文章目錄
- 說明
- 一 LLM 簡介
- 二 Transformer 架構
- 2.1 Transformer的架構組成
- 2.1.1 輸入嵌入 (Input Embedding)
- 2.1.2 編碼器 (Encoder) 的結構
- 解碼器 (Decoder) 的結構
- 2.1.3 輸出層 (Output Layer)結構
- 2.2 編碼和解碼器的獨立輸入理解
- 三 注意力機制
說明
- 本文適合初學者,大佬請路過。
一 LLM 簡介
- 大預言模型(Large Language Models、LLM)是一種由包含數百億以上參數的深度神經網絡構建的語言模型,使用自監督學習方法通過大量無標注文本進行訓練。
- GPT(GenerativePre-trainedTransformer)是一種大語言模型,是生成式人工智能的重要框架。GPT模型是基于Transformer架構的人工神經網絡,在未標記文本的大型數據集上進行預訓練,能夠生成新穎的類人內容。
- 大語言模型的應用領域非常廣泛,涵蓋機器翻譯、摘要生成、對話系統、文本自動生成等諸多領域。然而,大語言模型的使用也存在一些挑戰和問題。首先,雖然大語言模型能夠生成高度連貫和自然的文本,但沒有自我意識和理解能力。其次,大語言模型的大規模訓練數據集也使得其模型龐大而復雜,對計算資源要求較高,導致訓練和部署成本相對較高。
二 Transformer 架構
- 自然語言處理(Natural Language Processing,NLP)技術的發展是一個逐步迭代和優化的過程。Transformer的出現標志著自然語言處理進入一個新時代,特別是隨著BERT和GPT等模型的推出,大幅提升了自然語言的理解和生成能力。
- Transformer架構是一種基于注意力機制的深度學習模型,由谷歌的研究人員在2017年提出,被廣泛應用于自然語言處理任務,如機器翻譯、文本分類、情感分析等。
- 目前的聊天模型都是基于Transformer架構開發的。ChatGPT的后端是基于GPT模型的,GPT模型通過在大規模文本數據上進行無監督預訓練來學習語言的統計特征和語義。它使用自回歸的方式,即基于前面已經生成的詞來預測下一個詞,來學習詞之間的語義和語法關系,以及句子和文本的整體上下文信息。
- Transformer架構由編碼器(Encoder)和解碼器(Decoder)組成,其中編碼器用于學習輸入序列的表示,解碼器用于生成輸出序列。GPT主要采用了Transformer的解碼器部分,用于構建語言模型。
2.1 Transformer的架構組成

2.1.1 輸入嵌入 (Input Embedding)
- 在Transformer模型中,首先對輸入文本進行處理以得到合適的文本表示。因為計算機無法直接處理自然語言,它需要將我們的輸入轉換為它能理解的數學形式,換言之,他會把每個詞或字符編碼成一個特定的向量形式。
- 輸入嵌入(input Embedding):文本中的每個單詞都被轉換為一個高維向量,這個轉換通常是通過預訓練的詞嵌入模型(如Word2Vec、GloVe等)完成的。
- 位置嵌入(Positional Embedding):標準的Transformer模型沒有內置序列順序感知能力,因此需要添加位置信息。這是通過位置嵌入完成的,它與詞嵌入具有相同的維度,并且與詞嵌入相加。
- 輸入序列:模型接收一個 token 序列作為輸入,例如 “I love NLP”。
- 嵌入查找:
- 每個 token 通過查找嵌入矩陣被轉換為一個 d_model 維的向量。
- 嵌入矩陣的維度為 (vocab_size, d_model),其中 vocab_size 是詞匯表大小。
- 位置編碼添加:
- 生成與輸入序列長度相同的位置編碼矩陣,維度為 (seq_len, d_model)。
- 位置編碼與 token 嵌入逐元素相加,得到最終的輸入表示。
數學表示: X = Embedding ( i n p u t ) + PositionalEncoding X = \text{Embedding}(input) + \text{PositionalEncoding} X=Embedding(input)+PositionalEncoding
2.1.2 編碼器 (Encoder) 的結構
- 每個編碼器層包含以下子層:多頭自注意力機制 (Multi-Head Self-Attention)、前饋神經網絡 (Feed-Forward Network)
- 多頭自注意力機制 (Multi-Head Self-Attention)
-
線性變換:輸入 X 通過三個不同的線性層生成 Q (查詢)、K (鍵)、V (值) 矩陣。每個頭的維度為 d k = d m o d e l / h d_k = d_model / h dk?=dm?odel/h,其中 h 是頭數。
-
注意力計算:計算縮放點積注意力: Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk??QKT?)V。并行計算 h 個注意力頭,將結果拼接后通過線性層投影。
-
殘差連接和層歸一化: X attention = LayerNorm ( X + Attention ( X ) ) X_{\text{attention}} = \text{LayerNorm}(X + \text{Attention}(X)) Xattention?=LayerNorm(X+Attention(X))
- 前饋神經網絡 (Feed-Forward Network)
- 兩層線性變換:第一層將維度從 d_model 擴展到 d_ff (通常 2048 或 4096)。第二層將維度壓縮回 d_model。之間使用 ReLU 激活函數。
- 殘差連接和層歸一化: X out = LayerNorm ( X attention + FFN ( X attention ) ) X_{\text{out}} = \text{LayerNorm}(X_{\text{attention}} + \text{FFN}(X_{\text{attention}})) Xout?=LayerNorm(Xattention?+FFN(Xattention?))
解碼器 (Decoder) 的結構
- 每個解碼器層包含三個子層:掩碼多頭自注意力 (Masked Multi-Head Self-Attention)、編碼器-解碼器注意力 (Encoder-Decoder Attention)
- 掩碼多頭自注意力 (Masked Multi-Head Self-Attention)的掩碼機制:防止解碼器在訓練時"偷看"未來的 token;通過將未來位置的注意力分數設置為 -∞ 實現。
- 計算過程:與編碼器自注意力類似,但增加了掩碼。
- 編碼器-解碼器注意力 (Encoder-Decoder Attention):Q 來自解碼器,K 和 V 來自編碼器的最終輸出;允許解碼器關注輸入序列的相關部分。
