摘要
在遙感影像(RSI)中,準確且及時地檢測包含數十像素的多尺度小目標仍具有挑戰性。現有大多數方法主要通過設計復雜的深度神經網絡來學習目標與背景的區分特征,常導致計算量過大。本文提出一種兼顧檢測精度與計算代價的快速準確的遙感目標檢測方法,稱為 SuperYOLO。該方法融合多模態數據,并通過借助超分辨率(SR)學習,在低分辨率(LR)輸入下實現多尺度目標的高分辨率(HR)檢測。首先,我們設計了對稱緊湊的多模態融合(MF)模塊,從多種數據中提取補充信息,以提升遙感圖像中小目標的檢測效果。其次,我們構建了簡單靈活的超分支(SR branch),在訓練階段學習可區分小目標與廣闊背景的高分辨率特征,進一步提高檢測精度。另外,為避免增加推理階段的計算開銷,SR 分支僅在訓練時使用,推理時予以丟棄,且因輸入為低分辨率圖像而減少網絡整體計算量。實驗結果表明,在常用的 VEDAI 遙感數據集上,SuperYOLO 在 mAP50 指標上達到了 75.09%,較 YOLOv5l、YOLOv5x 及專為遙感設計的 YOLOrs 等大型模型提高了超過 10%。同時,SuperYOLO 的參數量和 GFLOPs 分別約為 YOLOv5x 的 1/18 和 1/3.8。所提模型在精度–速度權衡方面優于現有最先進方法。代碼將開源于:https://github.com/icey-zhang/SuperYOLO。
I. 引言
目標檢測在計算機輔助診斷、無人駕駛等諸多領域具有重要作用。過去數十年間,基于深度神經網絡(DNN)的多種優秀目標檢測框架[1–5]相繼被提出與優化,且在大規模自然圖像數據集及其精確標注的推動下,檢測精度顯著提升[6–8]。
與自然場景相比,遙感影像(RSI)目標檢測面臨若干關鍵挑戰:
標注樣本數量較少,限制了 DNN 的訓練效果;
RSI 中目標尺寸極小,僅占數十像素,相對于復雜廣闊的背景極易被淹沒[9,10];
目標尺度多樣,不同類別間存在顯著差異[11]。
如圖 1(a)所示,汽車在廣闊區域中非常微小;如圖 1(b)所示,相較于房車(camping vehicle),汽車尺度更小且變化多端。
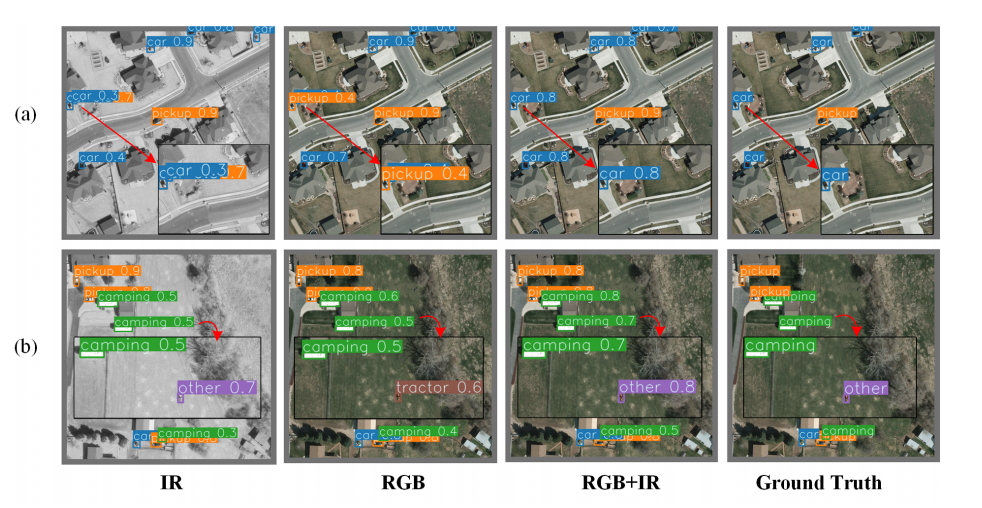
圖1 RGB圖像、IR圖像和ground truth (GT)的視覺對比。紅外圖像為解決RGB檢測中的難題提供了重要的補充信息。(a)中的物體在廣闊的區域內相當小。在(b)中,物體有較大的變化,其中汽車的規模小于露營車的規模。RGB和IR模態的融合有效地提高了檢測性能。
當前多數檢測技術僅針對單一模態(如 RGB 或紅外 IR)[12,13],難以利用不同模態間的互補信息提升地表目標識別能力[14]。隨著成像技術發展,多模態遙感數據日益可得,為提高檢測精度提供了契機。例如,將 RGB 與 IR 融合,可有效增強遙感小目標的可檢測性。另一方面,某些模態分辨率偏低,需要通過超分辨率技術提升圖像細節。近期超分辨率方法在遙感領域展現出巨大潛力[15–18],但基于 CNN 的高性能 SR 網絡計算開銷大,其在實時應用中的落地仍具挑戰。
本研究旨在提出一款用于多模態遙感的實時高效目標檢測框架,在保證高精度與高速推理的前提下,不增加額外計算負擔。受輕量化實時神經網絡的啟發,我們以小型 YOLOv5s[19] 作為檢測基線,其可降低部署成本并加速模型落地。考慮到小目標對高分辨率(HR)特征的需求,我們移除基線模型中的 Focus 模塊,不僅有利于小而密集目標的定位,也提升了檢測性能。我們提出如下關鍵技術:
像素級對稱緊湊融合(MF)——在低計算代價下,高效地雙向融合 RGB 與 IR 等多模態信息,相較于特征級融合進一步節省計算且不損失精度;
輔助超分辨率分支(SR branch)——在訓練階段引入 SR 任務,引導網絡生成能區分小目標與背景的 HR 特征,有效減少背景誤報;
無額外推理開銷——SR 分支僅作為輔助任務,訓練后舍棄,推理時保持低分辨率輸入,實現 HR 空間信息提取而不增加計算;
優異的精度–速度權衡——SuperYOLO 在 VEDAI 數據集上顯著超越現有實時及大型模型,提升超過 10% mAP50,且參數量和 FLOPs 大幅降低。
后續章節將依次介紹相關工作、方法細節、實驗結果及分析。
A. 基于多模態數據的目標檢測
近年來,多模態數據已在眾多實際應用場景中得到廣泛應用,包括視覺問答[20]、自動駕駛車輛[21]、顯著性檢測[22]以及遙感圖像分類[23]。研究表明,將多模態數據的內部信息進行融合,能夠有效傳遞互補特征,避免單一模態信息的遺漏。 在遙感影像(RSI)處理領域,來自不同傳感器的多種模態(如紅-綠-藍(RGB)、合成孔徑雷達(SAR)、激光雷達(LiDAR)、紅外(IR)、全色(PAN)和多光譜(MS)影像)可相互補充,以提升各類任務的性能[24–26]。例如,附加的紅外模態可捕獲更長的熱波段,在惡劣天氣下提升檢測能力[27]。Manish 等人[27]提出了一種多模態遙感影像實時目標檢測框架,其擴展版本在中層融合階段合并了多種模態數據。盡管多傳感器融合如圖 1所示能夠提升檢測性能,但其較低的檢測精度和亟待提升的計算速度難以滿足實時檢測的需求。
融合方法主要分為三類:像素級融合、特征級融合和決策級融合[28]。決策級融合在最后階段合并各分支檢測結果,可能因對每個模態分支重復計算而消耗大量資源。在遙感領域,特征級融合被廣泛采用:將多模態影像分別輸入并行分支,提取各自特征后通過注意力機制或簡單拼接等操作融合。但隨著模態數增多,并行分支帶來成倍的計算開銷,不利于實時應用。
相比之下,像素級融合能夠減少不必要的計算。本文中,我們的 SuperYOLO 在像素級對多模態進行融合,通過空間和通道域的高效操作挖掘不同模態間的內部互補信息,在大幅降低計算成本的同時提升檢測精度。
B. 目標檢測中的超分辨率
近期研究表明,多尺度特征學習[29,30]和基于上下文的檢測[31]能夠改善小目標檢測性能,但這些方法往往側重于多尺度信息的表示,而忽略了高分辨率上下文信息的保留。作為預處理手段,超分辨率(SR)已在多種目標檢測任務中得到驗證[32,33]。Shermeyer 等人[34]通過對不同分辨率的遙感影像進行檢測實驗,量化了 SR 對檢測性能的影響。Courtrai 等人[35]基于生成對抗網絡(GAN)生成高分辨率圖像,并將其送入檢測器以提升性能。Rabbi 等人[36]利用拉普拉斯算子提取輸入圖像的邊緣,以加強高分辨率重建,從而改善目標定位與分類。Hong 等人[37]引入循環一致性 GAN 架構作為 SR 網絡,并在 Faster R-CNN 中進行改進,用于檢測由 SR 網絡生成的增強圖像中的車輛。這些工作表明,SR 結構能有效應對小目標檢測難題,但由于輸入圖像分辨率增大,必然帶來額外計算開銷。
