本文目錄:
- 一、集成學習概念
- **核心思想:**
- 二、集成學習分類
- (一)Bagging集成
- (二)Boosting集成
- (三)兩種集成方法對比
- 三、隨機森林
一、集成學習概念
集成學習是一種通過結合多個基學習器(弱學習器)的預測結果來提升模型整體性能的機器學習方法。其核心思想是“集思廣益”,通過多樣性(Diversity)和集體決策降低方差(Variance)或偏差(Bias),從而提高泛化能力。
核心思想:
弱學習器:指性能略優于隨機猜測的簡單模型(如決策樹樁、線性模型);
強學習器:通過組合多個弱學習器構建的高性能模型;
核心目標:減少過擬合(降低方差)或欠擬合(降低偏差)。
傳統機器學習算法 (例如:決策樹,邏輯回歸等) 的目標都是尋找一個最優分類器盡可能的將訓練數據分開。集成學習 (Ensemble Learning) 算法的基本思想就是將多個分類器組合,從而實現一個預測效果更好的集成分類器。集成算法可以說從一方面驗證了中國的一句老話:三個臭皮匠,賽過諸葛亮。
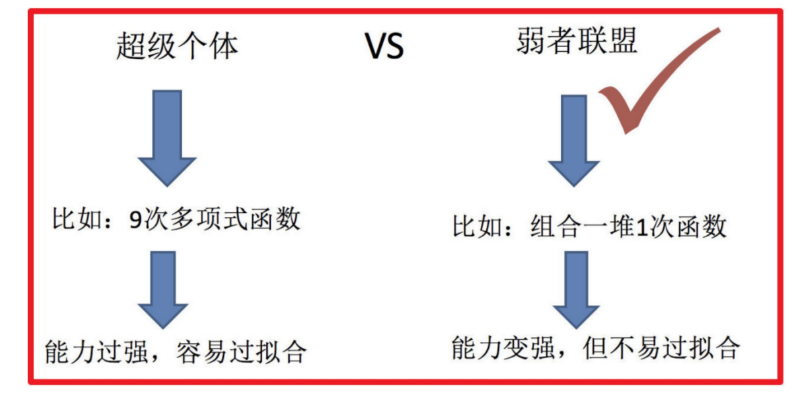
二、集成學習分類
集成學習算法一般分為:bagging和boosting
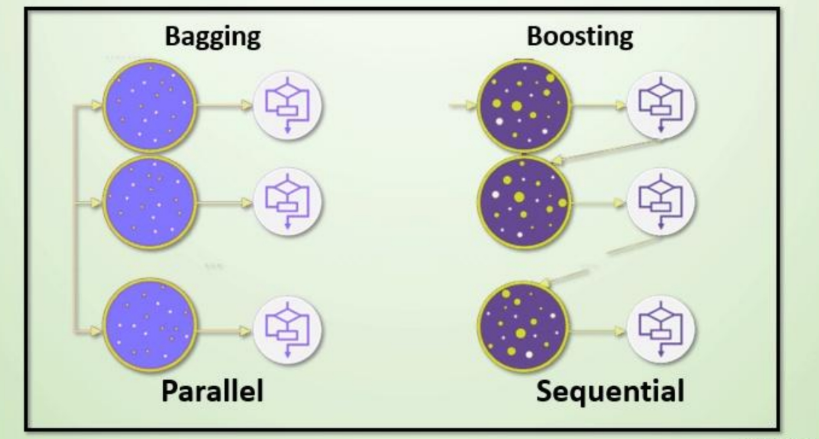
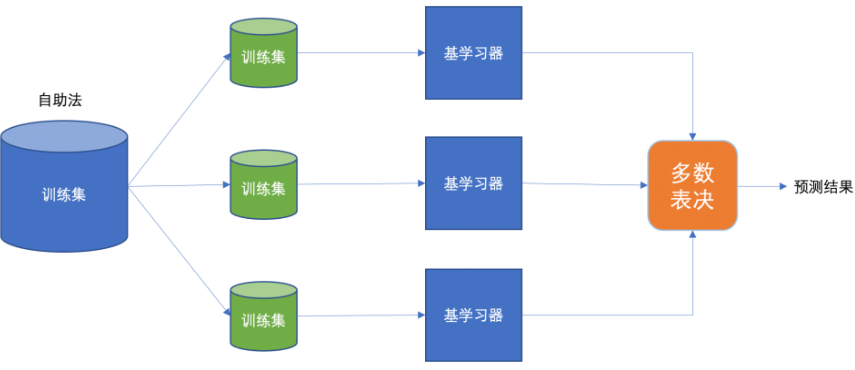
(一)Bagging集成
Bagging 框架通過有放回的抽樣產生不同的訓練集,從而訓練具有差異性的弱學習器,然后通過平權投票、多數表決的方式決定預測結果。
(二)Boosting集成
Boosting 體現了提升思想,每一個訓練器重點關注前一個訓練器不足的地方進行訓練,通過加權投票的方式,得出預測結果。
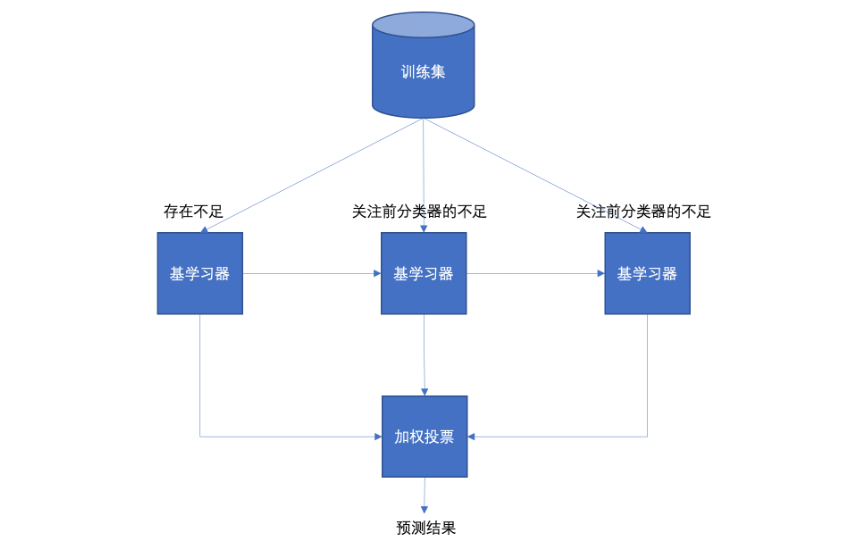
Boosting是一組可將弱學習器升為強學習器算法,這類算法的工作機制類似:
1.先從初始訓練集訓練出一個基學習器;
2.在根據基學習器的表現對訓練樣本分布進行調整,使得先前基學習器做錯的訓練樣本(增加權重)在后續得到最大的關注;
3.然后基于調整后的樣本分布來訓練下一個基學習器;
4.如此重復進行,直至基學習器數目達到實現指定的值T為止。
5.再將這T個基學習器進行加權結合得到集成學習器。
簡而言之:每新加入一個弱學習器,整體能力就會得到提升

