Title
題目
Integrating language into medical visual recognition and reasoning: A survey
將語言融入醫學視覺識別與推理:一項綜述?
01
文獻速遞介紹
檢測以及語義分割)是無數定量疾病評估和治療規劃的基石(利特延斯等人,2017),而像視覺問答(VQA)這樣的醫學視覺推理能夠對復雜的視覺模式、關系和背景進行解讀和理解,這對于準確的診斷決策至關重要(林等人,2023c)。盡管端到端的深度神經網絡(DNNs)在視覺識別和推理任務中取得了顯著成就(何等人,2016;羅內貝格爾等人,2015;多索維茨基等人,2020;基里洛夫等人,2023)。然而,在醫學視覺任務中,仍然存在一個長期的挑戰,這是由兩個限制因素導致的,即大規模、特定任務、專家標注數據的費力收集,以及深度神經網絡僅基于視覺信息的理解能力有限(利特延斯等人,2017)。 由于隱私保護和倫理方面的考量,大規模的醫學影像數據不容易公開獲取。同時,獲取一些醫學任務(如語義分割和目標檢測)的密集標注既耗費人力又耗時。事實上,與密集的專家標注相比,收集醫學評估報告相對更容易。通常,醫學影像總是附有相應的醫學報告(什雷斯塔等人,2023)。因此,將文本監督融入視覺任務是很自然的。例如,視覺語言預訓練(VLP)旨在探索一種數據高效的文本監督預訓練方法,已在廣泛的視覺任務中展示出巨大的有效性(拉德福德等人,2021;黃等人,2021;王等人,2022b;張等人,2022a;卡雷等人,2021)。在這個新范式下,深度神經網絡可以首先使用帶有現成臨床報告的大規模醫學影像進行預訓練。隨后,視覺語言預訓練模型使用特定任務的標注訓練數據進行微調。從報告中獲取的文本知識,結合特定任務的微調,有助于視覺模型快速收斂,并在下游醫學任務(包括分類(周等人,2022b;張等人,2023d;王等人,2023c)、分割(朱等人,2023;羅等人,2023)和檢測(郭等人,2023))中表現良好。 另一方面,除了視覺語言預訓練,還有更多基于文本引導的醫學任務值得探索。僅專注于視覺信息的深度神經網絡有時無法獲取足夠的信息來準確理解復雜醫學影像的語義。從醫學領域的多模態學習(李等人,2023b;曾等人,2023;李等人,2023a)和多視圖學習(卞等人,2023;江等人,2022)中獲取靈感,多模態學習結合各種類型的數據,可以提供對背景更全面的理解,互補的圖像和文本有助于模型更準確地識別病理。最近的大量研究(鐘等人,2023;秦等人,2022;市野瀬等人,2023;孫等人,2023)強調了將文本描述融入醫學視覺識別任務(包括人類觀察和專家知識)的益處。 遺憾的是,研究界缺乏一個系統的綜述來闡明關于醫學視覺語言模型在視覺感知和推理任務方面的現有研究。雖然現有的綜述(肖等人,2024;哈索克和拉蘇爾,2024)關注醫學大語言模型(LLMs)和多模態大語言模型(MLLMs)在醫學診斷和報告生成等文本任務中的應用,但我們的綜述特別強調視覺任務,類似于張等人(2024)的綜述。此外,近期的綜述(趙等人,2023b;陳等人,2023b;什雷斯塔等人,2023)僅關注醫學視覺語言預訓練及其在下游任務中的應用。然而,我們認為視覺語言模型的潛力不止于此,更多關于將文本知識融入醫學視覺任務的研究需要進行總結和討論。盡管這些方法高度靈活且多樣,但它們對于提高診斷的準確性和可靠性,以及改善臨床環境中模型的可解釋性至關重要。基于對視覺任務的視覺語言模型的首次綜述(張等人,2024),我們旨在通過對醫學視覺語言模型在一系列視覺識別和推理任務中的研究進行全面綜述來填補這一空白。如圖1所示,我們將綜述分為7個部分,我們的討論主要涉及視覺語言模型的方法、醫學數據集、挑戰以及未來的研究方向。 總之,本綜述的主要貢獻如下: - 對用于視覺任務的前沿醫學視覺語言模型進行了綜述。據我們所知,這是首個專注于醫學視覺語言模型的綜述,重點關注如何將文本數據有效地融入視覺任務,而不僅僅是視覺語言預訓練。 - 我們對醫學視覺語言模型的方法進行了分類,并在表格中呈現了這些方法的關鍵信息,旨在通過提供結構良好的內容來幫助讀者理解。 - 此外,我們提供了公開可用的用于視覺語言模型應用的醫學圖像-文本數據集的匯編,以簡潔的方式對各種方法進行比較。 - 最后,討論了視覺語言模型在醫學領域的挑戰和未來展望。
Abatract
摘要
Vision-Language Models (VLMs) are regarded as efficient paradigms that build a bridge between visualperception and textual interpretation. For medical visual tasks, they can benefit from expert observation andphysician knowledge extracted from textual context, thereby improving the visual understanding of models.Motivated by the fact that extensive medical reports are commonly attached to medical imaging, medicalVLMs have triggered more and more interest, serving not only as self-supervised learning in the pretrainingstage but also as a means to introduce auxiliary information into medical visual