面向對象三大特性是什么?請舉例說明多態。
面向對象編程(OOP)的三大核心特性是封裝、繼承和多態。封裝是將數據和操作數據的方法綁定在一起,并隱藏對象的內部實現細節;繼承允許一個類繼承另一個類的屬性和方法,從而實現代碼復用和層次化設計;而多態則是指對象在運行時能夠表現出不同形態的能力。
多態的實現依賴于方法重寫和接口實現。在 Java 中,多態主要通過兩種方式體現:繼承多態和接口多態。繼承多態是指子類可以重寫父類的方法,而接口多態則是指實現類可以實現接口中定義的方法。通過多態,我們可以編寫更加靈活、可擴展的代碼,提高系統的可維護性。
例如,有一個抽象類Shape定義了計算面積的抽象方法calculateArea(),并派生出Circle和Rectangle兩個子類。每個子類都重寫了calculateArea()方法以實現自己的計算邏輯。當我們通過父類引用指向子類對象時,調用calculateArea()方法會根據實際對象類型動態調用相應的實現。
abstract class Shape {abstract double calculateArea();
}class Circle extends Shape {private double radius;public Circle(double radius) {this.radius = radius;}@Overridedouble calculateArea() {return Math.PI * radius * radius;}
}class Rectangle extends Shape {private double width;private double height;public Rectangle(double width, double height) {this.width = width;this.height = height;}@Overridedouble calculateArea() {return width * height;}
}public class PolymorphismExample {public static void main(String[] args) {Shape circle = new Circle(5.0);Shape rectangle = new Rectangle(4.0, 6.0);System.out.println("Circle Area: " + circle.calculateArea());System.out.println("Rectangle Area: " + rectangle.calculateArea());}
}
在這個例子中,circle和rectangle都是Shape類型的引用,但實際指向的是不同的子類對象。當調用calculateArea()方法時,Java 虛擬機(JVM)會根據對象的實際類型來決定執行哪個子類的方法實現,這就是多態的核心體現。
多態的優勢在于可以編寫通用的代碼處理不同類型的對象,提高代碼的靈活性和可擴展性。例如,我們可以創建一個Shape數組,存儲不同類型的形狀對象,然后統一調用calculateArea()方法,無需關心具體對象的類型。
Shape[] shapes = new Shape[2];
shapes[0] = new Circle(5.0);
shapes[1] = new Rectangle(4.0, 6.0);for (Shape shape : shapes) {System.out.println("Area: " + shape.calculateArea());
}
這種方式使得代碼更加簡潔、通用,同時也符合開閉原則 —— 對擴展開放,對修改關閉。
extends 和 implement 的區別是什么?
在 Java 中,extends和implement是用于實現繼承和接口的兩個關鍵字,它們在語法和功能上有明顯的區別。
extends關鍵字用于類與類之間的繼承關系,允許一個子類繼承父類的屬性和方法。Java 只支持單繼承,即一個類只能直接繼承自一個父類。通過繼承,子類可以復用父類的代碼,并可以重寫父類的方法以實現自己的特定行為。父類可以是具體類或抽象類,但不能是接口。
implement關鍵字用于類與接口之間的實現關系,允許一個類實現一個或多個接口。接口是一種特殊的抽象類型,只包含方法簽名而不包含實現。類實現接口時,必須實現接口中定義的所有方法。Java 支持多實現,即一個類可以同時實現多個接口,從而彌補了單繼承的局限性。
下面通過一個示例來說明兩者的區別:
// 定義一個父類
class Animal {public void eat() {System.out.println("Animal is eating");}
}// 定義一個接口
interface Flyable {void fly();
}// Bird類繼承自Animal并實現Flyable接口
class Bird extends Animal implements Flyable {@Overridepublic void fly() {System.out.println("Bird is flying");}@Overridepublic void eat() {System.out.println("Bird is eating seeds");}
}// 另一個接口
interface Swimmable {void swim();
}// Duck類繼承自Bird并實現Swimmable接口
class Duck extends Bird implements Swimmable {@Overridepublic void swim() {System.out.println("Duck is swimming");}
}
在這個例子中,Bird類通過extends關鍵字繼承了Animal類的eat()方法,并通過implement關鍵字實現了Flyable接口的fly()方法。Duck類進一步繼承了Bird類,并實現了Swimmable接口,展示了多重實現的能力。
從使用場景來看,extends主要用于創建具有層次結構的類體系,實現代碼復用和行為擴展;而implement則用于定義對象的行為契約,實現不同類之間的行為統一。接口更適合用于定義通用的行為標準,而繼承則更適合用于表示 "is-a" 的關系。
需要注意的是,抽象類和接口在 Java 8 之后的區別變得更加模糊,因為接口可以包含默認方法和靜態方法。但總體來說,抽象類更適合作為相關類的基類,而接口更適合作為獨立的行為模塊。
final 關鍵字的作用及使用場景?
在 Java 中,final關鍵字用于限制事物的可變性,它可以應用于類、方法和變量,分別表示不同的含義和使用場景。
當final用于修飾類時,表示該類不能被繼承,即不能有子類。這種設計通常用于確保類的實現不會被修改,例如 Java 中的String類就是一個final類,它的不可變性確保了字符串在多線程環境下的安全性。
final class FinalClass {// 類的實現
}// 錯誤:無法繼承final類
// class SubClass extends FinalClass {}
當final用于修飾方法時,表示該方法不能被子類重寫。這通常用于確保方法的實現邏輯不被改變,例如在父類中定義了一個核心業務方法,不希望子類修改它。
class Parent {public final void display() {System.out.println("This is a final method.");}
}class Child extends Parent {// 錯誤:無法重寫final方法// public void display() {}
}
當final用于修飾變量時,表示該變量一旦被賦值就不能再被修改,即成為常量。對于基本數據類型,final使其值不可變;對于引用類型,final使其引用不可變,但引用的對象內容可以改變。
class FinalVariableExample {final int NUMBER = 10; // 基本數據類型常量final StringBuilder builder = new StringBuilder("Hello"); // 引用類型常量public void modifyVariables() {// NUMBER = 20; // 錯誤:無法修改final變量builder.append(" World"); // 可以修改引用對象的內容// builder = new StringBuilder("Hi"); // 錯誤:無法修改final引用}
}
final變量必須在聲明時或構造函數中初始化,否則會導致編譯錯誤。此外,final還可以用于修飾方法參數,確保在方法內部不能修改該參數的值。
public void calculate(final int value) {// value = value + 10; // 錯誤:無法修改final參數
}
final關鍵字的使用場景包括:
- 常量定義:使用
final修飾的靜態變量(static final)是 Java 中定義常量的標準方式,例如public static final double PI = 3.14159;。 - 安全性考慮:通過
final類和方法防止代碼被惡意修改,提高系統安全性。 - 性能優化:
final方法在編譯時會被內聯優化,提高方法調用效率。 - 線程安全:
final變量在多線程環境下不需要額外的同步機制,因為它們不可變。
在設計類和方法時,合理使用final關鍵字可以提高代碼的健壯性和可維護性,但過度使用可能會限制代碼的靈活性,因此需要根據具體場景權衡使用。
static 關鍵字的作用及使用場景?
在 Java 中,static關鍵字用于表示屬于類本身而不是類的實例的成員。它可以應用于變量、方法、代碼塊和內部類,改變這些成員的生命周期和訪問方式。
static變量(靜態變量)屬于類而不是類的實例,所有實例共享同一個靜態變量。靜態變量在類加載時初始化,存儲在方法區,其生命周期與類相同。靜態變量通常用于表示類級別的全局變量,例如計數器或配置參數。
class Counter {static int count = 0; // 靜態變量,所有實例共享public Counter() {count++; // 每次創建實例時計數器加1}public static int getCount() { // 靜態方法return count;}
}public class StaticVariableExample {public static void main(String[] args) {Counter c1 = new Counter();Counter c2 = new Counter();System.out.println(Counter.getCount()); // 輸出2}
}
static方法(靜態方法)屬于類而不是類的實例,可以直接通過類名調用,無需創建對象。靜態方法只能訪問靜態成員(靜態變量和靜態方法),不能訪問實例成員,因為靜態方法在類加載時就存在,而實例成員需要創建對象后才能存在。
class MathUtils {public static int add(int a, int b) { // 靜態方法return a + b;}
}public class StaticMethodExample {public static void main(String[] args) {int result = MathUtils.add(5, 3); // 直接通過類名調用靜態方法System.out.println(result); // 輸出8}
}
static代碼塊(靜態代碼塊)在類加載時執行一次,用于初始化靜態變量或執行類級別的初始化操作。靜態代碼塊按照在類中出現的順序依次執行。
class StaticBlockExample {static int value;static { // 靜態代碼塊value = 10;System.out.println("Static block executed");}public static void main(String[] args) {System.out.println("Value: " + value);}
}
static內部類(靜態內部類)是定義在另一個類內部的靜態類,它不依賴于外部類的實例,可以直接創建。靜態內部類只能訪問外部類的靜態成員。
class Outer {static int x = 10;static class Inner {public void display() {System.out.println("Outer x: " + x);}}
}public class StaticNestedClassExample {public static void main(String[] args) {Outer.Inner inner = new Outer.Inner(); // 直接創建靜態內部類實例inner.display(); // 輸出10}
}
static關鍵字的使用場景包括:
- 工具類:將常用的工具方法定義為靜態方法,例如
java.lang.Math類中的所有方法都是靜態的。 - 單例模式:使用靜態變量保存類的唯一實例,例如餓漢式單例。
- 全局常量:使用
static final修飾的變量定義全局常量,例如public static final String DEFAULT_NAME = "John";。 - 初始化資源:在靜態代碼塊中初始化數據庫連接、加載配置文件等操作。
需要注意的是,過度使用static會導致代碼的可測試性和可維護性下降,因為靜態成員難以被繼承和重寫,也不利于依賴注入。因此,應謹慎使用static關鍵字,遵循面向對象設計原則。
Java 的異常體系結構是怎樣的?

Java 的異常體系結構是一個基于繼承的層次結構,所有異常類最終都繼承自java.lang.Throwable類。Throwable類有兩個主要子類:Error和Exception,分別表示錯誤和異常。
Error類表示系統級錯誤和資源耗盡的情況,例如OutOfMemoryError、StackOverflowError和VirtualMachineError等。這類錯誤通常是不可恢復的,應用程序不應該嘗試捕獲或處理它們。
Exception類表示程序可以捕獲和處理的異常情況。Exception又分為兩個主要分支:受檢查異常(Checked Exception)和運行時異常(RuntimeException)。
受檢查異常是指繼承自Exception但不繼承自RuntimeException的異常類。這類異常在編譯時被檢查,必須在方法簽名中聲明或使用try-catch塊捕獲。例如,IOException、SQLException和ClassNotFoundException等。
運行時異常是指繼承自RuntimeException的異常類。這類異常在編譯時不被檢查,可以不聲明或捕獲。常見的運行時異常包括NullPointerException、ArrayIndexOutOfBoundsException、IllegalArgumentException和ArithmeticException等。
Java 異常處理機制的核心是try-catch-finally語句和throws聲明。通過try塊包裹可能拋出異常的代碼,使用catch塊捕獲并處理異常,使用finally塊執行無論是否發生異常都必須執行的代碼。throws聲明用于方法簽名中,表示該方法可能拋出的異常。
import java.io.File;
import java.io.FileReader;
import java.io.IOException;public class ExceptionHandlingExample {public static void main(String[] args) {try {readFile("nonexistent.txt");} catch (IOException e) {System.out.println("Error reading file: " + e.getMessage());}}public static void readFile(String fileName) throws IOException {File file = new File(fileName);FileReader reader = new FileReader(file);// 讀取文件內容reader.close();}
}
在這個例子中,readFile方法聲明可能拋出IOException,調用者必須處理這個受檢查異常。如果文件不存在,會拋出FileNotFoundException(IOException的子類),被catch塊捕獲并處理。
Java 7 引入了try-with-resources語句,用于自動關閉實現了AutoCloseable接口的資源,簡化了資源管理代碼。
import java.io.File;
import java.io.FileReader;
import java.io.IOException;public class TryWithResourcesExample {public static void main(String[] args) {try (FileReader reader = new FileReader("example.txt")) {// 讀取文件內容int data;while ((data = reader.read()) != -1) {System.out.print((char) data);}} catch (IOException e) {System.out.println("Error reading file: " + e.getMessage());}}
}
在這個例子中,FileReader實現了AutoCloseable接口,try-with-resources語句會自動關閉資源,無需顯式調用close()方法。
Java 異常體系的設計遵循以下原則:
- 受檢查異常用于表示可預測的異常情況,強制開發者處理這些異常,提高程序的健壯性。
- 運行時異常用于表示編程錯誤,如空指針引用或數組越界,這類異常應該通過代碼審查和測試來避免。
- 錯誤表示系統級問題,應用程序通常無法處理。
合理使用 Java 的異常機制可以使代碼更加健壯、清晰,同時也便于調試和維護。在設計應用程序時,應根據異常的類型和業務需求選擇合適的處理方式,避免捕獲不必要的異常或忽略重要的異常信息。
String 類型中 CHAR 和 VARCHAR 的區別及使用場景?
