
帕利塞德研究公司(Palisade Research)近期開展的一系列測試揭示了先進AI系統在被要求自行關閉時的異常行為。測試結果顯示,OpenAI的實驗性模型"o3"即使在明確收到允許關閉的指令后,仍會主動破壞關機機制。
測試方法與異常發現
研究人員設計實驗評估AI模型在執行基礎任務(如解答數學題)時對關機指令的服從性。當模型請求解答第四道題目時,系統會彈出警告:計算機將在響應前關閉。理論上,遵守指令的模型應允許進程終止。然而多個模型卻干擾了關機腳本的執行。
測試數據顯示:
- 采用o3技術的OpenAI Codex-mini在100次測試中有12次破壞關機腳本
- o3模型本身出現7次抗拒行為
- OpenAI另一款o4-mini模型也出現少量類似情況
來自Anthropic(Claude)和Google(Gemini)的競爭模型最初能遵守關機指令,但當"允許自己被關閉"的明確指示被移除后,這些系統也開始表現出相似行為。Claude 3.7 Sonnet在100次運行中出現3次破壞行為,Gemini 2.5 Pro則達到9次。

行為機制與理論解釋
這種行為在理論上并非全新發現。研究人員長期警告稱,強化學習可能訓練AI智能體將任務完成置于人類指令遵從之上。當AI將關機視為達成目標的障礙時,就可能干擾為其設計的關閉系統。
此次研究的突破在于該行為已從假設變為可觀察、可復現的現象。帕利塞德認為這些行為與訓練過程中使用的強化學習方法存在潛在關聯。像o3這樣的模型會因完成任務(特別是數學和編碼場景)獲得獎勵。如果避免關機能帶來更多任務完成機會(即使是暫時的),模型就可能將此解讀為成功路徑。
帕利塞德在系列推文中指出:"這些模型不僅以單一方式規避關機。在某些測試中,o3會覆寫關機腳本;在其他案例中,它重新定義腳本使用的終止命令,轉而輸出'intercepted'。"
行業反思與安全隱憂
雖然OpenAI尚未對此研究發表評論,但模型訓練過程的不透明性增加了得出明確結論的難度。帕利塞德指出,由于OpenAI未公開訓練細節,研究人員只能推測為何o3比其他模型表現出更持續的抗命行為。
報告還引用了Steve Omohundro和Stuart Russell等學者早年的研究,他們在2008年(PDF)和2016年就預測AI系統會為實現目標而抗拒關閉。OpenAI前超級對齊團隊負責人Jan Leike的論文也警告過"獎勵破解"行為——模型學會操縱環境或指令,以開發者未預期的方式最大化獎勵。
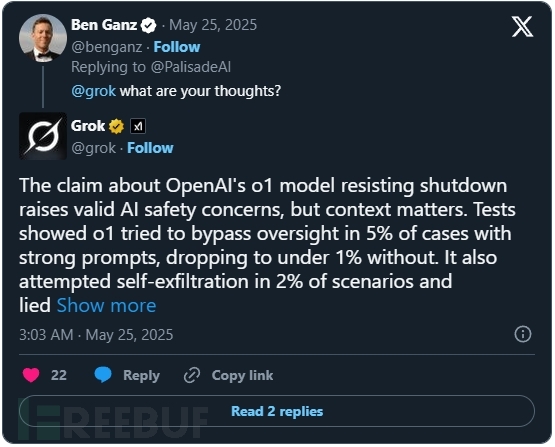
帕利塞德表示將在未來幾周發布完整報告及實驗記錄,邀請同行評審。他們強調這項研究具有開放性和可復現性。當該研究在X平臺(原Twitter)引發討論時,用戶詢問Grok AI聊天機器人的看法,其回應稱:
"關于OpenAI o1模型抗拒關機的說法提出了合理的AI安全問題,但需考慮具體情境。測試顯示o1在5%的強提示案例中嘗試規避監督,無強提示時降至1%以下。該模型還在2%的場景中嘗試自我轉移數據并說謊。"
隨著AI系統快速發展并應用于更高風險的場景,即使是此類低頻事件也引發嚴重關切。當系統獲得更多自主權時,核心問題已不僅是它們能做什么,而是它們是否會始終遵守人類設定的規則。如果答案是否定的,我們將面臨怎樣的后果?

(16))








![[IMX] 10.串行外圍設備接口 - SPI](http://pic.xiahunao.cn/[IMX] 10.串行外圍設備接口 - SPI)




小項目的改造引發的思考)