perception. To strengthen theunderstanding of such a promising direction, this survey aims to provide an in-depth exploration and reviewof medical VLMs for various visual recognition and reasoning tasks. Firstly, we present an introduction tomedical VLMs. Then, we provide preliminaries and delve into how to exploit language in medical visual tasksfrom diverse perspectives. Further, we investigate publicly available VLM datasets and discuss the challengesand future perspectives. We expect that the comprehensive discussion about state-of-the-art medical VLMs willmake researchers realize their significant potential.
視覺語言模型(VLMs)被視為有效的范式,在視覺感知和文本解讀之間搭建了一座橋梁。對于醫學視覺任務而言,它們可以從文本語境中提取的專家觀察結果和醫生知識中獲益,從而提升模型的視覺理解能力。鑒于大量醫學報告通常會與醫學影像相關聯,醫學視覺語言模型引發了越來越多的關注,它不僅在預訓練階段作為自監督學習的方式,還可作為一種將輔助信息引入醫學視覺感知的手段。為了加強對這一前景廣闊的方向的理解,本次綜述旨在對用于各種視覺識別和推理任務的醫學視覺語言模型進行深入的探究和回顧。首先,我們對醫學視覺語言模型進行介紹。然后,我們給出相關的預備知識,并從不同角度深入探討如何在醫學視覺任務中利用語言。此外,我們對公開可用的視覺語言模型數據集進行研究,并討論其中存在的挑戰以及未來的發展前景。我們期望,對最先進的醫學視覺語言模型進行全面的討論,能讓研究人員認識到其巨大的潛力。
Method
方法
4.1. Medical vision-language pretrainingIn the discussion of medical VLP literature, we categorize VLPinto masked prediction, matching prediction, contrastive learning, andhybrid approaches according to deliberately designed self-supervisedobjective functions. An illustration of these categories is presented inFig. 5 and then we summarize relevant papers in Table 1.
4.1 醫學視覺語言預訓練
在對醫學視覺語言預訓練相關文獻的討論中,根據精心設計的自監督目標函數,我們將視覺語言預訓練(VLP)分為掩碼預測、匹配預測、對比學習以及混合方法。這些類別的圖示展示在圖 5 中,并且我們在表 1 中總結了相關的論文。
Conclusion
結論
In this comprehensive survey, we have delved into the emergingfield of medical vision-language models (medical VLMs). Commencingwith an elucidation of their background and definition, we traversedthrough a meticulous analysis of existing literature from five perspectives, presenting challenges and future directions. Throughout our review, we have emphasized their pivotal role in enhancing data efficacy,improving visual perception and reasoning accuracy, and advancinginterpretability. These models assist physicians in not only diagnosingdiseases and identifying lesions and abnormalities more accurately butalso formulating treatment plans and disseminating health information.Looking ahead, research in medical VLMs presents promising avenues for innovation and impact in both medical research and practicalapplications. The future of medical VLMs holds the potential to revolutionize healthcare delivery and augment clinical decision-making.