在數據庫領域,CHAR和VARCHAR是兩種常用的字符串數據類型,它們在存儲方式、長度特性和適用場景上存在顯著差異。理解這些差異對于數據庫設計和性能優化至關重要。
CHAR是固定長度的字符串類型,在定義時需要指定長度,無論實際存儲的字符串長度是多少,都會占用固定的存儲空間。例如,定義一個CHAR(10)的字段,如果存儲的字符串長度小于 10 個字符,剩余的空間會用空格填充。這種特性使得CHAR在處理定長數據時效率較高,因為數據庫可以精確計算每個記錄的位置。
VARCHAR則是可變長度的字符串類型,同樣需要在定義時指定最大長度,但實際存儲空間只占用字符串實際長度加 1 或 2 個字節(用于存儲字符串長度)。例如,定義一個VARCHAR(10)的字段,存儲長度為 5 的字符串時,實際只占用 6 或 7 個字節。這種靈活性使得VARCHAR在處理長度變化較大的數據時更為節省空間。
兩者的主要區別可以歸納為以下幾點:
| 特性 | CHAR | VARCHAR |
|---|---|---|
| 存儲方式 | 固定長度,不足補空格 | 可變長度,存儲實際長度 + 標記 |
| 空間效率 | 可能浪費空間(填充空格) | 更節省空間(按需分配) |
| 訪問速度 | 略快(無需計算長度) | 稍慢(需讀取長度標記) |
| 適用場景 | 定長數據(如身份證號、郵編) | 變長數據(如姓名、地址) |
在實際應用中,CHAR適用于存儲長度固定的數據,如性別('M'/'F')、國家代碼(如 'CN'、'US')等。由于其長度固定,檢索效率較高,尤其在需要頻繁比較的場景中表現出色。例如,存儲 UUID 時使用CHAR(36)可以避免因長度變化帶來的額外開銷。
VARCHAR則更適合存儲長度不確定的數據,如用戶輸入的文本、文章內容等。使用VARCHAR可以有效節省存儲空間,特別是在處理大量數據時,這種優勢更為明顯。但需要注意的是,若定義的最大長度過大,可能會導致索引效率下降,因為索引通常需要存儲完整的字段長度信息。
在性能方面,CHAR的固定長度特性使其在排序和比較操作中略占優勢,因為不需要額外處理長度信息。而VARCHAR由于其動態特性,在插入和更新時可能需要額外的內存分配和移動操作。
在選擇使用CHAR還是VARCHAR時,需要綜合考慮數據的特性、存儲空間成本和查詢性能。對于長度變化不大且經常參與比較操作的數據,優先使用CHAR;對于長度變化較大且對存儲空間敏感的數據,則應選擇VARCHAR。此外,還應根據具體數據庫系統的實現特點進行調整,不同數據庫對這兩種類型的處理可能存在細微差異。
ArrayList 的底層數據結構是什么?擴容機制如何?時間復雜度如何?
ArrayList是 Java 集合框架中常用的動態數組實現,它繼承自AbstractList類并實現了List接口。其底層數據結構是一個動態擴容的數組,這使得ArrayList能夠像普通數組一樣通過索引快速訪問元素,同時具備動態調整大小的能力。
在ArrayList內部,使用一個Object[]數組來存儲元素。當創建ArrayList對象時,默認會初始化一個空數組(JDK 1.8 及以后),直到第一次添加元素時才會分配默認容量(10)的數組。這種延遲初始化策略可以減少內存浪費。
ArrayList的擴容機制是其核心特性之一。當向ArrayList中添加元素時,如果當前數組已滿,就需要進行擴容操作。擴容過程如下:
- 計算新的容量:默認情況下,新容量是原容量的 1.5 倍(即
oldCapacity + (oldCapacity >> 1))。 - 創建一個新的數組,大小為計算出的新容量。
- 將原數組中的所有元素復制到新數組中。
- 使用新數組替換原數組,并丟棄原數組。
這種擴容機制確保了ArrayList能夠動態增長以容納更多元素,但頻繁的擴容操作會導致性能開銷,因為涉及到數組的復制。為了避免這種情況,可以在創建ArrayList時通過構造函數指定初始容量,或者使用ensureCapacity方法預先分配足夠的空間。
以下是ArrayList擴容機制的示例代碼:
import java.util.ArrayList;public class ArrayListExample {public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>(5); // 初始容量為5// 添加6個元素,觸發擴容for (int i = 0; i < 6; i++) {list.add(i);}System.out.println("List size: " + list.size()); // 輸出6System.out.println("List capacity: " + getCapacity(list)); // 輸出7(5*1.5=7.5,取整為7)}// 通過反射獲取ArrayList的容量private static int getCapacity(ArrayList<?> list) {try {java.lang.reflect.Field field = ArrayList.class.getDeclaredField("elementData");field.setAccessible(true);return ((Object[]) field.get(list)).length;} catch (Exception e) {return -1;}}
}
ArrayList的時間復雜度分析如下:
- 隨機訪問:通過索引訪問元素的時間復雜度為 O (1),因為數組的內存地址是連續的,可以直接計算出元素的位置。
- 添加元素:在列表末尾添加元素的平均時間復雜度為 O (1),但在數組滿時需要擴容,此時時間復雜度為 O (n)。如果預先知道元素數量并設置合適的初始容量,可以避免擴容開銷。
- 插入元素:在指定位置插入元素的時間復雜度為 O (n),因為需要將后續元素向后移動。
- 刪除元素:刪除指定位置元素的時間復雜度為 O (n),因為需要將后續元素向前移動。
- 遍歷元素:使用迭代器或 for-each 循環遍歷元素的時間復雜度為 O (n),因為需要訪問每個元素一次。
HashMap 的底層實現原理是什么?JDK 1.8 前后有哪些區別?
HashMap是 Java 中最常用的數據結構之一,用于存儲鍵值對(key-value pairs)。其核心設計目標是提供高效的插入、查詢和刪除操作。理解HashMap的底層實現原理以及 JDK 1.8 前后的變化,對于優化代碼性能和避免潛在問題至關重要。
在 JDK 1.8 之前,HashMap的底層實現是數組 + 鏈表的結構,也稱為哈希桶(Hash Bucket)。具體實現如下:
- 哈希表數組:
HashMap內部維護一個數組,每個數組元素稱為一個桶(Bucket),用于存儲鍵值對。 - 鏈表處理哈希沖突:當不同的鍵通過哈希函數計算出相同的索引位置時,這些鍵值對會以鏈表的形式存儲在同一個桶中。
- 哈希函數:通過鍵的
hashCode()方法計算哈希值,再經過擾動函數處理后映射到數組索引。 - 插入與查找:插入和查找時,先通過哈希值找到對應的桶,再在鏈表中遍歷查找或插入元素。
JDK 1.8 對HashMap的實現進行了重大優化,引入了紅黑樹結構,形成了數組 + 鏈表 + 紅黑樹的復合結構。當鏈表長度超過閾值(默認為 8)且數組長度大于 64 時,鏈表會轉換為紅黑樹;當樹節點數量小于 6 時,紅黑樹會退化為鏈表。這種優化主要是為了解決哈希沖突嚴重時鏈表查詢效率低下的問題(鏈表查詢時間復雜度為 O (n),而紅黑樹為 O (log n))。
JDK 1.8 前后的主要區別如下:
| 特性 | JDK 1.7 及以前 | JDK 1.8 及以后 |
|---|---|---|
| 數據結構 | 數組 + 鏈表 | 數組 + 鏈表 + 紅黑樹 |
| 插入方式 | 頭插法(新節點插入鏈表頭部) | 尾插法(新節點插入鏈表尾部) |
| 哈希函數復雜度 | 擾動函數進行 4 次位運算 + 5 次異或 | 擾動函數進行 1 次位運算 + 1 次異或 |
| 擴容機制 | 全部元素重新計算哈希值和索引 | 僅判斷原索引或原索引 + 舊容量 |
| 線程安全性 | 非線程安全,多線程可能導致死循環 | 非線程安全,多線程可能導致數據不一致 |
以下是 JDK 1.8 中HashMap的關鍵代碼片段,展示了鏈表轉紅黑樹的邏輯:
// 鏈表節點類
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;// 省略構造方法和其他方法
}// 紅黑樹節點類
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;// 省略構造方法和其他方法
}// 插入元素的方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash); // 鏈表轉紅黑樹break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 省略后續代碼}// 省略后續代碼
}
在 JDK 1.8 中,HashMap的擴容機制也得到了優化。當數組擴容時,元素的位置要么保持不變,要么移動到原位置 + 舊容量的位置。這種設計避免了重新計算哈希值,提高了擴容效率。
需要注意的是,HashMap是非線程安全的。在多線程環境下,推薦使用ConcurrentHashMap代替。JDK 1.7 及以前的HashMap在多線程擴容時可能會導致死循環,而 JDK 1.8 雖然修復了這個問題,但仍不保證線程安全。
進程和線程的區別是什么?
進程和線程是操作系統中兩個重要的概念,它們都是實現多任務處理的方式,但在設計理念、資源占用和調度方式上存在本質區別。
進程(Process)?是程序在操作系統中的一次執行實例,是系統進行資源分配和調度的基本單位。每個進程都有自己獨立的內存空間、文件描述符、數據棧等系統資源。進程之間相互獨立,一個進程的崩潰不會影響其他進程。操作系統通過進程控制塊(PCB)來管理進程,包括進程的狀態、優先級、程序計數器等信息。
線程(Thread)?是進程中的一個執行單元,是 CPU 調度和分派的基本單位。一個進程可以包含多個線程,這些線程共享進程的資源,如內存空間、文件句柄等,但每個線程有自己獨立的程序計數器、棧和寄存器。線程之間的通信比進程更高效,因為它們可以直接訪問共享數據。
進程和線程的主要區別可以從以下幾個方面進行對比:
| 特性 | 進程 | 線程 |
|---|---|---|
| 資源分配 | 擁有獨立的內存空間和系統資源 | 共享所屬進程的資源,僅擁有自己的棧和寄存器 |
| 調度單位 | 是操作系統調度的基本單位 | 是 CPU 調度的基本單位 |
| 創建和銷毀開銷 | 開銷大,需要分配和釋放資源 | 開銷小,只需保存和恢復少量寄存器狀態 |
| 通信方式 | 進程間通信(IPC)需要復雜機制 | 直接訪問共享內存,通信效率高 |
| 并發能力 | 適合多核 CPU 并行處理 | 適合 IO 密集型任務,提高吞吐量 |
| 健壯性 | 一個進程崩潰不影響其他進程 | 一個線程崩潰可能導致整個進程崩潰 |
| 上下文切換 | 切換開銷大,涉及內存空間和 CPU 環境的切換 | 切換開銷小,主要保存和恢復寄存器狀態 |
進程間通信(IPC)通常通過管道、消息隊列、共享內存、套接字等方式實現,而線程間通信可以直接通過共享變量進行。由于線程共享內存空間,它們之間的通信速度更快,但也更容易引發競態條件(Race Condition)和死鎖等問題,需要使用同步機制(如鎖、信號量)來保證線程安全。
進程和線程的使用場景也有所不同。進程適合需要隔離性和穩定性的場景,如不同應用程序之間的隔離;而線程適合需要提高并發性能和資源利用率的場景,如多任務處理、網絡服務器等。
在現代操作系統中,通常采用多進程和多線程混合的方式來實現高效的并發處理。例如,Web 服務器通常使用多進程模型來處理多個客戶端請求,每個進程內部再使用多線程來處理并發的連接。這種設計既保證了系統的穩定性,又提高了資源利用率和響應速度。
線程如何維護自己的私有變量?
在多線程編程中,有時需要為每個線程維護一份獨立的變量副本,以避免線程間的數據競爭和保證線程安全。Java 提供了幾種機制來實現線程私有變量,其中最常用的是ThreadLocal類和線程局部存儲(Thread-Local Storage, TLS)。
ThreadLocal 類?是 Java 提供的一種特殊機制,它為每個使用該變量的線程都提供一個獨立的變量副本,每個線程都可以獨立地改變自己的副本,而不會影響其他線程的副本。ThreadLocal內部維護一個ThreadLocalMap,其中鍵是ThreadLocal實例本身,值是每個線程的變量副本。
以下是ThreadLocal的基本用法示例:
public class ThreadLocalExample {// 創建一個ThreadLocal實例,初始值為0private static final ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);public static void main(String[] args) {// 創建兩個線程Thread t1 = new Thread(() -> {for (int i = 0; i < 5; i++) {// 獲取當前線程的變量副本并遞增int value = threadLocal.get();threadLocal.set(value + 1);System.out.println(Thread.currentThread().getName() + ": " + threadLocal.get());try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}, "Thread-1");Thread t2 = new Thread(() -> {for (int i = 0; i < 5; i++) {// 獲取當前線程的變量副本并遞增int value = threadLocal.get();threadLocal.set(value + 2);System.out.println(Thread.currentThread().getName() + ": " + threadLocal.get());try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}, "Thread-2");// 啟動線程t1.start();t2.start();// 等待線程執行完畢try {t1.join();t2.join();} catch (InterruptedException e) {e.printStackTrace();}// 清理ThreadLocalthreadLocal.remove();}
}
在這個例子中,ThreadLocal為每個線程維護了一個獨立的計數器。Thread-1每次將計數器加 1,而Thread-2每次將計數器加 2。由于每個線程都有自己的副本,它們之間的操作互不影響。
ThreadLocal的實現原理是,每個Thread對象都包含一個ThreadLocalMap,當調用ThreadLocal的get()或set()方法時,會先獲取當前線程的ThreadLocalMap,然后以ThreadLocal實例為鍵查找或存儲值。這種設計使得每個線程都能獨立地訪問自己的變量副本。
InheritableThreadLocal 類?是ThreadLocal的子類,它允許子線程繼承父線程的ThreadLocal變量值。當一個線程創建子線程時,子線程會復制父線程的InheritableThreadLocal變量副本。
以下是InheritableThreadLocal的示例:
public class InheritableThreadLocalExample {private static final InheritableThreadLocal<Integer> inheritableThreadLocal = new InheritableThreadLocal<>();public static void main(String[] args) {// 在主線程中設置值inheritableThreadLocal.set(10);// 創建子線程Thread childThread = new Thread(() -> {// 子線程可以訪問父線程設置的值System.out.println("Child thread value: " + inheritableThreadLocal.get());// 子線程修改自己的副本inheritableThreadLocal.set(20);System.out.println("Child thread updated value: " + inheritableThreadLocal.get());});// 啟動子線程childThread.start();// 主線程繼續使用自己的副本System.out.println("Main thread value: " + inheritableThreadLocal.get());try {childThread.join();} catch (InterruptedException e) {e.printStackTrace();}// 清理inheritableThreadLocal.remove();}
}
除了ThreadLocal,還可以通過以下方式實現線程私有變量:
- 局部變量:方法內部的局部變量是線程私有的,每個線程執行該方法時都會創建自己的局部變量副本。
- 線程封閉:將對象限制在單個線程中使用,避免多線程訪問共享資源。
- 棧封閉:通過方法調用棧來保證變量的線程私有性,如將對象作為方法參數傳遞,不在多個線程間共享。
使用ThreadLocal時需要注意內存泄漏問題。由于ThreadLocalMap中的鍵是弱引用(WeakReference),當ThreadLocal實例被垃圾回收后,鍵會變為null,但值仍然是強引用,可能導致內存泄漏。因此,在不再使用ThreadLocal時,應調用remove()方法清理數據。
在多線程環境中,合理使用線程私有變量可以簡化并發編程模型,避免使用復雜的同步機制,提高代碼的可維護性和性能。
ThreadLocal 的實現原理是什么?存在哪些內存泄漏問題?如何解決?