- 前饋神經網絡:結構與編碼器中的前饋網絡相同。
2.1.3 輸出層 (Output Layer)結構
- 線性投影:將解碼器輸出投影到詞匯表大小的維度。
- Softmax 激活:生成每個 token 的概率分布。 P ( w ) = softmax ( W o X decoder + b o ) P(w) = \text{softmax}(W_o X_{\text{decoder}} + b_o) P(w)=softmax(Wo?Xdecoder?+bo?)
2.2 編碼和解碼器的獨立輸入理解
- 對于Transformer的輸入處理部分,從架構圖上編碼器和解碼器部分都有輸入,因為在Transformer模型中,編碼器(Encoder)和解碼器(Decoder)各自有獨立的輸入。通常,在有監督學習的場景下,編碼器負責處理輸入樣本,而解碼器負責處理與之對應的標簽,這些標簽在進入解碼器之前同樣需要經過適當的預處理,這樣的設置允許模型在特定任務上進行有針對性的訓練。
三 注意力機制
- 注意力機制就如字面含義一樣,就像我們生活中一樣,當開始做某一個事情時,通常會集中注意力在某些關鍵信息上,從而忽略其他不太相關的信息。對于計算機來說,transformer就是通過注意力機制解析上下文和理解不同語義之間的關系。
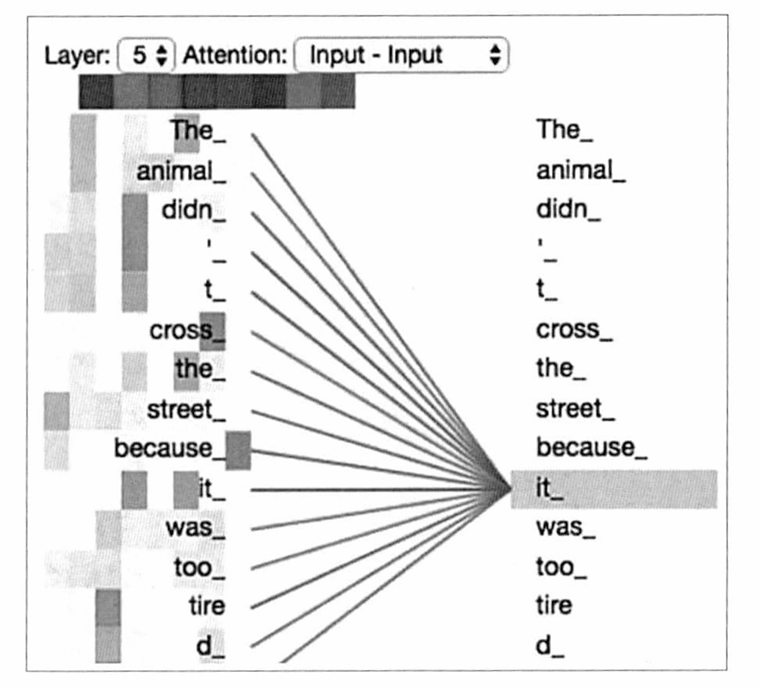
- 原始句子:The Animal didn’t cross the street because it was too tired。
- 譯為:因為動物太累了所以沒有過馬路。
-
it指代的是The Animal,然而,如果改變句子中的一個詞,將tired替換為narrow,得到的新句子是The Animal didn't cross the street because it was too narrow(由于街道太窄,動物沒有過馬路),在這個新的句子中,it指the street。因此,模型需要能夠理解當輸入的句子改變時,句子中的詞義也可能會隨之改變。這種靈活性和準確性在Transformer模型中得到了體現。 -
Attention機制的工作原理可以這樣形象化地描述:模型把每個詞編碼成一個向量,然后把這些向量送入模型中。在這里,每個詞都會像發送條“詢問”一樣,去問其他詞:“咱們之間的關系緊密嗎?”,如果關系緊密,模型就會采取一種行動,反之則會采取另一種行動。不僅每個詞都會發出這樣的“詢問”,而且也會回應其他詞的“詢問”。通過這樣的一問一答互動,模型能夠識別出每兩個詞之間的緊密關系。一旦這種關系被確定,模型就會把與該詞關系更緊密的詞的信息“吸收”進來,與其進行更多的信息融合。這樣,比如在翻譯任務中,模型就能準確地識別it應該翻譯為animal,因為它的向量已經融合了與animal這個詞緊密相關的信息。
-
所以,注意力機制的核心就是要做重構詞向量這樣一件事。對于上面形象化的描述中,可以抽取出注意力機制的三要素:
- Q:即Query,可以理解為某個單詞像其他單詞發出詢問。
- K:即Key,可以理解為某個單詞回答其他單詞的提問。
- V:即Value,可以理解為某個單詞的實際值,表示根據兩個詞之間的親密關系,決定提取出多少信息出來融入自身。
- 在 T r a n s f o r m e r Transformer Transformer模型中, Q 、 K Q、K Q、K和 V V V是通過輸入向量表示
