目錄
一,模型訓練
1.1 數據集介紹
1.2 CNN模型層結構
1.3 定義CNN模型
1.4 神經網絡的前向傳播過程
1.5 數據預處理
1.6 加載數據
1.7 初始化
1.8 模型訓練過程
1.9 保存模型
二,模型測試
2.1?定義與訓練時相同的CNN模型架構
2.2 圖像的預處理
2.3 預測
三,測試
3.1 測試方法
3.2 測試結果
四 ,總結
五,完整代碼
5.1 模型訓練部分代碼
5.2 模型測試部分代碼
本實驗直觀地體現了CNN對比全連接對于圖像處理的優勢
全連接網絡實現MNIST數字識別實驗如下鏈接:
基于MNIST數據集的手寫數字識別(簡單全連接網絡)-CSDN博客
一,模型訓練
1.1 數據集介紹
????????MNIST 數據集由 60,000 張圖像構成的訓練集和 10,000 張圖像組成的測試集構成,其中的圖像均為 28×28 像素的灰度圖,涵蓋 0 - 9 這 10 個阿拉伯數字,且數字書寫風格、大小、位置多樣。它源于美國國家標準與技術研究所(NIST)的數據集,經過歸一化和中心化處理。MNIST 數據集是圖像識別研究領域的經典數據集,常用于開發和評估圖像識別算法與模型,也是機器學習課程中常用的教學案例,許多高性能卷積神經網絡模型在該數據集測試集上準確率可達 99% 以上,充分展現出其在機器學習領域的重要價值和廣泛應用。
1.2 CNN模型層結構

1.3 定義CNN模型
def __init__(self):super(CNN, self).__init__() # 調用父類的初始化方法self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 定義第一個卷積層,輸入通道1,輸出通道32,卷積核大小3x3self.conv2 = nn.Conv2d(32, 64, kernel_size=3) # 定義第二個卷積層,輸入通道32,輸出通道64,卷積核大小3x3self.pool = nn.MaxPool2d(2, 2) # 定義最大池化層,池化核大小2x2self.dropout1 = nn.Dropout2d(0.25) # 定義第一個Dropout層,隨機丟棄25%的神經元self.fc1 = nn.Linear(64 * 12 * 12, 128) # 定義第一個全連接層,輸入維度64*12*12,輸出維度128self.dropout2 = nn.Dropout(0.5) # 定義第二個Dropout層,隨機丟棄50%的神經元self.fc2 = nn.Linear(128, 10) # 定義輸出層,輸入維度128,輸出維度10(對應10個數字類別)????????定義了一個用于手寫數字識別的卷積神經網絡(CNN)架構,專為 MNIST 等單通道圖像分類任務設計。網絡包含兩個卷積層(Conv1 和 Conv2)進行特征提取,每個卷積層后接 ReLU 激活函數和最大池化層(MaxPool2d)進行下采樣,逐步將 28×28 的輸入圖像轉換為更高層次的抽象特征。為防止過擬合,在卷積層后添加了 Dropout2d (0.25),在全連接層前使用 Dropout (0.5) 增強模型泛化能力。特征提取完成后,通過兩次全連接層(FC1 和 FC2)將卷積輸出的多維特征映射到 10 個類別,最終輸出對應 0-9 數字的分類得分。
1.4 神經網絡的前向傳播過程
def forward(self, x):# 第一層卷積+ReLU激活x = torch.relu(self.conv1(x))# 第二層卷積+ReLU激活+池化x = self.pool(torch.relu(self.conv2(x)))# 應用Dropoutx = self.dropout1(x)# 將多維張量展平為一維向量(64*12*12)x = x.view(-1, 64 * 12 * 12)# 第一個全連接層+ReLU激活x = torch.relu(self.fc1(x))# 應用Dropoutx = self.dropout2(x)# 輸出層,得到未歸一化的預測分數x = self.fc2(x)return x1.5 數據預處理
transform = transforms.Compose([transforms.ToTensor(), # 將圖像轉換為張量transforms.Normalize((0.1307,), (0.3081,)) # 使用MNIST數據集的均值和標準差進行歸一化
])1.6 加載數據
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform) # 加載MNIST訓練數據集
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 創建數據加載器,批次大小為64,打亂數據1.7 初始化
model = CNN() # 創建CNN模型實例
criterion = nn.CrossEntropyLoss() # 定義交叉熵損失函數
optimizer = optim.Adam(model.parameters(), lr=0.001) # 定義Adam優化器,學習率為0.0011.8 模型訓練過程
