Langchain系列文章目錄
01-玩轉LangChain:從模型調用到Prompt模板與輸出解析的完整指南
02-玩轉 LangChain Memory 模塊:四種記憶類型詳解及應用場景全覆蓋
03-全面掌握 LangChain:從核心鏈條構建到動態任務分配的實戰指南
04-玩轉 LangChain:從文檔加載到高效問答系統構建的全程實戰
05-玩轉 LangChain:深度評估問答系統的三種高效方法(示例生成、手動評估與LLM輔助評估)
06-從 0 到 1 掌握 LangChain Agents:自定義工具 + LLM 打造智能工作流!
07-【深度解析】從GPT-1到GPT-4:ChatGPT背后的核心原理全揭秘
08-【萬字長文】MCP深度解析:打通AI與世界的“USB-C”,模型上下文協議原理、實踐與未來
Python系列文章目錄
PyTorch系列文章目錄
機器學習系列文章目錄
深度學習系列文章目錄
Java系列文章目錄
JavaScript系列文章目錄
深度學習系列文章目錄
01-【深度學習-Day 1】為什么深度學習是未來?一探究竟AI、ML、DL關系與應用
02-【深度學習-Day 2】圖解線性代數:從標量到張量,理解深度學習的數據表示與運算
03-【深度學習-Day 3】搞懂微積分關鍵:導數、偏導數、鏈式法則與梯度詳解
04-【深度學習-Day 4】掌握深度學習的“概率”視角:基礎概念與應用解析
05-【深度學習-Day 5】Python 快速入門:深度學習的“瑞士軍刀”實戰指南
06-【深度學習-Day 6】掌握 NumPy:ndarray 創建、索引、運算與性能優化指南
07-【深度學習-Day 7】精通Pandas:從Series、DataFrame入門到數據清洗實戰
08-【深度學習-Day 8】讓數據說話:Python 可視化雙雄 Matplotlib 與 Seaborn 教程
09-【深度學習-Day 9】機器學習核心概念入門:監督、無監督與強化學習全解析
10-【深度學習-Day 10】機器學習基石:從零入門線性回歸與邏輯回歸
11-【深度學習-Day 11】Scikit-learn實戰:手把手教你完成鳶尾花分類項目
12-【深度學習-Day 12】從零認識神經網絡:感知器原理、實現與局限性深度剖析
13-【深度學習-Day 13】激活函數選型指南:一文搞懂Sigmoid、Tanh、ReLU、Softmax的核心原理與應用場景
14-【深度學習-Day 14】從零搭建你的第一個神經網絡:多層感知器(MLP)詳解
15-【深度學習-Day 15】告別“盲猜”:一文讀懂深度學習損失函數
16-【深度學習-Day 16】梯度下降法 - 如何讓模型自動變聰明?
17-【深度學習-Day 17】神經網絡的心臟:反向傳播算法全解析
文章目錄
- Langchain系列文章目錄
- Python系列文章目錄
- PyTorch系列文章目錄
- 機器學習系列文章目錄
- 深度學習系列文章目錄
- Java系列文章目錄
- JavaScript系列文章目錄
- 深度學習系列文章目錄
- 前言
- 一、為什么需要反向傳播?
- 1.1 梯度下降的回顧
- 1.2 簡單模型的梯度計算
- 1.3 深度網絡的挑戰
- 1.4 反向傳播的誕生
- 二、反向傳播的核心:鏈式法則
- 2.1 單變量鏈式法則
- 2.2 多變量鏈式法則
- 2.3 鏈式法則在神經網絡中的體現
- 2.3.1 關鍵思想:計算圖
- 三、前向傳播與反向傳播的流程
- 3.1 前向傳播 (Forward Propagation)
- (1) 流程步驟:
- (2) 目標:
- 3.2 反向傳播 (Backward Propagation)
- (1) 流程步驟:
- (2) 目標:
- 3.3 訓練循環
- 四、直觀理解:誤差如何逐層傳遞
- 4.1 誤差的源頭
- 4.2 責任的逐層分配
- 4.3 權重梯度的意義
- 五、常見問題與注意事項
- 5.1 梯度消失與梯度爆炸
- 5.2 自動求導的便利
- 5.3 理解原理的重要性
- 六、總結
前言
在上一篇文章【深度學習-Day 16】中,我們了解了梯度下降法——這個引領我們尋找損失函數最小值的強大工具。我們知道了,只要能計算出損失函數關于模型參數(權重 w w w 和偏置 b b b)的梯度,我們就能通過不斷迭代來更新參數,讓模型變得越來越好。但是,對于一個擁有成千上萬甚至數百萬參數的深度神經網絡來說,如何高效地計算這些梯度呢?手動推導顯然是不現實的。這時,神經網絡的“心臟”——反向傳播算法(Backpropagation, BP)——就登場了。它是一種能夠高效計算梯度的“魔法”,是絕大多數神經網絡訓練的基礎。本文將帶你深入探索反向傳播的奧秘。
一、為什么需要反向傳播?
