地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
摘要翻譯
自動駕駛技術作為推動交通和城市出行變革的催化劑,正從基于規則的系統向數據驅動策略轉變。傳統的模塊化系統受限于級聯模塊間的累積誤差和缺乏靈活性的預設規則。相比之下,端到端自動駕駛系統因其完全數據驅動的訓練過程有望避免誤差累積,但其 “黑箱” 特性往往導致透明度不足,使得決策的驗證和追溯復雜化。最近,大型語言模型(LLMs)已展現出上下文理解、邏輯推理和生成答案等能力。一個自然的想法是利用這些能力為自動駕駛賦能。通過將 LLM 與基礎視覺模型相結合,有望實現當前自動駕駛系統所缺乏的開放世界理解、推理和小樣本學習能力。本文系統綜述了用于自動駕駛的(視覺)大型語言模型((V) LLM4Drive)的研究路線,評估了當前的技術進展狀態,明確概述了該領域的主要挑戰和未來方向。為了方便學術界和工業界的研究人員,我們通過指定鏈接(GitHub - Thinklab-SJTU/Awesome-LLM4AD)提供該領域最新進展的實時更新以及相關開源資源。
總結
1. 背景
- 傳統模塊化系統:由感知、預測、規劃等獨立模塊組成,雖在多種場景中提供可靠性和安全性,但存在信息丟失、計算冗余和模塊間誤差累積等問題。
- 端到端系統:通過消除模塊間的集成誤差和減少冗余計算,增強了視覺和感官信息的表達,但決策過程缺乏透明度(“黑箱” 問題),解釋和驗證困難。
- LLMs 的潛力:憑借強大的上下文理解、推理和生成能力,結合多模態模型(如圖像、文本、點云等),可提升系統的泛化能力,支持零 / 小樣本學習,有望解決自動駕駛的長尾問題并提供決策解釋。
2. 動機
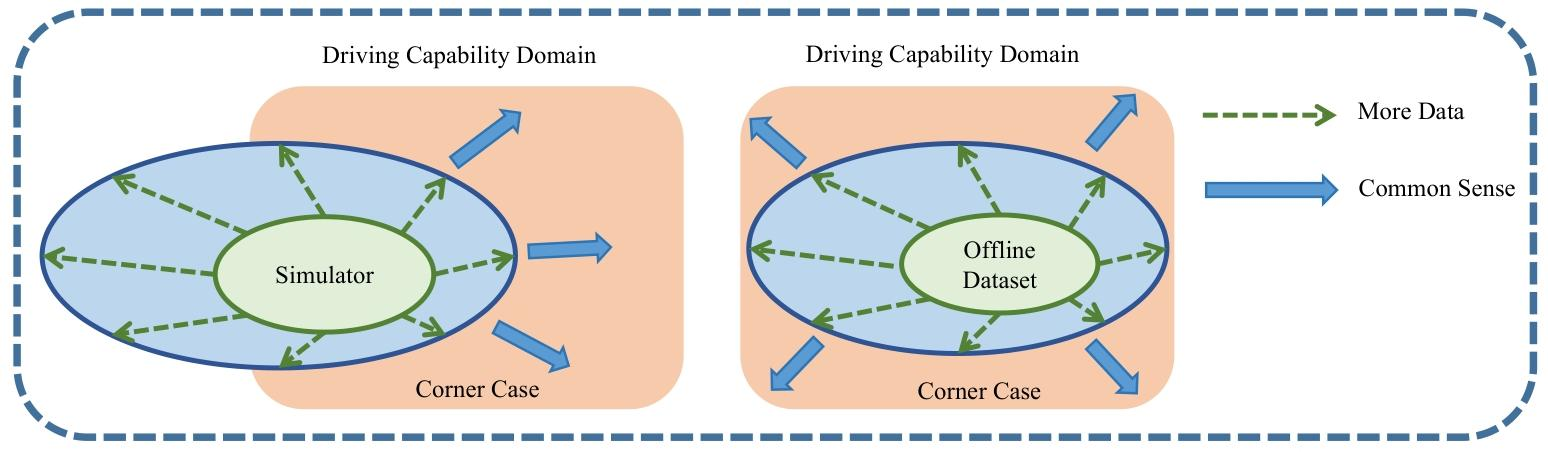