def train(epochs):model.train() # 設置模型為訓練模式for epoch in range(epochs): # 進行指定輪數的訓練running_loss = 0.0 # 初始化本輪的損失累加器for batch_idx, (data, target) in enumerate(train_loader): # 遍歷數據加載器中的每個批次optimizer.zero_grad() # 梯度清零output = model(data) # 前向傳播,計算模型輸出loss = criterion(output, target) # 計算損失loss.backward() # 反向傳播,計算梯度optimizer.step() # 更新模型參數running_loss += loss.item() # 累加當前批次的損失if batch_idx % 100 == 0: # 每100個批次打印一次損失print(f'Epoch {epoch + 1}, Batch {batch_idx}, Loss: {loss.item():.6f}')print(f'Epoch {epoch + 1} completed, Average Loss: {running_loss / len(train_loader):.6f}') # 打印本輪平均損失1.9 保存模型
if __name__ == '__main__':train(epochs=5) # 調用訓練函數,訓練5輪torch.save(model.state_dict(),'mnist_cnn_model.pth') # 保存模型的參數print("模型已保存為: mnist_cnn_model.pth") # 打印保存模型的信息二,模型測試
2.1?定義與訓練時相同的CNN模型架構
class CNN(nn.Module):def __init__(self):# 調用父類初始化方法super(CNN, self).__init__()# 第一個卷積層:輸入1通道(灰度圖),輸出32通道,卷積核3x3self.conv1 = nn.Conv2d(1, 32, kernel_size=3)# 第二個卷積層:輸入32通道,輸出64通道,卷積核3x3self.conv2 = nn.Conv2d(32, 64, kernel_size=3)# 最大池化層:核大小2x2,步長2self.pool = nn.MaxPool2d(2, 2)# Dropout層:訓練時隨機丟棄25%的神經元,防止過擬合self.dropout1 = nn.Dropout2d(0.25)# 第一個全連接層:輸入維度64*12*12,輸出128self.fc1 = nn.Linear(64 * 12 * 12, 128)# Dropout層:訓練時隨機丟棄50%的神經元self.dropout2 = nn.Dropout(0.5)# 輸出層:輸入128,輸出10個類別(對應0-9數字)self.fc2 = nn.Linear(128, 10)def forward(self, x):# 第一層卷積+ReLU激活x = torch.relu(self.conv1(x))# 第二層卷積+ReLU激活+池化x = self.pool(torch.relu(self.conv2(x)))# 應用Dropoutx = self.dropout1(x)# 將多維張量展平為一維向量(64*12*12)x = x.view(-1, 64 * 12 * 12)# 第一個全連接層+ReLU激活x = torch.relu(self.fc1(x))# 應用Dropoutx = self.dropout2(x)# 輸出層,得到未歸一化的預測分數x = self.fc2(x)return x2.2 圖像的預處理
def preprocess_image(image_path):"""預處理自定義圖像,使其符合模型輸入要求"""# 打開圖像并轉換為灰度圖(單通道)image = Image.open(image_path).convert('L')# 調整圖像大小為28x28像素(如果不是)if image.size != (28, 28):image = image.resize((28, 28), Image.Resampling.LANCZOS)# 將PIL圖像轉換為numpy數組以便處理img_array = np.array(image)# 預處理:二值化和顏色反轉# MNIST數據集中數字為白色(255),背景為黑色(0)if img_array.mean() > 127: # 如果平均像素值大于127,說明可能是黑底白字img_array = 255 - img_array # 顏色反轉# 將numpy數組轉換為PyTorch張量并添加批次維度img_tensor = transforms.ToTensor()(img_array).unsqueeze(0)# 使用MNIST數據集的均值和標準差進行歸一化img_tensor = transforms.Normalize((0.1307,), (0.3081,))(img_tensor)return image, img_tensor # 返回原始圖像和處理后的張量2.3 預測
