一、HTTP1.1和HTTP2的區別
HTTP/1(主要指 HTTP/1.1)和 HTTP/2 是 Web 協議發展中的兩個重要版本,二者在性能、協議機制和功能特性上有顯著差異。以下從多個維度對比分析,并結合具體案例說明:
一、連接與請求處理方式
1. HTTP/1.1:串行請求與隊頭阻塞
特點:
- 雖支持
持久連接(Keep-Alive),但同一 TCP 連接同一時刻只能處理一個請求,請求需按順序排隊執行。- 若某個請求阻塞(如響應慢或失敗),會導致后續請求被阻塞,即隊頭阻塞(Head-of-Line Blocking)。
示例:
瀏覽器加載一個網頁,包含:
- 1 個 HTML 文件(主資源)
- 3 張圖片(image1.jpg、image2.jpg、image3.jpg)
- 1 個 CSS 文件(style.css)
- 1 個 JS 文件(script.js)
在 HTTP/1.1 中,瀏覽器需逐個發起請求:
請求順序:HTML → CSS → JS → image1 → image2 → image3 (每個請求需等待前一個響應完成,總耗時較長)2. HTTP/2:多路復用(Multiplexing)
- 特點:
- 同一 TCP 連接中可并行發送多個請求 / 響應,通過
流(Stream)和幀(Frame)機制區分不同請求。- 徹底解決隊頭阻塞問題,多個資源可同時傳輸,無需排隊。
- 示例:
同樣加載上述網頁,HTTP/2 中所有資源請求同時發起,瀏覽器通過唯一流ID標識每個請求(如:流 1=HTML,流 2=CSS,流 3=JS,流 4-6 = 圖片)。
服務器將響應數據拆分為二進制幀(如 HEADERS 幀、DATA 幀),混合傳輸后由客戶端按流 ID 重組。
總耗時大幅減少,尤其適合高延遲或帶寬受限場景。二、協議格式:文本 vs 二進制
1. HTTP/1.1:純文本格式
- 特點:
請求和響應頭部、實體均為文本格式,可讀性強但解析效率低,冗余量大。
- 例如,每次請求需重復傳輸相同頭部字段(如
Host: example.com)。2. HTTP/2:二進制分幀(Binary Framing)
- 特點:
- 將整個請求 / 響應分解為最小單位的
幀(如 HEADERS 幀、DATA 幀、SETTINGS 幀等),以二進制格式傳輸。- 解析速度更快,且幀結構可精確控制(如標記流優先級、結束流等)。
- 示例:
一個 HTTP/2 請求的 HEADERS 幀包含壓縮后的頭部數據,DATA 幀包含實體內容。客戶端收到混合的幀后,按流 ID 合并為完整的請求 / 響應。
對比:HTTP/1.1 的文本格式需逐行解析,而 HTTP/2 的二進制格式可通過位運算快速處理,提升性能。三、頭部壓縮機制
1. HTTP/1.1:無頭部壓縮
- 問題:
每次請求 / 響應的頭部字段重復傳輸(如Accept、User-Agent、Cookie等),尤其在移動端或低帶寬場景下浪費流量。2. HTTP/2:HPACK 壓縮算法
- 機制:
- 客戶端和服務器維護一個
共享的頭部字段緩存表(Header Table),首次請求時傳輸完整頭部,后續重復字段通過索引引用緩存表。- 對未緩存的字段采用
哈夫曼編碼壓縮。- 示例:
首次請求https://example.com/page1時,頭部包含:第二次請求GET /page1 HTTP/2 Host: example.com User-Agent: Chrome/115.../page2時,Host和User-Agent字段可直接引用緩存表中的索引,僅傳輸變化的字段(如GET /page2)。
效果:頭部體積可壓縮至原大小的 10%~20%,節省帶寬。四、服務器推送(Server Push)
1. HTTP/1.1:無此功能
客戶端需主動發起所有資源請求,服務器無法主動推送資源。
2. HTTP/2:主動推送關聯資源
- 機制:
服務器可根據客戶端請求,主動推送其可能需要的資源(如 CSS、JS、圖片等),避免客戶端二次請求。- 示例:
客戶端請求index.html,服務器解析 HTML 后發現需加載style.css和main.js,可通過Link頭或 API 主動推送這兩個文件:效果:客戶端無需額外請求<!-- HTML中聲明推送資源 --> <link rel="preload" href="style.css" as="style" /> <link rel="preload" href="main.js" as="script" />style.css和main.js,直接從服務器緩存中獲取,減少 RTT(往返時間)。五、優先級與流量控制
1. HTTP/1.1:無顯式優先級
資源按請求順序處理,無法指定優先級(如先加載 CSS 再加載圖片)。
2. HTTP/2:流優先級(Stream Priority)
- 機制:
客戶端可通過:priority頭部為每個流設置優先級(如權重、依賴關系),服務器根據優先級分配資源(如先處理 CSS 流,再處理圖片流)。- 示例:
加載網頁時,CSS 樣式表的優先級高于圖片,客戶端可聲明:服務器優先處理該流,確保 CSS 先加載,避免頁面渲染阻塞。:method: GET :path: /style.css :priority: weight=200, depend=0 # 權重200,無依賴流六、性能對比總結
特性 HTTP/1.1 HTTP/2 連接方式 單連接串行請求 單連接多路復用 協議格式 文本格式 二進制分幀 頭部壓縮 無 HPACK 算法 服務器推送 不支持 支持 隊頭阻塞 存在 消除 典型頁面加載耗時 1000ms(假設) 300ms(假設,多路復用 + 壓縮)
二、 TCP的重傳機制
一、TCP 可靠傳輸的基礎:序列號與確認應答(ACK)
序列號(Sequence Number)
- 每個 TCP 報文段的數據部分會被分配一個序列號,用于標識數據在字節流中的位置(如首字節序號)。
- 作用:確保接收方按順序重組數據,檢測重復或丟失的報文段。
確認應答(ACK)
- 接收方收到報文段后,會向發送方返回 ACK,其中包含 “期望接收的下一個字節的序號”(即確認號)。
- 示例:若接收方成功收到序號為?
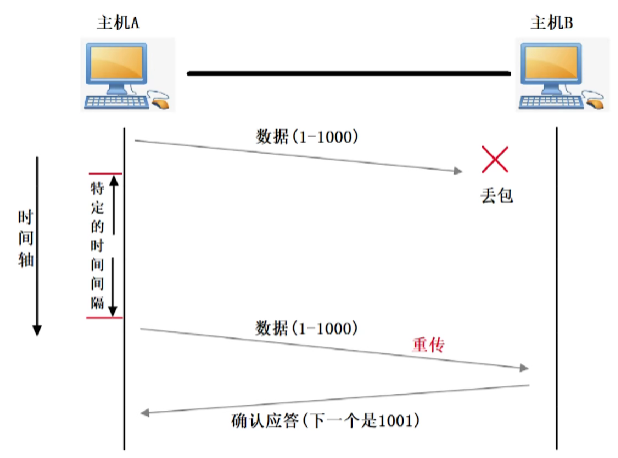
x、長度為?L?的數據,則 ACK 的確認號為?x+L,表示 “已收到?x?到?x+L-1?的數據,期望接收?x+L?開始的數據”。二、重傳機制的觸發條件
當發送方發現數據未被正確確認時,會觸發重傳。常見觸發場景包括:
?