近期,Wang 等人[38]在語義分割任務中提出了一種 SR 模塊,能夠在低分辨率輸入下保持高分辨率表示的同時減少計算量。受此啟發,我們設計了一個輔助 SR 分支。與上述在網絡初始階段即進行 SR 的方法不同,本工作中的輔助 SR 模塊在訓練過程中引導檢測主干學習高質量的高分辨率特征,不僅增強了小而密集目標的響應,也提升了空間域目標檢測性能。更重要的是,該 SR 分支僅作為訓練時的輔助任務,在推理階段被移除,從而避免了任何額外計算。
III. 基線結構
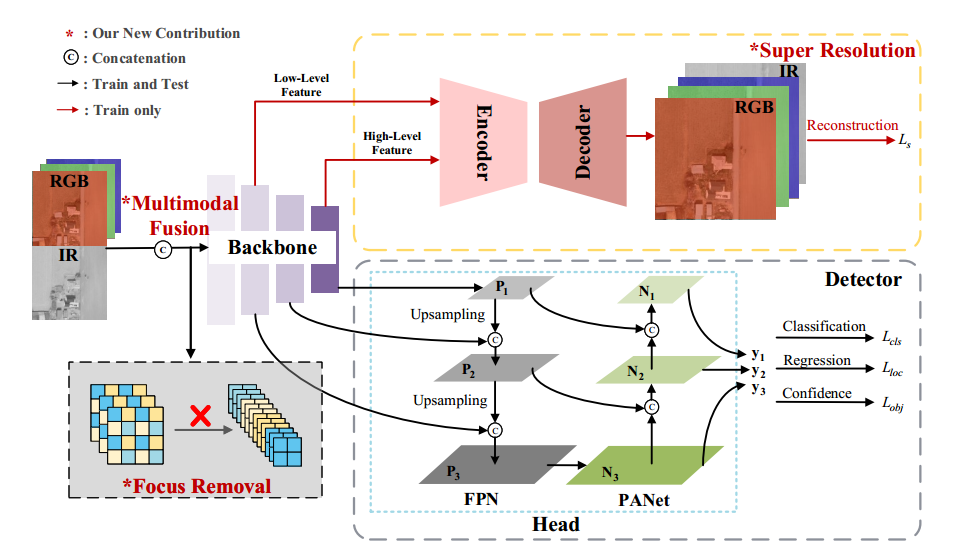
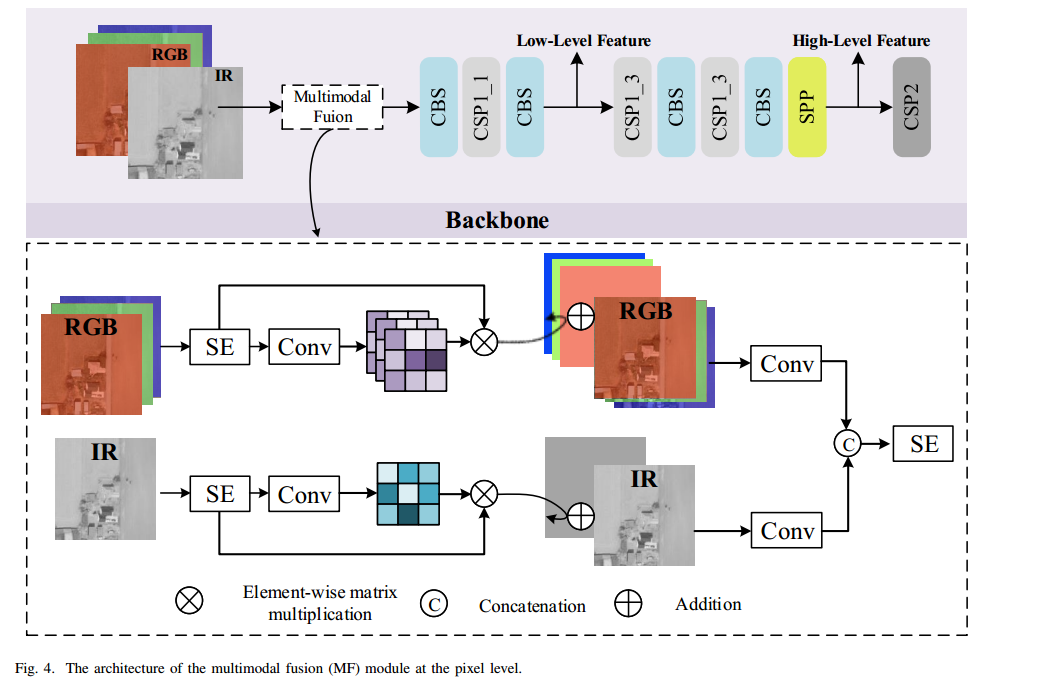
如圖 2 所示,基線 YOLOv5 網絡主要由兩部分構成:Backbone(主干)和 Head(包括 Neck)。主干用于提取低層次的紋理特征和高層次的語義特征。隨后,這些特征被送入 Head:先自上而下構建增強的特征金字塔,將強語義信息向下傳遞;再自下而上將局部紋理和模式特征的響應向上聚合。這樣便通過多尺度特征融合,解決了目標尺度多樣化的問題,提升了檢測性能。
在圖 3 中,Backbone 采用 CSPNet[39],由多個 CBS(Convolution?BatchNorm?SiLu)模塊和 CSP(Cross Stage Partial)模塊組成。CBS 包含卷積、批歸一化及 SiLu 激活[40]三步操作。CSP 則將上一層的特征圖復制為兩份,分別通過 1×1 卷積將通道數減半以降低計算量。其中一份特征直接連接到該階段末端,另一份送入若干 ResNet 或 CBS 塊進行進一步處理,最后再在通道維度拼接并經過一個 CBS 塊融合特征。SPP(Spatial Pyramid Pooling)模塊[41]由多個不同核尺寸的并行最大池化層組成,用以提取多尺度深層特征。通過堆疊 CSP、CBS 和 SPP 結構,網絡能夠同時獲得低級紋理和高級語義信息。
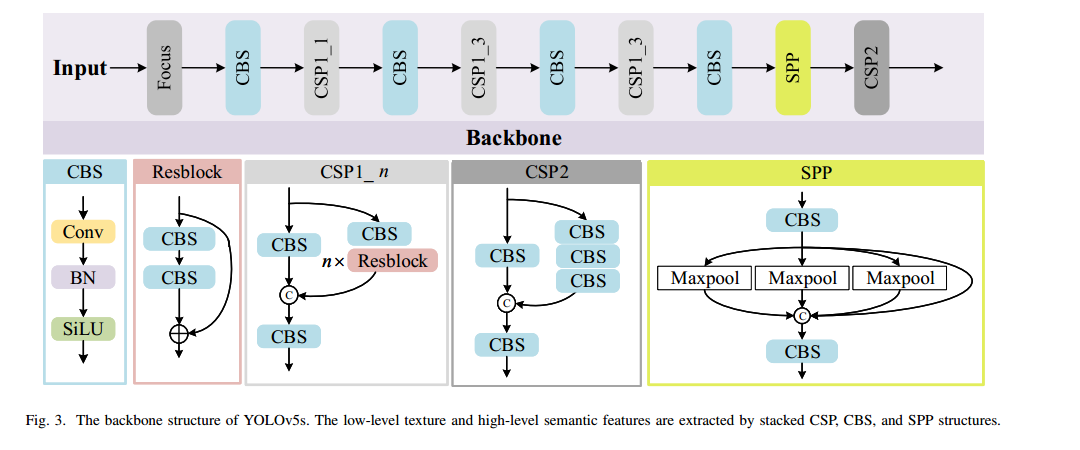
局限 1:YOLOv5 中引入了 Focus 模塊以減少計算量。如圖 2(左下)所示,該模塊將輸入按像素交錯切分并隔行重排,最后在通道維度拼接,實現輸入的下采樣,從而加速訓練與推理。但此操作在一定程度上犧牲了分辨率,容易對小目標檢測精度造成影響。
局限 2:YOLO 主干通過多次步幅為 2 的深度卷積將特征圖尺寸不斷減半,因此多尺度檢測所保留的特征圖遠小于原始輸入圖像。例如,輸入尺寸為 608×608 時,最后三個檢測層的特征圖尺寸僅為 76×76、38×38 和 19×19。低分辨率特征可能導致部分小目標遺漏。
IV. SUPERYOLO 架構
如圖 2 所示,SuperYOLO 在基線結構基礎上引入三項改進:
移除 Focus 模塊并替換為 MF 模塊,避免因下采樣重組而導致的分辨率和精度下降;
選擇高效的像素級融合,在像素層面融合 RGB 與 IR 模態,提取互補信息;
訓練階段添加輔助 SR 模塊,重建高分辨率圖像以指導主干網絡在空間維度學習并保留 HR 信息,推理階段舍棄該分支以免增加計算開銷。
A. 移除 Focus
如第 III 節及圖 2(左下)所示,YOLOv5 主干中的 Focus 模塊通過空間域的間隔采樣將輸入圖像切分重組,從而在通道維度拼接得到下采樣圖像。該操作雖能減少計算量并加速訓練與推理,但會引起分辨率下降,導致小目標的空間信息丟失。鑒于小目標檢測對高分辨率的依賴,我們舍棄 Focus,采用如圖 4 所示的 MF 模塊,以保持輸入分辨率。
