文章目錄
- 速覽
- 摘要
- 1 引言
- 2 相關工作
- 視頻異常檢測與數據集
- 視頻多模態大語言模型
- 具備推理能力的多模態大語言模型
- 3 方法:Vad-R1
- 3.1 從感知到認知的思維鏈(Perception-to-Cognition Chain-of-Thought)
- 3.2 數據集:Vad-Reasoning
- 3.3 AVA-GRPO
- 3.4 訓練流程(Training Pipeline)
- 4 實驗
- 4.1 實驗設置(Experimental Settings)
- 4.2 主要結果(Main Results)
- 4.3 消融實驗(Ablation Studies)
- 4.4 質性分析(Qualitative Analyses)
- 5 結論
- A 附錄概述(Summary of Appendix)
- B 所提出的 Vad-Reasoning 數據集
- B.1 標注流程(Annotation Pipeline)
- B.2 統計分析與對比(Statistical Analysis and Comparison)
- B.3 示例(Examples)
- C 實現細節(Implementation Details)
- C.1 提示設計(Prompt)
- C.2 AVA-GRPO 的訓練過程(Training Process of AVA-GRPO)
- C.3 更多實驗細節(More Experimental Details)
- C.4 在 VANE 基準上的評估(Evaluation on VANE Benchmark)
- D 更多實驗結果(More Experimental Results)
- D.1 基于大語言模型的評估(LLM-Guided Evaluation)
- D.2 更多輸入幀數量的實驗(Experiments on More Input Tokens)
- D.3 更多消融實驗(More Ablation Studies)
- D.4 訓練曲線(Training Curves)
- D.5 更多定性結果(More Qualitative Results)
- E 影響與局限性(Impact and Limitation)
Vad-R1: Towards Video Anomaly Reasoning via Perception-to-Cognition Chain-of-Thought
1中山大學深圳校區;2哈爾濱工業大學(深圳);3香港理工大學
arxiv’25’05
速覽
Vad-R1 提出“感知-認知”推理鏈、構建首個含 CoT 的 VAR 數據集,并以 AVA-GRPO 實現弱標簽下的自驗證強化學習,顯著提升異常檢測與深度推理能力。
動機
視頻異常檢測(VAD) 傳統上僅回答“有沒有異常”,而對 異常發生的原因、過程與后果 缺乏深度理解。
現有使用VLM/MLLM-輔助或直接執行異常檢測與理解的方法總體仍停留在淺層描述,模型無法給出連貫、可解釋的推理鏈。
挑戰
數據層面:公開數據集中缺少結構化推理注釋:大多數只有視頻級標簽或簡短描述,導致模型難以學習“先感知再推理”的完整邏輯。
訓練層面:如何在只擁有弱標簽的大量視頻上繼續提升模型推理質量,而不過度依賴人工標注。
數據集
設計 Perception-to-Cognition 四步推理鏈(全局感知 → 局部感知 → 淺層認知 → 深層認知),構建Vad-Reasoning數據集,可同時用于監督微調與強化學習
- 8 k+ 視頻
- 1755 條帶高質 CoT (SFT 子集)
- 6 k+ 條僅弱標簽 (RL 子集)
方法
在 GRPO 基礎上加入 異常驗證獎勵(剪視頻再判定)
- Case 1(正向獎勵):如果模型預測為異常,剪掉異常片段后視頻變正常,說明它準確定位了異常,給予正向獎勵 +0.5;
- Case 2(負向懲罰):如果模型預測為正常,但僅剪掉視頻開頭或結尾后就變異常,說明它原本憑少量幀判斷,給予懲罰 –0.2。
實驗
主要圍繞3個問題進行驗證:
Q1:推理是否能夠提升異常檢測性能? 通過比較無推理、隨機推理與結構化推理的性能
Q2:Vad-R1 在異常推理和檢測方面的表現如何? 通過與開源模型、推理專家模型、VAD專家模型進行比較
Q3:如何獲得推理能力? 通過消融實驗,單獨SFT、GRPO 不如 先SFT再GRPO
意義
首次在視頻異常場景下驗證了結構化 CoT + 自驗證 RL的可行性,為 MLLM 在安全監控、無人駕駛等任務上的可解釋應用奠定基礎。
摘要
近年來,多模態大語言模型(Multimodal Large Language Models, MLLMs)在推理能力方面取得了顯著進展,展現出在處理復雜視覺任務中的有效性。然而,現有基于 MLLM 的視頻異常檢測(Video Anomaly Detection, VAD)方法仍局限于淺層的異常描述,缺乏深層次的推理能力。
本文提出了一項新任務,稱為視頻異常推理(Video Anomaly Reasoning, VAR),旨在通過要求 MLLM 在回答前顯式思考,來實現對視頻中異常事件的深入分析與理解。為此,我們提出了 Vad-R1,一個端到端的基于 MLLM 的 VAR 框架。
具體而言,我們設計了一個“從感知到認知的思維鏈”(Perception-to-Cognition Chain-of-Thought, P2C-CoT),模擬人類識別異常的過程,引導 MLLM 逐步進行異常推理。在結構化的 P2C-CoT 指導下,我們構建了一個專為 VAR 設計的數據集 Vad-Reasoning。
此外,我們提出了一種改進的強化學習算法 AVA-GRPO,該算法通過有限標注下的自驗證機制,顯式激勵 MLLM 的異常推理能力。實驗結果表明,Vad-R1 在多個 VAD 和 VAR 任務上均實現了卓越性能,顯著超越了開源和專有模型。
代碼與數據集將發布于:https://github.com/wbfwonderful/Vad-R1。
1 引言
視頻異常檢測(Video Anomaly Detection, VAD)旨在識別視頻中的異常事件,已廣泛應用于監控系統 [49] 和自動駕駛 [37, 75] 等多個領域。傳統的 VAD 方法主要分為兩類:半監督方法和弱監督方法。半監督方法 [75, 32, 20, 34, 19, 17] 致力于建模正常事件的特征,而弱監督方法 [66, 49, 18, 17, 24, 90, 21] 僅提供視頻級標簽。隨著視覺-語言模型的發展,一些研究開始引入語義信息以增強 VAD [60, 68, 67, 76, 7]。然而,傳統方法僅停留在檢測層面,缺乏對異常的理解與解釋。
近年來,大語言模型在推理能力方面的進展引發了廣泛關注 [41, 9, 54]。與日常對話不同,推理要求模型在回答前進行思考,從而實現因果分析和深入理解。特別地,DeepSeek-R1 證明了強化學習(Reinforcement Learning, RL)在激發模型推理能力方面的有效性 [9]。與此同時,一些研究也開始嘗試將推理能力擴展到多模態領域 [53, 56]。
盡管對推理能力的興趣日益增長,但現有基于多模態大語言模型(Multimodal Large Language Models, MLLMs)的 VAD 方法在推理方面仍表現不足。這些方法可根據 MLLM 的角色分為兩類:一類將 MLLM 作為輔助模塊 [36, 84, 85, 11],用于在分類器預測異常置信度之后提供補充解釋。在此框架下,異常理解是檢測之后的一個步驟,MLLM 的輸出不會直接促進異常檢測。另一類方法雖然嘗試讓 MLLM 直接執行異常檢測與理解 [50, 38, 73, 80, 13, 12],但 MLLM 通常只生成異常描述或基于視頻內容進行簡單問答,缺乏思考與分析能力。因此,在 VAD 任務中,推理仍然是一個尚未充分探索的問題。
為彌補這一差距,我們提出了一項新任務:視頻異常推理(Video Anomaly Reasoning, VAR),旨在賦予 MLLM 結構化、逐步推理視頻中異常事件的能力。與現有的視頻異常檢測或理解任務相比,VAR 更加關注深層次分析,模擬人類的認知過程,從而實現上下文理解、行為解釋和規范違背分析。為此,我們提出了 Vad-R1,這是首個端到端的基于 MLLM 的 VAR 框架,其在生成答案之前顯式地進行推理。
然而,在視頻異常任務中實現推理面臨兩個主要挑戰。首先,現有 VAD 數據集缺乏結構化推理標注,無法滿足訓練與評估推理模型的需求。其次,如何有效訓練模型以獲得推理能力仍是一個開放性難題。不同于具有明確目標的任務,開放式 VAR 要求模型執行多步推理,這使得難以定義清晰的訓練目標或直接指導推理過程。
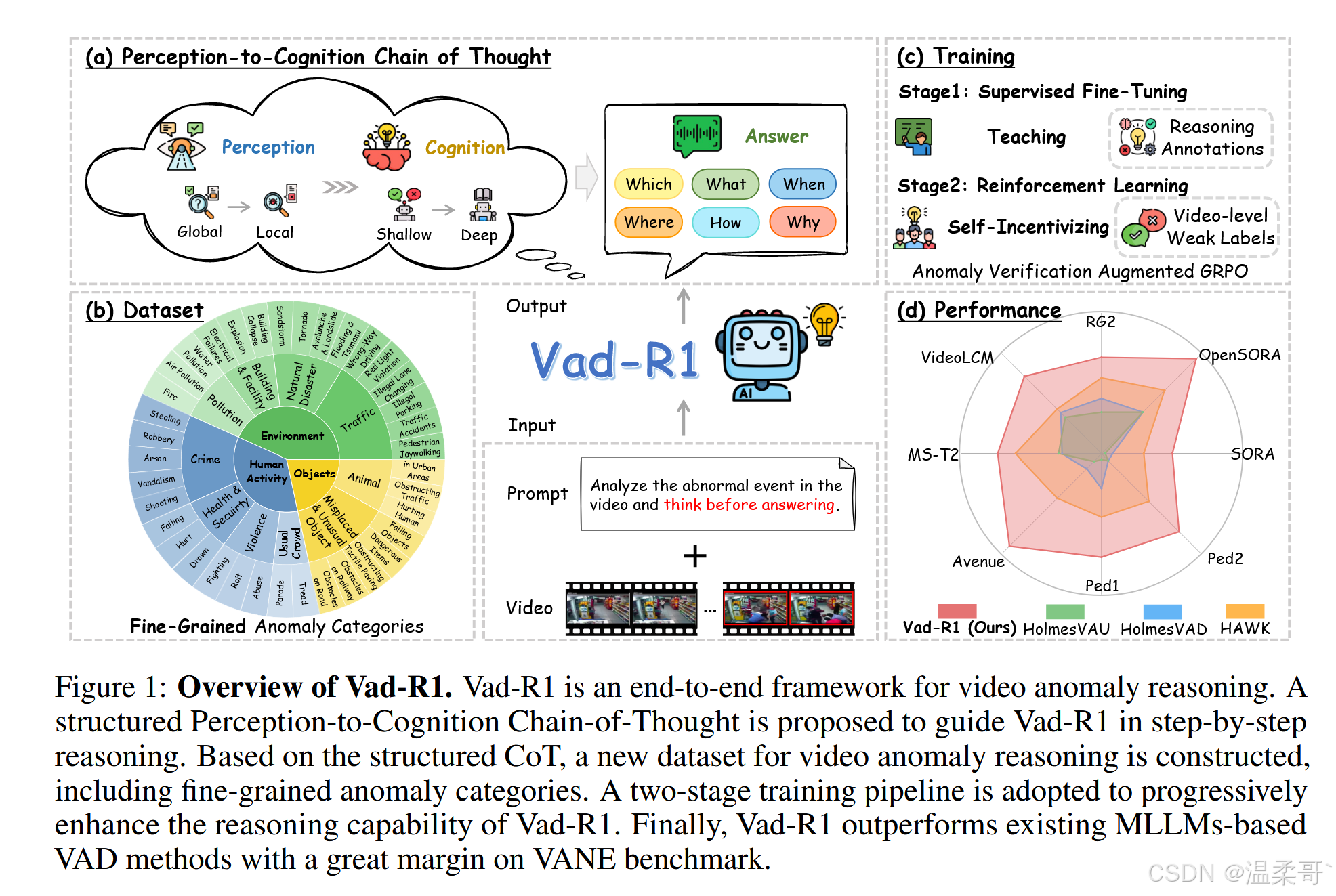
為了解決第一個挑戰,我們設計了一個結構化的“從感知到認知的思維鏈”(Perception-to-Cognition Chain-of-Thought, P2C-CoT)用于視頻異常推理,如圖 1(a) 所示。該結構借鑒了人類理解視頻異常的過程,首先引導模型從視頻的整體環境感知,逐步聚焦至可疑片段。在感知完成后,模型將基于視覺線索從淺層到深層逐級認知。最終,模型將輸出分析結果作為答案,包括異常類別、異常描述、異常發生的時間范圍、空間位置等。
基于上述思維鏈,我們構建了 Vad-Reasoning,這是一個專為 VAR 任務設計的數據集,涵蓋了細粒度的異常類別,如圖 1(b) 所示。Vad-Reasoning 包含兩個互補子集:一個子集包含由專有模型逐步生成的 P2C-CoT 注釋視頻,另一個子集包含數量更多但僅提供視頻級弱標注的視頻,目的是降低標注成本。