def predict_digit(image_path):"""預測自定義圖像中的數字"""# 創建模型實例model = CNN()# 加載預訓練模型權重model.load_state_dict(torch.load('mnist_cnn_model.pth'))# 設置模型為評估模式(關閉Dropout等訓練特有的層)model.eval()# 預處理輸入圖像original_img, img_tensor = preprocess_image(image_path)# 預測過程,不計算梯度以提高效率with torch.no_grad():# 前向傳播,得到模型輸出output = model(img_tensor)# 應用softmax將輸出轉換為概率分布probabilities = torch.softmax(output, dim=1)# 獲取最高概率及其對應的數字類別confidence, predicted = torch.max(probabilities, 1)三,測試
3.1 測試方法
如上文代碼所示,我這里用的測試圖片是自己定義圖片,使用電腦自帶的paint繪圖軟件,設置畫布為28*28像素,黑底白字,手動寫入一個字進行預測
3.2 測試結果

????????預測5的置信度為99.94%

????????預測0的置信度為99.99%
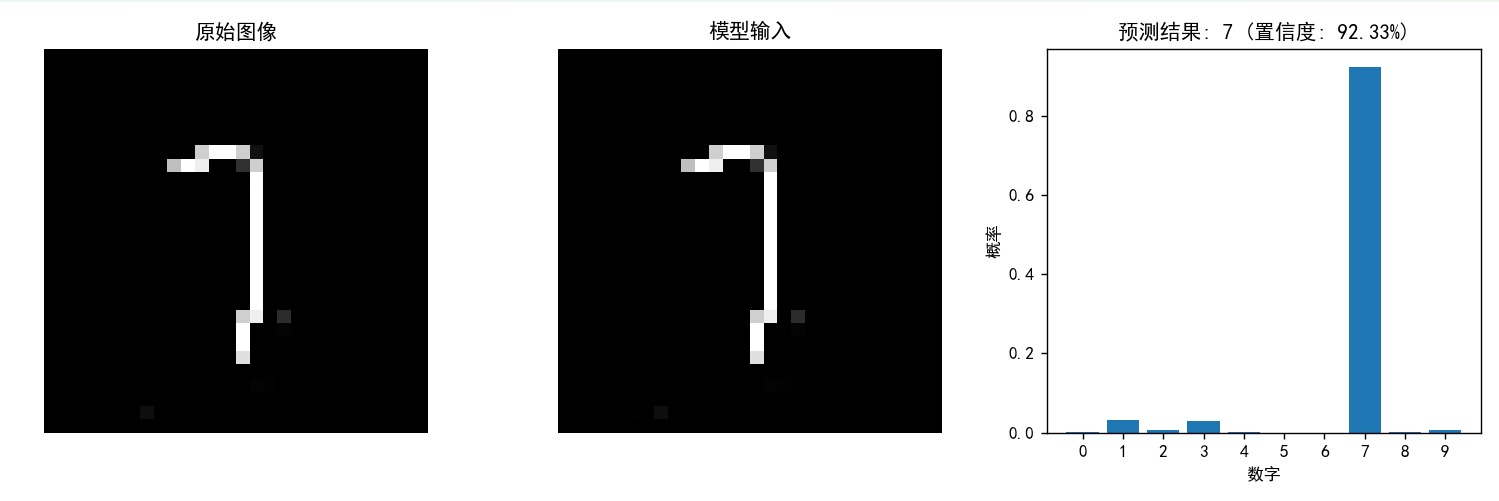
????????預測7的置信度為92.33%(盡管這個“7”寫的很不好但是并不影響預測結果)
四 ,總結
????????卷積神經網絡(CNN)在圖像分類中相比全連接網絡(FNN)具有顯著優勢:通過局部連接和權重共享機制,CNN 大幅減少參數量,避免全連接網絡因輸入維度高導致的參數爆炸問題,計算效率更高且不易過擬合;CNN 通過卷積核逐層提取圖像的局部特征(如邊緣、紋理),結合池化層的平移不變性,能自動學習從低級到高級的層級化語義特征,而全連接網絡將圖像展平為向量,完全忽略像素空間關系,需依賴人工特征或大量數據學習;此外,CNN 的卷積結構天然具備正則化效果,對數據量需求更低,訓練速度更快,且通過可視化卷積核和特征圖可直觀解釋其對圖像模式的捕捉過程,而全連接網絡的特征表示缺乏可解釋性。
五,完整代碼
5.1 模型訓練部分代碼
import torch # 導入PyTorch庫,用于深度學習
import torch.nn as nn # 導入PyTorch的神經網絡模塊
import torch.optim as optim # 導入PyTorch的優化器模塊
from torchvision import datasets, transforms # 從torchvision導入數據集和數據變換模塊
from torch.utils.data import DataLoader # 導入數據加載器模塊# 定義CNN模型
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 調用父類的初始化方法self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 定義第一個卷積層,輸入通道1,輸出通道32,卷積核大小3x3self.conv2 = nn.Conv2d(32, 64, kernel_size=3) # 定義第二個卷積層,輸入通道32,輸出通道64,卷積核大小3x3self.pool = nn.MaxPool2d(2, 2) # 定義最大池化層,池化核大小2x2self.dropout1 = nn.Dropout2d(0.25) # 定義第一個Dropout層,隨機丟棄25%的神經元self.fc1 = nn.Linear(64 * 12 * 12, 128) # 定義第一個全連接層,輸入維度64*12*12,輸出維度128self.dropout2 = nn.Dropout(0.5) # 定義第二個Dropout層,隨機丟棄50%的神經元self.fc2 = nn.Linear(128, 10) # 定義輸出層,輸入維度128,輸出維度10(對應10個數字類別)def forward(self, x):x = torch.relu(self.conv1(x)) # 對第一個卷積層的輸出應用ReLU激活函數x = self.pool(torch.relu(self.conv2(x))) # 對第二個卷積層的輸出應用ReLU激活函數,然后進行最大池化x = self.dropout1(x) # 應用第一個Dropout層x = x.view(-1, 64 * 12 * 12) # 將張量展平為一維向量,-1表示自動推斷批次維度x = torch.relu(self.fc1(x)) # 對第一個全連接層的輸出應用ReLU激活函數x = self.dropout2(x) # 應用第二個Dropout層x = self.fc2(x) # 通過輸出層return x # 返回模型的輸出# 數據預處理
transform = transforms.Compose([transforms.ToTensor(), # 將圖像轉換為張量transforms.Normalize((0.1307,), (0.3081,)) # 使用MNIST數據集的均值和標準差進行歸一化
])# 加載數據
