特征圖與注意力熱圖
知識點回顧:
- 不同CNN層的特征圖:不同通道的特征圖
- 通道注意力后的特征圖和熱力圖
特征圖本質就是不同的卷積核的輸出,淺層指的是離輸入圖近的卷積層,淺層卷積層的特征圖通常較大,而深層特征圖會經過多次下采樣,尺寸顯著縮小,尺寸差異過大時,小尺寸特征圖在視覺上會顯得模糊或丟失細節。步驟邏輯如下:
1. 初始化設置:
- 將模型設為評估模式,準備類別名稱列表
2.數據加載與處理:
- 從測試數據加載器中獲取圖像和標簽
- 限制處理量以避免冗余,僅處理前 `num_images` 張圖像(如2張)
3. 注冊鉤子捕獲特征圖:
- 為指定層(如 `conv1`, `conv2`, `conv3`)注冊前向鉤子
- 鉤子函數將這些層的輸出(特征圖)保存到字典中(以層名為鍵,特征圖(Tensor)為值)
4. 前向傳播與特征提取:
- 模型處理圖像,觸發鉤子函數,獲取并保存特征圖
- 移除鉤子,避免后續干擾
5. 可視化特征圖:對每張圖像
- 恢復原始像素值并顯示(反標準化)
- 為每個目標層創建子圖,展示前 `num_channels` 個通道的特征圖(每個通道的特征圖是單通道灰度圖,需獨立顯示)
- 每個通道的特征圖以網格形式排列,顯示通道編號
def visualize_feature_maps(model, test_loader, device, layer_names, num_images=3, num_channels=9):"""可視化指定層的特征圖(修復循環冗余問題)參數:model: 模型test_loader: 測試數據加載器layer_names: 要可視化的層名稱(如['conv1', 'conv2', 'conv3'])num_images: 可視化的圖像總數num_channels: 每個圖像顯示的通道數(取前num_channels個通道)"""model.eval() # 設置為評估模式class_names = ['飛機', '汽車', '鳥', '貓', '鹿', '狗', '青蛙', '馬', '船', '卡車']# 從測試集加載器中提取指定數量的圖像(避免嵌套循環)images_list, labels_list = [], []for images, labels in