1.線性方程和向量乘法
深度學習的基礎就是從線性回歸方程的理論進入的。簡單的線性回歸方程為
比如大家日常中買房子,價格受到哪些因素影響呢?
比如房齡、交通、是否是學區、有無配套超市、公園,這些基本是外部條件,內部條件諸如幾梯幾戶、層高、容積率、面積、朝向等這些,這樣一看如果使用上面的模型構建一個房屋價格預測的神經網絡模型,參數非常多這么多個參數影響了房屋的價格。所謂線性回歸(regression)是能為一個或者多個自變量與因變量之間關系建模的一類方法。回歸在數學中經常用來表示輸入和輸出之間的關系。
所以上面的房屋價格如果只考慮面積和房齡的話,預測模型就變成了
稱為偏執,或者截距;預測值所依據的自變量稱為特征或者協變量,把試圖預測的目標稱為標簽或者目標。。所以整體的預測值就可以描述為
我們用矩陣表示出來就是
向量是對于單個數據樣本特征。使用符號表示的矩陣就是
。就可以很方便的引用整個數據集的
個樣本。其中
的每一行就是一個樣本,每一列就是一種特征。對于特征集合
,預測值通過矩陣-向量乘法表示為
2.正態分布和平方損失
正態分布和線性回歸之間的關系很密切。 正態分布(normal distribution),也稱為高斯分布(Gaussian distribution), 最早由德國數學家高斯(Gauss)應用于天文學研究。 我們定義正態分布的時候,就是有一個隨機變量具有均值
和方差
(標準差
),其正態分布概率密度函數如下
在后面的方程中我們假設噪聲服從正態分布。
如果使用函數來實現
def normal(x, mu, sigma):p = 1/ math.sqrt(2 * math.pi * sigma**2)return p* np.exp(-0.5 / sigma**2 * (x-mu)**2)# 注意torch.normal定義中
torch.normal(mean: _float, std: _float, size: Sequence[Union[_int, SymInt]]...)
mean: 正態分布的均值,可以是一個數值也可以是一個張量
std: 正態分布的標準差,可以是一個數值也可以是一個張量
size:輸出隨機數的形狀,可以是一個整數用于生成size大小的一維張量;也可以是一個元組,用于生成相應形狀的多維張量3.樣本刷選
現在我們從市場上獲取了一批輸入數據,即有一批特征值。因為我們最終是尋找參數。所以雖然開始不知道最終具體的
是多少,但是可以根據經驗值填寫一個?
所以使用參數模型.其中?
作為噪聲項,服從均值為0的正態分布。這就是我們第一章節中的
import random # 導入random,用于需要隨機化初始的權重,以及隨機梯度下降
import torch
from d2l import torch as d2ldef synthetic_data(w, b, num_examples):"""生成y=xW +b+噪聲:param w::param b::param num_examples: 指定生成樣本的數量:return:"""X = torch.normal(0, 1, (num_examples, len(w))) # 生成均值為0,方差為1的,是num個樣本,列數是wy = torch.matmul(X, w) + b # Matrix Multiplication 兩個相乘y += torch.normal(0, 0.01, y.shape) # 加入一個隨機噪音,均值為0方差為1return X, y.reshape((-1, 1)) # 做成一個列向量返回📢注意:
features中的每一行都包含一個二維數據樣本,?labels中的每一行都包含一維標簽值(一個標量)?
x = torch.arange(12).reshape(2,6)print(x)y = x.reshape((-1,1))print(y)?這里還有一個就是,之前很多時候我們使用的時候都是
torch.arange(24).reshape(2,3,4)reshape的參數都是整數,但是上面的y.reshape((-1,1))是什么意思呢?
