機器學習 — KNN算法
文章目錄
- 機器學習 --- KNN算法
- 一,sklearn機器學習概述
- 二,KNN算法---分類
- 2.1樣本距離判斷
- 2.2 KNN算法原理
- 2.3 KNN缺點
- 2.4 API
- 2.5 使用sklearn中鳶尾花數據集實現KNN
一,sklearn機器學習概述
獲取數據、數據處理、特征工程后,就可以交給預估器進行機器學習,流程和常用API如下。
1.實例化預估器(估計器)對象(estimator), 預估器對象很多,都是estimator的子類(1)用于分類的預估器sklearn.neighbors.KNeighborsClassifier k-近鄰sklearn.naive_bayes.MultinomialNB 貝葉斯sklearn.linear_model.LogisticRegressioon 邏輯回歸sklearn.tree.DecisionTreeClassifier 決策樹sklearn.ensemble.RandomForestClassifier 隨機森林(2)用于回歸的預估器sklearn.linear_model.LinearRegression線性回歸sklearn.linear_model.Ridge嶺回歸(3)用于無監督學習的預估器sklearn.cluster.KMeans 聚類
2.進行訓練,訓練結束后生成模型estimator.fit(x_train, y_train)
3.模型評估(1)方式1,直接對比y_predict = estimator.predict(x_test)y_test == y_predict(2)方式2, 計算準確率accuracy = estimator.score(x_test, y_test)
4.使用模型(預測)
y_predict = estimator.predict(x_true)
二,KNN算法—分類
2.1樣本距離判斷
- 歐氏距離
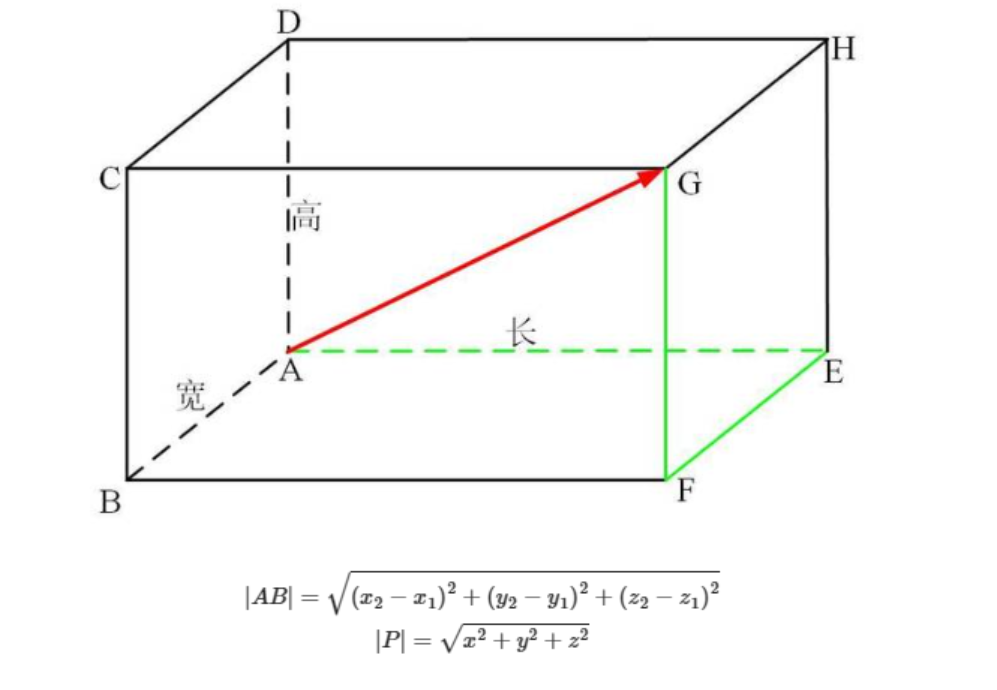
- 曼哈頓距離
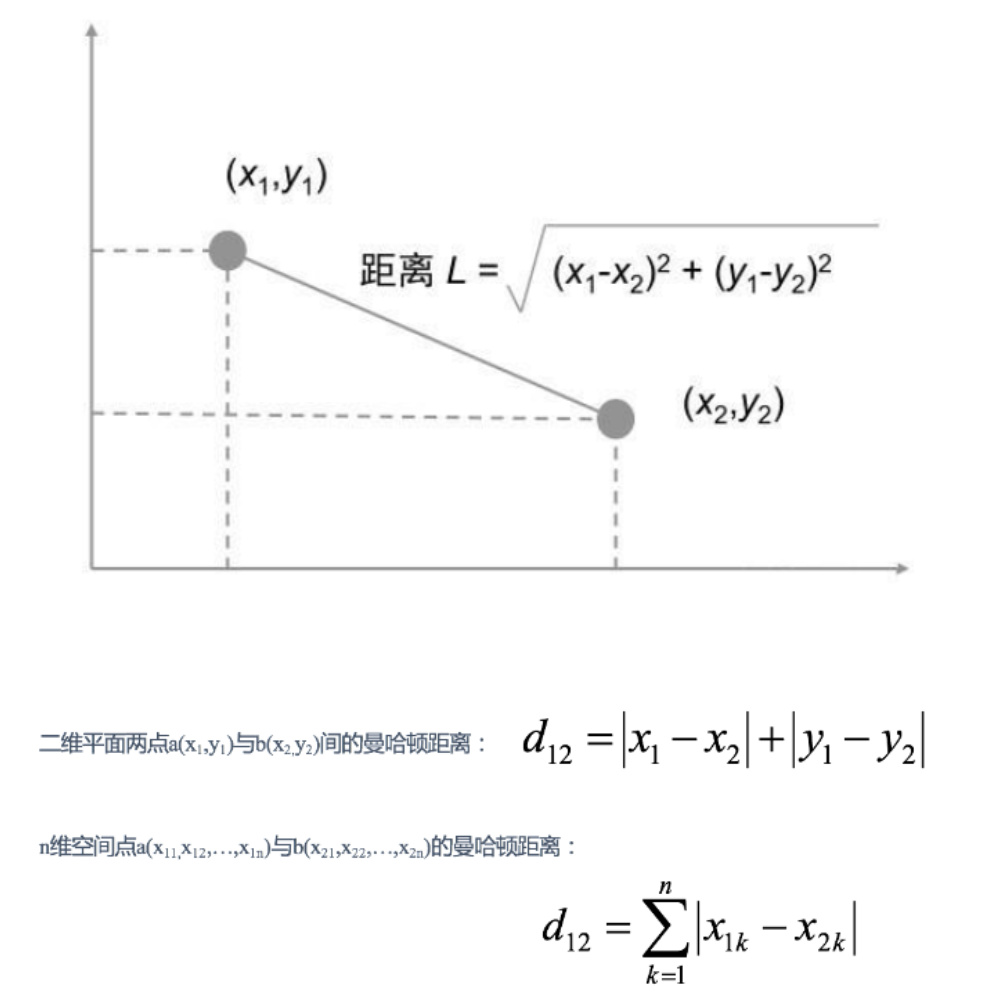
2.2 KNN算法原理
K-近鄰算法(K-Nearest Neighbors,簡稱KNN),根據K個鄰居樣本的類別來判斷當前樣本的類別;
如果一個樣本在特征空間中的k個最相似(最鄰近)樣本中的大多數屬于某個類別,則該類本也屬于這個類別
比如: 有10000個樣本,選出7個到樣本A的距離最近的,然后這7個樣本中假設:類別1有2個,類別2有3個,類別3有2個.那么就認為A樣本屬于類別2,因為它的7個鄰居中 類別2最多(近朱者赤近墨者黑)
2.3 KNN缺點
? 對于大規模數據集,計算量大,因為需要計算測試樣本與所有訓練樣本的距離。
? 對于高維數據,距離度量可能變得不那么有意義,這就是所謂的“維度災難”
? 需要選擇合適的k值和距離度量,這可能需要一些實驗和調整
2.4 API
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm='auto')
參數:
(1)n_neighbors: int, default=5, 默認情況下用于kneighbors查詢的近鄰數,就是K
