前言:
? ? ? 在人工智能領域,視覺語言模型的競爭愈發激烈。GPT-4o 一直是該領域的佼佼者,但英偉達的 Eagle 2.5 橫空出世,憑借其 80 億參數的精簡架構,在長上下文多模態任務中表現出色,尤其是在視頻和高分辨率圖像理解方面。其創新的訓練策略和優化架構使其成為 GPT-4o 的有力競爭者,有望重塑視覺 AI 的行業標準。這場技術對決表明,人工智能的未來不僅在于規模,更在于設
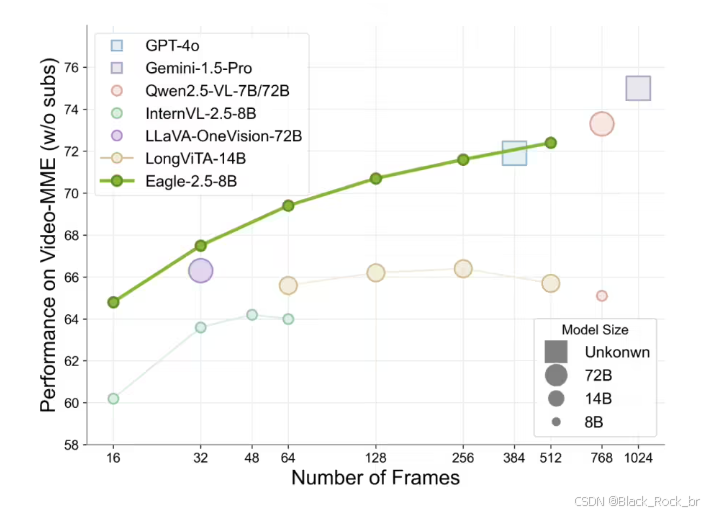
Eagle 2.5 專注于處理大規模視頻和圖像,尤其在高分辨率圖像和長視頻序列方面表現出色。盡管其參數規模僅為 8B,但在 Video-MME 基準測試(512 幀輸入)中,它取得了 72.4% 的高分,與 Qwen2.5-VL-72B 和 InternVL2.5-78B 等更大規模的模型不相上下。
1.從訓練方法看 Eagle 2.5
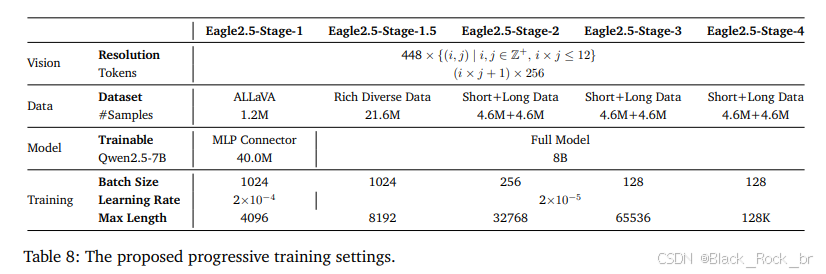
Eagle 2.5 的卓越表現得益于兩項關鍵訓練策略:信息優先采樣(Information-First Sampling) 和 漸進式后訓練(Progressive Post-Training) 。這些創新方法顯著提升了模型在視覺與語言任務中的性能。
信息優先采樣:優化輸入質量的關鍵
信息優先采樣通過兩項核心技術實現了對視覺和文本輸入的精細化處理:
- 圖像區域保留(IAP) :該技術能夠智能地保留超過 60% 的原始圖像區域,同時有效減少寬高比失真,確保圖像的關鍵細節得以完整保留。
