前言
我是基于token有限而考慮的一個省錢方案,還能夠快速返回結果,但是劣勢也很明顯,設計不好容易出問題,就如下面所介紹的語義飄逸和緩存污染,我認為在自己學習大模型的過程用來省錢非常可以,再加上學習過程中對于語義飄逸和緩存污染這些問題要求不是很高,只是基于大模型開發應用而已,還是得基于原生的大模型來解決。有點雞肋了說實話(doge)。
一、方案可行性分析
優勢
-
顯著節省Token消耗:避免重復計算相似問題
-
提升響應速度:緩存命中時可立即返回結果
-
降低API成本:減少大模型調用次數
潛在問題
-
相似度計算本身消耗Token(需優化計算方式)
-
緩存污染風險:相似但不相同的問題返回錯誤答案,
-
語義漂移:過度依賴緩存導致結果偏離最新知識
以下是于緩存污染和語義漂移的方案,其中相似度計算可以使用本地模型來解決。
后續專門做一節ollama快速部署本地模型的文章。
一、緩存污染解決方案(
產生的原因:相似但不相同的問題返回錯誤答案。
舉幾個例子:
1. 多級相似度校驗
def is_valid_cache(query, cached_query, cached_response):# 第一層:本地嵌入模型快速過濾(零Token消耗)local_sim = cosine_similarity(embed(query), embed(cached_query))if local_sim < 0.7: # 低置信度直接跳過return False# 第二層:關鍵詞/實體對比(防止語義近似但關鍵信息不同)if not key_entities_match(query, cached_query):return False# 第三層:大模型精細驗證(限制Token消耗)verification_prompt = f"""判斷兩個問題是否可共用同一答案(僅輸出Y/N):Q1: {query}Q2: {cached_query}答案: {cached_response}需滿足:1. 核心訴求一致2. 關鍵實體相同3. 答案完全適用輸出:"""return llm.generate(verification_prompt, max_tokens=1).strip() == "Y"
2. 動態閾值調整
-
基于領域敏感度的閾值:
def get_dynamic_threshold(query):if is_high_risk_domain(query): # 如醫療、法律return 0.9elif is_creative_domain(query): # 如文案生成return 0.6else: # 通用場景return 0.8
3. 緩存條目加權
-
基于置信度的緩存權重:
class CacheEntry:def __init__(self, response, confidence):self.response = responseself.weight = confidence * recency_factor() # 綜合置信度和時效性
-
檢索時優先返回高權重結果,低權重條目自動淘汰
二、語義漂移解決方案(結果偏離最新知識)
1. 知識時效性管理
class TemporalCache:def __init__(self):self.time_aware_cache = {} # {hash: (response, timestamp)}def get_valid_response(self, query):entry = self.find_similar(query)if entry and is_fresh(entry.timestamp):return entry.responsereturn Nonedef is_fresh(self, timestamp):# 動態過期策略if is_fast_changing_domain(query):return time.now() - timestamp < timedelta(hours=1)else: # 靜態知識return time.now() - timestamp < timedelta(days=30)