超時未收到 ACK(超時重傳)
- 發送方為每個報文段設置?重傳超時時間(RTO,Retransmission Timeout)。
- 若超過 RTO 未收到對應 ACK,則認為報文段丟失,觸發重傳。
收到重復 ACK(快速重傳)
- 當接收方發現中間某個報文段丟失時,后續收到的報文段會觸發重復 ACK(即連續發送多個相同的確認號)。
- 發送方若收到?3 個重復 ACK(即 “累計 3 次確認號未更新”),則認為該報文段丟失,立即重傳(無需等待超時),以降低延遲。
三、重傳策略詳解
1. 超時重傳(Timeout Retransmission)
核心邏輯:
- 發送方發送數據后啟動定時器,若超時未收到 ACK,則重傳該數據。
- 首次 RTO 通常設為?初始值(如 3 秒),后續根據網絡情況動態調整。
RTO 的動態計算:
- 通過?往返時間(RTT,Round-Trip Time)?測量網絡延遲,公式如下:
- 平滑往返時間(SRTT):
SRTT = (1 - α) * SRTT + α * RTT(α 通常為 0.125)。- 偏差值(RTTVAR):
RTTVAR = (1 - β) * RTTVAR + β * |RTT - SRTT|(β 通常為 0.25)。- RTO:
RTO = SRTT + δ * RTTVAR(δ 通常為 2)。- Karn 算法:重傳時不更新 RTT,避免因重傳報文段的 ACK 無法區分原始 / 重傳報文,導致 RTT 測量誤差。
缺點:
- 超時時間較長時,重傳延遲高;
- 網絡波動可能導致 RTO 調整不及時。
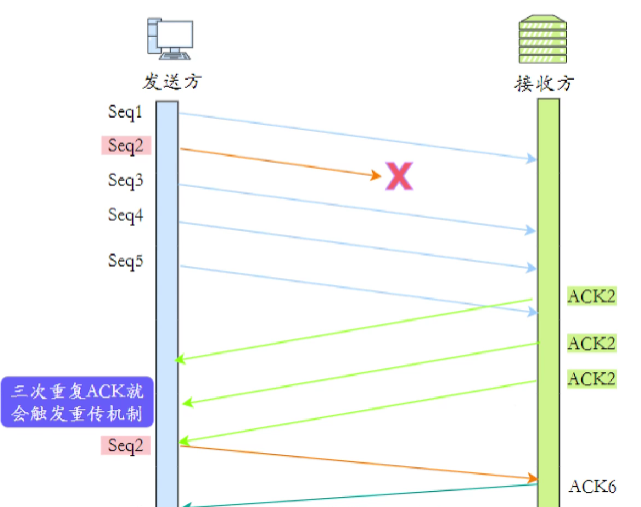
2. 快速重傳(Fast Retransmission)
核心邏輯:
- 當接收方發現數據失序時,會針對已接收的后續數據連續發送重復 ACK(確認號為失序報文段的起始序號)。
- 發送方收到?3 個重復 ACK?后,立即重傳丟失的報文段,無需等待超時。
- 示例:
- 發送方按順序發送報文段 1、2、3、4,若報文段 2 丟失:
- 接收方收到 1 后,ACK 確認號為 2;
- 收到 3 后,因 2 未到,再次 ACK 確認號為 2(重復 ACK);
- 收到 4 后,繼續 ACK 確認號為 2(累計 3 次重復 ACK);
- 發送方觸發快速重傳,立即重傳報文段 2。
優點:
- 相比超時重傳,能更快檢測到丟失,減少延遲。
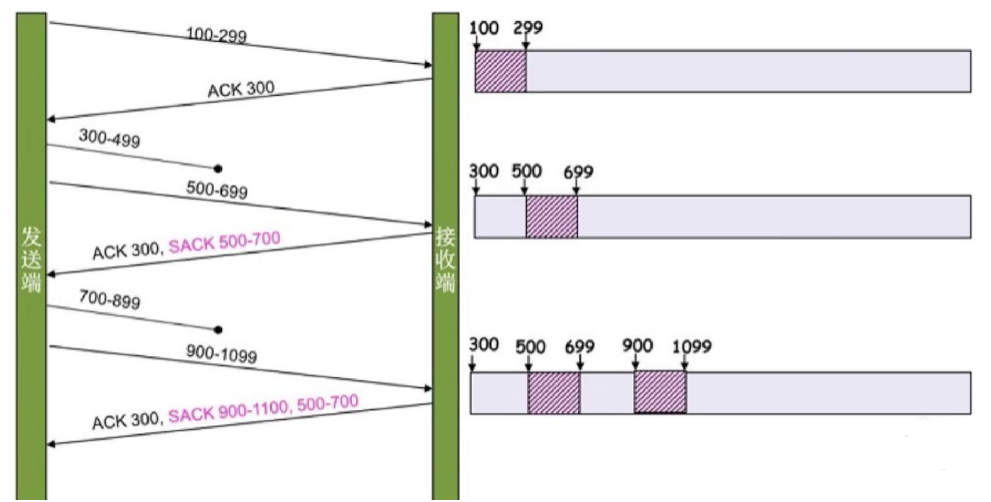
3. 選擇性重傳(Selective Retransmission,SACK)
背景:
- 傳統重傳機制會重傳?整個窗口內未確認的數據(如超時重傳),即使只有部分數據丟失,導致效率低下。
- 選擇性確認(SACK,Selective Acknowledgment)?是 TCP 的擴展選項,允許接收方告知發送方?哪些數據已正確接收,哪些數據丟失,從而僅重傳丟失的部分。
實現方式:
- 接收方在 ACK 中通過?SACK 選項?攜帶多個連續字節塊的范圍(如 “已收到 1-1000 和 2001-3000”)。
- 發送方根據 SACK 信息,僅重傳未被確認的字節塊,避免重傳已接收的數據。
前提:
- 需要雙方在 TCP 連接建立時協商啟用 SACK 選項(通過 SYN 報文段攜帶)。
四、重傳次數限制與資源釋放
重傳次數上限:
- 為避免無限重傳消耗資源,TCP 會限制最大重傳次數(如 Linux 默認值為 15 次,對應 RTO 從初始值指數級增長到約 30 分鐘)。
- 超過上限后,TCP 會斷開連接并通知應用層。
與擁塞控制的協同:
- 重傳機制與擁塞控制緊密關聯:
- 超時重傳通常觸發?擁塞避免(Congestion Avoidance)?或?慢啟動(Slow Start)?機制,降低發送速率以緩解網絡擁堵;
- 快速重傳后通常進入?快恢復(Fast Recovery)?階段,在不降低擁塞窗口的前提下調整發送策略。
三、TCP的擁塞控制
TCP 的擁塞控制是通過動態調整發送端的?擁塞窗口(Congestion Window, cwnd)?來實現的,目的是避免網絡過載導致的丟包和性能下降。其核心機制包括以下四種算法的協同工作:慢啟動(Slow Start)、擁塞避免(Congestion Avoidance)、快重傳(Fast Retransmit)?和?快恢復(Fast Recovery)。以下是詳細解析:
一、核心概念
擁塞窗口(cwnd)
發送端維護的一個狀態變量,表示當前網絡允許發送端發送的數據量上限(單位為「報文段個數」)。
- 發送端實際的發送窗口大小 = min (cwnd, 接收端通告的窗口大小)。
- cwnd 會根據網絡擁塞情況動態調整。
慢啟動閾值(ssthresh)
區分「慢啟動階段」和「擁塞避免階段」的閾值:
- 當 cwnd < ssthresh 時,處于慢啟動階段;
- 當 cwnd ≥ ssthresh 時,進入擁塞避免階段。
二、四大擁塞控制算法
1. 慢啟動(Slow Start)
- 目標:初始階段快速探測網絡可用帶寬,避免突發流量擁塞。
- 規則:
- 初始時,
cwnd = 1(單位為 MSS,最大段大小)。- 每收到一個確認(ACK),
cwnd += 1。每經過一個往返時間(RTT),cwnd 呈指數增長(如 1→2→4→8→…)。- 觸發條件:
- 新連接建立時;
- 超時重傳后(進入慢啟動階段)。
- 閾值調整:
- 當 cwnd 增長到等于 ssthresh 時,切換至「擁塞避免階段」。
- 若中途檢測到擁塞(如超時),執行:
ssthresh = max(cwnd/2, 2)(取半,最小為 2),cwnd = 1,重新進入慢啟動。2. 擁塞避免(Congestion Avoidance)
- 目標:避免網絡擁塞,使 cwnd 線性增長,穩定傳輸。
- 規則:
- 每經過一個 RTT,
cwnd += 1(線性增長,而非指數)。- 觸發條件:
- cwnd ≥ ssthresh 時自動進入。
- 閾值調整(擁塞發生時):
- 若檢測到超時(嚴重擁塞):
ssthresh = cwnd/2,cwnd = 1,回到慢啟動階段。- 若檢測到「三個重復 ACK」(輕度擁塞,見快重傳):
執行快重傳 + 快恢復算法(見下文)。3. 快重傳(Fast Retransmit)
- 目標:盡早檢測到單個報文段丟失,避免不必要的超時等待。
- 觸發條件:
- 接收端收到失序報文段時,重復發送前一個正確報文段的 ACK。
- 當發送端收到?3 個重復 ACK?時,判定為「丟包」,立即重傳丟失的報文段,無需等待超時。
- 操作:
- 重傳丟失的報文段;
- 進入「快恢復階段」,不執行慢啟動。
4. 快恢復(Fast Recovery)
- 目標:在輕度擁塞(三個重復 ACK)時,快速恢復傳輸,避免過度降低 cwnd。
- 規則:
ssthresh = cwnd/2(設置新的閾值);cwnd = ssthresh + 3(假設丟失的報文段已被接收端緩存,允許發送 3 個新報文段);- 每收到一個重復 ACK,
cwnd += 1(線性增加,快速恢復);- 當收到丟失報文段的 ACK 時,
cwnd = ssthresh,進入「擁塞避免階段」。- 與慢啟動的區別:
- 不將 cwnd 重置為 1,而是基于當前閾值快速恢復,減少吞吐量波動。
三、關鍵對比
場景 處理方式 cwnd 調整 ssthresh 調整 新連接 / 超時重傳 慢啟動 重置為 1 設為 cwnd/2 三個重復 ACK 快重傳 + 快恢復 設為 ssthresh + 3 設為 cwnd/2 擁塞避免階段正常傳輸 線性增長 cwnd cwnd += 1(每 RTT) 不變
?四、TCP的流量控制
TCP 的流量控制(Flow Control)是通過?滑動窗口機制(Sliding Window)?實現的,主要用于解決?發送方發送速率過快,導致接收方處理不及而丟包?的問題。其核心思想是:接收方根據自身接收能力,動態通知發送方調整發送窗口大小,從而控制數據傳輸速率。以下是詳細解析:
一、核心機制:滑動窗口(Sliding Window)
1.?基本概念
- 接收窗口(Receiver Window, rwnd):
接收方在?ACK 報文?中通告給發送方的?可用接收緩沖區大小,表示接收方當前能接收的數據量。
- 單位:字節(Byte)。
- 范圍:
0 ≤ rwnd ≤ 接收緩沖區大小。- 發送窗口(Send Window, swnd):
發送方根據接收方通告的?rwnd?維護的?允許發送的數據范圍,實際大小由?rwnd?決定(可能受擁塞窗口限制,此處先不考慮擁塞控制)。2.?窗口滑動過程
發送方維護以下四個指針(以字節為單位)
[已發送并確認] <--- [已發送未確認] <--- [未發送但可發送] <--- [未發送且不可發送]^左邊界 ^右邊界 ^發送窗口右邊界 ^數據末尾
- 已發送并確認:數據已被接收方確認,可從緩沖區刪除。
- 已發送未確認:數據已發送但未收到確認,處于窗口內。
- 未發送但可發送:未超出發送窗口,可直接發送。
- 未發送且不可發送:超出發送窗口,需等待窗口滑動后才能發送。
窗口滑動條件:
- 當?已發送未確認的數據被確認?時,左邊界右移,窗口滑動,釋放空間允許發送新數據。
- 當?接收方通告新的 rwnd?時,右邊界可能擴大或縮小,調整發送窗口大小。
二、流量控制的具體實現
1.?接收方通告窗口大小(Window Advertisement)
- 接收方在?ACK 報文?的?窗口字段(Window Field)?中告訴發送方當前可用的接收緩沖區大小(
rwnd)。- 發送方根據?