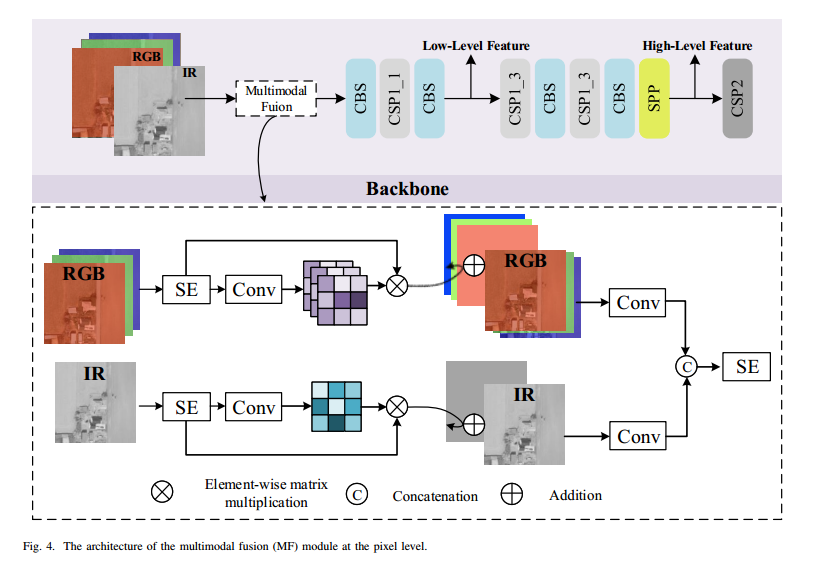
B. 多模態融合
利用更多信息有助于提升目標檢測性能。多模態融合是將來自不同傳感器的信息進行合并的有效途徑。主流融合方法包括決策級、特征級和像素級融合。由于決策級融合需對各模態分支重復檢測,計算開銷過大,故不在 SuperYOLO 中采用。
我們提出一種像素級多模態融合(MF),以對稱緊湊的方式雙向提取不同模態的共享與特色信息。其流程如圖 4 所示:
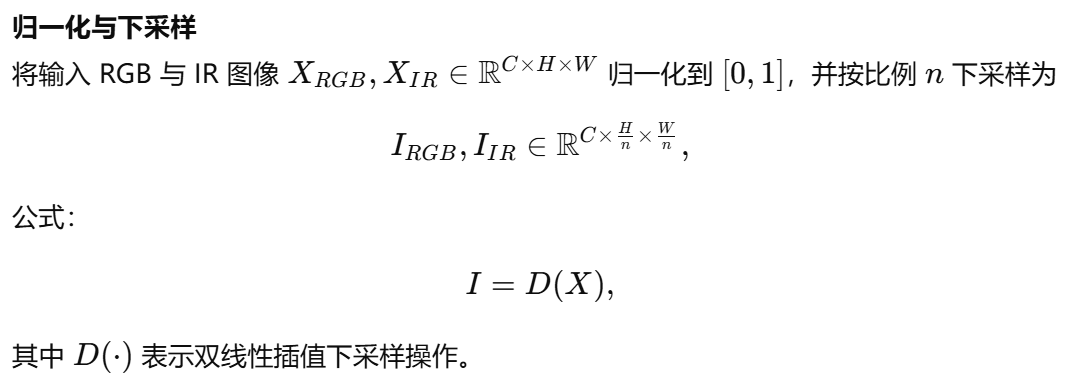


C. 超分辨率(Super Resolution)
如第 III 節所述,骨干網絡中用于多尺度檢測的特征尺寸遠小于原始輸入圖像。現有大多數方法通過上采樣操作來恢復特征尺寸,但由于紋理和模式信息在上采樣過程中丟失,因此在遙感圖像中檢測需要高分辨率(HR)保留的小目標時,效果并不理想。
為了解決這一問題,如圖 2 所示,我們引入了一個輔助的 SR 分支。該分支的設計目標有二:
幫助骨干網絡提取更多的高分辨率信息,以提升檢測性能;
不顯著增加計算量,以保證推理速度。
因此,在推理階段,它能夠在準確性和計算時間之間取得平衡。受 Wang 等人 [38] 研究啟發——其提出的 SR 方法在無需額外開銷的情況下促進了分割任務——我們在框架中引入了一個簡單而高效的 SR 分支。該設計在不增加計算和內存負擔的前提下提升了檢測精度,尤其當輸入分辨率較低(LR)時效果尤為顯著。
具體而言,該 SR 結構可視為一個簡易的編碼-解碼(Encode-Decoder)模型。我們分別選取骨干網絡的低層特征和高層特征,以融合局部紋理/模式信息和語義信息。如圖 4 所示,我們將第 4 模塊和第 9 模塊的輸出分別作為低層和高層特征。編碼器部分將這兩類特征進行集成:
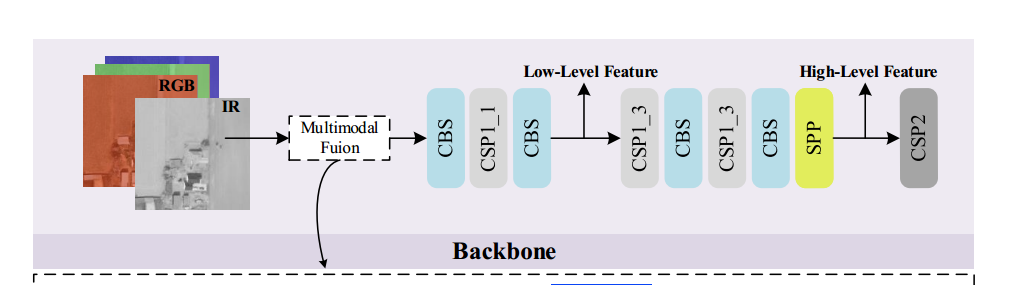
低層特征處理:對低層特征先進行一個 CR 模塊(卷積 + ReLU);
高層特征處理:先通過上采樣操作將其空間尺寸與低層特征對齊,再與低層特征拼接,隨后依次經過兩個 CR 模塊融合。
在解碼器部分,LR 特征被放大到 HR 空間,最終的 SR 輸出尺寸是輸入圖像尺寸的兩倍。如圖 5 所示,解碼器由三個反卷積層(deconvolutional layers)構成。SR 分支通過學習空間維度的映射,將高分辨率信息傳遞回主干分支,從而提升目標檢測性能。此外,我們還嘗試將 EDSR [43] 作為編碼器,以探索 SR 表現及其對檢測性能的影響。
為了更直觀地說明效果,我們在圖 6 中可視化了 YOLOv5s、YOLOv5x 和 SuperYOLO 的骨干特征。所有特征均上采樣至與輸入圖像相同的尺度進行對比。通過對比圖 6 中(c)、(f)與(i);(d)、(g)與(j);(e)、(h)與(k)的成對圖像,可以觀察到在 SR 分支的輔助下,SuperYOLO 所提取的物體結構更清晰、分辨率更高。最終,我們通過 SR 分支在高質量 HR 表征上獲得了豐碩成果,并使用 YOLOv5 的 Head 進行小目標檢測。

