SDS
Redis是基于C語言實現的,但是Redis中大量使用的字符串并沒有直接使用C語言字符串。
一、SDS 的設計動機
傳統 C 字符串以 \0 結尾,存在以下問題:
- 性能瓶頸:獲取長度需遍歷字符數組,時間復雜度 O(n)。
- 緩沖區溢出:拼接操作可能覆蓋相鄰內存。
- 二進制不安全:無法存儲含
\0的數據(如圖片、音頻)。 - 內存重分配頻繁:每次修改可能觸發
realloc,影響性能。
SDS 通過 結構體封裝元數據 和 內存預分配策略 解決這些問題。
二、SDS 的結構設計
SDS 的底層結構由 Header(元數據) 和 字符數組(實際數據) 組成。以 Redis 5.0 為例,其結構定義如下:
struct sdshdr {uint8_t len; // 已使用的字節數(字符串真實長度)uint8_t alloc; // 分配的總字節數(不含 Header)unsigned char flags; // SDS 類型標記(如 sdshdr5、sdshdr8)char buf[]; // 柔性數組,存儲實際字符(以 '\0' 結尾)
};
內存布局

三、SDS 的核心原理
1. O(1) 時間復雜度獲取長度
- 傳統 C 字符串:需遍歷直到
\0,時間復雜度 O(n)。 - SDS:直接讀取
len屬性,時間復雜度 O(1)。
2. 杜絕緩沖區溢出
- 自動擴容檢查:修改字符串前,檢查
alloc - len的剩余空間。- 空間不足時:觸發擴容機制,擴展至
新長度 * 2(小于 1MB)或新長度 + 1MB(大于 1MB)。
- 空間不足時:觸發擴容機制,擴展至
- 示例:
原字符串長度 5MB,追加 2MB 數據,新分配空間為5MB + 2MB + 1MB = 8MB。
3. 二進制安全
- 不依賴
\0終止符:通過len記錄真實長度,允許存儲任意二進制數據(包括\0)。 - 示例:
存儲 JPEG 圖片數據時,即使內容含多個\0,SDS 也能完整保存。
4. 內存優化策略
- 預分配(Pre-allocation):
擴容時預留額外空間,減少后續修改時的內存分配次數。 - 惰性釋放(Lazy Free):
縮短字符串時不立即釋放內存,僅減少len,保留alloc供后續使用。
Intset
Redis 的 intset(整數集合) 是一種高效的有序整數存儲結構,專門用于優化小規模整數集合的內存占用和查詢性能。
一、intset 的結構設計
1. 內存布局
intset 由三部分組成:
typedef struct intset {uint32_t encoding; // 編碼方式(決定每個整數占用的字節數)uint32_t length; // 元素數量int8_t contents[]; // 柔性數組,實際存儲整數
} intset;
- encoding:編碼類型,可選值:
INTSET_ENC_INT16(2 字節,范圍 -32768~32767)INTSET_ENC_INT32(4 字節,范圍 -231~231-1)INTSET_ENC_INT64(8 字節,范圍 -263~263-1)
- contents:元素按升序排列,便于二分查找。
二、intset 的核心特性
1. 動態編碼升級
- 觸發條件:插入的整數超出當前編碼范圍時,自動升級編碼(如從
INT16升級到INT32)。 - 升級過程:
- 計算新編碼所需空間。
- 按新編碼重新分配內存,并將舊數據轉換為新格式。
- 插入新元素并保持有序。
- 示例:
原編碼為INT16,插入40000(超出INT16范圍) → 升級為INT32。
2. 有序存儲