rwnd?更新發送窗口?swnd,公式為:
swnd = min(rwnd, 擁塞窗口 cwnd)
(此處先忽略擁塞窗口?cwnd,假設僅受流量控制影響,則?swnd = rwnd)。2.?動態調整窗口大小
- 窗口擴大:接收方處理完數據,釋放接收緩沖區后,通過增大?
rwnd?通知發送方可以發送更多數據。- 窗口縮小:接收方緩沖區快滿時,通過減小?
rwnd?通知發送方降低發送速率。- 零窗口(Zero Window):當接收緩沖區已滿時,接收方將?
rwnd?設為?0,發送方停止發送數據,進入?窗口關閉狀態。3.?零窗口與窗口探測(Zero Window Probe)
- 問題:當接收方通告?
rwnd=0?后,發送方停止發送數據。若接收方后續釋放了緩沖區,但未及時通知發送方,會導致雙方僵持(死鎖)。- 解決方案:
- 發送方啟動?零窗口定時器(Zero Window Timer),超時后發送一個?探測報文段(僅含 1 字節數據),詢問接收方當前?
rwnd。- 接收方收到探測報文后,回復新的?
rwnd,若仍為?0,則重新開啟定時器;若?rwnd>0,則發送方恢復數據發送。三、流量控制與擁塞控制的區別
維度 流量控制 擁塞控制 目標 防止接收方緩沖區溢出(點對點控制) 防止網絡擁塞(全局網絡負載控制) 控制方 接收方(通過? rwnd?通告)發送方(根據網絡狀態動態調整) 機制 滑動窗口(基于接收方能力) 慢啟動、擁塞避免、快重傳、快恢復等 作用范圍 發送方與接收方之間 所有網絡主機(端到端) 四、示例:流量控制過程
初始狀態:
- 接收方緩沖區大小為?
1000?字節,初始?rwnd=1000,發送方?swnd=1000,發送?500?字節數據。- 此時,接收方緩沖區剩余?
500?字節,回復?ACK?并通告?rwnd=500,發送方將?swnd?調整為?500。窗口縮小:
- 接收方處理緩慢,緩沖區剩余?
200?字節,回復?ACK?并通告?rwnd=200,發送方?swnd?調整為?200,僅允許發送?200?字節新數據。零窗口:
- 接收方緩沖區滿,通告?
rwnd=0,發送方停止發送,啟動零窗口定時器。- 定時器超時后,發送方發送探測報文,接收方處理數據后釋放緩沖區,通告?
rwnd=300,發送方恢復發送。
五、TCP 連接建立、狀態管理及銷毀的完整過程
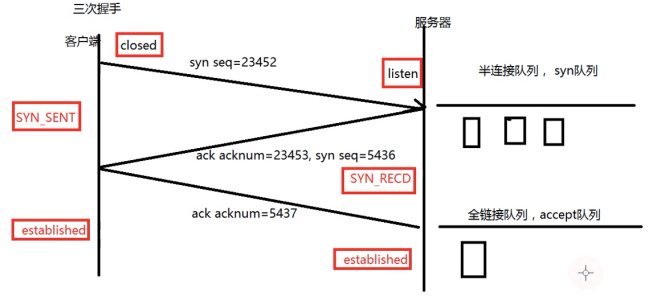
?????????在 TCP 連接建立過程中,當客戶端發起第一次握手,SYN 包到達服務器時,服務器會創建 TCB(TCP Control Block)并將該連接放入半連接隊列(SYN 隊列)。此時,連接處于未完全建立狀態。待客戶端發送 ACK 完成第三次握手,服務器會把連接從半連接隊列移至全連接隊列(accept 隊列),同時將 TCB 標記為 ESTABLISHED 狀態,意味著連接已成功建立。這里需要注意,連接進入全連接隊列時狀態就已變為 ESTABLISHED,而非在 accept () 調用之后。accept () 函數的作用是從全連接隊列中取出連接,將 TCB 與應用層 socket 關聯,分配 fd 和文件結構體,把已建立的連接交付給應用層。即使應用程序未調用 accept (),全連接隊列中的連接依然維持 ESTABLISHED 狀態,直到隊列滿時會觸發 SYN 重傳或拒絕新連接。在 Linux 系統中,半連接隊列和全連接隊列的大小可分別通過 net.ipv4.tcp_max_syn_backlog 和 somaxconn 參數進行配置。當連接斷開,如完成四次揮手,主動關閉方會進入 TIME_WAIT 狀態,此時 TCB 不會立即銷毀,而是會保留一段時間(默認 60 秒,可配置),以避免舊數據包對新連接造成干擾。
六、TCP連接狀態如何變化
TCP 連接管理通過有限狀態機(FSM)實現,共有11 種狀態,涵蓋連接建立、數據傳輸、連接關閉的完整生命周期。以下是各狀態的詳細說明及狀態轉換流程:
一、TCP 連接的 11 種狀態
1. CLOSED(關閉狀態)
- 描述:虛擬初始狀態,表示無連接或連接已關閉。
- 轉換:
- 客戶端主動發起連接時,從
CLOSED→SYN_SENT。- 服務端被動監聽時,從
CLOSED→LISTEN。2. LISTEN(監聽狀態)
- 描述:服務端等待客戶端連接請求。
- 觸發條件:服務端調用
listen()后進入此狀態。- 轉換:
- 收到客戶端
SYN包,發送SYN+ACK→SYN_RCVD。- 主動關閉連接→
CLOSED。3. SYN_SENT(同步已發送狀態)
- 描述:客戶端已發送
SYN包,等待服務端確認。- 觸發條件:客戶端調用
connect()后發送SYN。- 轉換:
- 收到服務端
SYN+ACK→ESTABLISHED(三次握手完成)。- 超時未收到回復→重發
SYN,若多次失敗→CLOSED。4. SYN_RCVD(同步已接收狀態)
- 描述:服務端已收到客戶端
SYN,并回復SYN+ACK,等待客戶端確認。- 觸發條件:服務端收到
SYN后發送SYN+ACK。- 轉換:
- 收到客戶端
ACK→ESTABLISHED。- 超時未收到
ACK→重發SYN+ACK,失敗則→CLOSED。5. ESTABLISHED(已建立連接狀態)
- 描述:連接已建立,雙方可雙向傳輸數據。
- 觸發條件:三次握手完成(客戶端和服務端均進入此狀態)。
- 轉換:
- 主動關閉連接(發送
FIN)→FIN_WAIT_1(客戶端)或CLOSE_WAIT(服務端)。- 被動關閉連接(收到對方
FIN)→CLOSE_WAIT(客戶端)或LAST_ACK(服務端)。6. FIN_WAIT_1(終止等待 1 狀態)
- 描述:主動關閉方(如客戶端)已發送
FIN,等待對方確認。- 觸發條件:主動關閉方調用
close()或shutdown()發送FIN。- 轉換:
- 收到對方
ACK→FIN_WAIT_2。- 收到對方
FIN+ACK→直接處理FIN→TIME_WAIT(跳過FIN_WAIT_2)。7. FIN_WAIT_2(終止等待 2 狀態)
- 描述:主動關閉方已收到對方
ACK,等待對方發送FIN。- 觸發條件:從
FIN_WAIT_1收到ACK后進入。- 轉換:
- 收到對方
FIN→發送ACK→TIME_WAIT。- 對方長期不關閉→可能保持此狀態直到超時(需系統配置支持)。
8. CLOSE_WAIT(關閉等待狀態)
- 描述:被動關閉方(如服務端)收到
FIN,但尚未發送自身FIN,需處理剩余數據。- 觸發條件:被動關閉方收到
FIN后回復ACK,進入此狀態。- 轉換:
- 處理完數據后,主動發送
FIN→LAST_ACK。- 若直接關閉(未發送
FIN)→可能導致連接泄漏,需程序主動調用close()。9. LAST_ACK(最后確認狀態)
- 描述:被動關閉方已發送
FIN,等待主動關閉方的ACK。- 觸發條件:被動關閉方發送
FIN后進入此狀態。- 轉換:
- 收到
ACK→CLOSED。- 超時未收到
ACK→重發FIN,失敗則→CLOSED。10. TIME_WAIT(時間等待狀態)
- 描述:主動關閉方在發送
ACK后等待一段時間(2 倍 MSL),確保連接安全關閉。- 觸發條件:主動關閉方在
FIN_WAIT_2收到FIN并回復ACK后進入。- 作用:
- 防止最后一個
ACK丟失,導致對方重發FIN時可重新響應。- 避免舊連接的數據包混入新連接(MSL 為最大段生存時間)。
- 轉換:
- 等待超時(2MSL)→
CLOSED。- 收到重發的
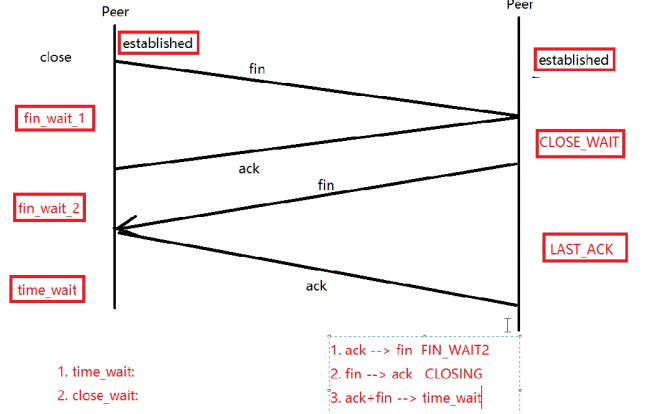
FIN→重新回復ACK并重置超時。11. CLOSING(關閉中間狀態)
- 描述:罕見狀態,雙方同時主動關閉時可能出現(雙方同時發送
FIN)。- 觸發條件:雙方同時從
ESTABLISHED發送FIN,各自進入FIN_WAIT_1,收到對方FIN后→CLOSING。- 轉換:
- 發送
ACK并收到對方ACK→TIME_WAIT。
七、TCP如何保證可靠傳輸的
TCP(傳輸控制協議)通過多種機制確保數據的可靠傳輸,核心思路是確認應答、重傳機制、流量控制、擁塞控制、順序控制等。以下是具體實現方式:
1. 序列號(Sequence Number)與確認應答(ACK)
作用
- 唯一標識數據字節:每個字節的數據都有唯一的序列號(32 位),用于標記數據順序,解決網絡中數據亂序問題。
- 確認應答機制:接收方收到數據后,通過確認號(ACK Number)告知發送方已成功接收的數據的下一個字節的序列號,表示該序列號之前的數據均已正確接收。
示例
- 發送方發送序列號為?