圖6所示。相同輸入的YOLOv5s、YOLOv5x和SuperYOLO主干特征級可視化:(a) RGB輸入,(b) IR輸入;?、(d)、(e)為YOLOv5s的特征;(f)、(g)、(h)為YOLOv5x的特征;(i)、(i)、(k)為SuperYOLO的特征。特征被上采樣到與輸入圖像相同的尺度以進行比較。?、(f)和(i)是第一層的特征。(d)、(g)、(j)為底層特征。(e)、(h)、(k)為同一深度各層的高層特征。
D、損失函數

實驗結果


D. 消融實驗
首先,我們通過一系列在驗證集第一折上進行的消融實驗來驗證所提方法的有效性。
基線框架驗證
在表 I 中,我們從層數、參數量和 GFLOPs 三個方面評估了不同基礎檢測框架的模型規模和推理能力,并以 mAP50(IOU = 0.5 下的平均精度)衡量其檢測性能。雖然 YOLOv4 的檢測精度最高,但其層數比 YOLOv5s 多 169 層(393 vs. 224),參數量是 YOLOv5s 的 7.4 倍(52.5M vs. 7.1M),GFLOPs 是 YOLOv5s 的 7.2 倍(38.2 vs. 5.3)。相比之下,YOLOv5s 的 mAP 略低于 YOLOv4 和 YOLOv5m,但其層數、參數量和 GFLOPs 均遠小于其他模型,更易于落地部署并實現實時推理。上述事實驗證了以 YOLOv5s 為基線檢測框架的合理性。
移除 Focus 模塊的影響
如第 IV-A 節所述,Focus 模塊會降低輸入分辨率,不利于遙感圖像中小目標的檢測。我們在四種 YOLOv5 框架(s/m/l/x)上進行了對比實驗(此處結果均在 RGB 與 IR 像素級拼接融合后獲得)。表 II 顯示,移除 Focus 后,YOLOv5s 的 mAP50 從 62.2% 提升至 69.5%,YOLOv5m 從 64.5% 提升至 72.2%,YOLOv5l 從 63.7% 提升至 72.5%,YOLOv5x 從 64.0% 提升至 69.2%。這是因為移除 Focus 后既避免了分辨率下降,又保留了小目標的空間間隔信息,從而減少了漏檢。總體而言,移除 Focus 模塊可讓各框架的 mAP50 提升超過 5%
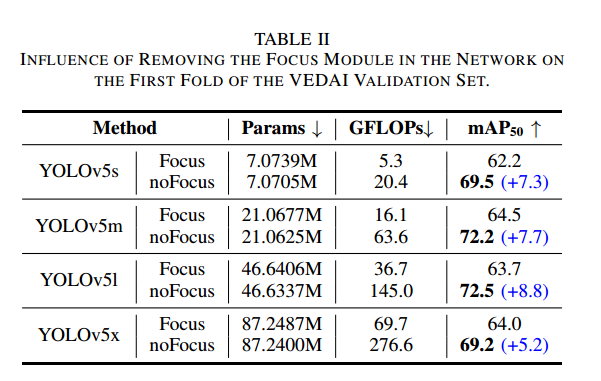
與此同時,移除 Focus 會帶來推理計算量(GFLOPs)的增加:YOLOv5s 從 5.3 增至 20.4,YOLOv5m 從 16.1 增至 63.6,YOLOv5l 從 36.7 增至 145,YOLOv5x 從 69.7 增至 276.6。但即便如此,YOLOv5s-noFocus 的 20.4 GFLOPs 仍低于 YOLOv3(52.8)、YOLOv4(38.2)和 YOLOrs(46.4)的計算量;移除 Focus 后模型參數也略有減少。綜上,為了在檢測更小目標時保留高分辨率,應以檢測精度為優先,采用卷積替代 Focus 模塊。
不同融合方式比較
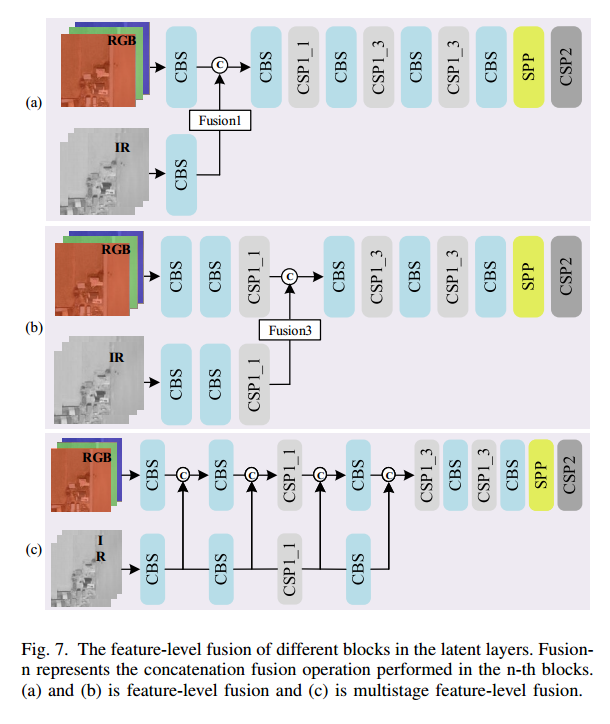
為評估各融合方法的效果,我們在 YOLOv5-noFocus 上比較了五種融合結果(詳見第 IV-B 節與圖 7)。fusion1–fusion4 分別表示在第 1、2、3、4 個塊中進行的像素級拼接融合;在特征級融合中,將 IR 圖像擴展為三通道以與 RGB 保持一致。表 III 中列出了不同方法的參數量、GFLOPs 和 mAP50:
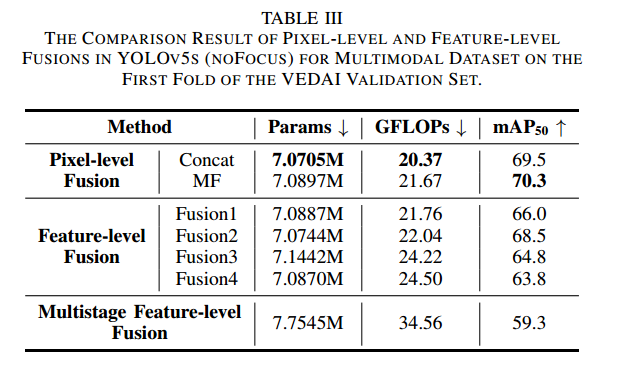