- 元素排序:所有整數按升序排列,支持 O(log n) 時間復雜度的二分查找。
- 插入復雜度:
- 查找位置 O(log n) + 移動元素 O(n)(需保持有序性)。
- 編碼升級時還需 O(n) 時間轉換數據。
3.案例分析
數組中先插入5,10,20
為了方便查找,Redis會將intset中所有的整數按照升序依次保存在contents數組中,結構如圖:
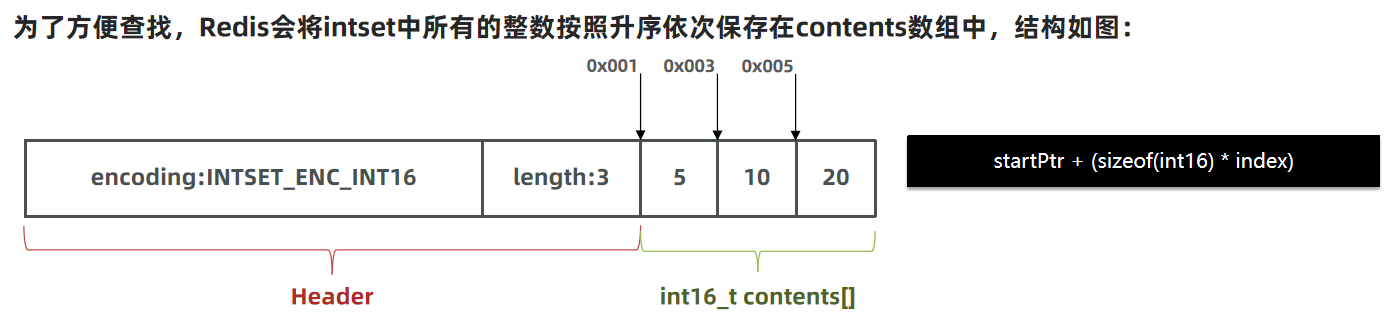
現在,數組中每個數字都在int16_t的范圍內,因此采用的編碼方式是INTSET_ENC_INT16,每部分占用的字節大小為:
encoding:4字節
length:4字節
contents:2字節 * 3 = 6字節

我們向該其中添加一個數字:50000,這個數字超出了int16_t的范圍,intset會自動升級編碼方式到合適的大小。
以當前案例來說流程如下:
- 升級編碼為INTSET_ENC_INT32, 每個整數占4字節,并按照新的編碼方式及元素個數擴容數組
- 倒序依次將數組中的元素拷貝到擴容后的正確位置(防止覆蓋后續元素)
- 將待添加的元素放入數組末尾
- 最后,將inset的encoding屬性改為INTSET_ENC_INT32,將length屬性改為4

4.插入元素以及擴容源碼
/* Upgrades the intset to a larger encoding and inserts the given integer. */
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {uint8_t curenc = intrev32ifbe(is->encoding);uint8_t newenc = _intsetValueEncoding(value);int length = intrev32ifbe(is->length);int prepend = value < 0 ? 1 : 0;/* First set new encoding and resize */is->encoding = intrev32ifbe(newenc);is = intsetResize(is,intrev32ifbe(is->length)+1);/* Upgrade back-to-front so we don't overwrite values.* Note that the "prepend" variable is used to make sure we have an empty* space at either the beginning or the end of the intset. */while(length--)_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));/* Set the value at the beginning or the end. */if (prepend)_intsetSet(is,0,value);else_intsetSet(is,intrev32ifbe(is->length),value);is->length = intrev32ifbe(intrev32ifbe(is->length)+1);return is;
}
Dict
Redis 中的 dict(字典) 是核心數據結構之一,用于實現鍵值存儲(Key-Value)、哈希類型(Hash)及數據庫鍵空間(Keyspace)等核心功能。
一、dict 的結構設計
1. 核心結構體定義