-1作為一個維度參數時,表示該維度的大小由數組的實際大小和其它維度決定。換句話說NumPy會自動計算這個維度的大小以保持數組元素總數不變。1表示新形狀中的另一個維度大小為1。因此,當你對一個數組或矩陣調用.reshape((-1, 1))時,你實際上是在告訴NumPy將原數組重塑為一個列向量(即每列只有一個元素的二維數組)。也就是說,無論輸入數組有多少個元素,結果都將是一個兩維數組,其中每個原始元素占據一行,且僅有一列。參考
x = torch.arange(12).reshape(2,6)print(x)y = x.reshape((-1,1))print(y)輸出如下所示:
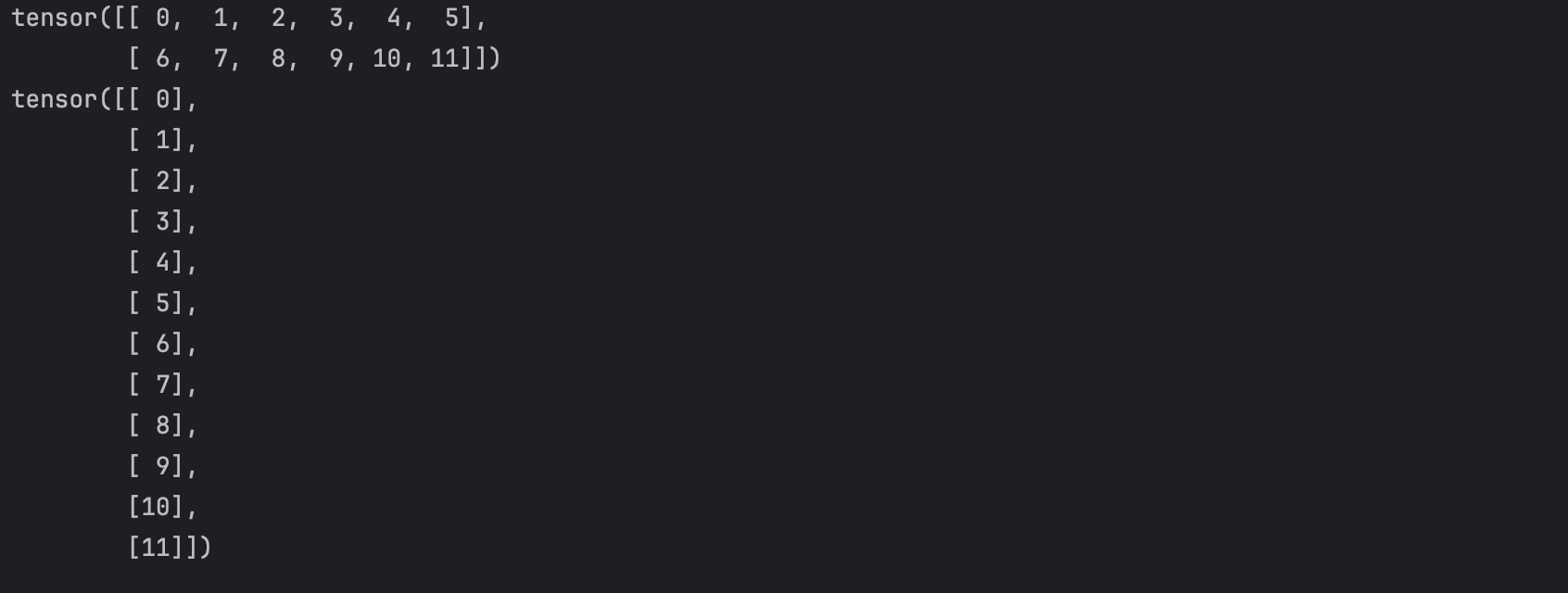
?我們調用上面的函數
true_w = torch.tensor([2, -3.4])true_b = 4.2features, labels = synthetic_data(true_w, true_b, 1000)print('output features:', features)print(f'output labels: {labels}')輸出如下所示,和上面的理解是一致的
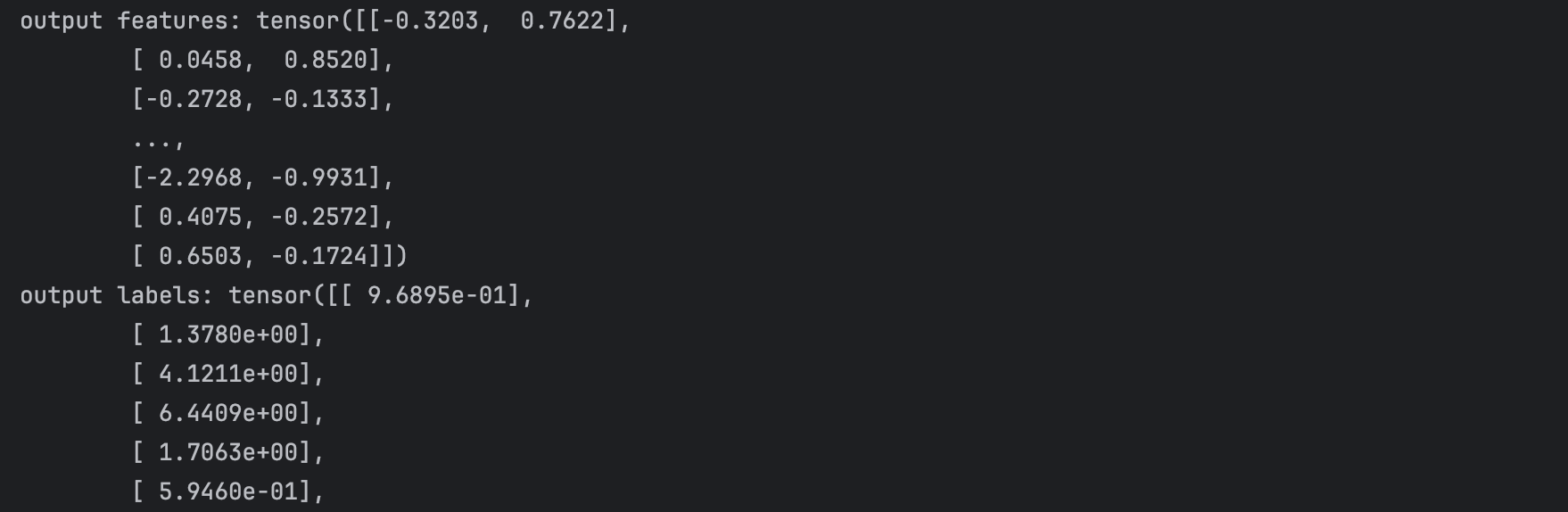