像素級拼接:7.0705M 參數,20.37 GFLOPs,69.5% mAP50
像素級 MF 模塊:7.0897M 參數,21.67 GFLOPs,70.3% mAP50(最佳)
特征級融合的參數量接近像素級融合,原因在于其融合發生在中間層,而非雙模型最前端;且各融合前模塊不同,導致通道數與參數量略異。實驗還對比了多階段特征級融合(圖 7?)與像素級融合:其 mAP50 僅為 59.3%,計算量為 34.56 GFLOPs,參數量 7.7545M,均高于像素級融合。這表明像素級創新融合在保持低計算成本的同時,更能有效提升檢測精度。最終,我們僅采用像素級融合以確保最低的計算開銷。
高分辨率影響
我們在表 IV 中比較了不同訓練/測試分辨率組合的性能。在訓練和測試分辨率相同的情況下,將 YOLOv5s 的輸入從 512→1024 后,mAP50 從 62.2% 提升至 77.7%(增幅 15.5%),GFLOPs 從 5.3 增至 21.3。同理,YOLOv5s-noFocus(1024)較(512)提升 9.8%(79.3% vs. 69.5%)。這說明提高輸入分辨率可同時提高召回率和精度,減少漏檢與誤檢。然而,高分辨率也帶來更高計算量:YOLOv5s 的 GFLOPs 從 5.3→21.3;YOLOv5s-noFocus 從 20.4→81.5。
當訓練/測試分辨率不一致時,mAP50 顯著下降(如 10.6% vs. 62.2%、48.2% vs. 77.7%、13.4% vs. 69.5%、62.9% vs. 79.3%),可能因訓練與測試時目標尺度不匹配,導致預測框尺寸不再適合測試圖像中的目標。
最后,YOLOv5s-noFocus+SR 在 512×512 分辨率下的 mAP50 達到 78.0%,接近 YOLOv5s-noFocus(1024)的 79.3%,且 GFLOPs 僅為 20.4(等同于 LR 512 下的值)。這表明所提 SR 分支能夠在測試階段通過下采樣降低計算量,同時保持與高分辨率輸入相當的檢測精度,充分體現了其優勢。
- 超分辨率分支的影響
表 V 中列出了一些關于 SR 分支的消融實驗結果。與普通的上采樣操作相比,加入超分辨率網絡的 YOLOv5s-noFocus 在 mAP50 上提升了 1.8%。這是因為 SR 網絡是一種可學習的上采樣方式,具有更強的重建能力,能夠幫助骨干網絡提取更豐富的特征以提升檢測效果。
此外,我們在主干網絡中刪除了 PANet 結構及負責中尺度和大尺度目標檢測的兩個檢測頭,因為在諸如 VEDAI 的遙感小目標數據集中,僅使用小尺度檢測頭即可滿足需求。僅保留一個檢測頭后,模型參數量可從 7.0705M 降至 4.8259M,GFLOPs 從 20.37 降至 16.68,同時 mAP50 從 78.0% 提升至 79.0%。
當我們在 SR 分支中用 EDSR 網絡替代三層反卷積解碼器,并用 L1 損失替換原先的 L2 損失時,SR 分支在超分重建任務上的表現得到進一步加強,且對檢測主干的特征提取也起到了更有力的輔助作用,加速了檢測網絡的收斂,從而進一步提升了整體檢測性能。這表明超分辨率與目標檢測兩者在特征提取層面是互補且協同增效的。
表 VI 展示了在不同基線網絡上加入 SR 分支后的精度-復雜度折中效果。與各自的“裸”基線相比,加入 SR 分支后:
YOLOv3+SR 的 mAP50 比 YOLOv3 提升了 9.2%;