1.1 梯度下降的回顧
我們知道,梯度下降的核心是更新規則:
θ = θ ? η ? θ J ( θ ) \theta = \theta - \eta \nabla_\theta J(\theta) θ=θ?η?θ?J(θ)
其中, θ \theta θ 代表模型的所有參數, J ( θ ) J(\theta) J(θ) 是損失函數, η \eta η 是學習率,而 ? θ J ( θ ) \nabla_\theta J(\theta) ?θ?J(θ) 就是損失函數對參數的梯度。關鍵就在于計算這個梯度 ? θ J ( θ ) \nabla_\theta J(\theta) ?θ?J(θ)。
1.2 簡單模型的梯度計算
對于像線性回歸或邏輯回歸這樣的簡單模型,損失函數相對直接,參數數量也不多,我們甚至可以手動推導出梯度的解析表達式。例如,對于單個樣本的均方誤差損失 J = 1 2 ( y p r e d ? y t r u e ) 2 J = \frac{1}{2}(y_{pred} - y_{true})^2 J=21?(ypred??ytrue?)2,如果 y p r e d = w x + b y_{pred} = wx + b ypred?=wx+b,計算 ? J ? w \frac{\partial J}{\partial w} ?w?J? 和 ? J ? b \frac{\partial J}{\partial b} ?b?J? 并不復雜。
1.3 深度網絡的挑戰
然而,當面對深度神經網絡時,情況變得復雜起來。
- 層級結構: 神經網絡通常包含多個隱藏層,輸出層的誤差是由前面所有層的計算共同決定的。
- 參數眾多: 一個典型的深度網絡可能有數百萬個參數。
- 計算依賴: 某一層的梯度計算,會依賴于其后一層的梯度信息。
如果對每個參數都獨立地去推導梯度表達式,計算量會極其龐大,且難以實現。想象一下,一個微小的參數變動,會像漣漪一樣擴散,影響到最終的輸出和損失。我們需要一種系統性的方法,能夠高效地計算出每個參數對最終損失的“貢獻度”,也就是梯度。
1.4 反向傳播的誕生
反向傳播算法應運而生。它并非一個全新的優化算法(優化算法是梯度下降等),而是一種計算梯度的高效方法。它巧妙地利用了微積分中的鏈式法則(Chain Rule),將最終的損失誤差從輸出層開始,逐層地“反向”傳播回輸入層,并在傳播過程中計算出每一層參數的梯度。
二、反向傳播的核心:鏈式法則
鏈式法則是理解反向傳播的關鍵。它告訴我們如何計算復合函數的導數。
2.1 單變量鏈式法則
如果 y = f ( u ) y = f(u) y=f(u) 且 u = g ( x ) u = g(x) u=g(x),那么 y y y 對 x x x 的導數可以表示為:
d y d x = d y d u ? d u d x \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} dxdy?=dudy??dxdu?