Transformer(x)與相應的權重矩陣 W q 、 W k 、 W v W_q、W_k、W_v Wq?、Wk?、Wv?進行矩陣運算得到的。這些權重矩陣最初是通過數學方法進行初始化的,然后在模型多輪訓練的過程中逐漸更新和優化。目標是使得傳入的數據與這些權重矩陣相乘后,能夠得到最優化的Q、K和V矩陣。以Q為例,其第一個元素是通過輸入向量x的第一行與權重矩陣W的第一列進行點乘和求和運算得到的。 - 因此,在Q矩陣中的第一行實際上有這樣的意義:它包含第一個詞(與輸入x的第一行對應)在查詢其他詞時所需的關鍵信息。同樣地,K和V矩陣的計算邏輯與此相似。在K矩陣的第一行中存儲的是第一個詞在回應其他詞的查詢時所需的信息。而V矩陣的第一行所包含的是第一個詞自身攜帶的信息。在通過Q和K確定了與其他詞的關系后,這些存儲在V中的信息被用來重構該詞的詞向量。
- 在獲取到Q、K、V之后,Attention執行如下操作: Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk??QKT?)V。公式中除以 d k d_k dk?是為了避免在計算向量的內積時,因為向量矩陣過大,計算出來的數值比較大。
而非單純的因為詞之間的緊密程度這一問題。 - 計算詞的緊密程度
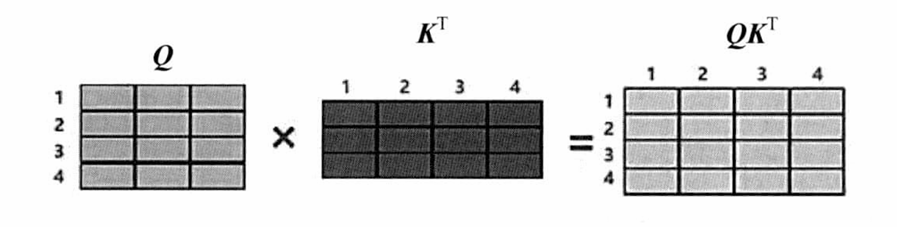
- 為什么 Q K T QK^T QKT矩陣就能表達詞與詞之間關系的緊密程度?
- 這種計算方式在數學上叫向量的內積。向量的內積在向量的幾何含義上表達的是:**內積越大,兩個向量就更趨向于平行的關系,也就表示兩個向量更加相似,當內積為0時,兩個向量就會呈現垂直的關系,表示兩個向量毫不相關。**對于Attention機制中這種Q和K一問一答的形式,問的就是兩個詞之間的緊密程度,所以可以通過內積的方式來衡量兩個詞之間的相似性。
- 在這個過程中,可能都注意到了,它對自己也進行了提問,并且自己也給出了回答,為什么要這樣做呢?
- 例如The Animal didn’t cross the street because it was too tired(因為動物太累了,所以沒有過馬路),it正常來說作為代詞,指代“它”,但在這個句子中,我們希望它指代是The Animal,所以它不把自己在這個句子中的重要性表現出來,不對自己的信息進行重構的話,它可能就沒有辦法改變自己原有的意思,也就無法從原本的意思“它”改為指代The Animal。也就是因為這種操作,所以在Transformer中的注意力機制被叫作Self-Attention(自注意力機制)。
- 當衡量句子之間的緊密關系的結果出來之后,那么如何重構V?
- 為解決如何量化決定哪些詞貢獻了多少信息。我們可以使用softmax函數對每一行進行歸一化處理,softmax操作實質上是在量化地均衡各個詞的信息貢獻度。
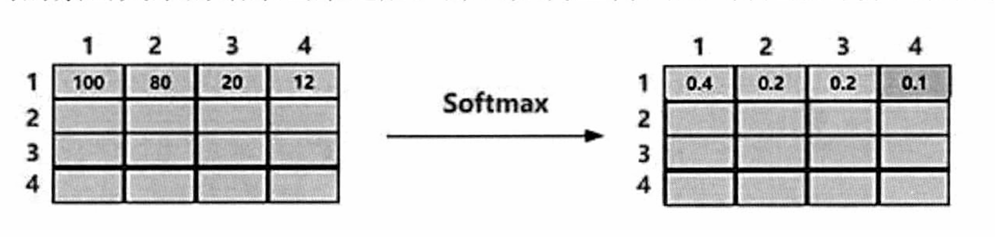
- 當得到了每個詞之間的信息貢獻度概率之后,重構V的過程轉換成計算過程。從每個詞中都會拿出部分信息,最終得到Z,通過這種計算形式得到的Z矩陣,每個位置就包含所有與之有關系的信息。這就是Transformer中自注意力機制中的計算過程。









)


——第一個小程序(進度條))







從零實現用MobileFaceNet算法進行實時人臉識別(四)安裝RKNN Toolkit Lite2)