YOLOv4+SR 的 mAP50 比 YOLOv4 提升了 3.3%;
YOLOv5s+SR 的 mAP50 比 YOLOv5s 提升了 2.2%。
值得注意的是,SR 分支在推理階段可以被移除,因此并不會引入額外的參數或計算開銷。這一點尤為難得,因為 SR 分支無需對檢測網絡進行大規模重構即可帶來顯著增益。該 SR 分支具備良好的通用性和可擴展性,可直接嵌入到現有的全卷積網絡(FCN)框架中。
E. 與現有方法的比較
圖 8 展示了在多種場景下,YOLO 系列方法與 SuperYOLO 的可視化檢測結果。可以看出,SuperYOLO 能準確檢測出在 YOLOv4、YOLOv5s 和 YOLOv5m 中漏檢、誤分類或模糊識別的目標。遙感圖像中的小目標檢測難度較大,尤其是 Pickup 與 Car、Van 與 Boat 等外觀相似的類別易被混淆。因此,除了定位精度外,提高檢測分類性能在該任務中尤為必要,而所提 SuperYOLO 在此方面表現優異。
表 VII 匯總了 YOLOv3 [47]、YOLOv4 [48]、YOLOv5s-x [19]、YOLOrs [27]、YOLO-Fine [49]、YOLOFusion [50] 及本文 SuperYOLO 的檢測性能。可見,多模態(RGB+IR)模式下的大多數類別 AP 明顯高于單模態(僅 RGB 或 IR),整體 mAP50 亦優于單一模態。這進一步驗證了多模態融合通過信息互補提升目標檢測效果的有效性。然而,多模態融合所帶來的參數與計算量的略微增加,也凸顯了像素級融合優于特征級融合的必要性。
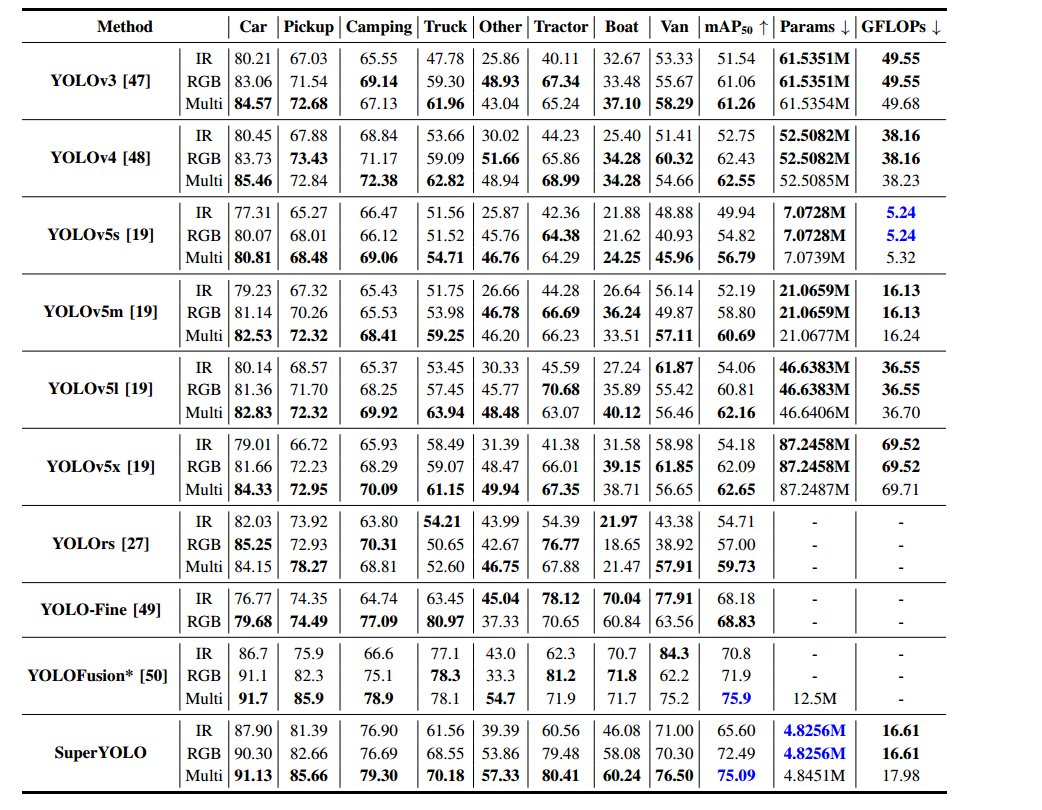
在整體 mAP50 上,SuperYOLO 超越了所有對比框架(YOLOFusion 除外)。YOLOFusion 略勝一籌,因其使用了在 MS COCO [7] 上預訓練的權重,但其參數量約為 SuperYOLO 的三倍。YOLO-Fine 在單模態下表現良好,但缺乏多模態融合技術的開發。值得注意的是,在多模態模式下,SuperYOLO 相比 YOLOv5x 提升了 12.44% 的 mAP50,同時參數量和 GFLOPs 分別僅為 YOLOv5x 的約 1/18 和 1/3.8。
此外,Car、Pickup、Tractor 和 Camping 等訓練樣本最多的類別上,SuperYOLO 的性能提升尤為顯著。YOLOv5s 雖在 GFLOPs 上占優(得益于 Focus 模塊壓縮輸入),卻在小目標檢測上性能欠佳,SuperYOLO 相較于其提升了 18.30% 的 mAP50。總體來看,所提 SuperYOLO 在速度—精度折中方面,相較于最先進的方法展現了優異的性能。
F. 在單模遙感圖像上的泛化能力
目前,雖然遙感領域存在大量的多模態圖像,但因人工標注成本高昂,目標檢測任務的標注數據集仍然匱乏。為驗證所提網絡的泛化能力,我們選取三個單模態大規模數據集——DOTA、DIOR 和 NWPU VHR-10,與多種一階/二階檢測方法進行對比。
DOTA
提出時間:2018 年,專為遙感圖像目標檢測設計。
數據規模:包含 2,806 幅大圖,共 188,282 個標注實例,分 15 類。
原圖尺寸:4,000×4,000 像素;實驗中裁剪為 1,024×1,024,重疊 200 像素。
