
MNN 是一個高效且輕量級的深度學習框架。它支持深度學習模型的推理和訓練,并在設備端的推理和訓練方面具有行業領先的性能。目前,MNN 已集成到阿里巴巴集團的 30 多個應用中,如淘寶、天貓、優酷、釘釘、閑魚等,覆蓋了直播、短視頻拍攝、搜索推薦、以圖搜貨、互動營銷、權益發放、安全風控等 70 多個使用場景。此外,MNN 還被用于嵌入式設備,如物聯網。
MNN-LLM 是一個基于 MNN 引擎開發的大型語言模型運行時解決方案。該項目的使命是將 LLM 模型部署在每個人的本地平臺上(手機/PC/物聯網)。它支持流行的大型語言模型,如千問、百川、智譜、LLAMA 等。
MNN-Diffusion 是一個基于 MNN 引擎開發的穩定擴散模型運行時解決方案。該項目的使命是在每個人的平臺上本地部署穩定擴散模型。

在阿里巴巴內部,MNN作為Walle系統中的計算容器基礎模塊,Walle系統是首個端到端、通用且大規模的設備-云協同機器學習生產系統,該系統已在頂級系統會議OSDI’22上發表。MNN的關鍵設計原則和廣泛的基準測試結果(與TensorFlow、TensorFlow Lite、PyTorch、PyTorch Mobile、TVM的對比)可以在OSDI論文中找到。基準測試的腳本和說明放在“/benchmark”路徑下。
主要特點
輕量級
- 針對設備進行優化,無依賴項,可輕松部署到移動設備和各種嵌入式設備。
- iOS 平臺:armv7+arm64 平臺的靜態庫大小約為 12MB,鏈接的可執行文件大小增加約為 2M。
- Android 平臺:核心 so 文件大小約為 800KB(armv7a - c++_shared)。
