
文章目錄
- Abstract
- Introduction
- Related Work
- Vector Graphics Recognition
- Panoptic Symbol Spotting
- Point Cloud Segmentation
- Method
- From Symbol to Points
- Primitive position
- Primitive feature
- Panoptic Symbol Spotting via Point-based Representation
- Backbone
- Symbol Spotting Head
- Attention with Connection Module
- Contrastive Connection Learning
- KNN Interpolation
- Training and Inference
- Experiments
- Experimental Setting
- Dataset and Metrics
- Implementation Details
- Benchmark Results
- Semantic symbol spotting
- Instance Symbol Spotting
- Panoptic Symbol Spotting
- Ablation Studies
- Effects of Techniques
- KNN Interpolation
- Architecture Design
- Conclusion and Future Work
paper
code
Abstract
本文研究的是全光學符號識別問題,即從計算機輔助設計(CAD)圖紙中識別和解析可計數物體實例(窗戶、門、桌子等)和不可計數物體(墻壁、欄桿等)。現有的方法通常包括將矢量圖形光柵化成圖像并使用基于圖像的方法進行符號識別,或者直接構建圖形并使用圖形神經網絡進行符號識別。在本文中,我們采用了一種不同的方法,將圖形原語視為一組局部連接的2D點,并使用點云分割方法來處理它。具體來說,我們利用一個點轉換器來提取原始特征,并附加一個類似于mask2former的點陣頭來預測最終輸出。為了更好地利用原語的局部連接信息,增強原語的可分辨性,我們進一步提出了連接模塊關注(ACM)和對比連接學習方案(CCL)。最后,我們提出了一種KNN插值機制,用于點狀頭的mask注意模塊,以更好地處理原始mask下采樣,這與圖像的像素級相比是原始級的。我們的方法名為SymPoint,簡單而有效,在FloorPlanCAD數據集上,其PQ和RQ的絕對增幅分別為9.6%和10.4%,優于最近最先進的GAT-CADNet方法。
Introduction
矢量圖形(VG)以其任意縮放的能力而聞名,而不會屈服于諸如模糊或細節混疊之類的問題,已成為工業設計中的主要內容。這包括它們在平面設計(Reddy et al., 2021)、2D界面(Carlier et al., 2020)和計算機輔助設計(CAD)(Fan et al., 2021)中的普遍使用。具體地說,CAD繪圖,由幾何原語(例如:(如弧、圓、折線等),已成為室內設計、室內建筑和房地產開發領域的首選數據表示方法,推動了這些領域更高的精度和創新標準。
