文章目錄
- DeepSeek推理優化技巧:提升速度與降低成本
- 引言
- 一、模型優化:減少模型參數與計算量
- 1. 模型剪枝(Pruning)
- 2. 模型量化(Quantization)
- 3. 知識蒸餾(Knowledge Distillation)
- 二、推理加速:提升計算效率
- 1. ONNX 優化
- 2. TensorRT 優化
- 3. 編譯優化(JIT)
- 三、硬件加速:利用專業設備
- 1. GPU 加速
- 2. NPU 加速
- 3. 多卡并行
- 四、內網穿透遠程調用本地大模型
- 五、總結
推薦
?
前些天發現了一個巨牛的人工智能學習網站,通俗易懂,風趣幽默,忍不住分享一下給大家。 點擊跳轉到網站
DeepSeek推理優化技巧:提升速度與降低成本
引言
DeepSeek 作為新興的大語言模型,在性能上展現出強大的潛力。然而,將 DeepSeek 應用于實際場景,尤其是高并發、低延遲的應用中,推理速度和成本往往是關鍵挑戰。本文將分享一些 DeepSeek 推理優化的實用技巧,涵蓋模型剪枝、量化、編譯優化、硬件加速等方面,并結合 cpolar 內網穿透工具 實現遠程調用本地大模型,幫助開發者更有效地利用 DeepSeek。

一、模型優化:減少模型參數與計算量
1. 模型剪枝(Pruning)
剪枝是指移除模型中不重要的連接或神經元,從而減少模型參數量。常見的剪枝方法包括:
-
基于權重的剪枝(移除接近零的權重)
-
基于激活的剪枝(移除對輸出影響小的神經元)
-
結構化剪枝(移除整個通道或層,更適合硬件加速)
-
剪枝后的模型通常需要 微調(Fine-tuning) 以恢復精度。