- 使用 MNN_BUILD_MINI 可以將包大小減少約 25%,但限制了固定模型輸入大小。
- 支持 FP16 / Int8 量化,可以將模型大小減少 50%-70%。
多功能性
- 支持
Tensorflow、Caffe、ONNX、Torchscripts,并支持常見的神經網絡,如CNN、RNN、GAN、Transformer。 - 支持具有多輸入或多輸出的 AI 模型,各種維度格式,動態輸入,控制流。
- MNN 支持近似全量的 AI 模型操作符。轉換器支持 178 個
Tensorflow操作符,52 個Caffe操作符,163 個Torchscripts操作符,158 個ONNX操作符。 - 支持 iOS 8.0+、Android 4.3+ 以及具有 POSIX 接口的嵌入式設備。
- 支持多設備混合計算。目前支持 CPU 和 GPU。
高性能
- 通過大量優化的匯編代碼實現核心計算,以充分利用 ARM / x64 CPU。
- 使用 Metal / OpenCL / Vulkan 支持移動設備上的 GPU 推理。
- 使用 CUDA 和 tensorcore 支持 NVIDIA GPU,以獲得更好的性能。
- 卷積和轉置卷積算法高效且穩定。Winograd 卷積算法廣泛用于更好地處理對稱卷積,如 3x3、4x4、5x5、6x6、7x7。
- 支持 FP16 半精度計算的新架構 ARM v8.2 速度提升兩倍。使用 sdot 和 VNNI 的 ARM v8.2 速度提升 2.5 倍。
支持的架構/精度MNN如下所示:
- S:支持且運行良好,深度優化,推薦使用
- A:支持且運行良好,可以使用
