[root@node-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# pwd
/usr/local/alertmanager-0.28.1.linux-amd64[root@node-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# cat alertmanager.yml
# 通用配置
global:resolve_timeout: 5msmtp_from: '914XXXXXX@qq.com'smtp_smarthost: 'smtp.qq.com:465'smtp_auth_username: '914XXXXXX@qq.com'smtp_auth_password: 'aalXXXjXXbXa'smtp_require_tls: falsesmtp_hello: 'qq.com'
# 定義路由信息
route:group_by: ['alertname']group_wait: 5sgroup_interval: 5srepeat_interval: 5mreceiver: 'sre_system'# 配置子路由routes:- receiver: 'sre_ops'match_re:job: linux96_ops_exporter# 建議將continue的值設置為true,表示當前的條件是否匹配,都將繼續向下匹配規則# 這樣做的目的是將消息發給最后的系統組(sre_system)continue: true- receiver: 'sre_k8s'match_re:job: linux96_k8s_exporter continue: true- receiver: 'sre_system'match_re:job: .*continue: true
# 定義接受者
receivers:
- name: 'sre_ops'email_configs:- to: '914XXXXX@qq.com'send_resolved: true- to: '914XXXXX@qq.com'send_resolved: true
- name: 'sre_k8s'email_configs:- to: '568XXXX@qq.com'send_resolved: true- to: '56XXXX@qq.com'send_resolved: true
- name: 'sre_system'email_configs:- to: '914XXXXX@qq.com'send_resolved: true- to: '56XXXXXX@qq.com'send_resolved: true引言
在深入探索 Prometheus 的過程中,我們往往會對其核心組件有較為深入的了解,但與此同時,一些輔助組件也發揮著不可或缺的作用,它們就像是為整個監控系統增添羽翼的利器,讓監控功能得以進一步拓展和完善。今天,我們就來聚焦于 Prometheus 生態系統中的兩個重要組件 ——Pushgateway 和 Alertmanager,深入剖析它們的工作原理、應用場景以及與整個 Prometheus 監控體系的協同合作方式,一同揭開它們在監控領域所蘊含的巨大潛力和價值,為你的技術監控之旅增添新的助力和洞察。
一、背景
隨著互聯網行業的蓬勃發展,各種復雜的應用系統和微服務架構層出不窮,這些系統的正常運轉對于企業的業務運營至關重要。為了確保這些系統能夠以最佳狀態持續運行,及時發現和解決潛在的問題,監控系統成為了不可或缺的基礎設施。
Prometheus 作為一款開源的監控告警系統,以其強大的數據模型、靈活的查詢語言(PromQL)以及高效的時序數據庫等優勢,在眾多監控解決方案中脫穎而出。它采用拉取(Pull)模式來收集被監控目標的指標數據,這種模式在大多數場景下能夠很好地工作,但在某些特殊場景,例如需要監控短生命周期的批處理任務、臨時性的任務或者在防火墻受限的環境中等,僅僅依靠 Prometheus 的拉取模式就顯得有些力不從心了,這就促使了 Pushgateway 這樣一個組件的誕生,它允許客戶端將指標數據推送到 Prometheus 中,從而彌補了拉取模式在這些特殊場景下的不足。