-
結構化剪枝相比非結構化剪枝,在 GPU/NPU 上運行時效率更高。
2. 模型量化(Quantization)
量化是指將模型中的浮點數參數(FP32)轉換為低精度整數(如 INT8/INT4),以減少存儲和計算開銷。主流方法包括:
-
訓練后量化(Post-Training Quantization):直接對訓練好的模型進行量化,簡單高效。
-
量化感知訓練(Quantization-Aware Training, QAT):在訓練過程中模擬量化,提高最終精度。
-
INT8 在大多數情況下是精度和速度的最佳平衡,INT4 可能帶來更大的精度損失。
-
量化在支持低精度計算的硬件(如 NVIDIA Tensor Cores、NPU)上效果更佳。
3. 知識蒸餾(Knowledge Distillation)
知識蒸餾使用大型 教師模型(Teacher Model) 指導小型 學生模型(Student Model) 的訓練,使其在保持較高精度的同時減少計算量。常見方法包括:
-
Logits 蒸餾:學生模型模仿教師模型的輸出概率分布。
-
中間層蒸餾(如注意力蒸餾):讓學生模型學習教師模型的中間特征表示。
-
結合 數據增強 可進一步提升學生模型的泛化能力。
二、推理加速:提升計算效率
1. ONNX 優化
ONNX(Open Neural Network Exchange)是一種開放的神經網絡交換格式,可通過 ONNX Runtime 進行高效推理優化,支持:
-
算子融合(Operator Fusion) 減少計算開銷。
-
動態/靜態形狀支持(動態形狀適用于可變輸入,靜態形狀優化更徹底)。
-
