在數據分析中,我們經常會看到帶有時間屬性的數據,比如股價波動,各種商品銷售數據,網站的網絡用戶活躍度等。一般來說,根據需求我們會分為兩種,分析歷史數據的特點和預測未來時間段的數據。
移動平均
移動平均的原理是用幾天的數據作為一個窗口,根據權重乘以值得出預測該天的數據。我們以分析銷售數據作為例子:
set.seed(123)
weeks <- 1:15
sales <- round(5000 + cumsum(rnorm(15, sd=300))) # 隨機波動
ma3_forecast <- stats::filter(sales, rep(1/3,3), sides=1)
# 預測第16周
next_week <- tail(ma3_forecast,1)
plot(weeks, sales, type="o", ylim=c(4000,6000),main="便利店周銷售額預測", ylab="銷售額", xlab="周數")
lines(weeks, ma3_forecast, col="red", type="o")
points(16, next_week, col="red", pch=19)
abline(v=15.5, lty=2)
text(16, next_week, labels=paste("預測:",round(next_week)), pos=4)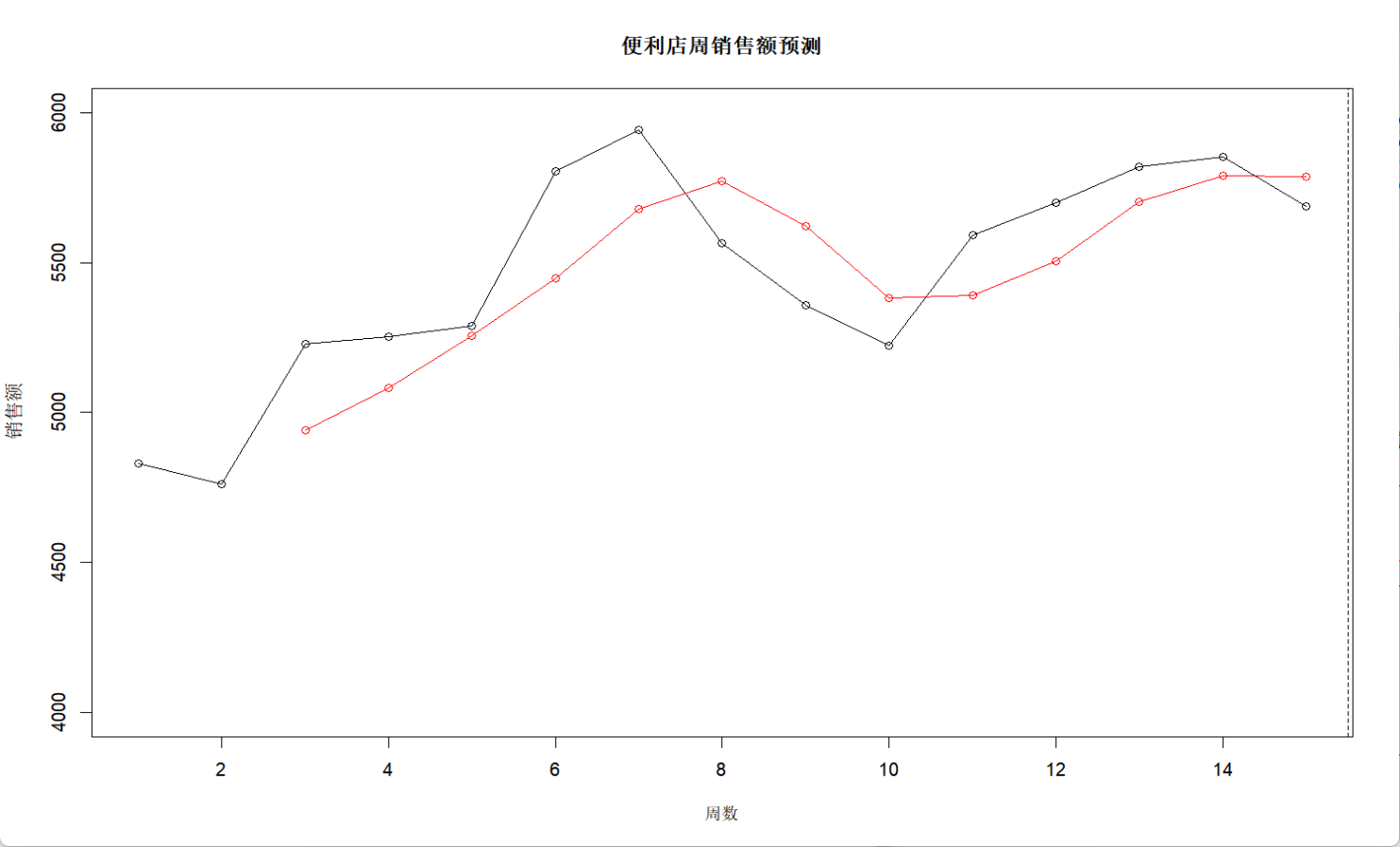
這里由于是要進行預測數據,代碼里的語法選擇了sides=1,意思是用歷史數據來預測,圖中的紅點是基于歷史數據生成的對于預測點,從這里我們可以觀察到紅色曲線像是往右偏移了的灰色曲線,這表明了如果簡單的用歷史數據去預測,那么預測得到的數據的特點會具有滯后性。
接下來我們來看看研究過去的體溫數據的例子:
set.seed(123)
days <- 1:14