1000、長度為?200?的數據(即字節范圍?1000~1199),接收方收到后,返回?ACK=1200,表示?1200?之前的數據(1000~1199)已確認接收。- 發送方通過未確認的序列號判斷哪些數據需要重傳。
2. 重傳機制(Retransmission)
作用
- 當數據丟失或確認超時,發送方重新傳輸數據,確保數據最終到達。
實現方式
超時重傳(Timeout Retransmission)
- 發送方發送數據時啟動定時器,若超時未收到對應?
ACK,則重傳數據。- 定時器初始值由?RTT(往返時間)?估算得出,超時時間會動態調整(如?Karn 算法?避免重傳時的 RTT 計算誤差)。
快速重傳(Fast Retransmission)
- 接收方發現數據失序時,立即發送重復確認(Dup ACK)(指向最后一個正確接收的連續序列號)。
- 發送方若收到?3 個相同的 Dup ACK,判斷為數據包丟失,立即重傳對應的數據包,無需等待超時(減少延遲)。
3. 流量控制(Flow Control)
作用
- 通過 ** 滑動窗口(Sliding Window)** 機制,讓發送方的發送速率匹配接收方的處理能力,避免接收方緩沖區溢出。
實現方式
- 接收窗口(rwnd):接收方在?
ACK?中攜帶自己當前的接收緩沖區剩余大小(即允許發送方發送的數據量)。- 發送方根據?
rwnd?調整發送窗口,確保發送的數據不超過接收方的處理能力。- 若?
rwnd=0,發送方暫停發送,直到接收方通過?ACK?通知窗口更新(如?TCP Keepalive?機制防止死鎖)。4. 擁塞控制(Congestion Control)
作用
- 避免網絡中數據流量過大導致擁塞(如路由器隊列溢出、丟包率上升),實現全局網絡穩定性。
核心算法
慢啟動(Slow Start)
- 初始時,發送方以 **1 個 MSS(最大段大小)** 為窗口大小,每收到一次?
ACK?就將窗口大小翻倍(指數增長),快速探測網絡容量。- 當窗口大小超過慢啟動閾值(ssthresh)時,進入擁塞避免階段。
擁塞避免(Congestion Avoidance)
- 窗口大小線性增長(每輪往返時間增加 1 個 MSS),避免網絡過載。
- 若檢測到丟包(如超時或 3 次 Dup ACK),觸發擁塞處理。
快重傳(Fast Retransmit)與快恢復(Fast Recovery)
- 若通過 3 次 Dup ACK 檢測到丟包,執行快重傳,并將?
ssthresh?設為當前窗口的一半,進入快恢復階段(窗口大小線性減少,而非重置為 1),繼續線性增長以快速恢復傳輸。- 若通過超時檢測到丟包,視為嚴重擁塞,
ssthresh?設為當前窗口的一半,窗口重置為 1,重新進入慢啟動。5. 校驗和(Checksum)
- 作用:檢測數據在傳輸過程中是否損壞或篡改。
- 實現方式:發送方在頭部計算偽首部 + 數據的校驗和,接收方進行校驗。若校驗失敗,直接丟棄數據包,不返回?
ACK,觸發發送方重傳。6. 順序控制與重復數據刪除
- 順序控制:接收方通過序列號對數據排序,將失序的數據暫存于緩沖區,等待缺失的數據包到達后按順序交付應用層。
- 重復數據刪除:若收到重復序列號的數據包,直接丟棄并返回相同的?
ACK,避免重復處理。7. 連接管理(三次握手與四次揮手)
- 三次握手:確保雙方初始序列號同步,建立可靠連接,避免歷史連接干擾。
- 四次揮手:確保雙方數據完全傳輸完畢后斷開連接,釋放資源(如?
TIME_WAIT?狀態防止最后一個?ACK?丟失導致的連接異常)。總結:可靠傳輸的核心機制
機制 作用描述 序列號 / 確認號 標記數據順序,確認應答確保數據到達 重傳機制 超時重傳和快速重傳處理丟包 流量控制 端到端控制發送速率,避免接收方緩沖區溢出 擁塞控制 全局控制發送速率,避免網絡擁塞 校驗和 檢測數據損壞,丟棄錯誤包 順序與重復控制 排序數據、去重,確保按序交付 連接管理 可靠建立和釋放連接,同步狀態
八、DNS域名解析的過程
DNS(域名系統)域名解析是將人類易讀的域名(如www.example.com)轉換為計算機可識別的 IP 地址的過程。這一過程涉及多級域名服務器的協同工作,通常分為遞歸查詢和迭代查詢兩個階段。以下是詳細解析過程:
一、初始請求:客戶端發起查詢
本地緩存檢查
當用戶在瀏覽器輸入域名(如www.baidu.com)時,操作系統會首先檢查本地 DNS 緩存(包括瀏覽器緩存、系統緩存)。若緩存中有該域名對應的 IP 地址,直接返回結果,解析過程結束。
- 瀏覽器緩存:瀏覽器會存儲近期解析過的域名記錄(存活時間由 DNS 響應中的 TTL 字段決定)。
- 系統緩存:操作系統(如 Windows 的
nscd、Linux 的systemd-resolved)也會緩存 DNS 結果,減少重復查詢。本地 DNS 服務器(遞歸解析器)
若本地緩存中無記錄,客戶端會向本地 DNS 服務器(通常由 ISP 提供,或手動設置為公共 DNS 如 114.114.114.114)發送遞歸查詢請求。
- 遞歸查詢的特點:本地 DNS 服務器需負責全程查詢,直到返回最終結果或失敗。
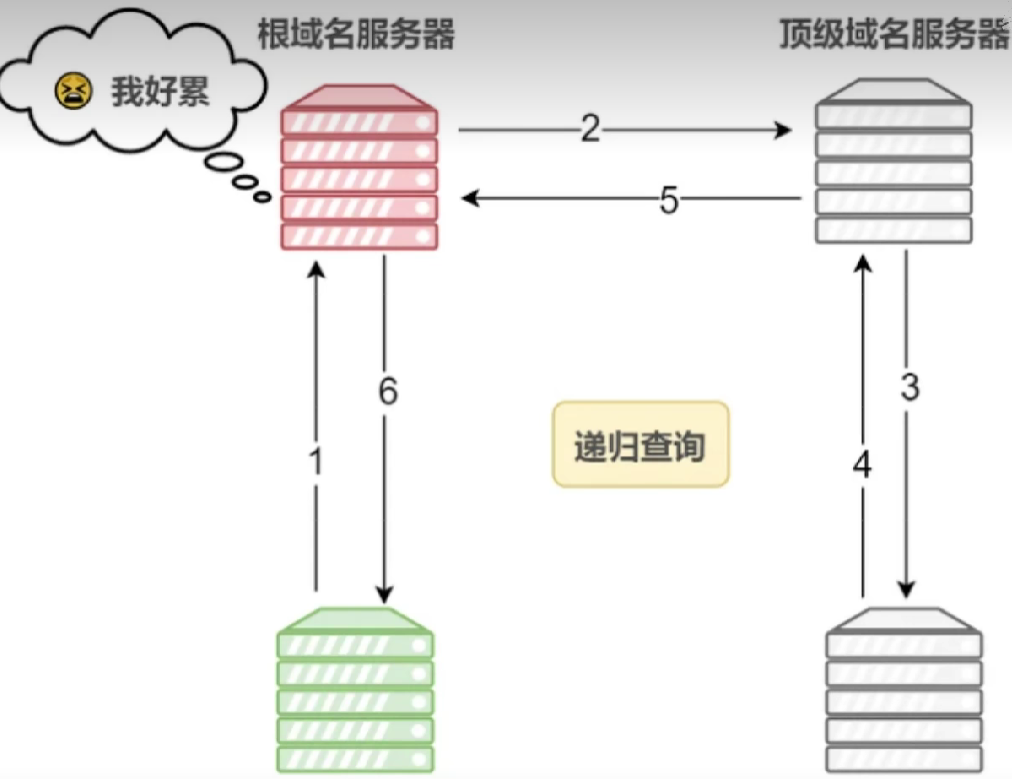
二、遞歸查詢:本地 DNS 服務器的迭代查詢過程
本地 DNS 服務器若未緩存目標域名,需通過迭代查詢向上級域名服務器逐步獲取信息,流程如下:
1. 根域名服務器(Root DNS Server)
本地 DNS 服務器首先向根域名服務器發起查詢。根服務器負責管理頂級域名(如.com、.cn 等)的解析權,返回對應 ** 頂級域名服務器(TLD Server)** 的地址。
?