對于固定輸入尺寸的模型,使用 靜態形狀 以獲得最佳性能。
2. TensorRT 優化
TensorRT 是 NVIDIA 提供的高性能推理優化器,支持:
-
層融合(Layer Fusion) 減少內核調用次數。
-
自動內核調優(Kernel Auto-Tuning) 適配不同 GPU 架構。
-
FP16/INT8 量化 加速計算。
-
使用 校準(Calibration) 提高 INT8 量化的精度(需少量無標簽數據)。
3. 編譯優化(JIT)
使用 Just-In-Time(JIT)編譯(如 TorchScript、TensorFlow AutoGraph)將模型轉換為優化后的本地代碼:
-
TorchScript 適用于 PyTorch 模型,可優化控制流。
-
TensorFlow AutoGraph 適用于 TensorFlow,自動轉換 Python 代碼為計算圖。
-
對于動態控制流較多的模型,可能需要手動調整以最大化性能。

三、硬件加速:利用專業設備
1. GPU 加速
- 使用 CUDA Graph 減少內核啟動開銷。
- 結合 混合精度訓練(FP16+FP32) 提升計算速度。
2. NPU 加速
- 需使用廠商專用工具鏈(如華為 CANN、高通 SNPE)進行模型轉換。
- 通常比 GPU 更省電,適合移動端/邊緣設備。
3. 多卡并行
-
數據并行:適用于高吞吐場景(如批量推理)。
-
模型并行:適用于超大模型(如單請求超出單卡顯存)。
-
使用 NCCL(NVIDIA 集合通信庫)優化多 GPU 通信。
四、內網穿透遠程調用本地大模型