而另一方面,在監控過程中,當發現指標數據出現異常時,及時準確地發出告警通知對于快速響應和處理問題是至關重要的。雖然 Prometheus 自身具備一定的告警規則配置功能,但當涉及到復雜的告警通知策略、告警分組、抑制以及與多種通知渠道的集成等場景時,單獨使用 Prometheus 的告警功能就會顯得較為復雜和局限,此時 Alertmanager 便應運而生。它作為 Prometheus 的告警管理組件,專門負責處理來自 Prometheus Server 的告警信息,對告警進行分組、去重、抑制等處理,并能夠根據預設的規則將告警通過多種方式(如郵件、Slack、PagerDuty 等)發送給相應的接收者,從而構建起一個完善且高效的告警通知體系。
通過對 Pushgateway 和 Alertmanager 這兩個組件的深入學習和應用,我們能夠使 Prometheus 監控系統在更多復雜多變的場景下發揮出更大的威力,為系統的穩定運行提供更加堅實可靠的保障。在接下來的博客內容中,我們將分別對這兩個組件進行詳細講解,包括它們的安裝部署、配置使用、實際案例分析等多個方面,希望能幫助你更好地掌握和運用這些強大的監控工具。
二、 Pushgateway組件部署
1. 下載軟件包
部署pushgateway
[root@node-exporter41 ~]# wget https://github.com/prometheus/pushgateway/releases/download/v1.11.0/pushgateway-1.11.0.linux-amd64.tar.gz解壓軟件包
[root@node-exporter41 ~]# tar xf pushgateway-1.11.0.linux-amd64.tar.gz -C /usr/local/bin/ pushgateway-1.11.0.linux-amd64/pushgateway --strip-components=1
[root@node-exporter41 ~]#
[root@node-exporter41 ~]# ll /usr/local/bin/pushgateway
-rwxr-xr-x 1 1001 1002 20656129 Jan 9 22:36 /usr/local/bin/pushgateway*
[root@node-exporter41 ~]# 2.?運行pushgateway?
[root@node-exporter41 ~]# pushgateway --web.telemetry-path="/metrics" --web.listen-address=:9091 --persistence.file=/data/pushgateway.data訪問pushgateway的WebUI
http://10.0.0.41:9091/#3. 使用pushgateway監控TCP的12種狀態
[root@elk93 ~]# cat /usr/local/bin/tcp_status2.sh
#!/bin/bashpushgateway_url="http://10.0.0.41:9091/metrics/job/tcp_status"
time=$(date +%Y-%m-%d+%H:%M:%S)state="SYN-SENT SYN-RECV FIN-WAIT-1 FIN-WAIT-2 TIME-WAIT CLOSE CLOSE-WAIT LAST-ACK LISTEN CLOSING ESTAB"
for i in $statedot=`ss -tan |grep $i |wc -l`echo tcp_connections{state=\""$i"\"} $t >>/tmp/tcp.txt
done;cat /tmp/tcp.txt | curl --data-binary @- $pushgateway_url
rm -rf /tmp/tcp.txt
[root@elk93 ~]# 2.調用腳本
[root@elk93 ~]# bash /usr/local/bin/tcp_status2.sh三、Alertmanager單機環境部署
1. 下載軟件包
2.下載Alertmanager
wget https://github.com/prometheus/alertmanager/releases/download/v0.28.1/alertmanager-0.28.1.linux-amd64.tar.gz3.解壓安裝包
[root@node-exporter43 ~]# tar xf alertmanager-0.28.1.linux-amd64.tar.gz -C /usr/local/
[root@node-exporter43 ~]# 2. 修改Alertmanager的配置文件