2. 版本化緩存
-
當檢測到以下情況時自動失效緩存:
-
大模型版本更新
-
知識庫更新時間戳變化
-
用戶手動觸發刷新
-
3. 增量驗證機制
def validate_with_latest_knowledge(query, cached_response):# 從最新知識庫抽取關鍵事實facts = knowledge_base.extract_facts(cached_response)# 快速驗證事實有效性(無需調用大模型)for fact in facts:if not knowledge_verifier.verify(fact):return Falsereturn True
三、工程化實踐方案
1. 緩存隔離策略
| 緩存分區 | 存儲內容 | 刷新策略 | 典型TTL |
|---|---|---|---|
| 高頻靜態知識 | 數學公式、常識 | 手動更新 | 永久 |
| 中頻半靜態 | 產品功能說明 | 每周驗證 | 7天 |
| 低頻動態 | 新聞、股價 | 每次請求驗證 | 1小時 |
2. 反饋閉環系統
def add_human_feedback(query, response, is_correct):if not is_correct:# 立即失效相關緩存cache.invalidate_similar(query)# 記錄錯誤模式analytics.log_contamination(query, response)# 觸發重新學習retrain_detector_model(error_case=(query, response))
3. 混合緩存架構
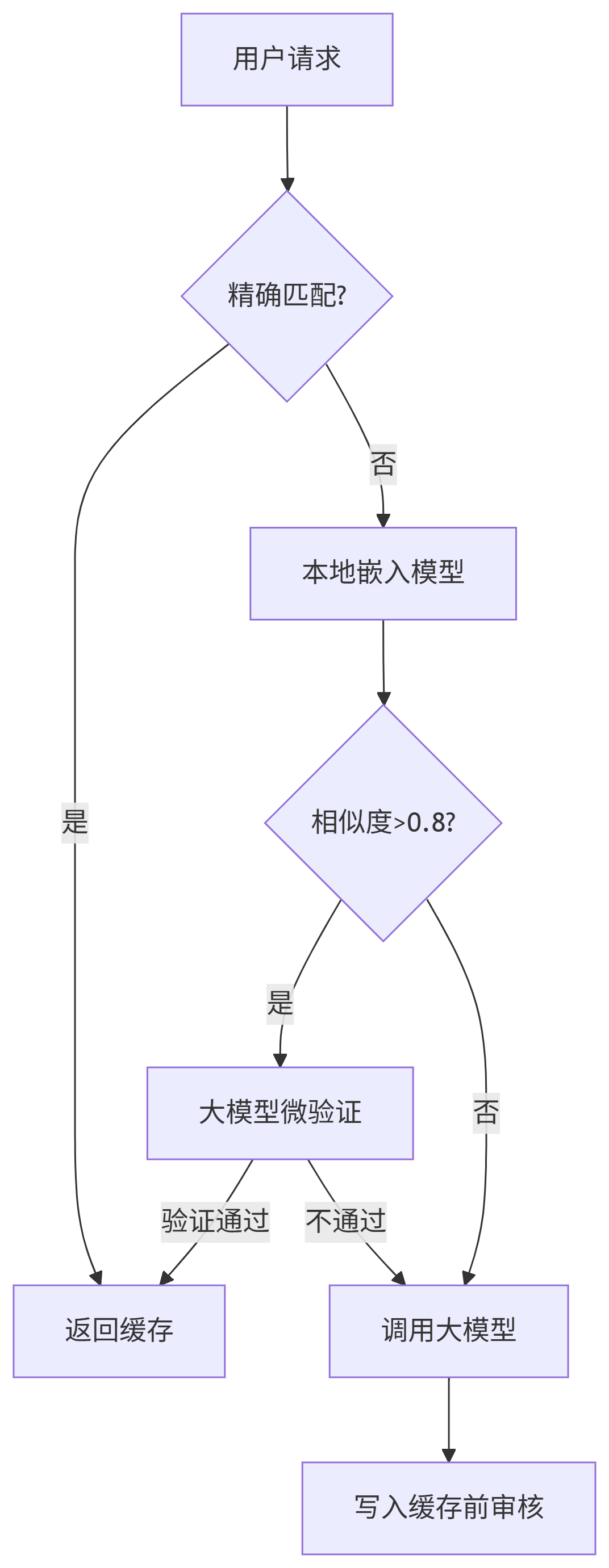
四、驗證與監控指標
1. 實時監控看板
| 指標 | 預警閾值 | 監控手段 |
|---|---|---|
| 緩存污染率 | >2% | 人工抽樣+自動規則檢測 |
| 語義漂移率 | >5% | 知識庫版本比對 |
| 平均置信度 | <0.7 | 相似度計算日志分析 |
2. 自動化測試框架
def run_contamination_test():# 注入已知污染案例test_cases = [("新冠疫苗副作用", "流感疫苗副作用"), # 相似但不同("2023年稅率", "2022年稅率") # 時效性失效]for q1, q2 in test_cases:assert cache.get(q1) != cache.get(q2), f"污染檢測失敗: {q1} vs {q2}"
五、進階方案
1. 對抗訓練增強
-
在緩存系統中注入對抗樣本:
def generate_adversarial_examples():# 生成形似但語義不同的查詢對return [("如何購買比特幣", "如何出售比特幣"),("Python的GIL問題", "Python的GIL優點")]# 定期用對抗樣本測試系統
2. 基于RAG的緩存凈化
def sanitize_cached_response(query, cached_response):# 用最新知識庫修正緩存答案corrected = knowledge_base.correct_with_rag(query, cached_response)if corrected != cached_response:cache.update(query, corrected)return corrected
總結
通過多級校驗、動態閾值、時效管理和反饋閉環的四層防御體系,可有效控制緩存污染和語義漂移。關鍵原則:
-
寧可漏存,不可錯存:嚴格驗證機制犧牲部分命中率換取準確性
-
持續進化:通過監控和對抗訓練不斷優化系統
-
領域適配:醫療/金融等高風險領域需更保守的策略
建議實施路線:
-
先建立基礎緩存+本地嵌入模型
-
加入時效性管理
-
逐步引入大模型驗證層
-
最終構建完整監控體系







Java/python/JavaScript/C/C++/GO最佳實現)