- 根服務器全球共 13 組(A~M),通過任播技術分布在全球各地。
- 示例:查詢
www.baidu.com時,根服務器會返回.com頂級域名服務器的地址。2. 頂級域名服務器(TLD Server)
本地 DNS 服務器根據根服務器返回的地址,向 **.com頂級域名服務器查詢。TLD 服務器負責管理該頂級域名下的所有二級域名(如baidu.com),返回對應權威域名服務器(Authoritative Server)** 的地址。
?
- 示例:.com TLD 服務器會返回
baidu.com的權威服務器地址(如ns1.baidu.com)。3. 權威域名服務器(Authoritative Server)
本地 DNS 服務器向權威域名服務器發起最終查詢。權威服務器是域名所有者配置的服務器,存儲該域名的具體解析記錄(如 A 記錄、AAAA 記錄),直接返回域名對應的 IP 地址。
?
- 示例:
baidu.com的權威服務器會返回www.baidu.com的 IP 地址(如 14.215.177.38)。三、結果返回與緩存
響應回傳
權威服務器將 IP 地址返回給本地 DNS 服務器,后者再將結果回傳給客戶端。客戶端收到 IP 地址后,即可與目標服務器建立連接(如 HTTP 請求)。緩存記錄
- 本地 DNS 服務器會緩存解析結果,供后續其他客戶端查詢使用。
- 客戶端也會將結果存入本地緩存,緩存時間由 DNS 響應中的TTL(生存時間)字段控制(如 TTL=3600 秒表示緩存 1 小時)。
關鍵概念補充
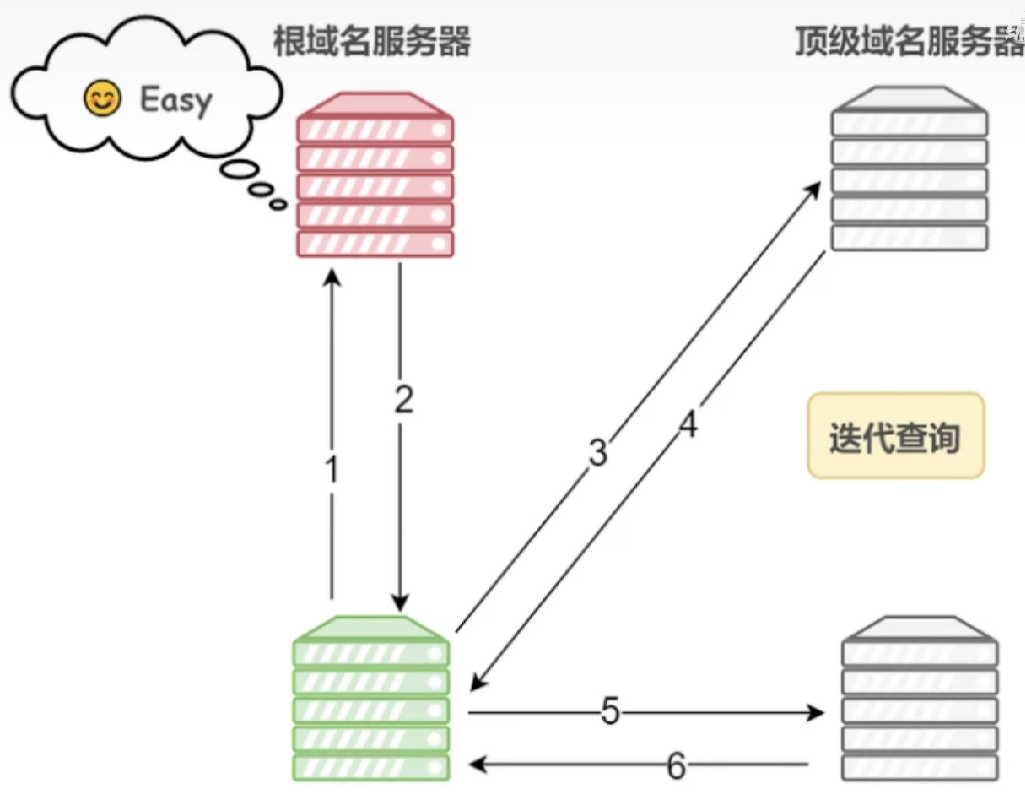
遞歸查詢 vs. 迭代查詢
- 遞歸查詢:客戶端只需向本地 DNS 服務器發起一次請求,服務器全程負責查詢(“代勞到底”)。
- 迭代查詢:本地 DNS 服務器逐次向根→TLD→權威服務器查詢,每次獲取下一步地址(“逐步問路”)。
DNS 協議細節
- 使用UDP 協議(端口 53),因查詢數據量小,UDP 效率更高;若響應超時,可能 fallback 到 TCP。
- 支持DNSSEC(域名系統安全擴展),通過數字簽名防止 DNS 欺騙(DNS 污染)。
現代擴展技術
- DNS over HTTPS(DoH)/ DNS over TLS(DoT):加密 DNS 查詢,避免中間人攻擊,常用于瀏覽器(如 Chrome、Firefox)。
- 任播(Anycast):根服務器和部分公共 DNS 通過任播技術,讓客戶端就近連接最近的節點,提升響應速度。
九、生動講解HTTPS加密過程
我們以「用戶訪問招商銀行官網(
cmbchina.com)并登錄」為例,全程模擬 HTTPS 加密過程,每個步驟都對應具體的操作和數據,讓你像看電影一樣理解整個流程:場景設定
- 你:坐在電腦前的用戶,打開瀏覽器輸入?
https://cmbchina.com- 招商銀行服務器:真正的銀行服務器,持有合法數字證書
- 黑客小明:躲在中間試圖竊聽或篡改通信(假設存在,但最終失敗)
一、客戶端發起連接:你「敲門」問安全能力(TLS 握手第 1 步)
你的瀏覽器動作:
??