這就像一個傳遞過程: x x x 的微小變化 Δ x \Delta x Δx 導致 u u u 的變化 Δ u \Delta u Δu,進而導致 y y y 的變化 Δ y \Delta y Δy。總的變化率是兩個階段變化率的乘積。
2.2 多變量鏈式法則
在神經網絡中,情況更復雜,因為一個節點的輸出可能影響多個后續節點,或者一個節點的輸入可能來自多個前序節點。這時就需要用到多變量鏈式法則。
假設 z = f ( x , y ) z = f(x, y) z=f(x,y),而 x = g ( t ) x = g(t) x=g(t), y = h ( t ) y = h(t) y=h(t),那么 z z z 對 t t t 的導數是:
d z d t = ? z ? x ? d x d t + ? z ? y ? d y d t \frac{dz}{dt} = \frac{\partial z}{\partial x} \cdot \frac{dx}{dt} + \frac{\partial z}{\partial y} \cdot \frac{dy}{dt} dtdz?=?x?z??dtdx?+?y?z??dtdy?
這個公式告訴我們,要計算 z z z 對 t t t 的總影響,需要將 t t t 通過所有可能的路徑(這里是 t → x → z t \to x \to z t→x→z 和 t → y → z t \to y \to z t→y→z)對 z z z 產生的影響加起來。
2.3 鏈式法則在神經網絡中的體現
想象一個簡單的神經網絡,輸入 x x x,經過第一層計算得到 a ( 1 ) a^{(1)} a(1),再經過激活函數得到 h ( 1 ) h^{(1)} h(1),然后進入第二層計算得到 a ( 2 ) a^{(2)} a(2),最后得到輸出 y p r e d y_{pred} ypred?,并計算損失 J J J。
- J J J 是 y p r e d y_{pred} ypred? 的函數。
- y p r e d y_{pred} ypred? (可能是 a ( 2 ) a^{(2)} a(2) 或其激活) 是 a ( 2 ) a^{(2)} a(2) 的函數。
- a ( 2 ) a^{(2)} a(2) 是 h ( 1 ) h^{(1)} h(1) 和第二層權重 w ( 2 ) w^{(2)} w(2)、偏置 b ( 2 ) b^{(2)} b(2) 的函數。
- h ( 1 ) h^{(1)} h(1) 是 a ( 1 ) a^{(1)} a(1) 的函數(激活函數)。
- a ( 1 ) a^{(1)} a(1) 是 x x x 和第一層權重 w ( 1 ) w^{(1)} w(1)、偏置 b ( 1 ) b^{(1)} b(1) 的函數。
如果我們想計算損失 J J J 對第一層某個權重 w i j ( 1 ) w_{ij}^{(1)} wij(1)? 的梯度 ? J ? w i j ( 1 ) \frac{\partial J}{\partial w_{ij}^{(1)}} ?wij(1)??J?,就需要沿著這條計算鏈,從 J J J 開始,一層一層地往回應用鏈式法則,直到 w i j ( 1 ) w_{ij}^{(1)} wij(1)?。
2.3.1 關鍵思想:計算圖
將神經網絡的計算過程表示為一個**計算圖(Computation Graph)**會非常有幫助。在這個圖中,節點代表變量(輸入、參數、中間結果、損失),邊代表操作(加法、乘法、激活函數等)。
在計算圖中,反向傳播就是從最終節點 J J J 開始,沿著邊的反方向,利用鏈式法則計算每個節點相對于 J J J 的梯度。
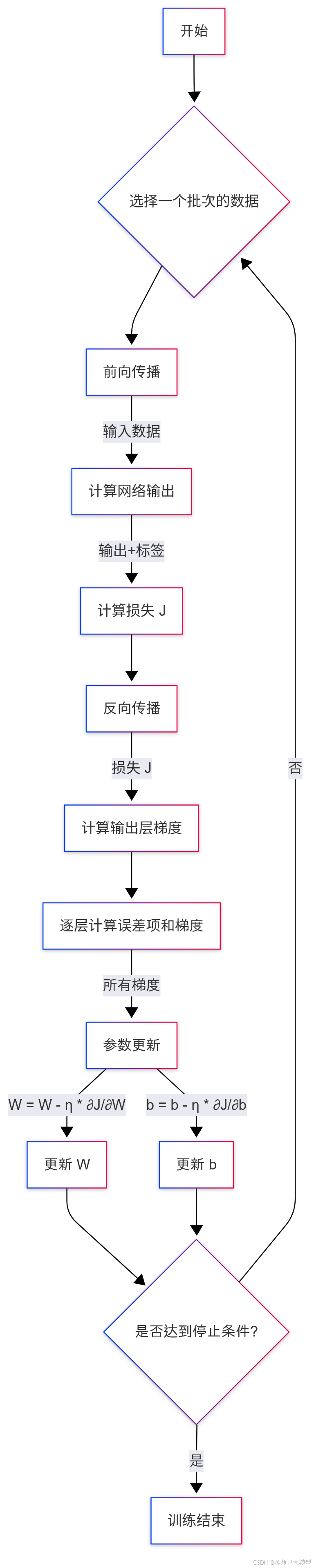
三、前向傳播與反向傳播的流程
神經網絡的訓練過程主要包含兩個階段:前向傳播和反向傳播。
3.1 前向傳播 (Forward Propagation)