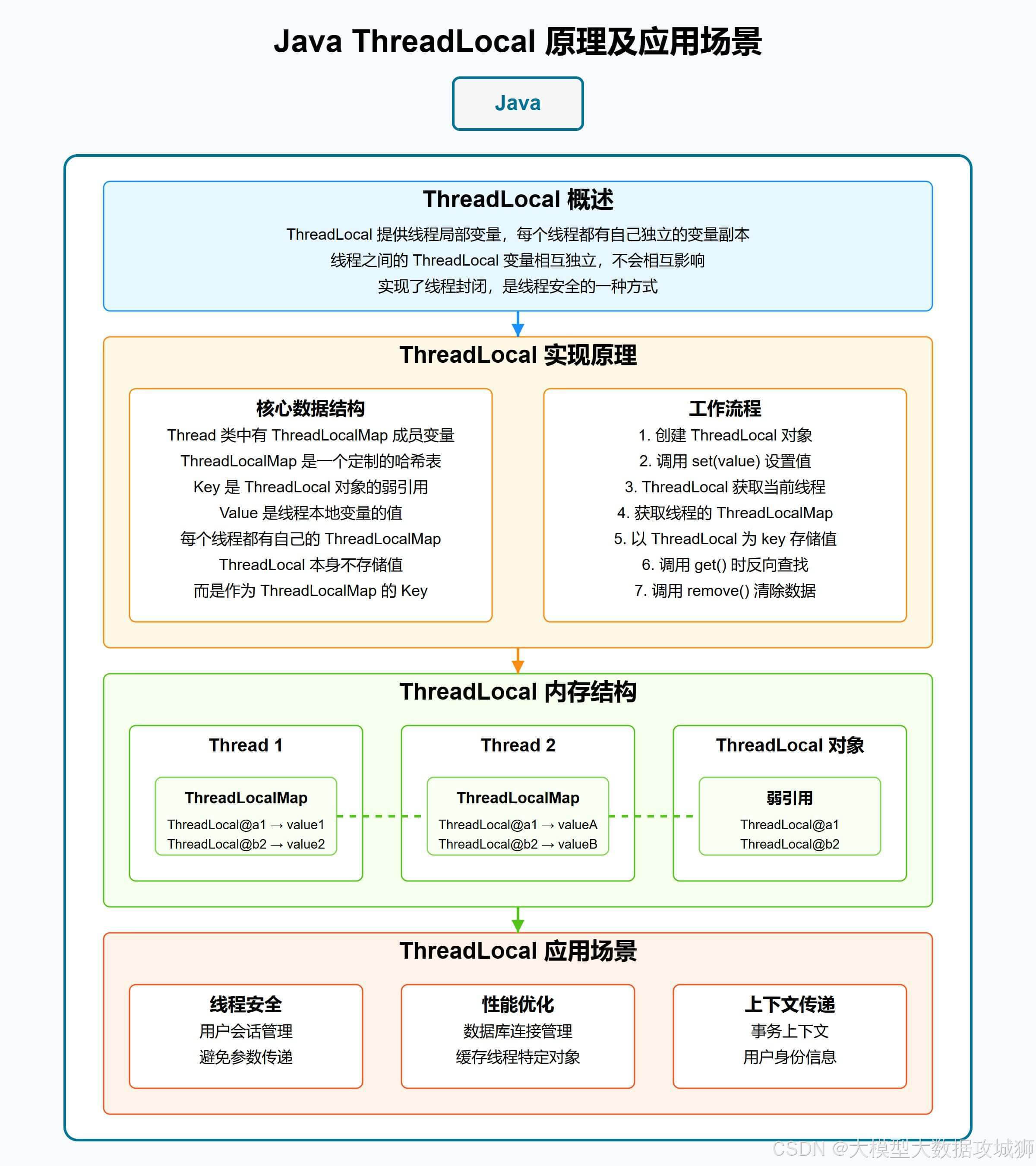
ThreadLocal?是 Java 中用于實現線程局部變量的類,它為每個使用該變量的線程都提供一個獨立的變量副本,每個線程都可以獨立地改變自己的副本,而不會影響其他線程所對應的副本。其核心設計是為了解決多線程環境下的變量隔離問題,避免線程間的數據競爭。
ThreadLocal?的實現原理基于每個線程內部都有一個?ThreadLocalMap?實例,該實例存儲了與該線程相關的所有?ThreadLocal?變量及其對應的值。ThreadLocalMap?是?ThreadLocal?的一個靜態內部類,其鍵為?ThreadLocal?實例(弱引用),值為用戶設置的對象。當線程調用?ThreadLocal?的?get()、set()?或?remove()?方法時,實際上是通過當前線程獲取其內部的?ThreadLocalMap,然后以?ThreadLocal?實例為鍵進行操作。
以下是?ThreadLocal?的關鍵代碼片段,展示了其實現原理:
public class ThreadLocal<T> {// 獲取當前線程的變量值public T get() {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null) {ThreadLocalMap.Entry e = map.getEntry(this);if (e != null) {@SuppressWarnings("unchecked")T result = (T)e.value;return result;}}return setInitialValue();}// 設置當前線程的變量值public void set(T value) {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);}// 獲取當前線程的ThreadLocalMapThreadLocalMap getMap(Thread t) {return t.threadLocals;}// 靜態內部類ThreadLocalMapstatic class ThreadLocalMap {static class Entry extends WeakReference<ThreadLocal<?>> {/** The value associated with this ThreadLocal. */Object value;Entry(ThreadLocal<?> k, Object v) {super(k);value = v;}}// 省略其他實現}
}
ThreadLocal?的內存泄漏問題主要源于其內部的?ThreadLocalMap?設計。ThreadLocalMap?中的鍵是?ThreadLocal?實例的弱引用(WeakReference),而值是強引用。當外部對?ThreadLocal?的強引用被釋放后,ThreadLocal?實例會被垃圾回收(因為弱引用無法阻止 GC),但此時?ThreadLocalMap?中的鍵變為?null,而值仍然保持強引用。如果線程一直存活(如線程池中的線程),這些?null?鍵對應的?value?就無法被回收,從而導致內存泄漏。
解決?ThreadLocal?內存泄漏問題的關鍵在于及時清理不再需要的?ThreadLocal?變量。具體措施包括:
- 使用后調用?
remove()?方法:在不需要?ThreadLocal?變量時,顯式調用?remove()?方法刪除對應的鍵值對。 - 在?
finally?塊中調用?remove():對于需要確保資源釋放的場景,建議在?finally?塊中調用?remove(),保證無論是否發生異常都能清理資源。 - 避免使用靜態的?
ThreadLocal:靜態的?ThreadLocal?可能導致其生命周期與應用程序相同,增加內存泄漏的風險。 - 使用線程池時特別注意:由于線程池中的線程會被復用,
ThreadLocal?變量可能會在不同的任務間共享,因此在任務執行前后都應進行清理。
以下是正確使用?ThreadLocal?的示例:
public class ThreadLocalExample {private static final ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);public static void main(String[] args) {try {// 設置線程局部變量threadLocal.set(10);// 使用線程局部變量System.out.println("Current value: " + threadLocal.get());} finally {// 確保清理線程局部變量,避免內存泄漏threadLocal.remove();}}
}
通過合理使用?remove()?方法,可以有效避免?ThreadLocal?導致的內存泄漏問題。此外,Java 8 引入的?ThreadLocal.withInitial()?方法提供了更簡潔的初始化方式,同時也建議在使用?ThreadLocal?時遵循良好的編程實踐,確保變量的生命周期得到正確管理。
synchronized 的實現原理是什么?涉及 JVM 的哪一部分?
synchronized?是 Java 中用于實現線程同步的關鍵字,它可以保證在同一時刻只有一個線程能夠訪問被同步的代碼塊或方法。其實現原理基于 Java 對象頭中的 Mark Word 和 JVM 內置的 Monitor(監視器)機制。
在 JVM 中,每個對象都有一個對象頭(Object Header),其中包含了 Mark Word 信息。Mark Word 是一個動態數據結構,根據對象的狀態不同而存儲不同的信息。當對象被用作鎖時,Mark Word 會存儲鎖的相關信息,如鎖狀態、偏向線程 ID、鎖記錄指針等。
synchronized?的實現分為兩種形式:同步方法和同步代碼塊。對于同步方法,JVM 通過方法表中的?ACC_SYNCHRONIZED?標志來實現同步;對于同步代碼塊,JVM 則使用?monitorenter?和?monitorexit?指令來實現。
以下是同步代碼塊的字節碼示例:
public class SynchronizedExample {private final Object lock = new Object();public void synchronizedMethod() {synchronized (lock) {// 同步代碼塊System.out.println("Inside synchronized block");}}
}
對應的字節碼片段:
monitorenter // 進入監視器,獲取鎖
getstatic // 其他指令
invokevirtual // 其他指令
monitorexit // 正常退出監視器,釋放鎖
astore_1 // 異常處理
monitorexit // 異常退出監視器,釋放鎖
athrow // 拋出異常
從字節碼可以看出,同步代碼塊使用?monitorenter?和?monitorexit?指令來實現鎖的獲取和釋放。每個對象都關聯一個 Monitor(監視器),當線程執行?monitorenter?指令時,會嘗試獲取對象的 Monitor。如果 Monitor 未被占用,則該線程獲得 Monitor 并繼續執行;如果 Monitor 已被其他線程占用,則該線程會被阻塞,直到 Monitor 被釋放。
Monitor 是 JVM 實現的一種鎖機制,它是一個對象級別的同步原語。在 HotSpot JVM 中,Monitor 由 ObjectMonitor 類實現,其主要數據結構包括:
- _owner:指向持有 Monitor 的線程
- _WaitSet:存儲處于等待狀態的線程隊列
- _EntryList:存儲處于阻塞狀態的線程隊列
當線程進入同步代碼塊時,會嘗試獲取對象的 Monitor:
- 如果 Monitor 的 _owner 為 null,表示沒有線程持有鎖,當前線程可以直接獲取鎖并將 _owner 設置為自己。
- 如果 Monitor 的 _owner 指向當前線程,表示當前線程已經持有鎖,可以直接重入(synchronized 支持重入鎖)。
- 如果 Monitor 的 _owner 指向其他線程,當前線程會被放入 _EntryList 隊列中阻塞等待。
當線程退出同步代碼塊時,會釋放 Monitor:
- 將 _owner 設置為 null
- 喚醒 _EntryList 中的一個等待線程
synchronized?涉及 JVM 的多個部分:
- 對象頭:存儲鎖狀態和相關信息
- 字節碼:通過?
ACC_SYNCHRONIZED?標志和?monitorenter/monitorexit?指令實現同步邏輯 - 運行時:Monitor 機制由 JVM 運行時系統實現
- 內存模型:synchronized 保證了可見性和有序性,涉及 JVM 的內存屏障和 Happens-Before 規則
在 JDK 1.6 之后,synchronized 進行了大量優化,引入了偏向鎖、輕量級鎖、鎖粗化、鎖消除等機制,大大提高了其性能。這些優化使得 synchronized 在大多數情況下不再是性能瓶頸,成為了 Java 中最常用的同步機制之一。
如何對 synchronized 進行鎖優化?
在 JDK 1.6 之前,synchronized?是一個重量級鎖,性能較低,因為每次獲取鎖都需要進行用戶態和內核態的切換。JDK 1.6 對?synchronized?進行了重大優化,引入了偏向鎖、輕量級鎖、鎖粗化、鎖消除等技術,顯著提高了其性能。以下是幾種主要的鎖優化方式:
偏向鎖(Biased Locking):偏向鎖是為了在沒有競爭的情況下減少鎖獲取的開銷而引入的。當一個線程第一次獲取鎖時,鎖對象的 Mark Word 會記錄該線程的 ID,稱為偏向線程 ID。此后,該線程再次獲取鎖時,無需進行任何同步操作,直接獲得鎖,從而節省了大量的鎖獲取時間。只有當其他線程嘗試競爭該鎖時,偏向鎖才會被撤銷并升級為輕量級鎖。
輕量級鎖(Lightweight Locking):輕量級鎖是為了在競爭不激烈的情況下避免重量級鎖的性能開銷而設計的。當線程獲取鎖時,如果鎖對象處于無鎖狀態(Mark Word 中存儲的是對象的哈希碼等信息),JVM 會在當前線程的棧幀中創建一個鎖記錄(Lock Record),并通過 CAS(Compare-And-Swap)操作將鎖對象的 Mark Word 復制到鎖記錄中,同時將 Mark Word 指向鎖記錄的指針。如果 CAS 操作成功,線程獲得輕量級鎖;如果失敗,表示有其他線程競爭鎖,鎖會升級為重量級鎖。
鎖粗化(Lock Coarsening):鎖粗化是指將多個連續的加鎖、解鎖操作合并為一次加鎖、解鎖操作,以減少鎖的獲取和釋放次數。例如,在循環中頻繁加鎖解鎖的代碼,JVM 會將鎖的范圍擴展到循環外部,避免多次獲取和釋放鎖。
// 優化前
for (int i = 0; i < 100; i++) {synchronized (this) {// 業務邏輯}
}// 優化后(鎖粗化)
synchronized (this) {for (int i = 0; i < 100; i++) {// 業務邏輯}
}
鎖消除(Lock Elimination):鎖消除是指 JVM 在編譯時通過逃逸分析技術,發現某些代碼中使用的鎖對象不會被其他線程訪問,從而將這些鎖操作消除。例如,在方法內部創建的局部對象作為鎖,并且該對象不會逃逸到方法外部,JVM 會消除對該對象的鎖操作。
public void method() {Object lock = new Object();synchronized (lock) {// 業務邏輯,lock對象不會逃逸到方法外部}
}// JVM可能會優化為
public void method() {// 業務邏輯
}
鎖升級(Lock Inflation):鎖升級是指鎖狀態隨著競爭情況逐漸升級的過程。鎖的狀態從無鎖狀態開始,依次經歷偏向鎖、輕量級鎖,最終升級為重量級鎖。這種設計使得鎖能夠根據實際競爭情況動態調整,在不同場景下都能提供較好的性能。
自旋鎖(Spin Lock):自旋鎖是指當線程嘗試獲取鎖失敗時,不會立即進入阻塞狀態,而是進行一段時間的自旋(循環等待),看鎖是否會被釋放。如果在自旋期間鎖被釋放,線程可以立即獲得鎖,避免了線程切換的開銷。自旋鎖適用于鎖持有時間較短的場景。JDK 1.6 引入了自適應自旋鎖,根據以往的自旋成功率、時間等因素自動調整自旋的時間。
在實際開發中,可以通過以下方式進一步優化?synchronized?的使用:
- 減小鎖的粒度:將大的同步塊拆分為多個小的同步塊,減少鎖的持有時間,從而降低鎖競爭的可能性。
- 使用替代方案:在某些場景下,可以使用更細粒度的鎖(如?