[root@node-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# pwd
/usr/local/alertmanager-0.28.1.linux-amd64[root@node-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# cat alertmanager.yml
# 通用配置
global:resolve_timeout: 5msmtp_from: '914@qq.com'smtp_smarthost: 'smtp.qq.com:465'smtp_auth_username: '914@qq.com'smtp_auth_password: 'ahjplbbja'smtp_require_tls: falsesmtp_hello: 'qq.com'
# 定義路由信息
route:group_by: ['alertname']group_wait: 5sgroup_interval: 5srepeat_interval: 5mreceiver: 'sre_system'# 配置子路由routes:- receiver: 'sre_ops'match_re:job: linux96_ops_exporter# 建議將continue的值設置為true,表示當前的條件是否匹配,都將繼續向下匹配規則# 這樣做的目的是將消息發給最后的系統組(sre_system)continue: true- receiver: 'sre_k8s'match_re:job: linux96_k8s_exporter continue: true- receiver: 'sre_system'match_re:job: .*continue: true
# 定義接受者
receivers:
- name: 'sre_ops'email_configs:- to: '914@qq.com'send_resolved: true- to: '914@qq.com'send_resolved: true
- name: 'sre_k8s'email_configs:- to: '5@qq.com'send_resolved: true- to: '5689@qq.com'send_resolved: true
- name: 'sre_system'email_configs:- to: '914@qq.com'send_resolved: true- to: '56@qq.com'send_resolved: true3.?檢查配置是否正確
[root@node-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# ./amtool check-config alertmanager.yml
Checking 'alertmanager.yml' SUCCESS
Found:- global config- route- 0 inhibit rules- 3 receivers- 0 templates4. 啟動Alertmanager服務并測試
[root@node-exporter43 alertmanager-0.28.1.linux-amd64]# ./alertmanager # 訪問webUI測試
http://10.0.0.41:9093/#/status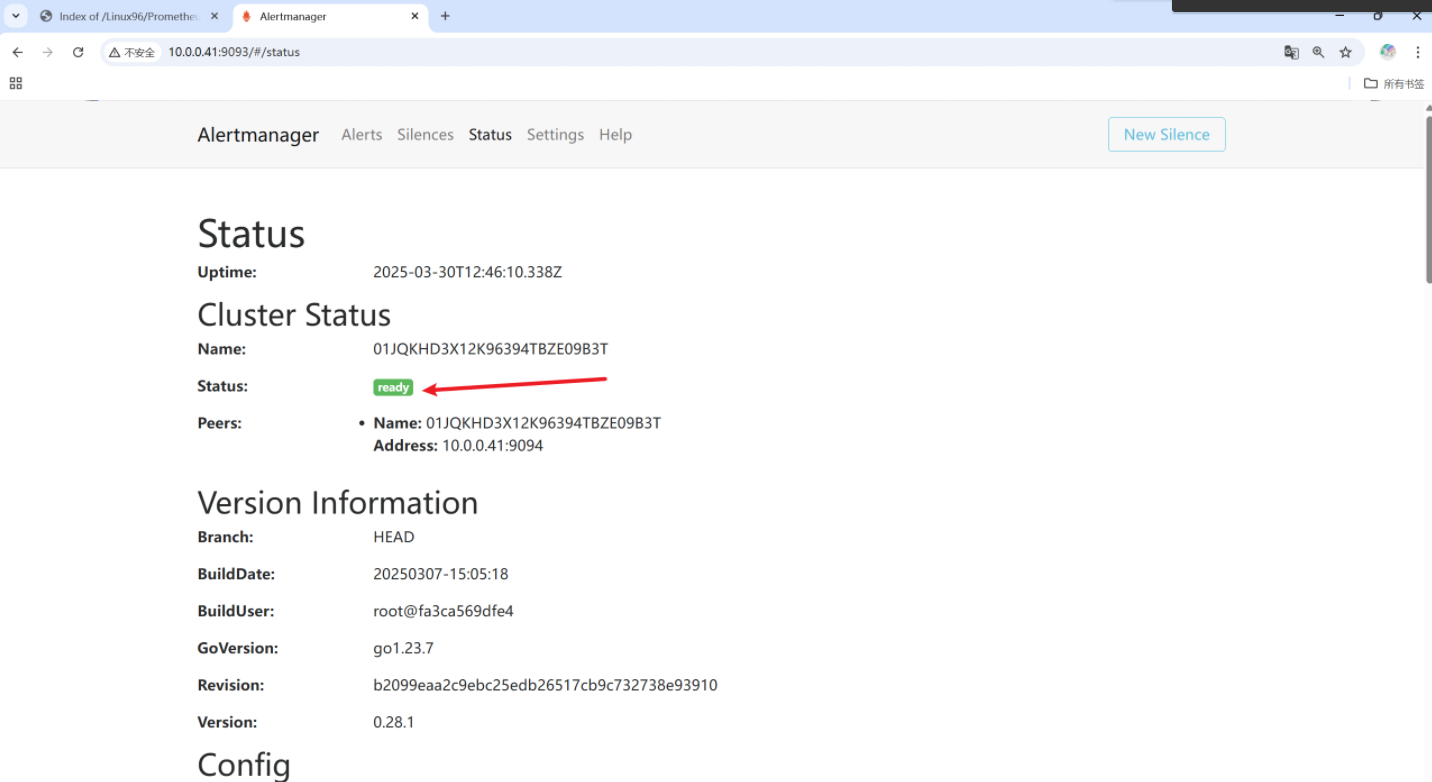
四、Prometheus server集成Alertmanager實現告警功能
1. 修改Prometheus配置文件,打開告警功能
[root@prometheus-server31 /softwares/prometheus-2.53.4.linux-amd64]# cat prometheus.yml
# my global config
global:scrape_interval: 3s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configuration ------------------->打開此alter的配置信息~~