- 數據與仿真的局限性:傳統方法依賴大量數據和仿真,但仿真與現實存在差距(sim2real gap),且離線數據難以覆蓋自動駕駛的長尾場景。
- LLMs 的補充作用:利用 LLMs 內置的常識知識,可縮小數據缺口,提升系統在復雜場景下的推理能力,推動自動駕駛向人類專家水平靠近。
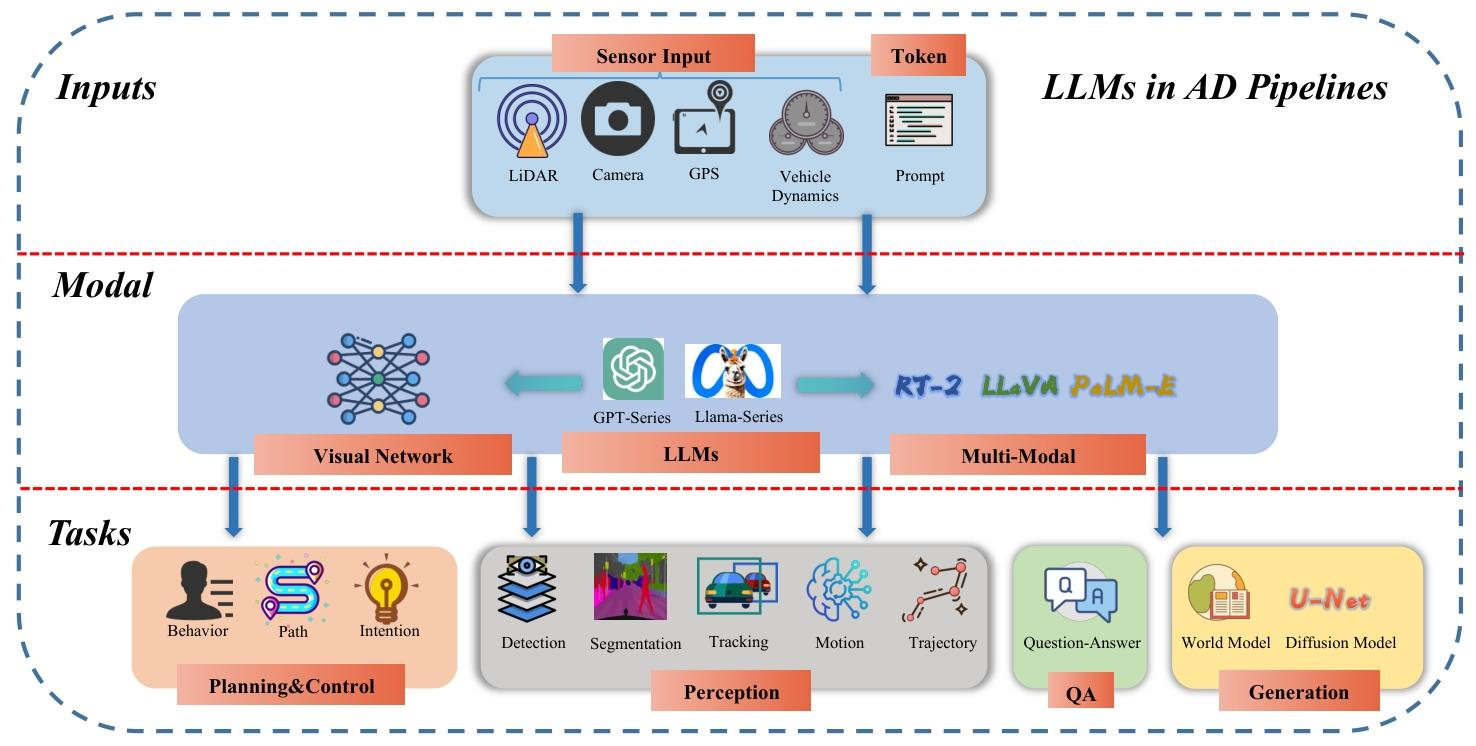
3. 應用場景
- 規劃與控制
- 微調預訓練模型:如 MTDGPT 將多任務決策轉化為序列建模問題;DriveGPT4 基于多模態 LLM 生成控制信號并解釋決策。
- 提示工程:如 DiLu 通過記憶模塊和 LLM 推理實現閉環駕駛;SurrealDriver 利用人類駕駛行為描述作為提示開發 “教練代理”。
- 感知:LLMs 通過跨模態特征融合(如 PromptTrack 的語言提示與 3D 檢測結合)或提示推理(如 HiLM-D 的風險目標定位)提升感知能力,尤其在數據稀缺場景下表現突出。
- 問答(QA):涵蓋傳統 QA(如 Tang 等人的領域知識蒸餾)和視覺 QA(如 DriveLM 的圖結構推理),支持實時場景理解和用戶交互。
- 生成:利用擴散模型(如 DriveDreamer、DrivingDiffusion)生成駕駛視頻、交通場景或軌跡,用于數據增強和場景仿真,降低數據收集成本。
4. 數據集與評估基準
- 數據集:如 BDD-X、NuScenes-QA、LingoQA 等,提供多模態標注(文本描述、QA 對、3D 邊界框等),支持 LLMs 在自動駕駛中的訓練和評估。
- 評估基準:包括 LangAuto(CARLA-based)、LingoQA、DriveSim 等,覆蓋場景理解、決策邏輯、安全性等多維度評估。
5. 挑戰與未來方向
- 挑戰:計算效率(LLMs 推理時間長)、實時性要求、可解釋性不足、數據質量(標注成本高)、安全性(對抗攻擊)和倫理問題(隱私、偏見)。
