連接管理是一個 HTTP 的關鍵話題:打開和保持連接在很大程度上影響著網站和 Web 應用程序的性能。在 HTTP/1.x 里有多種模型:短連接、_長連接_和 HTTP 流水線。
下面分別來詳細解釋
短連接
HTTP 協議最初(0.9/1.0)是個非常簡單的協議,通信過程也采用了簡單的 “請求 - 應答” 方式。
它底層的數據傳輸基于 TCP/IP,每次發送請求前需要先與服務器建立連接,收到響應報文后會立即關閉連接。
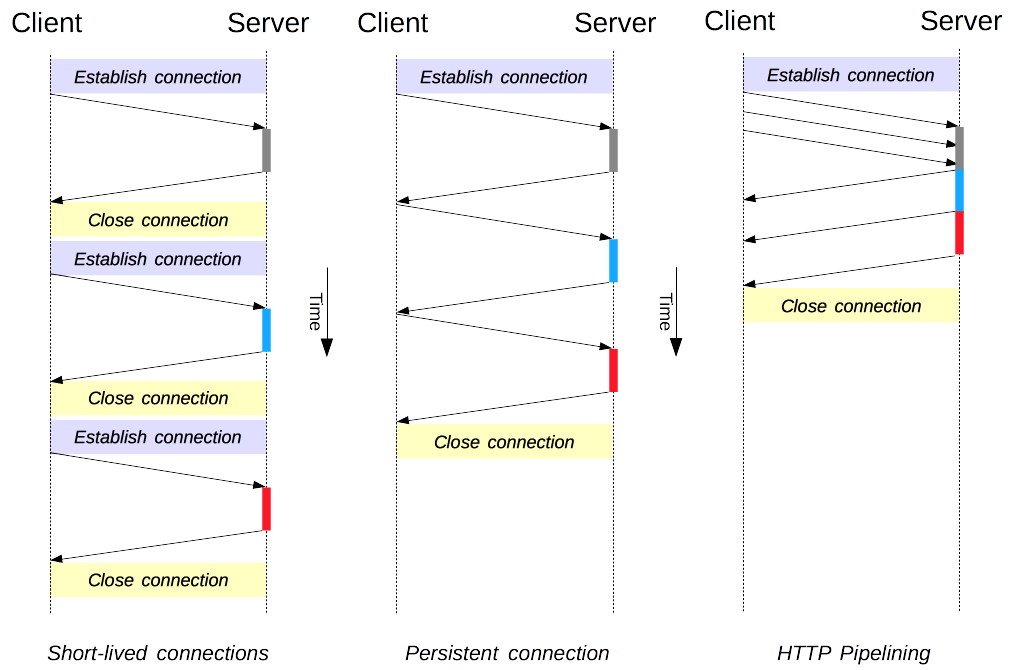
因為客戶端與服務器的整個連接過程很短暫,不會與服務器保持長時間的連接狀態,所以就被稱為 “短連接”(short-lived connections)。早期的 HTTP 協議也被稱為是 “無連接” 的協議。
這是 HTTP/1.0 的默認模型(如果沒有指定 Connection 協議頭,或者是值被設置為 close)。而在 HTTP/1.1 中,只有當 Connection 被設置為 close 時才會用到這個模型。
問題
在 TCP 協議里,建立連接和關閉連接都是非常 “昂貴” 的操作。TCP 建立連接要有“三次握手”,發送 3 個數據包,需要 1 個 RTT;關閉連接是“四次揮手”,4 個數據包需要 2 個 RTT。
而 HTTP 的一次簡單 “請求 - 響應” 通常只需要 4 個包,如果不算服務器內部的處理時間,最多是 2 個 RTT。這么算下來,浪費的時間就是“3÷5=60%”,有三分之二的時間被浪費掉了,傳輸效率低得驚人。
長連接
針對短連接暴露出的缺點,HTTP 協議就提出了 “長連接” 的通信方式,也叫 “持久連接”(persistent connections)、“連接保活”(keep alive)、“連接復用”(connection reuse)。
把 TCP 的連接和關閉時間成本由原來的一個 “請求 - 應答” 均攤到多個 “請求 - 應答” 上。
這樣雖然不能改善 TCP 的連接效率,但基于 “分母效應”,每個 “請求 - 應答” 的無效時間就會降低不少,整體傳輸效率也就提高了。
短連接與長連接的對比示意圖。
缺點
就算是在空閑狀態,它還是會消耗服務器資源,而且在重負載時,還有可能遭受 DoS 攻擊。這種場景下,可以使用非長連接,即盡快關閉那些空閑的連接,也能對性能有所提升。
HTTP/1.0 里默認并不使用長連接。把 Connection 設置成 close 以外的其他參數都可以讓其保持長連接,通常會設置為 retry-after。
在 HTTP/1.1 里,默認就是長連接的,不再需要標頭(但我們還是會把它加上,萬一某個時候因為某種原因要退回到 HTTP/1.0 呢)。
HTTP 流水線
默認情況下,HTTP 請求是按順序發出的。下一個請求只有在當前請求收到響應過后才會被發出。由于會受到網絡延遲和帶寬的限制,在下一個請求被發送到服務器之前,可能需要等待很長時間。
流水線是在同一條長連接上發出連續的請求,而不用等待應答返回。這樣可以避免連接延遲。理論上講,性能還會因為兩個 HTTP 請求有可能被打包到一個 TCP 消息包中而得到提升。就算 HTTP 請求不斷的繼續,尺寸會增加,但設置 TCP 的最大分段大小(MSS)選項,仍然足夠包含一系列簡單的請求。
并不是所有類型的 HTTP 請求都能用到流水線:只有冪等方式,比如 GET、HEAD、PUT 和 DELETE 能夠被安全地重試。如果有故障發生時,流水線的內容要能被輕易的重試。
今天,所有遵循 HTTP/1.1 標準的代理和服務器都應該支持流水線,雖然實際情況中還是有很多限制:一個很重要的原因是,目前沒有現代瀏覽器默認啟用這個特性。
缺點
● 正確的實現流水線是復雜的:傳輸中的資源大小、多少有效的 RTT 會被用到以及有效帶寬都會直接影響到流水線提供的改善。不知道這些的話,重要的消息可能被延遲到不重要的消息后面。這個重要性的概念甚至會演變為影響到頁面布局!因此 HTTP 流水線在大多數情況下帶來的改善并不明顯。
● 流水線受制于隊頭阻塞(HOL)問題。
由于這些原因,流水線已被 HTTP/2 中更好的算法——==多路復用(multiplexing)==所取代。


















)