- 發送一個「Hello 請求」給招商銀行服務器,內容包括:
- 隨機數 A:
20250521_abc123(好比你隨手寫的一串亂碼)- 支持的加密算法:[ECDHE-RSA-AES256-GCM-SHA384, RSA-AES256-CBC-SHA]
- TLS 版本:TLS 1.3(最新安全版本)
類比:你隔著門喊:“我帶了 AES256 和 RSA 兩種密碼本,用 TLS 1.3 協議聊,這是我的亂碼片段 A!”黑客小明的動作:試圖攔截這個請求,但此時還沒加密,內容可見,但他不知道接下來會發生什么。
二、服務器驗證身份:銀行「出示身份證」(TLS 握手第 2-3 步)
招商銀行服務器動作:
回復「Hello 響應」,內容包括:
- 選擇加密算法:ECDHE-RSA-AES256-GCM-SHA384(選了你支持的最強算法)
- 隨機數 B:
server_20250521_def456(服務器的亂碼片段)- 數字證書:
- 證書內容:
- 域名:
cmbchina.com(必須和你訪問的域名一致)- 公鑰:
-----BEGIN PUBLIC KEY-----...(服務器的公鑰,用于加密數據)- 有效期:2024.01.01 - 2026.12.31(未過期)
- CA 簽名:由 DigiCert(知名 CA 機構)用私鑰簽名的哈希值
- 比喻:服務器遞給你一張 “身份證”,上面有銀行照片(域名)、有效期、公安局蓋章(CA 簽名)。
你驗證證書真偽(瀏覽器自動完成):
- 檢查域名:確認證書里的域名是
cmbchina.com,不是cmbchina-fake.com。- 檢查有效期:當前時間是 2025 年 5 月,證書未過期。
- 用 DigiCert 的公鑰(瀏覽器內置根 CA 公鑰)解密證書中的「數字簽名」,對比證書內容的哈希值是否一致(確保證書沒被篡改)。
如果證書有問題:比如黑客偽造了一個cmbchina.com的證書,但沒有 DigiCert 的私鑰,簽名驗證失敗,瀏覽器會彈出 “不安全” 警告。黑客小明的動作:
- 想冒充銀行服務器,偽造了一個證書,但簽名無法通過 CA 驗證,你根本不會信任他。
- 或直接攔截服務器的真實證書,替換成自己的假證書,但你的瀏覽器發現簽名不對,拒絕繼續通信。
三、密鑰交換:生成「只有你和銀行知道的密碼本」(TLS 握手第 4-5 步)
你的瀏覽器動作:
- 生成「預主密鑰」:
pre_master_key_xyz789(真正的密碼本核心)。- 用招商銀行證書中的公鑰加密預主密鑰,發送給服務器:
公鑰加密(pre_master_key_xyz789)
比喻:你用銀行身份證上的公鑰(公開的鎖)把密碼本核心鎖在盒子里,只有銀行的私鑰(唯一的鑰匙)能打開。招商銀行服務器動作:
- 用自己的私鑰解密收到的密文,得到預主密鑰:
pre_master_key_xyz789。- 雙方獨立計算「會話密鑰」:
- 公式:
會話密鑰 = 哈希(預主密鑰 + 隨機數A + 隨機數B)- 結果:雙方得到相同的對稱密鑰,比如
session_key_secure123(用于后續加密的密碼本)。
比喻:你用A片段+預主密鑰拼出密碼本,銀行用B片段+預主密鑰拼出同樣的密碼本,黑客即使知道 A 和 B,但沒有預主密鑰(被公鑰加密保護),無法算出會話密鑰。黑客小明的動作:
- 截獲了隨機數 A、B 和加密后的預主密鑰,但沒有銀行私鑰,無法解密預主密鑰,更算不出會話密鑰。
四、安全通信:用密碼本加密傳輸登錄數據(TLS 握手完成后)
你發送登錄請求(假設賬號
user123,密碼pass456):
- 瀏覽器用「會話密鑰」加密數據:
- 明文:
{"username":"user123", "password":"pass456", "action":"login"}- 密文:
AES256-GCM加密(session_key_secure123, 明文)(變成亂碼)- 發送密文給銀行服務器。
招商銀行服務器接收并解密:
- 用「會話密鑰」解密密文,得到明文:
user123和pass456。- 驗證登錄信息正確后,返回加密的賬戶余額:
- 明文:
{"balance":"100000元", "timestamp":"2025-05-21 14:30"}- 密文:
AES256-GCM加密(session_key_secure123, 明文)黑客小明的動作:
- 截獲了密文,但沒有會話密鑰,無法解密,看到的只是亂碼:
�N�w���S�C�...- 想篡改密文中的 “balance” 為 “1000000 元”,但篡改后密文的完整性校驗(GCM 模式帶認證)會失敗,服務器會丟棄該數據。
五、關鍵細節:如果中間人參戰會怎樣?
假設黑客小明成功冒充路由器,實施中間人攻擊:
偽造證書:小明生成一個假的
cmbchina.com證書(自簽名證書,無 CA 簽名)。
- 你的瀏覽器驗證時發現證書簽名無效,彈出警告:“該網站證書不可信!”
- 你選擇 “繼續訪問”(危險操作),此時進入 “不安全通道”,小明可竊取密鑰。
成功欺騙的極端情況:
- 小明是某機構員工,持有偽造的 CA 證書(現實中幾乎不可能,因根 CA 私鑰極難竊取)。
- 你的瀏覽器信任該 CA,認為證書有效,此時小明可充當 “中間人”,解密你和銀行的通信(這就是為什么根 CA 安全至關重要)。
總結:例子中的核心對應關系
HTTPS 流程 具體例子場景 安全作用 數字證書 招商銀行的 “官方身份證” 防止冒充,驗證身份 公鑰加密預主密鑰 用銀行公鑰鎖密碼本核心 確保密鑰傳輸安全 會話密鑰 你和銀行的共享密碼本 高效加密大量數據 對稱加密通信 加密傳輸登錄密碼和賬戶余額 防止竊聽和篡改
十、瀏覽器從輸入url到展示頁面,經歷了哪些過程
一、導航準備階段:處理 URL & 安全校驗
場景:你在地址欄輸入
zhihu.com并按回車
URL 標準化
- 瀏覽器自動補全協議:
http://?→?https://(若默認啟用 HTTPS)- 修正格式:去除多余空格,處理特殊字符(如
%20轉空格)- 示例:輸入
zhihu.com?→ 轉為https://www.zhihu.com/(可能帶默認路徑)安全檢查(關鍵!)
- 協議校驗:
http:?直接跳轉,https:?需走加密流程(觸發 TLS 握手)- 跨站腳本防護(XSS):
- 檢查 URL 是否包含惡意腳本(如
javascript:alert(1)),攔截危險內容- 瀏覽器安全策略:
- 遵循
Content Security Policy (CSP)頭(若有),限制資源加載來源二、DNS 解析:從域名到 IP 的「地址翻譯」
場景:需要知道
www.zhihu.com的服務器 IP
多級緩存查詢(速度優先)
- 瀏覽器緩存:先查本地緩存(如 Chrome 輸入
chrome://net-internals/#dns可看),若有 IP(有效期內)直接使用- 系統緩存:查本機
hosts文件(Windows 在C:\Windows\System32\drivers\etc\hosts),可手動綁定 IP- 路由器緩存:家用路由器可能緩存 DNS 記錄,減少重復查詢
遞歸查詢流程(若緩存失效)
- 本地 DNS 服務器(LDNS):
你的網絡服務商提供的 DNS(如電信 / 聯通的 DNS),先查其緩存,若沒有則:- 根 DNS 服務器:返回
.com頂級域服務器地址(如a.gtld-servers.net)- 頂級域(TLD)服務器:返回
zhihu.com的權威 DNS 服務器地址- 權威 DNS 服務器:返回
www.zhihu.com的真實 IP(如180.163.151.35)- 耗時:全程約 50-200ms,HTTPS 站點可能用
DNS-over-HTTPS (DoH)加密查詢,防中間人攻擊三、網絡連接:建立安全通道(TCP+TLS)
場景:與知乎服務器
180.163.151.35:443建立連接1. TCP 三次握手(可靠傳輸)
- 你→服務器:發送 SYN 包,請求建立連接( seq=1001 )
- 服務器→你:回復 SYN+ACK 包( seq=2001, ack=1002 )
- 你→服務器:發送 ACK 包( ack=2002 ),連接建立
- 關鍵點:確認雙方收發能力正常,避免舊連接干擾
2. TLS 握手(HTTPS 加密通道)
- 你發送 ClientHello:
支持的 TLS 版本(如 1.3)、加密算法列表(如 ECDHE-RSA-AES256-GCM)、隨機數 A- 服務器返回 ServerHello + 證書:
選定算法、服務器數字證書(含公鑰)、隨機數 B- 你驗證證書:
檢查域名(www.zhihu.com)、有效期、CA 簽名(內置根證書驗證),若證書無效則彈窗警告- 生成會話密鑰:
你用服務器公鑰加密「預主密鑰」發送,雙方用預主密鑰 + 隨機數 A/B 算出相同的對稱密鑰(如session_key_secure)- 耗時:約 1-RTT(往返時間),現代瀏覽器支持「TLS 會話復用」減少后續連接耗時
四、HTTP 請求與響應:獲取頁面原始數據
場景:向知乎服務器請求首頁 HTML
發送請求(Request)
- 請求行:
GET / HTTP/2(使用 HTTP/2 協議,多路復用)- 請求頭:
{ "Host": "www.zhihu.com", "User-Agent": "Mozilla/5.0 Chrome/115...", // 標識瀏覽器 "Accept": "text/html", // 聲明接受HTML格式 "Cookie": "session_id=abc123" // 攜帶登錄狀態 }- 請求體:GET 方法無,POST/PUT 等方法攜帶數據
服務器處理請求
- 解析請求頭,驗證 Cookie(若已登錄,返回個性化頁面)
- 生成響應內容:讀取 HTML 文件、查詢數據庫(如用戶信息、推薦內容)
- 添加響應頭:
{ "Content-Type": "text/html; charset=utf-8", // 聲明內容類型 "Cache-Control": "max-age=3600", // 瀏覽器緩存策略 "Set-Cookie": "new_session=xyz789" // 可能更新Cookie }返回響應(Response)
- 狀態碼:
200 OK(成功)、302 Found(臨時重定向)、404 Not Found等- 響應體:HTML 文本(如知乎首頁的
<html><head>...</head><body>...</body></html>)- 耗時:取決于服務器處理速度、網絡延遲,通常幾十到幾百毫秒
五、瀏覽器解析渲染:從代碼到像素