alerting:alertmanagers:- static_configs:- targets:- 10.0.0.41:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: ------------------> 此配置是告警規則可以自定義# - "first_rules.yml"# - "second_rules.yml"- "linux96-rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["localhost:9090"]# 這里就是靜態配置- job_name: "linux96_ops_exporter"static_configs:- targets:- 10.0.0.41:9100- job_name: "linux96_k8s_exporter"static_configs:- targets:- 10.0.0.42:9100- job_name: "whatever_job_exporter"static_configs:- targets:- 10.0.0.43:91002.?編寫告警配置
[root@prometheus-server31 /softwares/prometheus-2.53.4.linux-amd64]# cat linux96-rules.yml
groups:
- name: linux96-rules-alertrules:- alert: linux96-rules-ops-alertexpr: up{job="linux96_ops_exporter"} == 0for: 3slabels:address: Shanghai class: linux96apps: opsannotations:summary: "{{ $labels.instance }} 服務器已經停止運行超過 3s!!!!!"- alert: linux96-rules-k8s-alterexpr: up{job="linux96_k8s_exporter"} == 0for: 3slabels:school: Beijingclass: linux96apps: k8sannotations:summary: "{{ $labels.instance }} K8S服務器已停止運行超過 3s!"- alert: othersServer-rules-system-alterexpr: up{job="whatever_job_exporter"} == 0for: 5slabels:school: Shenzhenclass: linux96apps: bigdataannotations:summary: "{{ $labels.instance }} 大數據服務器已停止運行超過 5s!"3.?檢查配置文件語法并重新加載配置
[root@prometheus-server31 /softwares/prometheus-2.53.4.linux-amd64]# ./promtool check config prometheus.yml
Checking prometheus.ymlSUCCESS: 1 rule files foundSUCCESS: prometheus.yml is valid prometheus config file syntaxChecking linux96-rules.ymlSUCCESS: 3 rules found[root@prometheus-server31 /softwares/prometheus-2.53.4.linux-amd64]# ### 重新加載prometheus的配置
curl -X POST http://10.0.0.31:9090/-/reload4.?觸發告警功能
[root@node-exporter41 ~]# systemctl stop node-exporter.service
[root@node-exporter41 ~]# ss -ntl | grep 9100
[root@node-exporter41 ~]# [root@node-exporter42 ~]# systemctl stop node-exporter.service
[root@node-exporter42 ~]#
[root@node-exporter42 ~]# ss -ntl | grep 9100
[root@node-exporter42 ~]# [root@node-exporter43 ~]# systemctl stop node-exporter.service
[root@node-exporter43 ~]#
[root@node-exporter43 ~]# ss -ntl | grep 91005.?查看alermanager的WebUI及郵箱接受者