符號識別(Rezvanifar et al., 2019;2020年;Fan等,2021;2022年;Zheng et al., 2022)是指從CAD圖紙中發現和識別符號,這是檢查設計圖紙和3D建筑信息建模(BIM)錯誤的基礎任務。由于存在諸如遮擋、聚類、外觀變化以及不同類別分布的顯著不平衡等障礙,在CAD繪圖中發現每個符號(一組圖形原語)是一項重大挑戰。傳統的符號識別通常處理代表可數事物的實例符號(Rezvanifar等人,2019),如桌子、沙發和床。Fan等人(2021)進一步將其擴展到全視符號識別,既可以識別可數實例(例如,一扇門、一扇窗、一張桌子等),也可以識別不可數物體(例如,墻、欄桿等)。
典型方法(Fan et al., 2021;2022)解決全光符號識別任務涉及首先將CAD圖紙轉換為光柵圖形(RG),然后使用強大的基于圖像的檢測或分割方法對其進行處理(Ren et al., 2015;Sun等人,2019)。另一行先前的作品(Jiang et al., 2021;鄭等,2022;Yang等人,2023)放棄柵格過程,直接處理矢量圖形,使用圖卷積網絡進行識別。代替將CAD繪圖光柵化到圖像或用GCN/GAT對圖形原語建模,這在計算上可能是昂貴的,特別是對于大型CAD圖形,我們提出了一個新的范例,它有可能產生新的見解,而不僅僅是在性能上提供增量進步。
通過對CAD圖紙數據特征的分析,我們可以發現CAD圖紙有三個主要特性:1)不規則性和無序性。與光柵圖形/圖像中的常規像素數組不同,CAD繪圖由幾何原語(例如:(圓弧、圓、折線等),沒有特定的順序。2).圖形基元之間的局部交互。每個圖形原語不是孤立的,而是與鄰近的原語局部相連,形成一個符號。3)變換下的不變性。每個符號對于某些變換都是不變的。例如,旋轉和翻譯符號不會改變符號的類別。這些屬性幾乎與點云相同。因此,我們將CAD繪圖視為點集(圖形原語),并利用點云分析的方法(Qi等人,2017a;b;Zhao et al., 2021)用于符號識別。
在這項工作中,我們首先將每個圖形原語視為具有位置和原語屬性(類型,長度等)信息的8維數據點。然后,我們利用點云分析的方法進行圖形原語表示學習。與點云不同,這些圖形原語是局部連接的。因此,我們提出了對比連接學習機制來利用這些局部連接。最后,我們借用了Mask2Former(Cheng et al., 2021;2022),并構建一個mask注意轉換器解碼器來執行全光符號識別任務。此外,不像(Cheng et al., 2022)那樣使用雙線性插值進行mask注意力降采樣,由于圖形基元的稀疏性可能導致信息丟失,我們提出了KNN插值,它融合了最近的相鄰基元,用于mask注意力降采樣。我們在FloorPlanCAD數據集上進行了廣泛的實驗,我們的SymPoint在全光符號識別設置下實現了83.3%的PQ和91.1%的RQ,大大優于最近最先進的GAT-CADNet方法(Zheng et al., 2022)。