劃分方式:1/2 原圖作訓練,1/6 作驗證,1/3 作測試;輸入尺寸統一為 512×512。
NWPU VHR-10
提出時間:2016 年。
數據規模:800 幅圖像,其中 650 幅含有目標;采用 520 幅作訓練,130 幅作測試。
類別數:10 類;輸入尺寸固定為 512×512。
DIOR
提出時間:2020 年。
數據規模:23,463 幅圖像,192,472 個實例。
劃分方式:11,725 幅訓練,11,738 幅測試;輸入尺寸統一為 512×512。
為適應上述數據集,我們對訓練配置做了如下調整:NWPU VHR-10 與 DIOR 訓練 150 個 epoch,DOTA 訓練 100 個 epoch;批量大小:DOTA、DIOR 為 16,NWPU 為 8。
對比方法
我們選用了 11 種代表性方法進行對比,包括:
一階段算法:YOLOv3 [47]、FCOS [53]、ATSS [54]、RetinaNet [51]、GFL [52]
兩階段方法:Faster R-CNN [5]
輕量化模型:MobileNetV2 [55]、ShuffleNet [56]
蒸餾方法:ARSD [59]
專為遙感設計:FMSSD [58]、O2DNet [57]
對比結果(表 VIII)
在 DOTA、NWPU VHR-10、DIOR 三個數據集上,SuperYOLO 分別達到了 69.99%、93.30% 和 71.82% 的 mAP50,模型參數(7.70 M、7.68 M、7.70 M)與 GFLOPs(20.89、20.86、20.93)均遠低于其他最先進檢測器。
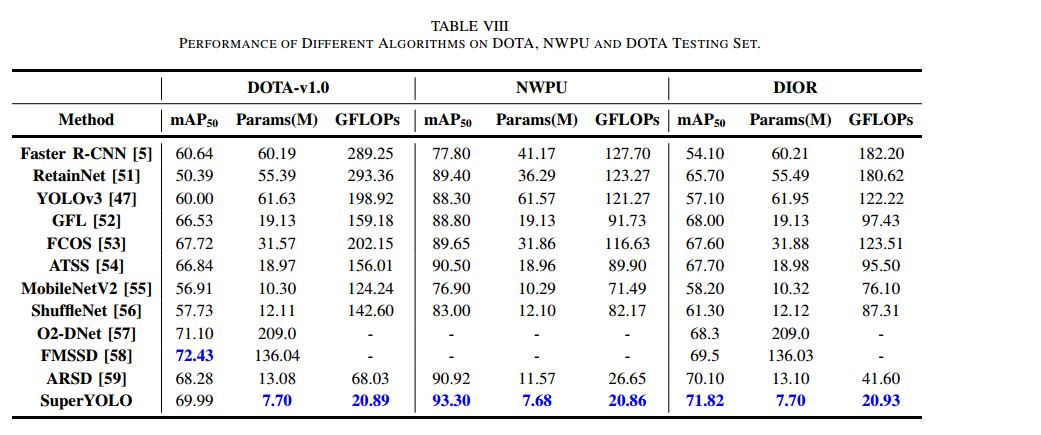
由于這些數據集中存在較大尺度目標(如操場等),我們在 SuperYOLO 中保留了 PANet 結構及三路檢測頭以增強對小、中、大尺度目標的檢測能力,因此其參數量相較于表 VII 中的多模態實驗略有增加。雖然 FMSSD 和 O2DNet 在性能上與我們的輕量級模型相近,但二者的參數量和 GFLOPs 均大幅超出,計算資源開銷巨大。相比之下,SuperYOLO 在檢測效率和準確率之間取得了更優的平衡。
VI. 結論與未來工作
在本文中,我們提出了 SuperYOLO,一種基于廣泛使用的 YOLOv5s 的實時輕量化網絡,旨在提升遙感圖像中小目標的檢測性能。首先,我們通過移除 Focus 模塊以避免分辨率下降,顯著改善了基線網絡,減少了小目標的漏檢;其次,我們研究了多模態融合技術,通過信息互補進一步提升檢測效果;最關鍵的是,我們引入了一個簡單靈活的超分辨率(SR)分支,幫助骨干網絡構建高分辨率特征表示,使得僅憑低分辨率輸入也能輕松識別大背景下的小目標。我們在推理階段移除了 SR 分支,保持原網絡結構和相同的 GFLOPs,實現了不增加計算量的高精度檢測。通過以上多項創新,SuperYOLO 在 VEDAI 數據集上以更低的計算開銷達到了 75.09% 的 mAP50,相較于 YOLOv5s 提升了 18.30%,相比 YOLOv5x 提升了超過 12.44%。
我們的方法在性能和推理效率上均體現了超分辨率技術在遙感任務中的價值,為多模態目標檢測的未來研究開辟了新方向。未來工作中,我們將聚焦于設計更低參數量的高分辨率特征提取模式,以進一步滿足實時性和高精度的雙重需求






)


_進階的開端)


)

)