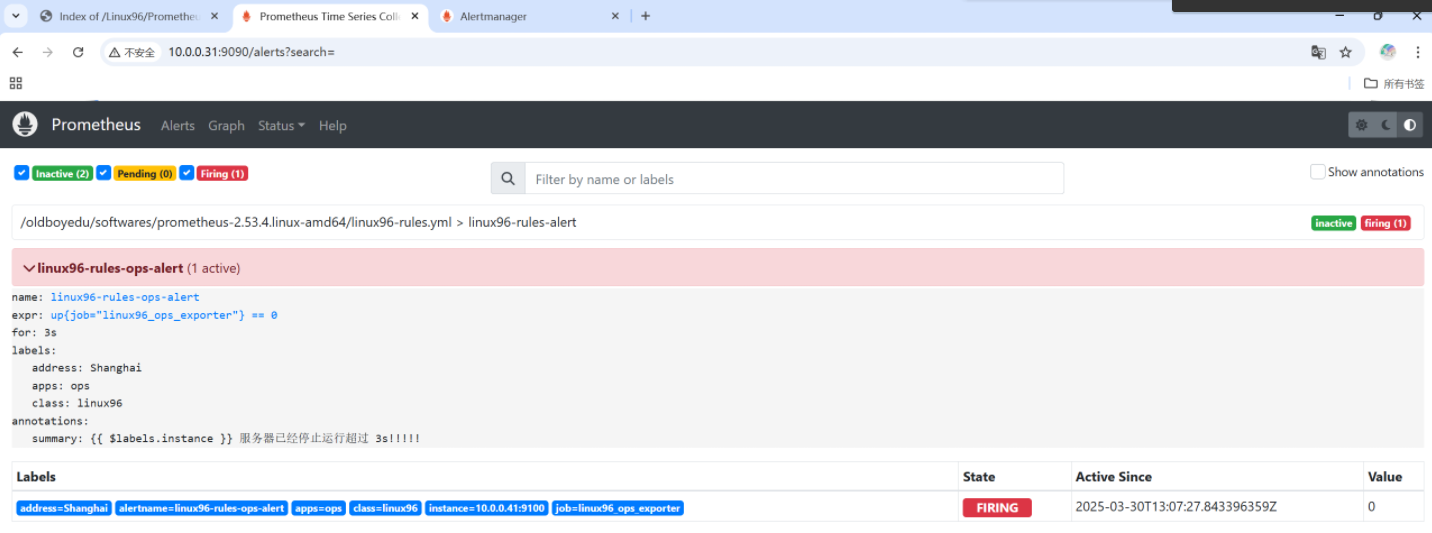
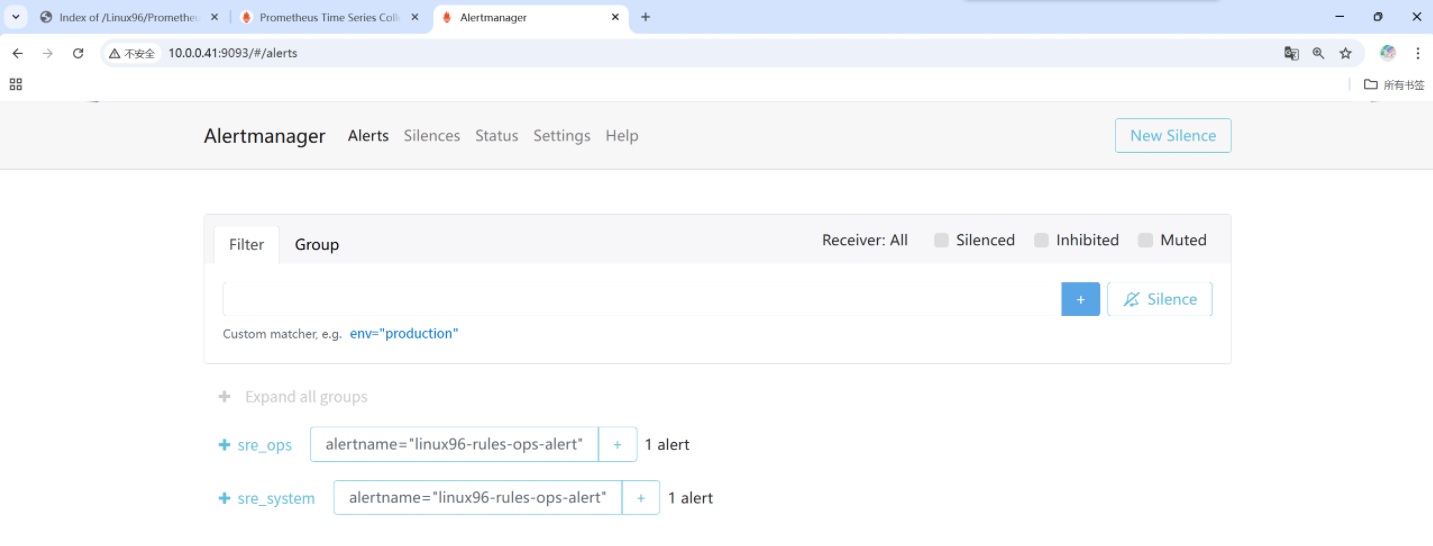

由此webUI可以發現我們的ops模塊異常了
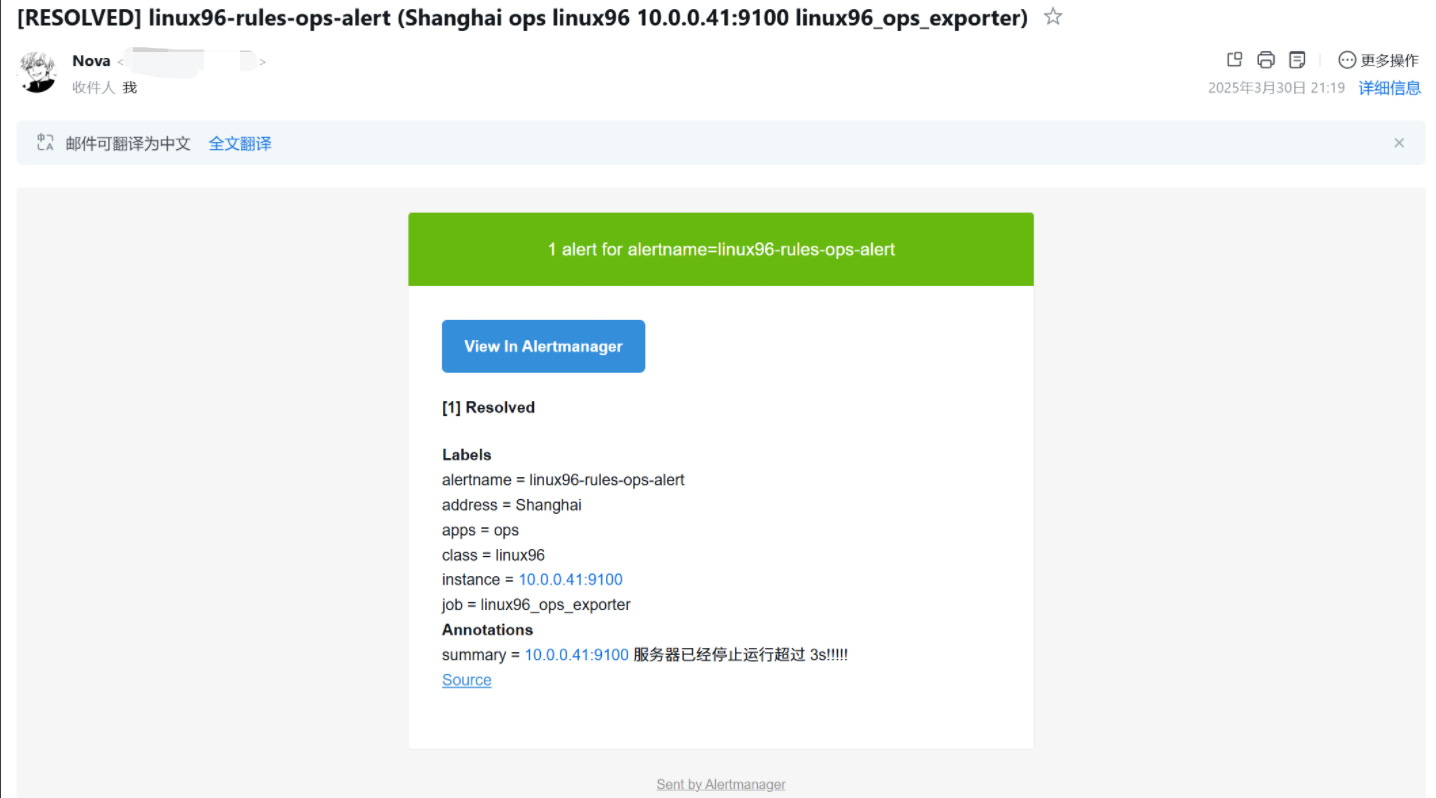
此時郵箱就會出現告警
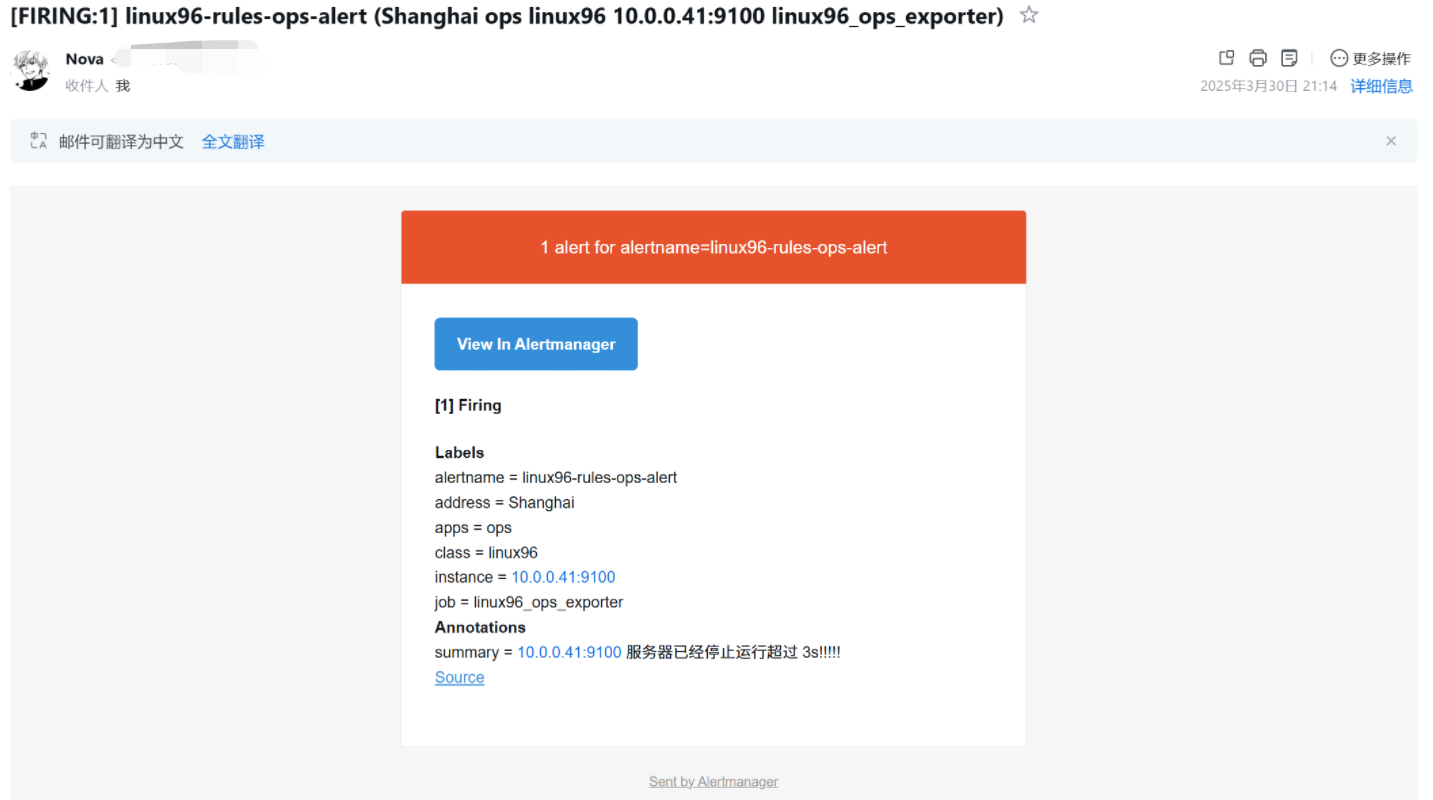 ?這時候我們去修復一下服務
?這時候我們去修復一下服務
[root@node-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# systemctl start node-exporter.service
[root@node-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# ss -ntl |grep 9100
LISTEN 0 4096 *:9100 *:* 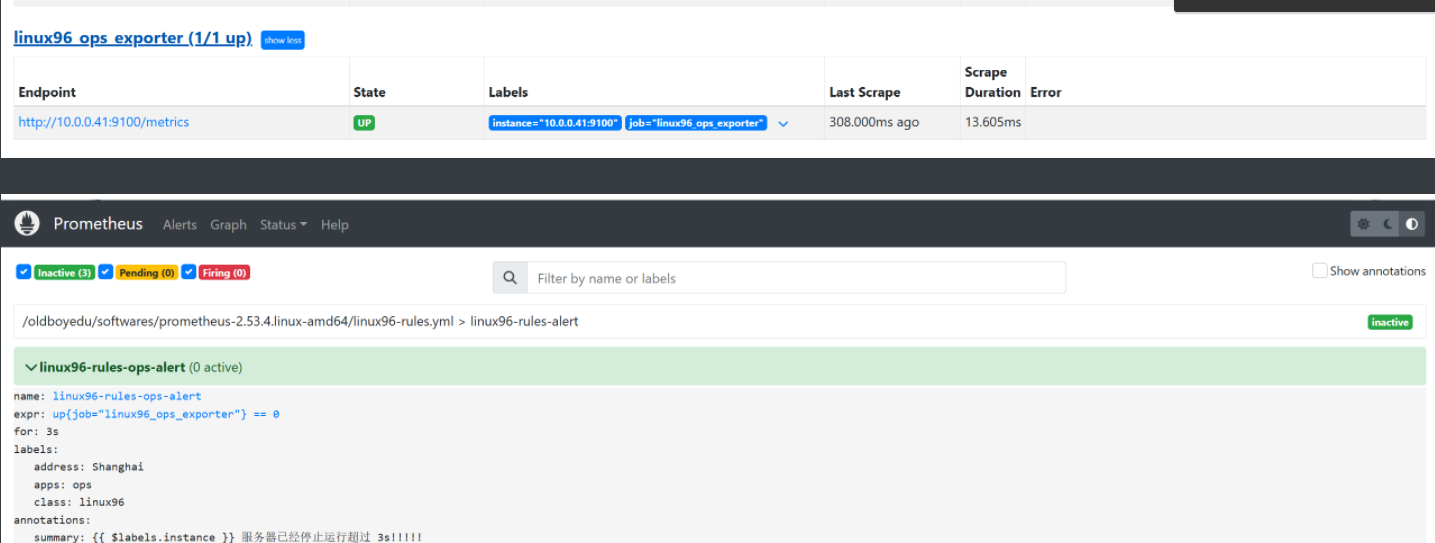
此時郵箱依舊會發送郵件告訴我們故障已解決
五、Alertmanager集成釘釘插件實現告警
參考鏈接:
?? ?https://github.com/timonwong/prometheus-webhook-dingtalk/
1.部署釘釘插件
1.1 下載釘釘插件
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.1.0/prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz1.2 解壓文件
[root@node-exporter43 ~]# tar xf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz -C /usr/local/
[root@node-exporter43 ~]#
[root@node-exporter43 ~]# cd /usr/local/prometheus-webhook-dingtalk-2.1.0.linux-amd64/
[root@node-exporter43 prometheus-webhook-dingtalk-2.1.0.linux-amd64]#
[root@node-exporter43 prometheus-webhook-dingtalk-2.1.0.linux-amd64]# ll
total 18752
drwxr-xr-x 3 3434 3434 4096 Apr 21 2022 ./
drwxr-xr-x 12 root root 4096 Mar 30 17:47 ../
-rw-r--r-- 1 3434 3434 1299 Apr 21 2022 config.example.yml
drwxr-xr-x 4 3434 3434 4096 Apr 21 2022 contrib/
-rw-r--r-- 1 3434 3434 11358 Apr 21 2022 LICENSE
-rwxr-xr-x 1 3434 3434 19172733 Apr 21 2022 prometheus-webhook-dingtalk*
[root@node-exporter43 prometheus-webhook-dingtalk-2.1.0.linux-amd64]# [root@node-exporter43 /usr/local/prometheus-webhook-dingtalk-2.1.0.linux-amd64]# cp config{.example,}.yml
[root@node-exporter43 /usr/local/prometheus-webhook-dingtalk-2.1.0.linux-amd64]# ll
total 18756
drwxr-xr-x 3 3434 3434 4096 Mar 30 13:47 ./
drwxr-xr-x 11 root root 4096 Mar 30 13:46 ../
-rw-r--r-- 1 3434 3434 1299 Apr 21 2022 config.example.yml
-rw-r--r-- 1 root root 1299 Mar 30 13:47 config.yml
drwxr-xr-x 4 3434 3434 4096 Apr 21 2022 contrib/