Related Work
Vector Graphics Recognition
矢量圖形廣泛應用于二維CAD設計、城市設計、平面設計、電路設計等領域,便于實現無分辨率的高精度幾何建模。考慮到矢量圖的廣泛應用和重要性,許多工作致力于矢量圖的識別任務。Jiang等人(2021)探索了矢量化目標檢測,并取得了優于檢測方法的精度(Bochkovskiy等人,2020;Lin等人,2017)在柵格圖形上工作,同時享受更快的推理時間和更少的訓練參數。Shi等人(2022)提出了一個統一的矢量圖形識別框架,該框架利用了矢量圖形和光柵圖形的優點。
Panoptic Symbol Spotting
傳統的符號識別通常處理代表可數事物的實例符號(Rezvanifar等人,2019),如桌子、沙發和床。遵循(Kirillov et al., 2019)的思想,Fan et al.(2021)通過識別不可數事物的語義擴展了定義,并將其命名為panoptic symbol spotting。因此,CAD繪圖中的所有組件都包含在一個任務中。例如,由一組平行線表示的墻被(Fan et al., 2021)處理得很好,但被(Jiang et al., 2021)作為背景處理;Shi et al., 2022;Nguyen et al., 2009)中的矢量圖形識別。同時,(Fan et al., 2021)以矢量圖形的形式發布了第一個大規模的真實世界floorplanad數據集。Fan等人(2022)提出了CADTransformer,它修改了現有的視覺transformer(ViT)主干,用于全光符號識別任務。Zheng等人(2022)提出了GAT-CADNet,它將實例符號識別任務表述為子圖檢測問題,并通過預測鄰接矩陣來解決。
Point Cloud Segmentation
點云分割的目的是將點映射到多個同質組中。點云與二維圖像不同,二維圖像的特征是有序排列的密集像素,而點云是由無序和不規則的點集組成的。這使得直接將圖像處理方法應用于點云分割成為一種不切實際的方法。然而,近年來,神經網絡的集成顯著增強了點云分割在一系列應用中的有效性,包括語義分割(Qi等人,2017a;a;Zhao et al., 2021),實例分割(Ngo et al., 2023;Schult et al., 2023)和全視分割(Zhou et al., 2021;Li et al., 2022;Hong et al., 2021;Xiao et al., 2023)等。
Method
我們的方法放棄了光柵圖像或GCN,而支持圖形原語的基于點的表示。與基于圖像的表示相比,由于原始CAD圖紙的稀疏性,它降低了模型的復雜性。在本節中,我們首先描述如何使用CAD圖紙的圖形原語形成基于點的表示。然后,我們說明了一個基線框架的全光符號定位。最后,我們詳細解釋了三種關鍵技術,即關注局部連接、對比連接學習和KNN插值,以使該基線框架更好地處理CAD數據。
From Symbol to Points