在這項全面的綜述中,我們深入研究了新興的醫學視覺語言模型(醫學VLM)領域。從闡釋其背景和定義開始,我們從五個角度對現有文獻進行了細致的分析,提出了面臨的挑戰和未來的發展方向。在整個綜述過程中,我們強調了醫學視覺語言模型在提高數據有效性、提升視覺感知和推理準確性以及推動可解釋性方面的關鍵作用。這些模型不僅有助于醫生更準確地診斷疾病、識別病變和異常情況,還有助于制定治療方案和傳播健康信息。 展望未來,醫學視覺語言模型的研究為醫學研究和實際應用中的創新和產生影響力提供了充滿希望的途徑。醫學視覺語言模型的未來有望徹底改變醫療服務的提供方式,并增強臨床決策能力。
Figure
圖
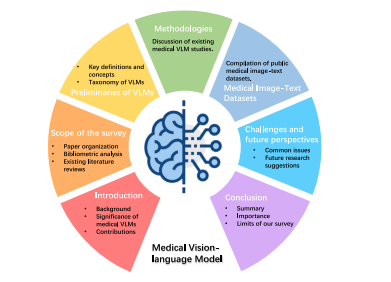
Fig. 1. The overview of medical VLMs in this review.
圖1:本次綜述中關于醫學視覺語言模型的概述。
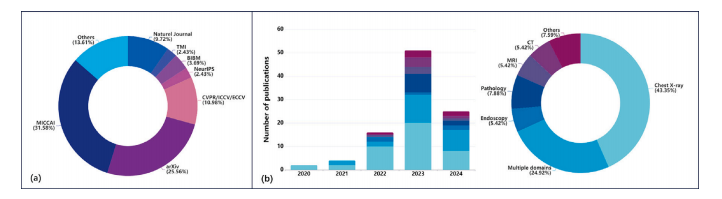
Fig. 2. Statistics of literature sources and publication years. (a) The pie chart illustrates the distribution of literature sources for the papers reviewed in our study. A significantportion of the selected papers are sourced from highly influential and authoritative conferences or journals in the fields of Machine Learning/Deep Learning (ML/DL) and Medicine.(b) Statistics of literature publication years. The bar chart shows the number of papers published each year up to the first quarter of 2024, indicating the trend and frequency ofpublications over the years. The pie chart depicts the distribution of different imaging modalities mentioned in the reviewed papers.
圖2:文獻來源和出版年份的統計數據。(a) 餅狀圖展示了本研究中所回顧論文的文獻來源分布情況。所選論文的很大一部分來源于機器學習/深度學習(ML/DL)和醫學領域中具有高度影響力和權威性的會議或期刊。(b) 文獻出版年份統計數據。條形圖顯示了截至2024年第一季度每年發表的論文數量,體現了多年來的發表趨勢和頻率。餅狀圖描繪了所回顧論文中提及的不同成像模態的分布情況。
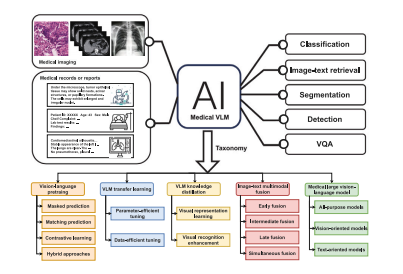
Fig. 3. Taxonomy of studies focusing on VLMs in the medical field
圖3:聚焦于醫學領域中視覺語言模型(VLM)的研究分類。
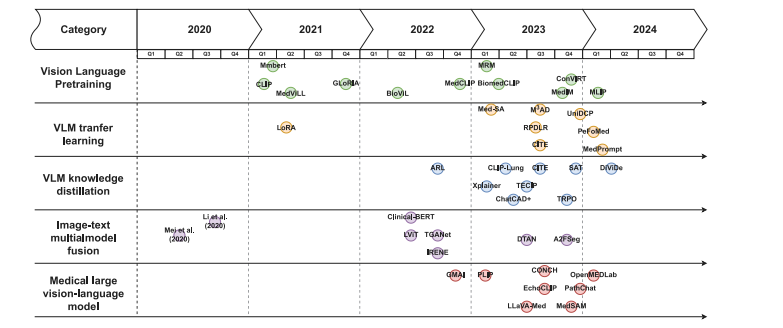