- B:支持但有bug或未優化,不推薦使用
- C:不支持
| 架構 / 精度 | 常規 | FP16 | BF16 | Int8 | |
|---|---|---|---|---|---|
| CPU | Native | B | C | B | B |
| x86/x64-SSE4.1 | A | B | B | A | |
| x86/x64-AVX2 | S | B | B | A | |
| x86/x64-AVX512 | S | B | B | S | |
| ARMv7a | S | S (ARMv8.2) | S | S | |
| ARMv8 | S | S (ARMv8.2) | S(ARMv8.6) | S | |
| GPU | OpenCL | A | S | C | S |
| Vulkan | A | A | C | A | |
| Metal | A | S | C | S | |
| CUDA | A | S | C | A | |
| NPU | CoreML | A | C | C | C |
| HIAI | A | C | C | C | |
| NNAPI | B | B | C | B |
News 🔥
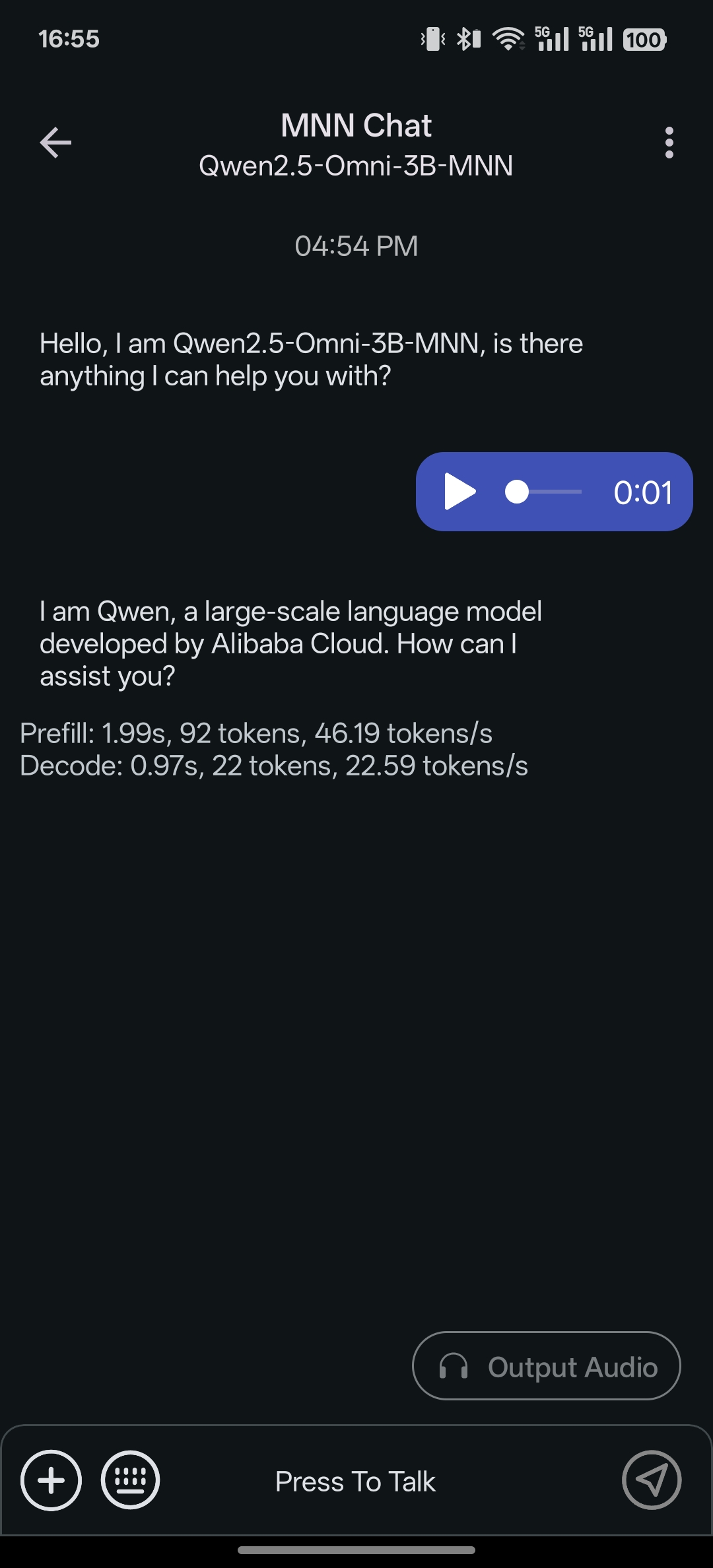
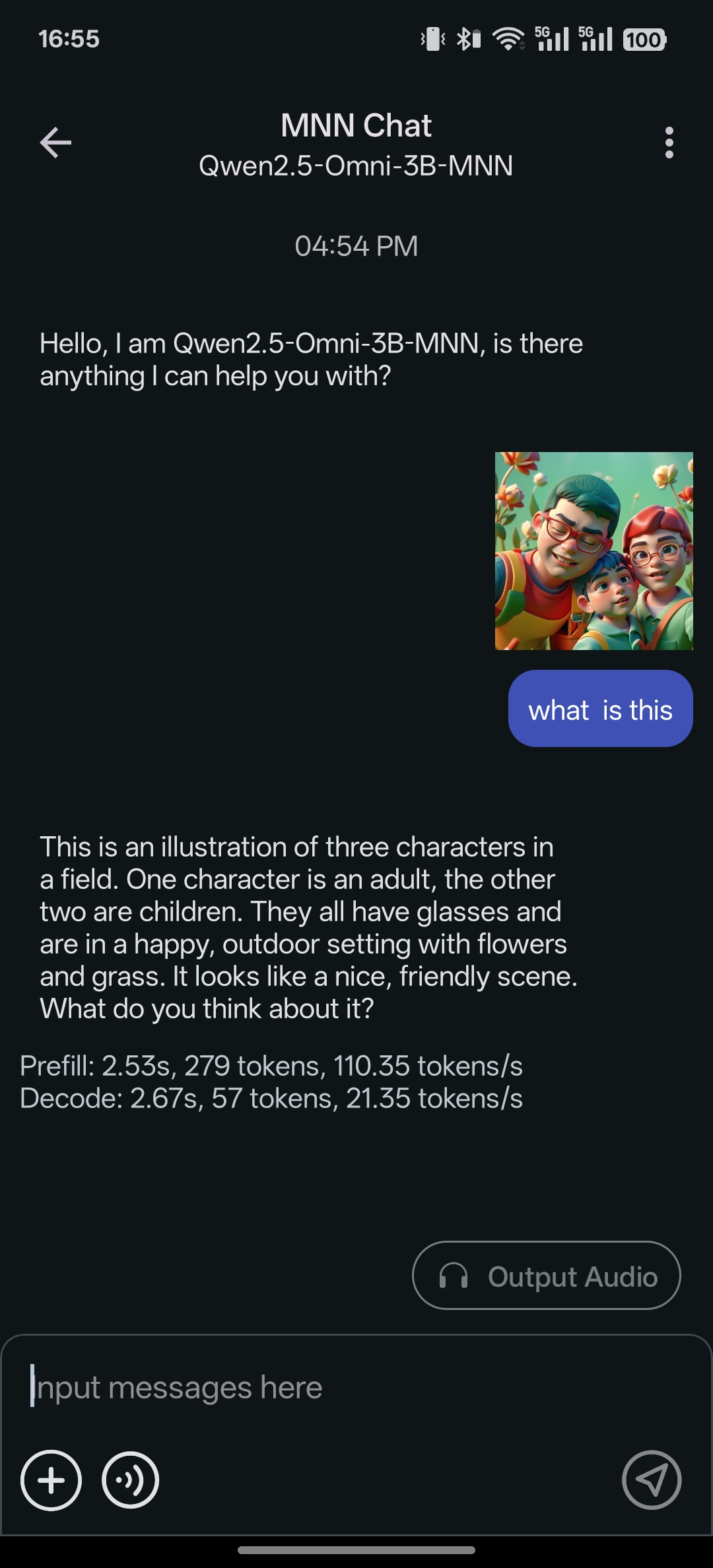
[2025/05/12] android app 支持 qwen2.5 omni 3b and 7b
代碼:https://github.com/alibaba/MNN/



)
)







)


_進階的開端)


)