test_loader:images_list.append(images)labels_list.append(labels)if len(images_list) * test_loader.batch_size >= num_images:break# 拼接并截取到目標數量images = torch.cat(images_list, dim=0)[:num_images].to(device) # torch.cat拼接多個batch的數據labels = torch.cat(labels_list, dim=0)[:num_images].to(device)with torch.no_grad():# 存儲各層特征圖feature_maps = {}# 保存鉤子句柄hooks = []# 定義鉤子函數,捕獲指定層的輸出def hook(module, input, output, name):feature_maps[name] = output.cpu() # 保存特征圖到字典,保存到CPU,避免GPU內存占用# 為每個目標層注冊鉤子,并保存鉤子句柄for name in layer_names:module = getattr(model, name) # 根據層名獲取模塊hook_handle = module.register_forward_hook(lambda m, i, o, n=name: hook(m, i, o, n)) # 綁定層名到鉤子hooks.append(hook_handle)# 前向傳播觸發鉤子_ = model(images)# 正確移除鉤子for hook_handle in hooks:hook_handle.remove()# 可視化每個圖像的各層特征圖(僅一層循環)for img_idx in range(num_images):img = images[img_idx].cpu().permute(1, 2, 0).numpy() # [C,H,W]→[H,W,C]# 反標準化處理(恢復原始像素值)img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1) # 確保像素值在[0,1]范圍內# 創建子圖num_layers = len(layer_names)fig, axes = plt.subplots(1, num_layers + 1, figsize=(4 * (num_layers + 1), 4))# 顯示原始圖像axes[0].imshow(img)axes[0].set_title(f'原始圖像\n類別: {class_names[labels[img_idx]]}')axes[0].axis('off')# 顯示各層特征圖for layer_idx, layer_name in enumerate(layer_names):fm = feature_maps[layer_name][img_idx] # 取第img_idx張圖像的特征圖fm = fm[:num_channels] # 僅取前num_channels個通道num_rows = int(np.sqrt(num_channels)) # 計算網格行數num_cols = num_channels // num_rows if num_rows != 0 else 1 # 計算網格列數# 創建子圖網格layer_ax = axes[layer_idx + 1]layer_ax.set_title(f'{layer_name}特征圖 \n')# 加個換行讓文字分離上去layer_ax.axis('off') # 關閉大子圖的坐標軸# 在大子圖內創建小網格for ch_idx, channel in enumerate(fm):ax = layer_ax.inset_axes([ch_idx % num_cols / num_cols, (num_rows - 1 - ch_idx // num_cols) / num_rows, 1/num_cols, 1/num_rows])ax.imshow(channel.numpy(), cmap='viridis')ax.set_title(f'通道 {ch_idx + 1}')ax.axis('off')plt.tight_layout()plt.show()# 調用示例(按需修改參數)
layer_names = ['conv1', 'conv2', 'conv3']