我們知道Redis是一個鍵值型(Key-Value Pair)的數據庫,我們可以根據鍵實現快速的增刪改查。而鍵與值的映射關系正是通過Dict來實現的。
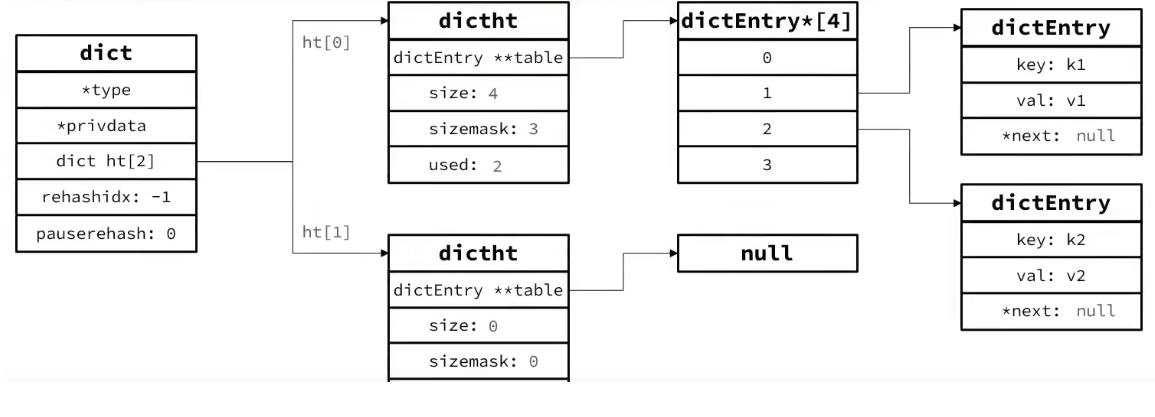
Dict由三部分組成,分別是:哈希表(DictHashTable)、哈希節點(DictEntry)和字典(Dict)
// 哈希表結構
typedef struct dictht {dictEntry **table; // 哈希桶數組(鏈式存儲)unsigned long size; // 哈希表大小(桶數量,2^n)unsigned long sizemask; // 哈希掩碼(size-1,用于計算索引)unsigned long used; // 已使用的桶數量(含鏈表節點)
} dictht;// 字典結構
typedef struct dict {dictType *type; // 類型特定函數(如哈希函數、鍵比較函數)void *privdata; // 私有數據(用于擴展)dictht ht[2]; // 兩個哈希表(用于漸進式 rehash)long rehashidx; // rehash 進度(-1 表示未進行)int iterators; // 當前運行的迭代器數量
} dict;// 哈希表節點(鏈表結構)
typedef struct dictEntry {void *key; // 鍵union {void *val;uint64_t u64;int64_t s64;double d;} v; // 值(支持多種類型)struct dictEntry *next; // 指向下一個節點(解決哈希沖突)
} dictEntry;
二、dict 的核心機制
1. 哈希函數與沖突解決
- 哈希函數:Redis 默認使用 MurmurHash2 算法(非加密型,高性能,分布均勻)。
- 沖突解決:采用 鏈地址法(Separate Chaining),同一桶內的節點以鏈表連接。
2.擴容
觸發條件
- 負載因子(Load Factor):
- 常規擴容:
load_factor = used / size ≥ 1,且當前未在后臺執行BGSAVE或BGREWRITEAOF。 - 強制擴容:
load_factor ≥ 5(無論是否在執行持久化操作,避免哈希沖突嚴重導致性能驟降)。
- 常規擴容:
擴容流程
-
計算新表大小:
- 新哈希表的大小為 第一個 ≥
used \* 2的 2^n(如used=3 → size=8)。 - 若當前正在執行
BGSAVE或BGREWRITEAOF,Redis 會 延遲擴容(避免資源過度消耗)。
- 新哈希表的大小為 第一個 ≥
-
初始化新哈希表(ht[1]):
// 分配新哈希表內存 dictht *new_ht = &d->ht[1]; new_ht->size = next_power(used * 2); new_ht->table = zcalloc(new_ht->size * sizeof(dictEntry*)); new_ht->sizemask = new_ht->size - 1; -
啟動漸進式 Rehash:
- 設置
rehashidx = 0,表示開始從舊表ht[0]的第 0 號桶遷移數據到ht[1]。 - 后續每次對字典的增刪改查操作,均遷移一個桶的數據,直到完成所有遷移。
- 設置
擴容設計思想
- 2^n 大小:通過位運算(
hash & sizemask)快速計算索引。 - 漸進式遷移:避免一次性遷移大量數據導致服務阻塞。
三、縮容
1. 觸發條件
- 負載因子(Load Factor):