即features特征值是一個每一行都包含一個二維數組的樣本,labels即預測值每一行都包含一個一維標簽值?。
我們看看特征值和標簽之間的散點分布圖。
d2l.set_figsize()# 這里的detach是從pytorch detach出來之后才能轉到numpy中d2l.plt.scatter(features[:, 0].detach().numpy(), labels.detach().numpy(), 1);d2l.plt.show()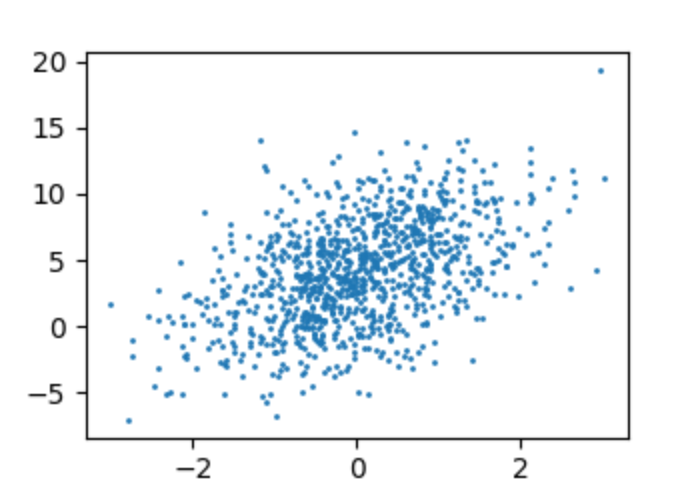
?現在我們的基礎數據已經構造完成。接下來一個重要的事情需要定義個函數,每次讀取一個小批量。
4.小批量數據構造
為什么要使用小批量,而不是使用全部的樣本呢,因為每次計算梯度需要對損失函數求導,損失函數是對我們樣本平均損失,所以求解一次梯度函數需要把所有樣本重新計算一遍,這個訓練過程太貴了,所以在神經網絡實際訓練幾乎不用全部的樣本。同樣一個神經網絡模型的訓練過程可能需要數分鐘數個小時,甚至更久。因為要計算幾百步,甚至幾千步才能求解出最終的結果。所以我們定義損失函數之后,只要能求解得到一個“差不多”的解就可以,而且在多維復雜的模型中,很少能得到準確解。所以我們損失函數就是多個采樣數據各自損失最后求平均得到最終的損失函數。所以我們采樣個樣本
來求解近似。
所以這里的采樣的個樣本,如果?