visualize_feature_maps(model=model,test_loader=test_loader,device=device,layer_names=layer_names,num_images=5, # 可視化5張測試圖像 → 輸出5張大圖num_channels=9 # 每張圖像顯示前9個通道的特征圖
)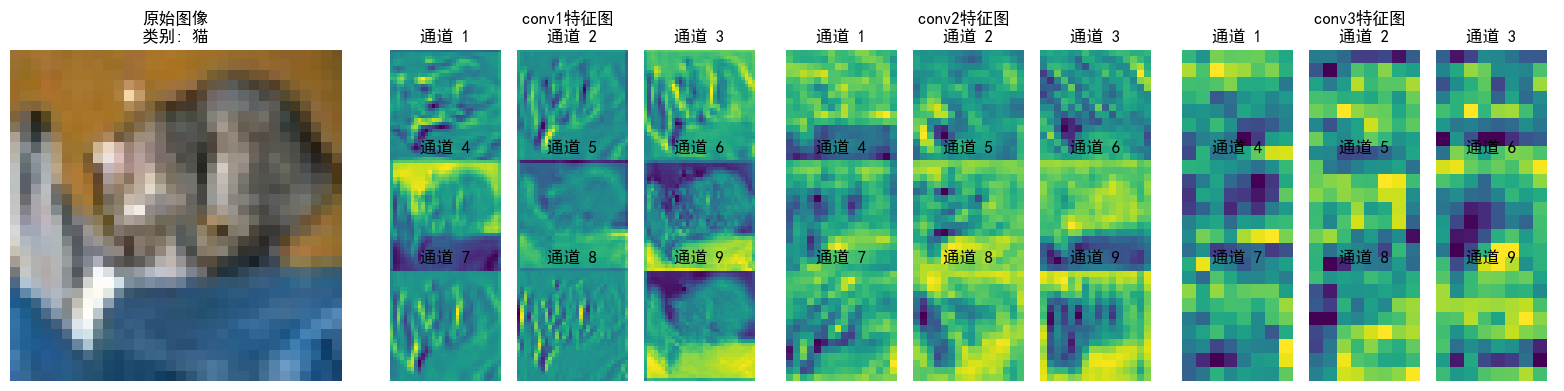
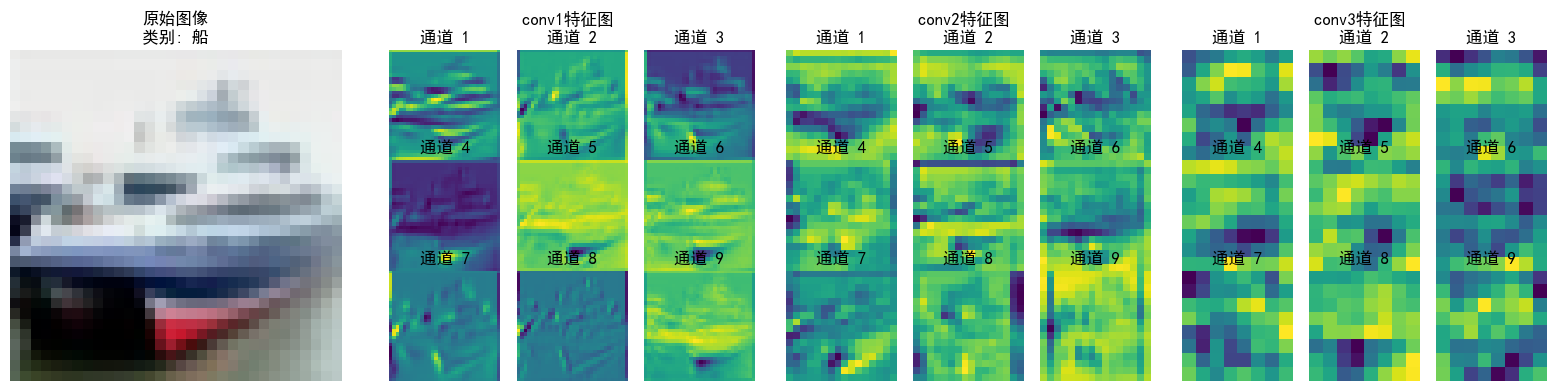
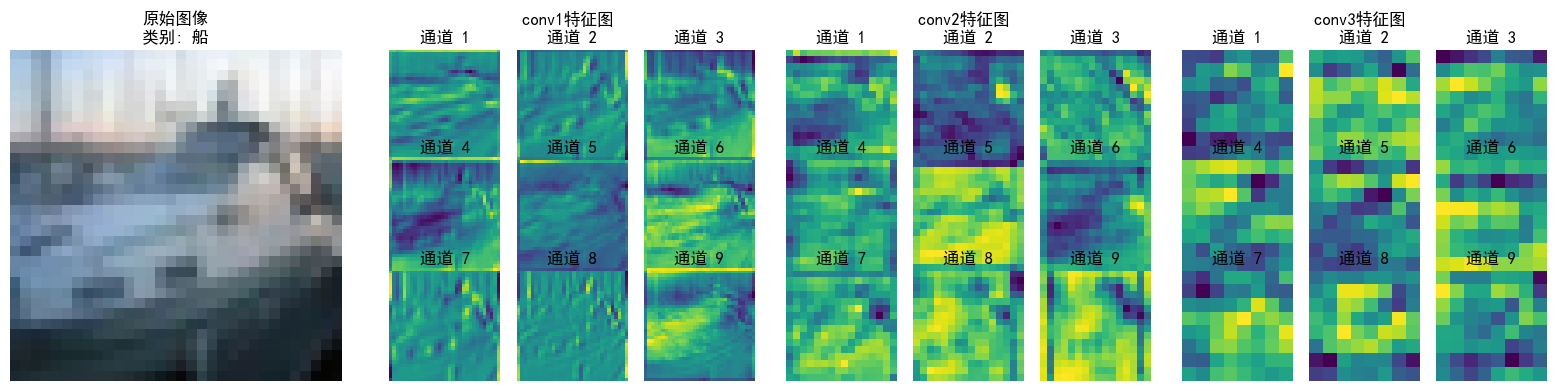
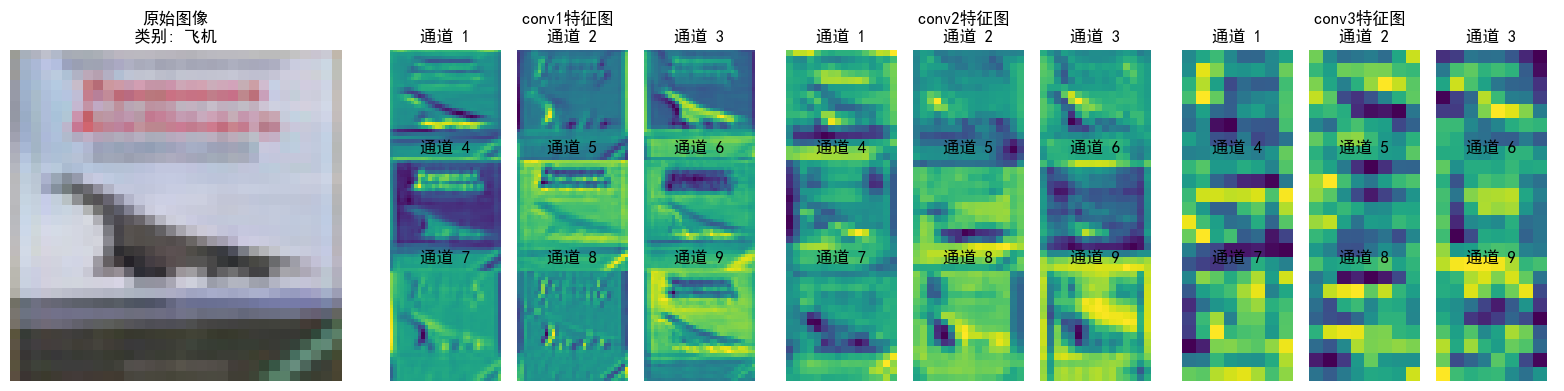
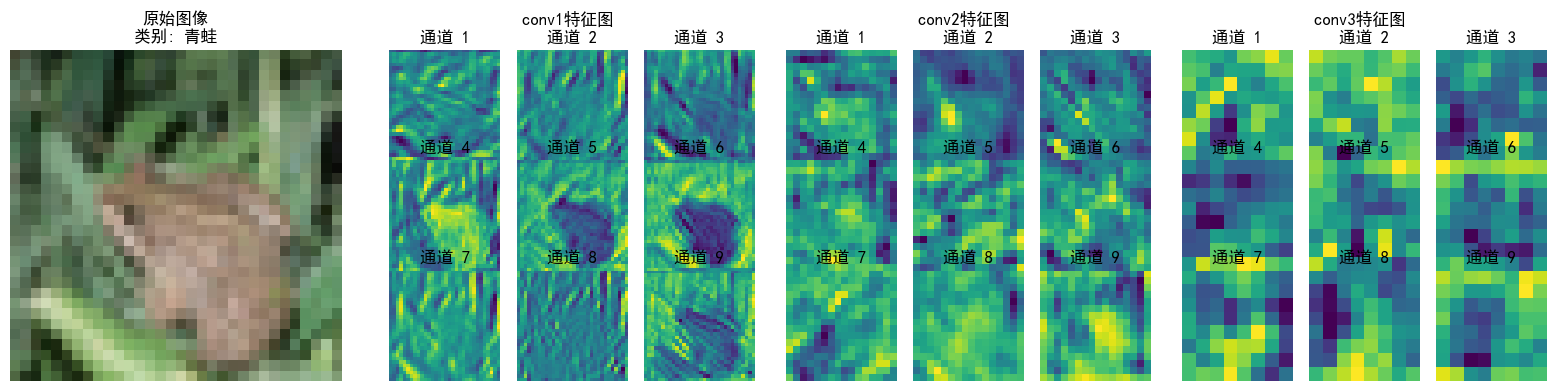
可以看到特征逐層抽象,從“看得見的細節”(conv1)→ “局部結構”(conv2)→ “類別相關的抽象模式”(conv3),模型通過這種方式實現從“看圖像”到“理解語義”的跨越;并且每層各個通道也聚焦了不同特征(如通道1檢測邊緣輪廓,通道2檢測紋理細節...),共同協作完成分類任務

?分別針對不同層次的模型理解需求的三種主流的神經網絡可視化方法,就差注意力熱圖沒學了,一般用于檢查注意力模塊是否聚焦與任務相關的關鍵通道或者空間,具體來說:
-
通道注意力熱圖:展示不同通道的權重分布,例如,在圖像分類任務中,模型可能會對包含目標物體的通道賦予更高的注意力權重
-
空間注意力熱圖:展示輸入圖像中不同空間位置的權重分布,例如,在目標檢測或圖像分類任務中,模型可能會對目標物體所在的區域分配更高的注意力權重
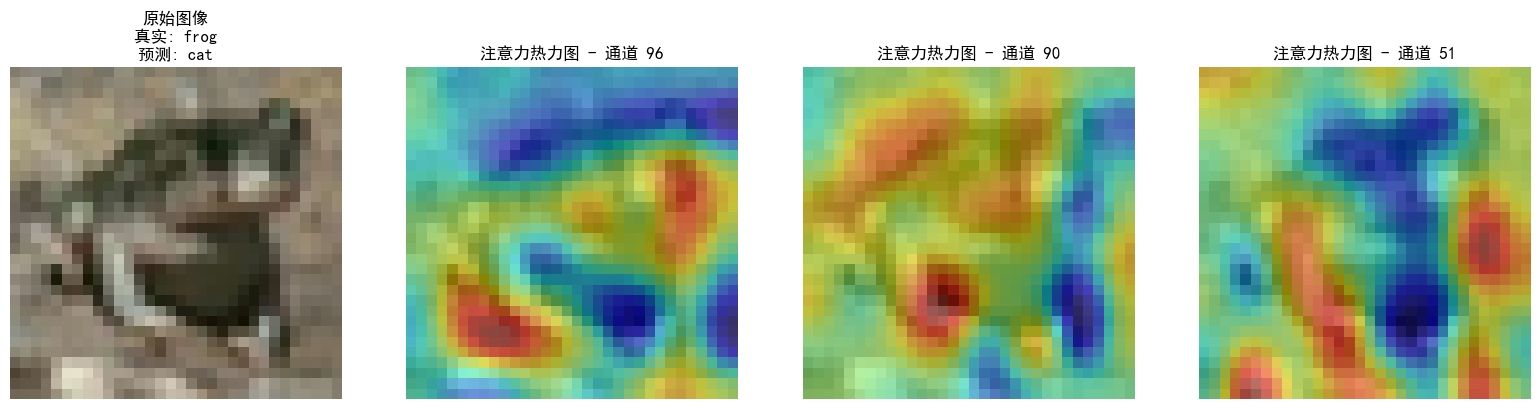
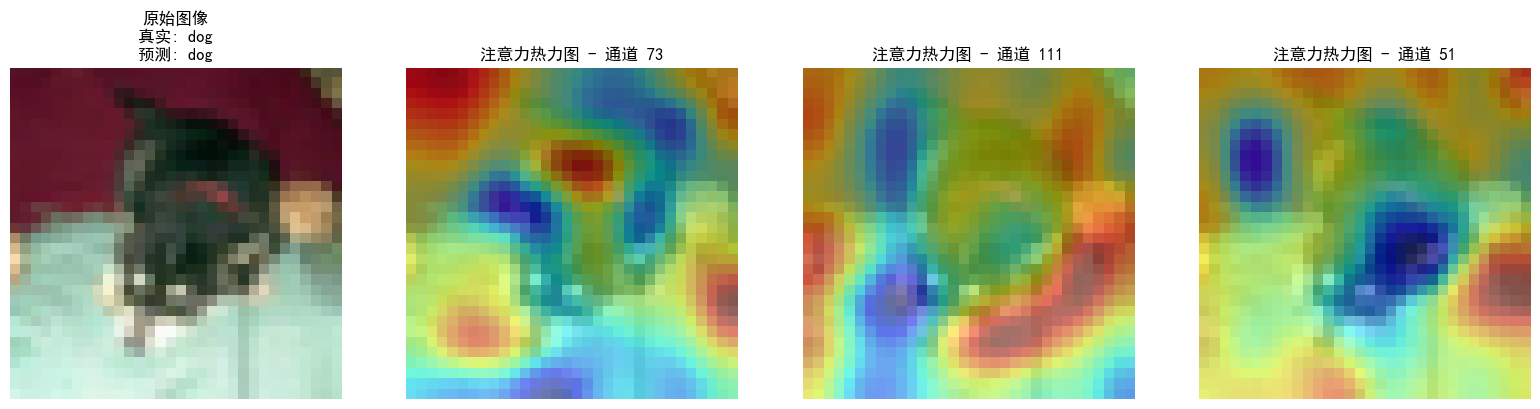
注意力熱圖的步驟和特征圖差不多,就是注意一下鉤子注冊位置僅在最后一個卷積層,就用昨天加入了通道注意力模塊的cnn模型訓練的結果來可視化
# 可視化空間注意力熱力圖(顯示模型關注的圖像區域)
def visualize_attention_map(model, test_loader, device, class_names, num_samples=3):"""可視化模型的注意力熱力圖,展示模型關注的圖像區域"""model.eval() # 設置為評估模式with torch.no_grad():for