true_temp <- 36.5 + 0.1 * sin(2 * pi * days/7) # 真實體溫有輕微周波動
measured_temp <- true_temp + rnorm(14, sd=0.3) # 測量誤差
ma3 <- stats::filter(measured_temp, rep(1/3, 3), sides=2)
plot(days, measured_temp, type="o", col="gray", main="每日體溫監測", ylab="體溫(℃)", xlab="天數") # 原始數據
lines(days, true_temp, col="green", lwd=2) # 平滑后的趨勢
lines(days, ma3, col="red", lwd=2, type="o")
legend("topright", legend=c("測量值", "真實值", "3天移動平均"),col=c("gray", "green", "red"), lty=1, pch=c(1,NA,1))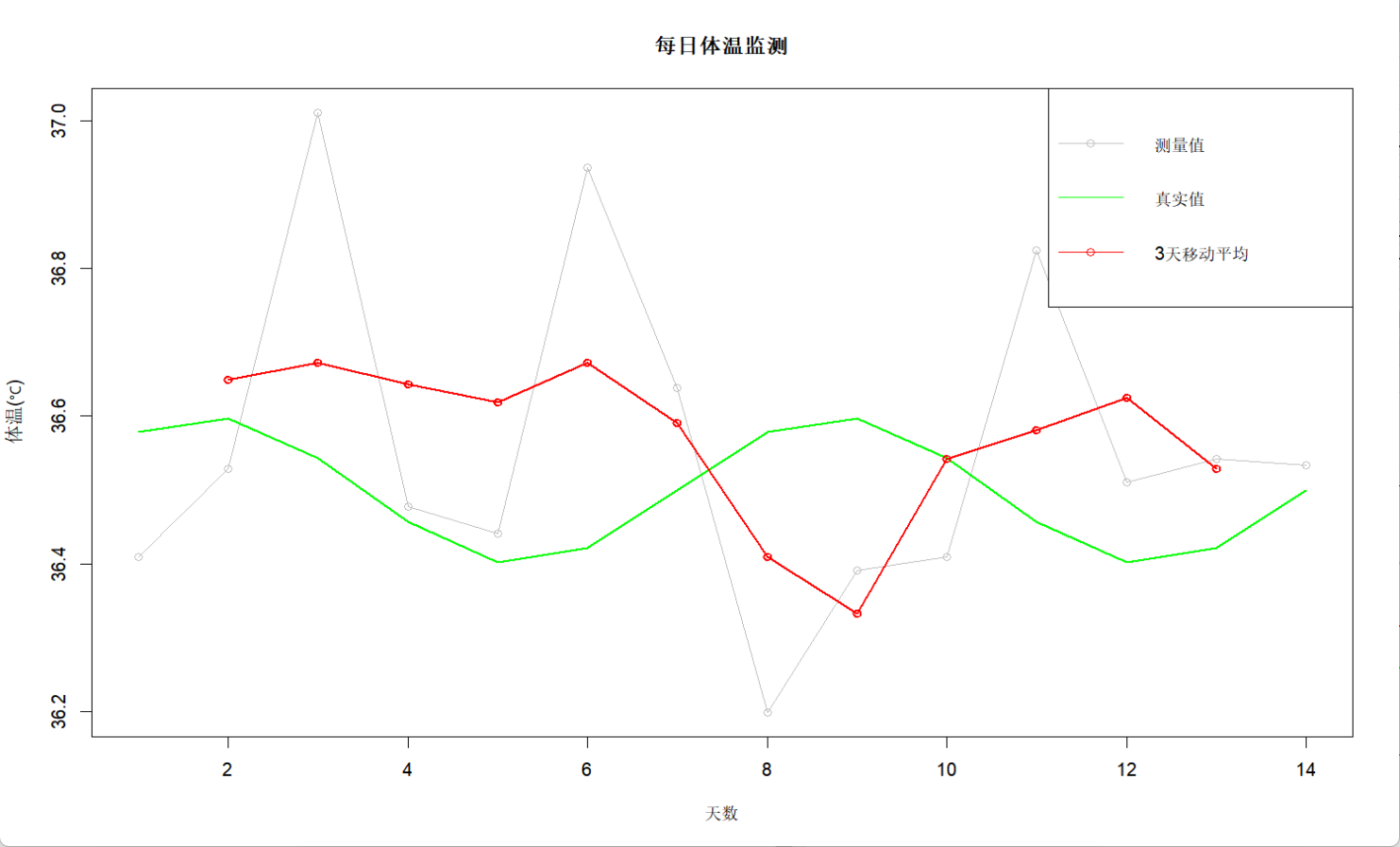
在這里我們用的是sides=2,表示中心平均,也就是三個數據的權重相同,當然了,如果數據本身特殊,也可以用不等量權重weight <- c(0.2,0.5,0.3),注意最左邊的是最靠近預測天數的那一個數據點。之所以分析歷史數據時我們用中心平均,是因為這樣利用了前后信息,可以從數據點的下一個數據得出反饋。此外,通過比較原始數據與平滑數據的偏差,如果某點的偏差遠大于其他點(如超出2倍標準差),我們也可以借機對其進行異常標記。像股價分析問題中,用中心化平滑股價波動,如果某天價格大幅度偏離平滑線,那就有可能是市場異常事件導致的。



)






:角色菜單)








![[De1CTF 2019]SSRF Me](http://pic.xiahunao.cn/[De1CTF 2019]SSRF Me)