load_factor = used / size < 0.1(默認閾值)。
2. 縮容流程
-
計算新表大小:
- 新哈希表的大小為 第一個 ≥
used的 2^n(如used=3 → size=4)。 - 若
used=0,則直接釋放舊表,重置為初始狀態。
- 新哈希表的大小為 第一個 ≥
-
初始化新哈希表(ht[1]):
dictht *new_ht = &d->ht[1]; new_ht->size = next_power(used); new_ht->table = zcalloc(new_ht->size * sizeof(dictEntry*)); new_ht->sizemask = new_ht->size - 1; -
啟動漸進式 Rehash:
- 與擴容相同,逐步遷移數據到新表
ht[1]。 - 遷移完成后,釋放舊表
ht[0],將ht[1]設為ht[0]。
- 與擴容相同,逐步遷移數據到新表
3. 縮容設計思想
- 節省內存:避免因數據刪除后哈希表過大導致內存浪費。
- 延遲縮容:防止頻繁縮容觸發性能抖動。
四、漸進式 Rehash 的通用流程
無論是擴容還是縮容,必定會創建新的哈希表,導致哈希表的size和sizemask變化,而key的查詢與sizemask有關。同時為了防止一次轉移導致的性能抖動,采用漸進式 Rehash 完成數據遷移:
-
每次操作觸發遷移:
- 對字典的 增、刪、改、查 操作均可能觸發遷移一個桶的數據。
- 遷移的桶號為
rehashidx,完成后rehashidx++。
-
遷移單個桶的步驟:
a. 遍歷舊桶鏈表:處理ht[0].table[rehashidx]的所有節點。
b. 重新哈希計算索引:對新表ht[1]計算每個節點的哈希值和索引。for (entry = old_table[rehashidx]; entry != NULL; entry = next_entry) {next_entry = entry->next;// 計算新索引uint64_t hash = dict->type->hashFunction(entry->key);uint64_t new_index = hash & new_sizemask;// 插入新表entry->next = new_table[new_index];new_table[new_index] = entry; }c. 清空舊桶:將
ht[0].table[rehashidx]設為NULL。
d. 更新計數器:遞減ht[0].used,遞增ht[1].used。 -
檢查遷移完成:
- 當
rehashidx >= ht[0].size時,所有桶遷移完成。 - 釋放舊表:銷毀
ht[0].table,將ht[1]設為ht[0],重置ht[1]為空。 - 結束 Rehash:設置
rehashidx = -1。
- 當
三、添加鍵值對的核心流程
1. 檢查 Rehash 狀態
- 判斷是否處于 Rehash:
- 若字典的
rehashidx != -1,表示正在進行 漸進式 Rehash(數據從舊表ht[0]遷移到新表ht[1])。 - 直接操作新表:所有新插入的鍵值對會寫入
ht[1],避免舊表ht[0]繼續積累數據。 - 觸發遷移:每次插入操作后,順帶遷移
ht[0]中的一個桶(Bucket)到ht[1],逐步完成數據遷移。
- 若字典的
2. 計算哈希值與索引
-
哈希函數:使用預設的哈希算法(如 MurmurHash2)計算鍵的哈希值。
hash = dict->type->hashFunction(key); // 例如,MurmurHash2 -