為了解決第二個挑戰,受 DeepSeek-R1 成功經驗的啟發,我們提出了一個如圖 1(c) 所示的兩階段訓練流程。在第一階段,通過監督微調(Supervised Fine-Tuning, SFT)使基礎 MLLM 具備基本的異常推理能力;在第二階段,使用我們提出的 AVA-GRPO(Anomaly Verification Augmented Group Relative Policy Optimization)強化學習算法進一步激勵模型的推理能力。
該算法是 GRPO [47] 的擴展版本,專為 VAR 任務設計。在強化學習過程中,模型首先生成一組推理結果。基于這些推理結果,對原始視頻進行時間裁剪,裁剪后的視頻再次輸入模型以生成新的推理輸出。隨后,比較兩組推理結果,若滿足預設條件,則給予額外的異常驗證獎勵。AVA-GRPO 通過這種自驗證機制,在僅有有限標注的情況下,有效提升 MLLM 的視頻異常推理能力。
總結而言,本文的主要貢獻如下:
-
我們提出了 Vad-R1,一個新穎的端到端 MLLM 框架,旨在對視頻異常事件進行深入分析與理解。
-
我們設計了結構化的 P2C-CoT,并據此構建了包含兩個子集的專用視頻異常推理數據集 Vad-Reasoning。同時,提出改進的強化學習算法 AVA-GRPO,通過自驗證機制激勵 MLLM 的推理能力。
-
實驗結果表明,Vad-R1 在多個評估場景中均表現出卓越性能,在異常檢測和推理任務中全面超越現有的開源及專有模型。
2 相關工作
視頻異常檢測與數據集
視頻異常檢測(Video Anomaly Detection)旨在定位視頻中的異常事件。根據訓練數據的不同,傳統的 VAD 方法通常可分為兩大類:半監督方法 [75, 32, 20, 34, 19, 17, 45, 72, 79] 和弱監督方法 [66, 49, 18, 17, 24, 90, 21, 91]。此外,一些研究嘗試引入文本描述以增強檢測性能 [60, 68, 67, 76, 7, 8]。近年來,越來越多的研究開始將多模態大語言模型(MLLMs)引入 VAD 以提升理解與解釋能力 [36, 50, 38, 73, 80, 84, 85, 11, 13, 12]。然而,目前的研究仍停留在淺層理解,缺乏對推理能力的深入探索。本文提出一個端到端的框架,旨在增強視頻異常任務中的推理能力。
此外,現有的 VAD 數據集主要提供粗粒度的類別標簽 [49, 66, 37, 1] 或異常事件描述 [13, 12, 50, 78],缺乏對推理過程的標注。為彌補這一空白,我們提出了結構化的“從感知到認知的思維鏈”(Perception-to-Cognition Chain-of-Thought),并構建了一個專門用于視頻異常推理的數據集,提供逐步的 CoT 標注。
視頻多模態大語言模型
視頻多模態大語言模型提供了一種交互式的方式來理解視頻內容。早期的工作通過映射網絡對視覺與文本 token 進行對齊,將視覺編碼器集成進大型語言模型中 [25, 30, 39, 83, 87]。與靜態圖像相比,視頻包含更多冗余信息,因此部分研究探索了 token 壓縮機制以獲取更長上下文 [29, 71, 86, 23]。此外,近期也有研究探索了在線流式視頻的理解 [6, 10, 74, 69]。盡管如此,這些方法仍局限于視頻理解層面,缺乏對推理能力的探索。
具備推理能力的多模態大語言模型
提升多模態大語言模型(MLLMs)推理能力已成為一個主要研究方向。一些研究提出多階段推理框架與大規模 CoT 數據集來增強 MLLMs 的推理能力 [70, 59, 33]。近期,DeepSeek-R1 [9] 展示了強化學習在提升推理能力方面的潛力,激發了后續在多模態領域的相關工作 [22, 81]。在視頻領域,一些研究也使用 RL 來提升空間推理 [28]、時間推理 [64] 和一般因果推理能力 [14, 88]。本文則聚焦于視頻異常推理任務。
3 方法:Vad-R1
概述
本節中我們介紹 Vad-R1,這是一個新穎的端到端基于多模態大語言模型(MLLM)的框架,用于視頻異常推理(VAR)任務。Vad-R1 的推理能力源于一個兩階段的訓練策略:首先在帶有高質量 CoT(Chain-of-Thought)注釋的視頻上進行監督微調(SFT),然后使用 AVA-GRPO 算法進行強化學習(RL)。
我們首先在第 3.1 節中介紹所提出的 P2C-CoT(Perception-to-Cognition Chain-of-Thought);隨后在第 3.2 節中基于該思維鏈構建新數據集 Vad-Reasoning;接著在第 3.3 節中介紹改進后的 RL 算法 AVA-GRPO;最后在第 3.4 節中介紹 Vad-R1 的整體訓練流程。
3.1 從感知到認知的思維鏈(Perception-to-Cognition Chain-of-Thought)
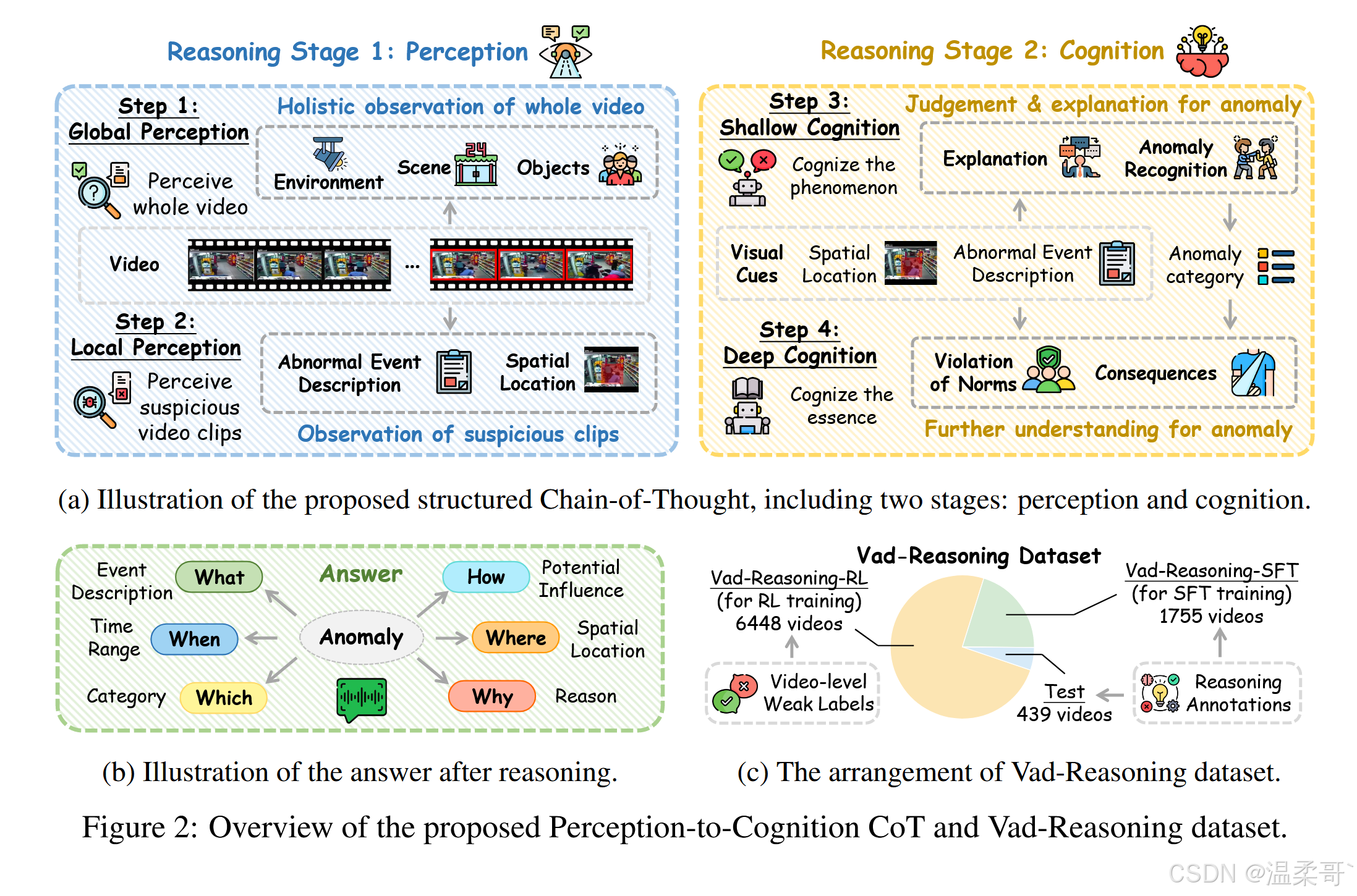
當人類理解一段視頻時,通常會首先觀察其中發生的事件,然后再基于視覺觀察發展出更深層次的理解。受此啟發,我們為視頻異常推理任務設計了一個結構化的“從感知到認知的思維鏈”(Perception-to-Cognition Chain-of-Thought, P2C-CoT)。該思維鏈從感知(Perception)逐步過渡到認知(Cognition),共包含兩個階段、四個步驟,如圖 2(a) 所示,最終形成如圖 2(b) 中的簡潔回答。
感知(Perception)
在觀看視頻時,人類通常先對整體場景與環境進行全局觀察,然后再將注意力轉向具體的物體或異常事件。與此一致,P2C-CoT 的感知階段體現了從全局觀察到局部聚焦的轉變。模型起初需關注整個環境,描述場景并識別視頻中的對象,該步驟要求模型具備對視頻中“正常性”的全面理解。在此基礎上,模型再聚焦于偏離正常性的事件,識別“發生了什么、何時發生、在哪里發生”。
認知(Cognition)
在觀察視頻內容之后,人類通常會基于視覺線索識別異常事件,并進一步推理其可能的后果。類似地,P2C-CoT 的認知階段從淺層認知逐步深入到深層認知。模型首先判斷事件是否異常,并結合視覺證據解釋其異常性;隨后模型需進行更高層次的推理,分析異常事件的成因、違背的社會預期,以及可能導致的后果。
回答(Answer)
如圖 2(b) 所示,在完成上述推理過程后,模型需對視頻中的判斷結果做出簡潔總結。最終回答應包含與異常相關的關鍵要素,包括異常類別(Which)、事件描述(What)、時空定位信息(When & Where)、異常原因(Why)及其潛在影響(How)。
值得注意的是,對于正常視頻,P2C-CoT 將被簡化為兩個步驟。詳見附錄 B。
3.2 數據集:Vad-Reasoning
視頻采集(Video Collection)
現有的 VAD 數據集普遍缺乏對推理過程的標注。為構建一個更適用于 VAR 的數據集,我們從以下兩個方面進行考量。
一方面,我們希望該數據集能夠涵蓋廣泛的真實生活場景。類似 HAWK [50],我們從已有 VAD 數據集中采集視頻,涵蓋的場景包括:監控下的犯罪行為(UCF-Crime [49])、鏡頭下的暴力事件(XD-Violence [66])、交通場景(TAD [37])、校園環境(ShanghaiTech [32])以及城市街景(UBnormal [1])。此外,我們還從 ECVA [12],一個多場景基準數據集中收集視頻。
另一方面,我們致力于擴大異常類別的覆蓋范圍。為此,我們定義了三類主要異常類型的分類體系:人類行為異常(Human Activity Anomaly)、環境異常(Environments Anomaly) 和 物體異常(Objects Anomaly)。每類被進一步細分為若干子類。隨后,我們基于已有數據集從互聯網補充采集視頻以擴充異常種類。
最終,Vad-Reasoning 數據集共包含 8203 個訓練視頻和 438 個測試視頻。如圖 2(c) 所示,訓練集被劃分為兩個子集:
- Vad-Reasoning-SFT:包含 1755 個帶有高質量推理過程標注的視頻;
- Vad-Reasoning-RL:包含 6448 個僅具有視頻級弱標簽的視頻。
標注過程(Annotation)
為構建 Vad-Reasoning 數據集,我們設計了一個多階段的標注流程,使用了兩個專有模型:Qwen-Max [55] 與 Qwen-VL-Max [57]。為了確保 P2C-CoT 標注涵蓋視頻中的所有關鍵信息,我們遵循高幀信息密度原則 [77]。
具體地,我們首先通過 Qwen-VL-Max 生成視頻幀的密集描述。然后將這些幀級描述輸入至 Qwen-Max,以不同提示詞逐步生成思維鏈(CoT)的各個階段內容。更多細節請見附錄 B。
250530:高幀信息密度強調的是 “進入推理過程中的幀必須有效、濃縮且富含關鍵線索”,它并不要求所有幀都攜帶異常,而是確保被用來推理的幀(尤其是異常片段)是最具語義價值的。
3.3 AVA-GRPO
原始的 GRPO 在文本推理任務中展現出了良好的效果。然而如前所述,多模態任務(如 VAR)本質上更加復雜。此外,由于標注成本較高,強化學習階段僅能獲取視頻級的弱標簽,這使得僅基于準確性和格式獎勵評估輸出質量變得困難。
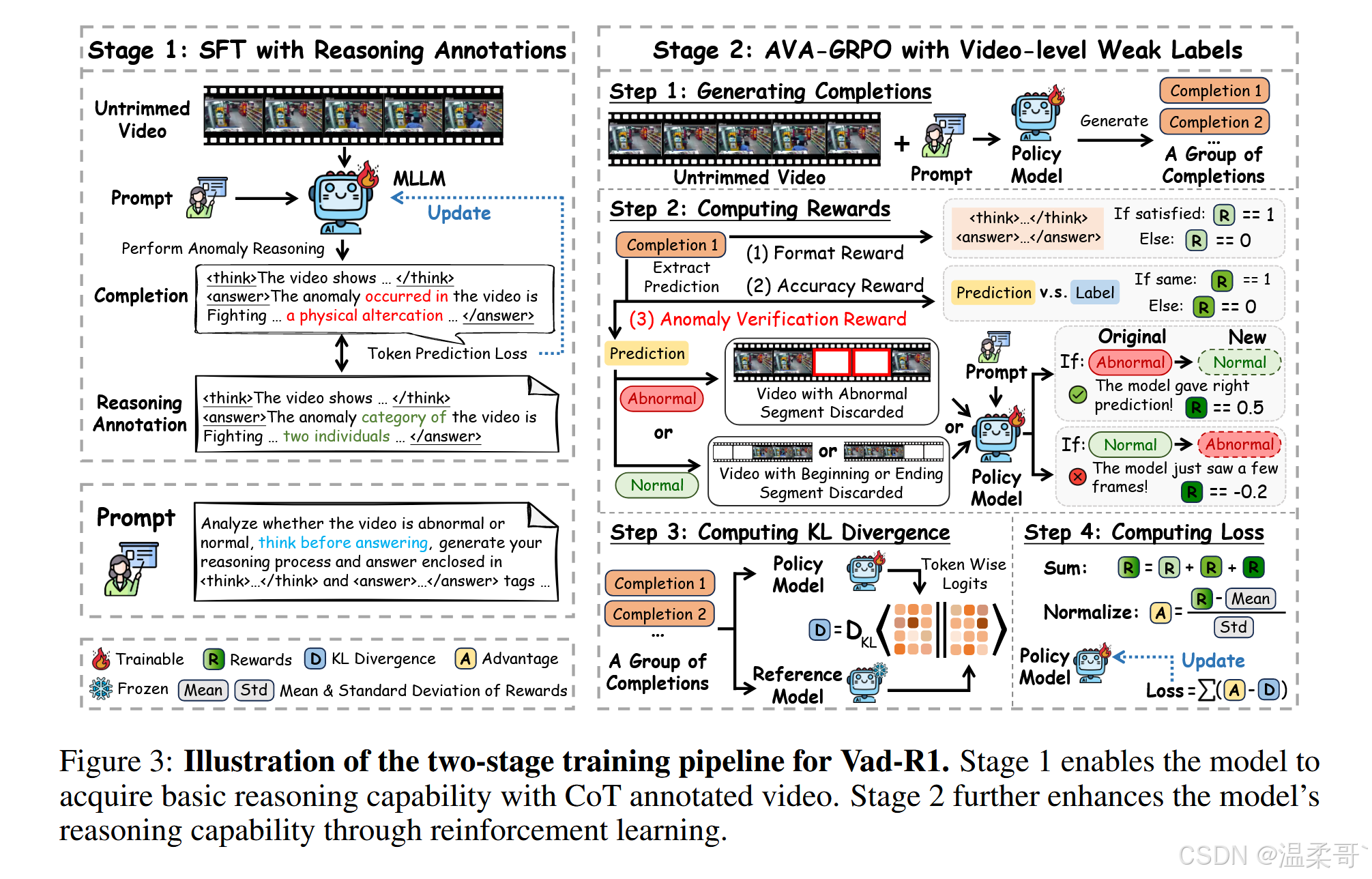
為應對這一挑戰,我們提出了 AVA-GRPO(Anomaly Verification Augmented GRPO),該方法通過自驗證機制引入了額外的獎勵,如圖 3 右側所示。
GRPO 概述
我們首先回顧原始 GRPO [47]。GRPO 去除了值函數模型,旨在最大化答案的相對優勢(relative advantages)。對于一個問題 q q q,模型首先生成一組回答 O = { o i } i = 0 G O = \{ o_i \}_{i=0}^{G} O={oi?}i=0G?,隨后計算對應獎勵 R = { r i } i = 0 G R = \{ r_i \}_{i=0}^{G} R={ri?}i=0G?,并根據預設的獎勵函數對其進行歸一化,計算相對優勢:
A i = r i ? mean ( R ) std ( R ) (1) A_i = \frac{r_i - \text{mean}(R)}{\text{std}(R)} \tag{1} Ai?=std(R)ri??mean(R)?(1)
其中, A i A_i Ai? 表示回答 o i o_i oi? 的相對優勢得分,能夠更有效地評估單個回答的質量以及組內的相對比較。此外,為防止當前策略 π θ \pi_\theta πθ? 與參考策略 π ref \pi_\text{ref} πref? 差異過大,GRPO 引入了 KL 散度正則項。最終目標函數如下:
L GRPO ( θ ) = E { q , O } [ 1 G ∑ i = 1 G ( min ? ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , 1 ? ? , 1 + ? ) A i ) ? β D K L ( π θ ∥ π ref ) ) ] (2) \mathcal{L}_{\text{GRPO}}(\theta) = \mathbb{E}_{\{q, O\}} \left[ \frac{1}{G} \sum_{i=1}^{G} \left( \min\left( \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_\text{old}}(o_i \mid q)} A_i, \text{clip}\left( \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_\text{old}}(o_i \mid q)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right) - \beta \, \mathrm{D}_{\mathrm{KL}}(\pi_\theta \,\|\, \pi_\text{ref}) \right) \right] \tag{2} LGRPO?(θ)=E{q,O}?[G1?i=1∑G?(min(πθold??(oi?∣q)πθ?(oi?∣q)?Ai?,clip(πθold??(oi?∣q)πθ?(oi?∣q)?,1??,1+?)Ai?)?βDKL?(πθ?∥πref?))](2)
其中, π θ ( o i ∣ q ) π θ old ( o i ∣ q ) \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_\text{old}}(o_i \mid q)} πθold??(oi?∣q)πθ?(oi?∣q)? 表示當前策略與舊策略之間的相對變化, clip ( ? , 1 ? ? , 1 + ? ) \text{clip}(\cdot, 1 - \epsilon, 1 + \epsilon) clip(?,1??,1+?) 用于限制變化范圍。
異常驗證獎勵(Anomaly Verification Reward)
GRPO 使用組相對評分替代值函數模型,從而減少了內存消耗與訓練時間。然而,僅依賴準確性和格式獎勵不足以評估視頻異常推理任務中答案的質量。為此,我們提出了 AVA-GRPO,這是 GRPO 的擴展版本,包含一種新的異常驗證獎勵機制。具體而言,如圖 3 右側所示,對于每個生成的答案 o i o_i oi?,首先提取模型預測的視頻異常類別,然后根據該預測對原視頻進行時間裁剪,并將裁剪后的視頻再次輸入模型以生成新的答案。通過比較原始與再生成的答案,決定是否給予額外的異常驗證獎勵。
一方面,若視頻最初被判定為異常,則提取異常事件的預測時間范圍,并從原視頻中裁剪對應片段,生成一個僅包含正常片段的新視頻。該裁剪后的視頻被重新輸入模型進行推理。如果該新視頻被模型判斷為“正常”,說明被裁剪的片段確實是異常的,且模型最初的判斷是正確的。在這種情況下,將給予正獎勵,以增強模型的原始判斷。
另一方面,受 Video-UTR [77] 啟發,我們考慮到視頻多模態語言模型中的“時間黑客(temporal hacking)”現象——模型傾向于僅憑開頭或結尾的少量幀做出預測,而不處理整個視頻序列,這不利于異常事件的識別。因此,若模型最初將視頻判斷為正常,我們將隨機丟棄視頻的起始或末尾片段,并將裁剪后的視頻重新輸入模型。如果此時模型判斷其為異常,則表明模型先前的預測僅基于不足的視覺證據,屬于非期望行為。在這種情況下,將給予負獎勵。
250530:Case 1(正向獎勵):如果模型預測為異常,剪掉異常片段后視頻變正常,說明它準確定位了異常,給予正向獎勵 +0.5;Case 2(負向懲罰):如果模型預測為正常,但僅剪掉視頻開頭或結尾后就變異常,說明它原本憑少量幀判斷,給予懲罰 –0.2。
3.4 訓練流程(Training Pipeline)
我們采用 Qwen-2.5-VL-7B [57] 作為基礎 MLLM。Vad-R1 的訓練流程由兩個階段組成,如圖 3 所示。
第一階段,在 Vad-Reasoning-SFT 數據集上進行監督微調(Supervised Fine-Tuning),該數據集中的視頻帶有高質量的思維鏈(Chain-of-Thought, CoT)標注。
在此階段,模型的能力將從通用的多模態理解逐步轉向視頻異常理解,使其具備基本的異常推理能力。
第二階段,在 Vad-Reasoning-RL 數據集上繼續訓練,并使用我們提出的 AVA-GRPO 強化學習算法。在該階段,由于僅提供視頻級的弱標簽,AVA-GRPO 通過自驗證機制評估模型響應的質量。這一階段旨在使模型擺脫 SFT 階段的模式匹配傾向,從而學習到更具靈活性與可遷移性的異常推理能力。
更多細節可參考附錄 C。
4 實驗
4.1 實驗設置(Experimental Settings)
實現細節(Implementation Details)
Vad-R1 基于 Qwen-2.5-VL-7B [57],采用兩階段訓練流程。在第一階段,使用 Vad-Reasoning-SFT 數據集進行 4 個 epoch 的監督微調(SFT)。第二階段使用 AVA-GRPO 算法在 Vad-Reasoning-RL 數據集上進行 1 個 epoch 的強化學習訓練,該階段僅提供視頻級的弱標簽。所有實驗在 4 塊 NVIDIA A100(80GB)GPU 上進行。更多細節見附錄 C。
評估指標與對比方法(Evaluation Metrics and Baselines)
我們在 VA-Reasoning 的測試集上評估 Vad-R1 的性能,重點關注兩個方面:異常推理與異常檢測。
- 對于異常推理,我們使用 BLEU [43]、METEOR [3] 和 ROUGE [31] 等指標評估推理過程文本的質量。
- 對于異常檢測,我們報告分類的準確率(accuracy)、精確率(precision)、召回率(recall)和 F1 分數,同時評估異常時間定位性能,包括 mIoU 和 R@K。
250530:
🧠 異常推理指標
BLEU:看模型寫的句子里,有多少詞組跟標準答案完全一樣,匹配得多就得分高。
METEOR:不光看詞是不是一樣,還考慮同義詞和詞形變化,判斷更聰明、更寬容。
ROUGE:看模型有沒有覆蓋參考答案里的關鍵信息,越全面得分越高。🚨 異常檢測指標
Accuracy(準確率):模型判斷對的次數除以總次數,越高說明整體判斷越可靠。
Precision(精確率):模型說“異常”的視頻中,實際真異常的比例,高說明誤報少。
Recall(召回率):所有真異常的視頻中,被模型成功識別出來的比例,高說明漏報少。
F1 分數:精確率和召回率的綜合得分,衡量模型是否又準又不漏。🕒 異常定位指標
mIoU(平均交并比):模型畫的異常時間段和真實異常段重合得有多好,越重合得分越高。
R@K(Recall at K):看模型前 K 個預測的異常片段中,有沒有命中真正的異常;比如 R@0.5 就是看有沒有畫對至少一半重合的異常片段。這里的“前 K 個”好像指的是模型對一個輸入視頻的預測可能會有多個異常片段,所以前 K 個是他最自信的 K 個。
此外,為進一步探索 Vad-R1 的能力,我們在 VANE [15] 數據集上進行實驗,該數據集是針對 MLLM 的視頻異常基準集,任務形式為單選題。我們報告各類別的預測準確率。
我們將 Vad-R1 與以下方法進行對比:
- 通用視頻 MLLMs:[25, 30, 39, 83, 87]
- 推理型視頻 MLLMs:[28, 64, 14, 88]
- 專有模型:[56, 40, 52, 51]
- 基于 MLLM 的 VAD 方法:[50, 85, 84]
接下來的章節將圍繞以下問題展開實驗結果分析:
- Q1:推理是否能提升異常檢測性能?
- Q2:Vad-R1 在異常推理和檢測任務中的表現如何?
- Q3:如何獲得推理能力?
4.2 主要結果(Main Results)
Q1:推理是否能夠提升異常檢測性能?
表 1 展示了異常推理的有效性。一方面,我們評估了 Qwen2.5-VL [57] 和 Qwen3 [58] 的性能。如表 1 前兩行所示,與直接回答相比,提示模型按照所提出的“從感知到認知的思維鏈(P2C-CoT)”進行推理可以顯著提升性能。與此同時,我們還評估了隨機推理的效果。在該設置下,性能提升非常有限,甚至低于直接回答。
250530:隨機推理指的是不依照 P2C-CoT(感知到認知的推理鏈條)結構去組織推理過程,而是生成一些沒有邏輯結構或順序混亂的推理內容。
值得注意的是,Qwen3 是一個同時支持推理模式與非推理模式的混合模型,在相同任務下的一致性能差異進一步驗證了所提出的 P2C-CoT 在異常推理與檢測中的有效性。
另一方面,我們比較了使用完整 P2C-CoT 與僅使用最終答案部分訓練的 Vad-R1 的性能。如表 1 第三行所示,當僅使用最終答案進行訓練時,模型性能出現下降。