-rw-r--r-- 1 3434 3434 11358 Apr 21 2022 LICENSE
-rwxr-xr-x 1 3434 3434 19172733 Apr 21 2022 prometheus-webhook-dingtalk*
[root@node-exporter43 /usr/local/prometheus-webhook-dingtalk-2.1.0.linux-amd64]# ?2.?登錄釘釘添加自定義機器人
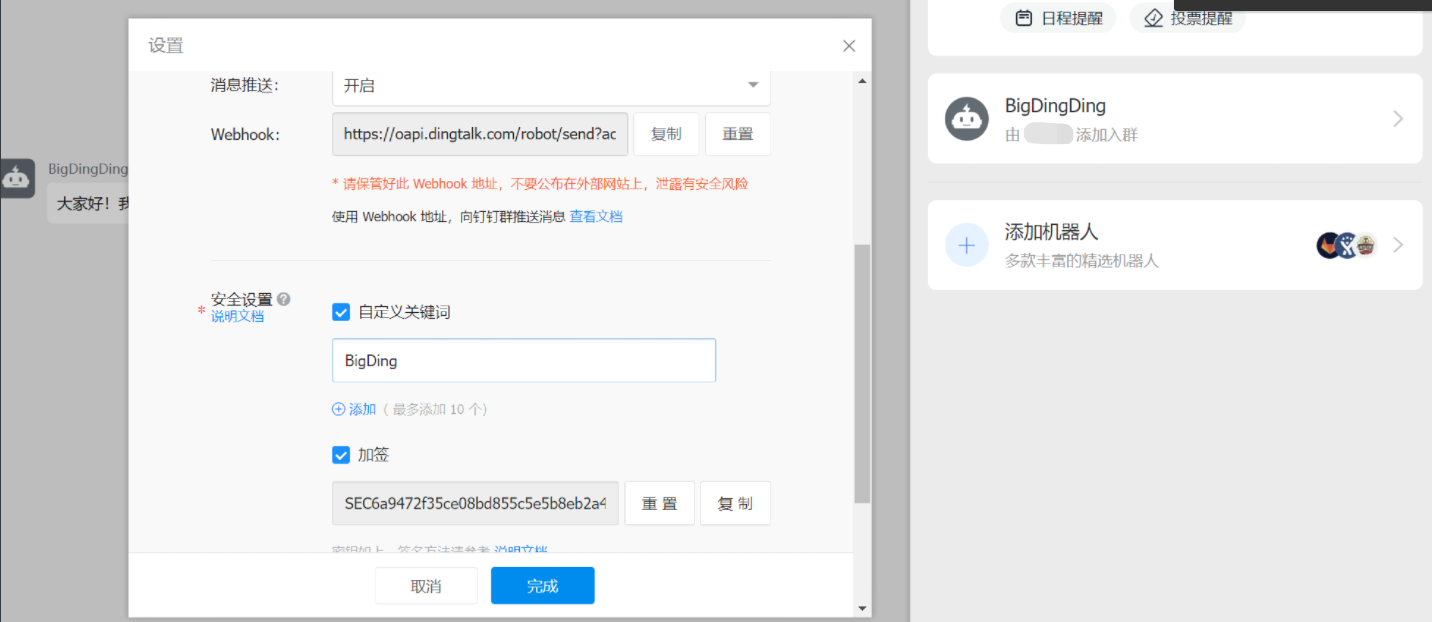
保存好配置文件信息
webhook地址:
https://oapi.dingtalk.com/robot/send?access_token=4b1f23e7286ebce1f626474534050d1cb3868f5055914d77d9217
加簽信息:
SEC6a9472f35ce08bd855c5e5b8cf3b39fd57fdb99d650aa35786acd884b9e
3.?配置釘釘的config.yml
[root@node-exporter43 /usr/local/prometheus-webhook-dingtalk-2.1.0.linux-amd64]# vim config.yml
## Request timeout
.....
### 配置釘釘的config.yml
## Targets, previously was known as "profiles"
targets:webhook1:url: https://oapi.dingtalk.com/robot/send?access_token=4b1f23e7286ebce1f624dff7c4eb236474534050d1cb3868f5055914d77d9217# secret for signaturesecret: SEC6a9472f35ce08bd855c5e5b8eb2a4cf3b39fd57fdb99d650aa35786acd884b9e
.....
當前只要一個自定觸發的鉤子,如果有多個可以繼續寫4.?啟動釘釘
[root@node-exporter43 /usr/local/prometheus-webhook-dingtalk-2.1.0.linux-amd64]# ./prometheus-webhook-dingtalk --web.listen-address="10.0.0.43:8060"
..........
這里有URL和一些messages
ts=2025-03-30T14:07:59.409Z caller=main.go:97 level=info component=configuration msg="Loading templates" templates=
ts=2025-03-30T14:07:59.410Z caller=main.go:113 component=configuration msg="Webhook urls for prometheus alertmanager" urls=http://10.0.0.43:8060/dingtalk/webhook1/send
ts=2025-03-30T14:07:59.411Z caller=web.go:208 level=info component=web msg="Start listening for connections" address=10.0.0.43:80605.?Alertmanager集成釘釘插件
[root@node-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# vim alertmanager.yml .....### 添加此配置- name: 'sre_system'webhook_configs:# 指向的是DingDing的插件地址- url: 'http://10.0.0.43:8060/dingtalk/webhook1/send'http_config: {}max_alerts: 0send_resolved: true#- name: 'sre_system'# email_configs:# - to: '94@qq.com'# send_resolved: true# headers: { Subject: "[WARN] LINUX96報警郵件" }
"alertmanager.yml" 76L, 2274B written
6. 測試