i, (images, labels) in enumerate(test_loader):if i >= num_samples: # 只可視化前幾個樣本breakimages, labels = images.to(device), labels.to(device)# 創建一個鉤子,捕獲中間特征圖activation_maps = []def hook(module, input, output):activation_maps.append(output.cpu())# 為最后一個卷積層注冊鉤子(獲取特征圖)hook_handle = model.conv3.register_forward_hook(hook)# 前向傳播,觸發鉤子outputs = model(images)# 移除鉤子hook_handle.remove()# 獲取預測結果_, predicted = torch.max(outputs, 1)# 獲取原始圖像img = images[0].cpu().permute(1, 2, 0).numpy()# 反標準化處理img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1)# 獲取激活圖(最后一個卷積層的輸出)feature_map = activation_maps[0][0].cpu() # 取第一個樣本# 計算通道注意力權重(使用SE模塊的全局平均池化)channel_weights = torch.mean(feature_map, dim=(1, 2)) # [C]# 按權重對通道排序sorted_indices = torch.argsort(channel_weights, descending=True)# 創建子圖fig, axes = plt.subplots(1, 4, figsize=(16, 4))# 顯示原始圖像axes[0].imshow(img)axes[0].set_title(f'原始圖像\n真實: {class_names[labels[0]]}\n預測: {class_names[predicted[0]]}')axes[0].axis('off')# 顯示前3個最活躍通道的熱力圖for j in