1. 概念
拉普拉斯噪聲是一種連續概率分布生成的隨機噪聲,其核心特點是符合拉普拉斯分布。這種噪聲被特意添加到數據(尤其是查詢結果或統計量)中,以實現差分隱私這一嚴格的隱私保護框架。
-
核心目的:?在保護數據集中的個體隱私的同時,允許對數據集整體進行有價值的統計分析或機器學習。
-
關鍵特性:
-
對稱性:?噪聲值圍繞0對稱分布,正負值出現的概率相同。
-
重尾性:?雖然較小的噪聲值更常見,但出現較大噪聲值的概率比高斯分布(正態分布)更高。這意味著添加的噪聲可能偶爾會比較大,但這是實現強隱私保證所必需的代價。
-
以0為中心:?期望值(均值)為0。這意味著如果對同一個查詢多次添加拉普拉斯噪聲并取平均,結果會趨近于真實的查詢結果(滿足“無偏性”)。
-
拉普拉斯分布的概率密度函數 :
在給定位置參數?μ和尺度參數?b的情況下,隨機變量?X取值恰好為?x的可能性大小(更嚴格地說,是在?x附近一個極小區間內的概率與該區間長度的比值)。
-
x:這是隨機變量?X可能取的值。是我們想要計算其概率密度的點。
-
μ?(位置參數):
-
這是分布的中心位置。它決定了分布對稱軸所在的位置。
-
在公式中體現為?
。因為使用了絕對值,所以分布關于?μ?對稱。也就是說,距離?μ相同距離的點(比如?
和?
),它們的概率密度是相等的。
-
μ也是分布的中位數和眾數(出現概率最高的點)。
-
-
b?(尺度參數):
-
這個參數?b>0,它控制著分布的離散程度(或“胖瘦”)。
-
b?越大:
-
分布越“胖”、越“平坦”。數據點更分散,偏離中心?μ的程度更大。
-
添加的噪聲(在差分隱私中)幅度越大,隱私保護越強,但數據可用性越低。
-
-
b越小:
-
分布越“瘦”、越“尖銳”。數據點更集中在中心?μ?附近。
-
添加的噪聲(在差分隱私中)幅度越小,數據可用性越高,但隱私保護越弱。
-
-
在公式中,b出現在分母?
?和指數部分的分母?
中。它同時影響峰值高度和衰減速度。
-
-
-
這個系數確保了整個概率密度函數曲線下的總面積等于 1(這是所有概率分布的基本要求)。
-
當?
時,指數項
,所以峰值密度就是
-
-
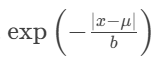 (指數衰減項):
(指數衰減項):-
這是公式的核心部分,它描述了概率密度如何隨著點?x遠離中心?μ而衰減。
-
-
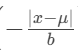 :?計算標準化的距離。距離?μ越遠,這個值越負。
:?計算標準化的距離。距離?μ越遠,這個值越負。 -
exp?(...):?指數函數。輸入值越負,輸出值越小。
-
關鍵特性:?這個項導致概率密度隨著?
-
靠近中心?μ的點出現的概率密度相對較高。
-
遠離中心的點出現的概率密度會迅速下降,但永遠不會降到零(“重尾”特性)。
-
相比于同樣方差的高斯分布(正態分布),拉普拉斯分布在中心更“尖”,在尾部更“厚”(有更大的概率產生遠離均值的值)。這是它適合差分隱私的關鍵:偶爾添加較大的噪聲能有效掩蓋個體貢獻。?
-
-
2. 實現原理
拉普拉斯噪聲在差分隱私中的實現原理緊密依賴于差分隱私的定義和全局敏感度的概念。
-
定義全局敏感度 (Δf):
-
這是拉普拉斯機制的核心輸入參數。
-
對于一個查詢函數?
f(例如求和、平均值、計數、直方圖等),其全局敏感度?Δf?定義為:對于任意兩個相鄰數據集?D?和?D'(它們僅在一個個體的數據記錄上不同),查詢結果變化的最大絕對值。?|
-
意義:?
Δf?衡量了單個個體的數據所能引起的最大影響。它是數據本身和查詢函數的屬性,與數據集的具體內容無關。
-
-
確定隱私預算 (ε):
-