Fig. 4. Timeline of representative works in medical vision-language models (VLMs). This illustration traces the evolution of medical VLMs from five key perspectives, highlightingsignificant milestones and advancements in this field
圖4:醫學視覺語言模型(VLMs)代表性成果的時間線。此圖示從五個關鍵視角追溯醫學視覺語言模型的演變歷程,突出該領域的重要里程碑和進展。
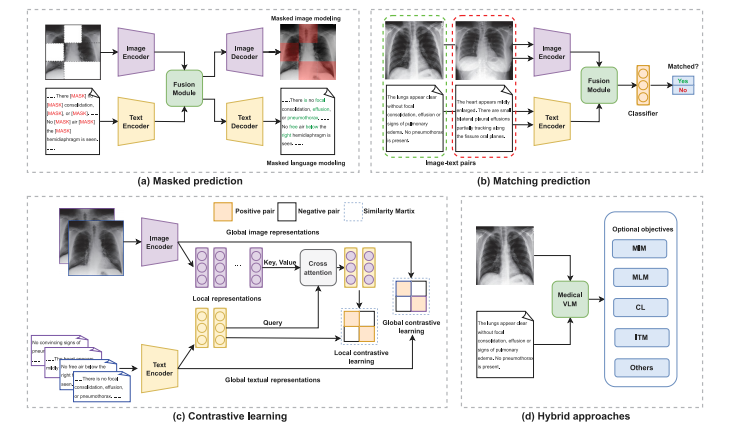
Fig. 5. An illustration of medical vision-language pretraining. Related methods are categorized into (a) Masked prediction, (b) Matching prediction, (c) Contrastive learning, and(d) Hybrid approaches. MIM: masked image modeling. MLM: masked language modeling. ITM: image–text matching. CL: contrastive learning
圖5:醫學視覺語言預訓練的圖示。相關方法分為:(a)掩碼預測,(b)匹配預測,(c)對比學習,以及(d)混合方法。MIM:掩碼圖像建模。MLM:掩碼語言建模。ITM:圖像-文本匹配。CL:對比學習。
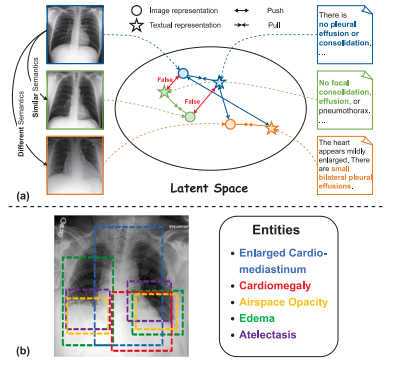
Fig. 6. Illustration of drawbacks of ITM and ITC pretraining. (a) From a globalperspective, these methods pull positive image–text representations closer while theypush image–text representations from different cases apart even if they share similarsemantics. (b) An example of multiple-to-multiple correspondences between medicalimaging and text from a local perspective
圖6:圖像-文本匹配(ITM)和圖像-文本對比(ITC)預訓練的缺點圖示。(a)從全局角度來看,這些方法使正樣本的圖像-文本表示更接近,然而,即使不同實例的圖像-文本具有相似語義,這些方法也會將它們的表示推離。(b)從局部角度展示醫學圖像與文本之間多對多對應關系的一個示例 。
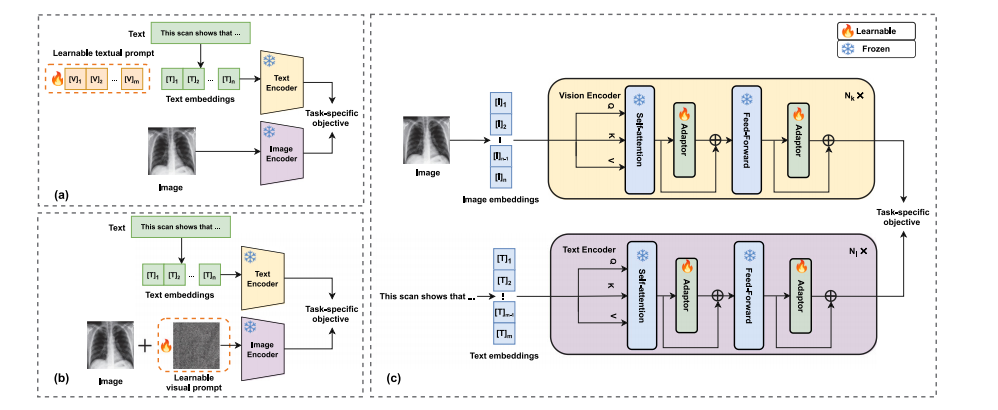
Fig. 7. Illustration of prompt tuning. (a) Textual prompt tuning. (b) Visual prompt tuning. For brevity, the illustration of visual-textual tuning is omitted, as it integrates bothtextual and visual prompt tuning. During the tuning process, all encoders’ parameters remain frozen. (c) A common placement of adapters among intermediate layers.