- 未來方向:輕量級 LLMs 優化、多模態融合(視覺 - 語言 - 傳感器)、邊緣計算部署、標準化評估指標、安全對齊(如形式化驗證)和倫理框架建設。
一、相關技術方法
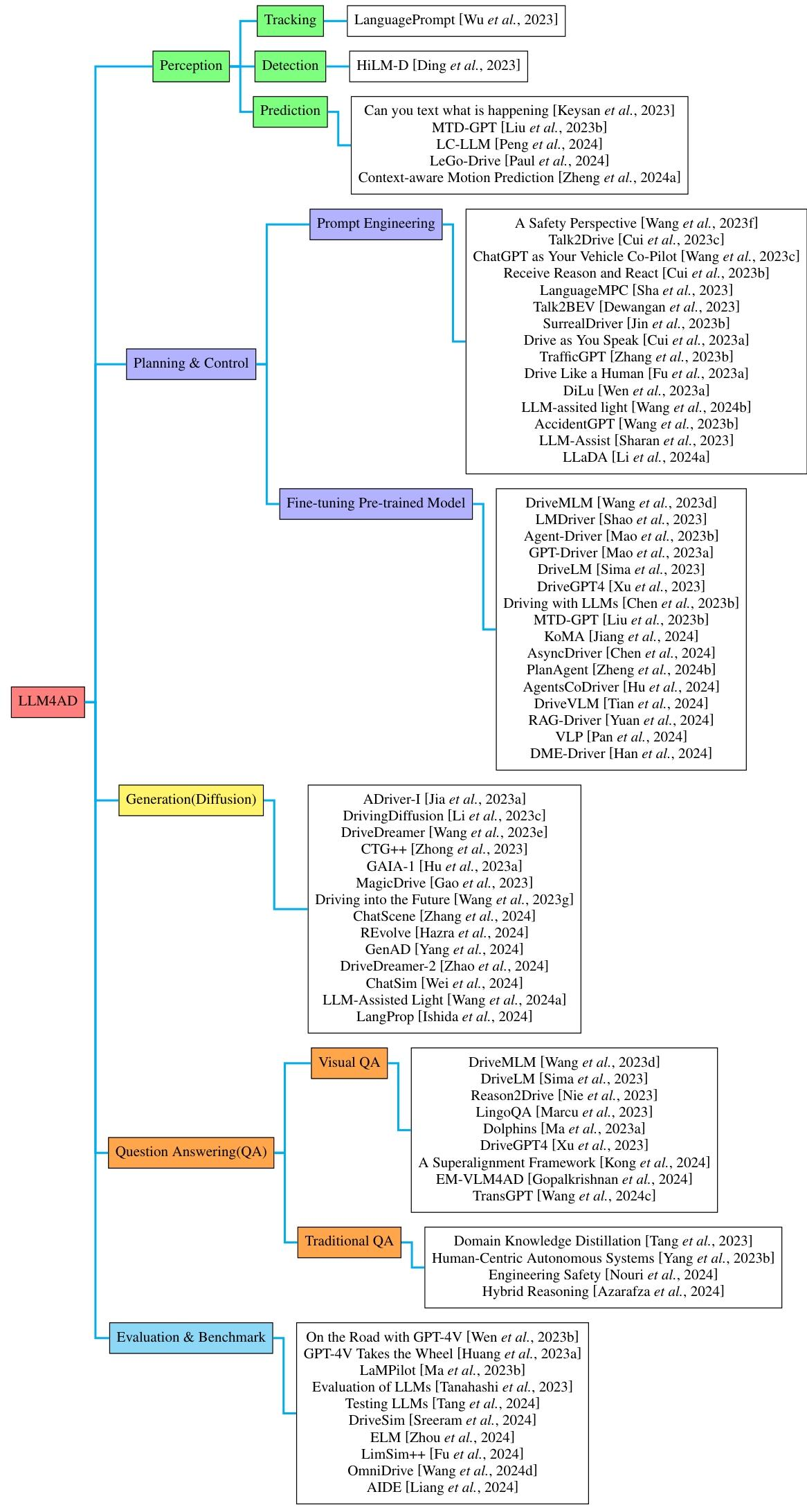
1. 規劃與控制方法
- 微調預訓練模型
- 核心思路:在預訓練 LLMs 基礎上,針對駕駛場景(如無信號交叉口決策、軌跡預測)進行微調,將駕駛任務轉化為序列建模或語言生成問題。
- 代表方法:MTDGPT 通過混合多任務數據集訓練處理復雜決策;Agent-Driver 引入工具庫和認知記憶增強推理;RAG-Driver 結合檢索增強上下文學習,實現可解釋的端到端駕駛。
- 提示工程
- 核心思路:通過設計特定提示(如 “思維鏈”、安全準則)激活 LLMs 的推理能力,無需大規模訓練。
- 代表方法:DiLu 利用記憶模塊記錄經驗,通過多輪 QA 實現推理和反思;TrafficGPT 融合 ChatGPT 與交通基礎模型,處理復雜交通問題;LanguageMPC 將 LLMs 與低級控制器結合,通過參數矩陣適應優化控制。
2. 感知方法
- 跨模態融合:如 PromptTrack 將語言提示作為語義線索,融合到 3D 檢測和跟蹤任務中;LC-LLM 利用 LLMs 理解復雜場景,提升車道變更預測的可解釋性。
- 提示推理:如 HiLM-D 將高分辨率視覺信息輸入多模態 LLMs,實現風險目標定位和意圖預測;Context-aware Motion Prediction 結合 GPT-4V 的場景描述與傳統模型,增強運動預測準確性。
3. 問答與生成方法
- 問答
- 傳統 QA:通過 “聊天” 與 LLMs 構建領域知識本體(如 Tang 等人的交通規則蒸餾),支持實時交互和干預。