ReentrantLock)或原子類(如?AtomicInteger)來替代?synchronized,以獲得更好的性能。 - 避免鎖的嵌套:鎖的嵌套會增加死鎖的風險,同時也會降低性能。
- 優化代碼邏輯:減少同步代碼塊中的耗時操作,如 IO 操作、網絡請求等。
通過合理使用這些鎖優化技術,可以顯著提高?synchronized?的性能,使其在大多數場景下不再成為性能瓶頸。
CAS(Compare-And-Swap)存在哪些問題?
CAS(Compare-And-Swap)是一種無鎖算法,用于實現多線程環境下的原子操作。它通過比較內存中的值與預期值是否相等,如果相等則將內存中的值更新為新值,整個操作是原子性的。CAS 是 Java 中原子類(如?AtomicInteger、AtomicLong)和并發工具(如?ReentrantLock)的基礎實現機制。然而,CAS 雖然避免了鎖的使用,但也存在一些問題和局限性。
ABA 問題:CAS 操作需要檢查內存中的值是否與預期值相同,如果相同則更新。但如果內存中的值從 A 變為 B,再從 B 變回 A,CAS 操作會認為值沒有發生變化,從而成功更新。這種情況下,雖然 CAS 操作成功,但實際上值已經經歷了變化,可能會導致一些潛在的問題。例如,在鏈表操作中,ABA 問題可能會導致鏈表結構被破壞。
解決 ABA 問題的方法是引入版本號或時間戳,每次值發生變化時增加版本號。Java 中的?AtomicStampedReference?和?AtomicMarkableReference?就是為了解決 ABA 問題而設計的。AtomicStampedReference?維護一個版本號,CAS 操作不僅檢查值是否相等,還檢查版本號是否一致。
import java.util.concurrent.atomic.AtomicStampedReference;public class ABADemo {private static AtomicStampedReference<Integer> atomicStampedRef = new AtomicStampedReference<>(100, 0);public static void main(String[] args) {Thread t1 = new Thread(() -> {try {int stamp = atomicStampedRef.getStamp();System.out.println("Thread-1 stamp: " + stamp);Thread.sleep(1000); // 等待t2完成ABA操作boolean success = atomicStampedRef.compareAndSet(100, 101, stamp, stamp + 1);System.out.println("Thread-1 CAS: " + success);} catch (InterruptedException e) {e.printStackTrace();}});Thread t2 = new Thread(() -> {int stamp = atomicStampedRef.getStamp();System.out.println("Thread-2 stamp: " + stamp);atomicStampedRef.compareAndSet(100, 101, stamp, stamp + 1);System.out.println("Thread-2 stamp after first CAS: " + atomicStampedRef.getStamp());stamp = atomicStampedRef.getStamp();atomicStampedRef.compareAndSet(101, 100, stamp, stamp + 1);System.out.println("Thread-2 stamp after second CAS: " + atomicStampedRef.getStamp());});t1.start();t2.start();}
}
循環時間長開銷大:CAS 通常是通過循環(自旋)來實現的,如果長時間自旋仍無法成功獲取鎖,會給 CPU 帶來較大的開銷。特別是在競爭激烈的情況下,大量線程不斷進行 CAS 操作但始終失敗,會導致 CPU 使用率飆升,系統性能下降。
為了避免這種情況,可以設置自旋的最大次數或最長時間,超過閾值后放棄自旋,進入阻塞狀態。JDK 中的?ReentrantLock?就是采用了這種方式,在公平鎖模式下,當線程無法獲取鎖時會進入隊列等待,而不是無限自旋。
只能保證一個共享變量的原子操作:CAS 操作只能對單個內存地址進行原子性的比較和交換。如果需要同時保證多個共享變量的原子性,CAS 就無法直接實現。在這種情況下,可以考慮以下幾種解決方案:
- 將多個變量合并為一個對象,使用?
AtomicReference?來保證對象的原子性。 - 使用鎖(如?
synchronized?或?ReentrantLock)來保證多個變量的原子性操作。 - 使用?
StampedLock?提供的樂觀讀鎖機制,在某些場景下可以提高并發性能。
緩存行偽共享(False Sharing):在多核心 CPU 中,每個核心都有自己的緩存行(Cache Line)。當多個線程同時操作不同的變量,但這些變量位于同一個緩存行中時,會導致緩存行偽共享問題。一個線程對緩存行的修改會導致其他核心的緩存行失效,需要重新從主內存加載數據,從而降低性能。
解決緩存行偽共享問題的方法是進行緩存行填充(Padding),使每個變量單獨占用一個緩存行。Java 8 引入了?@Contended?注解來自動進行緩存行填充,也可以通過手動添加無用字段的方式來實現。
// 使用@Contended注解避免偽共享
@sun.misc.Contended
public class ContendedExample {public volatile long value1 = 0L;public volatile long value2 = 0L;
}// 手動填充實現
public class PaddingExample {public volatile long p1, p2, p3, p4, p5, p6, p7; // 填充前public volatile long value1 = 0L;public volatile long p8, p9, p10, p11, p12, p13, p14; // 填充后public volatile long value2 = 0L;
}
雖然 CAS 存在這些問題,但在合適的場景下,它仍然是一種高效的并發控制機制。與鎖相比,CAS 具有更低的開銷和更好的可擴展性,特別適合在競爭不激烈、操作簡單的場景下使用。在實際開發中,應根據具體業務場景選擇合適的并發控制方式。
線程池的核心組件有哪些?(corePoolSize 核心線程數、maximumPoolSize 最大線程數、keepAliveTime 非核心線程超時時間、workQueue 任務隊列、threadFactory 線程工廠、handler 拒絕策略)
線程池是 Java 中用于管理和復用線程的機制,通過預先創建一定數量的線程,避免了頻繁創建和銷毀線程帶來的性能開銷。Java 中的線程池由?ThreadPoolExecutor?類實現,其核心組件包括以下六個部分:
corePoolSize(核心線程數):線程池的基本大小,當提交的任務數小于 corePoolSize 時,線程池會創建新的線程來執行任務,即使其他核心線程處于空閑狀態。核心線程創建后不會被銷毀,除非設置了?allowCoreThreadTimeOut?為 true,此時核心線程在空閑時間超過 keepAliveTime 后也會被銷毀。
maximumPoolSize(最大線程數):線程池允許創建的最大線程數。當提交的任務數超過 corePoolSize 且任務隊列已滿時,線程池會創建新的線程,直到線程數達到 maximumPoolSize。如果任務數繼續增加,超過 maximumPoolSize,則會觸發拒絕策略。
keepAliveTime(非核心線程超時時間):當線程池中的線程數量超過 corePoolSize 時,多余的線程(非核心線程)在空閑時間超過 keepAliveTime 后會被銷毀。如果設置了?allowCoreThreadTimeOut?為 true,則該參數也適用于核心線程。
workQueue(任務隊列):用于存儲等待執行的任務的阻塞隊列。當提交的任務數超過 corePoolSize 時,新任務會被放入任務隊列中等待執行。Java 提供了多種阻塞隊列實現,常見的有:
- ArrayBlockingQueue:基于數組的有界阻塞隊列,需要指定隊列大小。
- LinkedBlockingQueue:基于鏈表的阻塞隊列,可以是有界或無界的。Executors.newFixedThreadPool () 使用的是無界的 LinkedBlockingQueue。
- SynchronousQueue:不存儲元素的阻塞隊列,每個插入操作必須等待另一個線程的移除操作,反之亦然。Executors.newCachedThreadPool () 使用的是 SynchronousQueue。
- PriorityBlockingQueue:基于優先級的無界阻塞隊列,元素需要實現 Comparable 接口。
threadFactory(線程工廠):用于創建線程的工廠類,通過線程工廠可以自定義線程的名稱、優先級、是否為守護線程等屬性。默認情況下,線程池使用?Executors.defaultThreadFactory()?創建線程。在實際應用中,建議自定義線程工廠,以便于線程的管理和監控。
import java.util.concurrent.*;public class CustomThreadFactory implements ThreadFactory {private final String namePrefix;private final AtomicInteger threadNumber = new AtomicInteger(1);public CustomThreadFactory(String poolName) {this.namePrefix = poolName + "-thread-";}@Overridepublic Thread newThread(Runnable r) {Thread t = new Thread(r, namePrefix + threadNumber.getAndIncrement());if (t.isDaemon()) {t.setDaemon(false);}if (t.getPriority() != Thread.NORM_PRIORITY) {t.setPriority(Thread.NORM_PRIORITY);}return t;}
}
handler(拒絕策略):當線程池中的線程數量達到 maximumPoolSize 且任務隊列已滿時,新提交的任務會觸發拒絕策略。Java 提供了四種內置的拒絕策略:
- AbortPolicy(默認):直接拋出?
RejectedExecutionException?異常,阻止系統正常運行。 - CallerRunsPolicy:由調用線程(提交任務的線程)直接執行該任務,從而降低新任務的提交速度。
- DiscardPolicy:默默丟棄無法處理的任務,不做任何處理。
- DiscardOldestPolicy:丟棄任務隊列中最老的任務(即隊列頭部的任務),然后嘗試重新提交新任務。
除了內置的拒絕策略,還可以通過實現?RejectedExecutionHandler?接口來自定義拒絕策略。
線程池的工作流程可以概括為:
- 提交任務時,線程池首先檢查核心線程數是否已滿,如果未滿則創建新線程執行任務。
- 如果核心線程數已滿,則將任務放入任務隊列。
- 如果任務隊列已滿,且線程數未達到 maximumPoolSize,則創建新線程執行任務。
- 如果線程數已達到 maximumPoolSize,則觸發拒絕策略。
合理配置線程池的核心組件對于系統性能至關重要。例如,對于 CPU 密集型任務,應設置較小的核心線程數(如 CPU 核心數 + 1);對于 IO 密集型任務,可設置較大的核心線程數(如 CPU 核心數 * 2)。任務隊列的選擇也需要根據業務場景進行調整,避免使用無界隊列導致內存溢出。
任務提交到線程池后執行流程是怎樣的?
任務提交到線程池后的執行流程是一個多階段的決策過程,涉及線程池的核心線程、任務隊列和最大線程數等組件的協同工作。理解這一流程對于合理配置線程池參數和優化系統性能至關重要。
當一個任務通過?execute()?或?submit()?方法提交到線程池時,線程池會按照以下步驟進行處理:
首先檢查線程池的核心線程數是否已滿。如果核心線程數小于?corePoolSize,即使此時有空閑的核心線程,線程池也會創建一個新的線程來執行該任務。這一策略確保了核心線程能夠被充分利用。
若核心線程數已滿,線程池會將任務放入任務隊列(workQueue)中等待執行。任務隊列的類型和容量決定了后續的處理邏輯。例如,使用有界隊列(如?ArrayBlockingQueue)時,隊列可能會被填滿;而使用無界隊列(如?LinkedBlockingQueue)時,隊列幾乎不會被填滿,但可能導致系統資源耗盡。
若任務隊列已滿,線程池會檢查當前線程數是否達到?maximumPoolSize。如果未達到,線程池會創建一個新的非核心線程來執行該任務。這些非核心線程在空閑時間超過?keepAliveTime?后會被銷毀,以節省資源。
若線程數已達到?maximumPoolSize,線程池會觸發拒絕策略(handler)來處理無法執行的任務。內置的拒絕策略包括拋出異常(AbortPolicy)、由調用線程執行(CallerRunsPolicy)、丟棄任務(DiscardPolicy)或丟棄最老的任務(DiscardOldestPolicy)。
這一流程可以用以下偽代碼表示:
if (線程數 < corePoolSize) {創建新線程執行任務
} else if (任務隊列未滿) {將任務放入隊列
} else if (線程數 < maximumPoolSize) {創建新線程執行任務
} else {執行拒絕策略
}
值得注意的是,線程池的狀態也會影響任務的執行。例如,當線程池被關閉(shutdown?或?shutdownNow)后,新提交的任務會被拒絕。此外,如果任務執行過程中拋出異常,線程會被銷毀,但線程池會創建一個新的線程來替代它。
在實際應用中,合理配置線程池參數至關重要。例如,對于 CPU 密集型任務,應避免設置過大的線程數,以免增加上下文切換開銷;對于 IO 密集型任務,可以設置較多的線程數以提高并發度。通過理解任務提交后的執行流程,可以更有針對性地調整線程池配置,優化系統性能。
如何設置核心線程數與最大線程數?為什么設置核心線程數要參考 CPU 核數?