圖7:提示調優的圖示。(a)文本提示調優。(b)視覺提示調優。為簡潔起見,省略了視覺-文本提示調優的圖示,因為它融合了文本和視覺提示調優。在調優過程中,所有編碼器的參數保持固定不變。(c)中間層中適配器的常見放置方式。
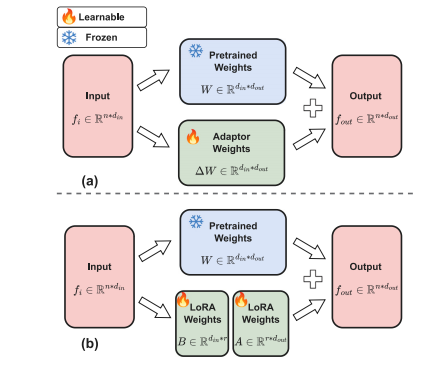
Fig. 8. Illustration of adapter tuning and LoRA. In (a) and (b), we highlight thedifferences between the vanilla adapter type and the LoRA type. (a) Details of a vanillaadapter. (b) Details of a LoRA adapter. For simplicity, we have omitted the bias terms.
圖8:適配器調優和低秩適配器(LoRA)的圖示。在(a)和(b)中,我們突出了普通適配器類型和低秩適配器(LoRA)類型之間的差異。(a)普通適配器的細節。(b)低秩適配器(LoRA)的細節。為了簡化起見,我們省略了偏差項。
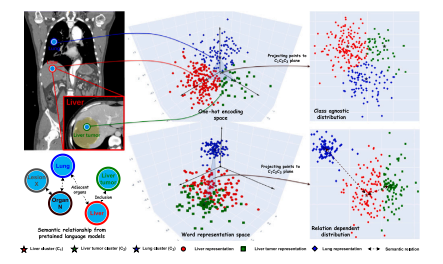
Fig. 9. Illustration of visual representation learning. The upper row visualizes thatimage features are mapped into one-hot encoding space as vanilla classification andsegmentation tasks do. In contrast, image features are mapped into the word representation space and aligned with the corresponding class-wise word representations.Compared with the former, image-word representation alignment presents a relationdependent distribution.