- 視覺 QA:如 DriveMLM 利用多視圖圖像和點云生成高層決策命令;EM-VLM4AD 設計輕量級多幀視覺語言模型,提升問答效率。
- 生成
- 擴散模型:如 DriveDreamer 基于文本、圖像和 HD 地圖生成駕駛視頻;CTG++ 通過 LLMs 將用戶查詢轉化為損失函數,驅動擴散模型生成可控交通場景。
- 場景仿真:ChatScene 利用 LLMs 生成安全關鍵場景,提升自動駕駛系統的魯棒性;GenAD 利用網絡數據和時間推理塊,實現零樣本場景泛化。
4. 評估與基準
- 仿真環境:如 CARLA、nuPlan、HighwayEnv,用于測試 LLMs 在閉環駕駛中的性能(如碰撞率、軌跡擬合度)。
- 指標體系:涵蓋傳統指標(如 L2 誤差、mAP)和語言評估指標(如 BLEU-4、ChatGPT 評分),但缺乏統一標準,需進一步標準化。
二、評價指標
1. 傳統指標
- 規劃與控制:軌跡跟蹤誤差(RMSE)、碰撞率、速度方差(SV)、時間效率(TE)。
- 感知:mAP(平均精度均值)、3D檢測準確率、目標定位誤差(L2誤差)。
2. 語言與多模態指標
- 問答:BLEU-4、METEOR、CIDEr、SPICE(用于評估生成文本的語義準確性)。
- 生成:FID(Fréchet Inception Distance)、CLIP分數(用于評估生成圖像/視頻的質量)。
3. 綜合指標
- 實時性:推理速度(如LLM-MPC在Jetson Orin上5.52秒/次)、控制頻率(如MPC保持20Hz)。
- 安全性:碰撞時間(TTC)、違規處罰(IP)、形式化驗證通過率。
三、數據集

四、亟待解決的核心問題
1. 計算效率與實時性瓶頸
- 挑戰:LLM推理延遲高(如GPT-4V在復雜場景中需數秒),難以滿足自動駕駛20Hz以上的控制頻率需求。
- 解決方案:
- 異步架構:如AsyncDriver將LLM推理與實時規劃解耦,通過低頻率高層決策指導高頻控制。
- 模型壓縮:結合量化(如INT8量化)和知識蒸餾(如CoT-Drive),在保持性能的同時減少計算量。
2. 多模態融合的動態適應性
- 挑戰:靜態融合方法無法應對數據分布變化(如傳感器故障、極端天氣),導致性能下降。
- 解決方案:
- 動態融合機制:如DynMM通過門控函數動態選擇模態組合,QMF利用不確定性估計實現質量感知融合。
- 跨模態對齊:如3D MLLM架構通過稀疏查詢統一視覺與語言的3D表示,提升場景理解一致性。
3. 數據質量問題
- 挑戰:合成數據的真實性不足(如紋理、物理特性差異),導致模型在真實場景中泛化能力弱。
- 解決方案:
- 生成式仿真優化:如ChatSim結合神經渲染與擴散模型,提升場景的視覺和物理真實性。
- 域適應技術:通過對抗訓練(如CycleGAN)或元學習,縮小合成數據與真實數據的分布差異。
4. 可解釋性與安全驗證
- 挑戰:LLM的“黑箱”特性導致決策邏輯難以追溯,且存在幻覺問題(如錯誤識別障礙物)。
- 解決方案:
- 可解釋性增強:如DriveGPT4通過自然語言生成決策依據,GenFollower結合思維鏈(CoT)提示輸出顯式推理過程。
- 形式化驗證:如Hybrid Reasoning框架將LLM決策與傳統控制器結合,通過邏輯推理驗證安全性。
5. 倫理與社會接受度
- 挑戰:自動駕駛系統的決策可能引發倫理爭議(如緊急避險時的優先級選擇),且用戶對AI駕駛的信任度不足。
- 解決方案:
- 倫理框架設計:建立多利益相關方參與的評估體系,如SurrealDriver通過人類用戶實驗評估駕駛行為的人性化程度。
- 透明交互界面:如Tang等人的領域知識蒸餾系統,通過實時問答增強用戶對系統的理解與控制。

簡易開發環境)

















)