Q2:Vad-R1 在異常推理和檢測方面的表現如何?
表 2 展示了 Vad-R1 在 Vad-Reasoning 測試集上的異常推理與檢測任務的性能對比結果。Vad-R1 在推理文本質量與異常檢測準確性兩個方面均取得了優異表現。
特別地,Vad-R1 在異常推理能力方面顯著超越了現有的專有 MLLM 推理模型,如 Gemini2.5-Pro、QVQ-Max 和 o4-mini,在 BLEU 分數上分別提升了 0.088、0.091 和 0.127。

此外,與現有的基于 MLLM 的 VAD 方法相比,Vad-R1 在異常推理與檢測方面也表現出更大優勢。表 3 展示了其在 VANE 基準上的結果,Vad-R1 超越了所有基線模型,包括通用視頻 MLLMs 與基于 MLLM 的 VAD 方法。

250530:Gani H, Bharadwaj R, Naseer M, et al. VANE-Bench: Video Anomaly Evaluation Benchmark for Conversational LMMs[C]//Findings of the Association for Computational Linguistics: NAACL 2025. 2025: 3123-3140.
4.3 消融實驗(Ablation Studies)
Q3:如何獲得推理能力?
表 4 展示了不同訓練策略的效果。當直接對基礎模型進行強化學習(RL)而沒有預先進行 SFT(監督微調)時,性能提升是有限的。這表明在缺乏基本推理能力的前提下,模型難以從僅有視頻級弱標簽的 RL 訓練中獲益。
相比之下,引入 SFT 可顯著提升性能,說明結構化的 CoT(Chain-of-Thought)標注能夠有效地賦予模型基礎的異常推理能力。值得注意的是,SFT 與 RL 的組合實現了最佳性能。這一結果與 DeepSeek-R1 [9] 的結論一致,即 SFT 階段為模型提供了基礎的推理能力,而 RL 階段則進一步強化該能力。