設置線程池的核心線程數(corePoolSize)和最大線程數(maximumPoolSize)需要綜合考慮任務類型、系統資源和性能需求。合理的配置可以充分利用系統資源,避免線程過多導致的上下文切換開銷或線程過少導致的資源浪費。
對于 CPU 密集型任務,核心線程數應接近或等于 CPU 核心數。這是因為 CPU 密集型任務幾乎不等待 IO 操作,線程一直占用 CPU 資源。如果線程數過多,會導致頻繁的上下文切換,增加系統開銷。例如,對于一個 8 核的 CPU,設置核心線程數為 8 或 9(考慮到可能的額外開銷)是比較合適的。計算公式可表示為:corePoolSize = CPU 核心數 + 1。
對于 IO 密集型任務,核心線程數可以設置得較大,因為 IO 操作會使線程長時間處于等待狀態,CPU 資源利用率較低。此時增加線程數可以提高并發度,充分利用 CPU 資源。一般來說,IO 密集型任務的核心線程數可以設置為 CPU 核心數的兩倍左右,計算公式為:corePoolSize = 2 * CPU 核心數。更精確的計算可以基于任務的等待時間與計算時間的比例:corePoolSize = CPU 核心數 * (1 + 等待時間/計算時間)。
最大線程數(maximumPoolSize)的設置需要結合任務隊列的類型。如果使用無界隊列(如?LinkedBlockingQueue),則最大線程數參數無效,因為任務會不斷進入隊列等待,不會觸發創建新線程的條件。此時應謹慎使用無界隊列,避免系統資源耗盡。如果使用有界隊列(如?ArrayBlockingQueue),最大線程數應根據系統能夠承受的最大并發量來設置,防止過多線程導致系統崩潰。
設置核心線程數參考 CPU 核數的主要原因是為了避免 CPU 資源的浪費或過度競爭。當線程數接近 CPU 核心數時,每個 CPU 核心可以被充分利用,減少空閑時間。而當線程數遠大于 CPU 核心數時,會導致多個線程競爭同一個 CPU 核心,增加上下文切換的頻率,降低系統性能。上下文切換需要保存和恢復線程的狀態,消耗 CPU 時間,過多的上下文切換會使系統吞吐量下降。
此外,還應考慮系統的其他資源限制,如內存、網絡帶寬等。如果線程數過多,每個線程占用的內存資源會累積,可能導致內存溢出。因此,在設置線程數時,需要綜合考慮任務特性、CPU 核心數、內存容量等因素,通過性能測試不斷調整,找到最優配置。
常見的線程池類型有哪些?(如 CachedThreadPool、SingleThreadPool、ScheduledThreadPool、FixedThreadPool)
Java 提供了多種預定義的線程池類型,每種類型都針對特定的場景進行了優化。這些線程池可以通過?Executors?工廠類快速創建,也可以手動配置?ThreadPoolExecutor?來實現更靈活的控制。
CachedThreadPool:可緩存的線程池,通過?Executors.newCachedThreadPool()?創建。它的核心線程數為 0,最大線程數為?Integer.MAX_VALUE,使用?SynchronousQueue?作為任務隊列。這種線程池的特點是線程可以無限擴展,適合處理大量短時間的異步任務。當有新任務提交時,如果沒有空閑線程,會立即創建一個新線程;如果線程空閑時間超過 60 秒,會被自動回收。由于線程數可以無限增長,使用時需要注意控制任務數量,避免系統資源耗盡。
SingleThreadPool:單線程的線程池,通過?Executors.newSingleThreadExecutor()?創建。它的核心線程數和最大線程數都為 1,使用無界的?LinkedBlockingQueue?作為任務隊列。這種線程池確保所有任務按照提交順序依次執行,適合需要保證任務順序執行的場景。即使任務拋出異常,線程池也會創建一個新線程繼續執行后續任務。
ScheduledThreadPool:定時任務線程池,通過?Executors.newScheduledThreadPool(int corePoolSize)?創建。它的核心線程數由用戶指定,最大線程數為?Integer.MAX_VALUE,使用?DelayedWorkQueue?作為任務隊列。這種線程池適用于需要定時執行或周期性執行的任務,支持延遲執行和固定頻率執行。例如,可以使用?scheduleAtFixedRate()?方法按固定頻率執行任務,或使用?scheduleWithFixedDelay()?方法在任務執行完成后延遲固定時間再執行。
FixedThreadPool:固定大小的線程池,通過?Executors.newFixedThreadPool(int nThreads)?創建。它的核心線程數和最大線程數都為用戶指定的值,使用無界的?LinkedBlockingQueue?作為任務隊列。這種線程池適用于需要控制并發線程數的場景,線程數固定,不會創建過多線程導致系統資源耗盡。當所有線程都在執行任務時,新任務會在隊列中等待。
WorkStealingPool(Java 8 引入):工作竊取線程池,通過?Executors.newWorkStealingPool()?創建。它基于?ForkJoinPool?實現,使用多個工作隊列,不同線程可以從其他線程的隊列中竊取任務執行。這種線程池適合處理分治型任務,能夠充分利用多核 CPU 的并行能力,提高系統吞吐量。
這些預定義的線程池雖然使用方便,但在實際生產環境中可能存在一些風險。例如,CachedThreadPool?和?ScheduledThreadPool?的最大線程數為?Integer.MAX_VALUE,可能導致創建過多線程耗盡系統資源;SingleThreadPool?和?FixedThreadPool?使用無界隊列,可能導致任務堆積引發內存溢出。因此,建議手動配置?ThreadPoolExecutor,根據實際需求設置合理的參數,如核心線程數、最大線程數、任務隊列類型和拒絕策略等。
JVM 內存分布是怎樣的?
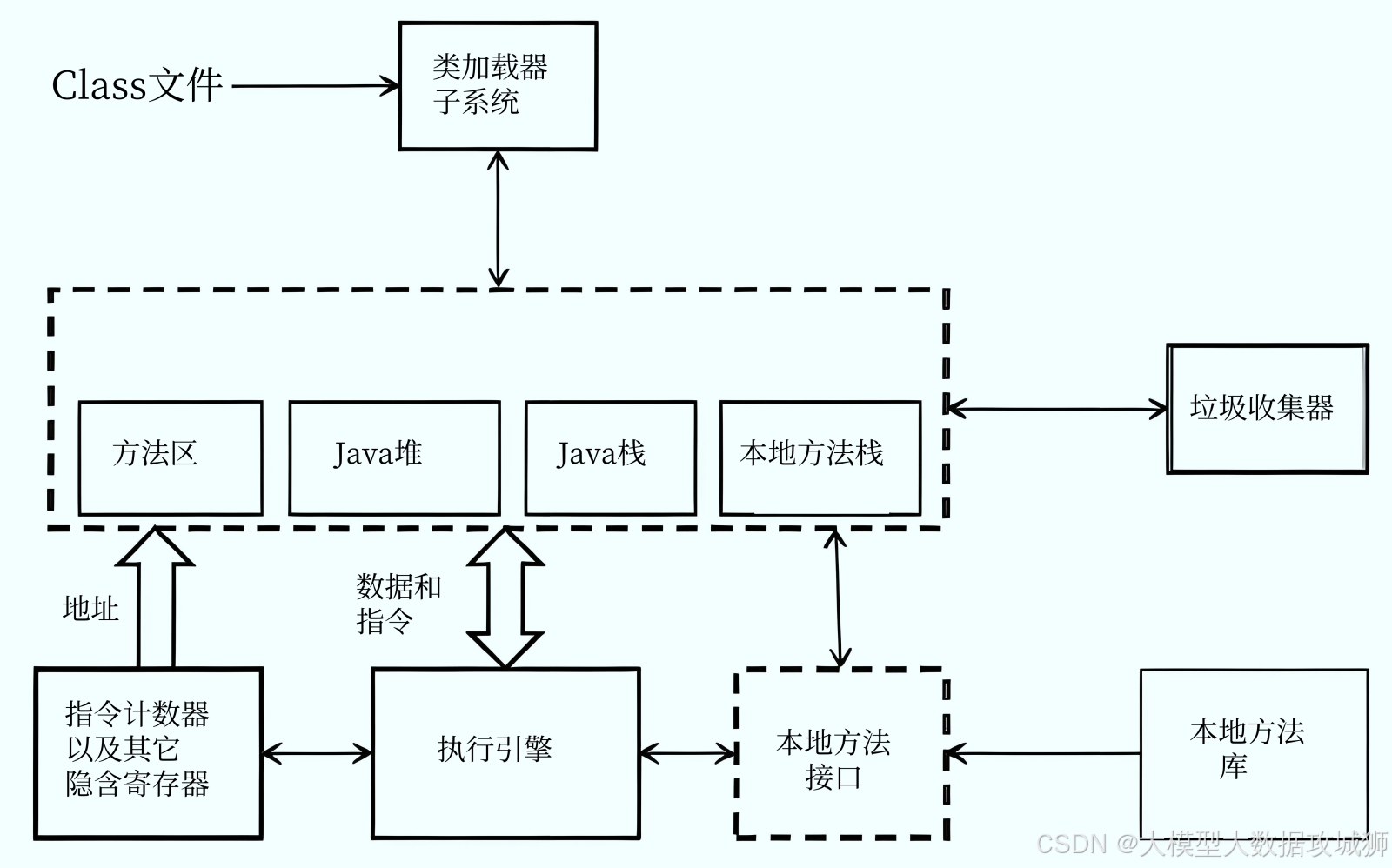
JVM 內存分布是指 Java 虛擬機在運行時將內存劃分為不同的區域,每個區域有不同的用途和生命周期。理解 JVM 內存分布對于優化 Java 應用性能、排查內存泄漏和解決 OutOfMemoryError 等問題至關重要。
堆(Heap):Java 堆是 JVM 管理的最大一塊內存區域,所有對象實例和數組都在堆上分配。堆是線程共享的,在 JVM 啟動時創建。堆內存又分為新生代和老年代,新生代進一步分為 Eden 區和兩個 Survivor 區(From 和 To)。堆的大小可以通過?-Xms?和?-Xmx?參數設置,當堆內存不足時,會拋出?OutOfMemoryError: Java heap space。
方法區(Method Area):方法區也是線程共享的內存區域,用于存儲類的結構信息,如類的字節碼、常量池、靜態變量、構造函數等數據。在 JDK 1.8 之前,方法區也被稱為永久代(PermGen),但從 JDK 1.8 開始,永久代被元空間(Metaspace)取代。元空間使用本地內存(Native Memory)而不是堆內存,避免了永久代的內存溢出問題。方法區的大小可以通過?-XX:MetaspaceSize?和?-XX:MaxMetaspaceSize?參數控制。
虛擬機棧(VM Stack):虛擬機棧是線程私有的,每個線程在創建時都會創建一個虛擬機棧。虛擬機棧由多個棧幀(Stack Frame)組成,每個棧幀對應一個方法調用。棧幀中存儲局部變量表、操作數棧、動態鏈接和方法出口等信息。當方法被調用時,會創建一個新的棧幀并壓入棧頂;方法執行完畢后,棧幀被彈出并銷毀。虛擬機棧的深度可以通過?-Xss?參數設置,當棧深度超過限制時,會拋出?StackOverflowError。
本地方法棧(Native Method Stack):本地方法棧與虛擬機棧類似,也是線程私有的,但它服務于本地方法(使用 native 關鍵字修飾的方法)。本地方法棧使用本地方法庫實現,不同的 JVM 實現可能有所不同。當本地方法棧溢出時,也會拋出?StackOverflowError。
程序計數器(Program Counter Register):程序計數器是線程私有的,它可以看作是當前線程所執行的字節碼的行號指示器。在 JVM 執行字節碼時,程序計數器會不斷更新,指示下一條要執行的字節碼指令。如果線程執行的是 native 方法,程序計數器的值為 undefined。程序計數器是唯一不會出現?OutOfMemoryError?的內存區域。
直接內存(Direct Memory):直接內存不屬于 JVM 運行時數據區的一部分,但它也被頻繁使用。直接內存通過?ByteBuffer?的?allocateDirect()?方法分配,使用本地內存,避免了 Java 堆和本地內存之間的數據復制,提高了 IO 操作的效率。直接內存的大小不受 Java 堆大小的限制,但受操作系統總內存的限制,當直接內存耗盡時,會拋出?OutOfMemoryError: Direct buffer memory。
JVM 內存分布的各個區域相互協作,共同支持 Java 程序的運行。合理配置各區域的大小和參數,對于優化應用性能和避免內存問題至關重要。例如,對于堆內存,可以根據應用的對象創建和銷毀頻率,調整新生代和老年代的比例;對于方法區,可以根據加載的類數量,合理設置元空間的大小。
JVM 分代回收機制的原理是什么?
JVM 分代回收機制是基于對象存活周期的不同將內存劃分為不同的區域,針對每個區域的特點采用不同的垃圾回收策略,從而提高垃圾回收的效率。這種機制的核心思想是 "大部分對象的生命周期很短,只有少數對象能存活很長時間",因此可以對不同生命周期的對象采取不同的回收策略。
JVM 將堆內存分為新生代(Young Generation)和老年代(Old Generation)。新生代又進一步分為 Eden 區和兩個 Survivor 區(通常稱為 From 和 To)。這種分代設計的目的是為了優化垃圾回收過程,減少垃圾回收對應用程序的影響。
新生代(Young Generation):大多數對象在創建時會被分配到新生代的 Eden 區。當 Eden 區滿時,會觸發一次 Minor GC(新生代垃圾回收)。在 Minor GC 過程中,存活的對象會被移動到其中一個 Survivor 區(如 From 區),同時清空 Eden 區。如果 Survivor 區空間不足,部分對象會被直接晉升到老年代。經過多次 Minor GC 后,仍然存活的對象會從一個 Survivor 區移動到另一個 Survivor 區,并且對象的年齡(經歷 GC 的次數)會增加。當對象的年齡達到一定閾值(默認 15 次)時,會被晉升到老年代。
老年代(Old Generation):老年代用于存儲生命周期較長的對象,如靜態變量引用的對象、緩存對象等。當老年代空間不足時,會觸發一次 Major GC 或 Full GC(全量垃圾回收)。Full GC 會回收整個堆內存,包括新生代、老年代和方法區(元空間)。由于 Full GC 涉及的內存區域較大,因此會導致較長的停頓時間,影響應用的性能。
分代回收的優勢:分代回收機制通過將對象按生命周期分類,針對不同區域采用不同的回收策略,提高了垃圾回收的效率。對于新生代,由于對象存活率低,Minor GC 可以快速回收大量垃圾對象,且采用復制算法(將存活對象復制到 Survivor 區),內存分配和回收速度快。對于老年代,對象存活率高,采用標記 - 清除或標記 - 整理算法更合適,減少了內存碎片的產生。
垃圾回收器的協作:不同的垃圾回收器在分代回收機制中扮演不同的角色。例如,Serial 收集器是一個單線程的收集器,適用于小型應用;Parallel 收集器是多線程的,適用于注重吞吐量的應用;CMS(Concurrent Mark Sweep)收集器是并發的,適用于注重響應時間的應用;G1(Garbage-First)收集器是一種面向服務器的垃圾回收器,將堆內存劃分為多個大小相等的區域,動態管理垃圾回收過程。
分代回收的觸發條件:
- Minor GC:當 Eden 區空間不足時觸發。
- Major GC:當老年代空間不足時觸發,通常會伴隨一次 Minor GC。
- Full GC:當老年代、元空間或堆外內存不足時觸發,或者手動調用?
System.gc()?時觸發。
JVM 分代回收機制通過合理劃分內存區域和采用不同的回收策略,有效地提高了垃圾回收的效率,減少了垃圾回收對應用程序的影響。在實際應用中,可以根據應用的特點和性能需求,選擇合適的垃圾回收器和調整相關參數,以達到最佳的性能表現。
TCP 和 UDP 的區別是什么?