[root@node-exporter43 ~]# systemctl stop node-exporter.service?
[root@node-exporter43 ~]#?
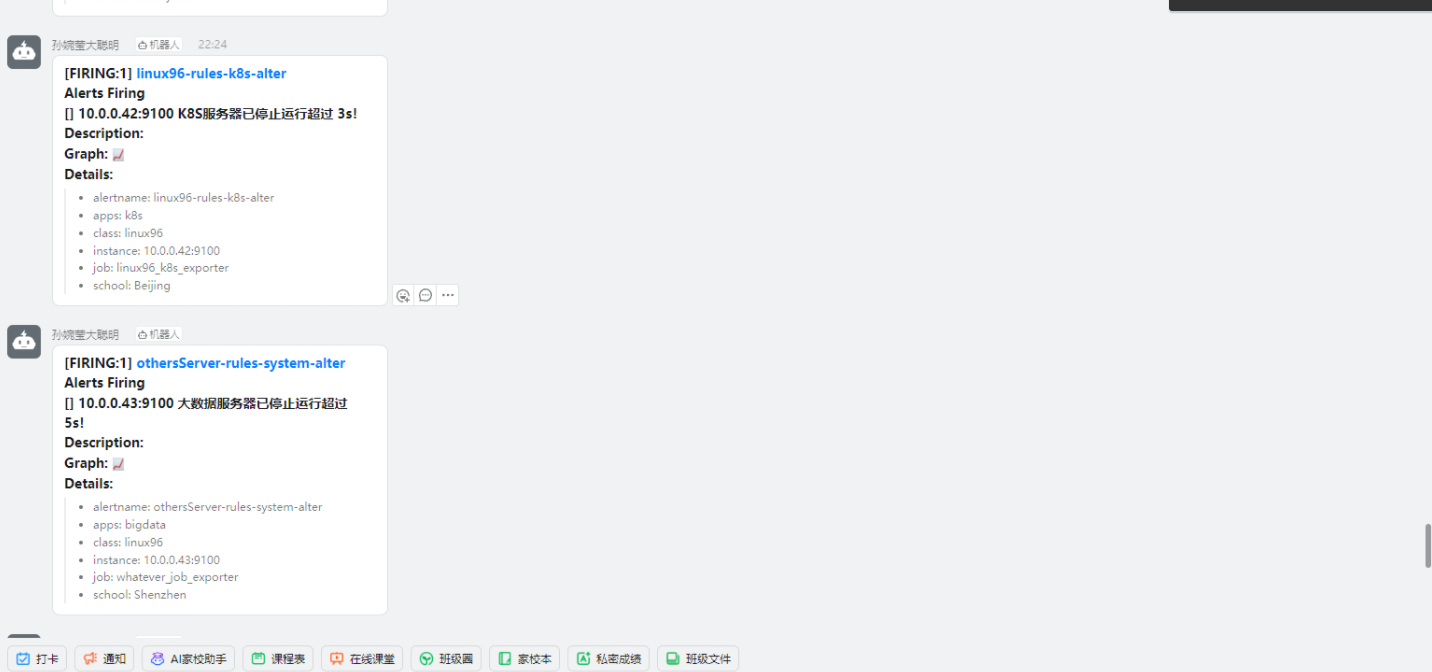
六.?Alertmanager的告警靜默(Silence)
1.告警靜默(Silence)
一般用于系統維護,預期要做的操作,這意味著就沒有必要告警。比如系統升級,需要8h,在這8h過程中,就可以考慮先不用告警。
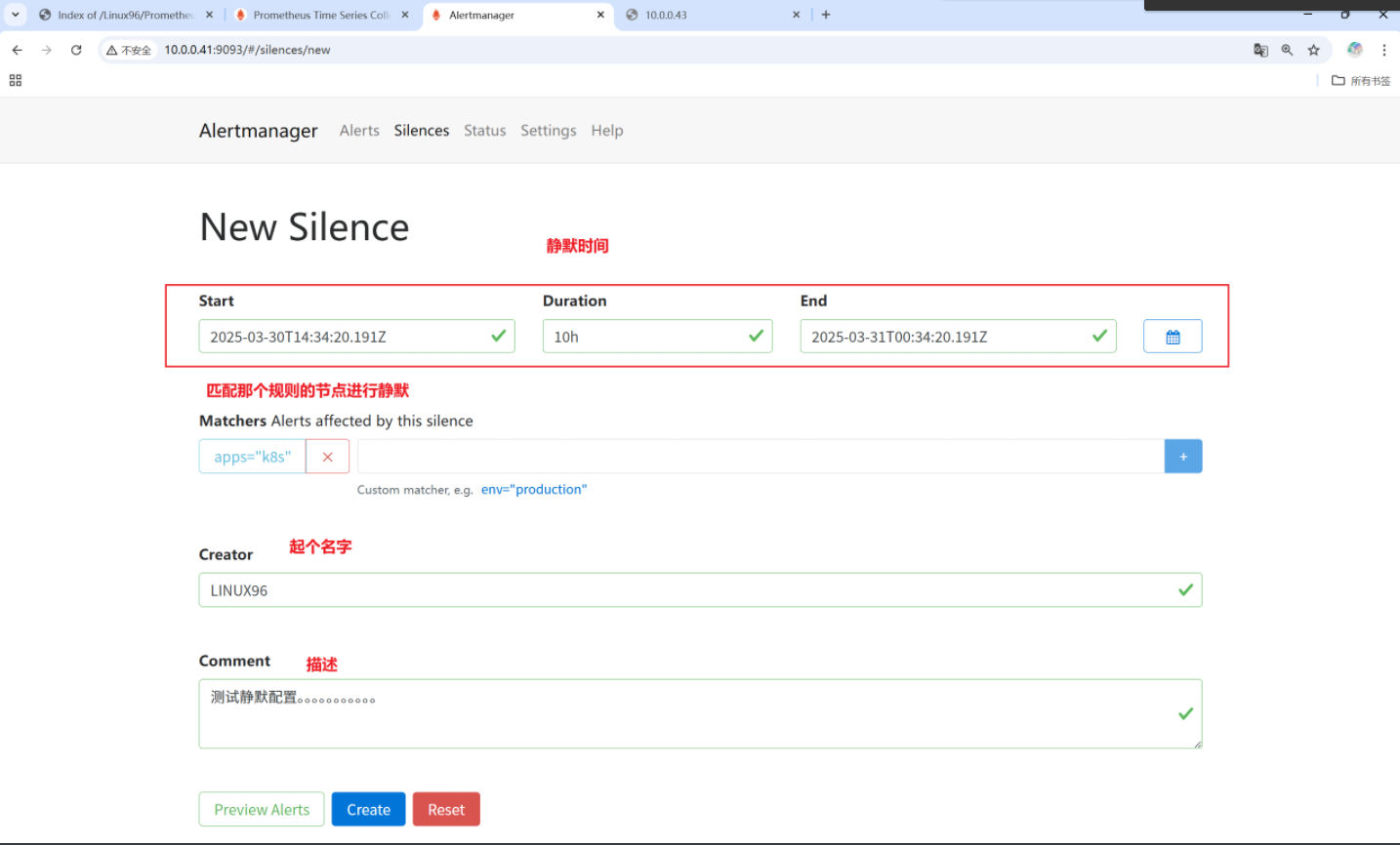

這時候就可以說明當前標簽為K8S規則的節點正在靜默,所以他即使有問題也不會報警,相反其他節點就可以正常。
測試
[root@node-exporter42 ~]# systemctl stop node-exporter.service
[root@node-exporter43 ~]# systemctl stop node-exporter.service 我們就可以看到42的k8s的警告就被靜默了,但是43還是正常報警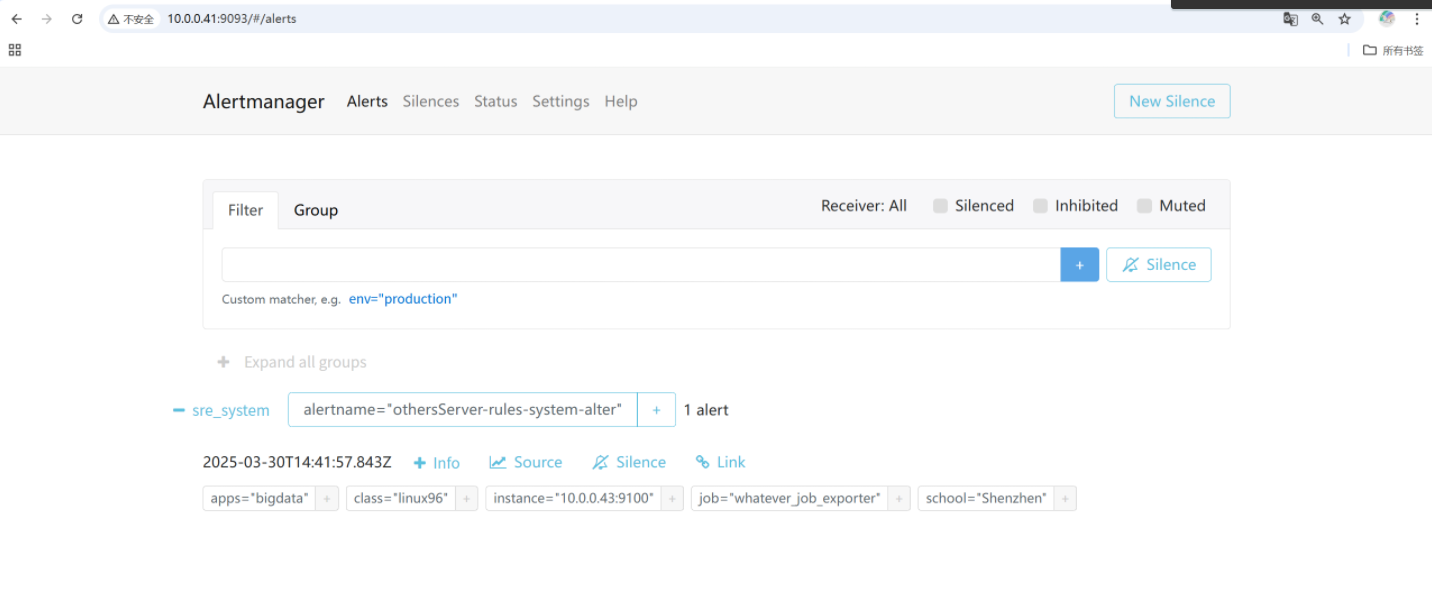 打開靜默就發現了K8S
打開靜默就發現了K8S
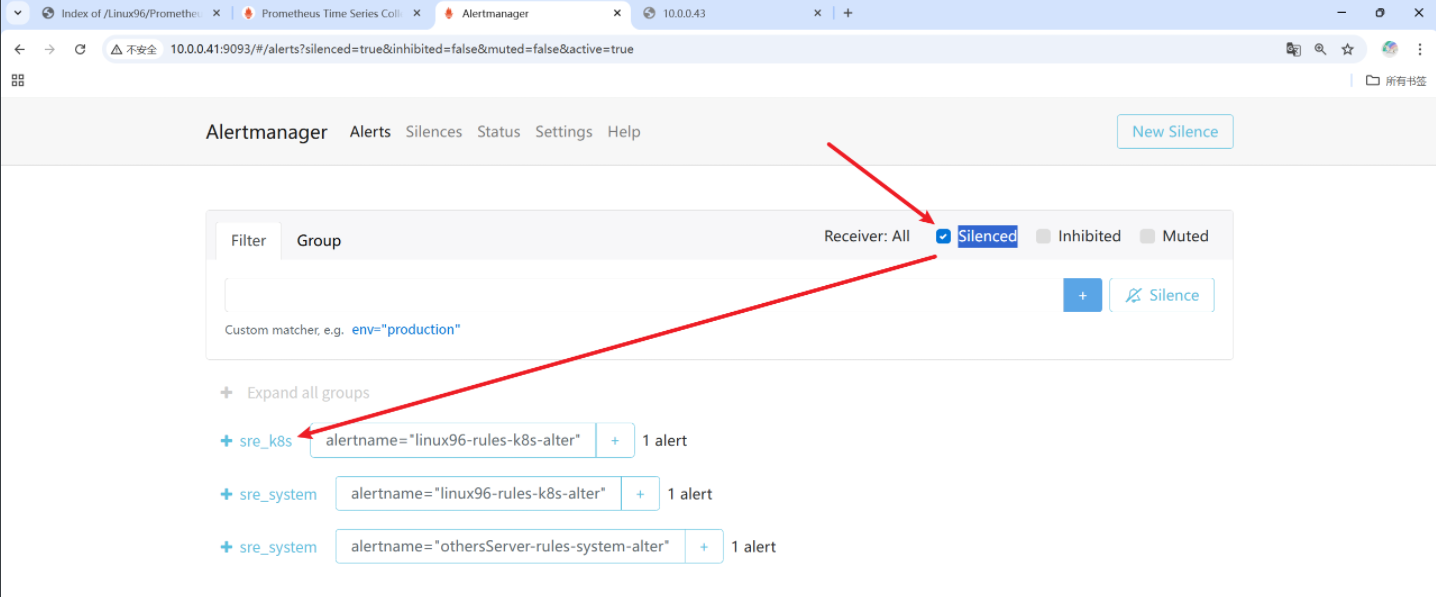
機器人的報警也是一樣的
沒有k8s標簽的警告
恢復節點
[root@node-exporter42 ~]# systemctl start node-exporter.service
[root@node-exporter43 ~]# systemctl start node-exporter.service 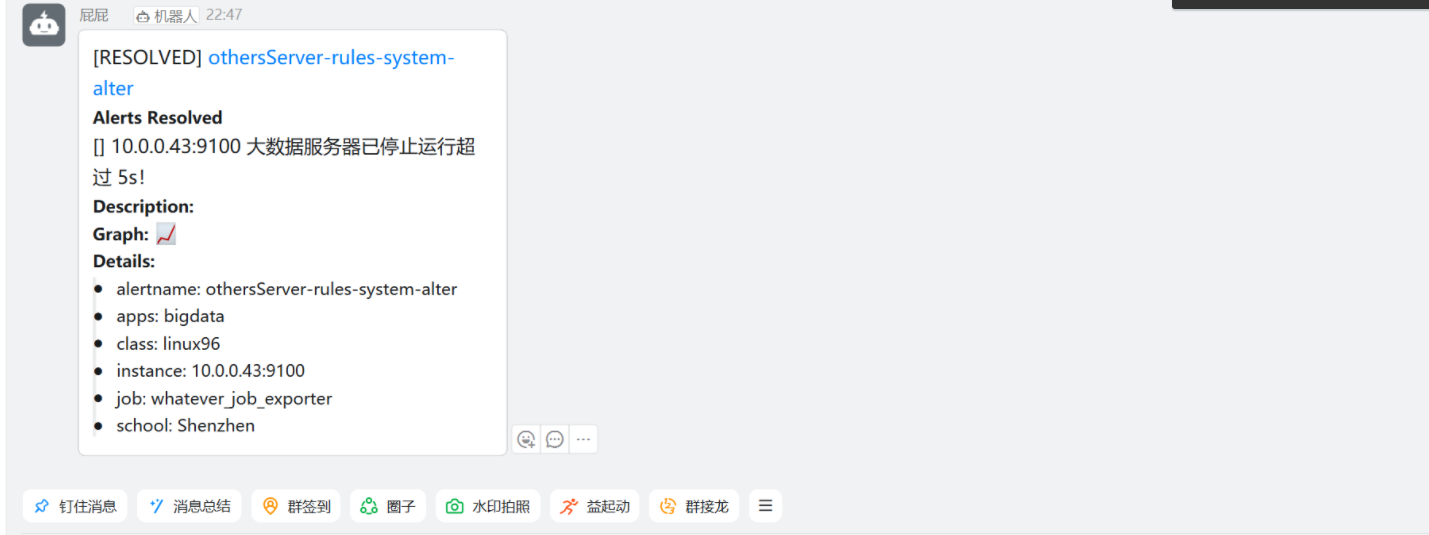
?七、Alertmanager的告警抑制(inhibit)
1.什么是告警抑制
說白了,就是抑制告警,和靜默不同的是,抑制的應用場景一般用于抑制符合條件的告警。舉個例子:?
?? ?一個數據中心有800臺服務器,每臺服務器有50個監控項,假設一個意味著有4w個監控告警。
?? ?如果數據中心端點,理論上來說就會有4w條告警發送到你的手機,你是處理不過來的,所以我們只需要將數據中心斷電的告警發出來即可。
1.?Prometheus編寫規則
### 主要添加severity: criticaldc: beijing
這兩行,標志著報警的級別和(可以理解為)標簽[root@prometheus-server31 /softwares/prometheus-2.53.4.linux-amd64]# vim linux96-rules.yml
- name: linux96-rules-alertrules:
groups:
- name: linux96-rules-alertrules:- alert: linux96-rules-ops-alertexpr: up{job="linux96_ops_exporter"} == 0for: 3slabels:address: Shanghaiclass: linux96apps: opsseverity: criticaldc: beijingannotations:summary: "{{ $labels.instance }} 服務器已經停止運行超過 3s!!!!!"- alert: linux96-rules-k8s-alterexpr: up{job="linux96_k8s_exporter"} == 0for: 3slabels:school: Beijingclass: linux96apps: k8sseverity: warningdc: beijingannotations:summary: "{{ $labels.instance }} K8S服務器已停止運行超過 3s!"- alert: othersServer-rules-system-alterexpr: up{job="whatever_job_exporter"} == 0for: 5slabels:school: Shenzhenclass: linux96apps: bigdataseverity: warningdc: Shenzhenannotations:summary: "{{ $labels.instance }} 大數據服務器已停止運行超過 5s!"
"linux96-rules.yml" 36L, 981B written ?2.?Alertmanager配置告警抑制規則?
......