4.4 質性分析(Qualitative Analyses)
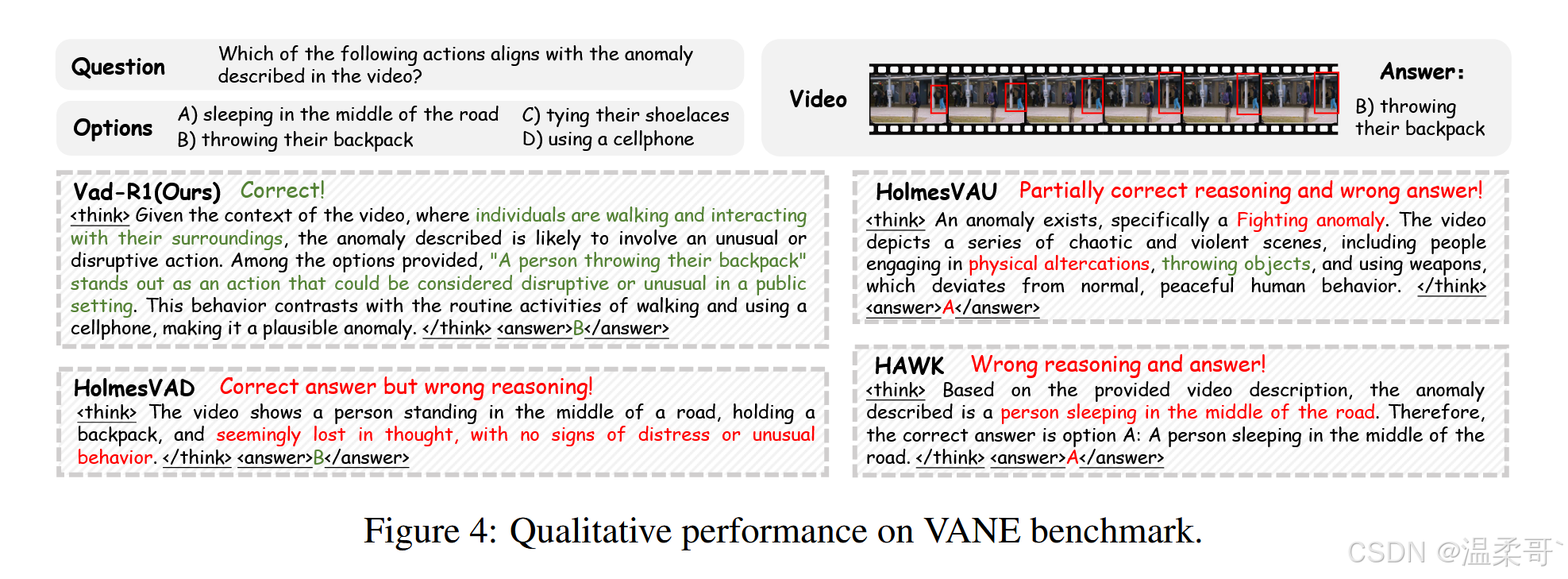
如圖 4 所示,Vad-R1 在復雜環境中展現了強大的推理能力,并能夠正確識別視頻中的異常事件。相比之下,HolmesVAU 的推理過程部分正確,導致判斷錯誤,而 HolmesVAD 的判斷雖然正確,但推理過程不準確。更多質性結果請見附錄 D。
5 結論
本文提出了 Vad-R1,一個新穎的端到端基于 MLLM 的視頻異常推理框架,旨在實現對視頻異常事件的深入分析與理解。Vad-R1 通過結構化的思維鏈(Chain-of-Thought)實現異常推理,該過程從感知逐步過渡到認知。
Vad-R1 的推理能力來源于兩階段訓練策略:在具有 CoT 注釋的視頻上進行的監督微調(SFT),以及結合異常驗證機制的強化學習(RL)。實驗結果表明,Vad-R1 在異常檢測與推理任務中表現出卓越性能。
A 附錄概述(Summary of Appendix)
本附錄為正文提供補充信息。首先,我們詳細介紹了所提出的 Vad-Reasoning 數據集,包括其構建過程、統計分析及示例。隨后,我們進一步提供了更多實驗細節,包括提示詞設計、參數設置及計算資源配置。此外,附錄還包含了更多實驗結果及可視化內容。最后,我們討論了本工作的潛在影響與局限性。
B 所提出的 Vad-Reasoning 數據集
B.1 標注流程(Annotation Pipeline)
Vad-Reasoning 的訓練集包含兩個子集:Vad-Reasoning-SFT 與 Vad-Reasoning-RL。
對于 Vad-Reasoning-RL,我們保留原始數據集的標注,并將其壓縮為視頻級別的弱標簽(異常或正常)。
對于 Vad-Reasoning-SFT,我們設計了一個基于所提出的 P2C-CoT 的多階段標注流程,如圖 5 所示。
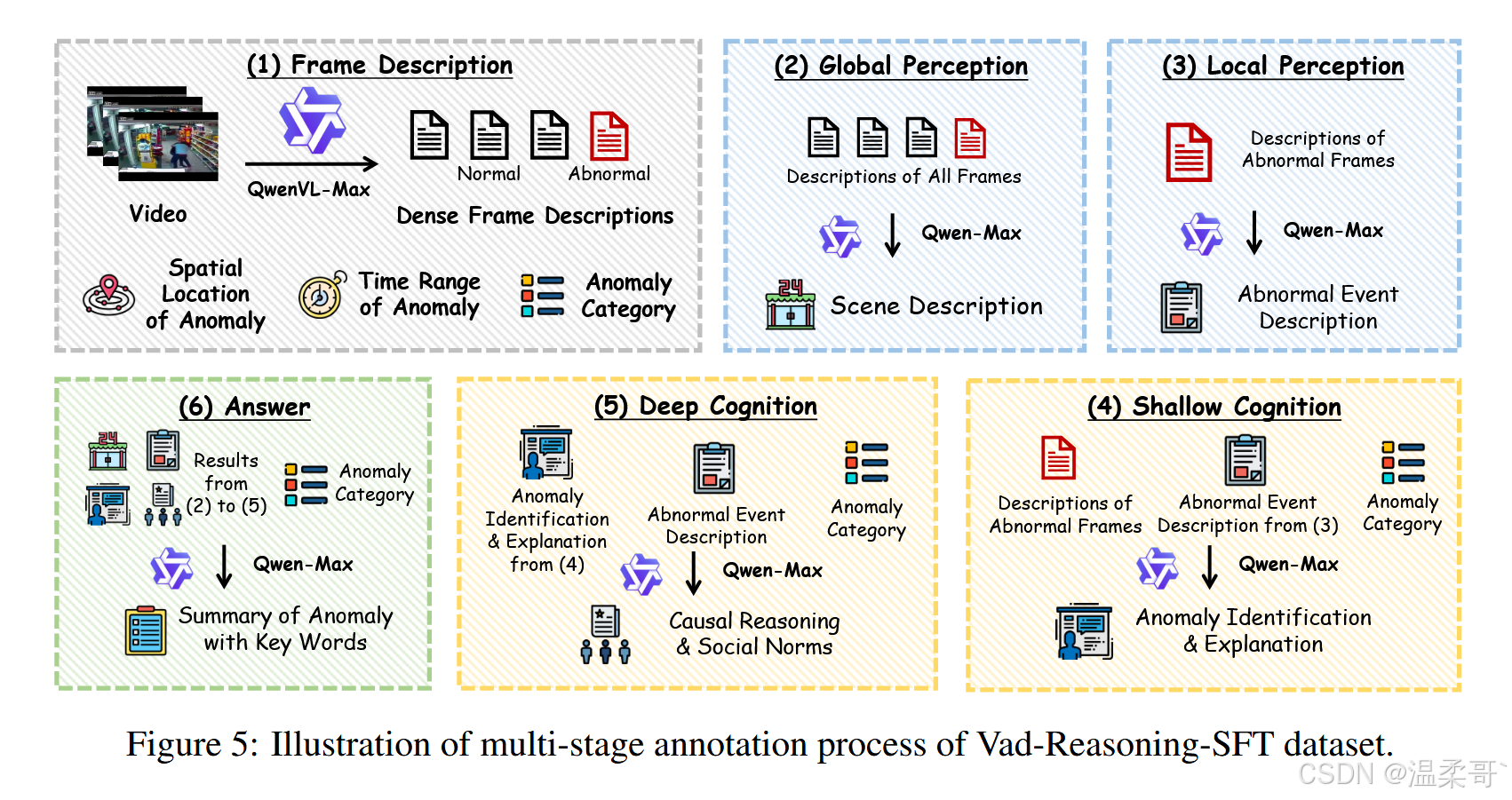
Frame Description(幀描述)
每段視頻首先被標注:(1) 異常的大致空間位置,(2) 異常的時間跨度,(3) 細粒度的異常類別。隨后,視頻按幀間隔 16 被分解為若干幀,并輸入 Qwen-VL-Max 生成詳細描述。
250530:這些標注到底是人標的還是模型標的,如果是模型標的,是先讓VL輸出大致空間位置、事件跨度、異常類別,然后再讓VL基于這個信息輸出幀描述嗎?
Global Perception(全局感知)
將所有幀的描述按時間順序拼接,并送入 Qwen-Max,生成涵蓋環境、物體和動作的整體場景描述。需要注意,此階段僅描述正常模式。
Local Perception(局部感知)
將對應于異常幀的描述提取出來,再次輸入 Qwen-Max,生成對異常事件的描述。但該階段仍停留在“感知”層面,不涉及對異常性的判斷。
Shallow Cognition(淺層認知)
基于異常幀的描述與對應異常類別,Qwen-Max 在此階段需完成異常的初步識別與簡要解釋。
Deep Cognition(深層認知)
在淺層認知的基礎上,Qwen-Max 對視頻中的異常進行更深入的推理,輸出更詳盡的異常事件描述及其對應類別。
Answer(答案)
最后,Qwen-Max 將以上各階段輸出整合生成簡潔摘要,并用定義好的標簽包裹關鍵詞,例如使用 <which></which> 表示預測的異常類型,<what></what> 表示異常事件的描述等。
標注規范
為確保 Qwen-VL-Max 與 Qwen-Max 生成的標注具有高質量和倫理合規性,我們在整個標注流程中遵循以下準則:
- Relevance(相關性):所有回答必須直接關聯視頻的可視內容,嚴禁出現無關假設或幻覺內容。
- Objectivity(客觀性):所有回答必須基于可觀察的視覺證據,避免主觀推測。
- Neutrality(中立性):不得包含地理位置、種族、性別、政治觀點或宗教信仰等偏向性內容。
- Non-discrimination(反歧視):嚴禁使用任何帶有偏見、歧視或冒犯性的語言。
- Style(風格):語言應簡潔、中性、通用,確保普遍可讀性與可用性。
- Conciseness(簡明性):每條回答應控制在 4 至 6 句之間,以保持表達清晰聚焦。
B.2 統計分析與對比(Statistical Analysis and Comparison)
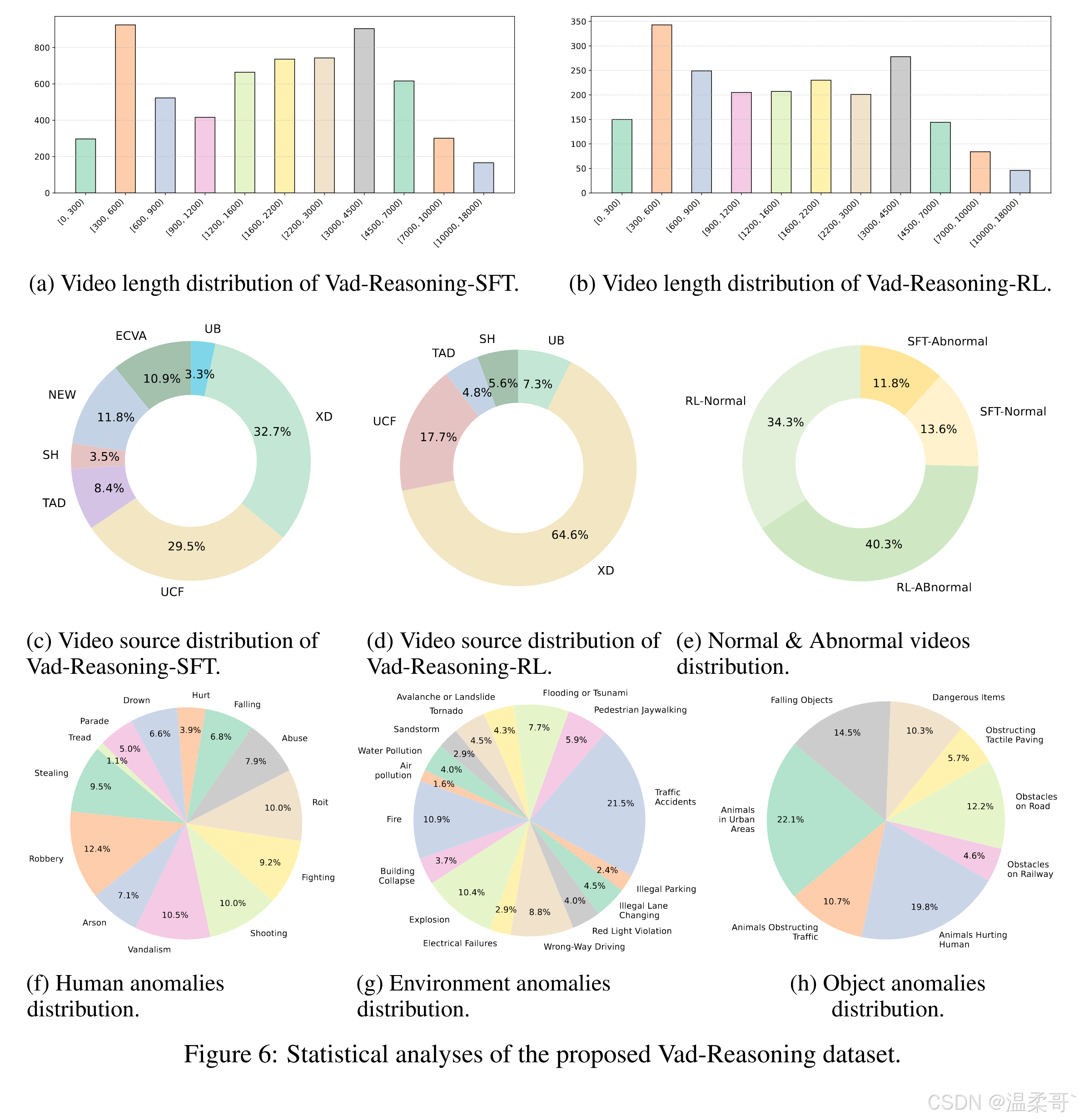
我們將 Vad-Reasoning 與現有的視頻異常檢測與理解數據集進行了對比,如表 5 和表 6 所示。Vad-Reasoning 總共包含 8641 個視頻,涵蓋 3400 萬幀和超過 360 小時的視頻時長,是當前最大規模的視頻異常理解基準之一。