給定由一組圖形基元{pk}表示的矢量圖形,我們將其視為點{pk | (xk , fk)}的集合,每個點都包含基元位置{xk}和基元特征{fk}信息;因此,點集可能是無序和無組織的。
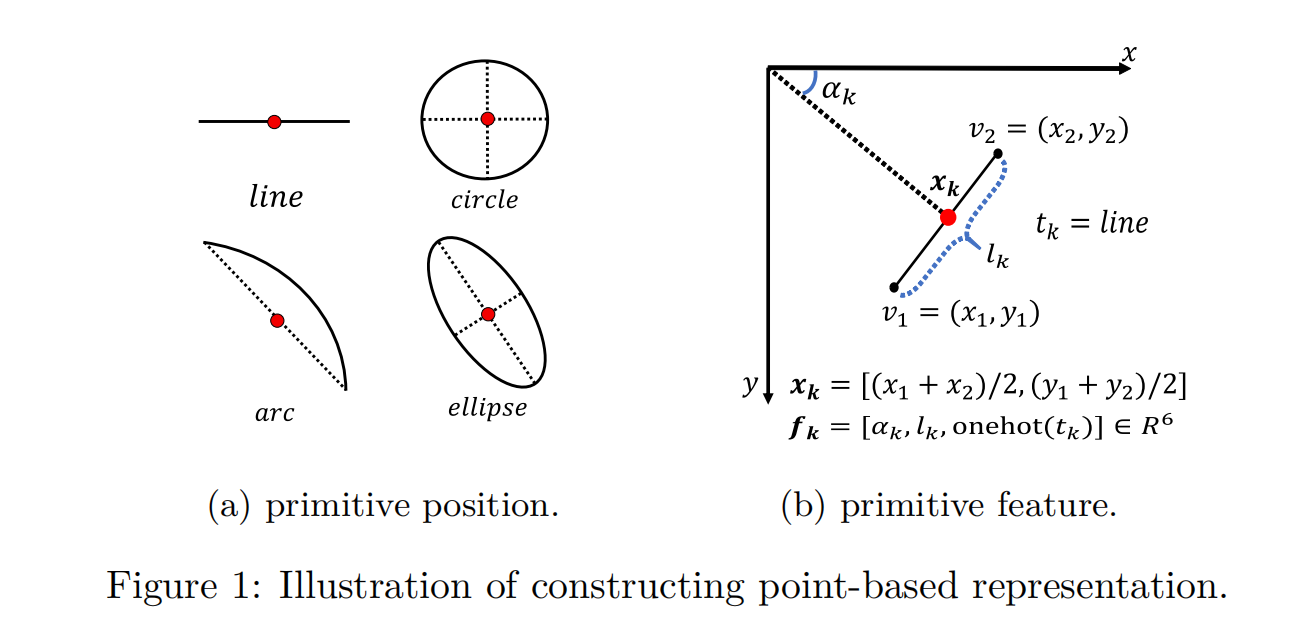
Primitive position
給定一個圖形原語,起點和終點的坐標分別為(x1, y1)和(x1, y2)。原始位置xk∈R2定義為:
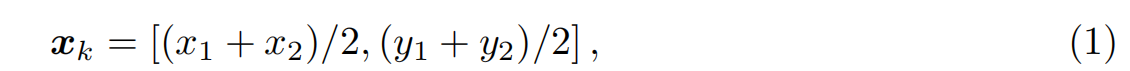
我們把它的中心作為封閉圖形原語(圓、橢圓)的原語位置。如圖1a所示。
Primitive feature
我們定義基元特征fk∈R6為:

其中αk為x正軸到xk的順時針角度,lk為v1到v2的長度,如圖1b所示。我們將原語類型tk(直線、圓弧、圓或橢圓)編碼為一個單熱向量,以彌補段近似的缺失信息。
Panoptic Symbol Spotting via Point-based Representation
基線框架主要由兩個部分組成:主干和符號定位頭。主干將原始點轉換為點特征,而符號識別頭通過可學習查詢預測符號掩碼(Cheng et al., 2021;2022)。圖2展示了整個框架。
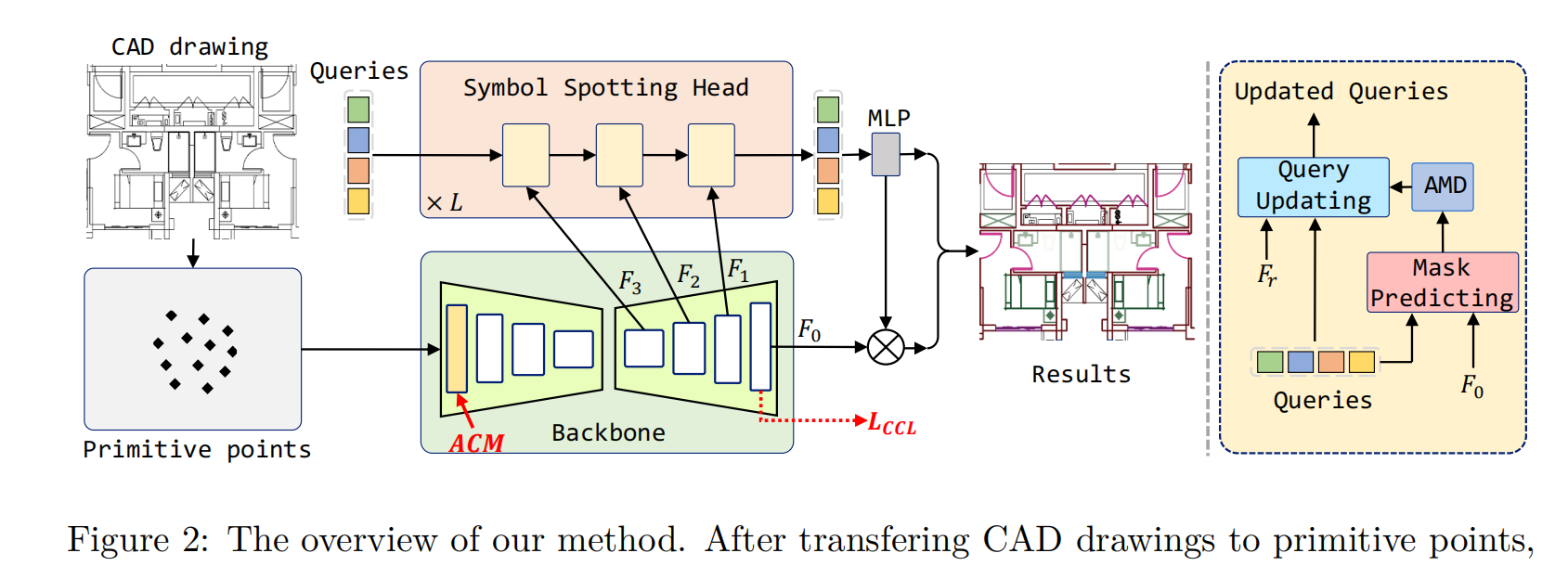
在將CAD圖形轉換為原始點后,我們使用主干提取多分辨率特征Fr,并附加符號識別頭來識別和識別符號。在此過程中,我們提出了連接模塊(ACM)的注意,該模塊在backone的第一階段進行自我注意時利用原始連接信息。隨后,我們提出了對比連接學習(CCL)來增強連接原語特征之間的區分能力。最后,我們提出了KNN插值的注意遮罩下采樣(AMD),以有效地下采樣高分辨率的注意遮罩。
Backbone
我們選擇具有對稱編碼器和解碼器的點transformer(Zhao et al., 2021)作為特征提取的骨干,因為它在全光符號識別方面具有良好的泛化能力。主干以原始點為輸入,在每個點與相鄰點之間進行向量關注,探索局部關系。給定一個點pi和它的鄰點M(pi),我們將它們投影到查詢特征qi、關鍵特征kj和值特征vj中,得到向量關注如下:
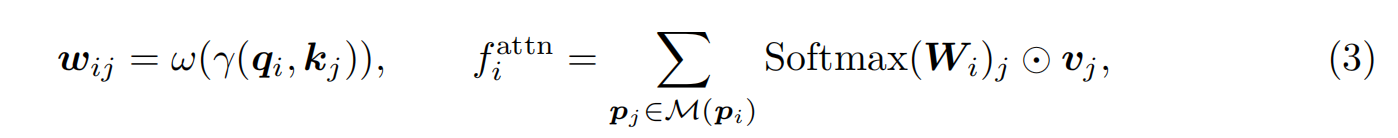
其中γ作為關系函數,例如減法。ω是一種可學習的權重編碼,用于計算注意力向量。⊙是Hadamard積。
Symbol Spotting Head
我們遵循Mask2Former (Cheng et al., 2022),使用來自骨干解碼器的分層多分辨率原語特征Fr∈RNr×D作為符號定位預測頭部的輸入,其中Nr為分辨率r中的特征令牌數,D為特征維數。該頭部由L層被屏蔽的注意力模塊組成,這些模塊逐步從主干中提升低分辨率特征,以產生用于掩碼預測的高分辨率逐像素嵌入。掩碼關注模塊有兩個關鍵組成部分:查詢更新和掩碼預測。對于每一層1,查詢更新涉及到與不同分辨率原語特征Fr交互以更新查詢特征。這個過程可以表示為:
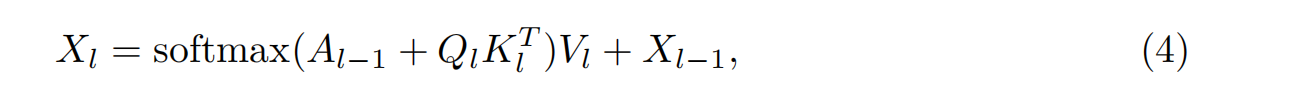