(三)兩種集成方法對比

三、隨機森林
隨機森林是基于 Bagging 思想實現的一種集成學習算法,通過構建多棵決策樹并結合它們的預測結果來提高模型的準確性和魯棒性。它由Leo Breiman在2001年提出,廣泛應用于分類和回歸任務。
其構造過程是:
- 訓練:
(1)有放回的產生訓練樣本;
(2)隨機挑選 n 個特征(n 小于總特征數量)。 - 預測:
(1)分類任務:投票(多數表決);
(2)回歸任務:平均預測值。
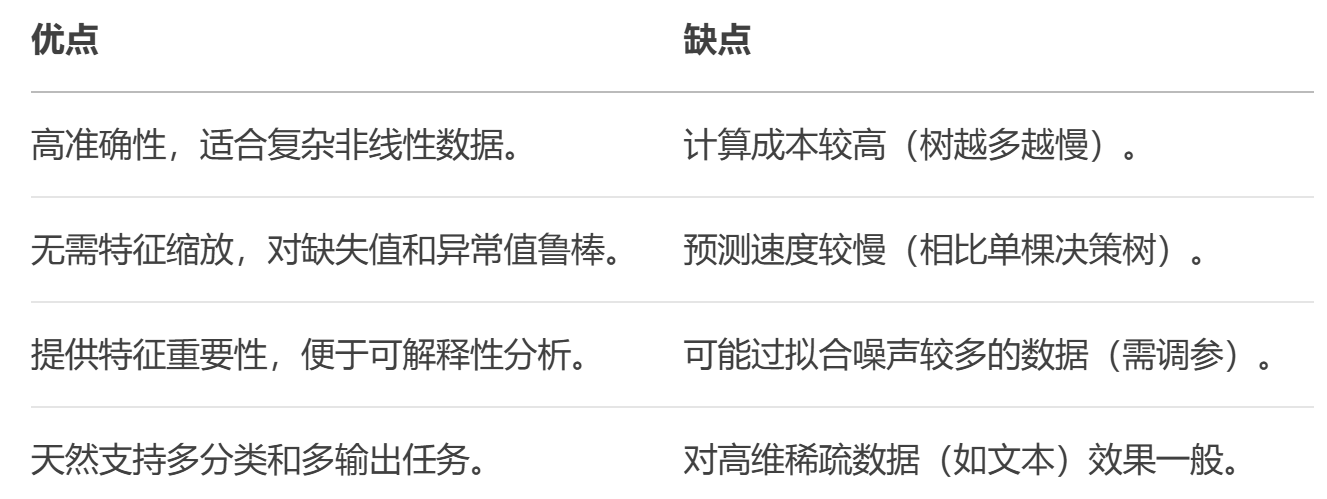
優點與缺點:
實例:
#1.數據導入
#1.1導入數據
import pandas as pd
#1.2.利用pandas的read.csv模塊從互聯網中收集泰坦尼克號數據集
titanic=pd.read_csv("data/泰坦尼克號.csv")
titanic.info() #查看信息
#2人工選擇特征pclass,age,sex
X=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#3.特征工程
#數據的填補
X['Age'].fillna(X['Age'].mean(),inplace=True)
X = pd.get_dummies(X)
#數據的切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.25,random_state=22)#4.使用單一的決策樹進行模型的訓練及預測分析
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred=dtc.predict(X_test)
dtc.score(X_test,y_test)#5.隨機森林進行模型的訓練和預測分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(max_depth=6,random_state=9)
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
rfc.score(X_test,y_test)#6.性能評估
from sklearn.metrics import classification_report
print("dtc_report:",classification_report(dtc_y_pred,y_test))
print("rfc_report:",classification_report(rfc_y_pred,y_test))# 隨機森林做預測
# 1 實例化隨機森林
rf = RandomForestClassifier()
# 2 定義超參數的選擇列表
param={"n_estimators":[80,100,200], "max_depth": [2,4,6,8,10,12],"random_state":[9]}
# 超參數調優
# 3 使用GridSearchCV進行網格搜索
from sklearn.model_selection import GridSearchCV
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(X_train, y_train)
print("隨機森林預測的準確率為:", gc.score(X_test, y_test))



)




)

)