在模型開發和調試階段,通常需要在本地運行 DeepSeek 模型。然而,為了方便團隊協作、遠程測試或將模型集成到云端服務中,我們需要將本地模型暴露給外部網絡。cpolar是一個簡單易用的內網穿透工具,可安全地將本地服務暴露到公網。
這里演示一下如何在Windows系統中使用cpolar遠程調用本地部署的deepseek大模型,首先需要準備Ollama下載與運行deepseek模型,并添加圖形化界面Open Web UI,詳細安裝流程可以查看這篇文章:Windows本地部署deepseek-r1大模型并使用web界面遠程交互
準備完畢后,介紹一下如何安裝cpolar內網穿透,過程同樣非常簡單:
首先進入cpolar官網:
cpolar官網地址: https://www.cpolar.com
點擊免費使用注冊一個賬號,并下載最新版本的cpolar:
登錄成功后,點擊下載cpolar到本地并安裝(一路默認安裝即可)本教程選擇下載Windows版本。
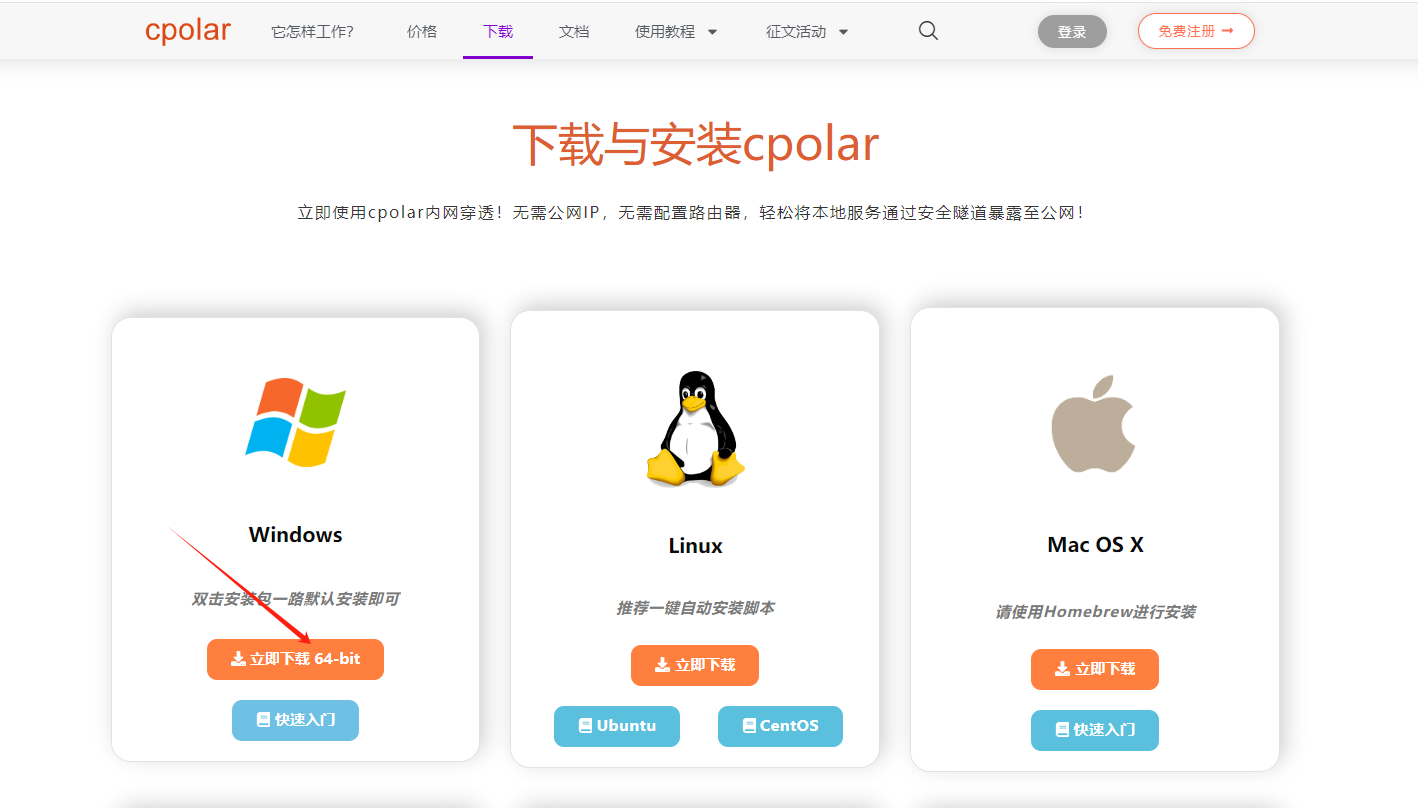
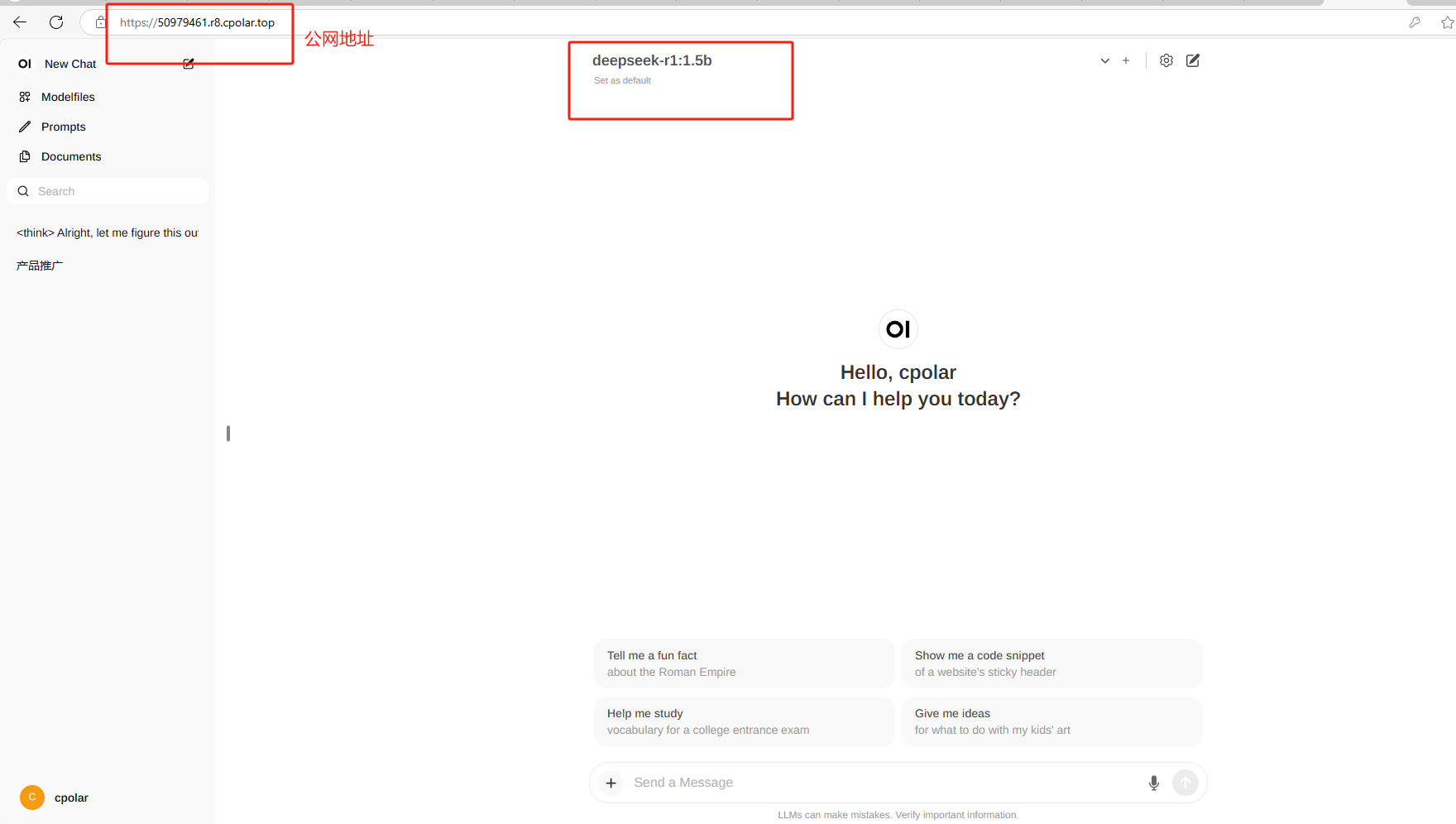
cpolar安裝成功后,在瀏覽器上訪問http://localhost:9200,使用cpolar賬號登錄,登錄后即可看到配置界面,結下來在WebUI管理界面配置即可。
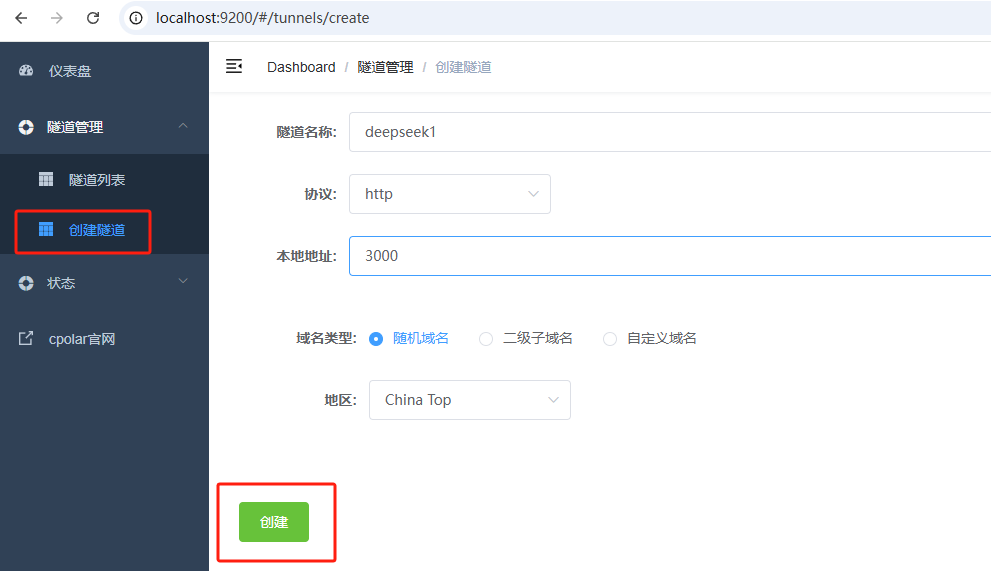
登錄后,點擊左側儀表盤的隧道管理——創建隧道,
- 隧道名稱:deepseek1(可自定義命名,注意不要與已有的隧道名稱重復)
- 協議:選擇 http
- 本地地址:3000 (本地訪問的地址)
- 域名類型:選擇隨機域名