其中Xl∈RO×D為查詢特征。O是查詢特征的數量。Ql = fQ(Xl?1),Kl = fK(Fr)和Vl = fV(Fr)是MLP層投影的查詢、鍵和值特征。Al?1為注意掩碼,計算公式為:
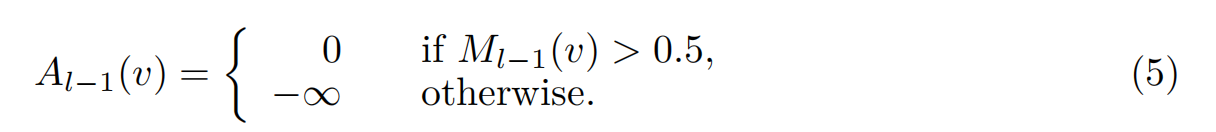
式中,v為特征點位置,Ml?1為掩碼預測部分預測的掩碼。
注意,我們需要對高分辨率的注意力掩碼進行下采樣,以采用對低分辨率特征的查詢更新。在實際應用中,我們利用了主干網解碼器的四個粗級原語特征,并進行了從粗到精的查詢更新。
在掩碼預測過程中,我們使用兩個MLP層fY和fM對查詢特征進行投影,得到對象掩碼Ml∈RO×N0及其對應的類別Yl∈RO×C;其中C為類別編號,N0為點數。流程如下:
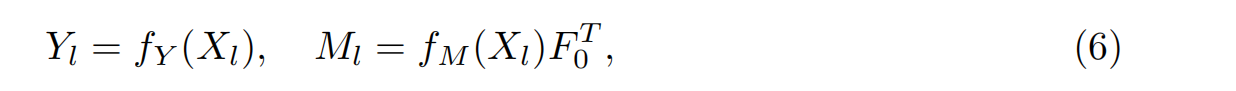
最后一層的輸出YL和ML是預測結果。
Attention with Connection Module
簡單而統一的框架通過提供CAD繪圖的新視角(一組點)來獎勵出色的泛化能力。與以往的方法相比,可以獲得較好的結果。然而,它忽略了CAD圖紙中普遍存在的原始連接。正是由于這些聯系,分散的、不相關的圖形元素才聚集在一起,形成具有特殊語義的符號。為了利用每個原語之間的這些連接,我們提出了注意連接模塊(ACM),詳細信息如下所示。
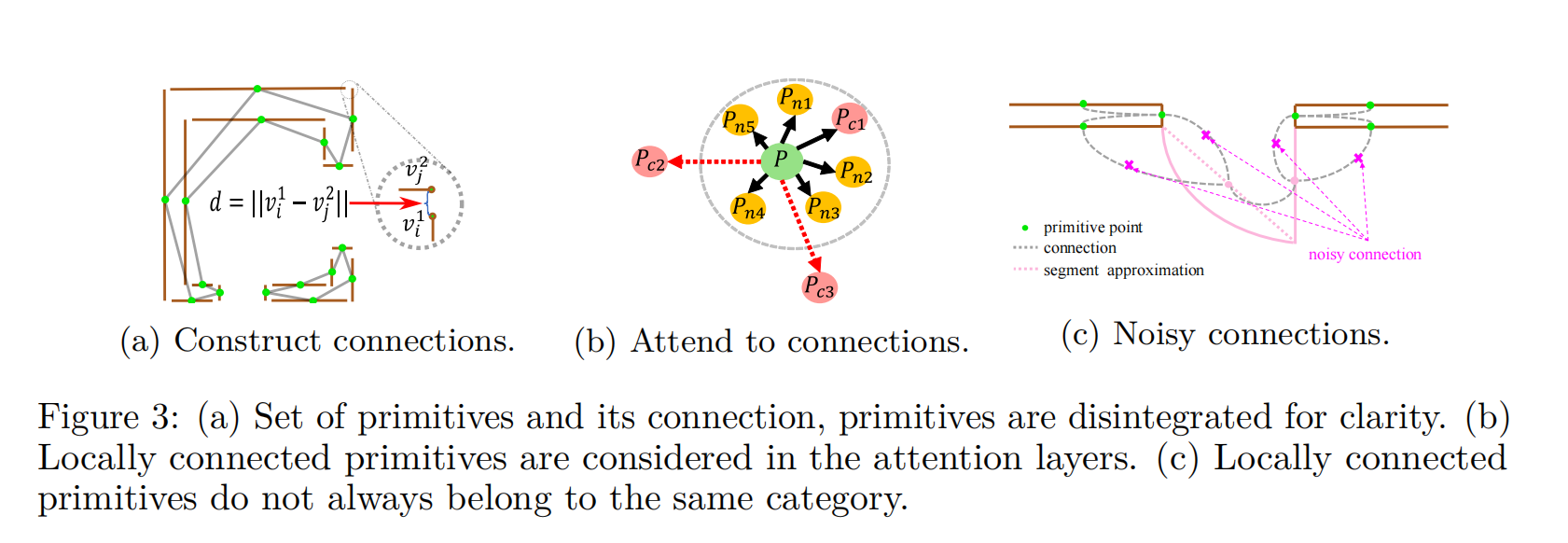
如果兩個圖基元(pi, pj)的端點(vi, vj)之間的最小距離dij低于某一閾值λ,則認為這兩個圖基元(pi, pj)是相互連接的,其中:
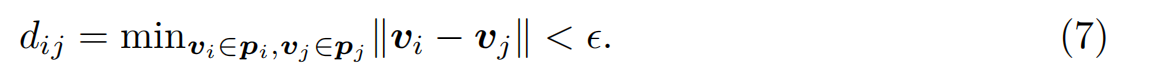
為了保持較低的復雜性,通過隨機刪除,每個圖形原語最多允許K個連接。圖3a展示了圍繞墻符號的連接構造,灰線是兩個原語之間的連接。在實踐中,我們設置為1.0px。(Zhao et al., 2021)中的注意機制直接在每個點與其相鄰點之間進行局部注意,以探索兩者之間的關系。原始注意機制僅與球面區域內相鄰點相互作用,如圖3b所示。我們的ACM還在注意力期間引入了與局部連接的原始點(粉色點)的相互作用,從本質上擴大了球面區域的半徑。請注意,我們通過實驗發現,在不考慮原始點的局部連接的情況下,粗略地增加球面區域的半徑并不能提高性能。這可能是由于感受野的擴大同時也引入了額外的噪音。具體地說,我們將Eq.(3)中的鄰點集M(pi)擴展為A(pi) = M(pi)∪C(pi),其中C(pi) = {pj |dij < λ},得到:
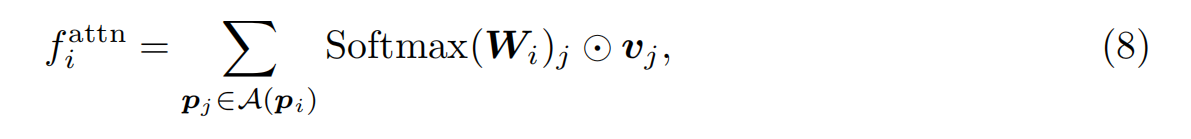
在實際應用中,由于我們無法直接獲得主干網中間層各點的連接關系,所以我們將該模塊集成到主干網的第一階段,以取代原有的局部關注,如圖2所示。
Contrastive Connection Learning
雖然在計算編碼器transformer的注意力時考慮了原語連接的信息,但局部連接的原語可能不屬于同一實例,即在考慮原語連接的同時可能引入噪聲連接,如圖3c所示因此,為了更有效地利用具有類別一致性的連接信息,我們遵循了廣泛使用的InfoNCE損失(Oord等人,2018)及其泛化(frost等人,2019;Gutmann & Hyv?rinen, 2010)定義對主干最終輸出特征的對比學習目標。我們鼓勵學習表征與來自同一類別的連接點更相似,與來自不同類別的其他連接點更不同。此外,我們還考慮了相鄰點M(pi),得到:
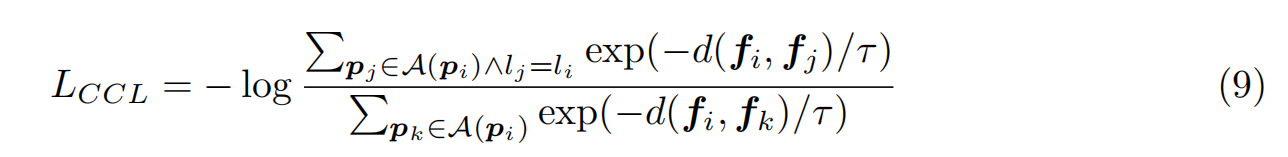
其中fi為pi的主干特征,d(·,·)為距離測量值,τ為對比學習中的溫度。我們默認設置τ = 1。
KNN Interpolation
在符號識別頭Eq.(4)和Eq.(5)的查詢更新過程中,我們需要將高分辨率掩碼預測轉換為低分辨率,進行注意掩碼計算,如圖2所示(右圖為AMD)。Mask2Former (Cheng et al., 2022)在像素級mask上采用雙線性插值進行下采樣。然而,CAD圖紙的mask是原始級的,直接對其進行雙線性插值是不可行的。為此,我們提出了KNN插值,通過融合最近鄰點對注意力mask進行降采樣。一個簡單的操作是最大池化或平均池化。我們使用基于距離的插值。為了簡單起見,我們省略了A中的層索引1,
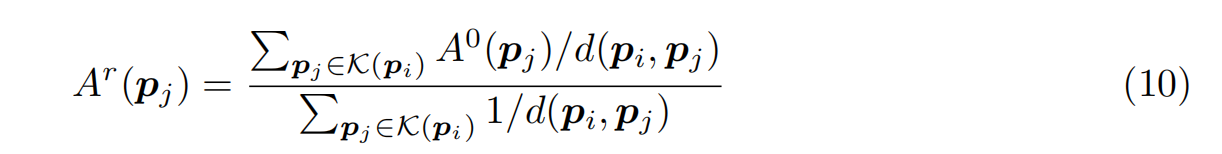
式中,A0和Ar分別為全分辨率注意掩碼和r分辨率注意掩碼。D(·,·)是距離度量。K(pi)是K個最近鄰的集合,在實踐中,我們在實驗中設置K= 4r。
Training and Inference
在整個訓練階段,我們采用二部匹配和設置預測損失的方法,以最小的匹配代價為預測分配基礎真值。全損失函數L可表示為L = λBCELBCE + λdiceLdice + λclsLcls + λCCLLCCL,其中LBCE為二值交叉熵損失(在該掩碼的前景和背景上),lice為Dice損失(Deng et al., 2018), Lcls為默認的多類交叉熵損失來監督查詢分類,LCCL為對比連接損失。在我們的實驗中,我們經驗地設置λBCE: λdice: λcls: λCCL = 5:5:2: 8。對于推斷,我們簡單地使用argmax來確定最終的全景結果。
Experiments
在本節中,我們介紹了在公共CAD繪圖數據集FloorPlanCAD上的實驗設置和基準測試結果(Fan et al., 2021)。繼之前的作品(Fan et al., 2021;鄭等,2022;Fan et al., 2022),我們還將我們的方法與典型的基于圖像的實例檢測進行了比較(Ren et al., 2015;Redmon & Farhadi, 2018;田等人,2019;Zhang等人,2022)。此外,我們還與點云語義分割方法進行了比較(Zhao et al., 2021),進行了廣泛的消融研究以驗證所提出技術的有效性。此外,我們還驗證了我們的方法在floorplanCAD以外的其他數據集上的通用性,詳細結果可在附錄A中獲得。
Experimental Setting
Dataset and Metrics