確定桶索引:通過哈希值與當前哈希表的大小掩碼(
sizemask = size - 1)計算索引。index = hash & dict->ht[table].sizemask; // table=0 或 1(取決于是否在 Rehash)
3. 處理鍵的存在性
-
遍歷鏈表:在目標桶的鏈表中順序查找鍵是否存在。
-
鍵已存在:
- 替換舊值,釋放舊值內存(若配置了值釋放函數)。
- 返回
DICT_OK表示更新成功。
-
鍵不存在:
- 創建新節點
dictEntry,將鍵值對存入。 - 頭插法插入鏈表:將新節點插入鏈表頭部(時間復雜度 O(1))。
entry->next = ht->table[index]; ht->table[index] = entry; - 創建新節點
-
4. 更新計數器與觸發擴容
-
更新計數器:遞增哈希表的
used計數器,表示已用桶數量增加。ht->used++; -
檢查擴容條件:
- 負載因子:計算
load_factor = used / size。 - 觸發擴容:
- 常規擴容:若
load_factor ≥ 1且允許擴容。 - 強制擴容:若
load_factor ≥ 5(避免哈希沖突嚴重導致性能驟降)。
- 常規擴容:若
- 擴容操作:
- 創建新哈希表
ht[1],大小為第一個 ≥used * 2的 2 的冪次(如used=4 → size=8)。 - 設置
rehashidx=0,啟動漸進式 Rehash。
- 創建新哈希表
- 負載因子:計算
5. 返回結果
- 成功:返回
DICT_OK。 - 失敗:若內存分配失敗(如無法創建新節點),返回
DICT_ERR。
graph TDsubgraph 添加鍵值對核心流程start([開始]) --> check_rehash{檢查Rehash狀態}check_rehash --> |rehashidx != -1| new_table[操作新表ht<x-preset class="no-tts reference-tag disable-to-doc" data-index="1">1</x-preset>]new_table --> migrate[遷移ht<x-preset class="no-tts reference-tag disable-to-doc" data-index="0">0</x-preset>的一個桶到ht<x-preset class="no-tts reference-tag disable-to-doc" data-index="1">1</x-preset>]check_rehash --> |rehashidx = -1| compute_hash[計算哈希值]migrate --> compute_hashcompute_hash --> get_index[計算桶索引: hash & sizemask]get_index --> key_check{鍵是否存在?}key_check --> |存在| replace[替換舊值并釋放內存]replace --> return_ok[返回DICT_OK]key_check --> |不存在| create_entry[創建新dictEntry]create_entry --> insert[頭插法插入鏈表]insert --> update_counter[更新used計數器]update_counter --> check_expand{檢查擴容條件}check_expand --> |load_factor ≥1| normal_expand[常規擴容]check_expand --> |load_factor ≥5| force_expand[強制擴容]normal_expand --> create_ht1[創建ht<x-preset class="no-tts reference-tag disable-to-doc" data-index="1">1</x-preset>\n大小為used*2的2^n]force_expand --> create_ht1create_ht1 --> start_rehash[設置rehashidx=0]start_rehash --> return_okreturn_ok --> end_process([結束])check_expand --> |無需擴容| return_okend_processend
Ziplist
一、ziplist的結構設計
1.整體布局

- **zlbytes(4字節)😗*總字節數,用于快速獲取列表大小。
- **zltail(4字節)😗*尾節點偏移量,用于定位尾節點。
- **zllen(2字節)😗*節點長度(數量)(若超過65535,需遍歷計算)。
- **entry:**節點單元,存儲數據。
- **zlend(1字節)😗*結束標識(0xFF)。
2.Entry結構

- **previous_entry_length(1或5字節)😗*前一節點單元大小。
- 前驅長度≤ 253:
prelen占一字節。 - 前驅長度 > 253:
prevlen首字節固定為0xFE,后4字節存儲實際長度。
- 前驅長度≤ 253:
- **encoding(1、2、5字節)😗*編碼屬性,用于標識
content的類型(字符串或整數)和長度。 - **content:**保存數據(字符串或整數)。
3.Encoding編碼
分為字符串和整數兩種
字符串類型編碼
字符串類型以00(1字節)、01(2字節)、10(5字節)開頭,除前兩位外其余位均記錄字符串大小。
| 編碼 | 編碼長度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
整數類型編碼
整數類型以11開頭,固定為1字節,其余六位標識五種整數類型分別占據了00|0000、01|0000、10|0000。這樣我們就能用11|xxxx直接保存數據在后四位,而11|0000和11|1110、0xff(結束標識)被占據所以具體可存儲值有13個。
| 編碼 | 編碼長度 | 整數類型 |
|---|---|---|
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int32_t(4 bytes) |
| 11100000 | 1 | int64_t(8 bytes) |
| 11110000 | 1 | 24位有符整數(3 bytes) |
| 11111110 | 1 | 8位有符整數(1 bytes) |
| 1111xxxx | 1 | 直接在xxxx位置保存數值,范圍從0001~1101,減1后結果為實際值 |
二、ziplist 的核心特性
1. 內存緊湊
- 連續存儲:消除指針開銷,內存利用率高。
- 變長編碼:根據數據動態調整存儲空間(如小整數用1字節)。
2. 雙向遍歷
- 前驅指針模擬:通過
prevlen字段反向計算前驅 entry 起始位置。 - 正向遍歷:利用
encoding解析當前 entry 長度,跳至下一 entry。
3. 自動編碼轉換
- 閾值控制:當元素數量或大小超過配置(如
hash-max-ziplist-entries),轉為標準結構(如哈希表)。
三、ziplist 的操作機制
1. 插入操作