- 自動降級采樣(ADS) :根據上下文長度動態調整視覺與文本輸入的比例,在保證文本完整性的同時,優化視覺細節的表現,使模型能夠更好地平衡多模態輸入。
漸進式后訓練:擴展上下文適應能力
漸進式后訓練是一種逐步擴展模型上下文窗口的訓練方法,從初始的 32K token 擴展到最終的 128K token。這種漸進式的訓練方式使模型能夠在不同長度的輸入中保持穩定的性能,避免了因過擬合單一上下文范圍而導致的性能瓶頸。
多模態架構的協同支持
為了進一步增強模型的靈活性和適應性,Eagle 2.5 還結合了 SigLIP 視覺編碼器 和 MLP 投影層 。這些組件共同作用,確保模型在多樣化任務中表現出色,無論是復雜的視覺理解還是跨模態生成任務,都能游刃有余。
2.預訓練定制數據集
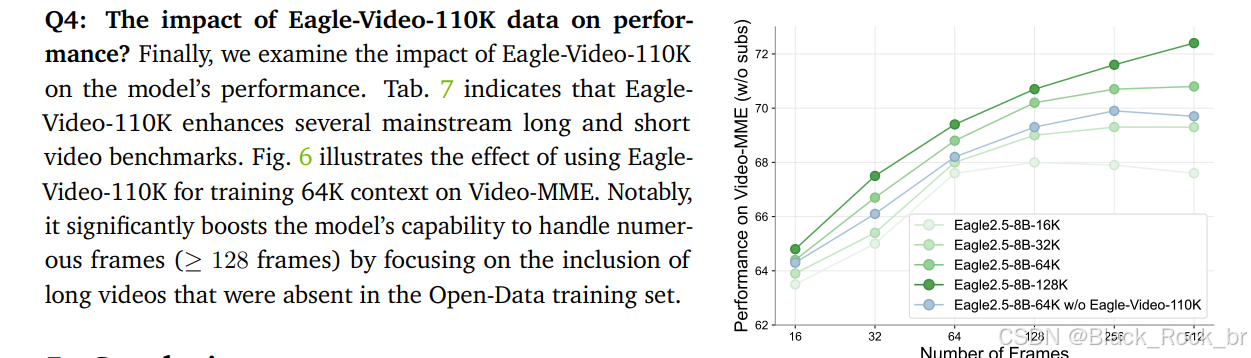
Eagle 2.5 的訓練數據管道整合了開源資源和專為長視頻理解設計的定制數據集 Eagle-Video-110K,并采用了雙重標注方式。

在自上而下的方法中,通過故事級分割結合人類標注的章節元數據和 GPT-4 生成的密集描述來標注數據;而在自下而上的方法中,則利用 GPT-4o 為短片段生成問答對,以捕捉時空細節。
數據集通過余弦相似度篩選,注重多樣性而非冗余,確保敘事連貫性和細粒度標注,從而顯著提升了模型在高幀數(≥128幀)任務中的表現。
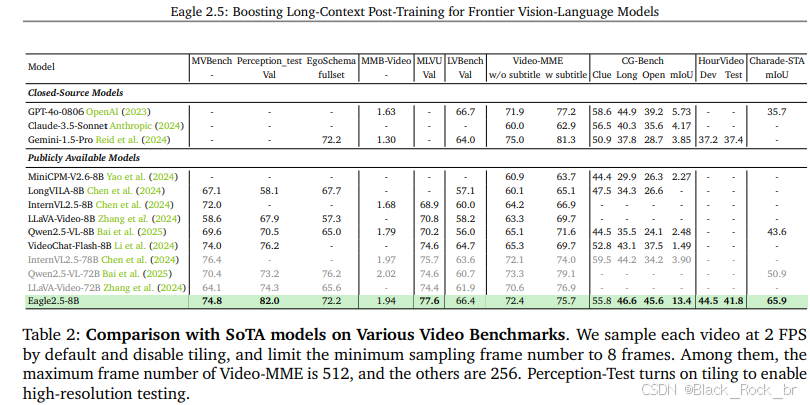
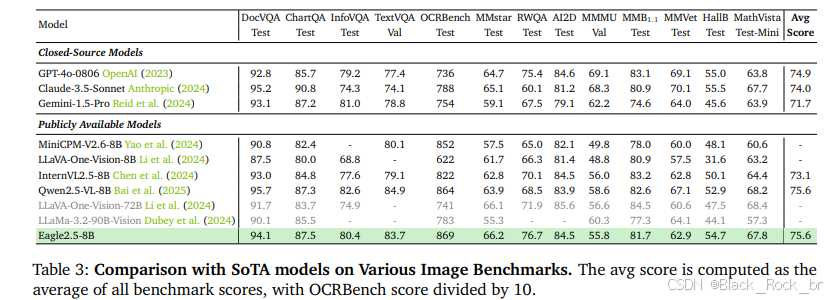
