取與任務調度目標 IP 的綁定控制,從而達到你想要的“制定任務執行時候 IP”的目標。
11.1. 任務注冊返回注冊 IP(執行器 IP)
11.1.1. 背景:
執行器(Executor)在啟動時會向 XXL-JOB 調度中心進行注冊,注冊的地址是:
xxl-job.executor.address如果你沒有手動指定,它會自動通過網絡接口獲取本機 IP + 端口注冊到調度中心。
11.1.2. ? 如何獲取注冊的 IP 地址?
注冊信息會出現在調度中心 Admin 中:
- 打開 XXL-JOB 管理后臺 → 執行器管理 → 某執行器 AppName → 查看注冊地址列表
- 顯示的是注冊上來的機器地址(IP:PORT)
這些地址信息被保存在調度中心的內存注冊表中,并作為調度路由時的可選地址池。
11.2. ? 如何指定任務調度到某個注冊 IP(機器)
你可以通過以下方式指定任務執行時調度到哪個 IP:
11.2.1. ? 方法一:手動注冊執行器地址(強綁定 IP)
在“執行器管理”中設置注冊方式為:
- 注冊方式:手動錄入機器地址
- 地址列表只填你希望綁定的機器 IP,如:
http://192.168.1.101:9999這樣,任務只會調度到該地址,不會被路由到其他注冊執行器。
11.2.2. ? 方法二:使用路由策略“指定機器”進行 IP 定向
如果注冊方式為自動發現(自動注冊),你仍可以:
- 任務配置時,選擇路由策略為:
指定機器(Routing: Specific Machine)- 調度時,調用 Admin 接口觸發任務時,傳入目標機器地址,例如:
JobTriggerPoolHelper.trigger(jobId,TriggerTypeEnum.MANUAL,-1,null,"http://192.168.1.101:9999", // 指定目標地址null
);這會強制任務發送到你指定的那臺機器(即那個注冊 IP)。
11.3. 🔧 附加:自動注冊時修改 IP 注冊行為
如果你想控制執行器注冊時的 IP 或端口,可以配置以下屬性:
xxl.job.executor.ip=192.168.1.101
xxl.job.executor.port=9999還可以通過 SPI 或代碼實現方式自定義注冊行為。
11.4. 📌 總結
| 目標 | 方法 |
| 獲取執行器注冊的 IP | 后臺執行器管理中可查看 |
| 控制任務調度到某臺 IP | 使用“手動地址注冊”或“指定機器”路由策略 |
| 自定義注冊 IP 行為 | 設置 |
| 自動注冊查看 IP 列表 | 調度中心內存緩存中維護,可查看或打印日志調試 |
博文參考
- 分布式任務調度平臺XXL-JOB

的操作指南)





)






)