這個過程我們已經比較熟悉了,它指的是數據從輸入層開始,逐層通過網絡,計算每一層的輸出,直到最終得到預測結果并計算損失。
(1) 流程步驟:
- 輸入數據: 將訓練樣本 X X X 輸入到網絡的第一層。
- 逐層計算:
- 對于第 l l l 層:
- 計算加權和: a ( l ) = W ( l ) h ( l ? 1 ) + b ( l ) a^{(l)} = W^{(l)}h^{(l-1)} + b^{(l)} a(l)=W(l)h(l?1)+b(l) (其中 h ( 0 ) = X h^{(0)} = X h(0)=X)
- 應用激活函數: h ( l ) = f ( l ) ( a ( l ) ) h^{(l)} = f^{(l)}(a^{(l)}) h(l)=f(l)(a(l))
- 對于第 l l l 層:
- 輸出結果: 最后一層(假設為 L L L 層)的輸出 h ( L ) h^{(L)} h(L) 就是模型的預測值 Y p r e d Y_{pred} Ypred?。
- 計算損失: 根據 Y p r e d Y_{pred} Ypred? 和真實標簽 Y t r u e Y_{true} Ytrue?,使用預定義的損失函數(如交叉熵或均方誤差)計算損失值 J J J。
(2) 目標:
前向傳播的目標是得到預測結果并計算出當前的損失值。這個損失值衡量了當前模型的好壞程度。
3.2 反向傳播 (Backward Propagation)
這是訓練的核心,目標是計算損失函數 J J J 對網絡中每一個參數( W W W 和 b b b)的梯度。
(1) 流程步驟:
-
計算輸出層梯度: 首先計算損失 J J J 對輸出層激活值 h ( L ) h^{(L)} h(L) 的梯度 ? J ? h ( L ) \frac{\partial J}{\partial h^{(L)}} ?h(L)?J?,以及對輸出層加權和 a ( L ) a^{(L)} a(L) 的梯度 ? J ? a ( L ) \frac{\partial J}{\partial a^{(L)}} ?a(L)?J?。這通常比較直接,因為 J J J 是 h ( L ) h^{(L)} h(L) (或 a ( L ) a^{(L)} a(L)) 的直接函數。
δ ( L ) = ? J ? a ( L ) = ? J ? h ( L ) ? ? h ( L ) ? a ( L ) = ? J ? h ( L ) ? f ′ ( L ) ( a ( L ) ) \delta^{(L)} = \frac{\partial J}{\partial a^{(L)}} = \frac{\partial J}{\partial h^{(L)}} \cdot \frac{\partial h^{(L)}}{\partial a^{(L)}} = \frac{\partial J}{\partial h^{(L)}} \cdot f'^{(L)}(a^{(L)}) δ(L)=?a(L)?J?=?h(L)?J???a(L)?h(L)?=?h(L)?J??f′(L)(a(L))
我們通常定義 δ ( l ) = ? J ? a ( l ) \delta^{(l)} = \frac{\partial J}{\partial a^{(l)}} δ(l)=?a(l)?J? 為第 l l l 層的誤差項。 -
反向逐層計算梯度: 從第 L ? 1 L-1 L?1 層開始,一直到第一層 ( l = L ? 1 , L ? 2 , . . . , 1 l = L-1, L-2, ..., 1 l=L?1,L?2,...,1):
- 計算當前層的誤差項 δ ( l ) \delta^{(l)} δ(l): 利用后一層 ( l + 1 l+1 l+1) 的誤差項 δ ( l + 1 ) \delta^{(l+1)} δ(l+1) 來計算當前層的誤差項。根據鏈式法則:
δ ( l ) = ? J ? a ( l ) = ? J ? a ( l + 1 ) ? ? a ( l + 1 ) ? h ( l ) ? ? h ( l ) ? a ( l ) = ( δ ( l + 1 ) W ( l + 1 ) ) ⊙ f ′ ( l ) ( a ( l ) ) \delta^{(l)} = \frac{\partial J}{\partial a^{(l)}} = \frac{\partial J}{\partial a^{(l+1)}} \cdot \frac{\partial a^{(l+1)}}{\partial h^{(l)}} \cdot \frac{\partial h^{(l)}}{\partial a^{(l)}} = (\delta^{(l+1)} W^{(l+1)}) \odot f'^{(l)}(a^{(l)}) δ(l)=?a(l)?J?=?a(l+1)?J???h(l)?a(l+1)???a(l)?h(l)?=(δ(l+1)W(l+1))⊙f′(l)(a(l))
其中 ⊙ \odot ⊙ 表示哈達瑪積(Hadamard product,即元素對應相乘)。這一步體現了誤差是如何從后一層傳播到前一層的。 - 計算當前層參數的梯度: 一旦有了當前層的誤差項 δ ( l ) \delta^{(l)} δ(l),就可以計算 W ( l ) W^{(l)} W(l) 和 b ( l ) b^{(l)} b(l) 的梯度了:
? J ? W ( l ) = δ ( l ) ( h ( l ? 1 ) ) T \frac{\partial J}{\partial W^{(l)}} = \delta^{(l)} (h^{(l-1)})^T ?W(l)?J?=δ(l)(h(l?1))T ? J ? b ( l ) = δ ( l ) \frac{\partial J}{\partial b^{(l)}} = \delta^{(l)} ?b(l)?J?=δ(l)
(注意:這里為了簡潔,省略了對批次求和或求平均的過程,實際實現中需要考慮)。
- 計算當前層的誤差項 δ ( l ) \delta^{(l)} δ(l): 利用后一層 ( l + 1 l+1 l+1) 的誤差項 δ ( l + 1 ) \delta^{(l+1)} δ(l+1) 來計算當前層的誤差項。根據鏈式法則:
-
梯度匯總: 收集所有層的梯度 ? J ? W ( l ) \frac{\partial J}{\partial W^{(l)}} ?W(l)?J? 和 ? J ? b ( l ) \frac{\partial J}{\partial b^{(l)}} ?b(l)?J?。
(2) 目標:
反向傳播的目標是高效地計算出所有參數的梯度,為梯度下降法的參數更新提供依據。
3.3 訓練循環
一個完整的訓練迭代(或一個批次的訓練)包括:
- 前向傳播: 計算預測值和損失。
- 反向傳播: 計算所有參數的梯度。
- 參數更新: 使用梯度下降法(或其變種)更新 W W W 和 b b b。
這個循環會重復進行,直到模型收斂或達到預設的訓練輪數。
四、直觀理解:誤差如何逐層傳遞
反向傳播不僅僅是一個數學技巧,它背后有著深刻的直觀含義。我們可以將其理解為一個責任分配的過程。
4.1 誤差的源頭
最終的損失 J J J 是衡量模型預測錯誤程度的指標。這個誤差是整個網絡共同作用的結果。反向傳播就是要弄清楚,網絡中的每一個神經元、每一個權重,對這個最終的誤差負有多大的責任。
4.2 責任的逐層分配
- 輸出層: 輸出層的神經元直接影響最終的損失,它們的責任(梯度)最容易計算。如果一個輸出神經元的激活值與真實值差距越大,它對損失的責任就越大。
- 倒數第二層: 這一層的神經元不直接影響損失,但它們通過影響輸出層來間接影響損失。一個倒數第二層的神經元 A A A 對最終損失的責任,取決于:
- 它對所有它連接到的輸出層神經元 B 1 , B 2 , . . . B_1, B_2, ... B1?,B2?,... 產生了多大的影響(即連接權重 W A B i W_{AB_i} WABi??)。