ε是差分隱私的核心參數,稱為隱私預算或隱私損失參數。 -
ε的值由數據發布者設定,代表了愿意承受的隱私風險級別。ε越小(例如 0.1, 1),提供的隱私保護越強(噪聲越大);ε越大(例如 10),提供的隱私保護越弱(噪聲越小),數據越準確。
-
-
計算噪聲尺度 (b):
-
噪聲的尺度參數?
b?由全局敏感度Δf和隱私預算ε共同決定:
b=Δf/ε -
原理:?為了滿足 ε-差分隱私,需要確保添加的噪聲強度足以“掩蓋”單個個體數據可能帶來的最大影響 (
Δf)。ε控制了這個掩蓋的程度。ε越小,要求掩蓋得越好,需要的噪聲 (b) 就越大(b =Δf/ε變大)。
-
-
生成并添加噪聲:
-
從以?
μ=0?和?b=Δf/ε為參數的拉普拉斯分布中獨立地抽取一個隨機樣本?L。 -
將這個噪聲樣本?
L?加到真實的查詢結果?f(D)?上:
M(D) = f(D) + L -
M(D)?就是滿足 ε-差分隱私的、帶有噪聲的發布結果。
-
3. 能解決什么問題?
拉普拉斯噪聲是解決如何在公開發布數據或數據分析結果時,嚴格保護其中個體隱私這一核心問題的關鍵技術。具體來說:
-
防止成員推斷攻擊:?攻擊者無法根據發布的(帶噪)結果,可靠地推斷出某個特定個體是否存在于原始數據集中。
-
防止屬性推斷攻擊:?攻擊者無法根據發布的(帶噪)結果,可靠地推斷出某個特定個體在數據集中的敏感屬性值(即使知道該個體在數據集中)。
-
提供可量化的隱私保證:?差分隱私(通過拉普拉斯機制實現)提供了嚴格的、可證明的數學隱私保證(ε-差分隱私)。隱私預算?
ε?的大小直接量化了隱私泄露的風險上限。 -
在隱私和效用之間實現可控的權衡:?通過調整?
ε,數據發布者可以明確地在個體隱私保護強度 (ε?小) 和發布結果的統計準確性/可用性 (ε?大) 之間進行權衡。
4. 應用場景
-
人口普查和官方統計機構:
-
發布人口統計數據(如不同地區、年齡段、職業的收入分布、教育水平等),保護公民個人隱私。
-
發布經濟指標。
-
-
醫療健康研究:
-
共享匿名的醫療數據集或聚合統計結果(如某種疾病的患病率、不同治療方案的有效性比較),用于公共健康研究或藥物研發,同時保護患者隱私。
-
醫院間共享去識別化的統計數據。
-
-
互聯網公司和服務提供商:
-
用戶行為分析:?收集聚合信息了解用戶如何使用產品(如某個功能的點擊率、不同用戶群的停留時長),用于改進產品,而不追蹤個體行為。例如,Google 的 RAPPOR 項目。
-
A/B 測試:?比較不同產品版本的效果(如轉化率)時保護個體用戶隱私。
-
個性化推薦/廣告的隱私保護:?在訓練推薦模型或計算用戶畫像相關統計量時加入噪聲。
-
-
位置數據服務:
-
發布熱門地點、人流密度地圖(如交通流量、商場人流量),保護單個用戶的行蹤軌跡隱私。
-
-
金融行業:
-
在滿足隱私法規的前提下,金融機構之間或向監管機構共享聚合的金融風險統計數據。
-
-
機器學習:
-
隱私保護機器學習:?在訓練過程中(如目標函數、梯度)添加拉普拉斯噪聲,使得最終發布的模型不會泄露訓練數據中個體的敏感信息。例如,差分隱私隨機梯度下降。
-
發布訓練好的模型參數(尤其是基于敏感數據訓練的模型)。
-
-
數據庫查詢:
-
對包含敏感信息的數據庫提供對外查詢接口,對每個查詢結果添加拉普拉斯噪聲以滿足差分隱私,防止通過多次查詢進行隱私推斷攻擊。
-

)


![[FreeRTOS- 野火] - - - 臨界段](http://pic.xiahunao.cn/[FreeRTOS- 野火] - - - 臨界段)






)

:核心概念 + 命令詳解 + 部署案例】)
)
 - 解堆 (行 -> 列))