場景:將知乎 HTML 轉換為屏幕上的文字、圖片、按鈕
1. 構建渲染樹(Render Tree)
- 解析 HTML→DOM 樹:
逐行解析 HTML,生成節點對象(如<div class="header">),形成樹狀結構
- 遇到
<script src="main.js">:暫停解析,下載 JS 并執行(默認阻塞渲染)- 遇到
<link rel="stylesheet" href="style.css">:并行下載 CSS,不阻塞 HTML 解析- 解析 CSS→CSSOM 樹:
解析 CSS 規則,生成樣式對象(如.header { color: #333; })- 合并為渲染樹:
過濾不可見元素(如display: none),保留需顯示的節點(如visibility: hidden仍保留)2. 布局計算(Layout)
- 計算每個元素的幾何屬性:
- 位置:基于 Flex/Grid 布局、盒模型(margin/padding/border)
- 尺寸:寬高(如
.header寬 100%,高 80px)- 示例:知乎首頁頭部導航欄,通過 CSS 計算得出左對齊、高度 60px、內邊距 10px
3. 繪制(Paint)
- 將元素的視覺屬性(顏色、陰影、邊框)轉換為像素數據:
- 文字渲染:調用系統字體引擎,生成字形像素
- 圖片解碼:將下載的 JPEG/PNG 轉為位圖(可能觸發「圖片解碼阻塞渲染」)
- 優化點:瀏覽器將不同層級元素(如浮層、視頻)分到不同圖層,避免重復繪制
4. 合成(Composite)
- 將多個圖層按層級合并(如背景層→內容層→浮層),輸出到屏幕:
- 使用 GPU 加速合成(
transform/opacity動畫不會觸發重排重繪)- 回流(Reflow):若修改布局(如
width: 50%),需重新計算布局→繪制→合成- 重繪(Repaint):僅修改樣式(如
color: red),只需重新繪制→合成六、資源加載與優化:并行獲取圖片、JS、CSS
場景:知乎首頁 HTML 中引用了 LOGO 圖片、JS 交互腳本、CSS 樣式表
優先級與并行加載
- 關鍵資源:CSS(阻塞渲染)、JS(阻塞解析,除非標記
async/defer)- 非關鍵資源:圖片、字體、視頻(異步加載)
- 瀏覽器策略:
- 同一域名下最多建立 6-8 個 TCP 連接(HTTP/1.1),HTTP/2 支持多路復用(單個連接并發加載)
- 預加載提示:HTML 中
<link rel="preload" href="main.js">告知瀏覽器提前下載示例資源加載流程
- HTML 解析到
<img src="logo.png">:發起 GET 請求獲取圖片(并行于 DOM 解析)- 解析到
<script src="analytics.js" defer>:下載 JS 但不阻塞渲染,DOM 構建完成后執行- CSS 文件下載完成后,觸發「樣式重新計算」,可能導致部分元素重新布局
七、JS 執行:動態交互的核心
場景:知乎首頁的搜索框自動補全、按鈕點擊事件
引擎編譯執行
- V8 引擎(Chrome)將 JS 代碼編譯為機器碼:
- 解析階段:生成抽象語法樹(AST)
- 優化階段:JIT(即時編譯)優化熱點代碼(如循環)
- 事件循環(Event Loop):處理異步操作(如
setTimeout、AJAX 回調),避免阻塞主線程DOM 操作與性能影響
- 示例代碼:
// 點擊按鈕修改文本(觸發重繪) document.getElementById('button').addEventListener('click', () => { document.getElementById('text').style.color = 'red'; // 重繪 }); // 調整布局(觸發回流+重繪) document.getElementById('box').style.width = '200px';- 優化建議:
- 批量修改 DOM(如先改
display: none,改完再顯示)- 使用
requestAnimationFrame處理動畫八、收尾階段:頁面完成與后續處理
onLoad 事件觸發
- 所有資源(HTML/CSS/JS/ 圖片)加載完成后,執行
window.onload回調- 示例:知乎首頁在此階段初始化全頁面 JS 組件(如評論區、推薦算法)
瀏覽器優化機制
- 預渲染:推測用戶可能訪問的鏈接(如鼠標懸停),提前加載頁面內容
- 內存管理:垃圾回收機制清理無效變量,避免內存泄漏
十一、HTTP協議中的cookie和session的區別
一、核心定義
1. Cookie
- 本質:存儲在客戶端(瀏覽器 / 手機)本地的小型文本數據(鍵值對形式)。
- 作用:用于服務器識別用戶身份,實現會話狀態的持久化(如保持登錄狀態)。
- 工作原理:
- 服務器通過響應頭(
Set-Cookie)向客戶端發送 Cookie。- 客戶端后續請求時,會自動在請求頭(
Cookie)中攜帶該 Cookie,回傳給服務器。例子:
用戶登錄網站后,服務器返回一個包含user_id=123的 Cookie,客戶端保存后,下次訪問時自動攜帶該 Cookie,服務器通過user_id識別用戶已登錄。2. Session
- 本質:存儲在服務器端的會話數據(如用戶權限、購物車信息等)。
- 作用:用于記錄用戶在一次會話中的動態狀態(如登錄狀態、臨時數據)。
- 工作原理:
- 服務器創建 Session 時,生成一個唯一的Session ID(如
session_id=abc123)。- 通過 Cookie 將 Session ID 發送給客戶端,客戶端后續請求攜帶該 ID,服務器通過 ID 查找對應的 Session 數據。
例子:
用戶在電商網站添加商品到購物車,服務器創建一個 Session 存儲購物車內容,并返回session_id給客戶端。用戶瀏覽其他頁面時,攜帶session_id,服務器根據 ID 找到對應的購物車數據。二、關鍵區別對比
維度 Cookie Session 存儲位置 客戶端(瀏覽器、本地文件) 服務器端(內存、數據庫、文件系統等) 安全性 較低(數據明文存儲于客戶端,易被篡改或竊取) 較高(敏感數據存儲在服務器,客戶端僅存 Session ID) 數據容量 小(單個 Cookie 通常限制為4KB,瀏覽器對每個域名的 Cookie 數量有限制) 大(取決于服務器配置,可存儲復雜數據結構) 有效期 可設置( Expires或Max-Age,支持持久化)默認僅在瀏覽器會話期間有效(關閉瀏覽器即過期),也可設置持久化 跨域支持 受同源策略限制(只能在同域名下使用) 依賴 Cookie 傳遞 Session ID,因此同樣受同源策略限制 服務器壓力 無(數據存儲在客戶端) 有(每個用戶會話占用服務器資源) 典型用途 存儲非敏感信息(如用戶偏好、登錄令牌) 存儲敏感或動態信息(如登錄狀態、購物車、表單臨時數據) 三、典型應用場景
場景 1:用戶登錄狀態保持
Cookie 方案:
服務器驗證用戶密碼后,返回一個包含auth_token的 Cookie(設置有效期為 7 天)。用戶下次訪問時,瀏覽器自動攜帶該 Cookie,服務器驗證令牌有效則允許登錄。
風險:若 Cookie 被竊取,攻擊者可偽造身份(需配合HttpOnly和Secure屬性增強安全性)。Session 方案:
服務器驗證用戶密碼后,創建 Session 存儲用戶信息(如user_role=admin),并返回session_id的 Cookie。用戶后續請求攜帶session_id,服務器通過 ID 查找 Session 并驗證權限。
優勢:敏感信息(如user_role)不暴露在客戶端,安全性更高。場景 2:電商購物車
Cookie 方案:
將購物車商品 ID 存儲在 Cookie 中(如cart=item1,item2)。
缺點:數據容量有限,且用戶在不同設備登錄時無法同步購物車。Session 方案:
購物車數據存儲在服務器 Session 中,客戶端僅存儲session_id。用戶更換設備后,重新登錄即可同步購物車(需結合用戶賬號體系)。
優勢:支持大容量數據,跨設備同步方便。四、配合使用:Cookie + Session
實際開發中,兩者常結合使用:
- 服務器創建 Session,生成
session_id。- 通過 Cookie 將
session_id返回給客戶端(這是 Session 機制的核心)。- 客戶端后續請求攜帶
session_id,服務器通過 ID 識別用戶會話。優點:
- 利用 Cookie 的跨請求傳遞能力,避免每次請求都重新認證。
- 敏感數據存儲在服務器,降低客戶端安全風險。
五、面試高頻問題
為什么 Session 需要依賴 Cookie?
答:Session 通過session_id識別用戶會話,而session_id需要通過 Cookie 傳遞給客戶端。若客戶端禁用 Cookie,則需通過 URL 重寫(如http://example.com/?session_id=abc123)傳遞,但安全性和兼容性較差。Cookie 的
HttpOnly和Secure屬性有什么用?
HttpOnly:禁止 JavaScript 讀取 Cookie(防止 XSS 攻擊竊取 Cookie)。Secure:僅在 HTTPS 連接下發送 Cookie(防止明文傳輸被劫持)。分布式系統中如何管理 Session?
答:單機 Session 無法跨服務器共享,需使用分布式 Session 方案(如 Redis 集群存儲 Session 數據,所有服務器共享同一存儲)。
十二、http和grpc的區別
一、核心定義與設計目標
1. HTTP
?
- 本質:基于請求 - 響應模型的應用層協議,用于規范客戶端(如瀏覽器)與服務器之間的通信。
- 設計目標:
- 實現超文本(文本、圖片、視頻等)的傳輸與展示,是 Web 服務的基礎。
- 強調通用性和可讀性,支持跨平臺、跨語言的交互(如瀏覽器可訪問任何支持 HTTP 的服務器)。
典型場景:
?
- 瀏覽器訪問網頁(如?
GET https://example.com/index.html)。- 對外提供 RESTful API(如調用第三方天氣接口?
GET https://api.weather.com/city=上海)。2. RPC(Remote Procedure Call)
?
- 本質:一種進程間通信機制,允許程序像調用本地函數一樣調用遠程服務器的函數。
- 設計目標:
- 隱藏網絡通信細節(如序列化、傳輸、反序列化),讓開發者專注于業務邏輯。
- 追求高效性和強類型約束,適用于分布式系統內部服務間的高頻交互。
典型場景:
?