很大,則計算出的結果相對比較精確但是計算復雜度很高;如果
比較小,計算比較容易但是精確度可能會很差。畢竟梯度的計算復雜度是和樣本的個數線性相關的。
def data_iter(batch_size, features, labels):""":param batch_size::param features::param labels::return:"""num_examples = len(features)indices = list(range(num_examples))# shuffle這些樣本是隨機讀取的,沒有特定的順序random.shuffle(indices) # 把indices列表中的元素隨機打亂,這樣就可以隨機訪問for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]測試下這個函數
batch_size = 10for X, y in data_iter(batch_size, features, labels):print('小批量數據:', X, '\n', y)break?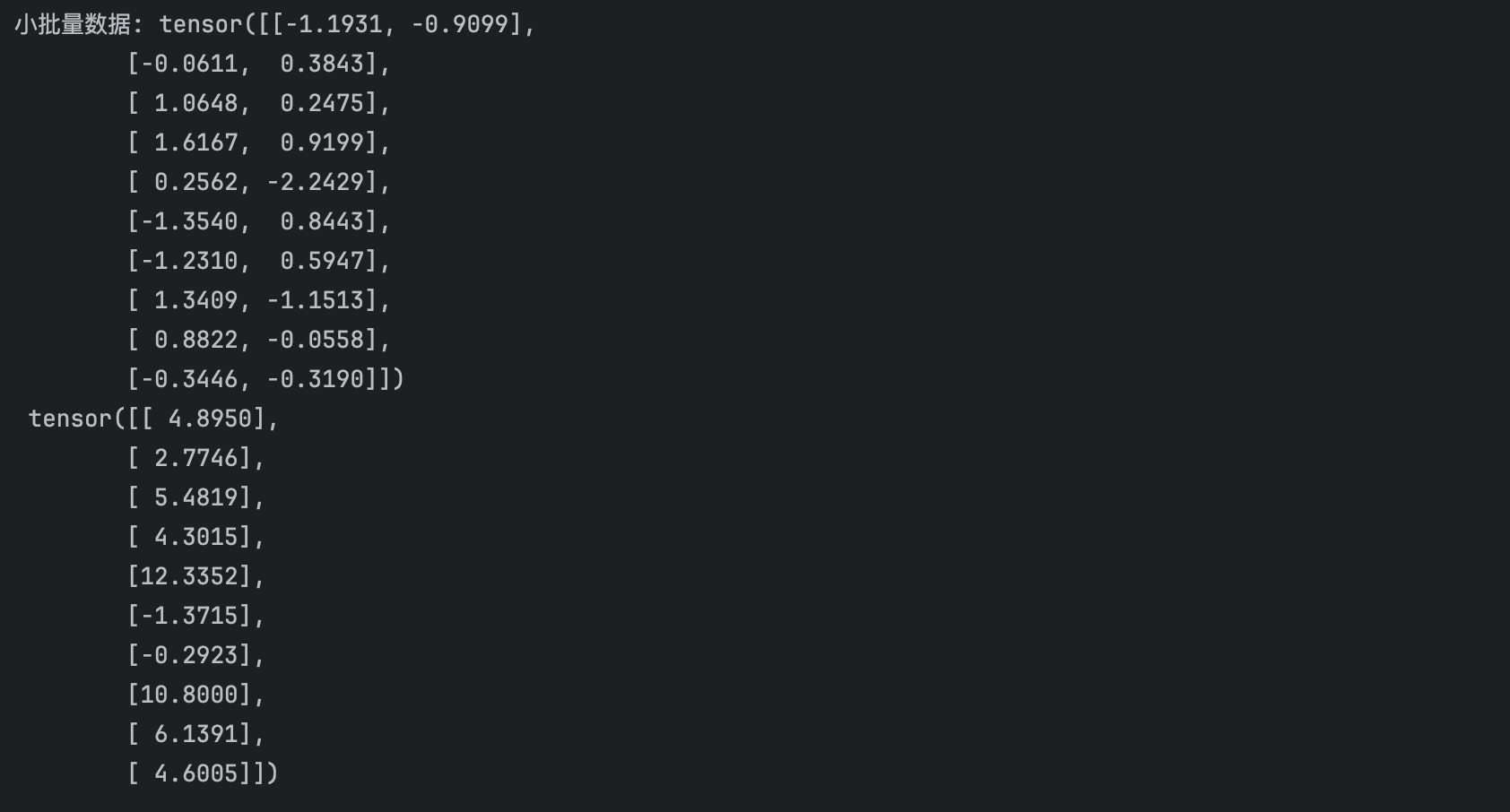
5.定義模型
def linreg(X, w, b):"""線性規劃模型:param X::param w::param b::return:"""return torch.matmul(X, w) + bw = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)這是一個均值為零,方差為0.01的正太分布函數。我們需要計算梯度requires_grad=True.對于偏差來說。我們直接給出一個0,當然也需要不斷地調整,所以需要計算梯度。
6.定義損失函數
def squared_loss(y_hat, y):"""定義損失函數,就是均方誤差:param y_hat: 預測值:param y: 真實值:return:"""# y.reshape(y_hat.shape) 確保兩者大小一樣return (y_hat - y.reshape(y_hat.shape)) **2 / 2其中是預測值,
是我們的真實值。原則上兩個個數是一樣的,但是計算中可能是一個行向量,一個是列向量。所以使用.shape函數統一下。
7.定義優化算法
def sgd(params, lr, batch_size):"""小批量隨機梯度下降:param params: params 包含了w和b:param lr:學習率:param batch_size::return:"""with torch.no_grad(): # 更新的時候不要更新梯度for param in params:param -= lr * param.grad / batch_sizeparam.grad.zero_() # 把梯度設置為0,下次計算梯度的時候就和上次不會相關了with*作用:torch.no_grad() 是一個上下文管理器(context manager),它告訴 PyTorch 在這個塊內不需要計算梯度。這意味著任何在此塊內的操作都不會被加入到自動求導圖中(即不會跟蹤這些操作以進行反向傳播),從而節省內存和計算資源。