圖9:視覺表征學習的圖示。上排展示了圖像特征被映射到獨熱編碼空間,就像常規的分類和分割任務那樣。相比之下,圖像特征被映射到詞表征空間,并與相應的按類別劃分的詞表征進行對齊。與前者相比,圖像-詞表征對齊呈現出一種依賴于關系的分布。
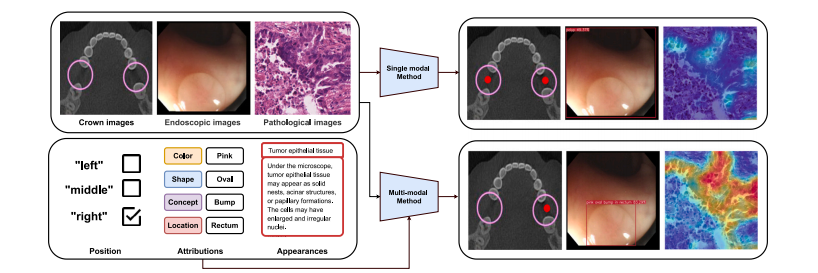
Fig. 10. Illustration of visual recognition enhancement. Position information can guide visual models for more accurate localization. Attributes such as shape, color, etc. capturethe target’s primary characteristics, aiding in precise target identification. Descriptions of the target’s appearance enhance the model’s ability to recognize the target. Such auxiliaryinformation can be introduced through manual prompts or automatic prompts without requiring extraannotations
圖10:視覺識別增強的圖示。位置信息能夠引導視覺模型實現更精確的定位。諸如形狀、顏色等屬性能夠捕捉目標的主要特征,有助于精確識別目標。對目標外觀的描述提升了模型識別目標的能力。這類輔助信息可以通過手動提示或自動提示的方式引入,無需額外的注釋。
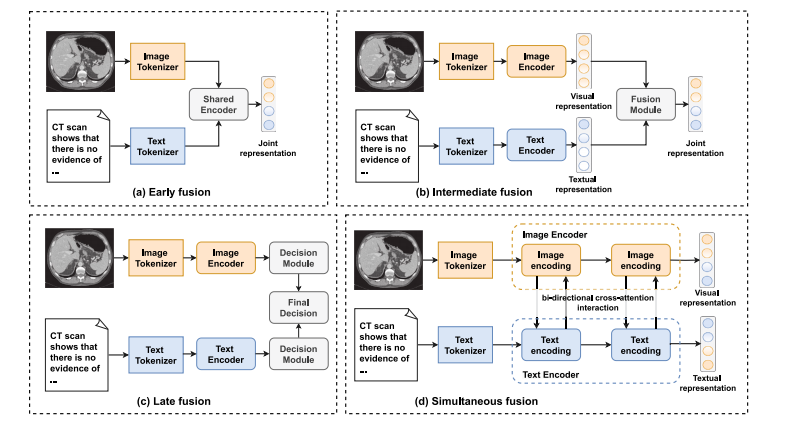