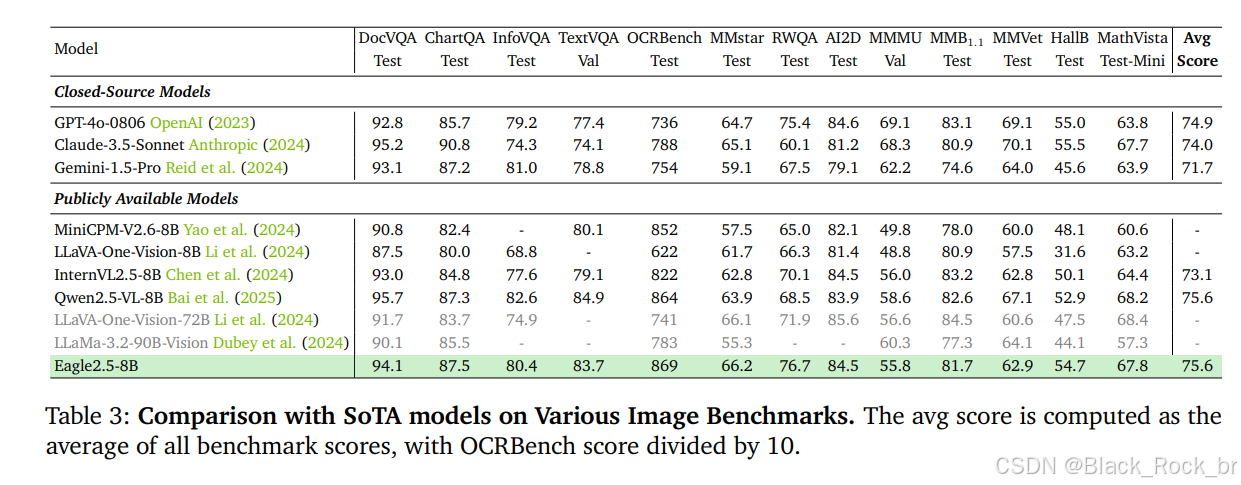
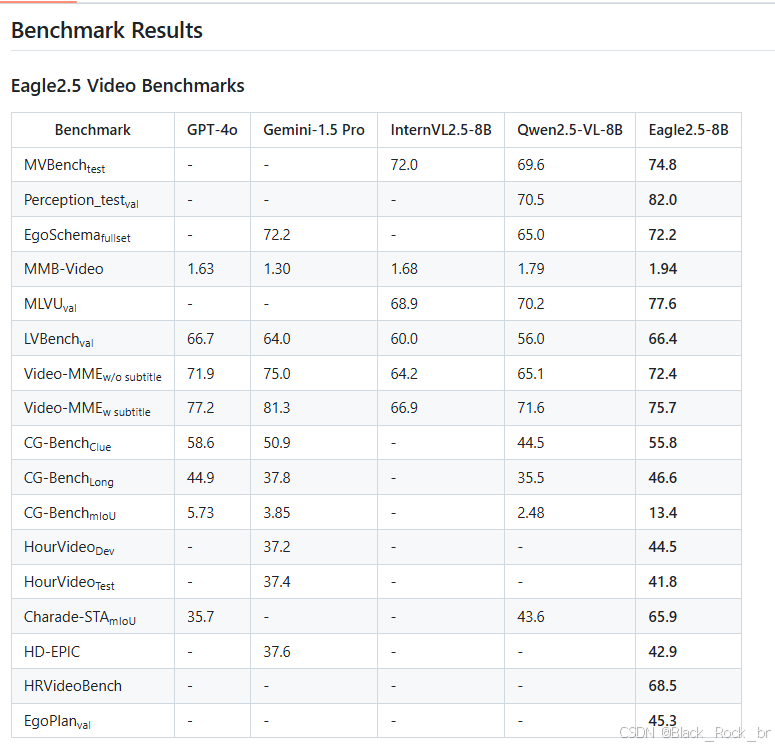
3.性能表現
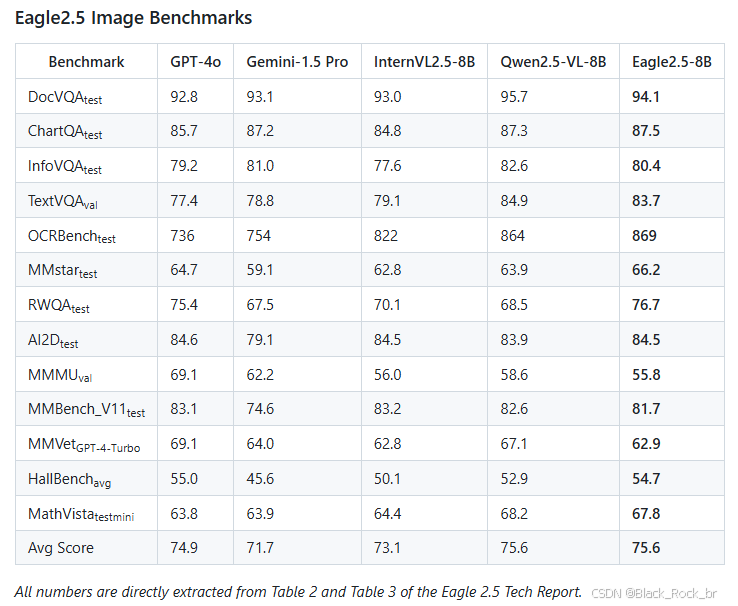
Eagle 2.5-8B 在視頻和圖像理解的多項任務中表現優異。在視頻基準測試中,其 MVBench 得分為 74.8,MLVU 為 77.6,LongVideoBench 為 66.4;在圖像基準測試中,DocVQA 得分為 94.1,ChartQA 為 87.5,InfoVQA 為 80.4。
消融研究表明,移除 IAP 和 ADS 會導致性能下降,而加入漸進式訓練和 Eagle-Video-110K 數據集則能帶來更穩定的性能提升。

 ?
?
未來展望
Eagle 2.5 的推出不僅標志著英偉達在多模態學習領域的突破,也為整個人工智能行業樹立了新的標桿。其高效的參數規模和卓越的性能使其在資源受限的環境中更具優勢,適用于醫療影像分析、自動駕駛輔助系統、虛擬助手開發等多個領域。隨著硬件進步和跨學科合作的深化,Eagle 2.5 所代表的多模態學習方向將引領行業邁向更高效率和更廣泛應用的新階段。
綜上所述,Eagle 2.5 以其創新的訓練策略、優化的數據集設計和卓越的性能表現,成功地在視覺語言模型領域與 GPT-4o 展開了競爭,為未來的人工智能發展提供了新的方向和思路。
link:https://arxiv.org/pdf/2504.15271






)










)