- 輸出層神經元 B 1 , B 2 , . . . B_1, B_2, ... B1?,B2?,... 各自對最終損失負有多大的責任(即 δ ( L ) \delta^{(L)} δ(L))。
- 神經元 A A A 本身的激活程度(通過激活函數的導數 f ′ f' f′ 體現,如果 f ′ f' f′ 很大,說明微小的輸入變化會導致較大的輸出變化,責任可能更大)。
- 因此, A A A 的責任是它對所有 B i B_i Bi? 的影響與其責任的加權和。這正是反向傳播公式 δ ( l ) = ( δ ( l + 1 ) W ( l + 1 ) ) ⊙ f ′ ( l ) ( a ( l ) ) \delta^{(l)} = (\delta^{(l+1)} W^{(l+1)}) \odot f'^{(l)}(a^{(l)}) δ(l)=(δ(l+1)W(l+1))⊙f′(l)(a(l)) 所表達的含義。
- 以此類推: 這個責任分配過程從輸出層開始,一層一層地向后傳遞,直到輸入層。每一層的神經元都將它所“承擔”的誤差責任,根據連接權重分配給它的前一層神經元。
4.3 權重梯度的意義
最終計算出的 ? J ? W i j ( l ) \frac{\partial J}{\partial W_{ij}^{(l)}} ?Wij(l)??J?,其直觀意義是:如果我將權重 W i j ( l ) W_{ij}^{(l)} Wij(l)? 增加一個微小的量,最終的損失 J J J 會發生多大的變化?
- 如果梯度為正,說明增加權重會增加損失,我們應該減小這個權重。
- 如果梯度為負,說明增加權重會減小損失,我們應該增大這個權重。
- 如果梯度接近零,說明這個權重對當前損失影響不大。
這正是梯度下降法更新參數的依據。反向傳播通過高效計算這些梯度,使得神經網絡能夠有效地從錯誤中學習,并調整自身,以做出更準確的預測。
五、常見問題與注意事項
5.1 梯度消失與梯度爆炸
正如我們在【Day 16】中提到的,在深層網絡中,反向傳播過程中梯度的連乘效應可能導致梯度變得極小(梯度消失)或極大(梯度爆炸),使得訓練困難。這與激活函數的選擇(如 Sigmoid 在兩端梯度接近0)和權重初始化有關。后續我們將學習 LSTM、GRU、ResNet 等結構以及 ReLU 等激活函數來緩解這些問題。
5.2 自動求導的便利
現代深度學習框架(如 TensorFlow 和 PyTorch)都內置了**自動求導(Automatic Differentiation)**功能。我們只需要定義好網絡結構(計算圖)和損失函數,框架就能自動地執行反向傳播并計算梯度,極大地簡化了開發過程。我們無需手動實現復雜的反向傳播代碼。
5.3 理解原理的重要性
盡管框架為我們做了很多工作,但深入理解反向傳播的原理仍然至關重要。它能幫助我們:
- 更好地設計網絡結構。
- 理解各種優化算法和正則化技巧的原理。
- 在模型訓練出現問題時進行診斷和調試。
- 跟進和理解最新的研究進展。
六、總結
反向傳播算法是深度學習領域一座重要的里程碑,它為訓練復雜而深層的神經網絡提供了可能。
- 核心目標: 高效計算損失函數關于網絡中所有參數的梯度。
- 核心原理: 基于微積分中的鏈式法則。
- 核心流程: 包括前向傳播(計算輸出和損失)和反向傳播(從輸出層開始,逐層計算并傳遞誤差項,進而計算梯度)。
- 直觀理解: 是一個將最終誤差責任逐層分配回網絡中每個參數的過程。
- 關鍵作用: 為梯度下降及其變種提供必要的梯度信息,驅動神經網絡的學習過程。
雖然現代框架隱藏了反向傳播的實現細節,但理解其工作機制,是我們深入掌握深度學習、成為一名優秀從業者的必經之路。在接下來的文章中,我們將學習更多優化算法,并開始接觸強大的深度學習框架,將這些理論知識付諸實踐。













)


——第一個小程序(進度條))