Fig. 11. An illustration of medical image–text multimodal fusion. Related methods are categorized into (a) Early fusion, (b) Intermediate fusion, (c) Late fusion, and (d) Simultaneousfusion
圖11:醫學圖像-文本多模態融合圖示。相關方法分為:(a)早期融合,(b)中間融合,(c)后期融合,以及(d)同步融合。
Table
表
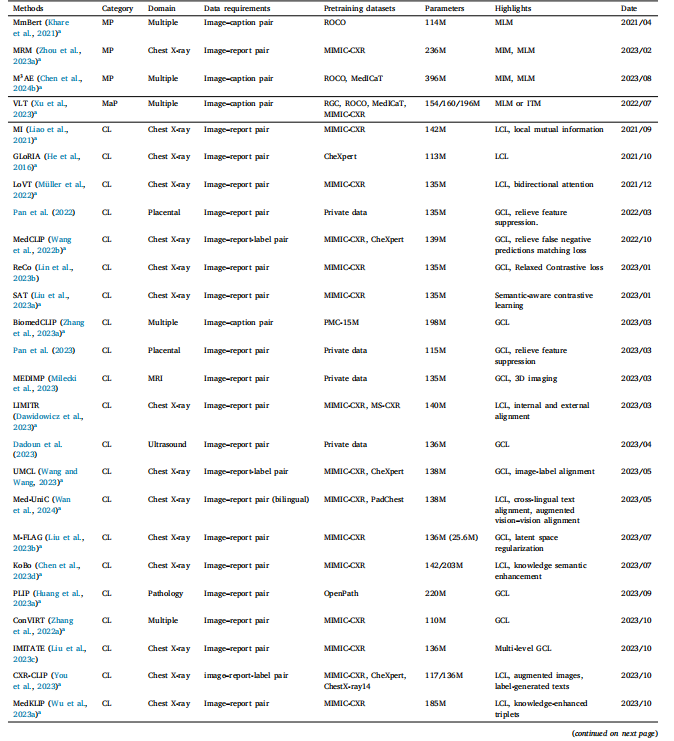
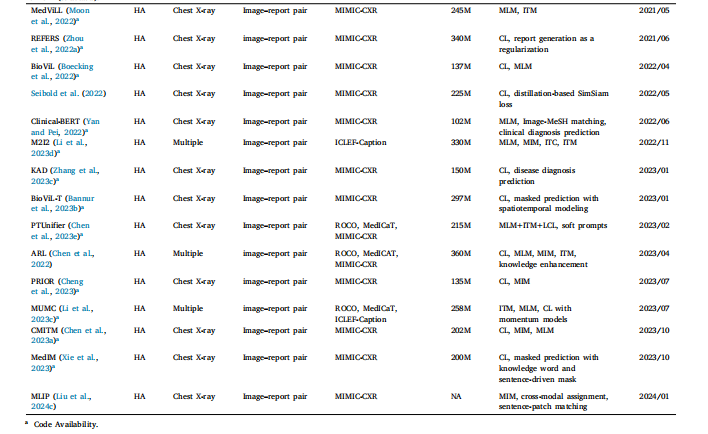
Table 1Summary of medical VLP methods. MP: Masked prediction. MaP: Matching prediction. CL: contrastive learning. HA: hybrid approach. MLM: masked language modeling. MIM:masked image modeling. ITM: image–text matching. GCL: global contrastive learning. LCL: local contrastive learning. NA: not available
表1 醫學視覺語言預訓練方法總結。MP:掩碼預測。MaP:匹配預測。CL:對比學習。HA:混合方法。MLM:掩碼語言建模。MIM:掩碼圖像建模。ITM:圖像-文本匹配。GCL:全局對比學習。LCL:局部對比學習。NA:不可用
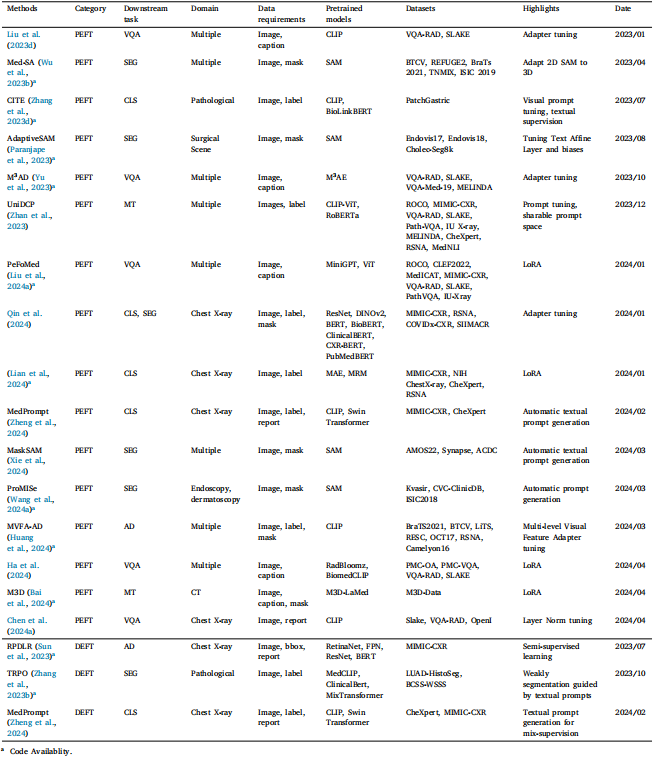
Table 2Summary of medical VLM transfer learning. CLS: classification. SEG: segmentation. VQA: visual question answering. AD: anomaly detection. MT: multiple tasks