range(3):channel_idx = sorted_indices[j]# 獲取對應通道的特征圖channel_map = feature_map[channel_idx].numpy()# 歸一化到[0,1]channel_map = (channel_map - channel_map.min()) / (channel_map.max() - channel_map.min() + 1e-8)# 調整熱力圖大小以匹配原始圖像from scipy.ndimage import zoomheatmap = zoom(channel_map, (32/feature_map.shape[1], 32/feature_map.shape[2]))# 顯示熱力圖axes[j+1].imshow(img)axes[j+1].imshow(heatmap, alpha=0.5, cmap='jet')axes[j+1].set_title(f'注意力熱力圖 - 通道 {channel_idx}')axes[j+1].axis('off')plt.tight_layout()plt.show()# 調用可視化函數
visualize_attention_map(model, test_loader, device, class_names, num_samples=3)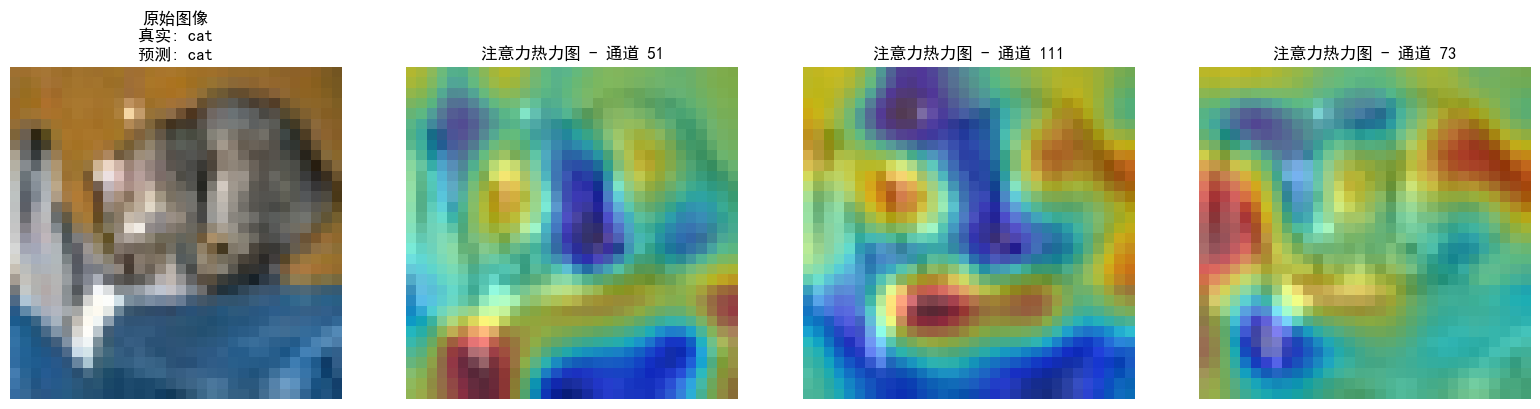
關于全局平均池化?torch.mean?vs nn.AdaptiveAvgPool2d 兩種方法其實功能上完全等價,只不過前者是直接操作張量的函數,更適合后處理;后者適合神經網絡。再明確一點,假設輸入特征圖[C, H, W]:
torch.mean(dim=(1, 2))?→ 輸出?[C](每個通道的標量均值)nn.AdaptiveAvgPool2d(1)?→ 輸出?[C, 1, 1](可通過?squeeze()?轉為?[C],所以這里直接注冊鉤子捕獲這一層輸出得到通道權重也行)
當前代碼的熱力圖是單通道特征圖的歸一化激活強度,再疊加到原圖上,并不是嚴格意義上的注意力熱圖,嚴謹一點的話應該用sigmoid后的通道權重來畫直方圖
@浙大疏錦行



)






)






)

Step-Back 回答回退策略擴大檢索范圍)