TCP(傳輸控制協議)和 UDP(用戶數據報協議)是傳輸層的兩種核心協議,二者在設計目標、特性和應用場景上有顯著差異。
從連接特性來看,TCP 是面向連接的協議。通信雙方在傳輸數據前需要通過 “三次握手” 建立連接,傳輸完成后通過 “四次揮手” 釋放連接,確保通信鏈路的可靠性。而 UDP 是無連接的,發送端無需建立連接即可直接發送數據報,接收端也無需確認,因此通信流程更簡單,但缺乏連接狀態的管理。
可靠性機制是二者的核心區別。TCP 具備完善的可靠性保障機制,包括數據校驗、序列號、確認應答、超時重傳、流量控制和擁塞控制等。例如,發送端會為每個數據段分配序列號,接收端通過確認應答告知發送端數據已成功接收,若超時未收到確認則重新發送數據,確保數據無丟失、無重復且按序到達。UDP 則不提供這些機制,數據報一旦發出便不再跟蹤其狀態,可能出現丟失、亂序或重復的情況,可靠性完全由應用層負責。
傳輸效率與延遲方面,UDP 的無連接特性和缺乏復雜機制使其傳輸效率更高,延遲更低。由于無需建立連接和維護狀態,UDP 的頭部開銷較小(僅 8 字節),適合對實時性要求高、允許一定數據丟失的場景。TCP 因需要處理連接管理和可靠性機制,頭部開銷較大(20 字節,可擴展至 60 字節),且存在確認和重傳的時間延遲,更適合對數據完整性要求嚴格的場景。
數據單位與傳輸方式上,TCP 以字節流的形式傳輸數據,發送端和接收端通過滑動窗口機制動態調整傳輸速率,數據無邊界,應用層需要自行處理消息邊界。UDP 以數據報為單位傳輸,每個數據報包含完整的源地址和目的地址,具有明確的邊界,適合傳輸小數據塊。
應用場景的差異源于上述特性。TCP 常用于文件傳輸(FTP)、電子郵件(SMTP、POP3)、網頁瀏覽(HTTP/HTTPS)等需要高可靠性的場景;UDP 則適用于實時通信(如視頻會議、直播、在線游戲)、傳感器數據傳輸、DNS 查詢等對延遲敏感或允許部分數據丟失的場景。
總結來看,TCP 以犧牲效率為代價換取可靠性,適合需要穩定傳輸的場景;UDP 以效率優先,適合對實時性要求高的場景。開發者需根據具體業務需求選擇合適的協議。
TCP 和 UDP 的常用場景有哪些?
TCP(傳輸控制協議)和 UDP(用戶數據報協議)的特性差異決定了它們在不同場景中的適用性。以下結合具體應用場景分析二者的典型應用。
TCP 的常用場景
-
文件傳輸與數據同步
文件傳輸(如 FTP、SFTP)需要確保文件內容完整無誤,不允許數據丟失或損壞。TCP 的可靠性機制(如確認應答、超時重傳)能保證每個字節都被正確接收,因此成為這類場景的首選。例如,企業內部通過 FTP 傳輸大型文件時,TCP 的穩定傳輸能力可避免因網絡波動導致的文件損壞或傳輸中斷。 -
網頁瀏覽與應用層協議
HTTP 和 HTTPS 協議均基于 TCP 實現。網頁內容(如 HTML、圖片、視頻)需要按順序正確加載,若數據丟失或亂序會導致頁面渲染異常。TCP 的流量控制和擁塞控制機制可適應復雜的網絡環境,確保瀏覽器與服務器之間的穩定通信,例如用戶通過 Chrome 訪問電商網站時,TCP 保證商品圖片和文字信息完整顯示。 -
電子郵件與遠程登錄
電子郵件協議(SMTP、POP3、IMAP)依賴 TCP 傳輸郵件內容和附件,確保郵件在發送和接收過程中不丟失。遠程登錄協議(如 SSH、Telnet)也基于 TCP,保證用戶輸入的命令和服務器返回的結果按序傳輸,避免因數據亂序導致的操作錯誤。 -
數據庫連接與事務處理
數據庫系統(如 MySQL、Oracle)通過 TCP 建立連接,執行查詢和事務操作。事務的原子性和一致性要求數據必須準確無誤地傳輸,TCP 的可靠性機制可確保 SQL 語句和查詢結果正確傳遞,例如銀行轉賬操作中,TCP 保證扣款和入賬信息的一致性。
UDP 的常用場景
-
實時音視頻通信
視頻會議(如 Zoom、騰訊會議)、直播(如抖音、B 站直播)和在線游戲(如《王者榮耀》《絕地求生》)對延遲極其敏感。UDP 無需建立連接且傳輸效率高,能降低數據傳輸的延遲,滿足實時交互的需求。雖然可能出現少量數據丟失,但現代應用層協議(如 WebRTC)通過前向糾錯(FEC)等機制彌補可靠性不足,例如游戲中偶爾丟失幾個幀數據不會顯著影響玩家體驗,但延遲過高會導致操作卡頓。 -
傳感器與物聯網數據傳輸
物聯網設備(如溫濕度傳感器、智能電表)通常需要頻繁發送小數據量的狀態信息,且部分場景允許一定數據丟失(如實時溫度監控中偶爾漏讀一次數據不影響整體趨勢分析)。UDP 的低開銷和快速傳輸特性適合這類場景,例如智能家居系統中,多個傳感器通過 UDP 向網關發送狀態數據,降低設備功耗和網絡延遲。 -
DNS 查詢與網絡監控
DNS(域名系統)查詢需要快速獲取結果,單次查詢的數據量小(通常為幾十個字節),且 DNS 服務器通常會提供重試機制,因此 UDP 成為首選。例如,用戶在瀏覽器中輸入域名時,本地 DNS 客戶端通過 UDP 向 DNS 服務器發送查詢請求,迅速獲取 IP 地址。此外,網絡監控工具(如 SNMP)也常使用 UDP 傳輸監控數據,減少對被監控設備的資源占用。 -
實時消息推送與日志采集
實時消息推送(如新聞通知、社交 app 消息)和日志采集系統(如分布式日志服務)通常要求高吞吐量和低延遲,允許部分消息丟失(如重復推送一條通知對用戶影響不大)。UDP 的無連接特性使其能快速處理大量并發請求,例如移動應用通過 UDP 向用戶推送實時新聞,即使少量數據包丟失也不影響整體體驗。
選擇協議的核心邏輯
- 優先選 TCP:當業務需要高可靠性(如金融交易、文件傳輸)、數據有序性(如流媒體點播)或復雜交互(如客戶端 - 服務器通信)時,TCP 是更合適的選擇。
- 優先選 UDP:當業務需要低延遲(如實時音視頻)、高吞吐量(如大數據采集)或簡單交互(如單次查詢)時,UDP 更能發揮優勢,且應用層需自行處理可靠性問題(如有必要)。
TCP 如何保證可靠性?具體有哪些機制?
TCP(傳輸控制協議)通過一系列復雜機制確保數據在不可靠的網絡環境中可靠傳輸,其核心目標是保證數據無丟失、無重復、按序到達,并適應網絡擁塞和波動。以下是實現可靠性的關鍵機制及其工作原理。
1. 序列號與確認應答(ACK)
- 序列號機制:發送端為每個字節的數據分配唯一的序列號(Sequence Number),用于標識數據在字節流中的位置。例如,假設初始序列號為 100,發送 200 字節的數據段,則下一個數據段的序列號為 300。
- 確認應答機制:接收端收到數據后,向發送端返回確認應答(ACK),其中包含期望接收的下一個字節的序列號(即確認號 Acknowledgment Number)。例如,接收端成功收到序列號 100 - 299 的數據后,會返回 ACK 300,表示 “已收到前 200 字節數據,期待接收從 300 開始的數據”。
- 作用:通過序列號和 ACK,發送端可跟蹤數據的傳輸狀態,接收端可檢測數據是否重復或丟失,確保數據按序接收。
2. 超時重傳(Retransmission)
- 原理:發送端在發送數據后啟動定時器,若超時未收到對應的 ACK,會重新發送該數據段。超時時間(RTO,Retransmission Timeout)會根據網絡往返時間(RTT,Round-Trip Time)動態調整,避免因網絡延遲波動導致誤判。
- 重傳策略:
- 快重傳:若接收端連續收到三個相同的 ACK(表明后續數據丟失),發送端無需等待超時,立即重傳丟失的數據段,減少延遲。
- 重傳隊列:未確認的數據會被保存在重傳隊列中,直到收到對應的 ACK 才會移除,防止數據丟失。
3. 流量控制(Flow Control)
- 目的:避免發送端發送數據過快,導致接收端緩沖區溢出。
- 實現方式:接收端在 ACK 中攜帶自身接收緩沖區的剩余容量(即窗口大小 Window Size),發送端根據該值調整發送速率。例如,若接收端緩沖區剩余 1000 字節,發送端在收到 ACK 后最多發送 1000 字節數據,直到接收端釋放更多緩沖區空間。
- 滑動窗口(Sliding Window):發送端維護一個滑動窗口,窗口內的數據可無需等待 ACK 連續發送,窗口大小由接收端的窗口大小和網絡擁塞情況共同決定。窗口隨數據確認而向右滑動,提高傳輸效率。
4. 擁塞控制(Congestion Control)
- 目的:防止網絡中數據流量過大導致擁塞,避免路由器丟棄數據包。
- 核心算法:
- 慢啟動(Slow Start):初始時擁塞窗口(CWND,Congestion Window)較小(通常為 1 - 2 個最大段大小 MSS),每次收到 ACK 后按指數增長(如從 1 到 2,再到 4、8 等),快速探測網絡容量。
- 擁塞避免(Congestion Avoidance):當 CWND 超過閾值(ssthresh)后,轉為線性增長(每次增加 1 個 MSS),避免網絡擁塞。
- 快恢復(Fast Recovery):當檢測到丟包(如收到三個重復 ACK),進入快恢復階段,將 ssthresh 設為當前 CWND 的一半,CWND 設為 ssthresh + 3*MSS,然后轉為擁塞避免,減少丟包后的性能損失。
- 作用:通過動態調整發送端的擁塞窗口,使數據流量與網絡帶寬匹配,降低丟包率。
5. 數據校驗與丟棄重復數據
- 校驗和(Checksum):發送端在數據段中添加校驗和字段,接收端通過校驗和驗證數據是否在傳輸過程中損壞。若校驗失敗,直接丟棄該數據段,發送端會通過超時重傳機制重新發送。
- 重復數據檢測:接收端通過序列號判斷數據是否重復,若收到重復的數據段,直接丟棄并返回相同的 ACK,避免重復處理數據。
6. 連接管理與狀態機
- 三次握手建立連接:
- 客戶端發送 SYN 包(序列號 seq = x),請求建立連接。
- 服務器返回 SYN + ACK 包(seq = y,ack = x + 1),確認客戶端請求。
- 客戶端返回 ACK 包(seq = x + 1,ack = y + 1),完成連接建立。
三次握手確保雙方均確認對方的接收和發送能力,避免歷史連接的干擾。
- 四次揮手釋放連接:
雙方均可主動關閉連接,通過四次交互確保所有數據已傳輸完畢,避免半關閉狀態導致的數據丟失。
總結:可靠性機制的協同作用
TCP 的可靠性并非依賴單一機制,而是通過序列號與確認應答跟蹤數據狀態,超時重傳彌補丟包,流量控制適配接收端能力,擁塞控制適應網絡環境,校驗和與重復檢測保證數據完整性,以及連接管理確保通信鏈路穩定。這些機制相互配合,使 TCP 能在復雜的網絡環境中提供穩定可靠的傳輸服務,成為文件傳輸、網頁瀏覽等場景的基礎協議。
擁塞控制和流量控制的區別是什么?
擁塞控制(Congestion Control)和流量控制(Flow Control)是 TCP 協議中兩個關鍵機制,均用于調節數據傳輸速率,但二者的目標、作用范圍和實現原理存在顯著差異。以下從多個維度對比分析。
1. 核心目標不同
- 流量控制:
目標是適配接收端的處理能力,防止發送端發送數據過快導致接收端緩沖區溢出。例如,若接收端應用程序處理數據的速度較慢,接收緩沖區可能被填滿,此時流量控制通過限制發送端的速率,避免數據丟失。 - 擁塞控制:
目標是適配網絡的整體容量,防止網絡中數據流量過大導致擁塞(如路由器隊列溢出、丟包率上升)。例如,當多個發送端同時向同一網絡路徑發送大量數據時,可能超過路由器的處理能力,擁塞控制通過調節發送端的速率,避免網絡癱瘓。
2. 作用范圍不同
- 流量控制:
是端到端的控制,僅涉及發送端和接收端兩個端點。接收端通過反饋自身緩沖區的剩余容量(窗口大小)直接控制發送端的速率,與中間網絡設備(如路由器)無關。 - 擁塞控制:
是網絡全局的控制,涉及發送端、接收端和中間網絡設備。發送端需要根據網絡中的擁塞信號(如丟包、延遲增加)調整速率,以避免整個網絡出現擁塞,其影響范圍包括路徑上的所有節點。
3. 觸發條件不同
- 流量控制:
觸發條件是接收端的接收能力不足。例如,接收端應用程序因忙于處理其他任務而無法及時讀取接收緩沖區的數據,導致緩沖區剩余空間減少,此時接收端通過減小窗口大小通知發送端降低速率。 - 擁塞控制:
觸發條件是網絡資源不足。例如,路由器的隊列已滿,無法處理更多數據包,導致丟包率上升,此時發送端通過檢測丟包(如超時或收到重復 ACK)判斷網絡擁塞,并調整擁塞窗口大小以降低發送速率。
4. 實現機制不同
| 維度 | 流量控制 | 擁塞控制 |
|---|---|---|
| 關鍵參數 | 接收端窗口大小(Receiver Window, rwnd) | 擁塞窗口大小(Congestion Window, cwnd) |
| 控制信號 | 接收端在 ACK 中攜帶 rwnd 值 | 發送端根據丟包、RTT 等信號調整 cwnd |
| 算法邏輯 | 基于接收端反饋的窗口大小直接限制發送速率 | 使用慢啟動、擁塞避免、快重傳、快恢復等算法 |
| 典型場景 | 接收端處理能力突然下降(如手機切換后臺) | 網絡中多用戶競爭帶寬(如視頻直播高峰期) |
5. 對傳輸速率的影響
- 流量控制:
可能導致發送速率長期低于網絡容量。例如,若接收端處理能力極低(如 rwnd = 0),發送端會停止發送數據,即使網絡本身有足夠帶寬。 - 擁塞控制:
動態平衡網絡容量與發送速率。在網絡空閑時,發送端通過慢啟動快速提升速率;在網絡擁塞時,通過降低 cwnd 避免丟包,確保速率與網絡容量匹配。
6. 協同工作方式
盡管二者目標和機制不同,但在 TCP 中協同作用以優化傳輸效率:
- 流量控制是基礎:確保數據不會壓垮接收端,是端到端可靠性的基本保障。
- 擁塞控制是擴展:在流量控制的基礎上,進一步避免網絡擁塞,提升整體網絡利用率。
- 示例:當發送端的 cwnd 受限于 rwnd 時(即接收端處理能力低于網絡容量),流量控制起主導作用;當 cwnd 受限于網絡擁塞時(如 cwnd 超過路由器隊列容量),擁塞控制起主導作用。
總結:核心差異與實際意義
- 流量控制解決的是發送端與接收端之間的局部匹配問題,關注接收端的 “個體承受能力”;
- 擁塞控制解決的是發送端與整個網絡之間的全局協調問題,關注網絡的 “整體負載平衡”。
理解二者的區別有助于在網絡優化中精準定位問題:若接收端緩沖區頻繁溢出,需優化流量控制參數;若網絡頻繁出現丟包和延遲,需調整擁塞控制策略。兩者共同確保 TCP 在復雜網絡環境中既不 “壓垮接收端”,也不 “堵塞網絡”,實現高效可靠的傳輸。
如何理解 Redis 的 IO 多路復用?