(2)algorithm:{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’。找到近鄰的方式,注意不是計算距離 的方式,與機器學習算法沒有什么關系,開發中請使用默認值'auto'
方法:(1) fit(x, y) 使用X作為訓練數據和y作為目標數據 (2) predict(X) 預測提供的數據,得到預測數據 2.5 使用sklearn中鳶尾花數據集實現KNN
# 引入數據集
from sklearn.datasets import load_iris
# 引入KNN算法
from sklearn.neighbors import KNeighborsClassifier
# 引入標準化工具
from sklearn.preprocessing import StandardScaler
#引入數據集劃分
from sklearn.model_selection import train_test_split
#引入joblib
import joblib#訓練函數
def train():#加載數據iris = load_iris()#加載鳶尾花數據集X = iris.data#鳶尾花特征數據y = iris.target#鳶尾花標簽數據#數據集劃分X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=22)#數據標準化transfer = StandardScaler()X_train = transfer.fit_transform(X_train)#創建knn模型model = KNeighborsClassifier(n_neighbors=5)#使用訓練集訓練模型model.fit(X_train,y_train)#測試集的預測結果X_test = transfer.transform(X_test)score = model.score(X_test,y_test)print("準確率:",score)#保存模型if score > 0.9:joblib.dump(model,"./model/knn.pkl")joblib.dump(transfer,"./model/transfer.pkl")else:print("模型效果不佳,重新訓練")# 推理函數
# 新數據預測
def detect():#加載數據model = joblib.load("./model/knn.pkl")transfer = joblib.load("./model/transfer.pkl")#新數據推理x_new = [[1,2,3,4]]x_new = transfer.transform(x_new)y_pred = model.predict(x_new)print("預測結果:",y_pred)if __name__ == '__main__':train()detect()
準確率: 0.9333333333333333
預測結果: [1]


毛子整潔架構(分布式日志/Redis緩存/OutBox Pattern))





![[6-8] 編碼器接口測速 江協科技學習筆記(7個知識點)](http://pic.xiahunao.cn/[6-8] 編碼器接口測速 江協科技學習筆記(7個知識點))










)