FloorPlanCAD數據集包含11,602張各種平面圖的CAD圖紙,帶有分段粒度的全景注釋,涵蓋30個物體和5個物體類。以下(Fan et al., 2021;鄭等,2022;Fan等人,2022),我們使用在矢量圖形上定義的全光質量(PQ)作為評估全光符號識別性能的主要指標。通過用語義標簽l和實例索引z表示圖形實體e = (l, z),將PQ定義為分割質量(SQ)和識別質量(RQ)的乘積,表示為
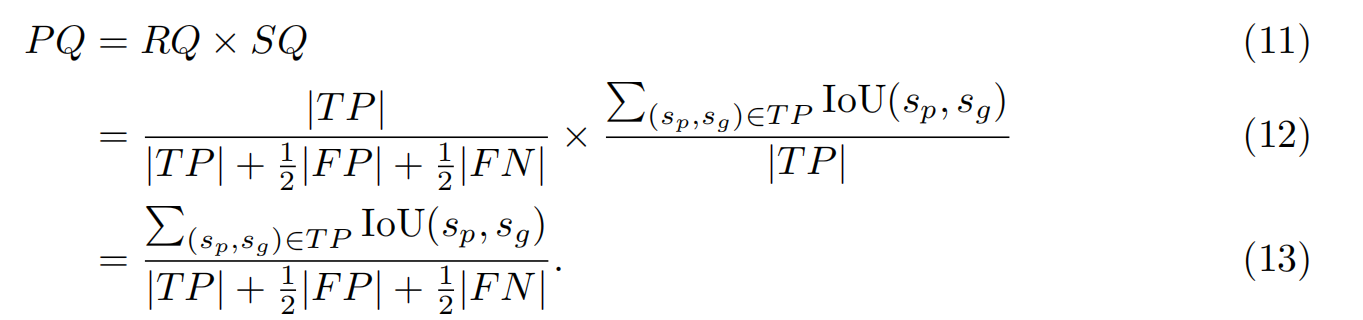
式中,sp = (lp, zp)為預測符號,sg = (lg, zg)為基礎真值符號。|T P|、|F P|、|F N|分別為真陽性、假陽性、假陰性。如果某個預測符號找到了一個基礎真值符號,則認為它匹配,其中lp = lg, IoU(sp, sg) > 0.5,其中IoU的計算方法為:
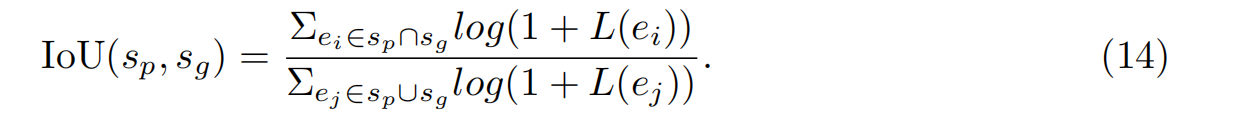
Implementation Details
我們用Pytorch實現SymPoint。我們使用雙通道的PointT (Zhao et al., 2021)作為主干,并將L = 3層堆棧用于符號定位頭。對于數據增強,我們采用旋轉、翻轉、縮放、移動和混合增強。我們選擇AdamW (Loshchilov & Hutter, 2017)作為優化器,默認權重衰減為0.001,初始學習率為0.0001,我們在8個NVIDIA A100 GPU上訓練模型1000次,批處理大小為每個GPU 2個。
Benchmark Results
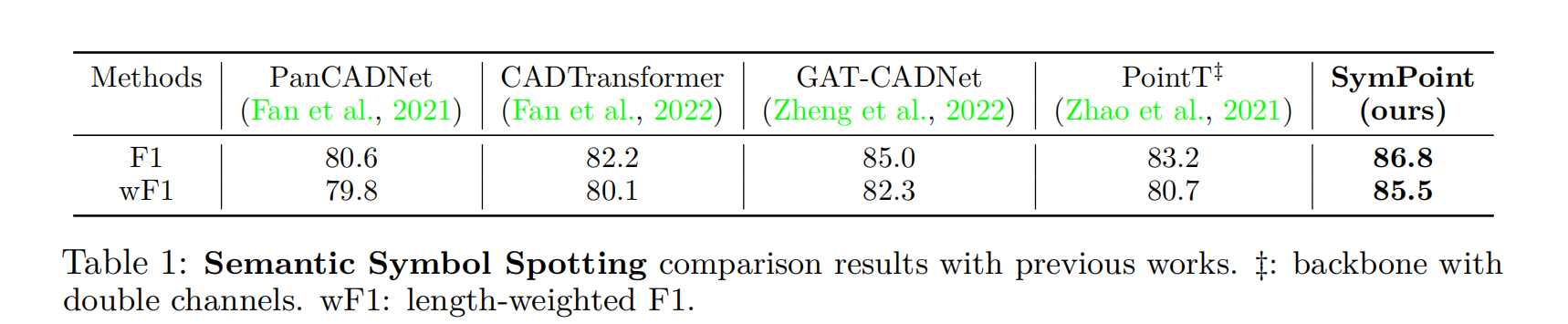
Semantic symbol spotting
我們將我們的方法與點云分割方法(Zhao et al., 2021)和符號識別方法(Fan et al., 2021;2022年;鄭等人,2022)。主要測試結果如表1所示,我們的算法在語義符號識別任務上優于以往的所有方法。更重要的是,與GAT-CADNet相比(Zheng et al., 2022),我們實現了1.8% F1的絕對改進。和3.2% wF1。對于點,我們使用3.1節中提出的基于點的表示法將CAD繪圖轉換為作為輸入的點集合。值得注意的是,PointT?已經取得了與GAT-CADNet相當的結果(Zheng et al., 2022),這證明了所提出的基于點的表示用于CAD符號識別的有效性。
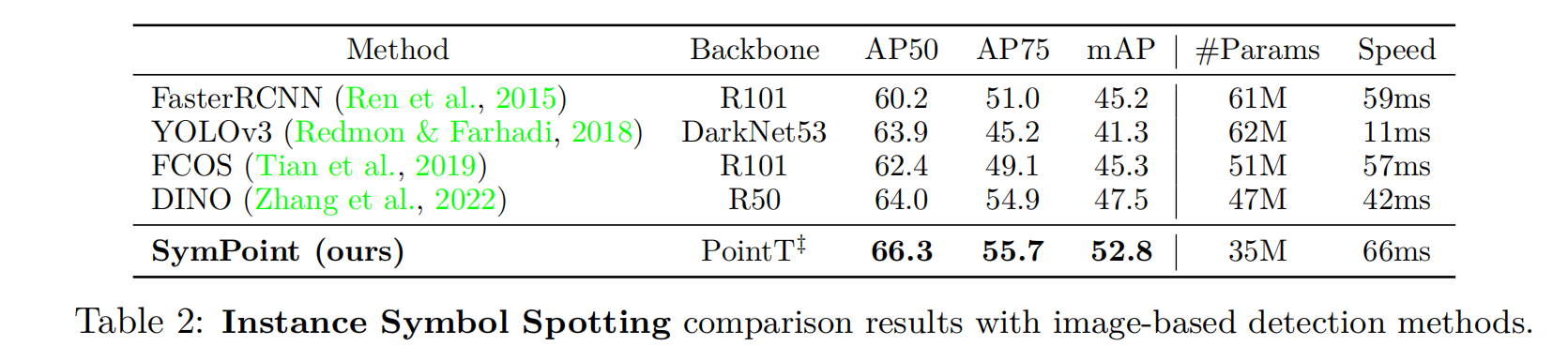
Instance Symbol Spotting
我們將我們的方法與各種圖像檢測方法進行了比較,包括fastrcnn (Ren et al., 2015)、YOLOv3 (Redmon & Farhadi, 2018)、FCOS和DINO。為了公平的比較,我們對預測的掩碼進行后處理,以產生一個用于度量計算的邊界框。主要對比結果如表2所示。雖然我們的框架沒有被訓練輸出一個邊界框,但它仍然達到了最好的結果。
Panoptic Symbol Spotting
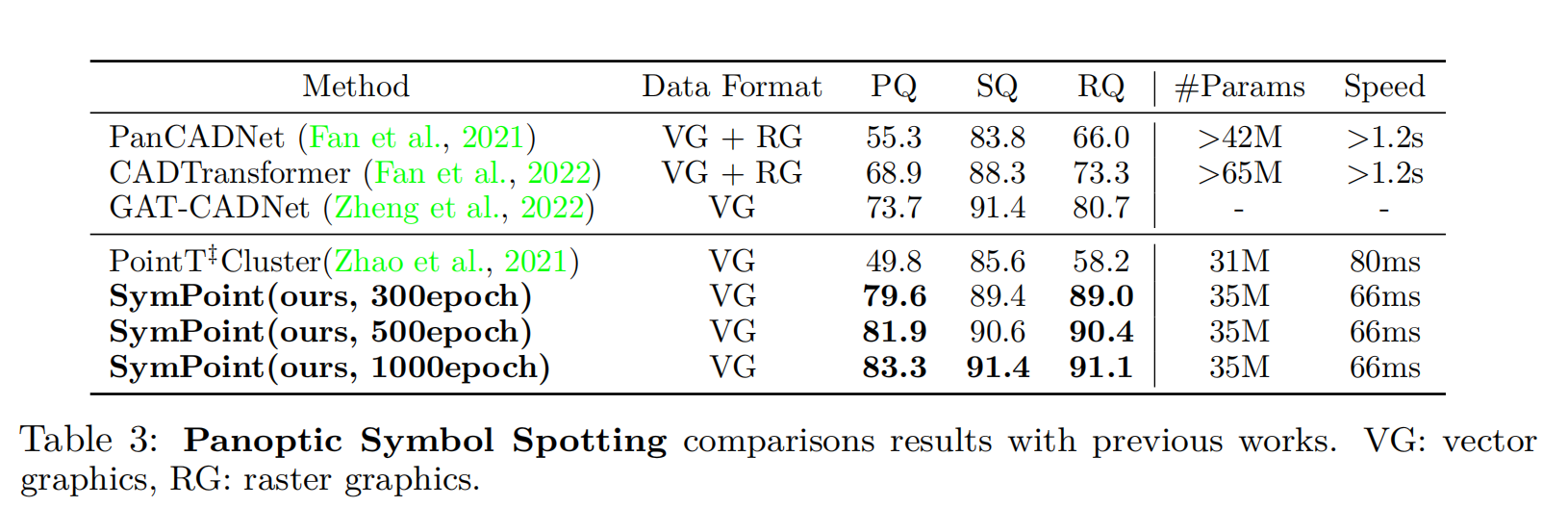
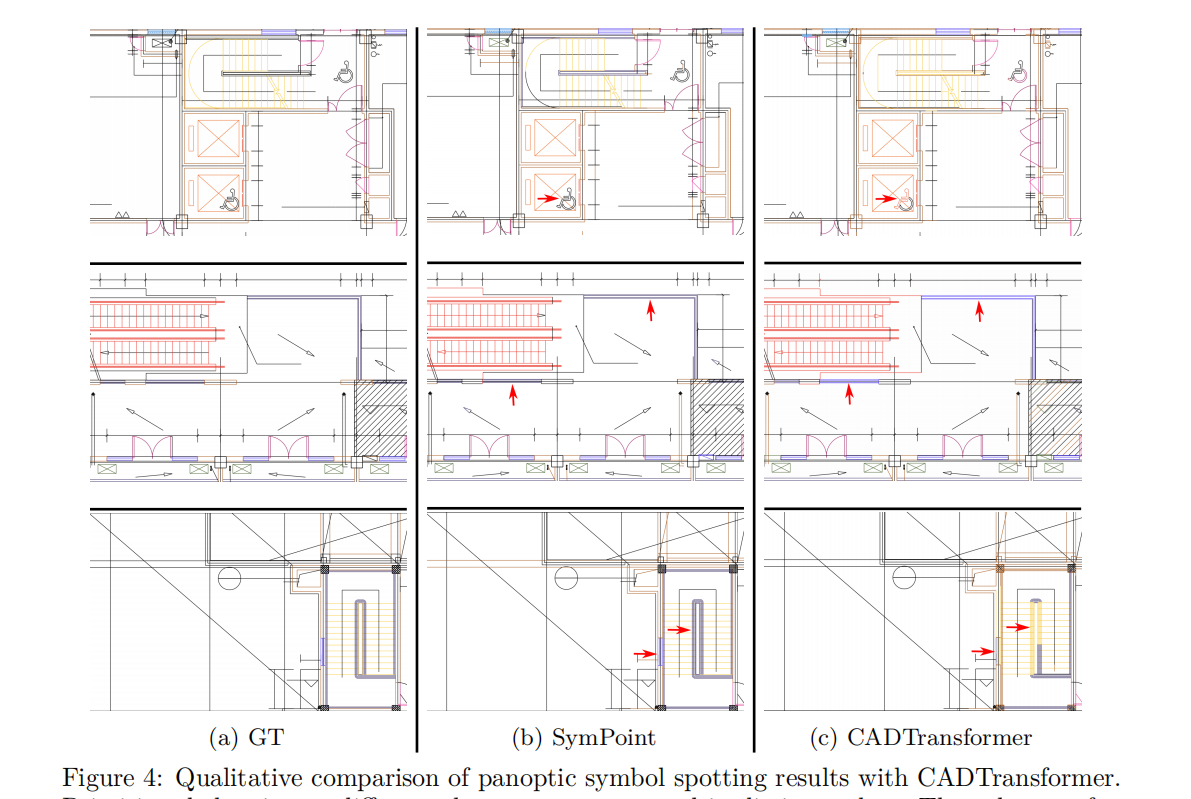