- 地區:選擇China Top
隧道創建成功后,點擊左側的狀態——在線隧道列表,查看所生成的公網訪問地址,有兩種訪問方式,一種是http 和https:
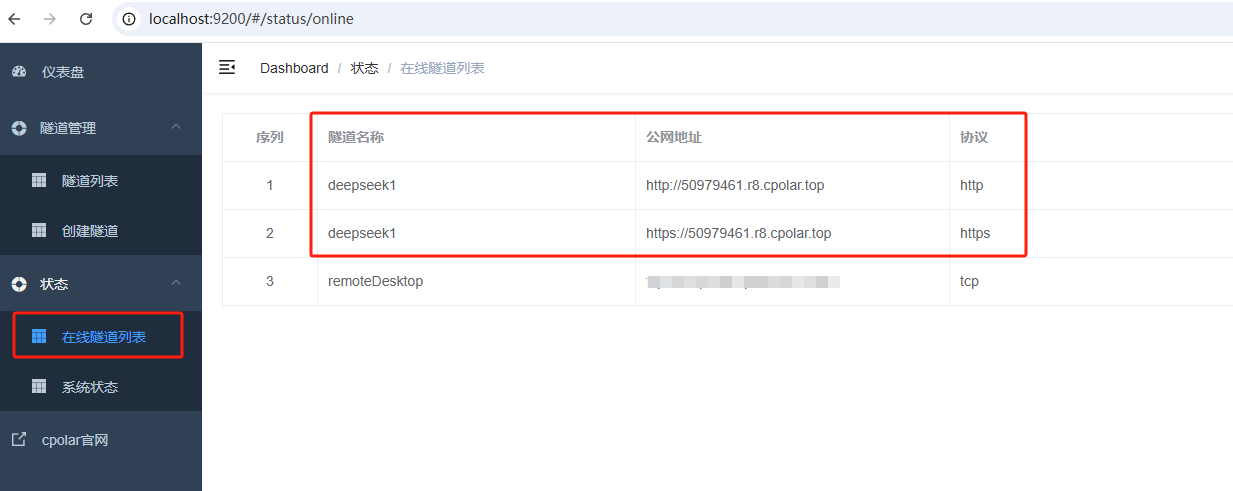
使用上面的任意一個公網地址,在手機或任意設備的瀏覽器進行登錄訪問,即可成功看到 Open WebUI 界面,這樣一個公網地址且可以遠程訪問就創建好了,使用了cpolar的公網域名,無需自己購買云服務器,即可到隨時在線訪問Open WebUI來在網頁中使用本地部署的Deepseek大模型了!
優勢:
- 安全可靠:SSL 加密傳輸,防止數據泄露。
- 簡單易用:無需復雜配置,適合快速部署。
- 穩定高效:提供低延遲的隧道服務。
安全建議:
- 如需更高安全性,可額外配置 API Key 驗證 或結合 防火墻規則。
五、總結
DeepSeek 模型的推理優化涉及 模型壓縮(剪枝/量化/蒸餾)、計算加速(ONNX/TensorRT/JIT)、硬件優化(GPU/NPU/多卡) 等多個方面。通過合理組合這些技術,可顯著提升推理速度并降低成本。
未來優化方向:
- 稀疏計算(Sparsity):利用剪枝后的稀疏結構進一步加速。
- 自適應推理(Early Exit):動態跳過部分計算層以降低延遲。
- 更高效的量化方法(如 FP8 量化)。
隨著硬件和算法的進步,DeepSeek 的推理性能將持續提升,為開發者提供更高效的 AI 解決方案。




:從客戶訪談評分到市場規模估算——移情階段的實戰進階)


)


)

數字化轉型之采購管理:從計劃到退貨的精細化管控)
:復雜地形精講之斜坡)