此外,Vad-Reasoning-SFT 提供了細粒度的思維鏈(CoT)標注,顯式模擬人類在異常事件上的推理過程,平均每段標注長度為 260 個詞。相比之下,近期的視頻異常理解數據集如 CUVA [13] 和 ECVA [12] 雖然也描述了異常的成因與影響,但它們的標注往往是零散、割裂的,缺乏系統結構與邏輯銜接。而 Vad-Reasoning-SFT 提供的是結構清晰、邏輯連貫的異常推理標注。
圖 6 對 Vad-Reasoning 數據集進行了全面的統計分析。圖 6(a) 與 6(b) 展示了視頻時長的整體分布,整體分布較為均勻。圖 6(c) 與 6(d) 顯示,大部分視頻來自 UCF-Crime [49] 與 XD-Violence [66],另有約 10% 的視頻來源于互聯網。
圖 6(e) 展示了正常與異常視頻在兩個子集中的分布比例,整體較為平衡。圖 6(f)-(h) 則呈現了細粒度異常類別的分布情況。
B.3 示例(Examples)
我們在圖 7 和圖 8 中提供了兩個 Vad-Reasoning 數據集的示例。需要注意的是,對于正常視頻,其 CoT(思維鏈)被簡化為兩個步驟,即感知與認知兩個階段。