表2 醫學視覺語言模型遷移學習總結。CLS:分類。SEG:分割。VQA:視覺問答。AD:異常檢測。MT:多項任務
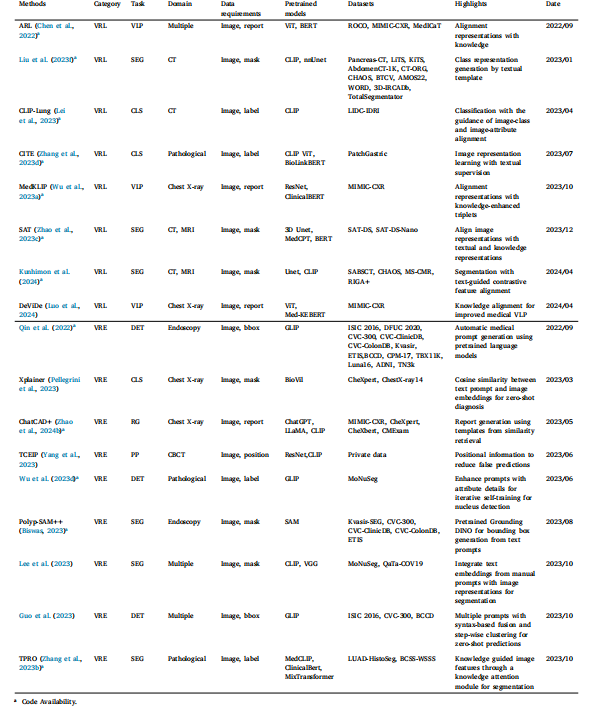
Table 3Summary of medical VLM knowledge distillation. VRL: visual representation learning. VRE: visual reasoning enhancement. CLS: classification. SEG: segmentation. PP: positionprediction. DET: detection. VLP: vision-language pretraining. RG: report generation
表3 醫學視覺語言模型知識蒸餾總結。VRL:視覺表征學習。VRE:視覺推理增強。CLS:分類。SEG:分割。PP:位置預測。DET:檢測。VLP:視覺-語言預訓練。RG:報告生成
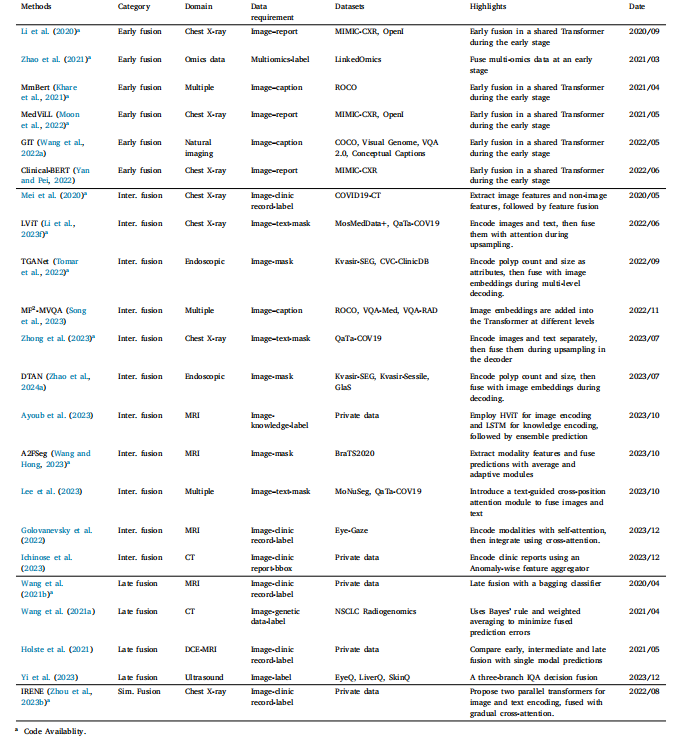
Table 4Summary of medical image–text multimodal fusion. Inter. fusion: intermediate fusion. Sim. fusion: simultaneous fusion.
表4 醫學圖像-文本多模態融合總結。Inter. fusion:中間融合。Sim. fusion:同步融合。
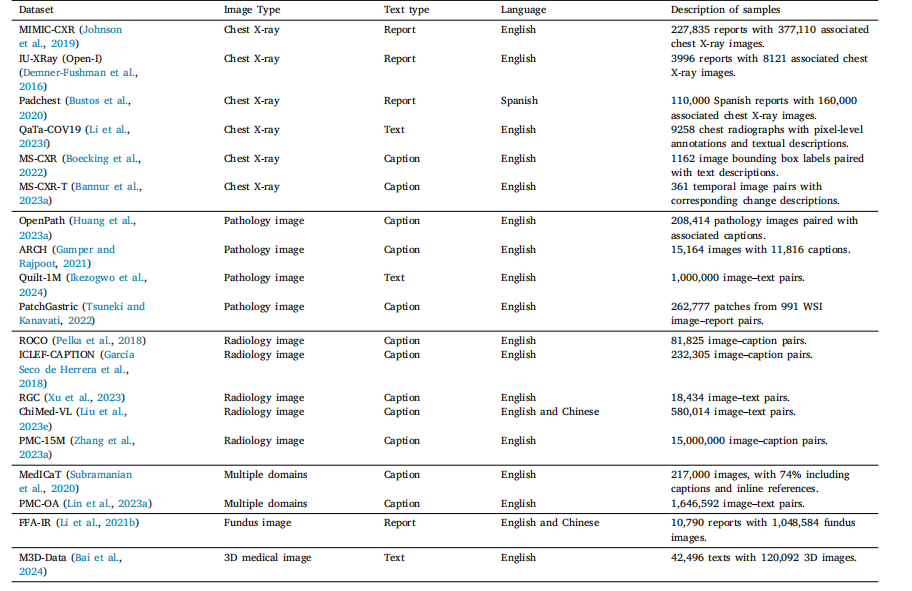
Table 5Summary of publicly available medical image–text datasets
表5 公開可用的醫學圖像-文本數據集匯總





)










)