原因:當確定某些操作(如參數更新)不需要參與梯度計算時,使用 torch.no_grad() 可以提高效率。特別是在推理階段或手動更新參數時,我們通常不需要追蹤這些操作的梯度。
將param.grad.zero_()的原因主要有:
- 將當前參數的梯度設置為零。這是因為在默認情況下,PyTorch 的反向傳播會累加梯度而不是覆蓋它們。如果不重置梯度,那么在下一次反向傳播時,新計算出的梯度會被加到舊的梯度上,導致不正確的更新。
- 為什么需要這樣做:每次參數更新后,我們應該清除之前的梯度信息,以便于下一輪迭代中正確地計算新的梯度并進行更新。
8.訓練
?現在結合上面的過程進行訓練
if __name__ == '__main__':true_w = torch.tensor([2, -3.4])true_b = 4.2features, labels = synthetic_data(true_w, true_b, 1000)# print('output features:', features)# print(f'output labels: {labels}')## d2l.set_figsize()# # 這里的detach是從pytorch detach出來之后才能轉到numpy中# d2l.plt.scatter(features[:, 0].detach().numpy(), labels.detach().numpy(), 1);## # d2l.plt.show()## # features就是自變量,輸入值;labels是標簽,這個就是因變量,輸出值batch_size = 10# for X, y in data_iter(batch_size, features, labels):# print('小批量數據:', X, '\n', y)# break# #w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)b = torch.zeros(1, requires_grad=True)# 訓練的過程lr = 0.03 # 學習率num_epochs = 3 # 把數據掃3遍net = linreg # 模型,就是我們linreg,之所以這樣寫,就是后續可以快速替換為其他模型loss = squared_loss # 均方損失for epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y)l.sum().backward() # 求和之后計算梯度sgd([w,b], lr, batch_size)with torch.no_grad():train_l = loss(net(features, w, b), labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')print(f'w的估計誤差: {true_w - w.reshape(true_w.shape)}')print(f'b的估計誤差: {true_b - b}')輸出如下所示:













)


——第一個小程序(進度條))