- 定位插入點:遍歷找到位置,計算所需空間。
- 內存重分配:擴展 ziplist 內存,移動后續 entry。
- 更新前后 entry:
- 修改后繼 entry 的
prevlen。 - 可能觸發 級聯更新(Cascade Update):若新 entry 導致后繼 entry 的
prevlen擴容(1→5字節),需遞歸處理后續 entry。
- 修改后繼 entry 的
2. 刪除操作
- 內存縮容:移除 entry 后,前移后續數據。
- 級聯更新風險:類似插入,可能觸發后繼 entry 的
prevlen調整。
3. 查詢操作
- 順序遍歷:從頭或尾(利用
zltail)開始,解析每個 entry 的encoding和prevlen。
四、級聯更新(Cascade Update)
1. 觸發條件
插入或刪除 entry 導致后繼 entry 的 prevlen 從1字節擴展為5字節(或反向收縮)
例如連續節點大小為250-253(前驅節點大小1字節),有一節點數據變更超出253字節,后續節點的prelen變為5字節存儲,變更后這個節點的大小也超過了253字節,循環往復。
2. 性能影響
- 最壞時間復雜度:O(n2)(如所有 entry 的
prevlen均需調整)。 - 實際場景:概率極低,通常在小規模 ziplist 中影響有限。
QuickList
quicklist 是 Redis 用于實現 列表(List) 數據類型的核心數據結構,結合了 ziplist(壓縮列表)和 linkedlist(雙向鏈表)的優勢,在內存效率與操作性能之間取得平衡。
一、qiucklist的設計背景
1.早期列表實現的不足
- ziplist
- **優點:**內存緊湊,不需要指針占據額外內存空間。
- **缺點:**插入、刪除操作需重分配內存,移動后續節點,大規模數據下性能差。
- linedlist
- 優點:插入、刪除高效。
- 缺點:內存碎片多,指針占據額外空間。
2.qiucklist的優勢
? 保留ziplist的內存緊湊優勢,同時限制ziplist大小,將多個ziplist通過雙向鏈表連接,避免了單個ziplist在大規模數據下內存重分配帶來的性能差的弊端。
二、quicklist的結構
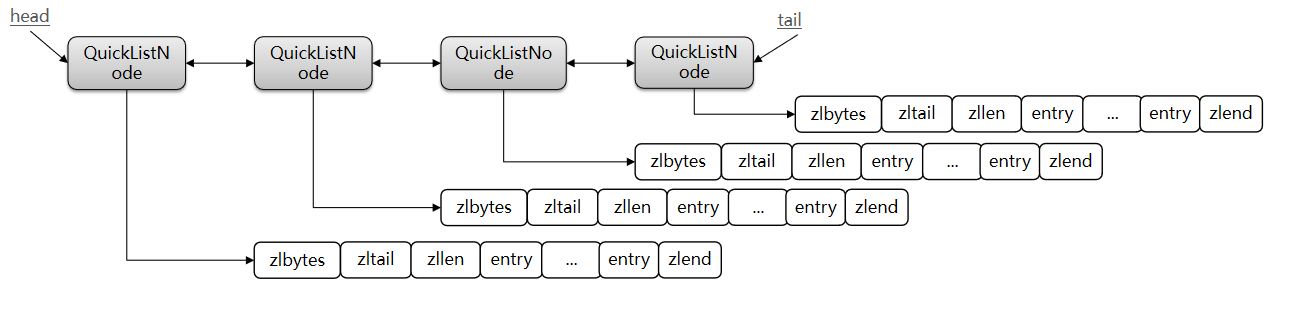
為了避免QuickList中的每個ZipList中entry過多,Redis提供了一個配置項:list-max-ziplist-size來限制。
如果值為正,則代表ZipList的允許的entry個數的最大值
如果值為負,則代表ZipList的最大內存大小,分5種情況:
- -1:每個ZipList的內存占用不能超過4kb
- -2:每個ZipList的內存占用不能超過8kb
- -3:每個ZipList的內存占用不能超過16kb
- -4:每個ZipList的內存占用不能超過32kb
- -5:每個ZipList的內存占用不能超過64kb
其默認值為 -2
三、quicklist 的核心機制
1. 動態節點管理
- 節點分裂:當插入元素導致單個 ziplist 超過
fill閾值時,分裂為兩個節點。 - 節點合并:當刪除元素導致相鄰節點容量過小時,合并以減少內存碎片。
2. 壓縮優化
- LZF 壓縮算法:對中間節點進行壓縮(
compress參數控制壓縮深度)。- 壓縮深度為 0:不壓縮。
- 壓縮深度為 1:頭尾各保留 1 個節點不壓縮,其余壓縮。
- 壓縮深度為 2:頭尾各保留 2 個節點不壓縮,其余壓縮。
SkipList
一、跳表的核心設計
1. 基本概念