### 在最后加入
## 配置告警抑制規則
inhibit_rules:# 如果"dc"的值相同的前提條件下。# 則當觸發了"severity: critical"告警,就會抑制"severity: warning"的告警信息。
- source_match:severity: criticaltarget_match:severity: warningequal:- dc3.?啟動Alertmanager&&DingDing
[root@node-exporter43 prometheus-webhook-dingtalk-2.1.0.linux-amd64]# ./prometheus-webhook-dingtalk --web.listen-address="10.0.0.43:8060" [root@node-exporter43 alertmanager-0.28.1.linux-amd64]# ./alertmanager 4.?停止服務在釘釘驗證
[root@node-exporter41 ~]# systemctl stop node-exporter.service
[root@node-exporter42 ~]# systemctl stop node-exporter.service
### 這里故意停止了相同的equal指標但是警告等級不一樣,這時候只會報警我們警告時(災難)嚴重級別的節點信息。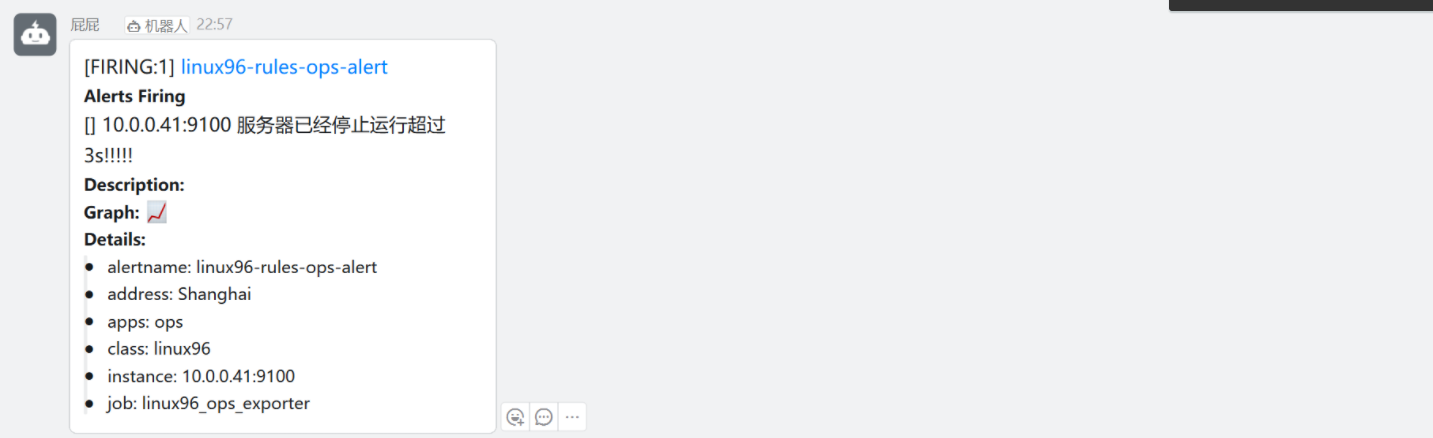
[root@node-exporter43 ~]# systemctl stop node-exporter.service?
再停止一個43節點不同equal指標的,當然就可以正常通知了
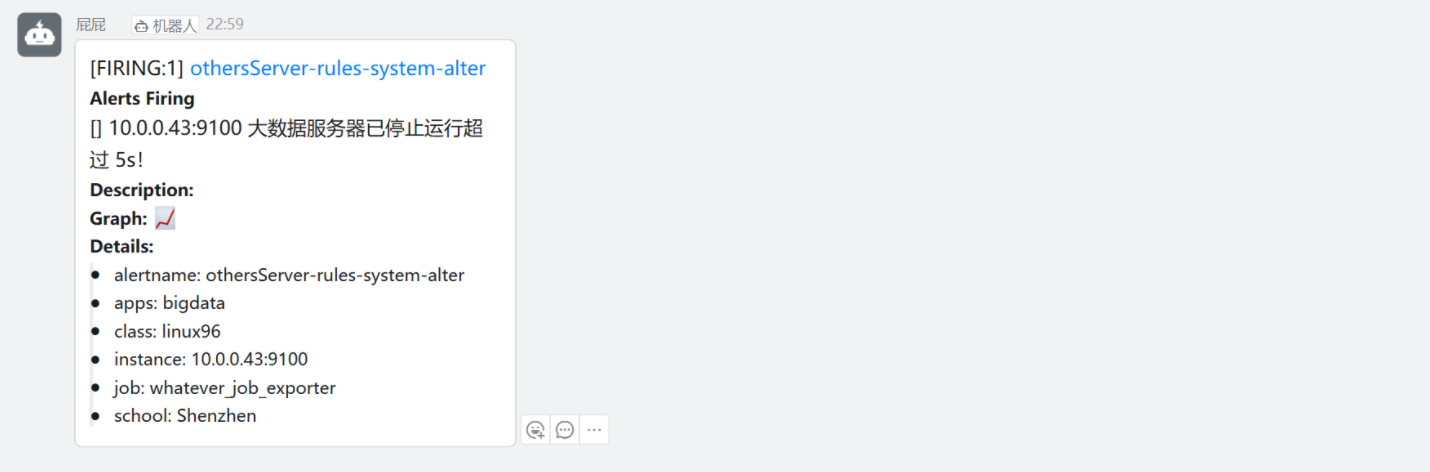
5. 恢復測試?
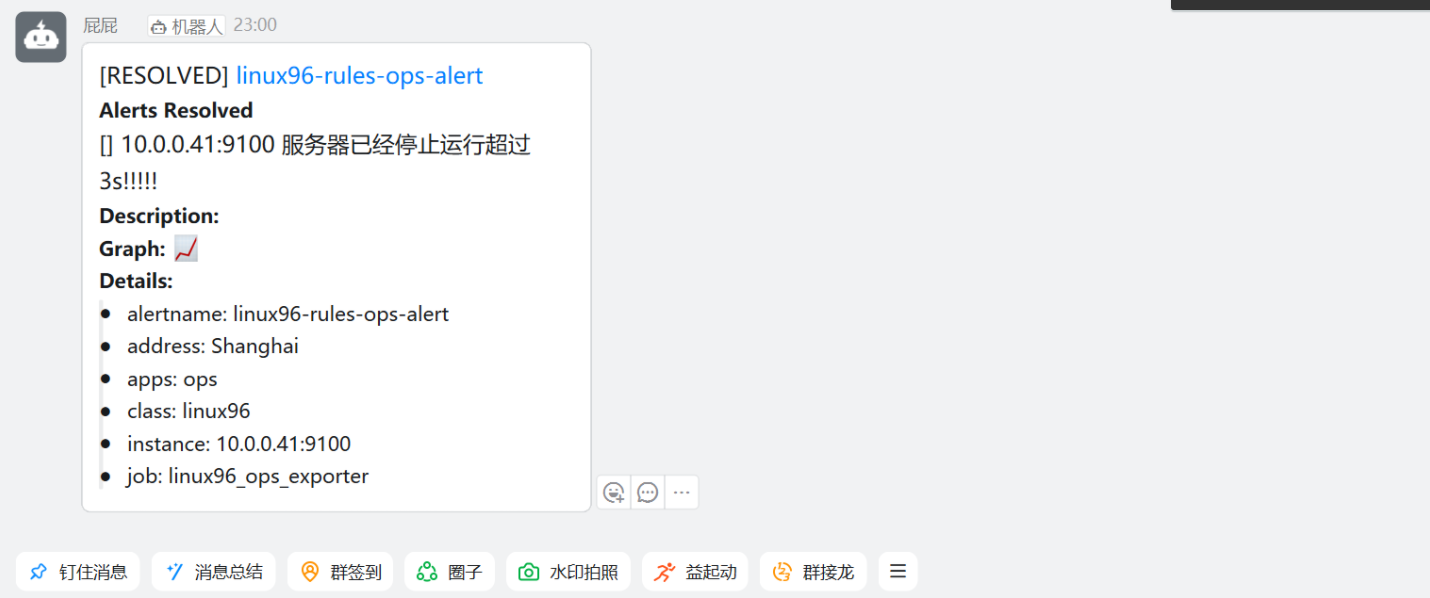
如果恢復了就正常恢復報警
[root@node-exporter41 ~]# systemctl start node-exporter.service
[root@node-exporter42 ~]# systemctl start node-exporter.service
[root@node-exporter43 ~]# systemctl start node-exporter.service?
八、總結
在本博客中,我們深入探討了 Prometheus 生態系統中的兩個重要組件 ——Pushgateway 和 Alertmanager。通過學習和實踐,我們了解到 Pushgateway 在特殊場景下(如短生命周期任務、防火墻限制等)彌補了 Prometheus 拉模式的不足,能夠接收客戶端推送的指標數據并臨時存儲,以便 Prometheus Server 進行拉取監控。我們還了解到 Alertmanager 的強大功能,它負責處理來自 Prometheus Server 的告警信息,實現了告警的分組、去重、抑制以及靈活的通知方式,使得告警系統更加高效和智能。
同時,我們還通過示例腳本的講解,掌握了如何利用 Pushgateway 來推送自定義的 TCP 連接狀態指標數據,進一步拓展了 Prometheus 的監控能力。理解并熟練運用 Pushgateway 和 Alertmanager 這兩個組件,對于我們構建一個完整、高效、可靠的監控告警體系具有重要意義,能夠更好地保障系統的穩定運行和及時響應問題。


)

:核心概念 + 命令詳解 + 部署案例】)
)
 - 解堆 (行 -> 列))