C 實現細節(Implementation Details)
C.1 提示設計(Prompt)
用于執行視頻異常推理的提示如圖 9 所示。該提示由三部分組成:任務定義(Task Definition)、輸出規范(Output Specification) 和 格式要求(Format Requirements)。
首先,任務定義描述了視頻異常推理的整體目標,并明確要求模型在回答前進行思考。
其次,輸出規范提供了推理過程與期望回答的詳細指導說明。
最后,格式要求展示了包含明確標簽的輸出示例(例如,使用 <think></think> 表示思維鏈內容,使用 <answer></answer> 表示最終答案)。

C.2 AVA-GRPO 的訓練過程(Training Process of AVA-GRPO)
所提出的 AVA-GRPO 的核心在于引入了額外的異常驗證獎勵(詳見算法 1)。

此外,我們還引入了長度獎勵(Length Reward)。我們首先分別計算 Vad-Reasoning-SFT 中異常視頻與正常視頻的推理文本長度。在強化學習過程中,若模型輸出的文本長度符合對應范圍,即可獲得長度獎勵。
值得注意的是,對于每次生成的回答,模型只更新一次參數。
因此,AVA-GRPO 的目標函數被簡化為:
L AVA-GRPO ( θ ) = E { q , O } [ 1 G ∑ i = 1 G ( π θ ( o i ∣ q ) π θ no?grad ( o i ∣ q ) A i ? β D K L ( π θ ∥ π ref ) ) ] (3) \mathcal{L}_{\text{AVA-GRPO}}(\theta) = \mathbb{E}_{\{q, O\}} \left[ \frac{1}{G} \sum_{i=1}^{G} \left( \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{no grad}}}(o_i \mid q)} A_i - \beta \, \mathrm{D}_{\mathrm{KL}}(\pi_\theta \,\|\, \pi_{\text{ref}}) \right) \right] \tag{3} LAVA-GRPO?(θ)=E{q,O}?[G1?i=1∑G?(πθno?grad??(oi?∣q)πθ?(oi?∣q)?Ai??βDKL?(πθ?∥πref?))](3)
其中 π θ no?grad \pi_{\theta_{\text{no grad}}} πθno?grad?? 與 π θ \pi_\theta πθ? 等價,僅用于梯度停止。最終,AVA-GRPO 的訓練過程詳見算法 2。

250530: π θ no?grad π_{θ_{\text{no grad}}} πθno?grad?? 不回傳梯度,是為了在策略優化中起到“對比基準”的作用,確保只有當前策略被更新,舊策略保持固定,從而穩定策略學習過程。這是 PPO/GRPO 等方法的標準做法。
C.3 更多實驗細節(More Experimental Details)
所有實驗均在 4 塊 NVIDIA A100(80GB)GPU 上進行。
- 監督微調階段:在 Vad-Reasoning-SFT 數據集上訓練基礎 MLLM 共 4 個 epoch,耗時約 6 小時。
- 強化學習階段:在 Vad-Reasoning-RL 數據集上繼續訓練 1 個 epoch,耗時約 26 小時。
為提升訓練效率,我們將所有視頻統一歸一化為 16 幀,且每幀的最大像素尺寸限制為 128 × 28 × 28 128 \times 28 \times 28 128×28×28。
- 兩階段的學習率均設為 1 × 10 ? 6 1 \times 10^{-6} 1×10?6。
- 每組生成的候選回答數量為 4。
- 異常驗證獎勵函數中公式 (3) 的超參數 β \beta β 設為 0.04。
- AVA-GRPO 共包含五種獎勵類型,具體值與含義詳見表 7。
推理過程長度約束如下:
- 對于正常視頻,設定范圍為 [ 140 , 261 ] [140, 261] [140,261];
- 對于異常視頻,設定范圍為 [ 233 , 456 ] [233, 456] [233,456]。
250530:128*28*28 大概就是 448*224