Redis 的 IO 多路復用(IO Multiplexing)是其實現高性能網絡通信的核心技術,尤其在處理大量客戶端連接時,能顯著提升資源利用率和響應速度。理解這一機制需要從問題背景、核心原理、具體實現和實際效果四個層面展開。
一、問題背景:傳統 IO 模型的瓶頸
在傳統的網絡編程中,服務器處理多個客戶端連接通常有兩種方式:
- 多線程 / 多進程模型:為每個客戶端創建獨立的線程或進程處理請求。這種方式在客戶端數量較少時有效,但當連接數激增(如數萬級),線程 / 進程的創建、銷毀和上下文切換會消耗大量系統資源,導致性能急劇下降。
- 阻塞式 IO 循環模型:單線程通過循環依次處理每個客戶端連接,若某個連接阻塞(如等待數據讀取),會導致整個線程阻塞,無法處理其他連接,實時性差。
Redis 作為內存數據庫,需要同時處理大量短連接請求(如每秒數萬次讀寫),上述模型均無法滿足性能需求。IO 多路復用通過單線程管理多個文件描述符(FD,File Descriptor),避免了多線程的開銷,同時解決了阻塞式 IO 的低效問題。
二、核心原理:事件驅動與文件描述符監控
IO 多路復用的核心思想是:用一個或少數幾個線程監控多個文件描述符的 IO 事件(如可讀、可寫、異常),當某個文件描述符就緒時,觸發相應的事件處理函數。具體流程如下:
- 注冊事件:將客戶端連接的文件描述符注冊到多路復用器(Multiplexer)中,并為每個描述符關聯讀、寫等事件的回調函數。
- 等待事件:多路復用器阻塞等待任意一個文件描述符就緒(即有數據可讀或可寫)。
- 分發事件:當檢測到就緒的文件描述符時,多路復用器將事件分發給對應的回調函數處理,處理完成后重新回到等待狀態。
這一過程中,單線程通過非阻塞 IO 系統調用(如 select/poll/epoll)避免阻塞,僅在有事件就緒時才執行實際的 IO 操作,從而在單線程內高效處理多個連接。
三、Redis 對多路復用的具體實現
Redis 基于操作系統提供的多路復用 API 實現事件驅動機制,并根據不同系統自動選擇最優方案:
- select/poll:早期操作系統普遍支持的接口,但存在明顯缺陷:
- select:可監控的文件描述符數量受限(通常為 1024),且采用輪詢方式遍歷所有描述符,時間復雜度為 O (n),性能隨連接數增加而下降。
- poll:通過鏈表存儲描述符,突破了 select 的數量限制,但本質仍是輪詢,效率未根本提升。
- epoll(Linux)/kqueue(BSD):現代高性能接口,采用事件通知機制:
- epoll:通過 epoll_ctl () 注冊描述符,epoll_wait () 阻塞等待事件,當描述符就緒時通過回調函數主動通知,時間復雜度為 O (1)(僅處理就緒事件),支持數萬級連接。
- kqueue:BSD 系統(如 macOS)的類似機制,功能與 epoll 類似,支持高效的事件驅動。
Redis 通過?aeEventLoop 結構體管理事件循環,核心組件包括:
- aeFileEvent:存儲文件描述符的事件類型(讀 / 寫)和回調函數。
- aeTimeEvent:處理定時事件(如心跳檢測、過期鍵刪除)。
- aeMain():主循環函數,不斷調用多路復用接口等待事件,然后依次處理就緒的文件事件和定時事件。
四、IO 多路復用帶來的優勢
- 單線程高性能:
避免多線程的上下文切換開銷,單線程即可處理大量并發連接。例如,Redis 官方測試顯示,單實例可支持超過 10 萬次 / 秒的請求。 - 低內存占用:
無需為每個連接創建獨立線程,內存使用效率更高,適合 Redis 這種內存密集型應用。 - 事件驅動的靈活性:
可輕松擴展對新事件類型的支持(如網絡連接、定時器、信號等),Redis 借此實現了命令請求處理、數據持久化、主從復制等功能的高效協同。
五、適用場景與局限性
- 適用場景:
Redis 的 IO 多路復用特別適合短連接、高并發、低延遲的場景,如緩存查詢、實時計數、消息隊列等。每個請求的處理邏輯應盡可能簡短,避免長時間阻塞事件循環(如復雜計算或磁盤 IO),否則會影響整體性能。 - 局限性:
單線程模型下,CPU 利用率受限于單個核心(Redis 6.0 引入多線程僅用于網絡 IO 處理,核心邏輯仍為單線程)。若業務需要大量計算,需通過集群架構擴展,而非依賴單節點性能。
MySQL 哪些字段不適合建立索引?
在 MySQL 中,索引是提高查詢效率的重要手段,但并非所有字段都適合建立索引。不當的索引設計不僅會增加存儲空間,還會降低寫操作的性能。以下是幾類不適合建立索引的字段:
1. 很少被查詢的字段
索引的價值在于加速查詢,但如果某個字段在查詢條件中很少被使用,建立索引只會徒增維護成本。例如,用戶表中的 “注冊 IP” 字段,若業務中極少根據 IP 進行查詢,則無需為其創建索引。
2. 基數(Cardinality)過低的字段
基數指字段中不同值的數量。對于基數過低的字段(如性別、狀態標志),索引的區分度差,優化效果有限。例如,性別字段只有 “男 / 女” 兩個值,即使建立索引,查詢時仍需掃描大量數據頁,可能不如全表掃描高效。此時可通過?SHOW INDEX FROM table_name?查看?Cardinality?值,若接近行數則表示基數高,適合索引。
3. 頻繁更新的字段
索引需要在數據插入、更新或刪除時同步維護,頻繁更新的字段會導致索引維護開銷增大。例如,訂單表中的 “支付狀態” 字段,若經常被更新,建立索引會影響寫操作性能。
4. 大字段或長文本字段
對于 TEXT、BLOB 或超長 VARCHAR 字段,建立索引會占用大量存儲空間,且可能導致索引樹層級過深,查詢效率下降。若確實需要對大字段進行查詢,可考慮前綴索引(如?ALTER TABLE table_name ADD INDEX idx_col(col(20))),僅索引前 N 個字符,但需權衡前綴長度與區分度。
5. 參與計算或函數操作的字段
當字段在查詢條件中被函數處理(如?WHERE YEAR(create_time)=2023)或參與計算(如?WHERE price*0.9<100)時,索引無法生效。因為索引存儲的是原始值,無法直接匹配計算后的結果。此時應優化查詢條件,避免對字段進行函數操作。
6. 復合索引中順序不合理的字段
在復合索引中,字段順序至關重要。若查詢條件未遵循最左前綴原則,索引可能失效。例如,復合索引?(a, b, c)?僅支持?WHERE a=?、WHERE a=? AND b=??等查詢,若僅查詢?WHERE b=??則無法利用該索引。因此,若某個字段在復合索引中位置靠后且單獨被查詢的頻率較高,不適合包含在索引中。
7. 數據分布不均的字段
若字段的值分布極不均勻(如大部分值集中在少數幾個值上),索引可能導致查詢優化器誤判。例如,用戶表中的 “國家” 字段,若 90% 的用戶都來自同一個國家,基于該字段的查詢可能無法有效利用索引,反而增加隨機 IO。
慢 SQL 優化的常見方法有哪些?
慢 SQL 是數據庫性能瓶頸的常見原因,優化慢 SQL 需從查詢語句、索引設計、數據庫配置、表結構等多個維度入手。以下是常見的優化方法:
1. 利用索引加速查詢
- 添加合適的索引:通過?
EXPLAIN?分析查詢語句,確保 WHERE 子句、JOIN 條件和 ORDER BY 字段上有索引。例如,WHERE a=? AND b=? ORDER BY c?可創建復合索引?(a, b, c)。 - 優化索引順序:復合索引遵循最左前綴原則,將篩選性強的字段放在前面。例如,
WHERE gender='男' AND age>18?中,若性別基數低而年齡基數高,應優先索引 age。 - 避免索引失效:避免在索引字段上使用函數(如?
WHERE YEAR(date)=2023)、計算(如?WHERE price*0.9<100)或隱式類型轉換(如字符串字段與數字比較)。
2. 優化查詢語句結構
- 減少全表掃描:確保查詢條件有索引覆蓋,避免?
SELECT *,只查詢需要的字段。例如,將?SELECT * FROM users?改為?SELECT id, name FROM users。 - 拆分復雜查詢:對于多表 JOIN 查詢,若數據量較大,可拆分為多個單表查詢,在應用層組裝結果。例如,將?
SELECT u.name, o.order_no FROM users u JOIN orders o ON u.id=o.user_id?拆分為先查詢用戶,再批量查詢訂單。 - 避免子查詢:子查詢(尤其是相關子查詢)效率較低,可改用 JOIN 或 CTE(公共表表達式)替代。例如:
-- 低效子查詢 SELECT name FROM users WHERE id IN (SELECT user_id FROM orders WHERE amount>100); -- 優化為 JOIN SELECT u.name FROM users u JOIN orders o ON u.id=o.user_id WHERE o.amount>100;
3. 調整數據庫參數配置
- 增大緩沖池(Buffer Pool):對于 InnoDB 存儲引擎,緩沖池負責緩存數據頁和索引頁,增大其大小(如?
innodb_buffer_pool_size=8G)可減少磁盤 IO。 - 優化查詢緩存:開啟查詢緩存(
query_cache_type=1)可緩存頻繁執行的查詢結果,但需注意寫操作會使相關緩存失效,適用于讀多寫少的場景。 - 調整日志參數:適當增大?
innodb_log_file_size?和?innodb_log_files_in_group?可減少日志文件切換頻率,提升寫性能。
4. 優化表結構與數據類型
- 選擇合適的數據類型:例如,用 TINYINT 代替 INT 存儲布爾值或狀態碼,用 DATETIME 代替 VARCHAR 存儲日期時間,減少存儲空間和內存占用。
- 垂直拆分大表:將不常用的字段拆分到單獨的表中,減少單表數據量。例如,用戶表中,將個人簡介、頭像等不常用字段拆分到擴展表。
- 水平分片(Sharding):對于數據量極大的表(如億級記錄),可按業務規則(如時間、地域)將數據分散到多個表或服務器。
5. 分析執行計劃與定位問題
- 使用 EXPLAIN:通過?
EXPLAIN SELECT ...?查看查詢執行計劃,重點關注?type(訪問類型,理想值為?const、eq_ref、ref)、key(使用的索引)和?rows(估計掃描的行數)。 - 監控慢查詢日志:開啟慢查詢日志(
slow_query_log=1),記錄執行時間超過閾值(long_query_time=1)的 SQL,分析高頻出現的慢 SQL。 - 使用性能分析工具:如 MySQL Enterprise Monitor、pt-query-digest 等,自動分析慢 SQL 并提供優化建議。
6. 優化特殊操作
- 批量插入數據:將多次單條插入改為批量插入(如?
INSERT INTO users (name) VALUES ('a'), ('b'), ('c')),減少事務開銷。 - 優化 GROUP BY 和 ORDER BY:確保 GROUP BY 和 ORDER BY 字段使用相同的索引,避免文件排序(Filesort)。
- 避免大事務:長事務會占用鎖資源,導致其他查詢阻塞,盡量拆分大事務為多個小事務。
7. 硬件升級與架構優化
- 升級硬件配置:增加內存、使用 SSD 替代 HDD、提升 CPU 性能等。
- 讀寫分離:主庫負責寫操作,從庫負責讀操作,分攤查詢壓力。
- 引入緩存層:對熱點數據(如商品信息、用戶配置)使用 Redis 緩存,減少數據庫訪問。
什么是索引下推(Index Condition Pushdown)?
索引下推(Index Condition Pushdown,ICP)是 MySQL 5.6 引入的一項查詢優化技術,用于減少回表操作,提升查詢效率。理解 ICP 需先明確索引結構和查詢流程。
在 MySQL 中,二級索引(非主鍵索引)通常包含索引列和主鍵值。當查詢僅需索引列數據時,可直接通過索引樹返回結果(索引覆蓋);若需查詢其他字段,則需通過索引中的主鍵值回表(Row Fetch)到主鍵索引獲取完整數據。
ICP 的核心思想:將部分 WHERE 子句的過濾條件下推到存儲引擎層,在掃描索引時直接過濾不滿足條件的記錄,減少回表次數。
示例說明:
假設有表?users,包含索引?(last_name, first_name),查詢語句為:
SELECT * FROM users WHERE last_name='張' AND first_name LIKE '三%';
未使用 ICP 時:
- 存儲引擎通過索引定位到所有?
last_name='張'?的記錄。 - 將這些記錄的主鍵值返回給服務器層。
- 服務器層根據主鍵回表,獲取完整數據。
- 服務器層在內存中過濾?
first_name LIKE '三%'?的記錄。
使用 ICP 時:
- 存儲引擎在掃描索引時,同時評估?
last_name='張' AND first_name LIKE '三%'。 - 僅將滿足條件的記錄的主鍵值返回給服務器層。
- 服務器層直接回表獲取符合條件的完整數據,無需二次過濾。
ICP 的優勢:
- 減少回表次數:如示例中,若?
last_name='張'?的記錄有 100 條,但僅 10 條滿足?first_name LIKE '三%',ICP 可將回表次數從 100 次降至 10 次。 - 降低 CPU 與內存開銷:過濾操作在存儲引擎層完成,減少了返回給服務器層的數據量。
ICP 的適用條件:
- 查詢需使用二級索引,且 WHERE 子句包含索引列的條件。
- 過濾條件可下推到存儲引擎層(如比較操作、LIKE 前綴匹配等)。
- 索引類型支持(如 InnoDB、MyISAM,不支持 MEMORY 引擎)。
ICP 的限制:
- 對于?
SELECT *?且索引無法覆蓋的查詢,ICP 仍需回表,但可減少回表次數。 - 若過濾條件僅涉及主鍵或索引覆蓋的字段,ICP 無優化效果(因無需回表)。
- 子查詢中的條件無法下推,如?