跳表通過 多層鏈表 實現有序數據的快速訪問。每個節點包含多個 層級,每層維護一個指向后續節點的指針,高層指針可跨越多個低層節點,從而加速查找。
2. 節點結構
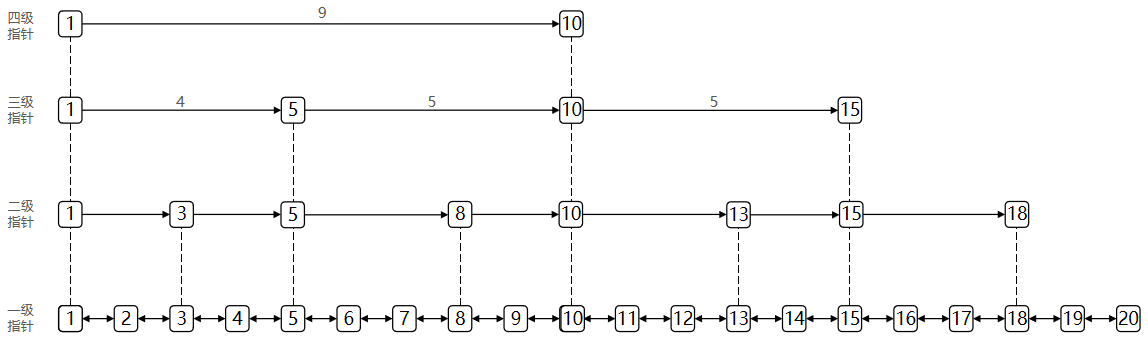
3. 層數生成規則
- 冪次定律:新節點的層數隨機生成,概率逐層減半。
- 第 1 層概率:100%
- 第 2 層概率:50%
- 第 3 層概率:25%
- …
- 最大層數:
ZSKIPLIST_MAXLEVEL = 32(Redis 默認限制)
二、跳表的操作機制
1. 查找操作
- 從最高層開始:逐層遍歷,若當前層的下個節點分值大于目標值,則下降一層繼續查找。
- 時間復雜度:平均 O(log n),最壞 O(n)。
2. 插入操作
- 確定插入位置:查找過程中記錄每層的前驅節點。
- 生成隨機層數:根據冪次定律確定新節點層數。
- 調整指針:將新節點插入各層鏈表,更新前后節點的指針和跨度。
3. 刪除操作
- 定位節點:查找目標節點,并記錄各層前驅節點。
- 更新指針:將前驅節點的指針指向目標節點的后繼節點。
- 釋放內存:若節點無其他引用,釋放內存。
RedisObject
Redis 的 redisObject 是管理所有數據類型(如字符串、列表、哈希等)的核心結構,它通過統一的接口抽象,實現了內存優化、編碼轉換等操作。
一、redisObject 的結構定義
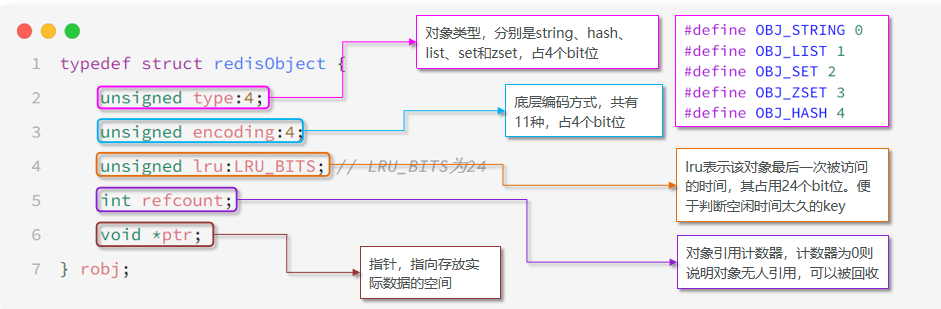
二、核心字段詳解
1. 數據類型(type)
Redis 支持 5 種基礎數據類型,由 type 標識:
OBJ_STRING:字符串(簡單值、計數器、二進制數據)。OBJ_LIST:列表(隊列、棧、阻塞隊列)。OBJ_HASH:哈希(對象屬性存儲)。OBJ_SET:集合(唯一性集合、交并差運算)。OBJ_ZSET:有序集合(排行榜、范圍查詢)。
2. 編碼方式(encoding)
同一數據類型可對應多種底層編碼,Redis 根據數據特征自動選擇最優編碼:
| 數據類型 | 編碼方式(encoding) | 底層結構 | 適用場景 |
|---|---|---|---|
| 字符串 | OBJ_ENCODING_INT | 整數直接存儲 | 值為整數(如 SET key 42) |
OBJ_ENCODING_EMBSTR | embstr 格式 SDS | 短字符串(≤44字節) | |
OBJ_ENCODING_RAW | SDS 動態字符串 | 長字符串或二進制數據 | |
| 列表 | OBJ_ENCODING_QUICKLIST | 快速列表(分段 ziplist) | 默認實現(Redis 3.2+) |
| 哈希 | OBJ_ENCODING_ZIPLIST | 壓縮列表(ziplist) | 字段少且值小(配置閾值內) |
OBJ_ENCODING_HT | 哈希表(dict) | 字段多或值大 | |
| 集合 | OBJ_ENCODING_INTSET | 整數集合(intset) | 元素全為整數且數量少 |
OBJ_ENCODING_HT | 哈希表(dict) | 元素含非整數或數量超限 | |
| 有序集合 | OBJ_ENCODING_ZIPLIST | 壓縮列表(ziplist) | 元素少且值小(配置閾值內) |
OBJ_ENCODING_SKIPLIST | 跳躍表 + 哈希表(組合結構) | 元素多或值大 |

)






:角色菜單)








![[De1CTF 2019]SSRF Me](http://pic.xiahunao.cn/[De1CTF 2019]SSRF Me)