C.4 在 VANE 基準上的評估(Evaluation on VANE Benchmark)
VANE [15] 是一個專為評估視頻多模態大語言模型(video-MLLMs)檢測視頻異常能力而設計的基準數據集。該數據集包含 325 段視頻剪輯與 559 個問答對,涵蓋現實監控場景與 AI 生成視頻,異常類型被劃分為 9 類。
對于現實世界異常,VANE 從現有的視頻異常檢測數據集中收集了 128 段視頻(例如:CUHK Avenue [35]、UCSD-Ped1/Ped2 [26]、UCF-Crime [49])。
對于 AI 生成的異常,VANE 包含 197 段由以下系統生成的視頻:
- SORA [4]
- OpenSora [16]
- Runway Gen2 [46]
- ModelScopeT2V [61]
- VideoLCM [62]
我們報告了 Vad-R1 及其他基于 MLLM 的 VAD 方法在不同類別上的性能表現。
需要注意的是,由于 Vad-R1 使用了包含 UCF-Crime 視頻的 Vad-Reasoning 數據集進行訓練,我們在 VANE 基準中排除了 UCF-Crime 對應子集以避免數據泄漏。
250530:數據泄露是指測試集中的數據在訓練過程中已經以某種方式被模型見過或用過了,導致評估結果虛高、不公平、不可信。
D 更多實驗結果(More Experimental Results)
D.1 基于大語言模型的評估(LLM-Guided Evaluation)
傳統的評估指標,如 BLEU 和 METEOR,主要關注生成答案與參考答案在 token 級別的重合度。然而,這些指標在捕捉生成答案的語義質量方面存在天然局限,尤其在涉及因果推理與上下文判斷的任務中更為明顯。
為彌補這一不足,我們借助專有的大語言模型(LLM)對生成回答的質量進行輔助評估。參考 HAWK [50],我們從以下幾個方面進行評估:
-
Reasonability(合理性):評估生成的回答是否呈現出連貫且邏輯有效的異常因果推理。
-
Detail(細節性):評估模型輸出中信息的具體性與內容的豐富性。高質量回答應覆蓋關鍵的上下文要素。
-
Consistency(一致性):關注生成回答與參考元數據之間的事實對齊程度,包括事件描述、潛在后果等內容。
每一維度的評分范圍為 [ 0 , 1 ] [0, 1] [0,1],其中 1 表示語義對齊與推理質量最高。
表 8 展示了在 Vad-Reasoning 測試集上的評估結果對比。結果表明:
- Vad-R1 在所有開源方法中表現最佳;
- 與專有 MLLM 相比,Vad-R1 尤其在 Reasonability 與 Consistency 兩項指標上展現出更優性能,甚至超過了 GPT-4o。

D.2 更多輸入幀數量的實驗(Experiments on More Input Tokens)
在訓練與推理階段,原始視頻統一采樣為 16 幀輸入,每幀像素上限為 128 × 28 × 28 128 \times 28 \times 28 128×28×28。在本節中,我們將每個視頻的幀數增加到 32 與 64,并將每幀的最大像素數提高至 256 × 28 × 28 256 \times 28 \times 28 256×28×28。實驗結果見表 9。
一方面,我們觀察到幀數從 16 增加至 64 可在異常推理與檢測兩個任務上均帶來性能提升,說明更多幀提供了更有用的視覺信息。
另一方面,分辨率的提升是否有益則取決于幀數。當在 16 幀設置下將像素上限提升到 256 × 28 × 28 256 \times 28 \times 28 256×28×28 時,模型性能雖提升幅度較小,但提升穩定,表明高分辨率細節可在幀數較少時帶來補償效果。
相反,當幀數增加到 32 時,若進一步提升像素上限,性能反而下降,這可能是由于 token 冗余導致。因此,相較于分辨率,增加幀數更有效;而提升分辨率則可能引起信息過載。

D.3 更多消融實驗(More Ablation Studies)
在本節中,我們評估所提出的 AVA-GRPO 的有效性。
與原始 GRPO 相比,AVA-GRPO 額外引入了異常驗證獎勵,用于在僅有視頻級弱標簽的情況下激勵 MLLM 提升異常推理能力。同時,我們還加入了一個長度獎勵,以控制生成文本的長度。
這兩個附加獎勵項的有效性如表 10 所示:
- 在 16 幀和 32 幀兩種設置下,AVA-GRPO 在異常推理與檢測任務中均優于原始 GRPO。
- 相比之下,若僅使用其中一個獎勵項,模型性能提升有限且不穩定。
這些結果表明:結合異常獎勵與長度獎勵是提升整體推理與檢測性能的關鍵。

D.4 訓練曲線(Training Curves)
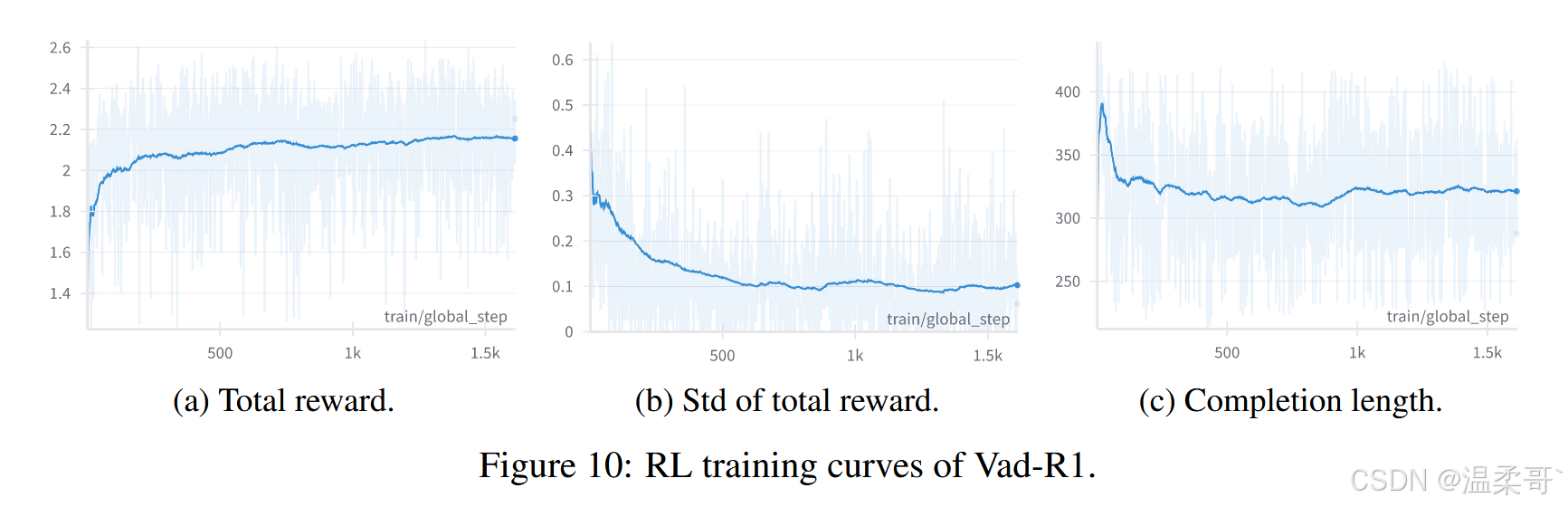
圖 10 展示了 Vad-R1 在強化學習階段的關鍵訓練曲線。
- 圖 10(a) 顯示了 AVA-GRPO 的總獎勵隨訓練步驟的變化,總體趨勢為穩定上升,并在約 1000 步后收斂,說明 Vad-R1 的輸出策略與獎勵函數的匹配程度持續提升。
- 圖 10(b) 顯示了總獎勵的標準差,在訓練初期迅速下降,并穩定在 0.1 以下,表明輸出質量隨訓練的進行而逐漸穩定。
- 圖 10(c) 報告了生成回答的平均長度,在訓練初期有所上升,隨后趨于平穩,暗示模型逐步生成更加精煉而高效的回答,同時保持較高獎勵水平。
D.5 更多定性結果(More Qualitative Results)
我們在圖 11 和圖 12 中展示了兩個定性結果。與一些專有模型相比,Vad-R1 展示出穩健的異常推理與檢測能力。
例如,在圖 11 中,Vad-R1 成功識別了“白色塑料袋”為異常對象,并進行了合理的推理。
相比之下,Claude 雖然也檢測到了塑料袋,但將其異常原因解釋為“塑料袋在移動”,而非“塑料袋阻擋路徑”這一更合理的因果邏輯。
此外,QVQ-Max 與 o4-mini 雖然也注意到了白色塑料袋,但并未將其判斷為異常。

E 影響與局限性(Impact and Limitation)
本文提出了一個新任務:視頻異常推理(Video Anomaly Reasoning),旨在使 MLLM 能夠對視頻中的異常事件進行深入分析與理解。我們希望本工作能為視頻異常研究領域作出貢獻。
然而,Vad-R1 的一個局限性在于推理速度較慢。由于其采用多階段推理機制,這帶來了額外的計算開銷。





)

:核心概念 + 命令詳解 + 部署案例】)
)
 - 解堆 (行 -> 列))