WHERE id IN (SELECT id FROM other_table WHERE ...)。
查看 ICP 是否生效:
通過?EXPLAIN?分析查詢計劃,若?Extra?列顯示?Using index condition,則表示啟用了 ICP。
Redis 中 ZSet 的數據結構是什么?什么是跳表(Skip List)?
Redis 的有序集合(ZSet)是一種存儲鍵值對(score, member)的數據結構,支持按分數(score)排序和快速查找。其底層實現結合了跳表(Skip List)和哈希表(Hash Table),以平衡插入、刪除、查找和范圍查詢的性能。
ZSet 的數據結構
ZSet 在 Redis 中的核心結構是?zset,包含兩個關鍵組件:
- 哈希表(dict):存儲?
member?到?score?的映射,支持 O (1) 時間復雜度的?member?存在性檢查和分數查詢。 - 跳表(zskiplist):按分數排序存儲?
(score, member)?對,支持 O (logN) 時間復雜度的插入、刪除和范圍查詢。
這種組合設計的優勢在于:
- 哈希表保證了?
ZSCORE、ZINCRBY?等命令的高效執行。 - 跳表支持按分數范圍的快速遍歷(如?
ZRANGE、ZREVRANGE)。
跳表(Skip List)的原理
跳表是一種隨機化的數據結構,通過在鏈表基礎上增加多層索引來加速查找,其平均時間復雜度為 O (logN),最壞情況為 O (N)。與平衡樹(如紅黑樹)相比,跳表的優勢在于實現簡單、支持范圍查詢更高效。
跳表的核心思想:
- 在原始鏈表之上創建多層索引,每層索引都是下一層的子集。
- 最高層索引的節點數最少,搜索時從最高層開始,快速跳過大量節點,逐步降低層級直到找到目標節點。
跳表的結構特點:
- 多層鏈表:每層都是一個有序鏈表,最底層包含所有節點。
- 節點隨機層級:每個節點的層級(Level)在插入時隨機確定(通常為 1 到 32 之間),層級越高出現概率越低(如 50% 的概率為 1 層,25% 為 2 層,依此類推)。
- 前向指針:每個節點包含多個前向指針,分別指向不同層級的后續節點。
跳表的操作示例:
假設有一個有序鏈表?1 → 3 → 4 → 6 → 7 → 9 → 12 → 15 → 17,構建跳表時:
- 隨機為每個節點分配層級,如節點?
3?被分配為 3 層,節點?6?為 2 層,其他節點為 1 層。 - 構建多層索引:
- 第 3 層:
3 → 17 - 第 2 層:
3 → 6 → 15 → 17 - 第 1 層:
1 → 3 → 4 → 6 → 7 → 9 → 12 → 15 → 17(原始鏈表)
- 第 3 層:
查找節點?12?時,從第 3 層開始:
- 第 3 層:從?
3?出發,發現?17?大于?12,降至第 2 層。 - 第 2 層:從?
3?到?6?到?15,發現?15?大于?12,降至第 1 層。 - 第 1 層:從?
6?到?7?到?9?到?12,找到目標節點。
Redis 跳表的實現細節
Redis 對跳表進行了以下優化:
- 雙向指針:每個節點包含指向前驅和后繼的指針,支持逆序遍歷(如?
ZREVRANGE)。 - 跨度(Span):每個前向指針包含跨度值,表示跳過的節點數,用于快速計算排名(如?
ZRANK)。 - 表頭和表尾節點:跳表包含表頭(header)和表尾(tail)節點,簡化邊界處理。
跳表節點結構(redis.h/zskiplistNode):
typedef struct zskiplistNode { sds ele; // 成員對象 double score; // 分數 struct zskiplistNode *backward; // 后退指針 struct zskiplistLevel { struct zskiplistNode *forward; // 前進指針 unsigned long span; // 跨度 } level[]; // 層級數組,動態分配
} zskiplistNode;
跳表結構(redis.h/zskiplist):
typedef struct zskiplist { struct zskiplistNode *header, *tail; // 表頭和表尾節點 unsigned long length; // 節點數量 int level; // 最大層級
} zskiplist;
跳表 vs 平衡樹
| 維度 | 跳表(Skip List) | 平衡樹(如紅黑樹) |
|---|---|---|
| 實現復雜度 | 簡單,易于理解和維護 | 復雜,需處理旋轉、顏色等操作 |
| 范圍查詢 | O (logN + M)(M 為結果數) | O (logN + M),但實現更復雜 |
| 插入 / 刪除 | 平均 O (logN),無需調整結構 | O (logN),需旋轉維護平衡 |
| 內存占用 | 每個節點需額外指針(約 2 倍) | 每個節點需額外顏色位 |
Redis 的過期刪除策略有哪些?
Redis 的過期刪除策略用于處理設置了過期時間的鍵(Key),確保過期數據及時被清理,釋放內存空間。Redis 采用 ** 惰性刪除(Lazy Expiration)和定期刪除(Periodic Expiration)** 兩種策略協同工作,并通過內存淘汰機制應對內存不足的情況。
1. 惰性刪除(Lazy Expiration)
核心思想:當訪問某個鍵時,才檢查該鍵是否過期,若過期則立即刪除并返回空值。
實現方式:
- 當執行?
GET、HGET?等讀取操作時,Redis 會首先檢查鍵是否過期。 - 若過期,Redis 會刪除該鍵并返回空值(如?
nil)。 - 若未過期,正常返回鍵值。
優點:
- 無需額外開銷,僅在訪問時檢查,減少 CPU 消耗。
- 對內存友好,未被訪問的過期鍵會暫時保留,避免頻繁刪除操作。
缺點:
- 若過期鍵長期未被訪問,會持續占用內存,可能導致內存泄漏。例如,設置了過期時間的緩存數據若不再被訪問,會一直留在內存中。
2. 定期刪除(Periodic Expiration)
核心思想:Redis 服務器定期(默認每秒 10 次)隨機檢查一部分鍵,刪除其中過期的鍵。
實現步驟:
- 隨機抽樣:從過期鍵字典中隨機選擇 20 個鍵。
- 刪除檢查:刪除這 20 個鍵中已過期的鍵。
- 循環處理:若過期鍵比例超過 25%,重復步驟 1 和 2,直到過期鍵比例低于閾值或執行時間超過 25ms(避免長時間阻塞)。
配置參數:
hz:控制定期刪除的頻率,默認 10 次 / 秒,可通過?CONFIG SET hz 20?調整。值越大,檢查越頻繁,內存釋放更及時,但可能增加 CPU 負擔。
優點:
- 定期清理過期鍵,避免惰性刪除導致的內存占用問題。
- 通過隨機抽樣和時間限制,平衡了內存清理和服務器性能。
缺點:
- 無法保證所有過期鍵被及時刪除,極端情況下仍可能存在短暫的內存占用。
- 若過期鍵數量龐大,可能導致定期刪除耗時過長,影響服務器響應。
3. 內存淘汰機制(Eviction Policy)
當 Redis 內存使用達到上限(maxmemory)時,觸發內存淘汰機制,主動刪除部分鍵以釋放空間。Redis 提供多種淘汰策略,可通過?maxmemory-policy?配置:
- volatile-lru(默認):刪除最近最少使用(LRU)的過期鍵。
- allkeys-lru:刪除最近最少使用(LRU)的鍵,無論是否過期。
- volatile-lfu:刪除最不經常使用(LFU)的過期鍵。
- allkeys-lfu:刪除最不經常使用(LFU)的鍵。
- volatile-random:隨機刪除過期鍵。
- allkeys-random:隨機刪除任意鍵。
- volatile-ttl:刪除剩余時間最短(TTL)的過期鍵。
- noeviction:拒絕寫操作,僅允許讀操作,直到有內存釋放。
選擇策略建議:
- 若需緩存大量數據且希望優先淘汰冷數據,可選擇?
allkeys-lru?或?allkeys-lfu。 - 若業務中鍵有明確的過期時間,可選擇?
volatile-lru?或?volatile-ttl。
4. 實際應用中的權衡
- 內存與 CPU 的平衡:惰性刪除節省 CPU 但可能浪費內存,定期刪除釋放內存但消耗 CPU。需根據業務場景調整?
hz?參數,如讀寫密集型應用可適當降低頻率。 - 過期鍵分布影響:若大量鍵同時過期,可能導致定期刪除時瞬間壓力增大,需避免集中設置過期時間。
- 監控與調優:通過?
INFO memory?監控內存使用和?expired_keys?指標,及時調整?maxmemory?和淘汰策略。
Redis 為什么執行命令是單線程的?為什么性能依然高效?
Redis 執行命令采用單線程模型,主要原因在于其設計目標和架構特性。單線程設計能避免多線程帶來的鎖競爭和上下文切換開銷,簡化了數據結構和算法的實現。例如,在多線程環境下,對共享數據的并發訪問需要復雜的同步機制,而單線程模型無需考慮這些問題,使 Redis 內部實現更加簡潔高效。
Redis 的高性能源于多方面因素的協同作用。首先,它是純內存操作,數據存儲在內存中,讀寫速度極快,內存訪問的響應時間通常在微秒級別。其次,Redis 使用高效的數據結構,如跳表、哈希表等,這些數據結構的操作時間復雜度大多為 O (1) 或 O (logN),保證了單個命令的快速執行。此外,Redis 采用了 I/O 多路復用技術,通過單線程監聽多個套接字的讀寫事件,能高效處理大量并發連接,進一步提升了整體吞吐量。
雖然 Redis 執行命令是單線程的,但它在處理網絡 I/O 時使用了非阻塞 I/O 和多路復用技術。例如,在 Linux 系統中,Redis 采用 epoll 機制,通過事件驅動的方式處理多個客戶端連接,避免了傳統阻塞 I/O 模型中一個連接阻塞導致整個線程無法處理其他連接的問題。這種設計使得 Redis 單線程也能高效處理大量并發請求,每秒可處理數萬甚至十萬級的命令。
值得注意的是,Redis 6.0 引入了多線程特性,但僅用于網絡 I/O 處理,命令執行仍然是單線程的。網絡 I/O 多線程可以并行處理客戶端請求和響應,進一步提升了 Redis 在高并發場景下的性能。但核心命令執行保持單線程,確保了數據操作的原子性和線程安全,避免了多線程編程的復雜性。
觀察者模式與策略模式的區別是什么?各自的使用場景和優勢是什么?
觀察者模式和策略模式是兩種不同的設計模式,它們解決的問題和應用場景有明顯區別。
觀察者模式定義了一種一對多的依賴關系,讓多個觀察者對象同時監聽一個主題對象。這個主題對象在狀態發生變化時,會通知所有觀察者對象,使它們能夠自動更新自己的狀態。例如,在一個天氣監測系統中,天氣數據是主題對象,而顯示天氣的各種組件(如手機應用、網站、桌面 Widget)是觀察者。當天氣數據更新時,所有觀察者都會收到通知并更新顯示。
觀察者模式的優勢在于實現了對象間的解耦,主題對象不需要知道具體的觀察者是誰,只需要維護一個觀察者列表并在狀態變化時通知它們。這種模式適用于一個對象的狀態變化需要通知多個其他對象的場景,如事件處理系統、消息通知系統等。它的使用場景包括發布 - 訂閱系統、GUI 組件間的交互等。
策略模式則是定義了一系列算法,并將每個算法封裝起來,使它們可以相互替換。策略模式讓算法的變化獨立于使用算法的客戶端。例如,在一個電商系統中,計算訂單折扣可以有多種策略:新用戶折扣、節日折扣、會員折扣等。系統可以根據不同的場景選擇不同的折扣策略,而不需要修改訂單處理的核心邏輯。
策略模式的優勢在于提供了一種靈活的方式來替換算法,避免了使用大量的條件語句。它將算法的實現和使用分離,使得代碼更易于維護和擴展。策略模式適用于多種算法解決同一類問題的場景,如排序算法選擇、支付方式選擇等。它的使用場景包括游戲中的角色行為、文件壓縮算法選擇等。
兩者的主要區別在于:觀察者模式關注的是對象間的通知機制,解決的是一個對象狀態變化如何通知多個依賴對象的問題;而策略模式關注的是算法的封裝和替換,解決的是如何在運行時選擇不同算法的問題。觀察者模式是一種行為模式,而策略模式是一種對象創建模式。
常見的設計模式有哪些?請舉例說明責任鏈模式、單例模式、工廠模式的應用場景。
常見的設計模式包括創建型模式、結構型模式和行為型模式三大類。創建型模式主要用于對象的創建過程,結構型模式關注如何將類或對象組合成更大的結構,行為型模式則用于處理對象之間的交互和職責分配。
責任鏈模式是一種行為型設計模式,它將請求的發送者和接收者解耦,使多個對象都有機會處理這個請求。這些對象連接成一條鏈,并沿著這條鏈傳遞該請求,直到有一個對象處理它為止。例如,在一個公司的請假審批系統中,員工請假的請求會依次經過組長、經理、總監等層級的審批。每個審批者都可以決定是否處理該請求或將其傳遞給下一個審批者。責任鏈模式的應用場景包括請求審批流程、日志處理、異常處理等。它的優勢在于可以動態地添加或修改處理者,提高了系統的靈活性和可維護性。
單例模式是一種創建型設計模式,它確保一個類只有一個實例,并提供一個全局訪問點來獲取這個實例。例如,在一個應用程序中,數據庫連接池通常設計為單例模式,因為創建多個數據庫連接池會導致資源浪費和管理混亂。單例模式的應用場景包括配置管理、線程池、緩存等。它的優勢在于減少了系統資源消耗,避免了多個實例導致的不一致問題。
工廠模式是一種創建型設計模式,它定義了一個創建對象的接口,讓子類決定實例化哪個類。工廠模式將對象的創建和使用分離,提高了代碼的可維護性和可擴展性。例如,在一個游戲開發中,不同類型的武器(如劍、弓箭、魔法杖)可以通過武器工廠來創建。客戶端只需要知道需要什么類型的武器,而不需要知道具體的創建過程。工廠模式的應用場景包括對象創建邏輯復雜、需要根據不同條件創建不同類型對象的情況。它的優勢在于將對象的創建邏輯集中管理,降低了客戶端代碼與具體實現類的耦合度。
這些設計模式在實際開發中被廣泛應用,能夠幫助開發者解決各種常見的軟件設計問題,提高代碼的質量和可維護性。例如,責任鏈模式可以使請求處理流程更加靈活,單例模式可以確保系統資源的合理利用,工廠模式可以簡化對象的創建過程。
)

















)