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform) # 加載MNIST訓練數據集
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 創建數據加載器,批次大小為64,打亂數據# 初始化模型、損失函數和優化器
model = CNN() # 創建CNN模型實例
criterion = nn.CrossEntropyLoss() # 定義交叉熵損失函數
optimizer = optim.Adam(model.parameters(), lr=0.001) # 定義Adam優化器,學習率為0.001# 訓練模型
def train(epochs):model.train() # 設置模型為訓練模式for epoch in range(epochs): # 進行指定輪數的訓練running_loss = 0.0 # 初始化本輪的損失累加器for batch_idx, (data, target) in enumerate(train_loader): # 遍歷數據加載器中的每個批次optimizer.zero_grad() # 梯度清零output = model(data) # 前向傳播,計算模型輸出loss = criterion(output, target) # 計算損失loss.backward() # 反向傳播,計算梯度optimizer.step() # 更新模型參數running_loss += loss.item() # 累加當前批次的損失if batch_idx % 100 == 0: # 每100個批次打印一次損失print(f'Epoch {epoch + 1}, Batch {batch_idx}, Loss: {loss.item():.6f}')print(f'Epoch {epoch + 1} completed, Average Loss: {running_loss / len(train_loader):.6f}') # 打印本輪平均損失# 執行訓練并保存模型
if __name__ == '__main__':train(epochs=5) # 調用訓練函數,訓練5輪torch.save(model.state_dict(),'mnist_cnn_model.pth') # 保存模型的參數print("模型已保存為: mnist_cnn_model.pth") # 打印保存模型的信息5.2 模型測試部分代碼
# 導入PyTorch深度學習框架及其神經網絡模塊
import torch
import torch.nn as nn
# 導入torchvision的圖像變換工具
from torchvision import transforms
# 導入PIL庫用于圖像處理
from PIL import Image
# 導入matplotlib用于可視化
import matplotlib.pyplot as plt
# 導入numpy用于數值計算
import numpy as np
# 導入os模塊用于文件和路徑操作
import os# 設置matplotlib的字體,確保中文正常顯示
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Micro Hei', 'Heiti TC']
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題# 定義與訓練時相同的CNN模型架構
class CNN(nn.Module):def __init__(self):# 調用父類初始化方法super(CNN, self).__init__()# 第一個卷積層:輸入1通道(灰度圖),輸出32通道,卷積核3x3self.conv1 = nn.Conv2d(1, 32, kernel_size=3)# 第二個卷積層:輸入32通道,輸出64通道,卷積核3x3self.conv2 = nn.Conv2d(32, 64, kernel_size=3)# 最大池化層:核大小2x2,步長2self.pool = nn.MaxPool2d(2, 2)# Dropout層:訓練時隨機丟棄25%的神經元,防止過擬合self.dropout1 = nn.Dropout2d(0.25)# 第一個全連接層:輸入維度64*12*12,輸出128self.fc1 = nn.Linear(64 * 12 * 12, 128)# Dropout層:訓練時隨機丟棄50%的神經元self.dropout2 = nn.Dropout(0.5)# 輸出層:輸入128,輸出10個類別(對應0-9數字)self.fc2 = nn.Linear(128, 10)def forward(self, x):# 第一層卷積+ReLU激活x = torch.relu(self.conv1(x))# 第二層卷積+ReLU激活+池化x = self.pool(torch.relu(self.conv2(x)))# 應用Dropoutx = self.dropout1(x)# 將多維張量展平為一維向量(64*12*12)x = x.view(-1, 64 * 12 * 12)# 第一個全連接層+ReLU激活x = torch.relu(self.fc1(x))# 應用Dropoutx = self.dropout2(x)# 輸出層,得到未歸一化的預測分數x = self.fc2(x)return xdef preprocess_image(image_path):"""預處理自定義圖像,使其符合模型輸入要求"""# 打開圖像并轉換為灰度圖(單通道)image = Image.open(image_path).convert('L')# 調整圖像大小為28x28像素(如果不是)if image.size != (28, 28):image = image.resize((28, 28), Image.Resampling.LANCZOS)# 將PIL圖像轉換為numpy數組以便處理img_array = np.array(image)# 預處理:二值化和顏色反轉# MNIST數據集中數字為白色(255),背景為黑色(0)if img_array.mean() > 127: # 如果平均像素值大于127,說明可能是黑底白字img_array = 255 - img_array # 顏色反轉# 將numpy數組轉換為PyTorch張量并添加批次維度img_tensor = transforms.ToTensor()(img_array).unsqueeze(0)# 使用MNIST數據集的均值和標準差進行歸一化img_tensor = transforms.Normalize((0.1307,), (0.3081,))(img_tensor)return image, img_tensor # 返回原始圖像和處理后的張量def predict_digit(image_path):"""預測自定義圖像中的數字"""# 創建模型實例model = CNN()# 加載預訓練模型權重model.load_state_dict(torch.load('mnist_cnn_model.pth'))# 設置模型為評估模式(關閉Dropout等訓練特有的層)model.eval()# 預處理輸入圖像original_img, img_tensor = preprocess_image(image_path)# 預測過程,不計算梯度以提高效率with torch.no_grad():# 前向傳播,得到模型輸出output = model(img_tensor)# 應用softmax將輸出轉換為概率分布probabilities = torch.softmax(output, dim=1)# 獲取最高概率及其對應的數字類別confidence, predicted = torch.max(probabilities, 1)# 創建可視化窗口plt.figure(figsize=(12, 4))# 子圖1:顯示原始輸入圖像plt.subplot(1, 3, 1)plt.imshow(original_img, cmap='gray')plt.title('原始圖像')plt.axis('off') # 關閉坐標軸顯示# 子圖2:顯示模型實際輸入(歸一化后的圖像)plt.subplot(1, 3, 2)plt.imshow(img_tensor[0][0], cmap='gray')plt.title('模型輸入')plt.axis('off')# 子圖3:顯示預測結果和置信度條形圖plt.subplot(1, 3, 3)plt.bar(range(10), probabilities[0].numpy())plt.xticks(range(10)) # 設置x軸刻度為0-9plt.title(f'預測結果: {predicted.item()} (置信度: {confidence.item() * 100:.2f}%)')plt.xlabel('數字')plt.ylabel('概率')# 自動調整子圖布局plt.tight_layout()# 顯示圖像plt.show()# 返回預測結果和置信度return predicted.item(), confidence.item() * 100if __name__ == '__main__':# 指定要測試的圖像路徑,請替換為實際路徑image_path = r"C:\Users\10532\Desktop\Study\test\Untitled.png"# 檢查文件是否存在if not os.path.exists(image_path):print(f"錯誤:文件 '{image_path}' 不存在")else:# 執行預測digit, confidence = predict_digit(image_path)print(f"預測結果: {digit},置信度: {confidence:.2f}%")





配置和持久化)
![[ctfshow web入門] web77](http://pic.xiahunao.cn/[ctfshow web入門] web77)


 詳解)


![WeakAuras Lua Script [TOC BOSS 5 - Anub‘arak ]](http://pic.xiahunao.cn/WeakAuras Lua Script [TOC BOSS 5 - Anub‘arak ])