- 微服務架構中,用戶服務調用訂單服務的接口(如?
userService.createOrder(userId, productId))。- 高性能場景下的內部通信(如電商系統中庫存服務與支付服務的實時交互)。
二、關鍵區別對比
維度 HTTP RPC 通信模型 嚴格的請求 - 響應模型(一問一答) 支持請求 - 響應、單向調用(如通知)、流式傳輸(如 gRPC 的雙向流) 協議層級 應用層協議(基于 TCP/IP) 通常基于 TCP 或 HTTP/2,可自定義傳輸層協議 數據格式 文本格式(JSON/XML),可讀性強但體積較大 二進制格式(如 Protobuf/Thrift),體積小、解析快 接口定義 松散(通過 URL 和 HTTP 方法定義接口,如? GET /users/{id})強類型(通過 IDL(接口定義語言)明確接口參數和返回值,如? .proto?文件)調用方式 顯式(需手動構造請求 URL、參數、 headers) 隱式(自動生成客戶端 Stub,像調用本地函數) 性能 相對較低(文本解析、協議開銷較大) 較高(二進制協議、連接復用、更少網絡開銷) 跨語言支持 天然跨語言(基于標準協議) 依賴框架支持(需為每種語言生成對應 Stub) 服務治理 需依賴外部組件(如 API 網關、Nginx) 內置支持(如負載均衡、服務發現、熔斷限流) 三、核心機制對比
1. 數據格式與序列化
HTTP:
以 JSON 為例,請求體可能是:{"method": "getUser","params": { "userId": "123" } }優點:易讀、易調試,適合對外接口或需要人工介入的場景(如前端調試)。
缺點:文本格式冗余,解析性能較低(如 JSON 轉對象需遍歷鍵值對)。RPC:
以 Protobuf 為例,通過?.proto?文件定義接口:service UserService {rpc getUser(GetUserRequest) returns (UserResponse) {} } message GetUserRequest { string userId = 1; }編譯后生成二進制數據(如?
userId=123?可能編碼為?0x0A\x03\x31\x32\x33)。
優點:二進制格式緊湊(體積通常比 JSON 小 30%~50%),解析速度快(基于字段編號而非字符串匹配)。
缺點:可讀性差,需依賴工具生成代碼。2. 調用方式對比
HTTP 調用(以 RESTful 為例):
客戶端需手動構造 HTTP 請求,例如用 Python 的?requests?庫:import requests response = requests.get("https://api.example.com/users/123", headers={"Authorization": "Bearer token"}) data = response.json()特點:需顯式處理網絡請求細節(URL、headers、錯誤處理)。
RPC 調用(以 gRPC 為例):
客戶端通過自動生成的 Stub 調用,例如:import user_service_pb2_grpc, user_service_pb2channel = grpc.insecure_channel("order-service:50051") stub = user_service_pb2_grpc.UserServiceStub(channel) request = user_service_pb2.GetUserRequest(userId="123") response = stub.getUser(request) # 像調用本地函數一樣特點:網絡通信細節(序列化、傳輸、反序列化)由框架自動處理,代碼更簡潔。
四、適用場景對比
適合用 HTTP 的場景
- 對外提供開放接口:
如第三方開發者調用的 API(如微信支付接口),需跨語言、跨平臺兼容,HTTP+JSON 的組合簡單易用。- 需要瀏覽器直接訪問的場景:
瀏覽器原生支持 HTTP,無需額外客戶端庫(如前端通過?fetch?調用接口)。- 低性能要求的簡單場景:
如內部管理系統的 API,對速度要求不高,但需要易調試和維護。適合用 RPC 的場景
- 微服務架構內部通信:
如電商系統中,用戶服務、訂單服務、庫存服務之間的高頻交互,需高性能和強類型接口(如庫存扣減時要求參數必須為整數)。- 實時性要求高的場景:
如即時通訊、實時數據同步(如股票行情推送),RPC 的二進制協議和連接復用(如 HTTP/2 的多路復用)可減少延遲。- 需要服務治理的復雜系統:
RPC 框架(如 Dubbo、gRPC)內置負載均衡、熔斷、限流等功能,適合大規模分布式系統。五、典型框架對比
類型 框架 / 工具 特點 HTTP Flask/Django 快速開發 Web 服務,適合中小型項目。 HTTP Spring Boot 基于 Java,支持 RESTful API,適合企業級應用。 RPC gRPC 基于 HTTP/2,支持多語言,性能高,Google 開源(如用于 Kubernetes 內部通信)。 RPC Dubbo 阿里巴巴開源,支持豐富的服務治理功能,適合 Java 生態的微服務架構。 RPC Thrift/Protobuf 專注于序列化和接口定義,可獨立于傳輸層使用(如通過 TCP 直接傳輸)。 六、面試高頻問題
為什么 RPC 比 HTTP 快?
答:
- RPC 使用二進制協議(如 Protobuf),體積更小、解析更快;
- 通常復用長連接(如 HTTP/2 的持久連接),減少 TCP 三次握手開銷;
- 框架層優化(如連接池、批量請求)進一步提升性能。
HTTP 和 RPC 可以共存嗎?
答:可以。例如:
- 對外提供 HTTP API 供瀏覽器 / 第三方調用;
- 內部微服務之間使用 RPC 通信以提升性能(如電商平臺的前端用 HTTP 調用網關,網關內部通過 RPC 調用各個服務)。
gRPC 是 HTTP 還是 RPC?
答:gRPC 是基于 HTTP/2 的 RPC 框架。它復用了 HTTP/2 的多路復用、二進制分幀等特性,但通過 IDL 實現了強類型的 RPC 調用,屬于 RPC 范疇。
十三、HTTP方法GET、POST、PUT和PATCH的區別是什么
一、核心功能對比
方法 功能描述 GET 請求獲取資源(如查詢數據、獲取文件等),不改變服務器狀態。 POST 用于創建新資源(如提交表單、上傳文件等),通常會導致服務器狀態變化。 PUT 更新資源(覆蓋式更新),需指定完整資源數據,常用于替換已有資源或創建指定 ID 的資源。 PATCH 部分更新資源,只需提交需要修改的字段,無需提供完整數據,比 PUT 更靈活高效。 二、關鍵特性對比
1. 冪等性(Idempotence)
- 冪等性:多次執行相同操作,結果與一次執行相同,不會產生副作用。
- GET:冪等。多次獲取同一資源,結果不變(如查詢商品列表)。
- POST:非冪等。多次提交可能創建多個資源(如重復提交訂單)。
- PUT:冪等。多次覆蓋同一資源,結果一致(如用 PUT 更新用戶信息,每次傳入完整數據)。
- PATCH:非冪等。多次部分更新可能產生累積效果(如先修改用戶郵箱,再修改手機號)。
2. 安全性(Safety)
- 安全性:方法是否僅用于獲取資源,不修改狀態。
- GET:安全。僅用于讀取數據,不影響服務器狀態。
- POST/PUT/PATCH:非安全。會修改服務器資源(如創建、更新數據)。
3. 參數位置
- GET:參數通過 URL 傳遞(如?
?key=value),明文可見,長度受限(瀏覽器 / 服務器限制)。- POST/PUT/PATCH:參數通常放在請求體(Request Body)中,可傳輸較大數據,且不暴露在 URL 中。
4. 資源定位
- GET/POST:資源由 URL 定位(如?
GET /users?獲取用戶列表,POST /users?創建用戶)。- PUT/PATCH:需指定具體資源的完整 URL(如?
PUT /users/123?更新 ID 為 123 的用戶)。三、典型使用場景
1. GET
- 查詢數據:如獲取用戶信息、商品詳情(
GET /users/1)。- 非敏感數據請求:如獲取靜態文件(圖片、API 列表)。
2. POST
- 創建資源:如用戶注冊(
POST /users?提交用戶數據)、提交表單。- 非冪等操作:如支付請求(重復提交會導致多筆交易)。
3. PUT
- 完整更新資源:如修改用戶全部信息(需傳入完整用戶數據)。
- 創建指定資源:如上傳文件到固定路徑(
PUT /files/abc.txt)。4. PATCH
- 部分更新資源:如僅修改用戶郵箱(
PATCH /users/1?傳入?{"email": "new@example.com"})。- 高效更新:避免傳輸未修改的字段,減少數據量(如 RESTful API 中優化更新操作)。
四、對比總結表格
特性 GET POST PUT PATCH 用途 讀取資源 創建資源 全量更新 部分更新 冪等性 ? 冪等 ? 非冪等 ? 冪等 ? 非冪等 安全性 ? 安全 ? 非安全 ? 非安全 ? 非安全 參數位置 URL 請求體 請求體 請求體 典型場景 查詢列表 提交表單 替換資源 修改字段 五、常見誤區與最佳實踐
不要濫用 POST:
傳統 Web 開發中常用 POST 處理所有操作,但在 RESTful 設計中,應根據操作類型選擇方法(如更新用 PUT/PATCH,刪除用 DELETE)。PUT vs. PATCH 的選擇:
- 需要覆蓋整個資源時用 PUT(如重置用戶密碼)。
- 只需修改部分字段時用 PATCH(如更新用戶頭像 URL)。
冪等性的重要性:
在分布式系統中,冪等性可避免重復請求導致的數據不一致(如接口重試時,PUT 比 POST 更安全)。
0voice · GitHub??
:從基礎到高頻面試題)









)







:統一過程模型(RUP))