為了驗證符號定位頭的有效性,我們還設計了一種沒有這個頭的變體方法,名為PointT?Cluster,它預測每個圖形實體的偏移向量,以收集公共實例質心周圍的實例實體,并執行類智能聚類(例如meanshift (Cheng, 1995)),以獲得CADTransformer (Fan et al., 2022)中的實例標簽。最終結果如表3所示。我們使用300epoch訓練的SymPoint的性能大大優于point?Cluster和最近的SOTA方法GAT-CADNet(Zheng et al., 2022),證明了所提出方法的有效性。我們的方法也受益于更長的訓練時間,并實現進一步的性能提高。此外,我們的方法在推理階段的運行速度比以前的方法快得多。對于基于圖像的方法,將矢量圖形渲染為圖像大約需要1.2s,而我們的方法不需要這個過程。定性結果如圖4所示。
Ablation Studies
所有的消融都是在300次訓練下進行的
Effects of Techniques
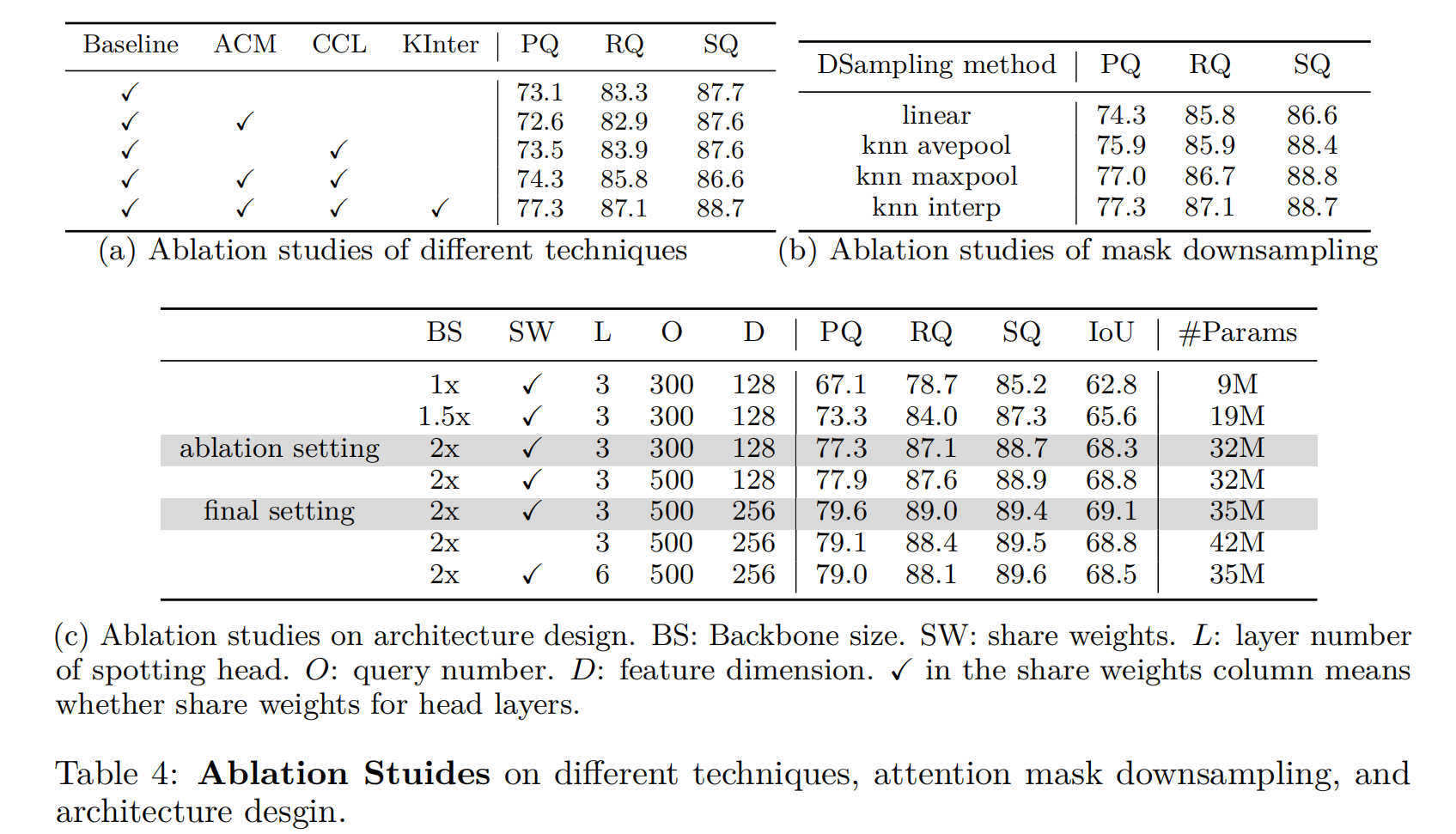
我們在表4a中進行了各種對照實驗,以驗證提高SymPoint性能的不同技術。這里的基線是指第3.2節中描述的方法。當我們只引入ACM (Attention with Connection Module)時,由于嘈雜的連接,性能會下降一點。但當我們將其與CCL(對比連接學習)相結合時,性能提高到PQ的74.3。注意,單獨應用CCL只能略微提高性能。此外,KNN插值顯著提高了性能,達到了PQ的77.3。
KNN Interpolation
在表4b中,我們列出了不同的下采樣注意掩碼方法:1)線性插值,2)KNN平均池化,3)KNN最大池化,4)KNN插值。KNN平均池化和KNN最大池化是指使用最近的K個相鄰點的平均值或最大值作為輸出,而不是使用Eq.(10)中定義的輸出。我們可以看到,所提出的KNN插值達到了最好的性能。
Architecture Design
我們分析了不同的模型架構設計,如主干網通道數和符號識別頭的L層是否共享權重的影響。從表4c可以看出,增大符號點頭的主干、查詢數和特征通道可以進一步提高性能。定位頭權值共享不僅節省了模型參數,而且比不權值共享獲得了更好的性能。
Conclusion and Future Work
本研究為全光學符號識別提供了一個新的視角。我們將CAD圖紙視為點的集合,并利用點云分析的方法來識別符號。我們的方法SymPoint簡單而有效,優于以往的工作。一個限制是我們的方法需要很長的訓練時間來獲得有希望的性能。因此,加速模型收斂是今后工作的重要方向。

![[閉源saas選項]Pinecone:為向量數據庫而生的實時語義搜索引擎](http://pic.xiahunao.cn/[閉源saas選項]Pinecone:為向量數據庫而生的實時語義搜索引擎)

)

)
——Chat Client API)


![[藍橋杯]堆的計數](http://pic.xiahunao.cn/[藍橋杯]堆的計數)


簡易開發環境)






